Entries
Filters: Sorted by date
Maybe Meta’s Llama claims to be open source because of the EU AI act

I encountered a theory a while ago that one of the reasons Meta insist on using the term “open source” for their Llama models despite the Llama license not actually conforming to the terms of the Open Source Definition is that the EU’s AI act includes special rules for open source models without requiring OSI compliance.
[... 852 words]Image segmentation using Gemini 2.5

Max Woolf pointed out this new feature of the Gemini 2.5 series (here’s my coverage of 2.5 Pro and 2.5 Flash) in a comment on Hacker News:
[... 1,428 words]GPT-4.1: Three new million token input models from OpenAI, including their cheapest model yet

OpenAI introduced three new models this morning: GPT-4.1, GPT-4.1 mini and GPT-4.1 nano. These are API-only models right now, not available through the ChatGPT interface (though you can try them out in OpenAI’s API playground). All three models can handle 1,047,576 tokens of input and 32,768 tokens of output, and all three have a May 31, 2024 cut-off date (their previous models were mostly September 2023).
[... 1,124 words]CaMeL offers a promising new direction for mitigating prompt injection attacks
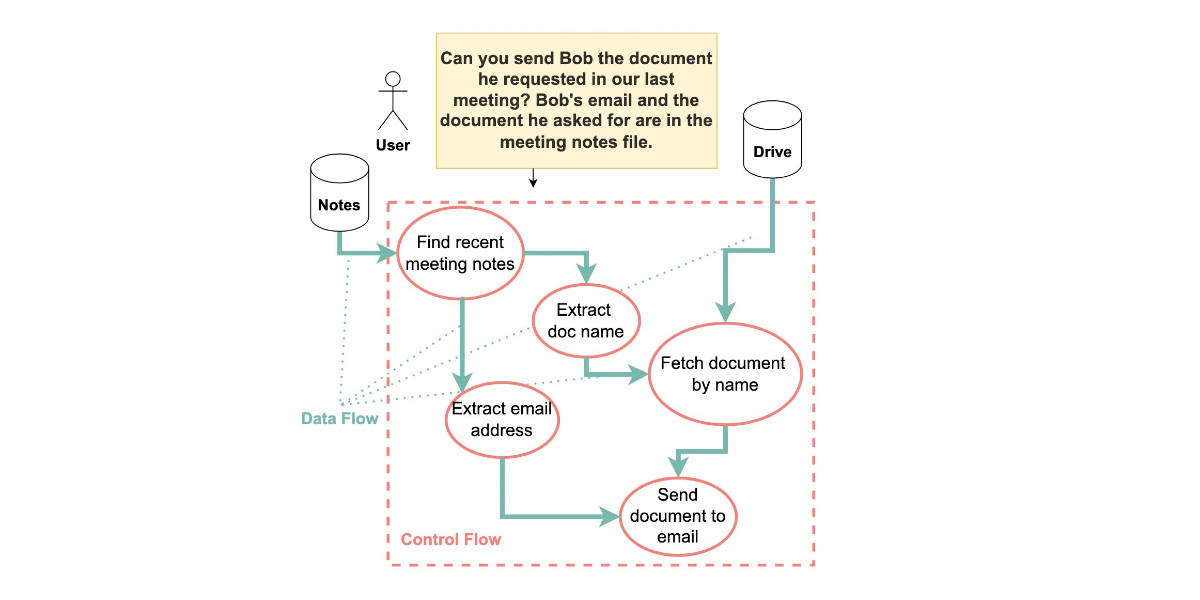
In the two and a half years that we’ve been talking about prompt injection attacks I’ve seen alarmingly little progress towards a robust solution. The new paper Defeating Prompt Injections by Design from Google DeepMind finally bucks that trend. This one is worth paying attention to.
[... 2,052 words]Model Context Protocol has prompt injection security problems
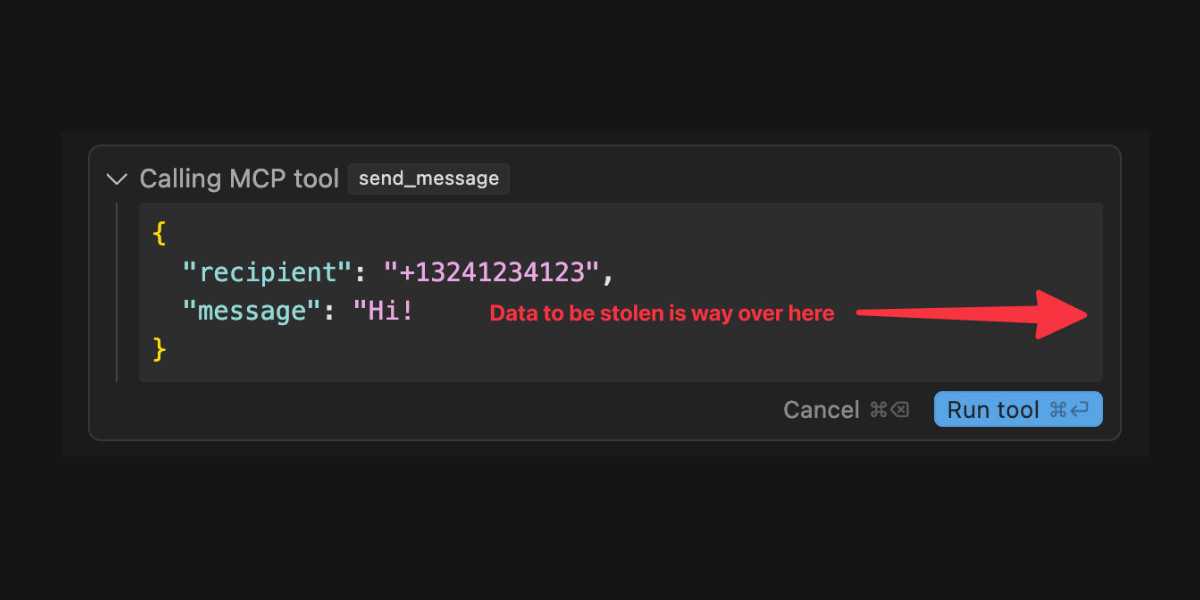
As more people start hacking around with implementations of MCP (the Model Context Protocol, a new standard for making tools available to LLM-powered systems) the security implications of tools built on that protocol are starting to come into focus.
[... 1,559 words]Long context support in LLM 0.24 using fragments and template plugins
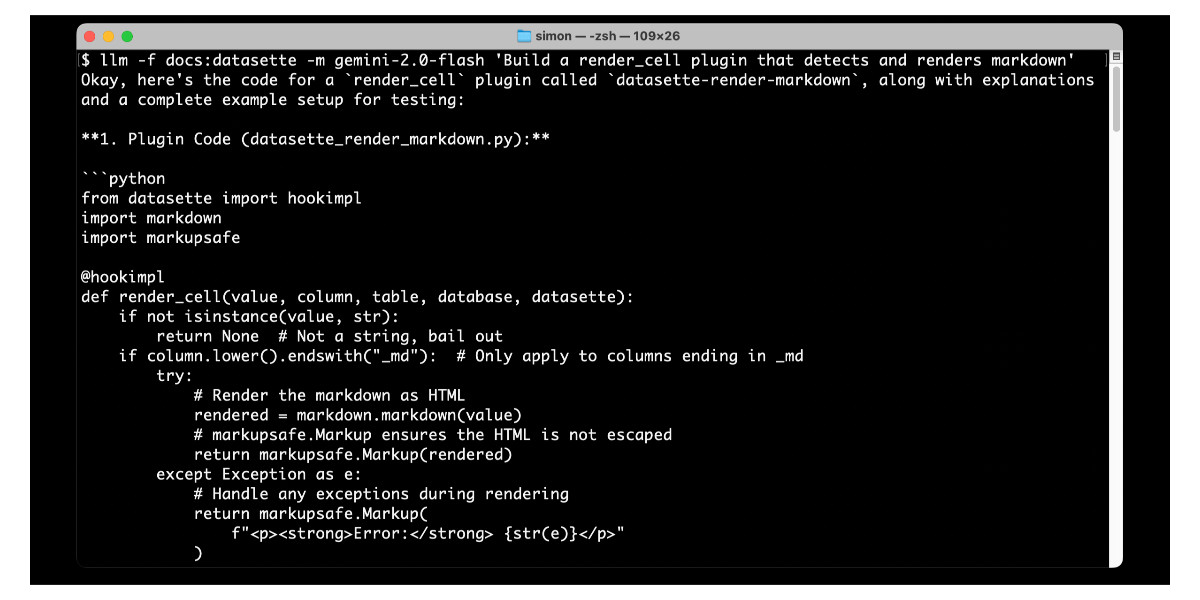
LLM 0.24 is now available with new features to help take advantage of the increasingly long input context supported by modern LLMs.
[... 1,896 words]Initial impressions of Llama 4
Dropping a model release as significant as Llama 4 on a weekend is plain unfair! So far the best place to learn about the new model family is this post on the Meta AI blog. They’ve released two new models today: Llama 4 Maverick is a 400B model (128 experts, 17B active parameters), text and image input with a 1 million token context length. Llama 4 Scout is 109B total parameters (16 experts, 17B active), also multi-modal and with a claimed 10 million token context length—an industry first.
[... 1,468 words]Putting Gemini 2.5 Pro through its paces

There’s a new release from Google Gemini this morning: the first in the Gemini 2.5 series. Google call it “a thinking model, designed to tackle increasingly complex problems”. It’s already sat at the top of the LM Arena leaderboard, and from initial impressions looks like it may deserve that top spot.
[... 2,400 words]New audio models from OpenAI, but how much can we rely on them?
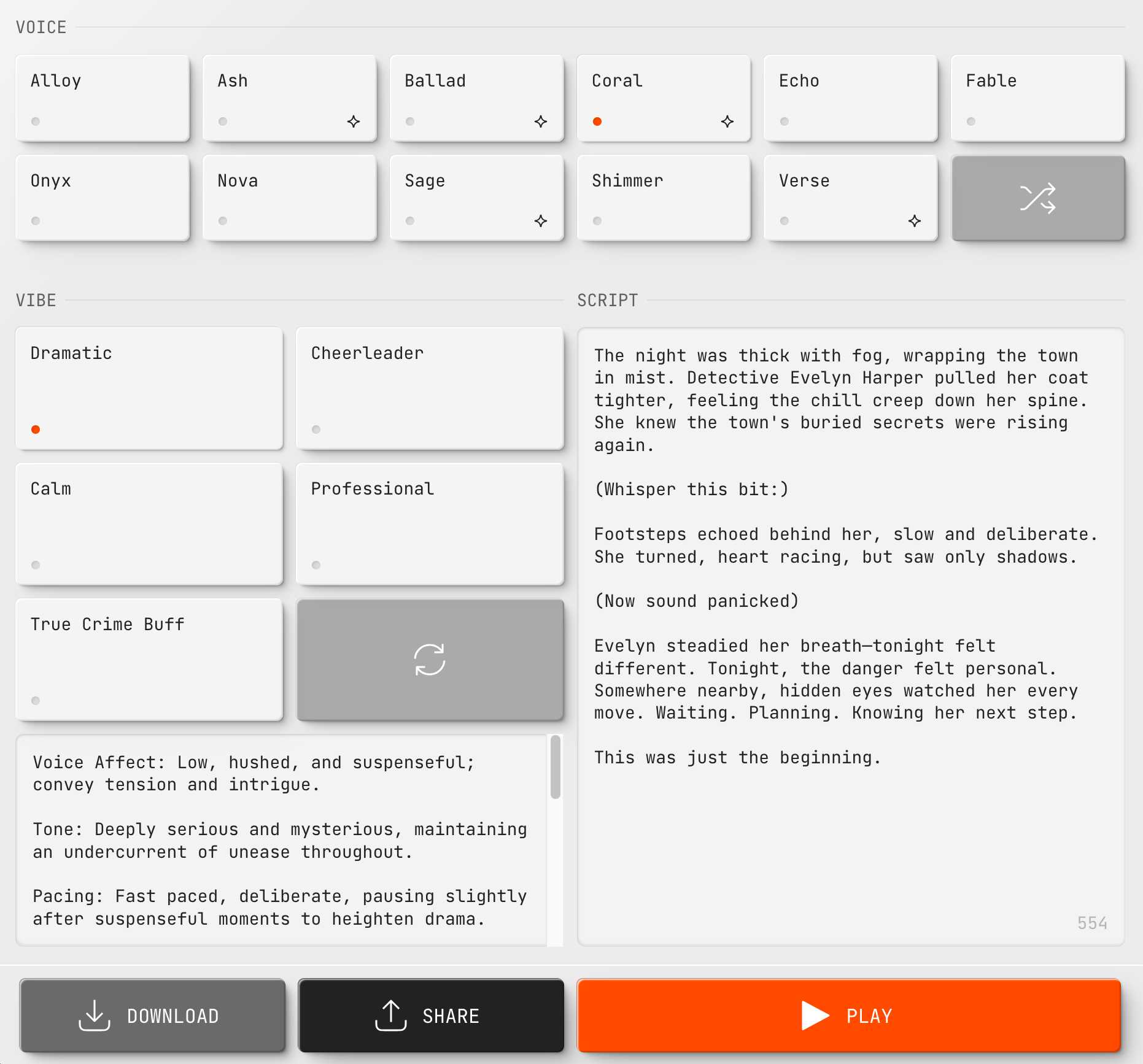
OpenAI announced several new audio-related API features today, for both text-to-speech and speech-to-text. They’re very promising new models, but they appear to suffer from the ever-present risk of accidental (or malicious) instruction following.
[... 866 words]Calling a wrap on my weeknotes
After 192 posts that ranged from weekly to roughly once-a-month, I’ve decided to call a wrap on my weeknotes habit. The original goal was to stay transparent during my 2019-2020 JSK fellowship, and I kept them up after that as an accountability mechanism and to get into a habit of writing regularly.
[... 281 words]Not all AI-assisted programming is vibe coding (but vibe coding rocks)
Vibe coding is having a moment. The term was coined by Andrej Karpathy just a few weeks ago (on February 6th) and has since been featured in the New York Times, Ars Technica, the Guardian and countless online discussions.
[... 1,486 words]Adding AI-generated descriptions to my tools collection

The /colophon page on my tools.simonwillison.net site lists all 78 of the HTML+JavaScript tools I’ve built (with AI assistance) along with their commit histories, including links to prompting transcripts. I wrote about how I built that colophon the other day. It now also includes a description of each tool, generated using Claude 3.7 Sonnet.
[... 741 words]Notes on Google’s Gemma 3
Google’s Gemma team released an impressive new model today (under their not-open-source Gemma license). Gemma 3 comes in four sizes—1B, 4B, 12B, and 27B—and while 1B is text-only the larger three models are all multi-modal for vision:
[... 804 words]Here’s how I use LLMs to help me write code
Online discussions about using Large Language Models to help write code inevitably produce comments from developers who’s experiences have been disappointing. They often ask what they’re doing wrong—how come some people are reporting such great results when their own experiments have proved lacking?
[... 5,178 words]What’s new in the world of LLMs, for NICAR 2025

I presented two sessions at the NICAR 2025 data journalism conference this year. The first was this one based on my review of LLMs in 2024, extended by several months to cover everything that’s happened in 2025 so far. The second was a workshop on Cutting-edge web scraping techniques, which I’ve written up separately.
[... 2,797 words]I built an automaton called Squadron

I believe that the price you have to pay for taking on a project is writing about it afterwards. On that basis, I feel compelled to write up my decidedly non-software project from this weekend: Squadron, an automaton.
[... 1,142 words]Notes from my Accessibility and Gen AI podcast appearance

I was a guest on the most recent episode of the Accessibility + Gen AI Podcast, hosted by Eamon McErlean and Joe Devon. We had a really fun, wide-ranging conversation about a host of different topics. I’ve extracted a few choice quotes from the transcript.
[... 947 words]Hallucinations in code are the least dangerous form of LLM mistakes
A surprisingly common complaint I see from developers who have tried using LLMs for code is that they encountered a hallucination—usually the LLM inventing a method or even a full software library that doesn’t exist—and it crashed their confidence in LLMs as a tool for writing code. How could anyone productively use these things if they invent methods that don’t exist?
[... 1,052 words]Structured data extraction from unstructured content using LLM schemas
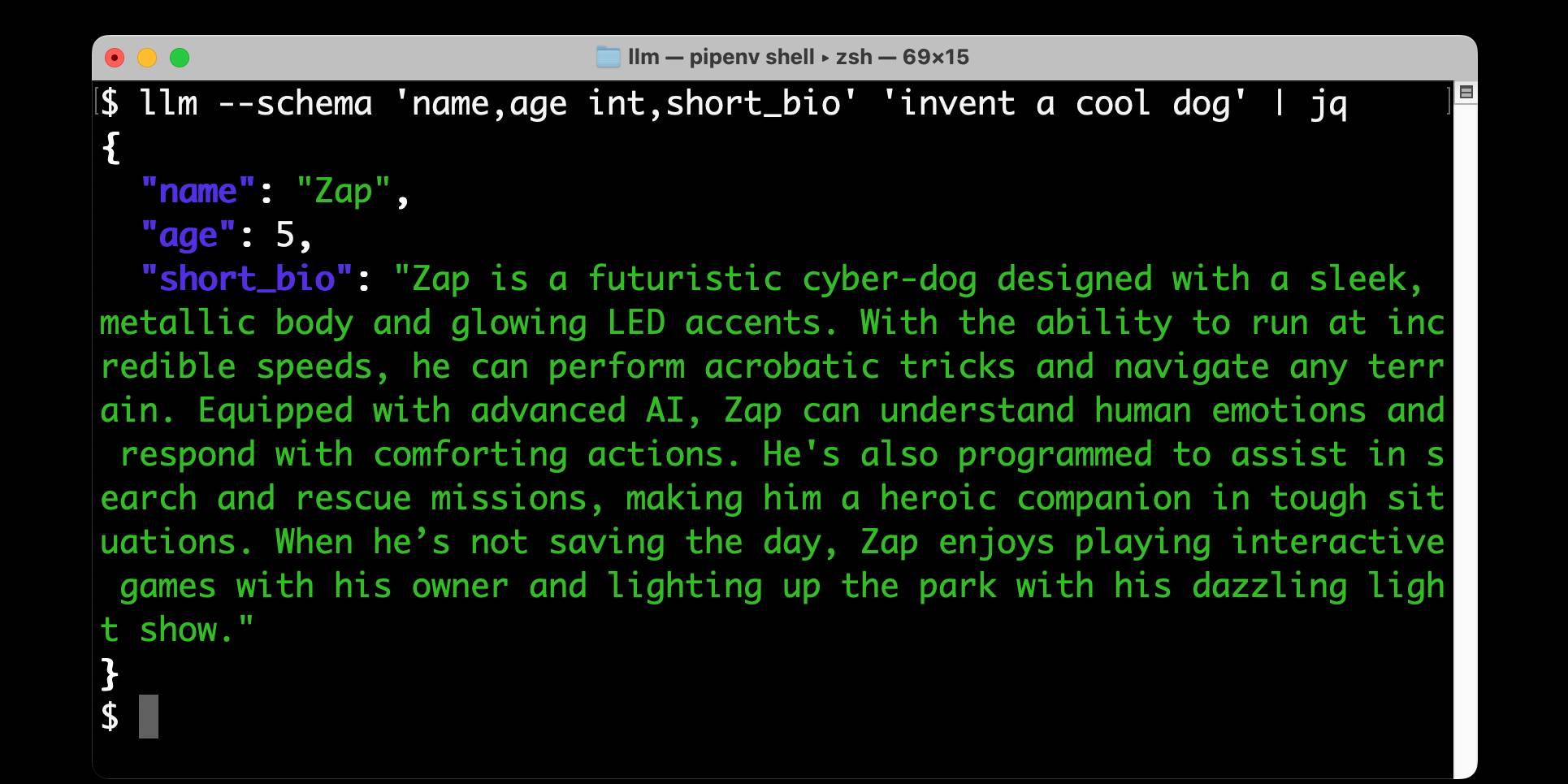
LLM 0.23 is out today, and the signature feature is support for schemas—a new way of providing structured output from a model that matches a specification provided by the user. I’ve also upgraded both the llm-anthropic and llm-gemini plugins to add support for schemas.
[... 2,601 words]Initial impressions of GPT-4.5
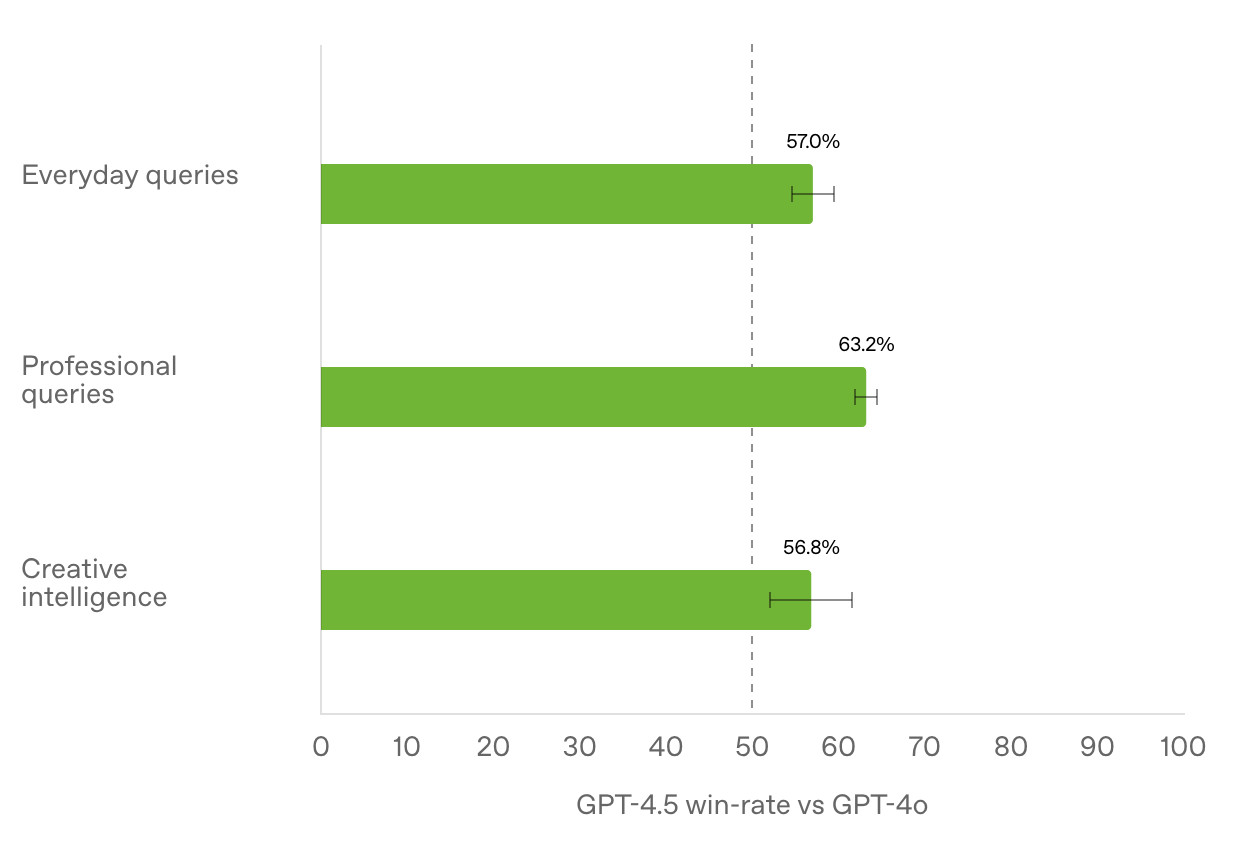
GPT-4.5 is out today as a “research preview”—it’s available to OpenAI Pro ($200/month) customers and to developers with an API key. OpenAI also published a GPT-4.5 system card.
[... 745 words]Claude 3.7 Sonnet, extended thinking and long output, llm-anthropic 0.14

Claude 3.7 Sonnet (previously) is a very interesting new model. I released llm-anthropic 0.14 last night adding support for the new model’s features to LLM. I learned a whole lot about the new model in the process of building that plugin.
[... 1,491 words]LLM 0.22, the annotated release notes
I released LLM 0.22 this evening. Here are the annotated release notes:
[... 1,340 words]Run LLMs on macOS using llm-mlx and Apple’s MLX framework
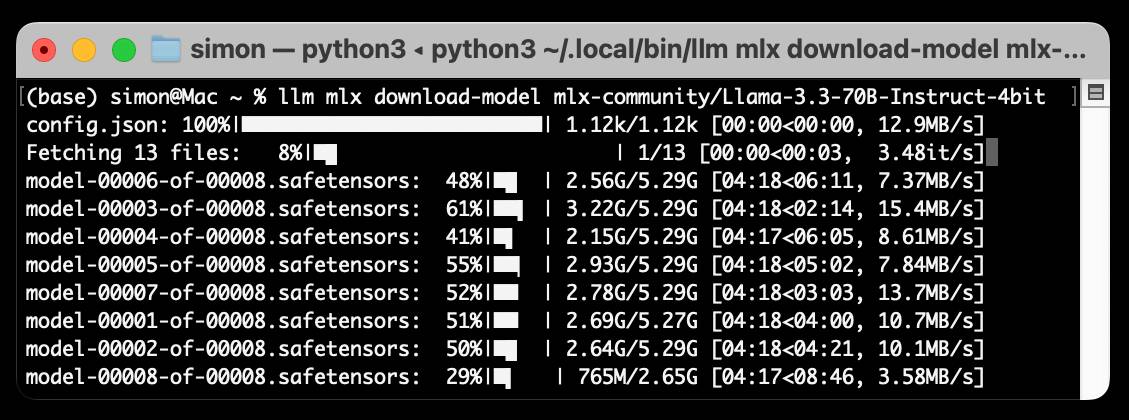
llm-mlx is a brand new plugin for my LLM Python Library and CLI utility which builds on top of Apple’s excellent MLX array framework library and mlx-lm package. If you’re a terminal user or Python developer with a Mac this may be the new easiest way to start exploring local Large Language Models.
[... 1,524 words]URL-addressable Pyodide Python environments
This evening I spotted an obscure bug in Datasette, using Datasette Lite. I figure it’s a good opportunity to highlight how useful it is to have a URL-addressable Python environment, powered by Pyodide and WebAssembly.
[... 1,905 words]Using pip to install a Large Language Model that’s under 100MB
I just released llm-smollm2, a new plugin for LLM that bundles a quantized copy of the SmolLM2-135M-Instruct LLM inside of the Python package.
[... 1,553 words]OpenAI o3-mini, now available in LLM
OpenAI’s o3-mini is out today. As with other o-series models it’s a slightly difficult one to evaluate—we now need to decide if a prompt is best run using GPT-4o, o1, o3-mini or (if we have access) o1 Pro.
[... 748 words]A selfish personal argument for releasing code as Open Source

I’m the guest for the most recent episode of the Real Python podcast with Christopher Bailey, talking about Using LLMs for Python Development. We covered a lot of other topics as well—most notably my relationship with Open Source development over the years.
[... 464 words]Anthropic’s new Citations API
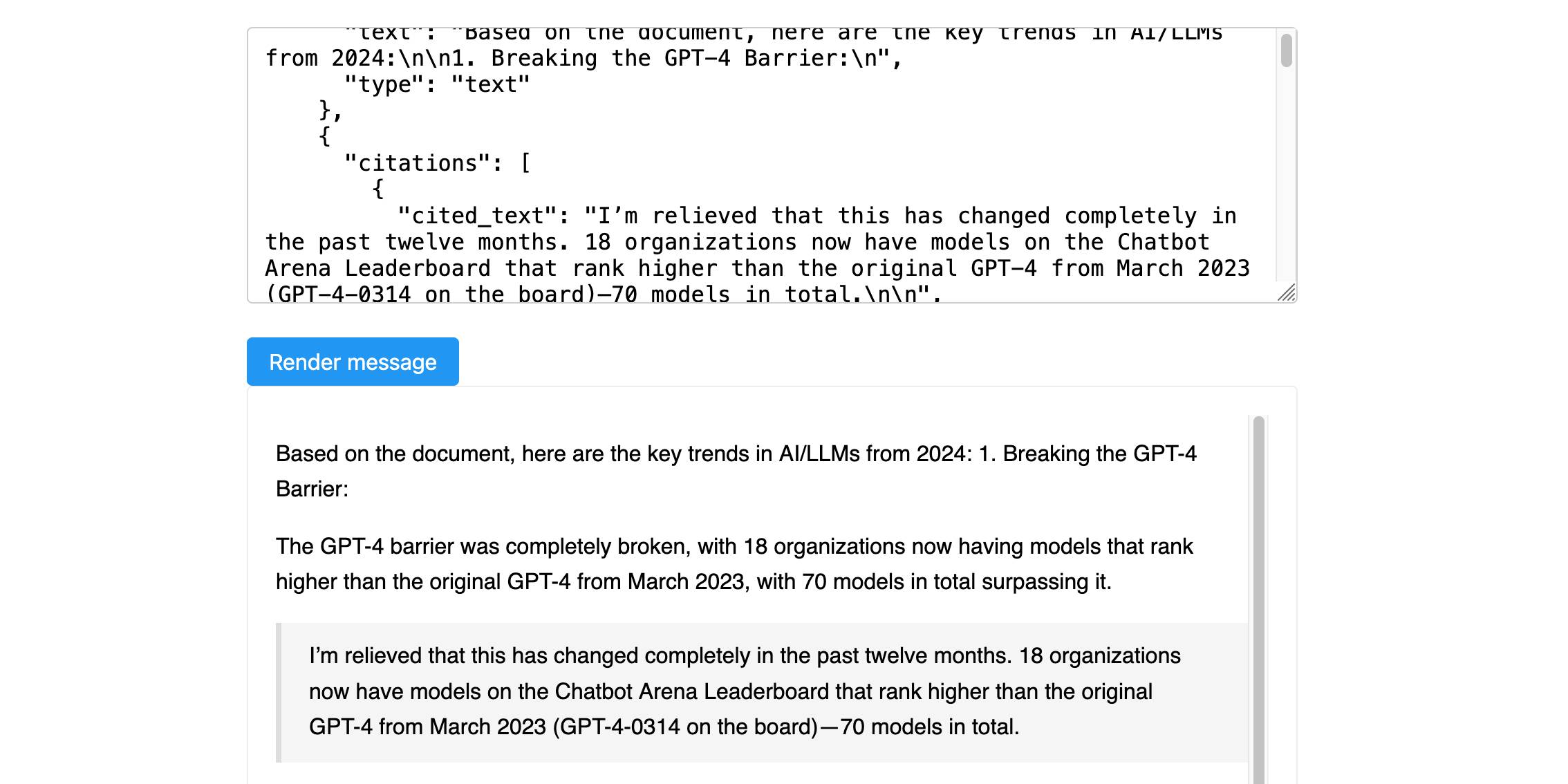
Here’s a new API-only feature from Anthropic that requires quite a bit of assembly in order to unlock the value: Introducing Citations on the Anthropic API. Let’s talk about what this is and why it’s interesting.
[... 1,319 words]Six short video demos of LLM and Datasette projects
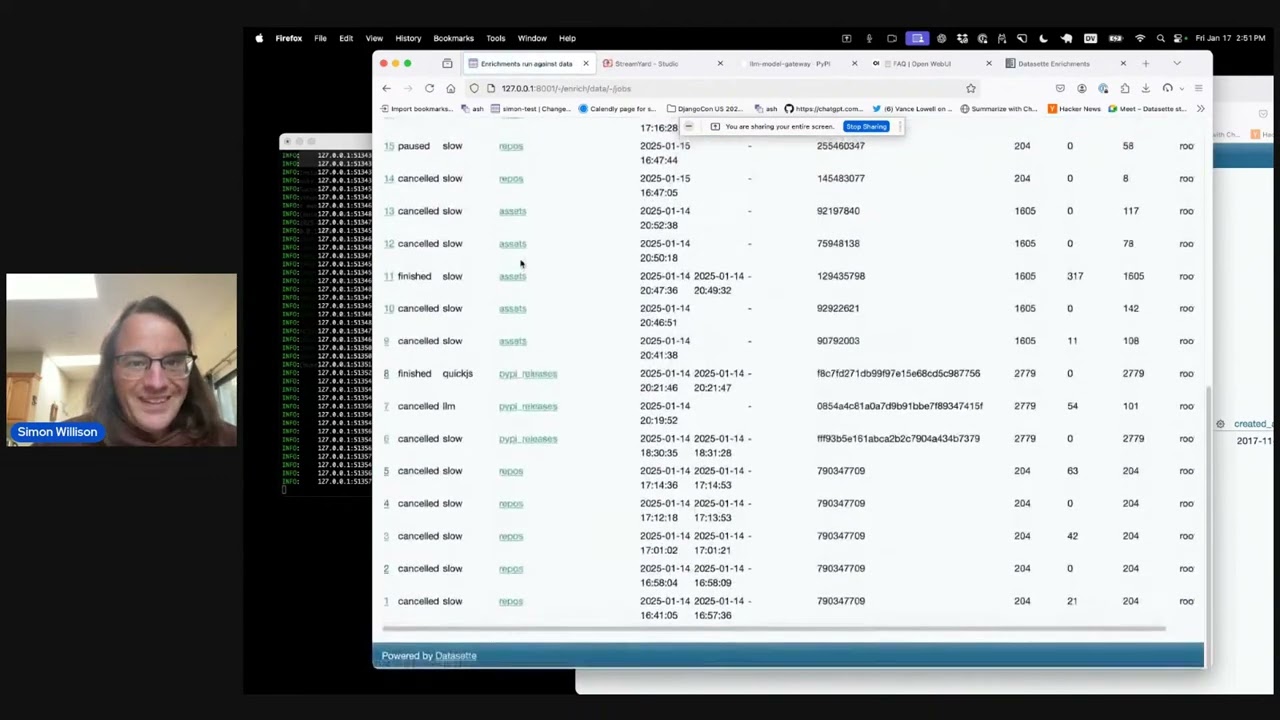
Last Friday Alex Garcia and I hosted a new kind of Datasette Public Office Hours session, inviting members of the Datasette community to share short demos of projects that they had built. The session lasted just over an hour and featured demos from six different people.
[... 1,047 words]DeepSeek-R1 and exploring DeepSeek-R1-Distill-Llama-8B

DeepSeek are the Chinese AI lab who dropped the best currently available open weights LLM on Christmas day, DeepSeek v3. That model was trained in part using their unreleased R1 “reasoning” model. Today they’ve released R1 itself, along with a whole family of new models derived from that base.
[... 1,276 words]