58 posts tagged “agentic-engineering”
Using coding agents for professional software development. I've written a lot more about this under my broader tag ai-assisted-programming.
2026
The shared language of a software project is not English or Python but it is the common understanding of what its concepts mean, where the boundaries are, which invariants matter, who owns what, and why the system has the shape it does. This language is rarely written down in one place. It lives partly in documentation and code, but also in code review, conversations, arguments, and the experience of having to explain a change to somebody else.
Before agents, some of this shared understanding was maintained by friction. If I wanted to change your storage layer, I usually had to read your code, ask you questions, and perhaps coordinate with another team whose service depended on it. This was slow, and much of that slowness was waste but not all of it was. Some of it was the process by which your understanding became mine, and by which both of us discovered whether we still agreed about how the system worked. This friction synchronizes people.
— Armin Ronacher, The Tower Keeps Rising
Rewriting Bun in Rust (via) Jarred Sumner has been promising this blog post (since May 9th) about his Zig to Rust rewrite of Bun for significantly longer than it took him to finish the rewrite.
Honestly, it was worth the wait. This is a detailed description of an extremely sophisticated piece of agentic engineering, featuring dynamic workflows, trial runs, adversarial review and all sorts of other interesting tricks.
Jarred spends the first half of the post praising Zig for getting Bun this far. Then we get to a core idea in the piece, emphasis mine:
Our bugfix list felt bad and I was tired of going to sleep worrying about crashes in Bun. I don't blame Zig for that - other users of Zig don't have the bugs we had, and mixing GC with manually-managed memory is an uncommon enough thing for software to need that no language really designs for it. We wouldn't have gotten this far if not for Zig, and I'll always be grateful. Until very recently, programming language choice was a one-way decision for a project like Bun.
Everyone knows you should never stop the world and rewrite a large piece of software from the ground up. Joel Spolsky highlighted that in Things You Should Never Do, Part I back in April 2000!
Coding agents powered by today's frontier models change that equation.
Why pick Rust? It all came down to those challenges with memory management:
A large percentage of bugs from that list are use-after-free, double-free, and "forgot to free" in an error path. In safe Rust, these are compiler errors and RAII-like automatic cleanup with
Drop.
A crucial enabling factor for the rewrite was that the Bun test suite was written in TypeScript, which meant it could act as a conformance suite. This allowed an agent harness to automate much of the initial port from Bun to Rust, initially as an experiment to try out an earlier version of the model we now have access to as Mythos/Fable.
At first, I didn't expect it to work. A few days in, a high % of the test suite started passing and I saw how much the new Rust code matched up with the original Zig codebase. My opinion went from "this is worth trying" to "I'm going to merge this". [...]
For most of those 11 days (and after), I monitored workflows - manually reading the outputs to check for issues and bugs, and prompting Claude to edit the loop to fix things.
How do you review a PR with +1 million lines added? How do you start to build the confidence needed to responsibly merge large quantities of LLM-authored code?
A language-independent test suite with a million assertions, adversarial code review and when something does go wrong, fixing the process that generates the code instead of hand-fixing the code.
The new implementation of Bun has been live in Claude Code for nearly a month now:
Claude Code v2.1.181 (released June 17th) and later use the Rust port of Bun. Startup got 10% faster on Linux but otherwise, barely anyone noticed. Boring is good.
A perk of working at Anthropic is that you don't have to pay for your tokens - handy when the estimated cost is $165,000!
Pre-merge, this took 5.9 billion uncached input tokens, 690 million output tokens, and 72 billion cached input token reads — around $165,000 at API pricing.
This whole thing is a fascinating case study in taking on wildly ambitious projects with the help of coordinated parallel agents.
sqlite-utils 4.0, now with database schema migrations
This morning I released sqlite-utils 4.0, the 124th release of that project and the first major version bump since 3.0 in November 2020. In addition to some small but significant breaking changes (described in this upgrade guide), this version introduces three major features: database migrations, nested transactions (via a new db.atomic() method), and support for compound foreign keys.
sqlite-utils 4.0rc2, mostly written by Claude Fable (for about $149.25)
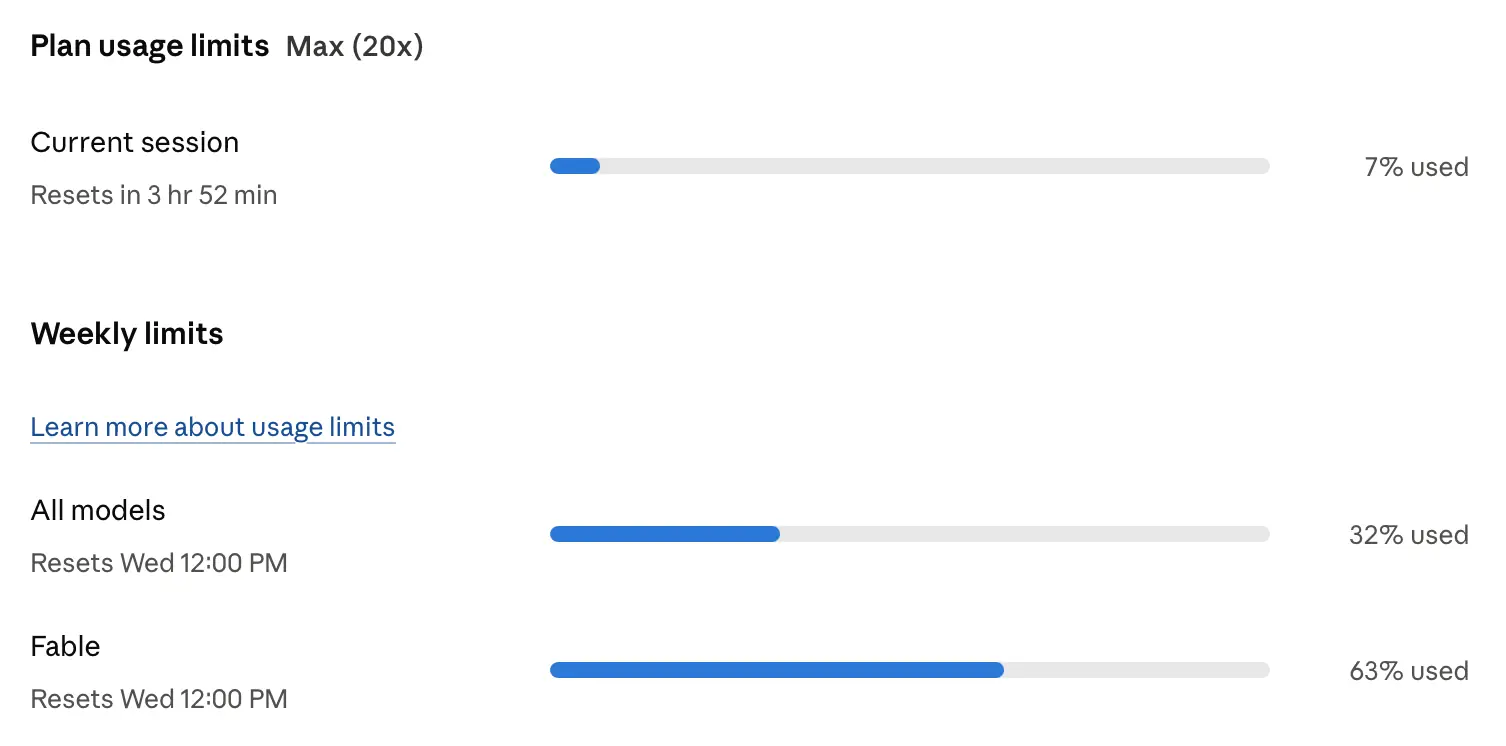
I wrote about the sqlite-utils 4.0rc1 release a couple of weeks ago. Since we only have Claude Fable on our Max subscriptions for a few more days, I decided to see if it could help me get to a 4.0 stable release that I felt truly comfortable about, since I try to keep to SemVer and like my incompatible major versions to be as rare as possible.
[... 2,427 words]Have your agent record video demos of its work with shot-scraper video
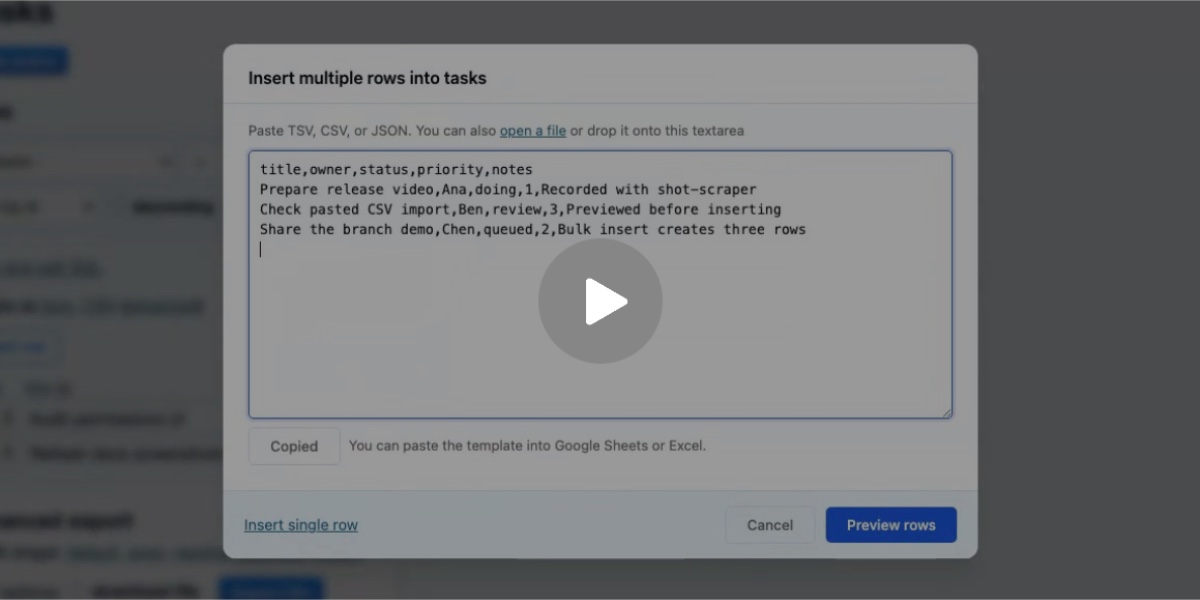
shot-scraper video is a new command introduced in today’s shot-scraper 1.10 release which accepts a storyboard.yml file defining a routine to run against a web application and uses Playwright to record a video of that routine. I’ve written before about the importance of having coding agents produce demos of their work; this is my latest attempt at enabling them to do that.
HumanAgent in the loopI dislike the phrase “human in the loop” because it cedes authority to the machines. Let’s flip the narrative. It’s our loop, we work the same way we always have, now we recruit agents to join the team. An agent-assisted process need not be a black box that takes in prompts and emits features. [...]
Let’s do agentic software development like that. Not as a loop we’ve been excluded from, instead as one we invite agents into.
— Jon Udell, “Doctor, it hurts when agents create unreviewable PRs.” “Don’t do that.”
AI enthusiasts are in a race against time, AI skeptics are in a race against entropy (via) Charity Majors neatly captures the dynamic between AI enthusiasts and AI skeptics, both of whom are trying to build great software, often in the same teams:
The enthusiasts are not wrong. We are starting to see real, non-imaginary, discontinuous leaps in capabilities from teams that lean in hard to working with AI. And this does not feel like a normal technology cycle where you can wait for the dust to settle; teams that sit this out while competitors are hustling could be out of business before the dust settles. That’s a real, existential threat.
The skeptics are also not wrong. When you ship code faster than engineers can read it, in domains where nobody has full context, you are making withdrawals from a trust account that took years to build. Reliability degrades, institutional knowledge evaporates. You end up with systems nobody understands, products burbling into incoherence, and on-call rotations that grind people up and spit them out. That is ALSO a real existential threat.
Charity recommends treating this as both a leadership challenge and an engineering challenge. The key issue:
There is no natural feedback loop connecting enthusiasts with skeptics.
Designing feedback loops to help "mend the gap in shared reality" between the two groups is a fascinating organizational design problem.
[...] On the interesting side is how fungible programming languages are nowadays. Programming languages used to be LOCK IN, and they're increasingly not so. You think the Bun rewrite in Rust is good for Rust? Bun has shown they can be in probably any language they want in roughly a week or two. Rust is expendable. Its useful until its not then it can be thrown out. That's interesting!
— Mitchell Hashimoto, on Bun porting from Zig to Rust
GitLab Act 2 (via) There's a lot going on in this announcement from GitLab about the "workforce reduction" and "structural and strategic decisions" they are making with respect to the agentic era.
- They're "planning to reduce the number of countries by up to 30% where we have small teams". One of the most interesting things about GitLab is that they have employees spread across a large number of countries - 18 are listed in their public employee handbook but this post says they are "operating in nearly 60 countries". That handbook used to document their payroll workflows for those countries too - they stopped publishing that in 2023 but the last public version (hooray for version control) remains a fascinating read. Since we don't know which of those 60 countries have small teams, we can't calculate how many countries that 30% applies to.
- "We're planning to flatten the organization, removing up to three layers of management in some functions so leaders are closer to the work." - this isn't the first announcement of this type I've seen that's trimming management. Coinbase recently announced a much more aggressive version of this: they were "flattening our org structure to 5 layers max below" and "No pure managers: Every leader at Coinbase must also be a strong and active individual contributor. Managers should be like player-coaches".
- In terms of team structure: "We're re-organizing R&D to create roughly 60 smaller, more empowered teams with end-to-end ownership, nearly doubling the number of independent teams." I've always loved the idea of individual teams that can ship features unblocked by other teams, and it makes sense to me that agentic engineering can increase the capability of such teams. The 37signals public employee handbook used to have a section on working In self-sufficient, independent teams which perfectly captured this for me, I'm sad to see they removed that detail in January 2024!
- Tucked away towards the bottom: "We will be retiring CREDIT as our values framework" - that's the values framework described on this page: "Collaboration, Results for Customers, Efficiency, Diversity, Inclusion & Belonging, Iteration, and Transparency". The new values are "Speed with Quality, Ownership Mindset, Customer Outcomes". The fact that "Diversity" is no longer in there is likely to attract a whole lot of attention, so it's worth noting that a sub-bullet under Customer Outcomes reads "Interpersonal excellence: individuals who are good humans, embrace diversity, inclusion and belonging, assume good intent and treat everyone with respect".
Here's the part of their new strategy that most resonated with me:
The agentic era multiplies demand for software. Software has been the force multiplier behind nearly every business transformation of the last two decades. The constraint was the cost and time of producing and managing it. That constraint is collapsing. As the cost of producing software collapses, demand for it will expand. Last year, the developer platform market used to be measured in tens of dollars per user per month, this year it is hundreds/user/month and headed to thousands. Not only is the value of software for builders increasing, but we believe there will be more software and builders than ever, and we will serve an increasing volume of both.
That very much encapsulates my own optimistic, Jevons-paradox-inspired hope for how this will all work out.
Their opinion on this does need to be taken with a big grain of salt though. GitLab's stock price was ~$52 a year ago and is ~$26 today, and it's plausible that the drop corresponds to uncertainty about GitLab's continued growth as agentic engineering eats its way through their core market.
If your entire business depends on software engineering growing as a field and producing larger volumes of more lucrative seats, you have a strong incentive to believe that agents will have that effect!
Your AI coding agent, the one you use to write code, needs to reduce your maintenance costs. Not by a little bit, either. You write code twice as quick now? Better hope you’ve halved your maintenance costs. Three times as productive? One third the maintenance costs. Otherwise, you’re screwed. You’re trading a temporary speed boost for permanent indenture. [...]
The math only works if the LLM decreases your maintenance costs, and by exactly the inverse of the rate it adds code. If you double your output and your cost of maintaining that output, two times two means you’ve quadrupled your maintenance costs. If you double your output and hold your maintenance costs steady, two times one means you’ve still doubled your maintenance costs.
— James Shore, You Need AI That Reduces Maintenance Costs
Vibe coding and agentic engineering are getting closer than I’d like
I recently talked with Joseph Ruscio about AI coding tools for Heavybit’s High Leverage podcast: Ep. #9, The AI Coding Paradigm Shift with Simon Willison. Here are some of my highlights, including my disturbing realization that vibe coding and agentic engineering have started to converge in my own work.
[... 1,542 words]Salvatore Sanfilippo submitted a PR adding a new data type - arrays - to Redis.
The new commands are ARCOUNT, ARDEL, ARDELRANGE, ARGET, ARGETRANGE, ARGREP, ARINFO, ARINSERT, ARLASTITEMS, ARLEN, ARMGET, ARMSET, ARNEXT, AROP, ARRING, ARSCAN, ARSEEK, ARSET.
The implementation is currently available in a branch, so I had Claude Code for web build this interactive playground for trying out the new commands in a WASM-compiled build of a subset of Redis running in the browser.
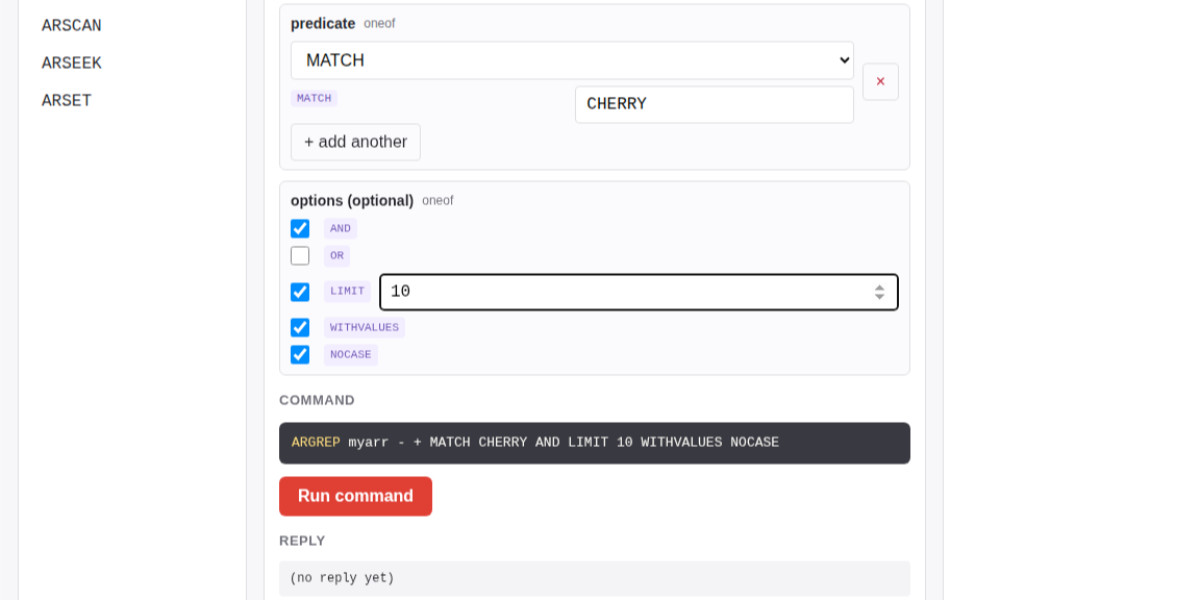
The most interesting new command is ARGREP which can run a server-side grep against a range of values in the array using the newly vendored TRE regex library.
Salvatore wrote more about the AI-assisted development process for the array type in Redis array type: short story of a long development.
Codex CLI 0.128.0 adds /goal
(via)
The latest version of OpenAI's Codex CLI coding agent adds their own version of the Ralph loop: you can now set a /goal and Codex will keep on looping until it evaluates that the goal has been completed... or the configured token budget has been exhausted.
It looks like the feature is mainly implemented though the goals/continuation.md and goals/budget_limit.md prompts, which are automatically injected at the end of a turn.
Five months in, I think I've decided that I don't want to vibecode — I want professionally managed software companies to use AI coding assistance to make more/better/cheaper software products that they sell to me for money.
— Matthew Yglesias, in a now-deleted Tweet
Extract PDF text in your browser with LiteParse for the web
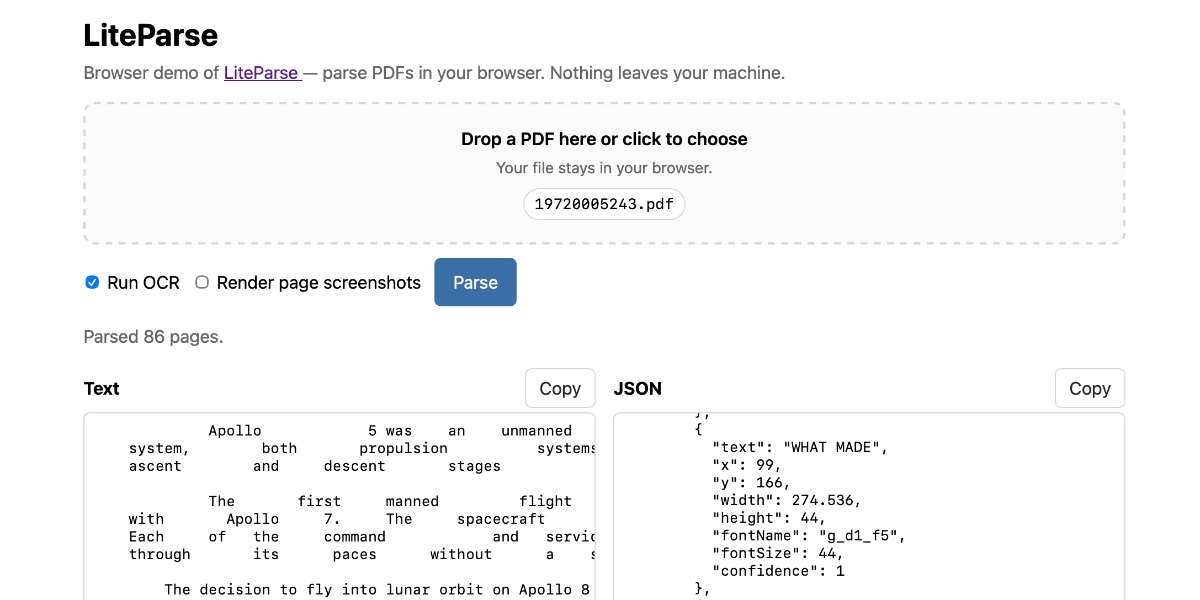
LlamaIndex have a most excellent open source project called LiteParse, which provides a Node.js CLI tool for extracting text from PDFs. I got a version of LiteParse working entirely in the browser, using most of the same libraries that LiteParse uses to run in Node.js.
[... 2,089 words]Adding a new content type to my blog-to-newsletter tool
Here's an example of a deceptively short prompt that got a quite a lot of work done in a single shot.
First, some background. I send out a free Substack newsletter around once a week containing content copied-and-pasted from my blog. I'm effectively using Substack as a lightweight way to allow people to subscribe to my blog via email.
I generate the newsletter with my blog-to-newsletter tool - an HTML and JavaScript app that fetches my latest content from this Datasette instance and formats it as rich text HTML, which I can then copy to my clipboard and paste into the Substack editor. Here's a detailed explanation of how that works. [... 902 words]
I was chatting with my buddy at Google, who's been a tech director there for about 20 years, about their AI adoption. Craziest convo I've had all year.
The TL;DR is that Google engineering appears to have the same AI adoption footprint as John Deere, the tractor company. Most of the industry has the same internal adoption curve: 20% agentic power users, 20% outright refusers, 60% still using Cursor or equivalent chat tool. It turns out Google has this curve too. [...]
There has been an industry-wide hiring freeze for 18+ months, during which time nobody has been moving jobs. So there are no clued-in people coming in from the outside to tell Google how far behind they are, how utterly mediocre they have become as an eng org.
On behalf of @Google, this post doesn't match the state of agentic coding at our company. Over 40K SWEs use agentic coding weekly here. Googlers have access to our own versions of @antigravity, @geminicli, custom models, skills, CLIs and MCPs for our daily work. Orchestrators, agent loops, virtual SWE teams and many other systems are actively available to folks. [...]
Maybe tell your buddy to do some actual work and to stop spreading absolute nonsense. This post is completely false and just pure clickbait.
Update 20th April 2026: Steve doubled down:
My tweet last week about Google's AI adoption drew a lot of pushback, to say the least.
Since then, Googlers from multiple orgs have reached out to me independently and anonymously. They've expressed fear of being doxxed, concern about what they saw as bullying of me, and general corroboration of my original tweet. [...]
Eight years of wanting, three months of building with AI (via) Lalit Maganti provides one of my favorite pieces of long-form writing on agentic engineering I've seen in ages.
They spent eight years thinking about and then three months building syntaqlite, which they describe as "high-fidelity devtools that SQLite deserves".
The goal was to provide fast, robust and comprehensive linting and verifying tools for SQLite, suitable for use in language servers and other development tools - a parser, formatter, and verifier for SQLite queries. I've found myself wanting this kind of thing in the past myself, hence my (far less production-ready) sqlite-ast project from a few months ago.
Lalit had been procrastinating on this project for years, because of the inevitable tedium of needing to work through 400+ grammar rules to help build a parser. That's exactly the kind of tedious work that coding agents excel at!
Claude Code helped get over that initial hump and build the first prototype:
AI basically let me put aside all my doubts on technical calls, my uncertainty of building the right thing and my reluctance to get started by giving me very concrete problems to work on. Instead of “I need to understand how SQLite’s parsing works”, it was “I need to get AI to suggest an approach for me so I can tear it up and build something better". I work so much better with concrete prototypes to play with and code to look at than endlessly thinking about designs in my head, and AI lets me get to that point at a pace I could not have dreamed about before. Once I took the first step, every step after that was so much easier.
That first vibe-coded prototype worked great as a proof of concept, but they eventually made the decision to throw it away and start again from scratch. AI worked great for the low level details but did not produce a coherent high-level architecture:
I found that AI made me procrastinate on key design decisions. Because refactoring was cheap, I could always say “I’ll deal with this later.” And because AI could refactor at the same industrial scale it generated code, the cost of deferring felt low. But it wasn’t: deferring decisions corroded my ability to think clearly because the codebase stayed confusing in the meantime.
The second attempt took a lot longer and involved a great deal more human-in-the-loop decision making, but the result is a robust library that can stand the test of time.
It's worth setting aside some time to read this whole thing - it's full of non-obvious downsides to working heavily with AI, as well as a detailed explanation of how they overcame those hurdles.
The key idea I took away from this concerns AI's weakness in terms of design and architecture:
When I was working on something where I didn’t even know what I wanted, AI was somewhere between unhelpful and harmful. The architecture of the project was the clearest case: I spent weeks in the early days following AI down dead ends, exploring designs that felt productive in the moment but collapsed under scrutiny. In hindsight, I have to wonder if it would have been faster just thinking it through without AI in the loop at all.
But expertise alone isn’t enough. Even when I understood a problem deeply, AI still struggled if the task had no objectively checkable answer. Implementation has a right answer, at least at a local level: the code compiles, the tests pass, the output matches what you asked for. Design doesn’t. We’re still arguing about OOP decades after it first took off.
Lalit Maganti's syntaqlite is currently being discussed on Hacker News thanks to Eight years of wanting, three months of building with AI, a deep dive into how it was built.
This inspired me to revisit a research project I ran when Lalit first released it a couple of weeks ago, where I tried it out and then compiled it to a WebAssembly wheel so it could run in Pyodide in a browser (the library itself uses C and Rust).
This new playground loads up the Python library and provides a UI for trying out its different features: formating, parsing into an AST, validating, and tokenizing SQLite SQL queries.
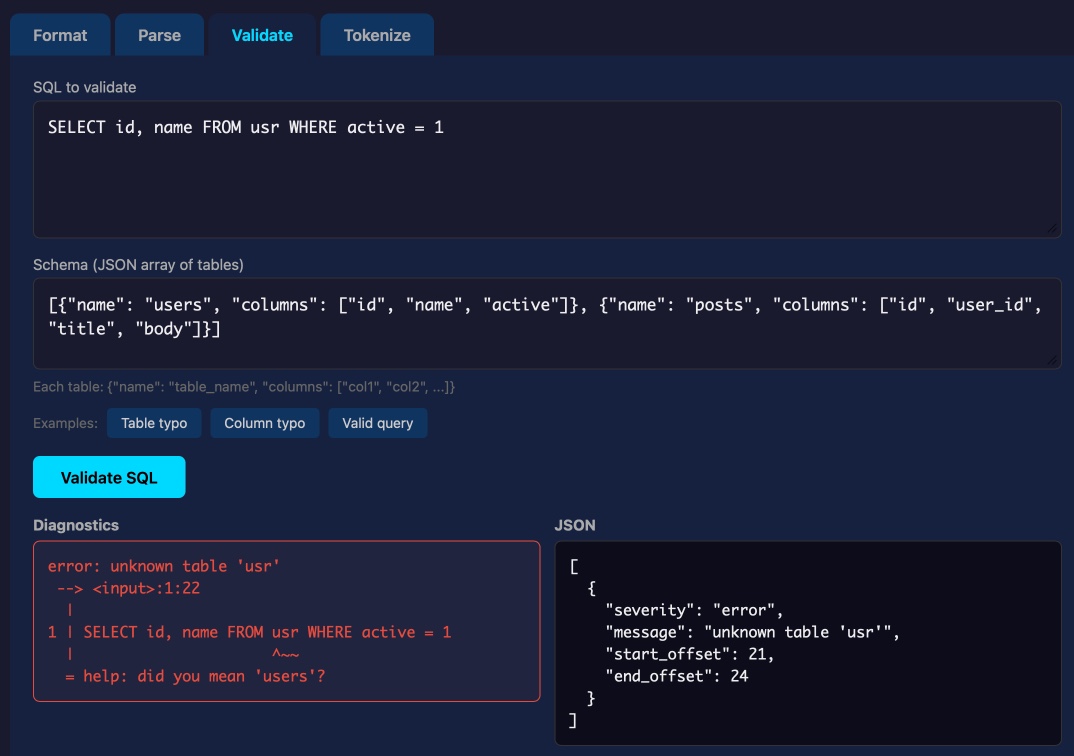
Update: not sure how I missed this but syntaqlite has its own WebAssembly playground linked to from the README.
I like publishing transcripts of local Claude Code sessions using my claude-code-transcripts tool but I'm often paranoid that one of my API keys or similar secrets might inadvertently be revealed in the detailed log files.
I built this new Python scanning tool to help reassure me. You can feed it secrets and have it scan for them in a specified directory:
uvx scan-for-secrets $OPENAI_API_KEY -d logs-to-publish/
If you leave off the -d it defaults to the current directory.
It doesn't just scan for the literal secrets - it also scans for common encodings of those secrets e.g. backslash or JSON escaping, as described in the README.
If you have a set of secrets you always want to protect you can list commands to echo them in a ~/.scan-for-secrets.conf.sh file. Mine looks like this:
llm keys get openai
llm keys get anthropic
llm keys get gemini
llm keys get mistral
awk -F= '/aws_secret_access_key/{print $2}' ~/.aws/credentials | xargs
I built this tool using README-driven-development: I carefully constructed the README describing exactly how the tool should work, then dumped it into Claude Code and told it to build the actual tool (using red/green TDD, naturally.)
A fun thing about recording a podcast with a professional like Lenny Rachitsky is that his team know how to slice the resulting video up into TikTok-sized short form vertical videos. Here's one he shared on Twitter today which ended up attracting over 1.1m views!
That was 48 seconds. Our full conversation lasted 1 hour 40 minutes.
Highlights from my conversation about agentic engineering on Lenny’s Podcast

I was a guest on Lenny Rachitsky’s podcast, in a new episode titled An AI state of the union: We’ve passed the inflection point, dark factories are coming, and automation timelines. It’s available on YouTube, Spotify, and Apple Podcasts. Here are my highlights from our conversation, with relevant links.
[... 3,558 words]I want to argue that AI models will write good code because of economic incentives. Good code is cheaper to generate and maintain. Competition is high between the AI models right now, and the ones that win will help developers ship reliable features fastest, which requires simple, maintainable code. Good code will prevail, not only because we want it to (though we do!), but because economic forces demand it. Markets will not reward slop in coding, in the long-term.
— Soohoon Choi, Slop Is Not Necessarily The Future
The thing about agentic coding is that agents grind problems into dust. Give an agent a problem and a while loop and - long term - it’ll solve that problem even if it means burning a trillion tokens and re-writing down to the silicon. [...]
But we want AI agents to solve coding problems quickly and in a way that is maintainable and adaptive and composable (benefiting from improvements elsewhere), and where every addition makes the whole stack better.
So at the bottom is really great libraries that encapsulate hard problems, with great interfaces that make the “right” way the easy way for developers building apps with them. Architecture!
While I’m vibing (I call it vibing now, not coding and not vibe coding) while I’m vibing, I am looking at lines of code less than ever before, and thinking about architecture more than ever before.
— Matt Webb, An appreciation for (technical) architecture
We Rewrote JSONata with AI in a Day, Saved $500K/Year. Bit of a hyperbolic framing but this looks like another case study of vibe porting, this time spinning up a new custom Go implementation of the JSONata JSON expression language - similar in focus to jq, and heavily associated with the Node-RED platform.
As with other vibe-porting projects the key enabling factor was JSONata's existing test suite, which helped build the first working Go version in 7 hours and $400 of token spend.
The Reco team then used a shadow deployment for a week to run the new and old versions in parallel to confirm the new implementation exactly matched the behavior of the old one.
Thoughts on slowing the fuck down. Mario Zechner created the Pi agent framework used by OpenClaw, giving considerable credibility to his opinions on current trends in agentic engineering. He's not impressed:
We have basically given up all discipline and agency for a sort of addiction, where your highest goal is to produce the largest amount of code in the shortest amount of time. Consequences be damned.
Agents and humans both make mistakes, but agent mistakes accumulate much faster:
A human is a bottleneck. A human cannot shit out 20,000 lines of code in a few hours. Even if the human creates such booboos at high frequency, there's only so many booboos the human can introduce in a codebase per day. [...]
With an orchestrated army of agents, there is no bottleneck, no human pain. These tiny little harmless booboos suddenly compound at a rate that's unsustainable. You have removed yourself from the loop, so you don't even know that all the innocent booboos have formed a monster of a codebase. You only feel the pain when it's too late. [...]
You have zero fucking idea what's going on because you delegated all your agency to your agents. You let them run free, and they are merchants of complexity.
I think Mario is exactly right about this. Agents let us move so much faster, but this speed also means that changes which we would normally have considered over the course of weeks are landing in a matter of hours.
It's so easy to let the codebase evolve outside of our abilities to reason clearly about it. Cognitive debt is real.
Mario recommends slowing down:
Give yourself time to think about what you're actually building and why. Give yourself an opportunity to say, fuck no, we don't need this. Set yourself limits on how much code you let the clanker generate per day, in line with your ability to actually review the code.
Anything that defines the gestalt of your system, that is architecture, API, and so on, write it by hand. [...]
I'm not convinced writing by hand is the best way to address this, but it's absolutely the case that we need the discipline to find a new balance of speed v.s. mental thoroughness now that typing out the code is no longer anywhere close to being the bottleneck on writing software.
Experimenting with Starlette 1.0 with Claude skills
Starlette 1.0 is out! This is a really big deal. I think Starlette may be the Python framework with the most usage compared to its relatively low brand recognition because Starlette is the foundation of FastAPI, which has attracted a huge amount of buzz that seems to have overshadowed Starlette itself.
[... 1,194 words]Using Git with coding agents
Git is a key tool for working with coding agents. Keeping code in version control lets us record how that code changes over time and investigate and reverse any mistakes. All of the coding agents are fluent in using Git's features, both basic and advanced.
This fluency means we can be more ambitious about how we use Git ourselves. We don't need to memorize how to do things with Git, but staying aware of what's possible means we can take advantage of the full suite of Git's abilities.
Git essentials
Each Git project lives in a repository - a folder on disk that can track changes made to the files within it. Those changes are recorded in commits - timestamped bundles of changes to one or more files accompanied by a commit message describing those changes and an author recording who made them. [... 1,396 words]
Subagents
LLMs are restricted by their context limit - how many tokens they can fit in their working memory at any given time. These values have not increased much over the past two years even as the LLMs themselves have seen dramatic improvements in their abilities - they generally top out at around 1,000,000, and benchmarks frequently report better quality results below 200,000.
Carefully managing the context such that it fits within those limits is critical to getting great results out of a model.
Subagents provide a simple but effective way to handle larger tasks without burning through too much of the coding agent’s valuable top-level context. [... 926 words]
Use subagents and custom agents in Codex (via) Subagents were announced in general availability today for OpenAI Codex, after several weeks of preview behind a feature flag.
They're very similar to the Claude Code implementation, with default subagents for "explorer", "worker" and "default". It's unclear to me what the difference between "worker" and "default" is but based on their CSV example I think "worker" is intended for running large numbers of small tasks in parallel.
Codex also lets you define custom agents as TOML files in ~/.codex/agents/. These can have custom instructions and be assigned to use specific models - including gpt-5.3-codex-spark if you want some raw speed. They can then be referenced by name, as demonstrated by this example prompt from the documentation:
Investigate why the settings modal fails to save. Have browser_debugger reproduce it, code_mapper trace the responsible code path, and ui_fixer implement the smallest fix once the failure mode is clear.
The subagents pattern is widely supported in coding agents now. Here's documentation across a number of different platforms:
- OpenAI Codex subagents
- Claude Code subagents
- Gemini CLI subagents (experimental)
- Mistral Vibe subagents
- OpenCode agents
- Subagents in Visual Studio Code
- Cursor Subagents
Update: I added a chapter on Subagents to my Agentic Engineering Patterns guide.