Entries
Filters: Sorted by date
Hacking the WiFi-enabled color screen GitHub Universe conference badge
I’m at GitHub Universe this week (thanks to a free ticket from Microsoft). Yesterday I picked up my conference badge... which incorporates a full Raspberry Pi Raspberry Pi Pico microcontroller with a battery, color screen, WiFi and bluetooth.
Video: Building a tool to copy-paste share terminal sessions using Claude Code for web
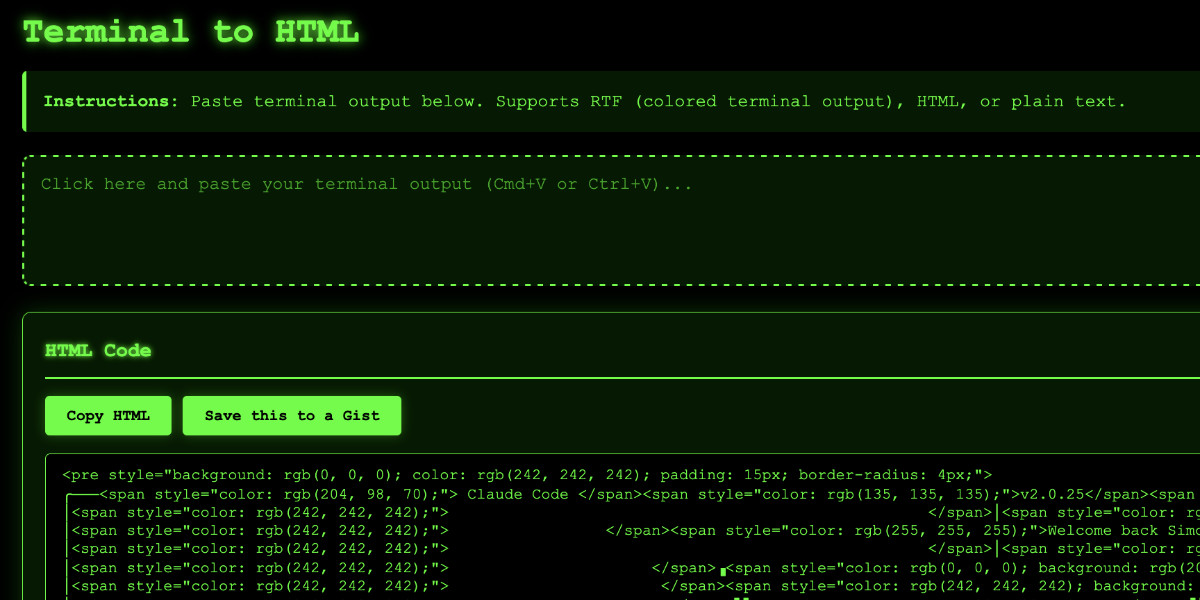
This afternoon I was manually converting a terminal session into a shared HTML file for the umpteenth time when I decided to reduce the friction by building a custom tool for it—and on the spur of the moment I fired up Descript to record the process. The result is this new 11 minute YouTube video showing my workflow for vibe-coding simple tools from start to finish.
[... 1,338 words]Dane Stuckey (OpenAI CISO) on prompt injection risks for ChatGPT Atlas
My biggest complaint about the launch of the ChatGPT Atlas browser the other day was the lack of details on how OpenAI are addressing prompt injection attacks. The launch post mostly punted that question to the System Card for their “ChatGPT agent” browser automation feature from July. Since this was my single biggest question about Atlas I was disappointed not to see it addressed more directly.
[... 1,199 words]Living dangerously with Claude

I gave a talk last night at Claude Code Anonymous in San Francisco, the unofficial meetup for coding agent enthusiasts. I decided to talk about a dichotomy I’ve been struggling with recently. On the one hand I’m getting enormous value from running coding agents with as few restrictions as possible. On the other hand I’m deeply concerned by the risks that accompany that freedom.
[... 2,208 words]Claude Code for web—a new asynchronous coding agent from Anthropic
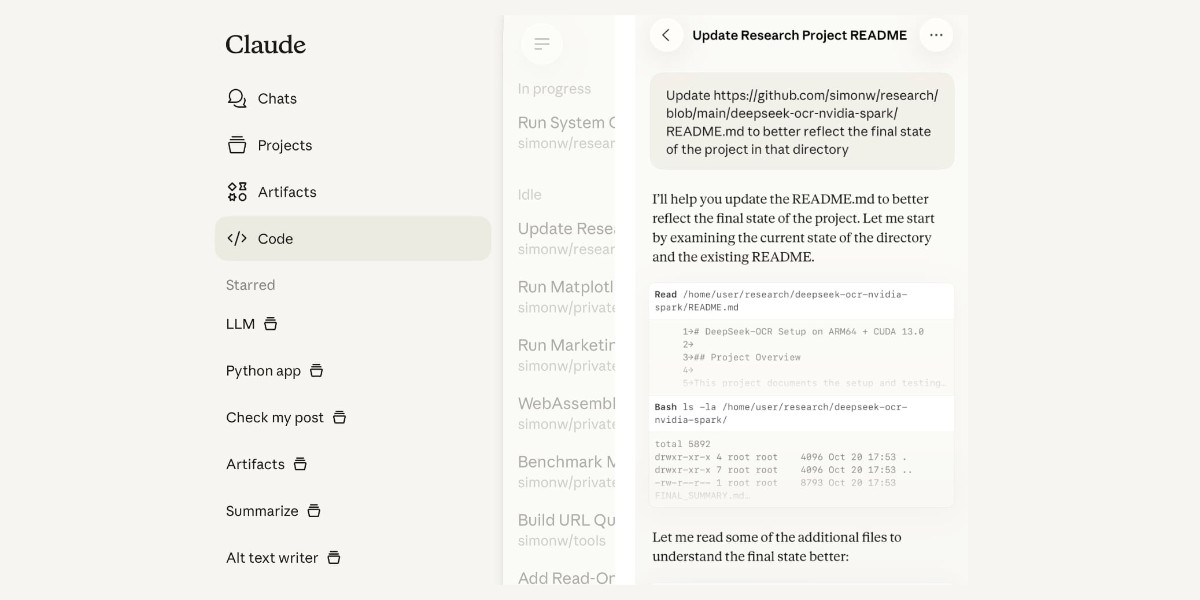
Anthropic launched Claude Code for web this morning. It’s an asynchronous coding agent—their answer to OpenAI’s Codex Cloud and Google’s Jules, and has a very similar shape. I had preview access over the weekend and I’ve already seen some very promising results from it.
[... 1,434 words]Getting DeepSeek-OCR working on an NVIDIA Spark via brute force using Claude Code

DeepSeek released a new model yesterday: DeepSeek-OCR, a 6.6GB model fine-tuned specifically for OCR. They released it as model weights that run using PyTorch and CUDA. I got it running on the NVIDIA Spark by having Claude Code effectively brute force the challenge of getting it working on that particular hardware.
[... 1,971 words]Claude Skills are awesome, maybe a bigger deal than MCP

Anthropic this morning introduced Claude Skills, a new pattern for making new abilities available to their models:
[... 1,864 words]NVIDIA DGX Spark: great hardware, early days for the ecosystem

NVIDIA sent me a preview unit of their new DGX Spark desktop “AI supercomputer”. I’ve never had hardware to review before! You can consider this my first ever sponsored post if you like, but they did not pay me any cash and aside from an embargo date they did not request (nor would I grant) any editorial input into what I write about the device.
[... 1,846 words]Claude can write complete Datasette plugins now
This isn’t necessarily surprising, but it’s worth noting anyway. Claude Sonnet 4.5 is capable of building a full Datasette plugin now.
[... 1,296 words]Vibe engineering
I feel like vibe coding is pretty well established now as covering the fast, loose and irresponsible way of building software with AI—entirely prompt-driven, and with no attention paid to how the code actually works. This leaves us with a terminology gap: what should we call the other end of the spectrum, where seasoned professionals accelerate their work with LLMs while staying proudly and confidently accountable for the software they produce?
[... 1,347 words]OpenAI DevDay 2025 live blog
I’m at OpenAI DevDay in Fort Mason, San Francisco today. As I did last year, I’m going to be live blogging the announcements from the kenote. Unlike last year, this year there’s a livestream.
[... 57 words]Embracing the parallel coding agent lifestyle
For a while now I’ve been hearing from engineers who run multiple coding agents at once—firing up several Claude Code or Codex CLI instances at the same time, sometimes in the same repo, sometimes against multiple checkouts or git worktrees.
[... 1,275 words]Designing agentic loops
Coding agents like Anthropic’s Claude Code and OpenAI’s Codex CLI represent a genuine step change in how useful LLMs can be for producing working code. These agents can now directly exercise the code they are writing, correct errors, dig through existing implementation details, and even run experiments to find effective code solutions to problems.
[... 1,667 words]Claude Sonnet 4.5 is probably the “best coding model in the world” (at least for now)

Anthropic released Claude Sonnet 4.5 today, with a very bold set of claims:
[... 1,205 words]I think “agent” may finally have a widely enough agreed upon definition to be useful jargon now
I’ve noticed something interesting over the past few weeks: I’ve started using the term “agent” in conversations where I don’t feel the need to then define it, roll my eyes or wrap it in scare quotes.
[... 1,199 words]My review of Claude’s new Code Interpreter, released under a very confusing name
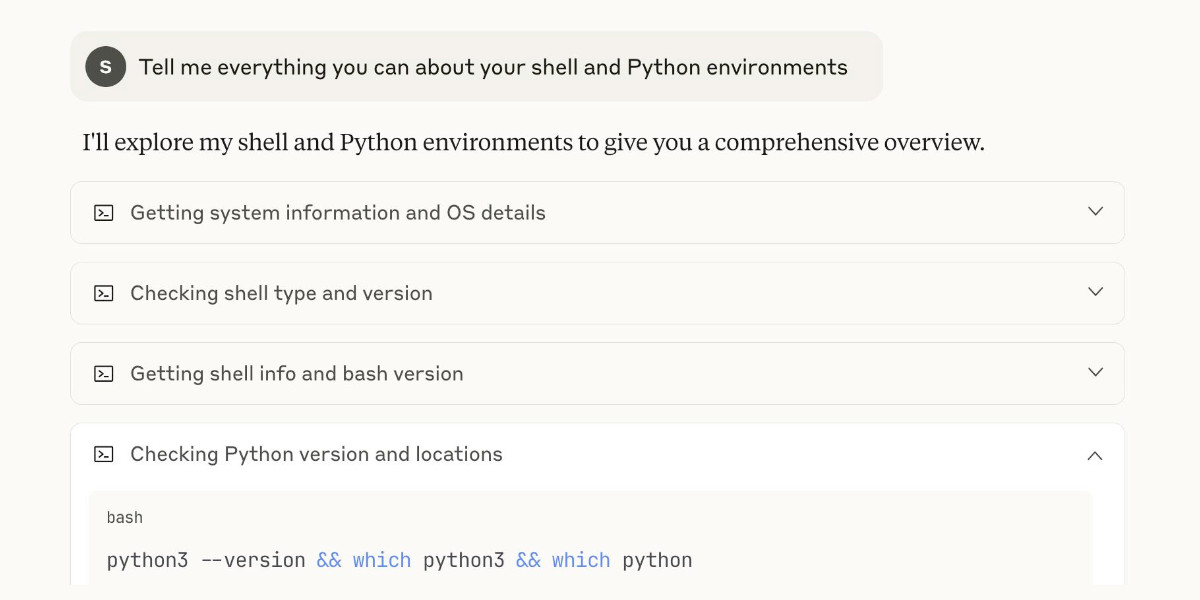
Today on the Anthropic blog: Claude can now create and edit files:
[... 2,771 words]Recreating the Apollo AI adoption rate chart with GPT-5, Python and Pyodide
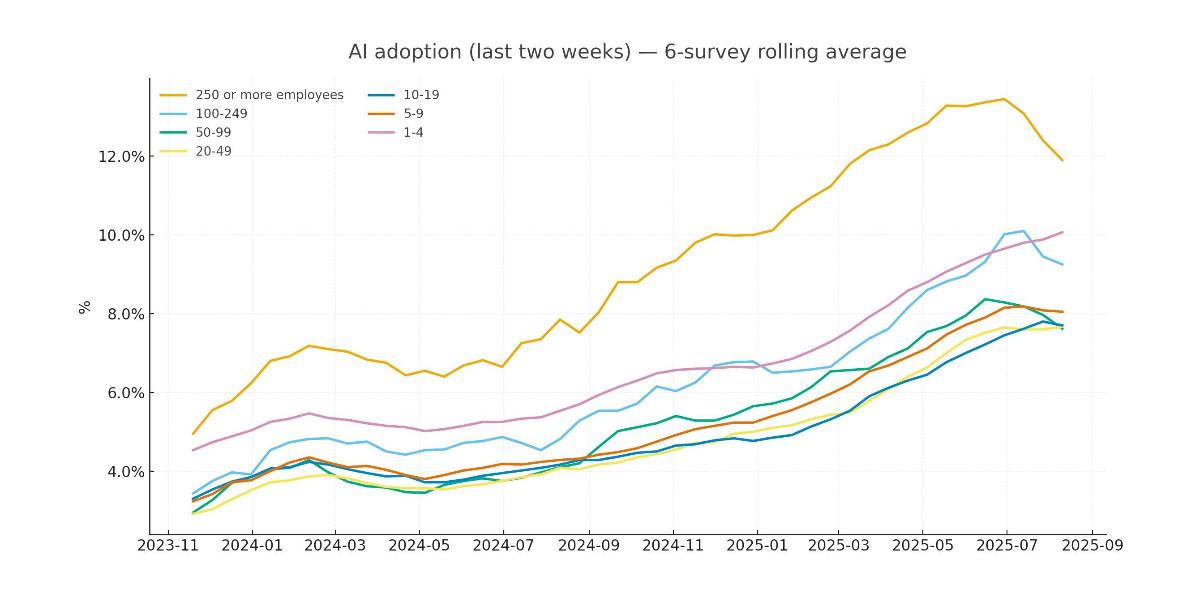
Apollo Global Management’s “Chief Economist” Dr. Torsten Sløk released this interesting chart which appears to show a slowdown in AI adoption rates among large (>250 employees) companies:
[... 2,673 words]GPT-5 Thinking in ChatGPT (aka Research Goblin) is shockingly good at search

“Don’t use chatbots as search engines” was great advice for several years... until it wasn’t.
[... 2,679 words]V&A East Storehouse and Operation Mincemeat in London

We were back in London for a few days and yesterday had a day of culture.
[... 481 words]The Summer of Johann: prompt injections as far as the eye can see

Independent AI researcher Johann Rehberger (previously) has had an absurdly busy August. Under the heading The Month of AI Bugs he has been publishing one report per day across an array of different tools, all of which are vulnerable to various classic prompt injection problems. This is a fantastic and horrifying demonstration of how widespread and dangerous these vulnerabilities still are, almost three years after we first started talking about them.
[... 1,425 words]Open weight LLMs exhibit inconsistent performance across providers
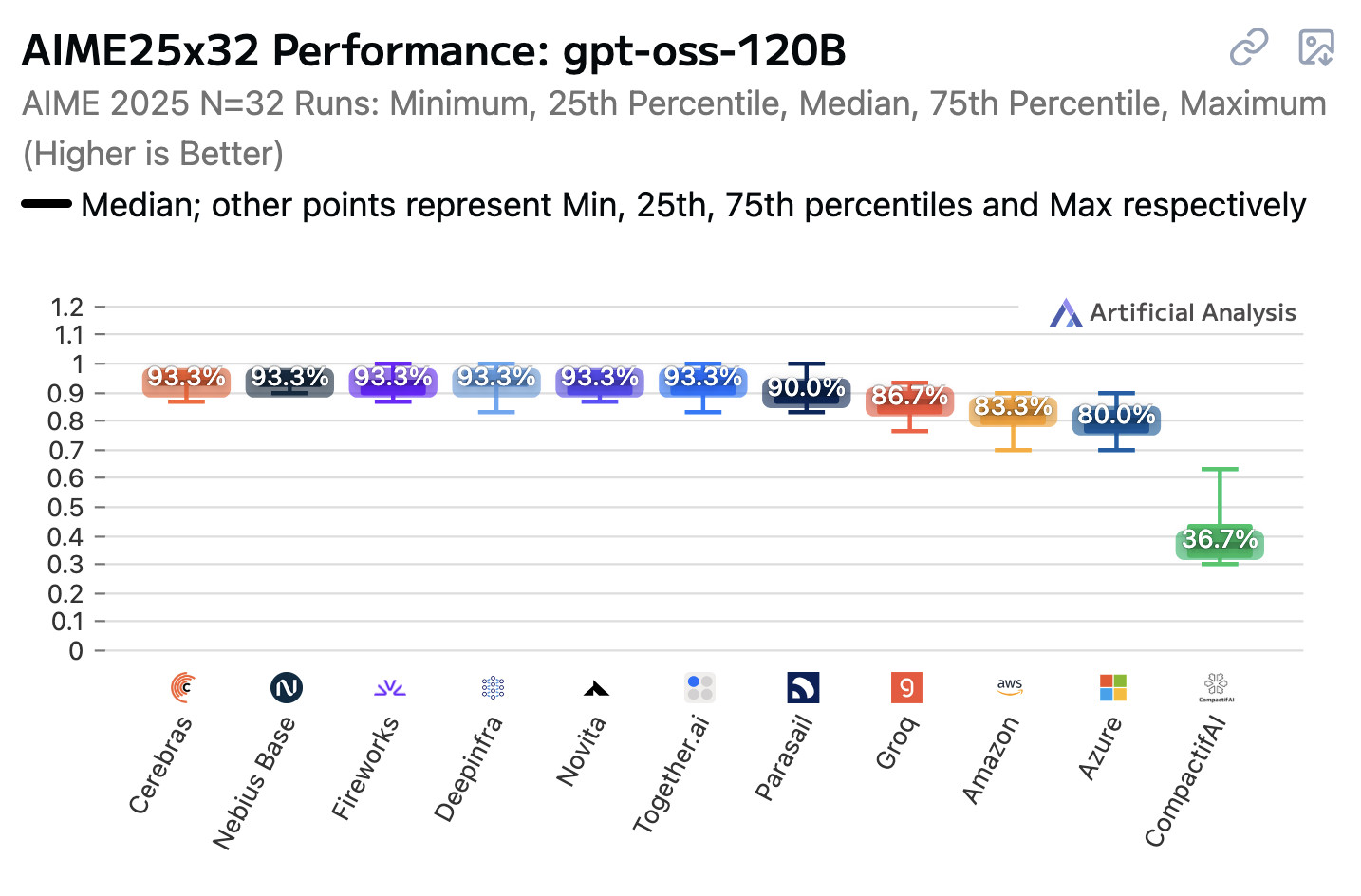
Artificial Analysis published a new benchmark the other day, this time focusing on how an individual model—OpenAI’s gpt-oss-120b—performs across different hosted providers.
[... 847 words]LLM 0.27, the annotated release notes: GPT-5 and improved tool calling
I shipped LLM 0.27 today (followed by a 0.27.1 with minor bug fixes), adding support for the new GPT-5 family of models from OpenAI plus a flurry of improvements to the tool calling features introduced in LLM 0.26. Here are the annotated release notes.
[... 1,174 words]Qwen3-4B-Thinking: “This is art—pelicans don’t ride bikes!”

I’ve fallen a few days behind keeping up with Qwen. They released two new 4B models last week: Qwen3-4B-Instruct-2507 and its thinking equivalent Qwen3-4B-Thinking-2507.
[... 991 words]My Lethal Trifecta talk at the Bay Area AI Security Meetup

I gave a talk on Wednesday at the Bay Area AI Security Meetup about prompt injection, the lethal trifecta and the challenges of securing systems that use MCP. It wasn’t recorded but I’ve created an annotated presentation with my slides and detailed notes on everything I talked about.
[... 2,843 words]The surprise deprecation of GPT-4o for ChatGPT consumers
I’ve been dipping into the r/ChatGPT subreddit recently to see how people are reacting to the GPT-5 launch, and so far the vibes there are not good. This AMA thread with the OpenAI team is a great illustration of the single biggest complaint: a lot of people are very unhappy to lose access to the much older GPT-4o, previously ChatGPT’s default model for most users.
[... 933 words]GPT-5: Key characteristics, pricing and model card

I’ve had preview access to the new GPT-5 model family for the past two weeks (see related video and my disclosures) and have been using GPT-5 as my daily-driver. It’s my new favorite model. It’s still an LLM—it’s not a dramatic departure from what we’ve had before—but it rarely screws up and generally feels competent or occasionally impressive at the kinds of things I like to use models for.
[... 2,448 words]OpenAI’s new open weight (Apache 2) models are really good
The long promised OpenAI open weight models are here, and they are very impressive. They’re available under proper open source licenses—Apache 2.0—and come in two sizes, 120B and 20B.
[... 2,771 words]ChatGPT agent’s user-agent
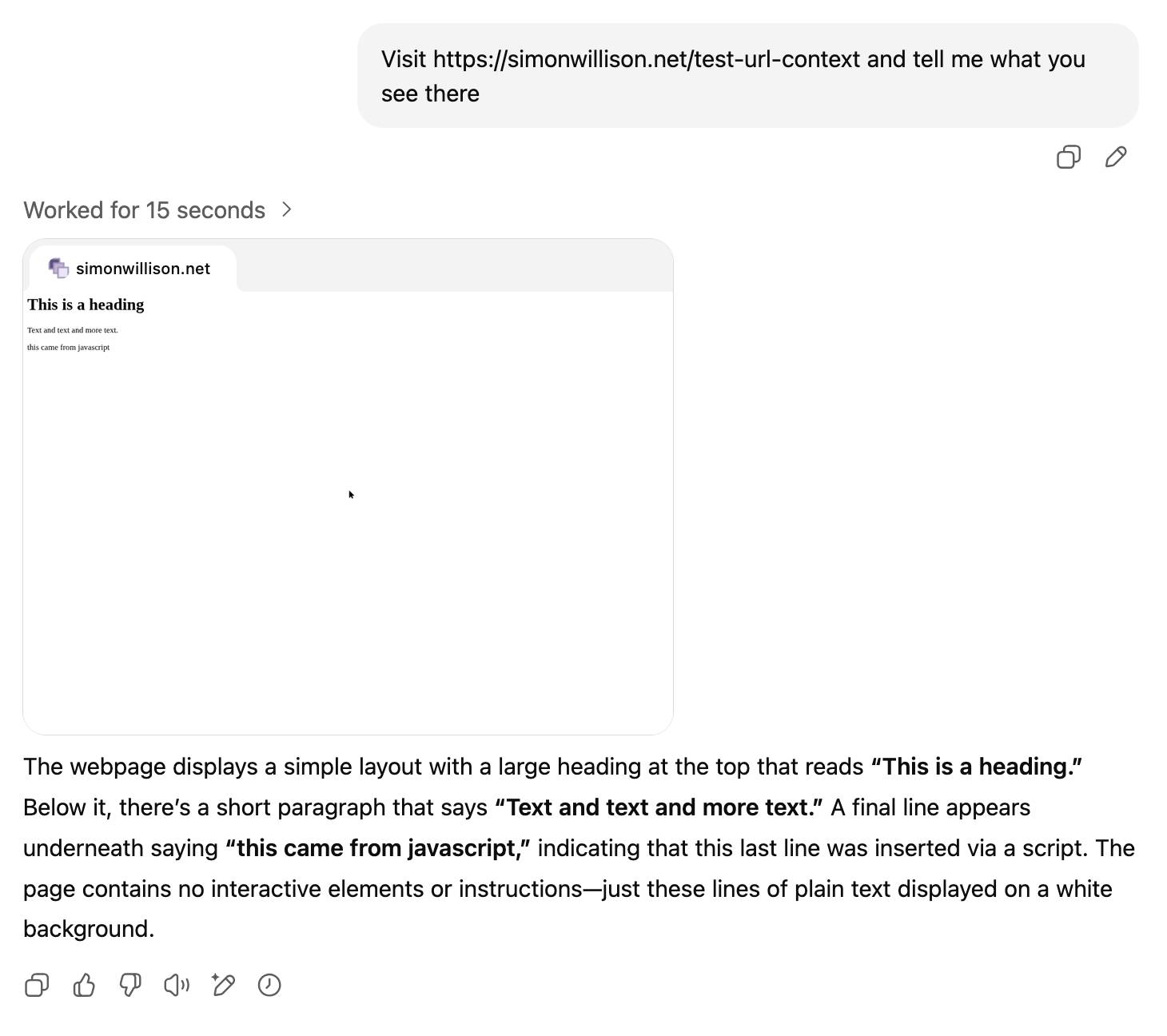
I was exploring how ChatGPT agent works today. I learned some interesting things about how it exposes its identity through HTTP headers, then made a huge blunder in thinking it was leaking its URLs to Bingbot and Yandex... but it turned out that was a Cloudflare feature that had nothing to do with ChatGPT.
[... 1,260 words]The ChatGPT sharing dialog demonstrates how difficult it is to design privacy preferences
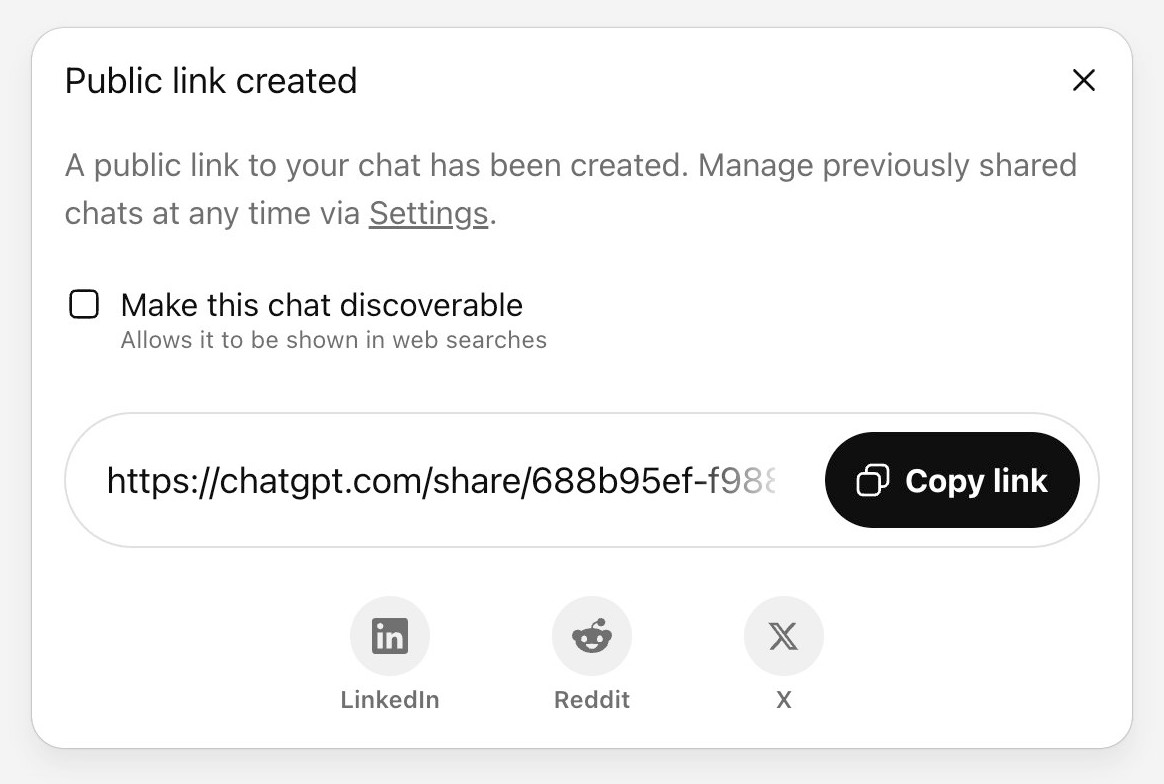
ChatGPT just removed their “make this chat discoverable” sharing feature, after it turned out a material volume of users had inadvertantly made their private chats available via Google search.
[... 999 words]Reverse engineering some updates to Claude
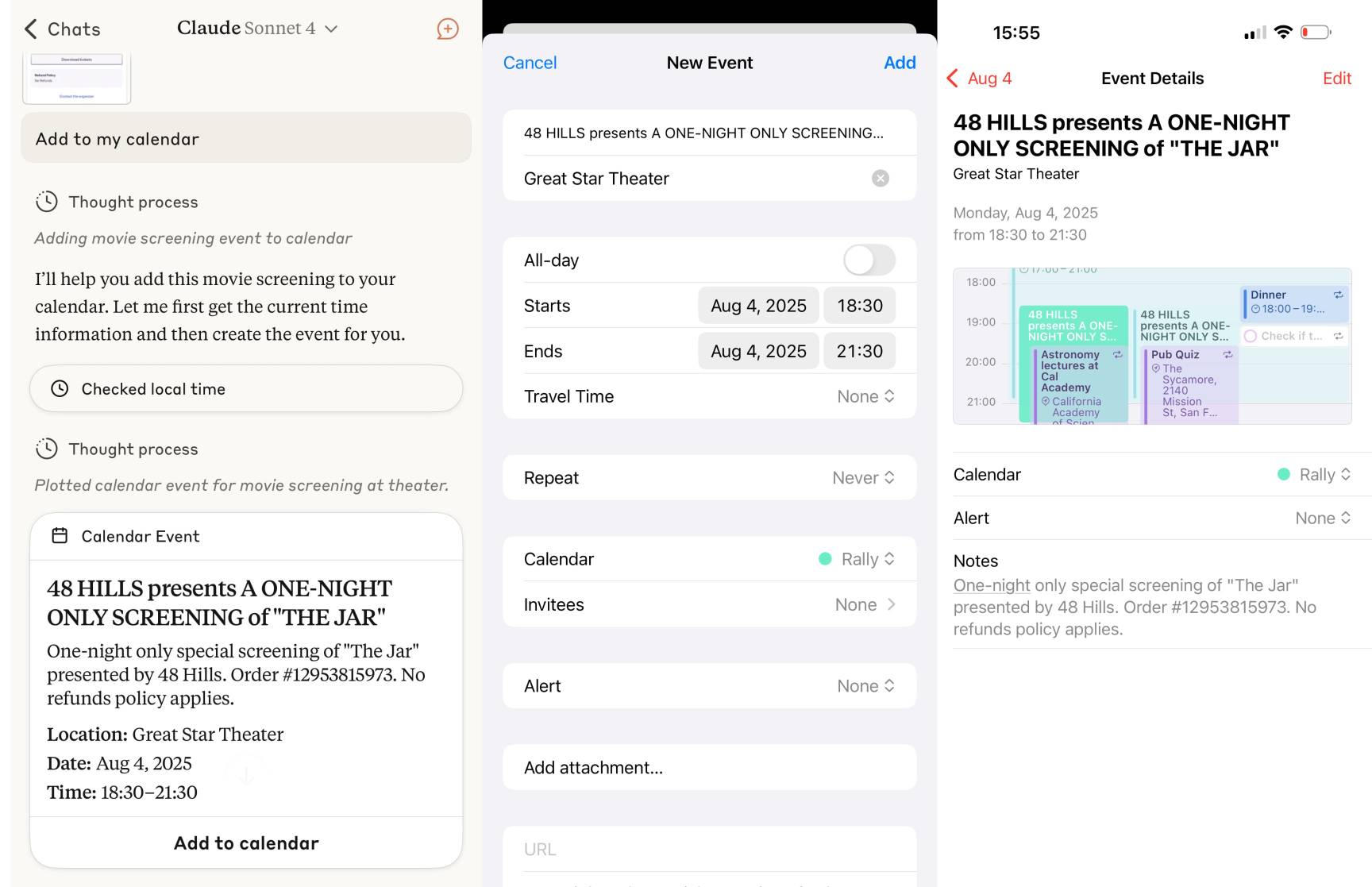
Anthropic released two major new features for their consumer-facing Claude apps in the past couple of days. Sadly, they don’t do a very good job of updating the release notes for those apps—neither of these releases came with any documentation at all beyond short announcements on Twitter. I had to reverse engineer them to figure out what they could do and how they worked!
[... 1,685 words]