93 posts tagged “search”
2022
Simple, Fast, and Scalable Reverse Image Search Using Perceptual Hashes and DynamoDB. Christopher Bong provides a clear explanation of how perceptual hashes can be used to create a string representing the visual content of an image, such that similar images can be identified by calculating a hamming distance between those hashes. He then explains how they built a large-scale system for this at Canva on top of DynamoDB, by splitting those strings into smaller hash windows and using those for efficient bulk lookups of similar candidates.
Exploring the training data behind Stable Diffusion
Two weeks ago, the Stable Diffusion image generation model was released to the public. I wrote about this last week, in Stable Diffusion is a really big deal—a post which has since become one of the top ten results for “stable diffusion” on Google and shown up in all sorts of different places online.
[... 2,897 words]Abusing AWS Lambda to make an Aussie Search Engine (via) Ben Boyter built a search engine that only indexes .au Australian websites, with the novel approach of directly compiling the search index into 250 different ~40MB large lambda functions written in Go, then running searches across 12 million pages by farming them out to all of the lambdas and combining the results. His write-up includes all sorts of details about how he built this, including how he ran the indexer and how he solved the surprisingly hard problem of returning good-enough text snippets for the results.
2020
Building a search engine for datasette.io
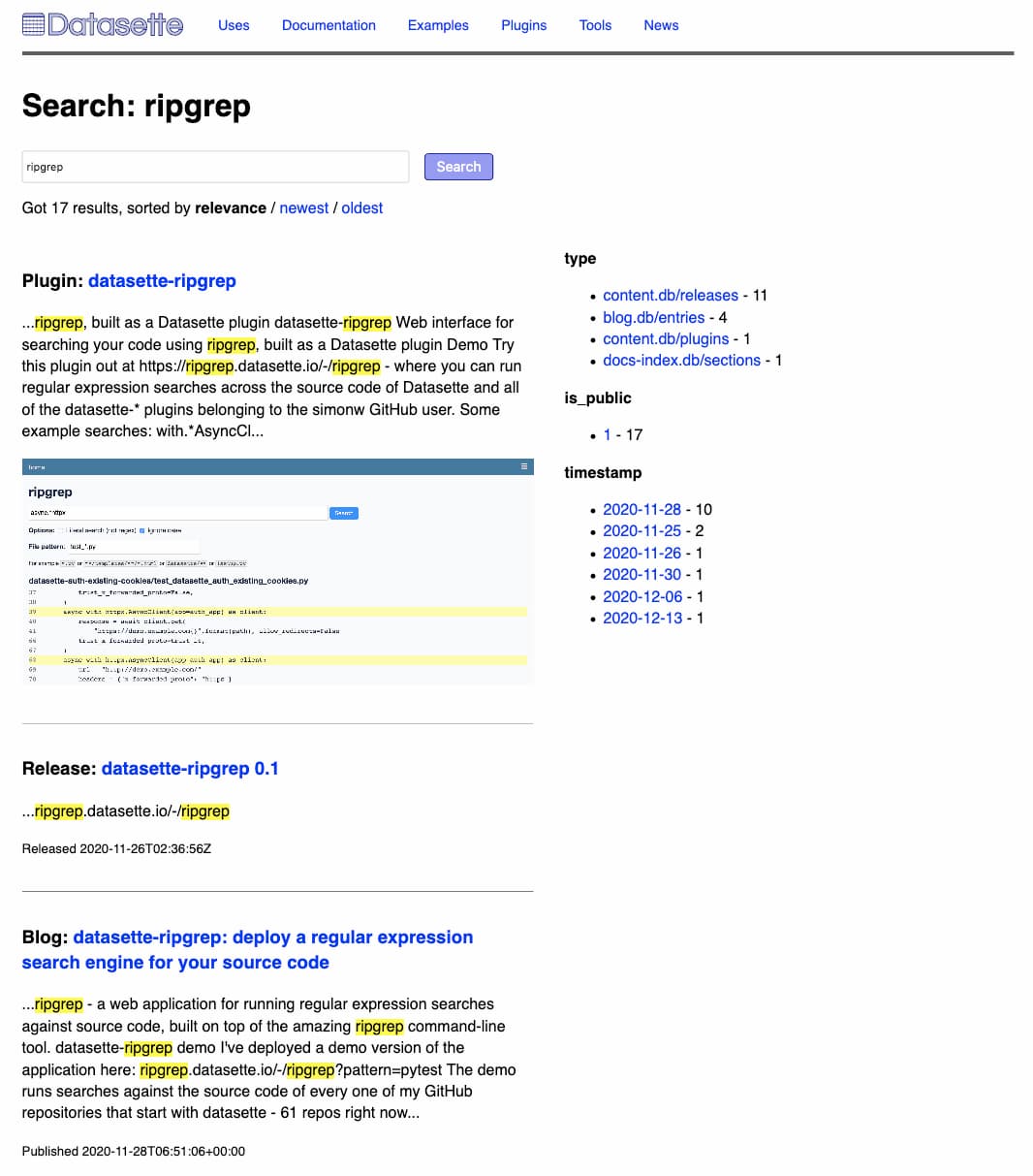
This week I added a search engine to datasette.io, using the search indexing tool I’ve been building for Dogsheep.
[... 1,391 words]sqlite-utils 2.14 (via) I finally figured out porter stemming with SQLite full-text search today—it turns out it’s as easy as adding tokenize=’porter’ to the CREATE VIRTUAL TABLE statement. So I just shipped sqlite-utils 2.14 with a tokenize= option (plus the ability to insert binary file data from stdin).
PostgreSQL full-text search in the Django Admin. Today I figured out how to use PostgreSQL full-text search in the Django admin for my blog, using the get_search_results method on a subclass of ModelAdmin.
Reducing search indexing latency to one second. Really detailed dive into the nuts and bolts of Twitter’s latest iteration of search indexing technology, including a great explanation of skip lists.
datasette-search-all: a new plugin for searching multiple Datasette tables at once
I just released a new plugin for Datasette, and it’s pretty fun. datasette-search-all is a plugin written mostly in JavaScript that executes the same search query against every searchable table in every database connected to your Datasette instance.
[... 819 words]Weeknotes: datasette-ics, datasette-upload-csvs, datasette-configure-fts, asgi-csrf
I’ve been preparing for the NICAR 2020 Data Journalism conference this week which has lead me into a flurry of activity across a plethora of different projects and plugins.
[... 834 words]2019
Guide To Using Reverse Image Search For Investigations (via) Detailed guide from Bellingcat’s Aric Toler on using reverse image search for investigative reporting. Surprisingly Google Image Search isn’t the state of the art: Russian search engine Yandex offers a much more powerful solution, mainly because it’s the largest public-facing image search engine to integrate scary levels of face recognition.
Falsehoods Programmers Believe About Search (via) These are great. “When you find the boolean operator ‘OR’, you always know it doesn’t mean Oregon”.
Discussion about Altavista on Hacker News. Fascinating thread on Hacker News where Bryant Durrell, a former Director from Altavista provides some insider thoughts on how they lost against Google.
Exploring search relevance algorithms with SQLite
SQLite isn’t just a fast, high quality embedded database: it also incorporates a powerful full-text search engine in the form of the FTS4 and FTS5 extensions. You’ve probably used these a bunch of times already: many iOS, Android and desktop applications use SQLite under-the-hood and use it to implement their built-in search.
[... 1,390 words]2018
Fast Autocomplete Search for Your Website (via) I wrote a tutorial for the 24 ways advent calendar on building fast autocomplete search for a website on top of Datasette and SQLite. I built the demo against 24 ways itself—I used wget to recursively fetch all 330 articles as HTML, then wrote code in a Jupyter notebook to extract the raw data from them (with BeautifulSoup) and load them into SQLite using my sqlite-utils Python library. I deployed the resulting database using Datasette, then wrote some vanilla JavaScript to implement autocomplete using fast SQL queries against the Datasette JSON API.
Datasette: Full-text search. I wrote some documentation for Datasette’s full-text search feature, which detects tables which have been configured to use the SQLite FTS module and adds a search input box and support for a _search= querystring parameter.
Typesense (via) A new (to me) open source search engine, with a focus on being “typo-tolerant” and offering great, fast autocomplete—incredibly important now that most searches take place using a mobile phone keyboard. Similar to Elasticsearch or Solr in that it runs as an HTTP server that you serve JSON via POST and GET—and it offers read-only replicas for scaling and high availability. And since it’s 2018, if you have Docker running (I use Docker for Mac) you can start up a test instance with a one-line shell command.
2017
New in Datasette: filters, foreign keys and search
I’ve released Datasette 0.13 with a number of exciting new features (Datasette previously).
[... 1,143 words]Implementing faceted search with Django and PostgreSQL
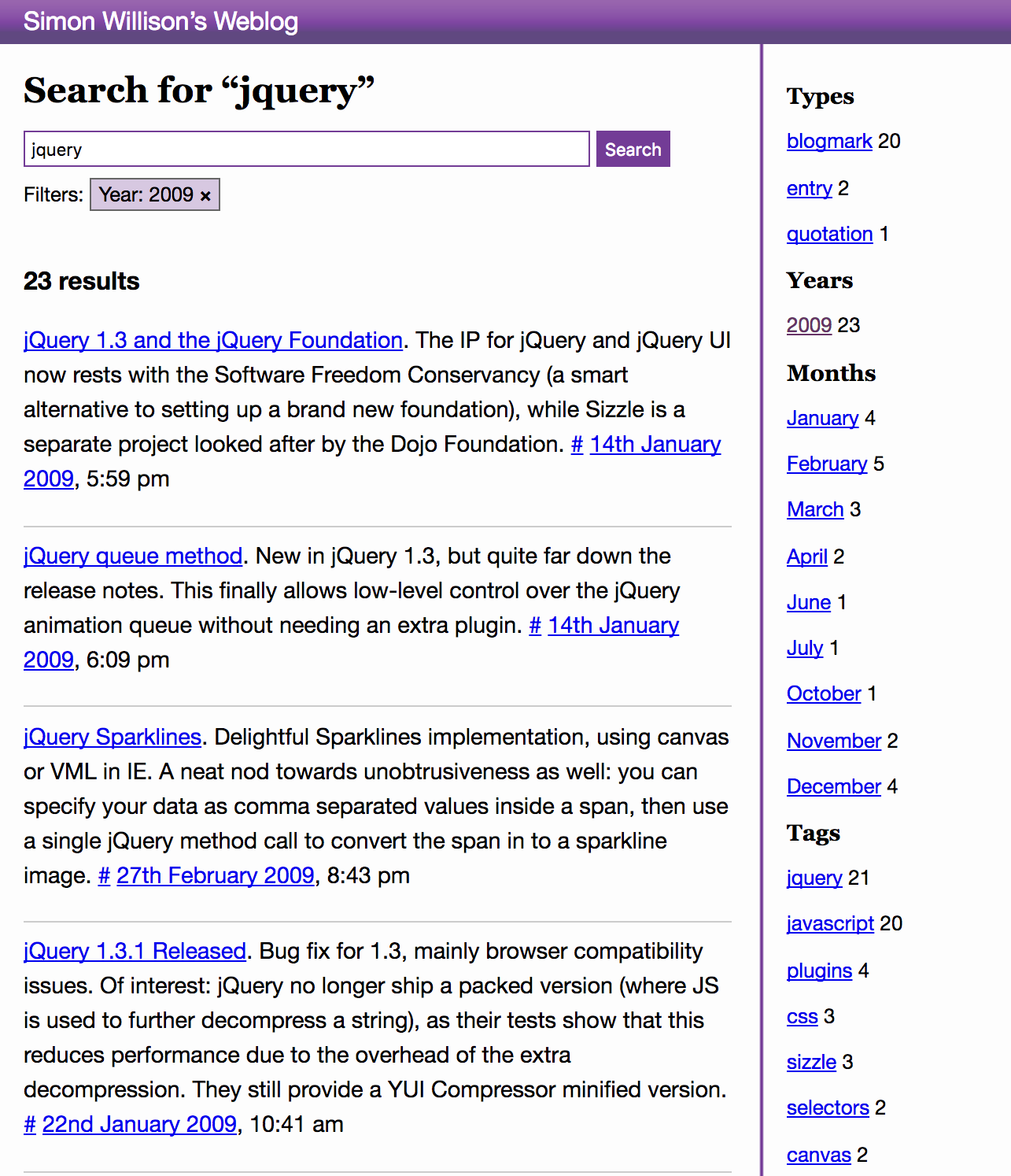
I’ve added a faceted search engine to this blog, powered by PostgreSQL. It supports regular text search (proper search, not just SQL“like” queries), filter by tag, filter by date, filter by content type (entries vs blogmarks vs quotation) and any combination of the above. Some example searches:
[... 3,103 words]2013
Why is site search so bad on most websites?
It’s not so much that site search is bad, it’s that your expectations have been raised enormously high by the incredible quality of search provided by search engines like Google.
[... 125 words]2012
Is there a place or portal where I can search for hashtags which track possible upcoming events or topics?
Our site http://lanyrd.com/ includes hashtags for thousands of upcoming conferences and professional events.
[... 39 words]What are the best events search engines?
Since I co-founded one I’m certainly not qualified to express an opinion on which ones are best, but here are a few of my favourites:
[... 233 words]What kind of publicly available search software is able to be purchased or used freely as part of a website, and how good is it?
There are plenty of good open source options—Solr is currently my favourite. It’s extremely powerful but you do need to do some programming on top of it—I use Django and Haystack to build the search UI on most of my projects.
[... 115 words]2011
Why does Wolfram|Alpha present all search results as pictures rather than text?
Wolfram Alpha is essentially a web interface to Mathematica (plus a huge corpus of structured data). Mathematica has been around for decades, and has an extremely sophisticated visualisation engine (try typing “sin(x)/cos(x)” in to Wolfram Alpha and see what happens). It’s also very good at rendering mathematical formulae that would be very hard to represent in plain HTML (without using MathML, which isn’t supported by IE).
[... 137 words]Twitter API: What is the best data storage mechanism and client library for analysing tweets using Python?
It depends on how much data you intend to collect, and how you intend to then share that data.
[... 182 words]elasticsearch: Percolator. Another fascinating elasticsearch feature: Percolator lets you register searches with your elasticsearch cluster, then pass in a document and have the matching query IDs returned. It’s an upside down search engine. I’m sure there are some very neat things you could build with this, I just haven’t figured out what they are just yet.
2010
Indexing JSON in Solr 3.1. The next release of Solr will support indexing documents provided as JSON—Solr currently requires incoming documents to be formatted as XML.
Who are major competitors to Solr?
ElasticSearch is a really interesting one—it’s the same underlying search library (Lucene) and the same integration model (an HTTP interface) but takes quite a different approach. It hasn’t been around for a long time but it looks very impressive: http://www.elasticsearch.com/
[... 95 words]How do Solr, Lucene, Sphinx and Searchify compare?
Lucene is a Java library for creating and searching through a full text index. If you want to make use of it, you’ll need to write your own Java code that integrates with it.
[... 109 words]Which major companies are using Solr for search?
The Guardian newspaper uses Solr for its Open Platform Content API. http://www.guardian.co.uk/open-p...
[... 27 words][UPDATE] Spatial Search in Apache Lucene and Solr. Spacial search is finally coming (back) to Solr—trunk now supports sorting and boosting by distance.