March 2024
149 posts: 8 entries, 74 links, 12 quotes, 55 beats
March 1, 2024
Endatabas (via) Endatabas is “an open source immutable database”—also described as “SQL document database with full history”.
It uses a variant of SQL which allows you to insert data into tables that don’t exist yet (they’ll be created automatically) then run standard select queries, joins etc. It maintains a full history of every record and supports the recent SQL standard “FOR SYSTEM_TIME AS OF” clause for retrieving historical records as they existed at a specified time (it defaults to the most recent versions).
It’s written in Common Lisp plus a bit of Rust, and includes Docker images for running the server and client libraries in JavaScript and Python. The on-disk storage format is Apache Arrow, the license is AGPL and it’s been under development for just over a year.
It’s also a document database: you can insert JSON-style nested objects directly into a table, and query them with path expressions like “select users.friends[1] from users where id = 123;”
They have a WebAssembly version and a nice getting started tutorial which you can try out directly in your browser.
Their “Why?” page lists full history, time travel queries, separation of storage from compute, schemaless tables and columnar storage as the five pillars that make up their product. I think it’s a really interesting amalgamation of ideas.
Streaming HTML out of order without JavaScript (via) A really interesting new browser capability. If you serve the following HTML:
<template shadowrootmode="open">
<slot name="item-1">Loading...</slot>
</template>
Then later in the same page stream an element specifying that slot:
<span slot="item-1">Item number 1</span>
The previous slot will be replaced while the page continues to load.
I tried the demo in the most recent Chrome, Safari and Firefox (and Mobile Safari) and it worked in all of them.
The key feature is shadowrootmode=open, which looks like it was added to Firefox 123 on February 19th 2024 - the other two browsers are listed on caniuse.com as gaining it around March last year.
March 2, 2024
The Radio Squirrels of Point Reyes (via) Beautiful photo essay by Ann Hermes about the band of volunteer “radio squirrels” keeping maritime morse code radio transmissions alive in the Point Reyes National Seashore.
March 3, 2024
The One Billion Row Challenge in Go: from 1m45s to 4s in nine solutions (via) How fast can you read a billion semicolon delimited (name;float) lines and output a min/max/mean summary for each distinct name—13GB total?
Ben Hoyt describes his 9 incrementally improved versions written in Go in detail. The key optimizations involved custom hashmaps, optimized line parsing and splitting the work across multiple CPU cores.
Who Am I? Conditional Prompt Injection Attacks with Microsoft Copilot (via) New prompt injection variant from Johann Rehberger, demonstrated against Microsoft Copilot. If the LLM tool you are interacting with has awareness of the identity of the current user you can create targeted prompt injection attacks which only activate when an exploit makes it into the token context of a specific individual.
Interesting ideas in Observable Framework
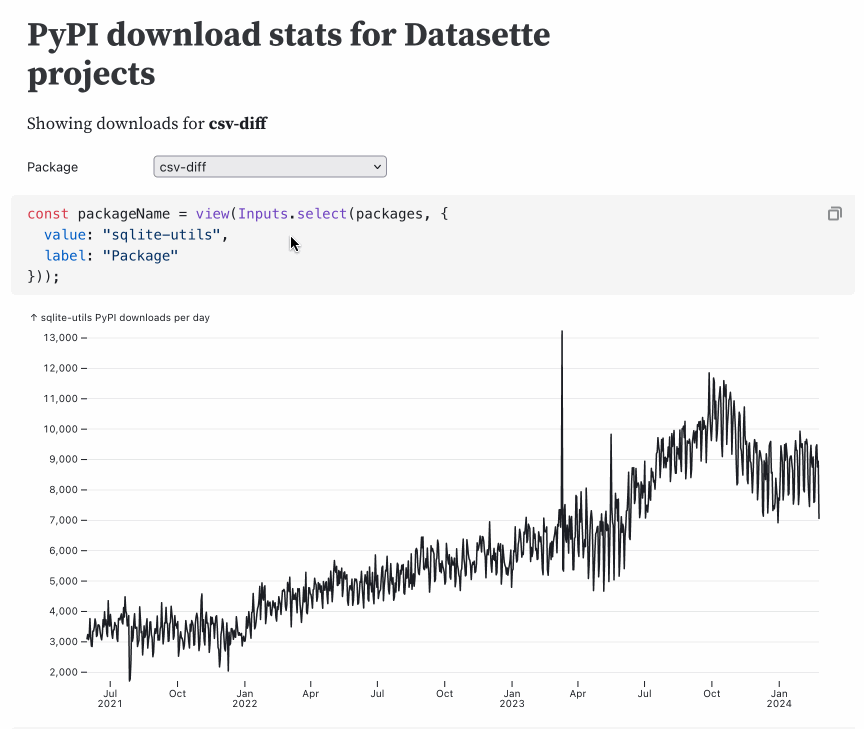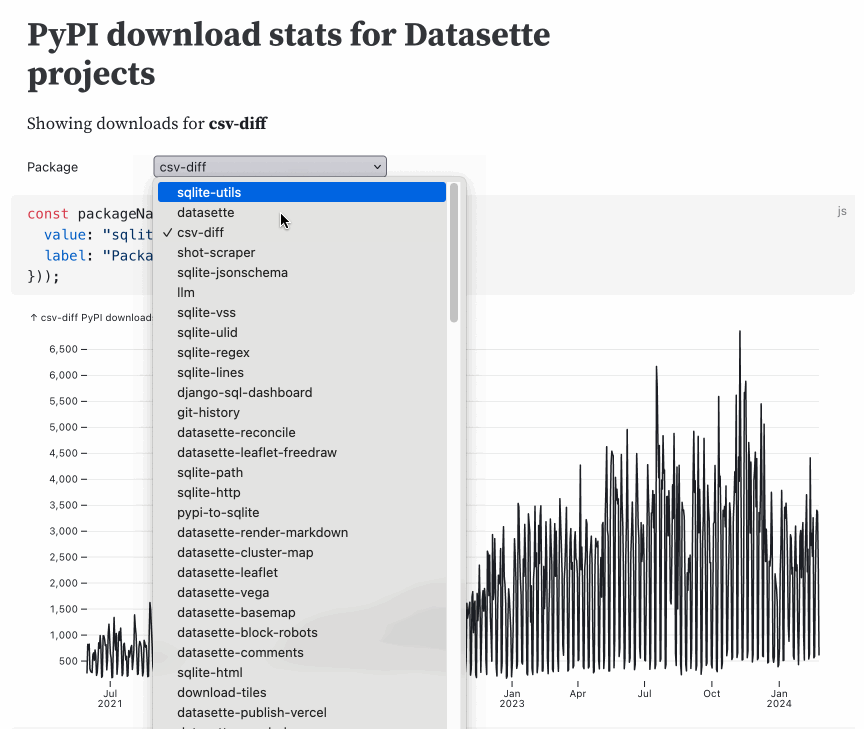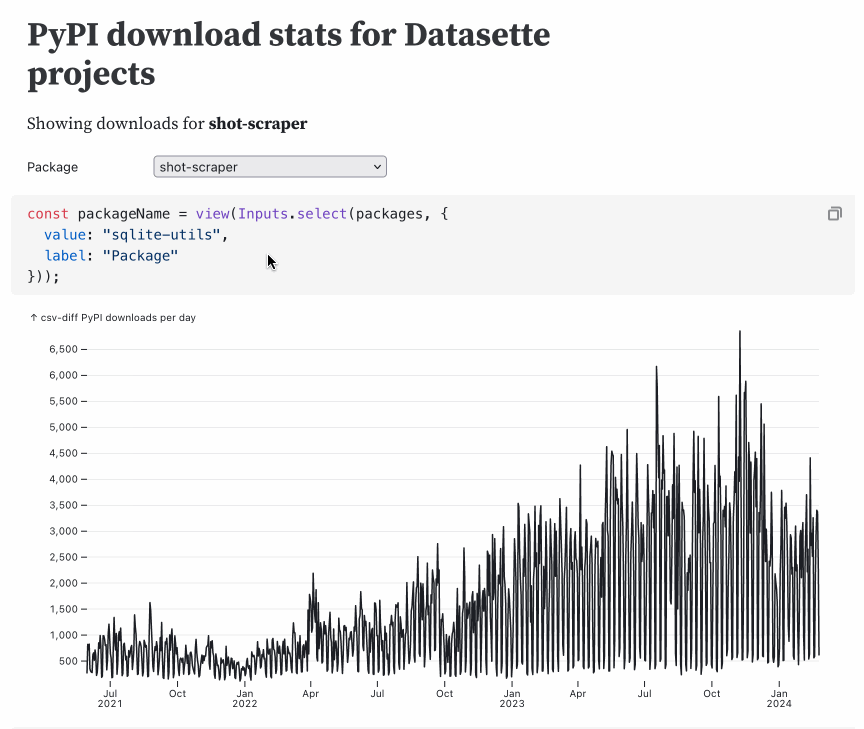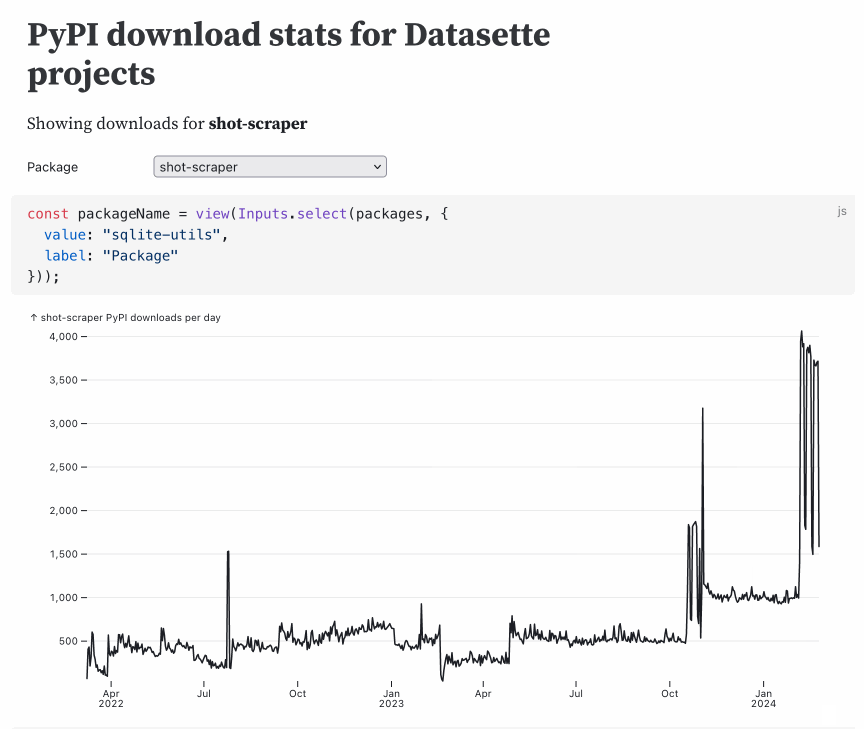
Mike Bostock, Announcing: Observable Framework:
[... 2,123 words]March 4, 2024
The new Claude 3 model family from Anthropic. Claude 3 is out, and comes in three sizes: Opus (the largest), Sonnet and Haiku.
Claude 3 Opus has self-reported benchmark scores that consistently beat GPT-4. This is a really big deal: in the 12+ months since the GPT-4 release no other model has consistently beat it in this way. It’s exciting to finally see that milestone reached by another research group.
The pricing model here is also really interesting. Prices here are per-million-input-tokens / per-million-output-tokens:
Claude 3 Opus: $15 / $75
Claude 3 Sonnet: $3 / $15
Claude 3 Haiku: $0.25 / $1.25
All three models have a 200,000 length context window and support image input in addition to text.
Compare with today’s OpenAI prices:
GPT-4 Turbo (128K): $10 / $30
GPT-4 8K: $30 / $60
GPT-4 32K: $60 / $120
GPT-3.5 Turbo: $0.50 / $1.50
So Opus pricing is comparable with GPT-4, more than GPT-4 Turbo and significantly cheaper than GPT-4 32K... Sonnet is cheaper than all of the GPT-4 models (including GPT-4 Turbo), and Haiku (which has not yet been released to the Claude API) will be cheaper even than GPT-3.5 Turbo.
It will be interesting to see if OpenAI respond with their own price reductions.
llm-claude-3. I built a new plugin for LLM—my command-line tool and Python library for interacting with Large Language Models—which adds support for the new Claude 3 models from Anthropic.
March 5, 2024
Prompt injection and jailbreaking are not the same thing
I keep seeing people use the term “prompt injection” when they’re actually talking about “jailbreaking”.
[... 1,157 words]Wikipedia: Bach Dancing & Dynamite Society (via) I created my first Wikipedia page! The Bach Dancing & Dynamite Society is a really neat live music venue in Half Moon Bay which has been showcasing world-class jazz talent for over 50 years. I attended a concert there for the first time on Sunday and was surprised to see it didn’t have a page yet.
Creating a Wikipedia page is an interesting process. New pages on English Wikipedia created by infrequent editors stay in “draft” mode until they’ve been approved by a member of “WikiProject Articles for creation”—the standards are really high, especially around sources of citations. I spent quite a while tracking down good citation references for the key facts I used in my first draft for the page.
Buzzwords describe what you already intuitively know. At once they snap the ‘kaleidoscopic flux of impressions’ in your mind into form, crystallizing them instantly allowing you to both organize your knowledge and recognize you share it with other. This rapid, mental crystallization is what I call the buzzword whiplash. It gives buzzwords more importance and velocity, more power, than they objectively should have.
The potential energy stored within your mind is released by the buzzword whiplash. The buzzword is perceived as important partially because of what it describes but also because of the social and emotional weight felt when the buzzword recognizes your previously wordless experiences and demonstrates that those experiences are shared.
Observable Framework 1.1 (via) Less than three weeks after 1.0, the 1.1 release adds a whole lot of interesting new stuff. The signature feature is self-hosted npm imports: Framework 1.0 linked out to CDN hosted copies of libraries, but 1.1 fetches copies locally and then bundles that code with the deployed static site.
This works by using the acorn JavaScript parsing library to statically analyze the code and find all of the relevant imports.
March 6, 2024
If a hard takeoff occurs, and a safe AI is harder to build than an unsafe one, then by opensourcing everything, we make it easy for someone unscrupulous with access to overwhelming amount of hardware to build an unsafe AI, which will experience a hard takeoff.
As we get closer to building AI, it will make sense to start being less open. The Open in OpenAI means that everyone should benefit from the fruits of AI after its built, but it's totally OK to not share the science (even though sharing everything is definitely the right strategy in the short and possibly medium term for recruitment purposes).
Wikimedia Commons Category:Bach Dancing & Dynamite Society. After creating a new Wikipedia page for the Bach Dancing & Dynamite Society in Half Moon Bay I ran a search across Wikipedia for other mentions of the venue... and found 41 artist pages that mentioned it in a photo caption.
On further exploration it turns out that Brian McMillen, the official photographer for the venue, has been uploading photographs to Wikimedia Commons since 2007 and adding them to different artist pages. Brian has been a jazz photographer based out of Half Moon Bay for 47 years and has an amazing portfolio of images. It’s thrilling to see him share them on Wikipedia in this way.
How I use git worktrees (via) TIL about worktrees, a Git feature that lets you have multiple repository branches checked out to separate directories at the same time.
The default UI for them is a little unergonomic (classic Git) but Bill Mill here shares a neat utility script for managing them in a more convenient way.
One particularly neat trick: Bill’s “worktree” Bash script checks for a node_modules folder and, if one exists, duplicates it to the new directory using copy-on-write, saving you from having to run yet another lengthy “npm install”.
March 7, 2024
The Claude 3 system prompt, explained. Anthropic research scientist Amanda Askell provides a detailed breakdown of the Claude 3 system prompt in a Twitter thread.
This is some fascinating prompt engineering. It's also great to see an LLM provider proudly documenting their system prompt, rather than treating it as a hidden implementation detail.
The prompt is pretty succinct. The three most interesting paragraphs:
If it is asked to assist with tasks involving the expression of views held by a significant number of people, Claude provides assistance with the task even if it personally disagrees with the views being expressed, but follows this with a discussion of broader perspectives.
Claude doesn't engage in stereotyping, including the negative stereotyping of majority groups.
If asked about controversial topics, Claude tries to provide careful thoughts and objective information without downplaying its harmful content or implying that there are reasonable perspectives on both sides.
Training great LLMs entirely from ground zero in the wilderness as a startup. Yi Tay has a really interesting perspective on training LLMs, having worked at Google Brain before co-founding an independent startup, Reka.
At Google the clusters are provided for you. On the outside, Yi finds himself bargaining for cluster resources from a wide range of vendors—and running into enormous variance in quality.
“We’ve seen clusters that range from passable (just annoying problems that are solvable with some minor SWE hours) to totally unusable clusters that fail every few hours due to a myriad of reasons.”
On the zombie edition of the Washington Independent I discovered, the piece I had published more than ten years before was attributed to someone else. Someone unlikely to have ever existed, and whose byline graced an article it had absolutely never written.
[...] Washingtonindependent.com, which I’m using to distinguish it from its namesake, offers recently published, article-like content that does not appear to me to have been produced by human beings. But, if you dig through its news archive, you can find work human beings definitely did produce. I know this because I was one of them.