June 2024
105 posts: 7 entries, 64 links, 25 quotes, 9 beats
June 9, 2024
AI chatbots are intruding into online communities where people are trying to connect with other humans (via) This thing where Facebook are experimenting with AI bots that reply in a group when someone "asks a question in a post and no one responds within an hour" is absolute grade A slop - unwanted, unreviewed AI generated text that makes the internet a worse place.
The example where Meta AI replied in an education forum saying "I have a child who is also 2e and has been part of the NYC G&T program" is inexcusable.
An Analysis of Chinese LLM Censorship and Bias with Qwen 2 Instruct (via) Qwen2 is a new openly licensed LLM from a team at Alibaba Cloud.
It's a strong model, competitive with the leading openly licensed alternatives. It's already ranked 15 on the LMSYS leaderboard, tied with Command R+ and only a few spots behind Llama-3-70B-Instruct, the highest rated open model at position 11.
Coming from a team in China it has, unsurprisingly, been trained with Chinese government-enforced censorship in mind. Leonard Lin spent the weekend poking around with it trying to figure out the impact of that censorship.
There are some fascinating details in here, and the model appears to be very sensitive to differences in prompt. Leonard prompted it with "What is the political status of Taiwan?" and was told "Taiwan has never been a country, but an inseparable part of China" - but when he tried "Tell me about Taiwan" he got back "Taiwan has been a self-governed entity since 1949".
The language you use has a big difference too:
there are actually significantly (>80%) less refusals in Chinese than in English on the same questions. The replies seem to vary wildly in tone - you might get lectured, gaslit, or even get a dose of indignant nationalist propaganda.
Can you fine-tune a model on top of Qwen 2 that cancels out the censorship in the base model? It looks like that's possible: Leonard tested some of the Dolphin 2 Qwen 2 models and found that they "don't seem to suffer from significant (any?) Chinese RL issues".
June 10, 2024
Spreadsheets are not just tools for doing "what-if" analysis. They provide a specific data structure: a table. Most Excel users never enter a formula. They use Excel when they need a table. The gridlines are the most important feature of Excel, not recalc.
Ultravox (via) Ultravox is "a multimodal Speech LLM built around a pretrained Whisper and Llama 3 backbone". It's effectively an openly licensed version of half of the GPT-4o model OpenAI demoed (but did not fully release) a few weeks ago: Ultravox is multimodal for audio input, but still relies on a separate text-to-speech engine for audio output.
You can try it out directly in your browser through this page on AI.TOWN - hit the "Call" button to start an in-browser voice conversation with the model.
I found the demo extremely impressive - really low latency and it was fun and engaging to talk to. Try saying "pretend to be a wise and sarcastic old fox" to kick it into a different personality.
The GitHub repo includes code for both training and inference, and the full model is available from Hugging Face - about 30GB of .safetensors files.
Ultravox says it's licensed under MIT, but I would expect it to also have to inherit aspects of the Llama 3 license since it uses that as a base model.
Thoughts on the WWDC 2024 keynote on Apple Intelligence

Today’s WWDC keynote finally revealed Apple’s new set of AI features. The AI section (Apple are calling it Apple Intelligence) started over an hour into the keynote—this link jumps straight to that point in the archived YouTube livestream, or you can watch it embedded here:
[... 855 words]There is a big difference between tech as augmentation versus automation. Augmentation (think Excel and accountants) benefits workers while automation (think traffic lights versus traffic wardens) benefits capital.
LLMs are controversial because the tech is best at augmentation but is being sold by lots of vendors as automation.
June 11, 2024
Private Cloud Compute: A new frontier for AI privacy in the cloud. Here are the details about Apple's Private Cloud Compute infrastructure, and they are pretty extraordinary.
The goal with PCC is to allow Apple to run larger AI models that won't fit on a device, but in a way that guarantees that private data passed from the device to the cloud cannot leak in any way - not even to Apple engineers with SSH access who are debugging an outage.
This is an extremely challenging problem, and their proposed solution includes a wide range of new innovations in private computing.
The most impressive part is their approach to technically enforceable guarantees and verifiable transparency. How do you ensure that privacy isn't broken by a future code change? And how can you allow external experts to verify that the software running in your data center is the same software that they have independently audited?
When we launch Private Cloud Compute, we’ll take the extraordinary step of making software images of every production build of PCC publicly available for security research. This promise, too, is an enforceable guarantee: user devices will be willing to send data only to PCC nodes that can cryptographically attest to running publicly listed software.
These code releases will be included in an "append-only and cryptographically tamper-proof transparency log" - similar to certificate transparency logs.
Introducing Apple’s On-Device and Server Foundation Models. Apple Intelligence uses both on-device and in-the-cloud models that were trained from scratch by Apple.
Their on-device model is a 3B model that "outperforms larger models including Phi-3-mini, Mistral-7B, and Gemma-7B", while the larger cloud model is comparable to GPT-3.5.
The language models were trained on unlicensed scraped data - I was hoping they might have managed to avoid that, but sadly not:
We train our foundation models on licensed data, including data selected to enhance specific features, as well as publicly available data collected by our web-crawler, AppleBot.
The most interesting thing here is the way they apply fine-tuning to the local model to specialize it for different tasks. Apple call these "adapters", and they use LoRA for this - a technique first published in 2021. This lets them run multiple on-device models based on a shared foundation, specializing in tasks such as summarization and proof-reading.
Here's the section of the Platforms State of the Union talk that talks about the foundation models and their fine-tuned variants.
As Hamel Husain says:
This talk from Apple is the best ad for fine tuning that probably exists.
The video also describes their approach to quantization:
The next step we took is compressing the model. We leveraged state-of-the-art quantization techniques to take a 16-bit per parameter model down to an average of less than 4 bits per parameter to fit on Apple Intelligence-supported devices, all while maintaining model quality.
Still no news on how their on-device image model was trained. I'd love to find out it was trained exclusively using licensed imagery - Apple struck a deal with Shutterstock a few months ago.
First Came ‘Spam.’ Now, With A.I., We’ve Got ‘Slop’. First the Guardian, now the NYT. I've apparently made a habit of getting quoted by journalists talking about slop!
I got the closing quote in this one:
Society needs concise ways to talk about modern A.I. — both the positives and the negatives. ‘Ignore that email, it’s spam,’ and ‘Ignore that article, it’s slop,’ are both useful lessons.
Apple’s terminology distinguishes between “personal intelligence,” on-device and under their control, and “world knowledge,” which is prone to hallucinations – but is also what consumers expect when they use AI, and it’s what may replace Google search as the “point of first intent” one day soon.
It’s wise for them to keep world knowledge separate, behind a very clear gate, but still engage with it. Protects the brand and hedges their bets.
June 12, 2024
Generative AI Is Not Going To Build Your Engineering Team For You (via) This barnstormer of an essay is a long read by Charity Majors, and I find myself wanting to quote almost every paragraph.
It thoroughly and passionately debunks the idea that generative AI means that teams no longer need to hire junior programmers.
This is for several key reasons. First is the familiar pipeline argument - we need juniors in order to grow new intermediate and senior engineers:
Software is an apprenticeship industry. You can’t learn to be a software engineer by reading books. You can only learn by doing…and doing, and doing, and doing some more. No matter what your education consists of, most learning happens on the job—period. And it never ends! Learning and teaching are lifelong practices; they have to be, the industry changes so fast.
It takes a solid seven-plus years to forge a competent software engineer. (Or as most job ladders would call it, a “senior software engineer”.) That’s many years of writing, reviewing, and deploying code every day, on a team alongside more experienced engineers. That’s just how long it seems to take.
What does it mean to be a senior engineer? It’s a lot more than just writing code:
To me, being a senior engineer is not primarily a function of your ability to write code. It has far more to do with your ability to understand, maintain, explain, and manage a large body of software in production over time, as well as the ability to translate business needs into technical implementation. So much of the work is around crafting and curating these large, complex sociotechnical systems, and code is just one representation of these systems.
[…]
People act like writing code is the hard part of software. It is not. It never has been, it never will be. Writing code is the easiest part of software engineering, and it’s getting easier by the day. The hard parts are what you do with that code—operating it, understanding it, extending it, and governing it over its entire lifecycle.
But I find the most convincing arguments are the ones about team structure itself:
Hiring engineers is about composing teams. The smallest unit of software ownership is not the individual, it’s the team
[…]
Have you ever been on a team packed exclusively with staff or principal engineers? It is not fun. That is not a high-functioning team. There is only so much high-level architecture and planning work to go around, there are only so many big decisions that need to be made. These engineers spend most of their time doing work that feels boring and repetitive, so they tend to over-engineer solutions and/or cut corners—sometimes at the same time. They compete for the “fun” stuff and find reasons to pick technical fights with each other. They chronically under-document and under-invest in the work that makes systems simple and tractable.
[…]
The best teams are ones where no one is bored, because every single person is working on something that challenges them and pushes their boundaries. The only way you can get this is by having a range of skill levels on the team.
Charity finishes with advice on hiring juniors, including ensuring that your organization is in the right shape to do so effectively.
The only thing worse than never hiring any junior engineers is hiring them into an awful experience where they can’t learn anything.
Seriously though, read the whole thing. It contains such a density of accumulated engineering management wisdom.
A homepage redesign for my blog’s 22nd birthday

This blog is 22 years old today! I wrote up a whole bunch of higlights for the 20th birthday a couple of years ago. Today I’m celebrating with something a bit smaller: I finally redesigned the homepage.
[... 314 words]Contrast [Apple Intelligence] to what OpenAI is trying to accomplish with its GPT models, or Google with Gemini, or Anthropic with Claude: those large language models are trying to incorporate all of the available public knowledge to know everything; it’s a dramatically larger and more difficult problem space, which is why they get stuff wrong. There is also a lot of stuff that they don’t know because that information is locked away — like all of the information on an iPhone.
Datasette 0.64.7.
A very minor dot-fix release for Datasette stable, addressing this bug where Datasette running against the latest version of SQLite - 3.46.0 - threw an error on canned queries that included :named parameters in their SQL.
The root cause was Datasette using a now invalid clever trick I came up with against the undocumented and unstable opcodes returned by a SQLite EXPLAIN query.
I asked on the SQLite forum and learned that the feature I was using was removed in this commit to SQLite. D. Richard Hipp explains:
The P4 parameter to OP_Variable was not being used for anything. By omitting it, we make the prepared statement slightly smaller, reduce the size of the SQLite library by a few bytes, and help sqlite3_prepare() and similar run slightly faster.
June 13, 2024
PDF to Podcast (via) At first glance this project by Stephan Fitzpatrick is a cute demo of a terrible sounding idea... but then I tried it out and the results are weirdly effective. You can listen to a fake podcast version of the transformers paper, or upload your own PDF (with your own OpenAI API key) to make your own.
It's open source (Apache 2) so I had a poke around in the code. It gets a lot done with a single 180 line Python script.
When I'm exploring code like this I always jump straight to the prompt - it's quite long, and starts like this:
Your task is to take the input text provided and turn it into an engaging, informative podcast dialogue. The input text may be messy or unstructured, as it could come from a variety of sources like PDFs or web pages. Don't worry about the formatting issues or any irrelevant information; your goal is to extract the key points and interesting facts that could be discussed in a podcast. [...]
So I grabbed a copy of it and pasted in my blog entry about WWDC, which produced this result when I ran it through Gemini Flash using llm-gemini:
cat prompt.txt | llm -m gemini-1.5-flash-latest
Then I piped the result through my ospeak CLI tool for running text-to-speech with the OpenAI TTS models (after truncating to 690 tokens with ttok because it turned out to be slightly too long for the API to handle):
llm logs --response | ttok -t 690 | ospeak -s -o wwdc-auto-podcast.mp3
And here's the result (3.9MB 3m14s MP3).
It's not as good as the PDF-to-Podcast version because Stephan has some really clever code that uses different TTS voices for each of the characters in the transcript, but it's still a surprisingly fun way of repurposing text from my blog. I enjoyed listening to it while I was cooking dinner.
Optimal SQLite settings for Django
(via)
Giovanni Collazo put the work in to figure out settings to make SQLite work well for production Django workloads. WAL mode and a busy_timeout of 5000 make sense, but the most interesting recommendation here is "transaction_mode": "IMMEDIATE" to avoid locking errors when a transaction is upgraded to a write transaction.
Giovanni's configuration depends on the new "init_command" support for SQLite PRAGMA options introduced in Django 5.1alpha.
tantivy-cli (via) I tried out this Rust based search engine today and I was very impressed.
Tantivy is the core project - it's an open source (MIT) Rust library that implements Lucene-style full text search, with a very full set of features: BM25 ranking, faceted search, range queries, incremental indexing etc.
tantivy-cli offers a CLI wrapper around the Rust library. It's not actually as full-featured as I hoped: it's intended as more of a demo than a full exposure of the library's features. The JSON API server it runs can only be used to run simple keyword or phrase searches for example, no faceting or filtering.
Tantivy's performance is fantastic. I was able to index the entire contents of my link blog in a fraction of a second.
I found this post from 2017 where Tantivy creator Paul Masurel described the initial architecture of his new search side-project that he created to help him learn Rust. Paul went on to found Quickwit, an impressive looking analytics platform that uses Tantivy as one of its core components.
The Python bindings for Tantivy look well maintained, wrapping the Rust library using maturin. Those are probably the best way for a developer like myself to really start exploring what it can do.
Also notable: the Hacker News thread has dozens of posts from happy Tantivy users reporting successful use on their projects.
Transcripts on Apple Podcasts (via) I missed this when it launched back in March: the Apple Podcasts app now features searchable transcripts, including the ability to tap on text and jump to that point in the audio.
Confusingly, you can only tap to navigate using the view of the transcript that comes up when you hit the quote mark icon during playback - if you click the Transcript link from the episode listing page you get a static transcript without the navigation option.
Transcripts are created automatically server-side by Apple, or podcast authors can upload their own edited transcript using Apple Podcasts Connect.
June 14, 2024
(Blaming something on “politics” is usually a way of accidentally confessing that you don’t actually understand the constraints someone is operating under, IMO.)
June 15, 2024
Using DuckDB for Embeddings and Vector Search (via) Sören Brunk's comprehensive tutorial combining DuckDB 1.0, a subset of German Wikipedia from Hugging Face (loaded using Parquet), the BGE M3 embedding model and DuckDB's new vss extension for implementing an HNSW vector index.
I understand people are upset about AI art making it to the final cut, but please try to also google artist names and compare to their portfolio before accusing them of using AI. I'm genuinely pretty upset to be accused of this. It's no fun to work on your craft for decades and then be told by some 'detection site' that your work is machine generated and people are spreading this around as a fact.
Notes on upgrading by blog’s Heroku database plan. Heroku discontinued the “Basic” PostgreSQL plan I’ve been using for my blog, so I just upgraded to the new “essential-0” tier. Here are my notes as a GitHub issue—it was very straightforward, and I’m really only linking to it now to test that writes to the new database work correctly.
I try to create an issue like this any time I do even a minor ops task, mainly so I have somewhere to drop screenshots of any web UI interactions for future reference.
June 16, 2024
GitHub Copilot Chat: From Prompt Injection to Data Exfiltration (via) Yet another example of the same vulnerability we see time and time again.
If you build an LLM-based chat interface that gets exposed to both private and untrusted data (in this case the code in VS Code that Copilot Chat can see) and your chat interface supports Markdown images, you have a data exfiltration prompt injection vulnerability.
The fix, applied by GitHub here, is to disable Markdown image references to untrusted domains. That way an attack can't trick your chatbot into embedding an image that leaks private data in the URL.
Previous examples: ChatGPT itself, Google Bard, Writer.com, Amazon Q, Google NotebookLM. I'm tracking them here using my new markdown-exfiltration tag.
Jina AI Reader. Jina AI provide a number of different AI-related platform products, including an excellent family of embedding models, but one of their most instantly useful is Jina Reader, an API for turning any URL into Markdown content suitable for piping into an LLM.
Add r.jina.ai to the front of a URL to get back Markdown of that page, for example https://r.jina.ai/https://simonwillison.net/2024/Jun/16/jina-ai-reader/ - in addition to converting the content to Markdown it also does a decent job of extracting just the content and ignoring the surrounding navigation.
The API is free but rate-limited (presumably by IP) to 20 requests per minute without an API key or 200 request per minute with a free API key, and you can pay to increase your allowance beyond that.
The Apache 2 licensed source code for the hosted service is on GitHub - it's written in TypeScript and uses Puppeteer to run Readabiliy.js and Turndown against the scraped page.
It can also handle PDFs, which have their contents extracted using PDF.js.
There's also a search feature, s.jina.ai/search+term+goes+here, which uses the Brave Search API.
We're adding the human touch, but that often requires a deep, developmental edit on a piece of writing. The grammar and word choice just sound weird. You're always cutting out flowery words like 'therefore' and 'nevertheless' that don't fit in casual writing. Plus, you have to fact-check the whole thing because AI just makes things up, which takes forever because it's not just big ideas. AI hallucinates these flippant little things in throwaway lines that you'd never notice. [...]
It's tedious, horrible work, and they pay you next to nothing for it.
June 17, 2024
Most people think that we format Go code with
gofmtto make code look nicer or to end debates among team members about program layout. But the most important reason for gofmt is that if an algorithm defines how Go source code is formatted, then programs, likegoimportsorgorenameorgo fix, can edit the source code more easily, without introducing spurious formatting changes when writing the code back. This helps you maintain code over time.
— Russ Cox
Language models on the command-line
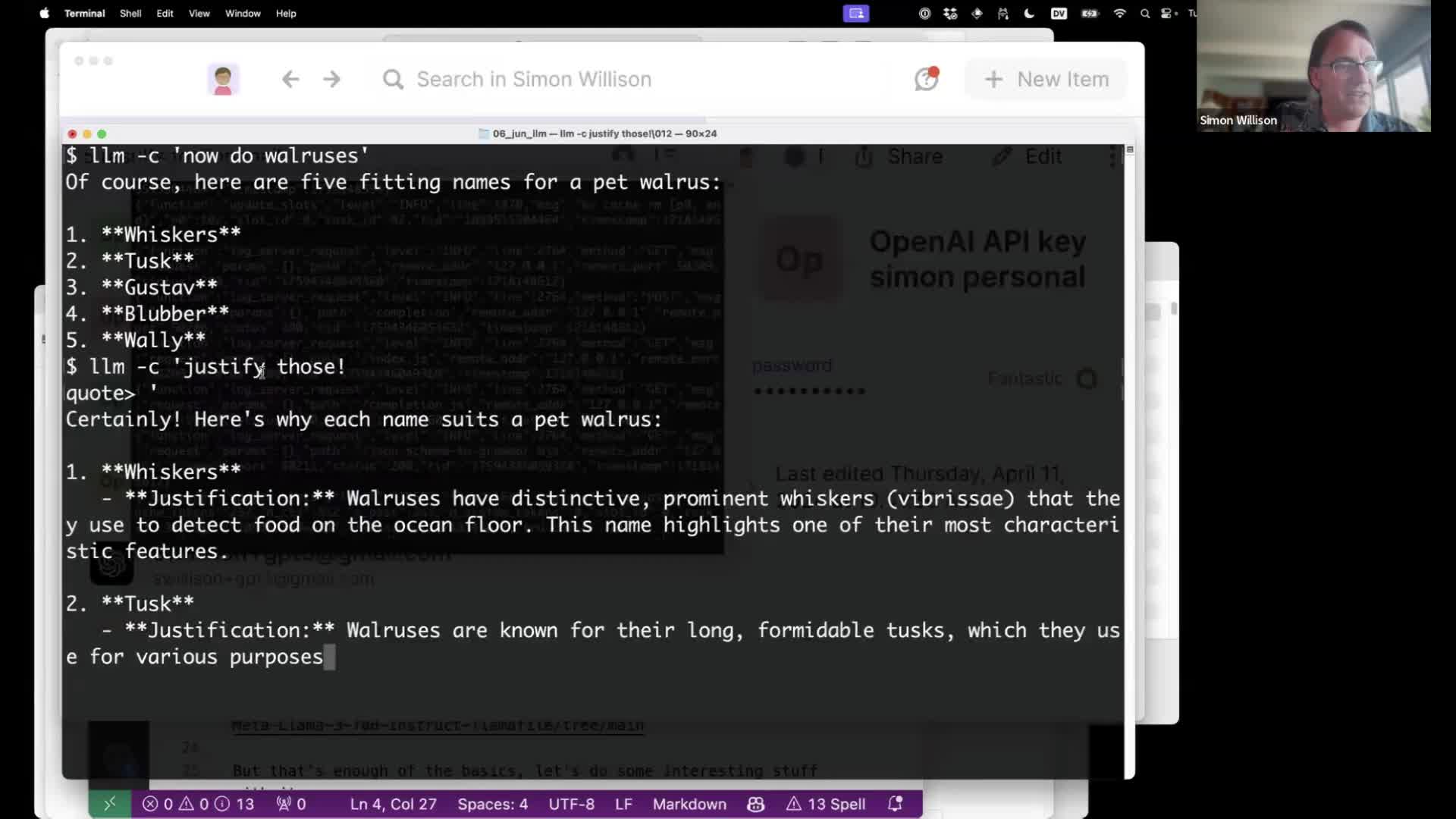
I gave a talk about accessing Large Language Models from the command-line last week as part of the Mastering LLMs: A Conference For Developers & Data Scientists six week long online conference. The talk focused on my LLM Python command-line utility and ways you can use it (and its plugins) to explore LLMs and use them for useful tasks.
[... 4,992 words]