5 posts tagged “pi”
The Pi agent hardness and coding agent.
2026
Better Models: Worse Tools. Armin reports on a weird problem he ran into while hacking on Pi:
The short version is that newer Claude models sometimes call Pi’s edit tool with extra, invented fields in the nested
edits[]array. And not Haiku or some small model: Opus 4.8. The edit itself is usually correct but the arguments do not match the schema as the model invents made-up keys and Pi thus rejects the tool call and asks to try again.That alone is not too surprising as models emit malformed tool calls sometimes. Particularly small ones. What surprised me is that this is getting worse with newer Anthropic models as both Opus 4.8 and Sonnet 5 show it but none of the older models. In other words, the SOTA models of the family are worse at this specific tool schema than their older siblings.
Armin theorizes that this is because more recent Anthropic models have been specifically trained (presumably via Reinforcement Learning) to better use the edit tools that are baked into Claude Code. This has the unfortunate effect that other coding harnesses, such as Pi, may find that their own custom edit tools are more likely to be used incorrectly.
Claude's edit tool uses search and replace. OpenAI's Codex uses an apply_patch mechanism instead, and OpenAI have talked in the past about how their models are trained to use that tool effectively.
Does this mean third-party coding harnesses like Pi should implement multiple edit tools just so they can use the one with the best performance for the underlying model the user has selected?
I can 100% attest to the fact that Qwen3.6-27B is a very capable local model for coding tasks. Over the last month and a half I've been using it almost daily, either on my M2 Ultra or on my RTX 5090 box. I use it for small mundane tasks at ggml-org - nothing really impressive, but definitely a helpful tool for a maintainer. I think I would be using it much more, if I didn't have to spend a lot of my time on reviewing PRs. Currently, I have a very lightweight harness - the pi agent with everything stripped (
pi -nc --offline) and a short system prompt to align it a bit with my style.
— Georgi Gerganov, Hacker News comment on Running local models is good now by Boykis
The most frustrating failure mode right now is that people submit issues that are not in their own voice. They contain an observed problem somewhere, but it has been thrown into a clanker and the clanker reworded it and made a huge mess of it. Typically, it was prompted so badly that the conclusions produced are more often than not inaccurate but always full of confidence. The result is complete guesswork on root causes, fake-minimal repros, suggested implementation strategies, analogies to adjacent but often the wrong code, and long lists of error classes that might or might not matter. [...]
So at least personally, I increasingly want issue reports to be condensed to what the human actually observed:
- I ran this command.
- I expected this to happen.
- This happened instead.
- Here is the exact error or log.
— Armin Ronacher, on slop issues filed against Pi
Thoughts on slowing the fuck down. Mario Zechner created the Pi agent framework used by OpenClaw, giving considerable credibility to his opinions on current trends in agentic engineering. He's not impressed:
We have basically given up all discipline and agency for a sort of addiction, where your highest goal is to produce the largest amount of code in the shortest amount of time. Consequences be damned.
Agents and humans both make mistakes, but agent mistakes accumulate much faster:
A human is a bottleneck. A human cannot shit out 20,000 lines of code in a few hours. Even if the human creates such booboos at high frequency, there's only so many booboos the human can introduce in a codebase per day. [...]
With an orchestrated army of agents, there is no bottleneck, no human pain. These tiny little harmless booboos suddenly compound at a rate that's unsustainable. You have removed yourself from the loop, so you don't even know that all the innocent booboos have formed a monster of a codebase. You only feel the pain when it's too late. [...]
You have zero fucking idea what's going on because you delegated all your agency to your agents. You let them run free, and they are merchants of complexity.
I think Mario is exactly right about this. Agents let us move so much faster, but this speed also means that changes which we would normally have considered over the course of weeks are landing in a matter of hours.
It's so easy to let the codebase evolve outside of our abilities to reason clearly about it. Cognitive debt is real.
Mario recommends slowing down:
Give yourself time to think about what you're actually building and why. Give yourself an opportunity to say, fuck no, we don't need this. Set yourself limits on how much code you let the clanker generate per day, in line with your ability to actually review the code.
Anything that defines the gestalt of your system, that is architecture, API, and so on, write it by hand. [...]
I'm not convinced writing by hand is the best way to address this, but it's absolutely the case that we need the discipline to find a new balance of speed v.s. mental thoroughness now that typing out the code is no longer anywhere close to being the bottleneck on writing software.
Shopify/liquid: Performance: 53% faster parse+render, 61% fewer allocations (via) PR from Shopify CEO Tobias Lütke against Liquid, Shopify's open source Ruby template engine that was somewhat inspired by Django when Tobi first created it back in 2005.
Tobi found dozens of new performance micro-optimizations using a variant of autoresearch, Andrej Karpathy's new system for having a coding agent run hundreds of semi-autonomous experiments to find new effective techniques for training nanochat.
Tobi's implementation started two days ago with this autoresearch.md prompt file and an autoresearch.sh script for the agent to run to execute the test suite and report on benchmark scores.
The PR now lists 93 commits from around 120 automated experiments. The PR description lists what worked in detail - some examples:
- Replaced StringScanner tokenizer with
String#byteindex. Single-bytebyteindexsearching is ~40% faster than regex-basedskip_until. This alone reduced parse time by ~12%.- Pure-byte
parse_tag_token. Eliminated the costlyStringScanner#string=reset that was called for every{% %}token (878 times). Manual byte scanning for tag name + markup extraction is faster than resetting and re-scanning via StringScanner. [...]- Cached small integer
to_s. Pre-computed frozen strings for 0-999 avoid 267Integer#to_sallocations per render.
This all added up to a 53% improvement on benchmarks - truly impressive for a codebase that's been tweaked by hundreds of contributors over 20 years.
I think this illustrates a number of interesting ideas:
- Having a robust test suite - in this case 974 unit tests - is a massive unlock for working with coding agents. This kind of research effort would not be possible without first having a tried and tested suite of tests.
- The autoresearch pattern - where an agent brainstorms a multitude of potential improvements and then experiments with them one at a time - is really effective.
- If you provide an agent with a benchmarking script "make it faster" becomes an actionable goal.
- CEOs can code again! Tobi has always been more hands-on than most, but this is a much more significant contribution than anyone would expect from the leader of a company with 7,500+ employees. I've seen this pattern play out a lot over the past few months: coding agents make it feasible for people in high-interruption roles to productively work with code again.
Here's Tobi's GitHub contribution graph for the past year, showing a significant uptick following that November 2025 inflection point when coding agents got really good.
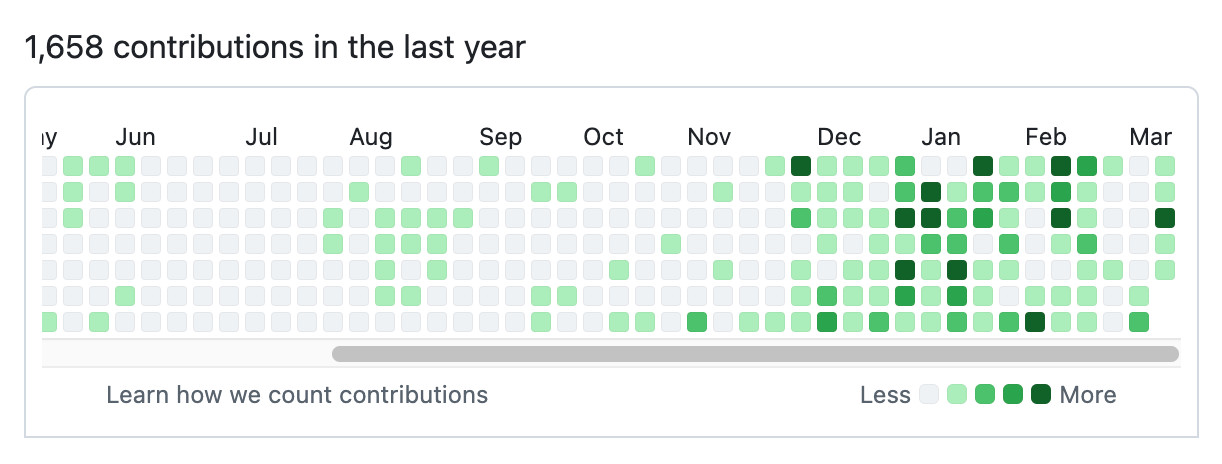
He used Pi as the coding agent and released a new pi-autoresearch plugin in collaboration with David Cortés, which maintains state in an autoresearch.jsonl file like this one.