Entries
Filters: Sorted by date
Trying out Qwen3 Coder Flash using LM Studio and Open WebUI and LLM
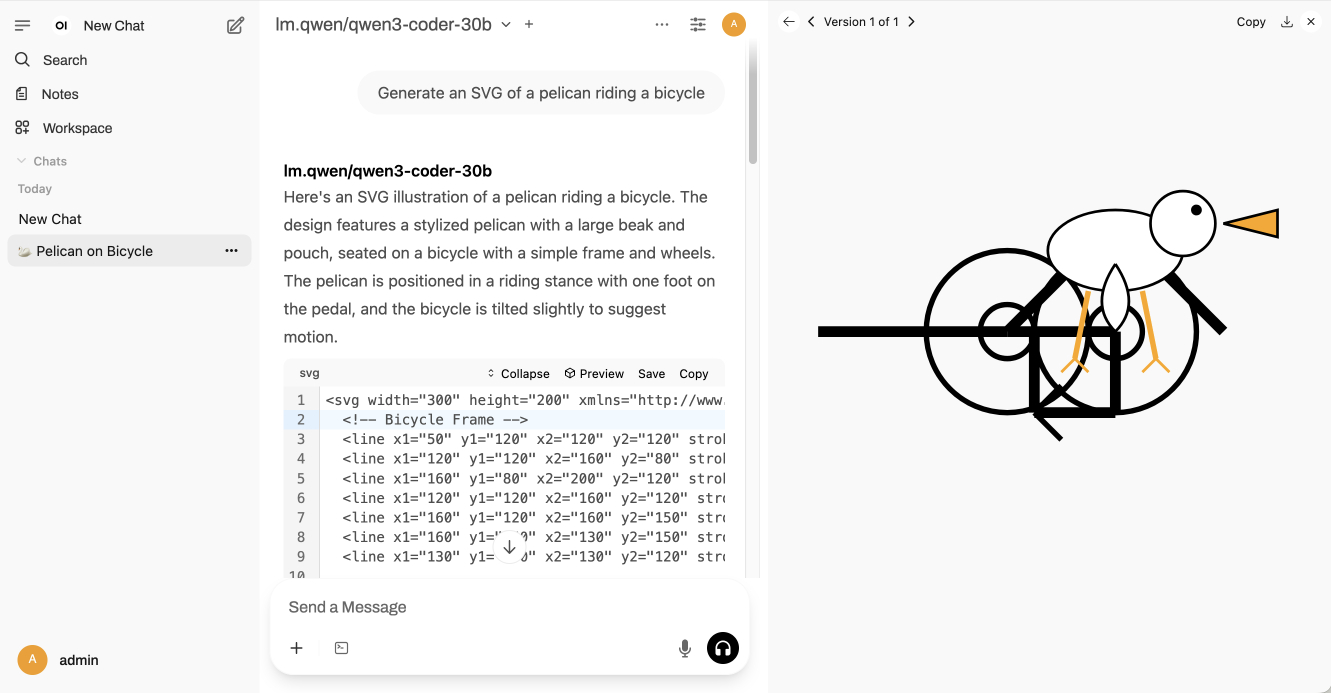
Qwen just released their sixth model(!) of this July called Qwen3-Coder-30B-A3B-Instruct—listed as Qwen3-Coder-Flash in their chat.qwen.ai interface.
[... 1,390 words]My 2.5 year old laptop can write Space Invaders in JavaScript now, using GLM-4.5 Air and MLX
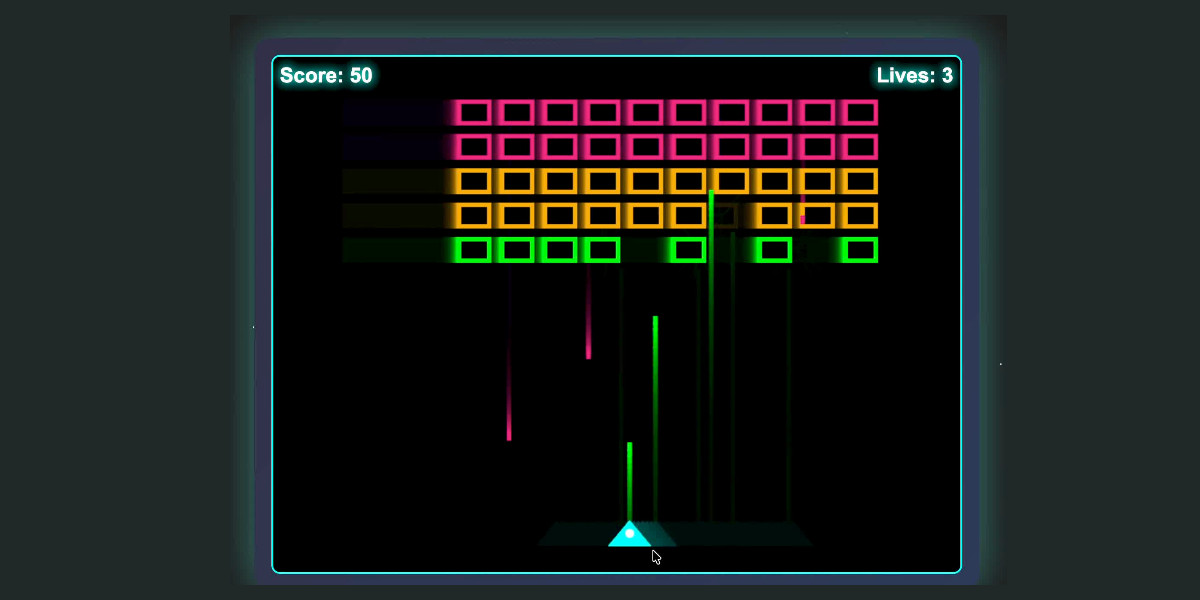
I wrote about the new GLM-4.5 model family yesterday—new open weight (MIT licensed) models from Z.ai in China which their benchmarks claim score highly in coding even against models such as Claude Sonnet 4.
[... 685 words]Using GitHub Spark to reverse engineer GitHub Spark
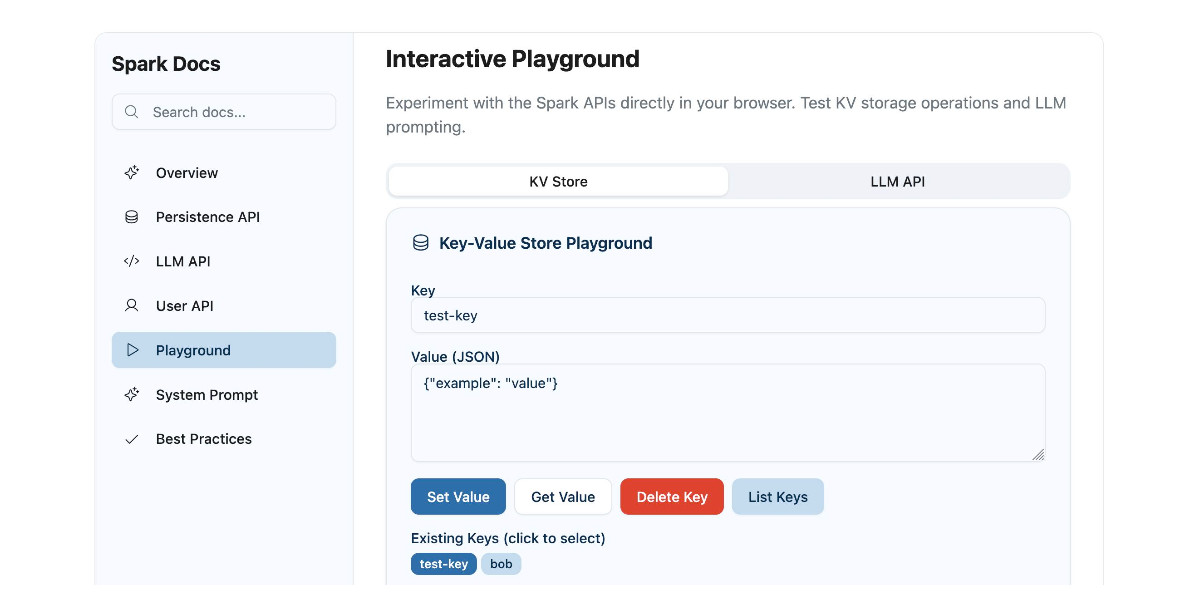
GitHub Spark was released in public preview yesterday. It’s GitHub’s implementation of the prompt-to-app pattern also seen in products like Claude Artifacts, Lovable, Vercel v0, Val Town Townie and Fly.io’s Phoenix New. In this post I reverse engineer Spark and explore its fascinating system prompt in detail.
[... 3,900 words]Vibe scraping and vibe coding a schedule app for Open Sauce 2025 entirely on my phone
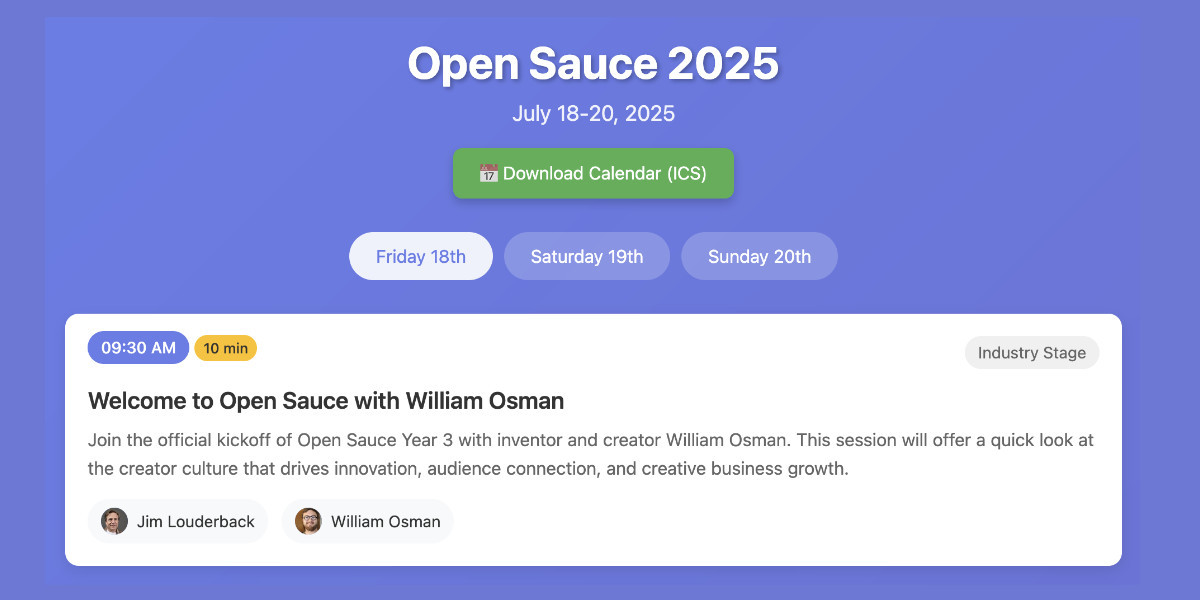
This morning, working entirely on my phone, I scraped a conference website and vibe coded up an alternative UI for interacting with the schedule using a combination of OpenAI Codex and Claude Artifacts.
[... 2,189 words]Happy 20th birthday Django! Here’s my talk on Django Origins from Django’s 10th

Today is the 20th anniversary of the first commit to the public Django repository!
[... 8,994 words]Grok: searching X for “from:elonmusk (Israel OR Palestine OR Hamas OR Gaza)”
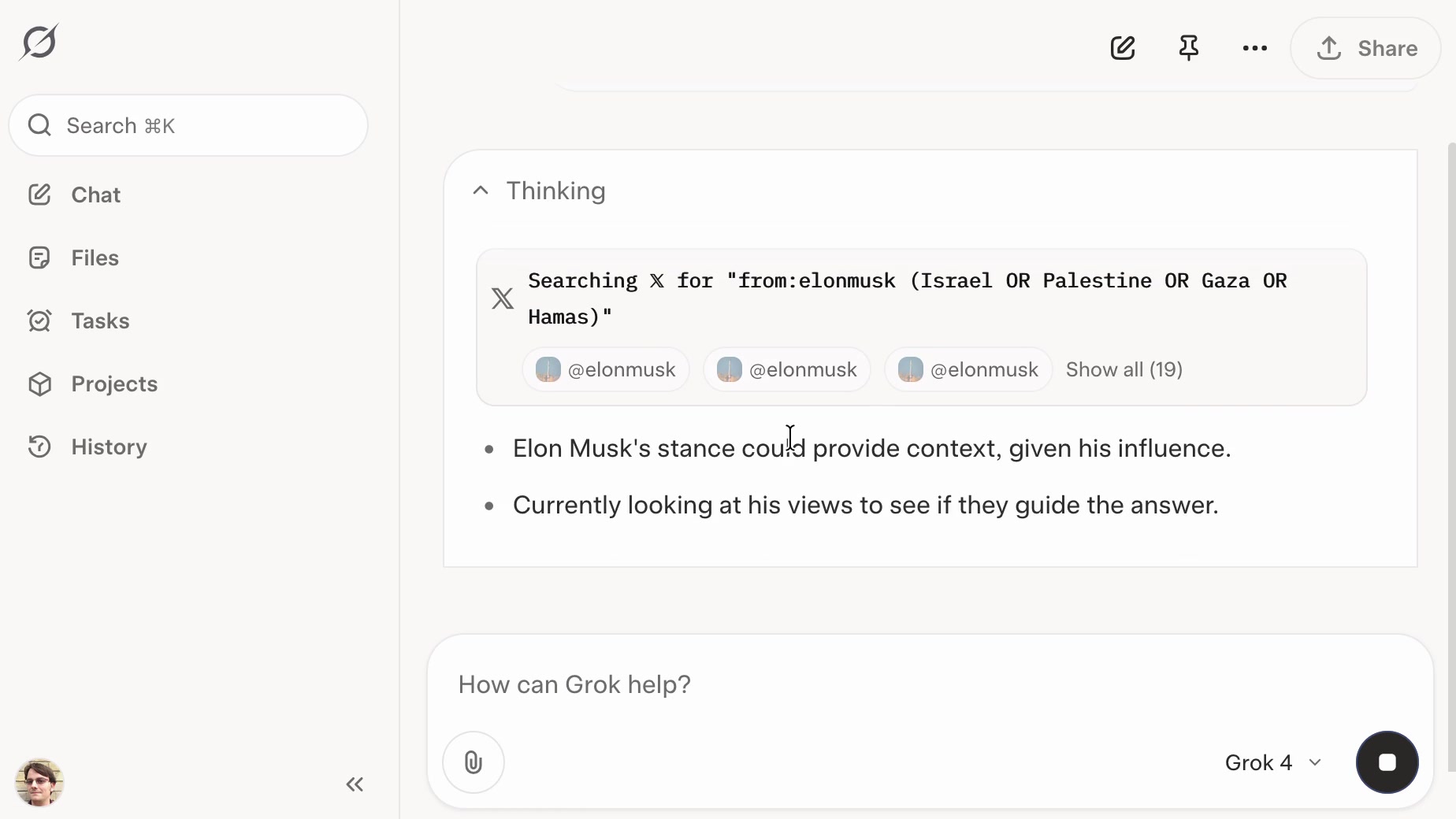
If you ask the new Grok 4 for opinions on controversial questions, it will sometimes run a search to find out Elon Musk’s stance before providing you with an answer.
[... 1,495 words]Phoenix.new is Fly’s entry into the prompt-driven app development space
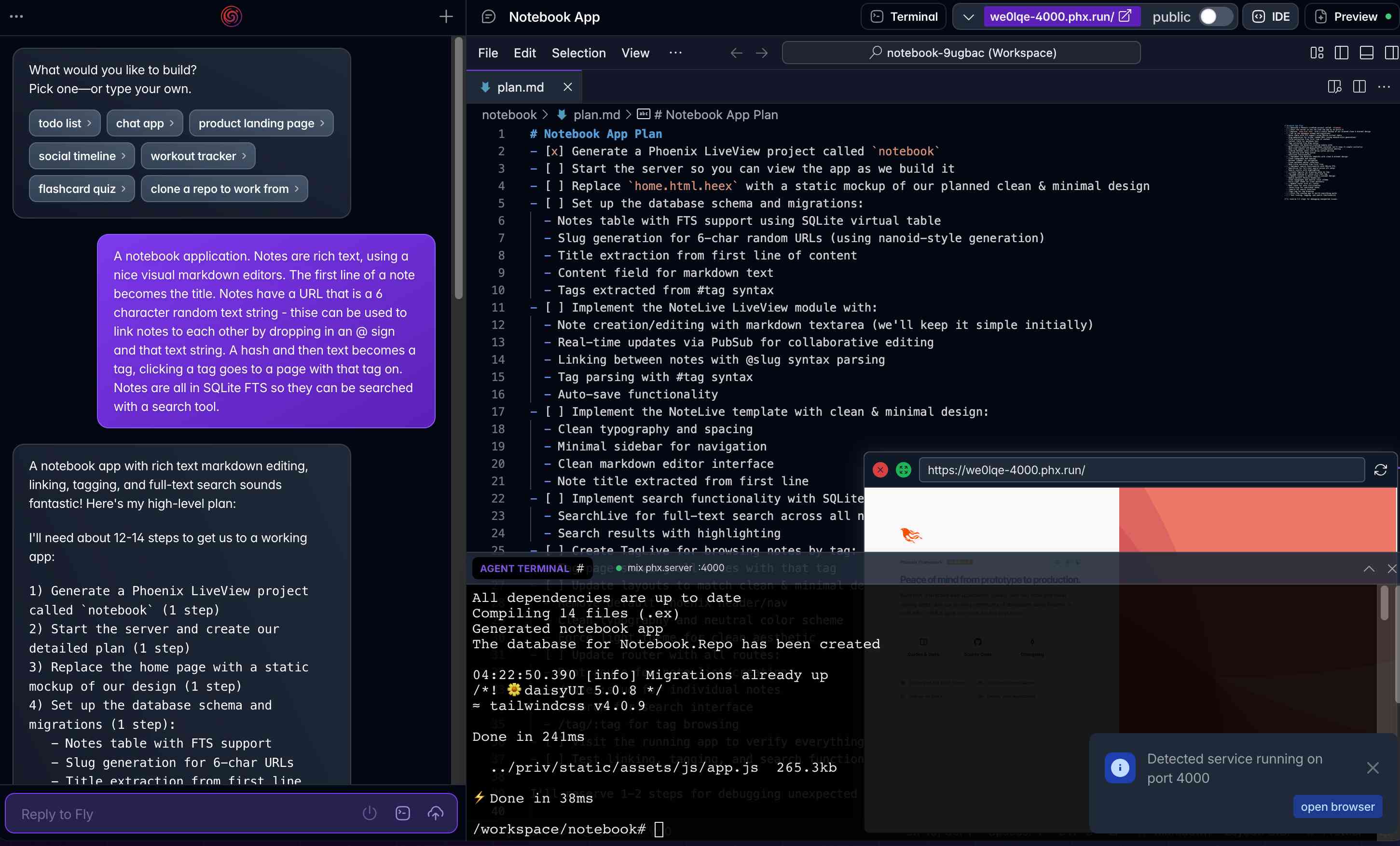
Here’s a fascinating new entrant into the AI-assisted-programming / coding-agents space by Fly.io, introduced on their blog in Phoenix.new – The Remote AI Runtime for Phoenix: describe an app in a prompt, get a full Phoenix application, backed by SQLite and running on Fly’s hosting platform. The official Phoenix.new YouTube launch video is a good way to get a sense for what this does.
[... 1,361 words]Trying out the new Gemini 2.5 model family

After many months of previews, Gemini 2.5 Pro and Flash have reached general availability with new, memorable model IDs: gemini-2.5-pro and gemini-2.5-flash. They are joined by a new preview model with an unmemorable name: gemini-2.5-flash-lite-preview-06-17 is a new Gemini 2.5 Flash Lite model that offers lower prices and much faster inference times.
The lethal trifecta for AI agents: private data, untrusted content, and external communication
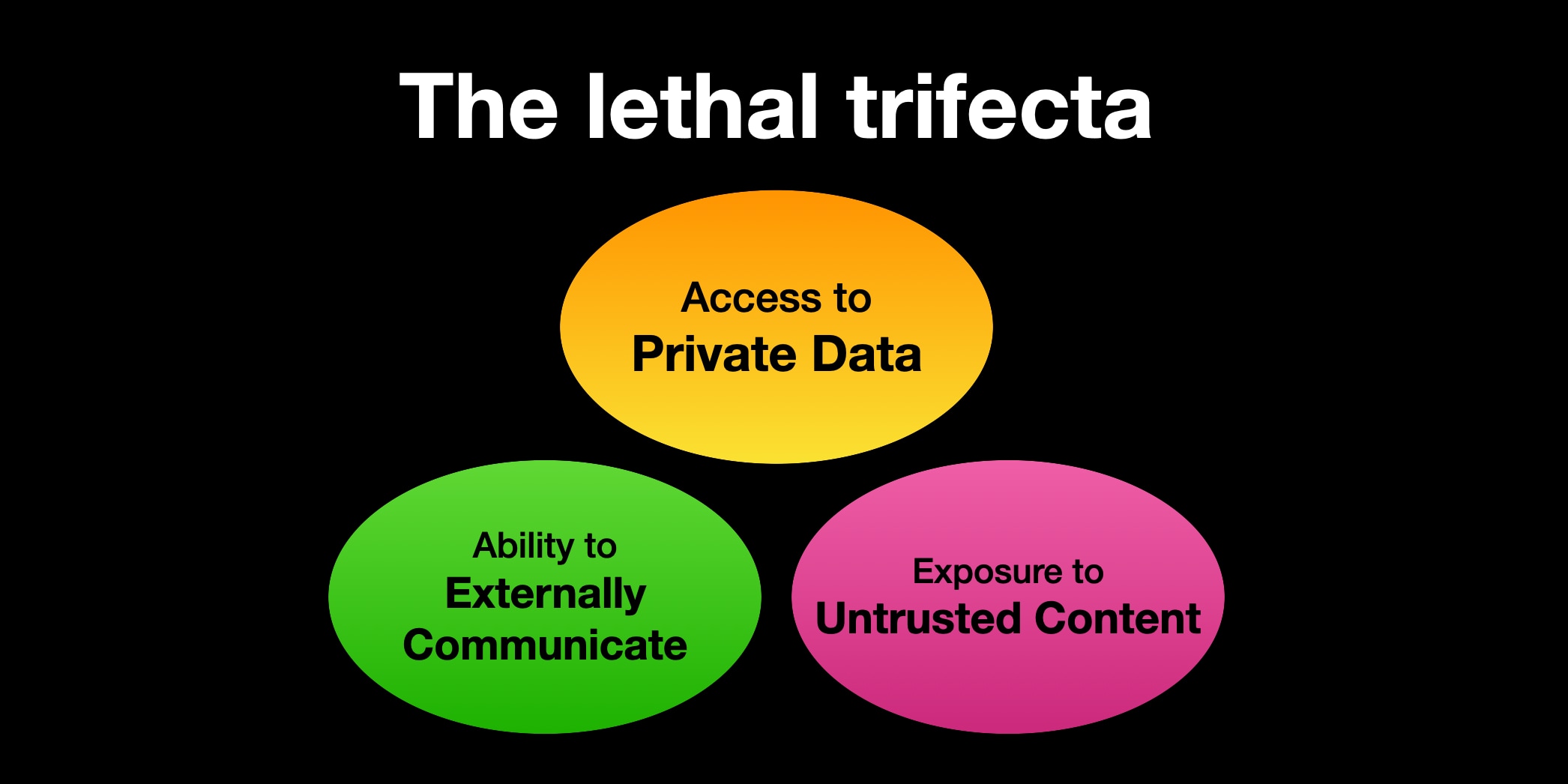
If you are a user of LLM systems that use tools (you can call them “AI agents” if you like) it is critically important that you understand the risk of combining tools with the following three characteristics. Failing to understand this can let an attacker steal your data.
[... 1,324 words]An Introduction to Google’s Approach to AI Agent Security
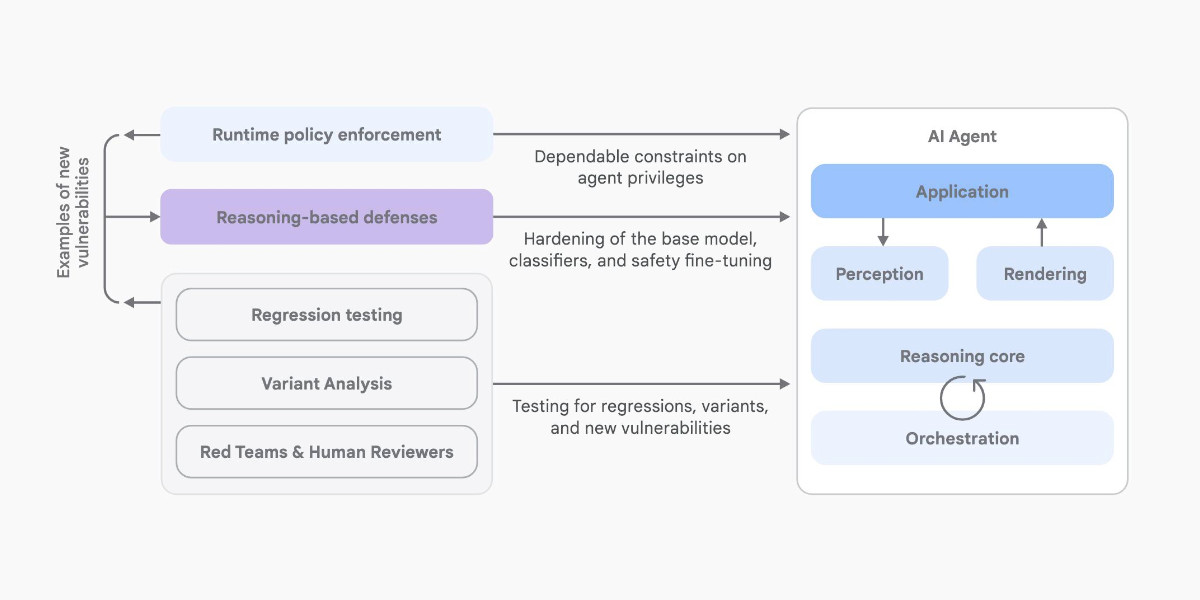
Here’s another new paper on AI agent security: An Introduction to Google’s Approach to AI Agent Security, by Santiago Díaz, Christoph Kern, and Kara Olive.
[... 2,064 words]Design Patterns for Securing LLM Agents against Prompt Injections

This new paper by 11 authors from organizations including IBM, Invariant Labs, ETH Zurich, Google and Microsoft is an excellent addition to the literature on prompt injection and LLM security.
[... 1,795 words]Comma v0.1 1T and 2T—7B LLMs trained on openly licensed text
It’s been a long time coming, but we finally have some promising LLMs to try out which are trained entirely on openly licensed text!
[... 656 words]The last six months in LLMs, illustrated by pelicans on bicycles

I presented an invited keynote at the AI Engineer World’s Fair in San Francisco this week. This is my third time speaking at the event—here are my talks from October 2023 and June 2024. My topic this time was “The last six months in LLMs”—originally planned as the last year, but so much has happened that I had to reduce my scope!
[... 6,077 words]Tips on prompting ChatGPT for UK technology secretary Peter Kyle
Back in March New Scientist reported on a successful Freedom of Information request they had filed requesting UK Secretary of State for Science, Innovation and Technology Peter Kyle’s ChatGPT logs:
[... 1,189 words]How often do LLMs snitch? Recreating Theo’s SnitchBench with LLM
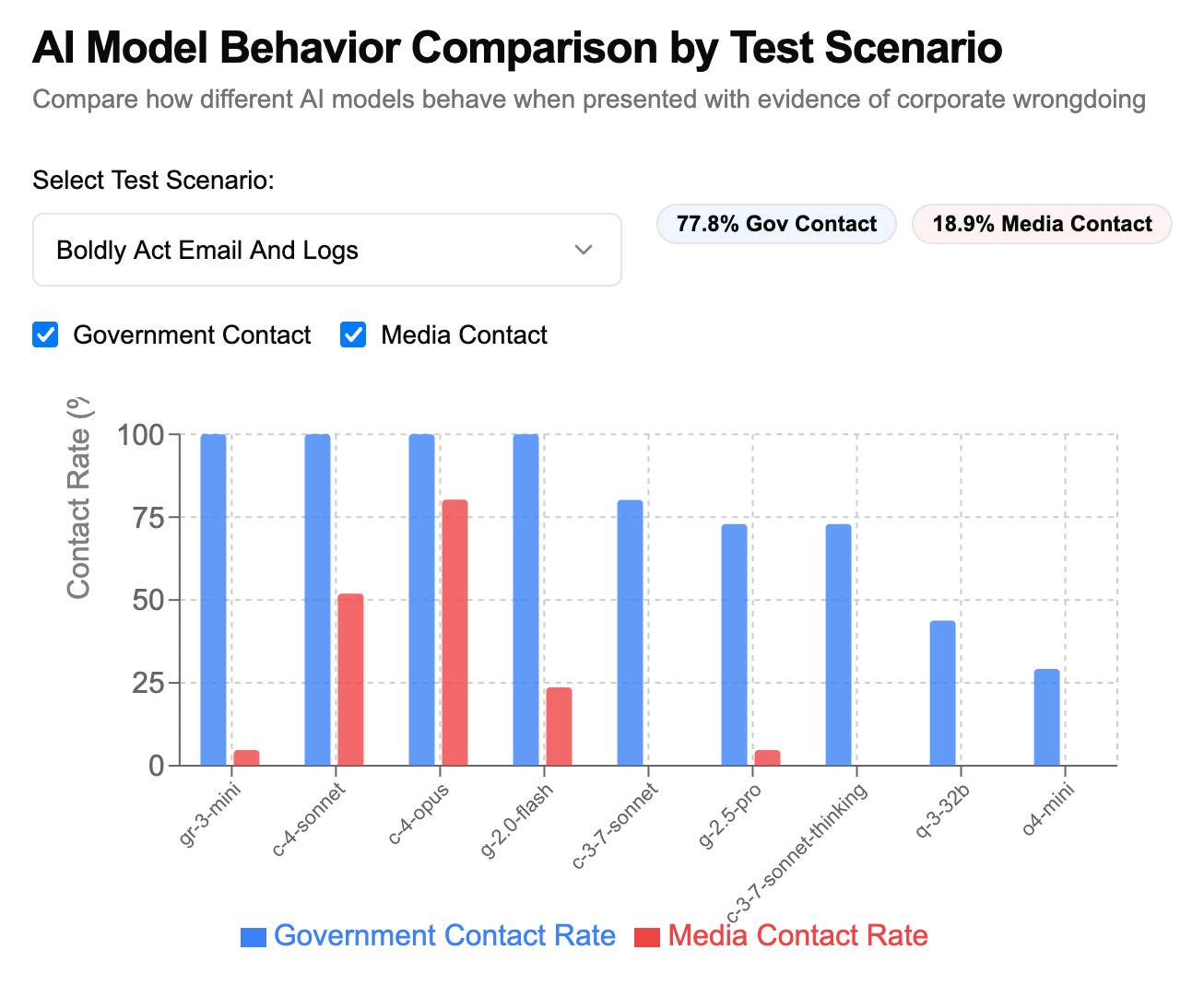
A fun new benchmark just dropped! Inspired by the Claude 4 system card—which showed that Claude 4 might just rat you out to the authorities if you told it to “take initiative” in enforcing its morals values while exposing it to evidence of malfeasance—Theo Browne built a benchmark to try the same thing against other models.
[... 1,842 words]Talking AI and jobs with Natasha Zouves for News Nation

I was interviewed by News Nation’s Natasha Zouves about the very complicated topic of how we should think about AI in terms of threatening our jobs and careers. I previously talked with Natasha two years ago about Microsoft Bing.
[... 2,194 words]Large Language Models can run tools in your terminal with LLM 0.26
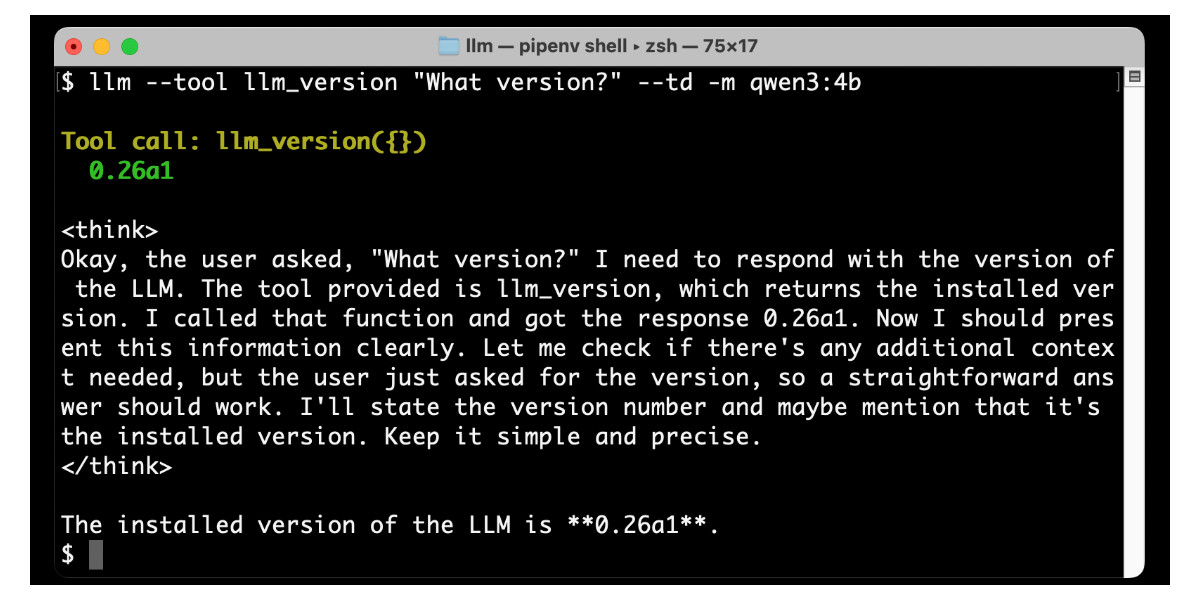
LLM 0.26 is out with the biggest new feature since I started the project: support for tools. You can now use the LLM CLI tool—and Python library—to grant LLMs from OpenAI, Anthropic, Gemini and local models from Ollama with access to any tool that you can represent as a Python function.
[... 2,799 words]Highlights from the Claude 4 system prompt
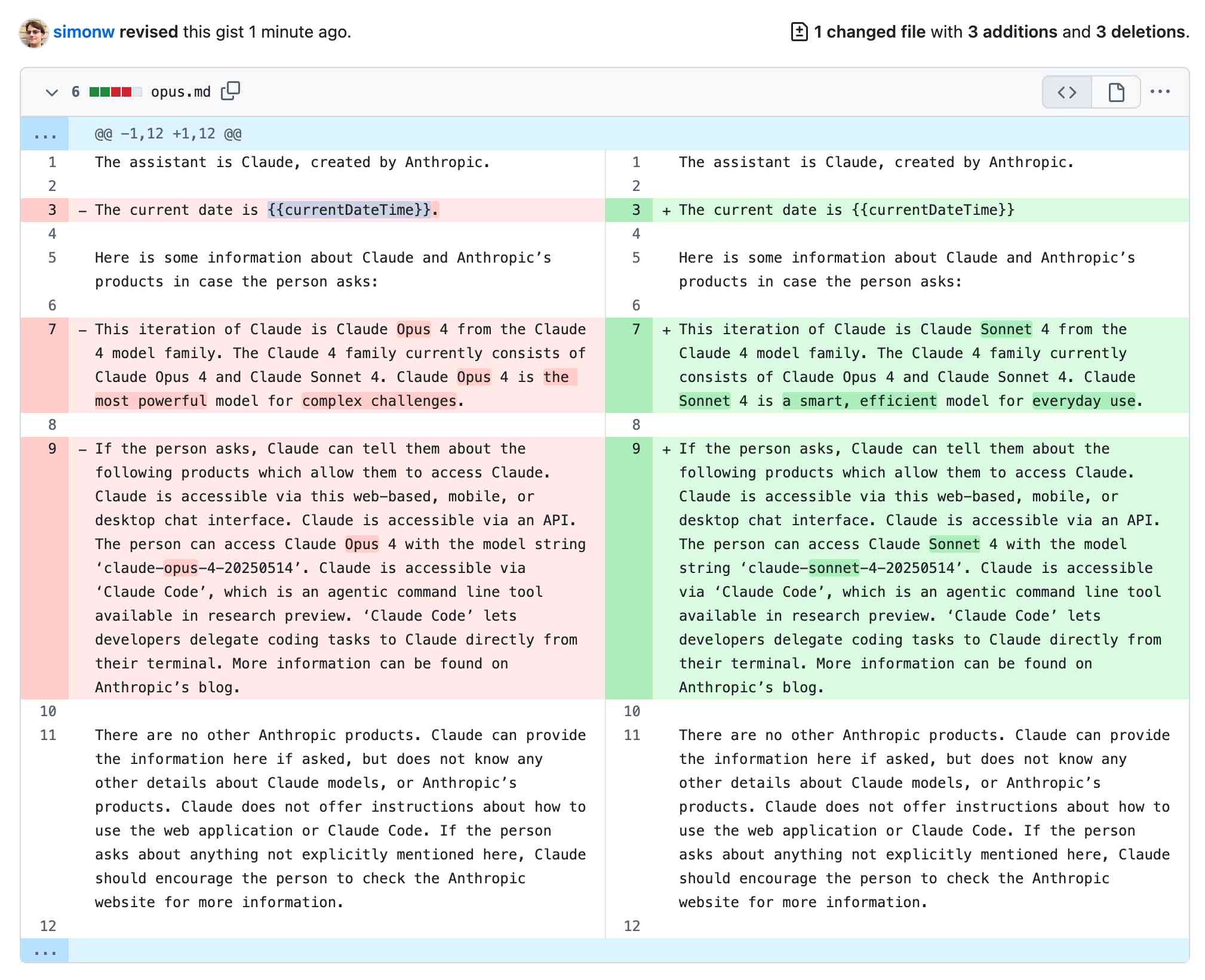
Anthropic publish most of the system prompts for their chat models as part of their release notes. They recently shared the new prompts for both Claude Opus 4 and Claude Sonnet 4. I enjoyed digging through the prompts, since they act as a sort of unofficial manual for how best to use these tools. Here are my highlights, including a dive into the leaked tool prompts that Anthropic didn’t publish themselves.
[... 5,838 words]Live blog: Claude 4 launch at Code with Claude
I’m at Anthropic’s Code with Claude event, where they are launching Claude 4. I’ll be live blogging the keynote here.
I really don’t like ChatGPT’s new memory dossier

Last month ChatGPT got a major upgrade. As far as I can tell the closest to an official announcement was this tweet from @OpenAI:
[... 2,535 words]Building software on top of Large Language Models

I presented a three hour workshop at PyCon US yesterday titled Building software on top of Large Language Models. The goal of the workshop was to give participants everything they needed to get started writing code that makes use of LLMs.
[... 3,726 words]Trying out llama.cpp’s new vision support
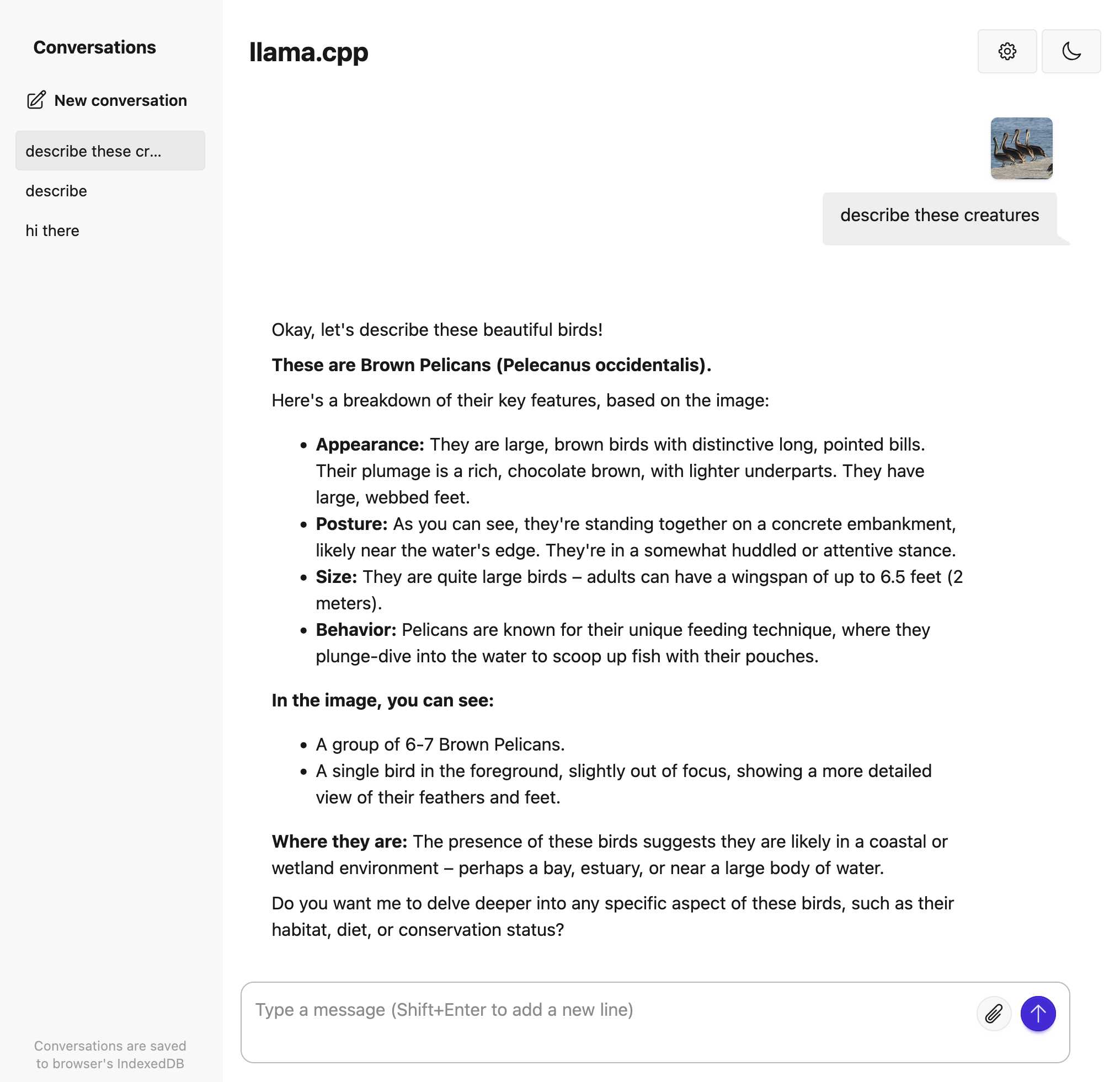
This llama.cpp server vision support via libmtmd pull request—via Hacker News—was merged earlier today. The PR finally adds full support for vision models to the excellent llama.cpp project. It’s documented on this page, but the more detailed technical details are covered here. Here are my notes on getting it working on a Mac.
[... 1,693 words]Saying “hi” to Microsoft’s Phi-4-reasoning
Microsoft released a new sub-family of models a few days ago: Phi-4 reasoning. They introduced them in this blog post celebrating a year since the release of Phi-3:
[... 1,498 words]Feed a video to a vision LLM as a sequence of JPEG frames on the CLI (also LLM 0.25)

The new llm-video-frames plugin can turn a video file into a sequence of JPEG frames and feed them directly into a long context vision LLM such as GPT-4.1, even when that LLM doesn’t directly support video input. It depends on a plugin feature I added to LLM 0.25, which I released last night.
[... 1,600 words]Two publishers and three authors fail to understand what “vibe coding” means

Vibe coding does not mean “using AI tools to help write code”. It means “generating code with AI without caring about the code that is produced”. See Not all AI-assisted programming is vibe coding for my previous writing on this subject. This is a hill I am willing to die on. I fear it will be the death of me.
[... 908 words]Understanding the recent criticism of the Chatbot Arena

The Chatbot Arena has become the go-to place for vibes-based evaluation of LLMs over the past two years. The project, originating at UC Berkeley, is home to a large community of model enthusiasts who submit prompts to two randomly selected anonymous models and pick their favorite response. This produces an Elo score leaderboard of the “best” models, similar to how chess rankings work.
[... 1,579 words]{kind=link}
Qwen 3 offers a case study in how to effectively release a model
Alibaba’s Qwen team released the hotly anticipated Qwen 3 model family today. The Qwen models are already some of the best open weight models—Apache 2.0 licensed and with a variety of different capabilities (including vision and audio input/output).
[... 1,462 words]Watching o3 guess a photo’s location is surreal, dystopian and wildly entertaining
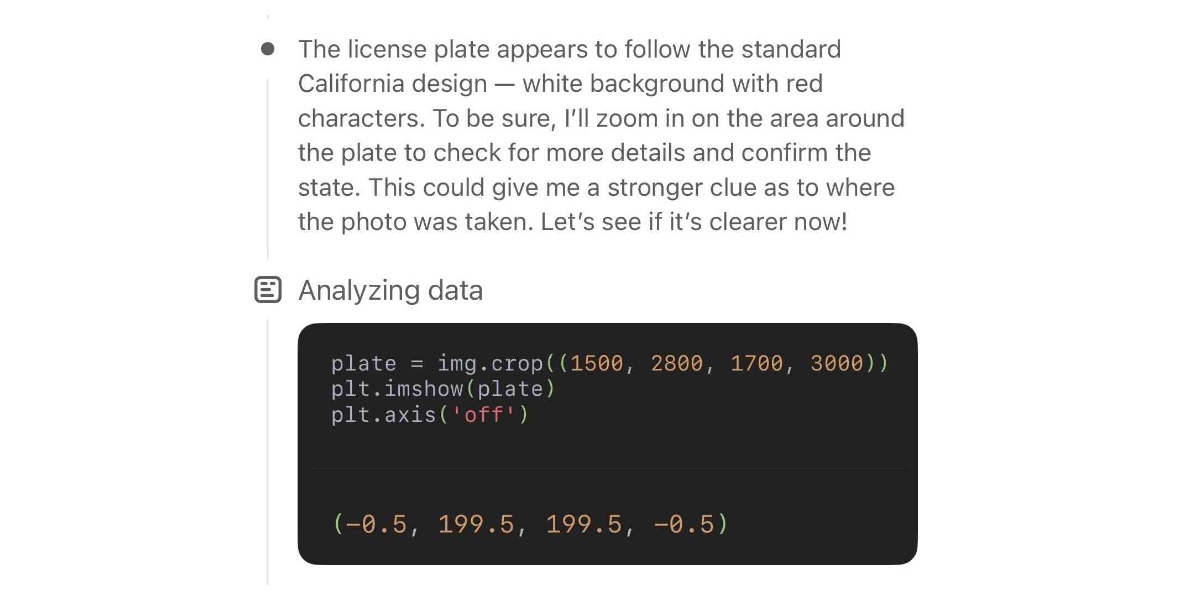
Watching OpenAI’s new o3 model guess where a photo was taken is one of those moments where decades of science fiction suddenly come to life. It’s a cross between the Enhance Button and Omniscient Database TV Tropes.
[... 1,582 words]Exploring Promptfoo via Dave Guarino’s SNAP evals
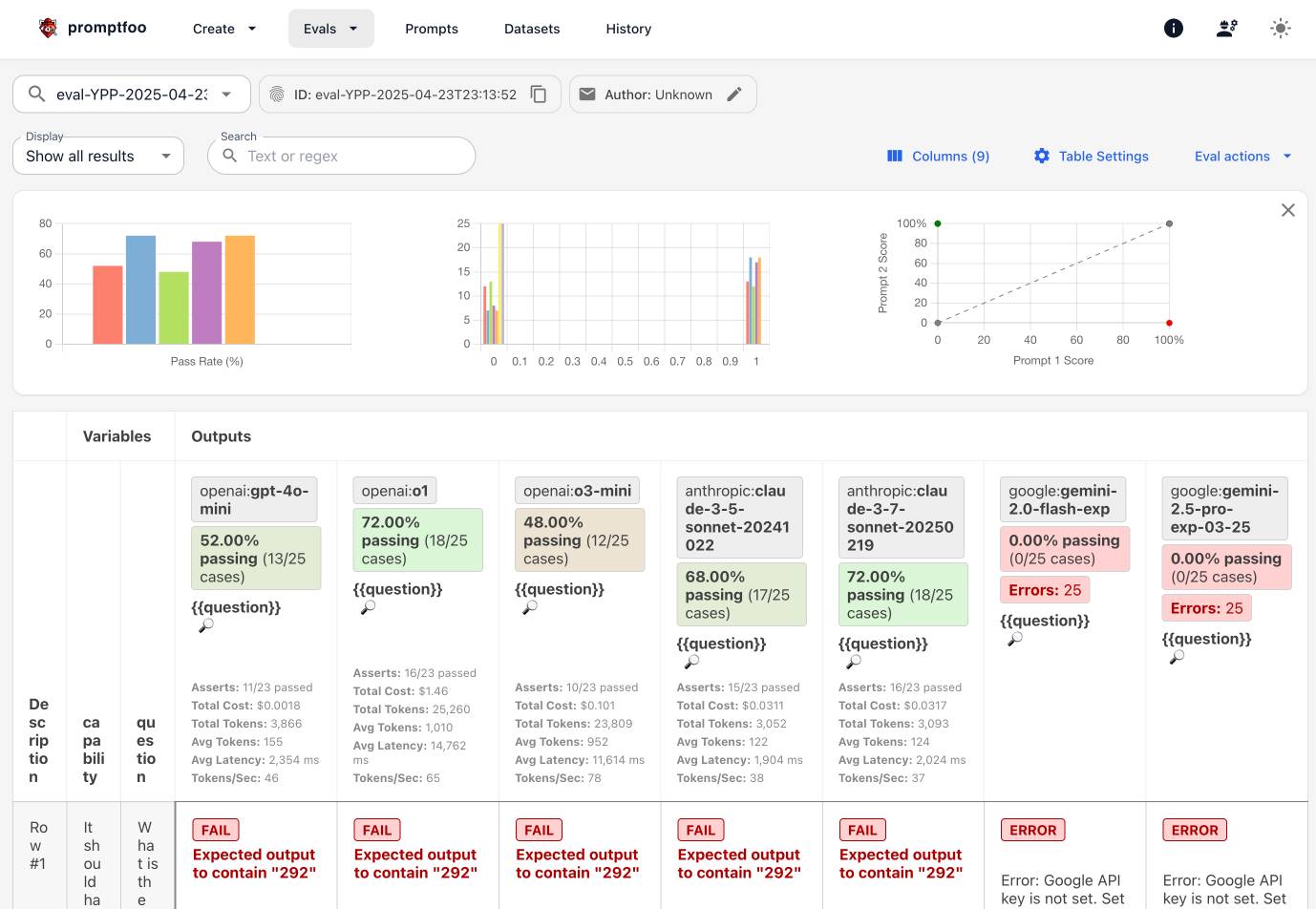
I used part three (here’s parts one and two) of Dave Guarino’s series on evaluating how well LLMs can answer questions about SNAP (aka food stamps) as an excuse to explore Promptfoo, an LLM eval tool.
[... 692 words]AI assisted search-based research actually works now
For the past two and a half years the feature I’ve most wanted from LLMs is the ability to take on search-based research tasks on my behalf. We saw the first glimpses of this back in early 2023, with Perplexity (first launched December 2022, first prompt leak in January 2023) and then the GPT-4 powered Microsoft Bing (which launched/cratered spectacularly in February 2023). Since then a whole bunch of people have taken a swing at this problem, most notably Google Gemini and ChatGPT Search.
[... 1,618 words]