Building a search engine for datasette.io
19th December 2020
This week I added a search engine to datasette.io, using the search indexing tool I’ve been building for Dogsheep.
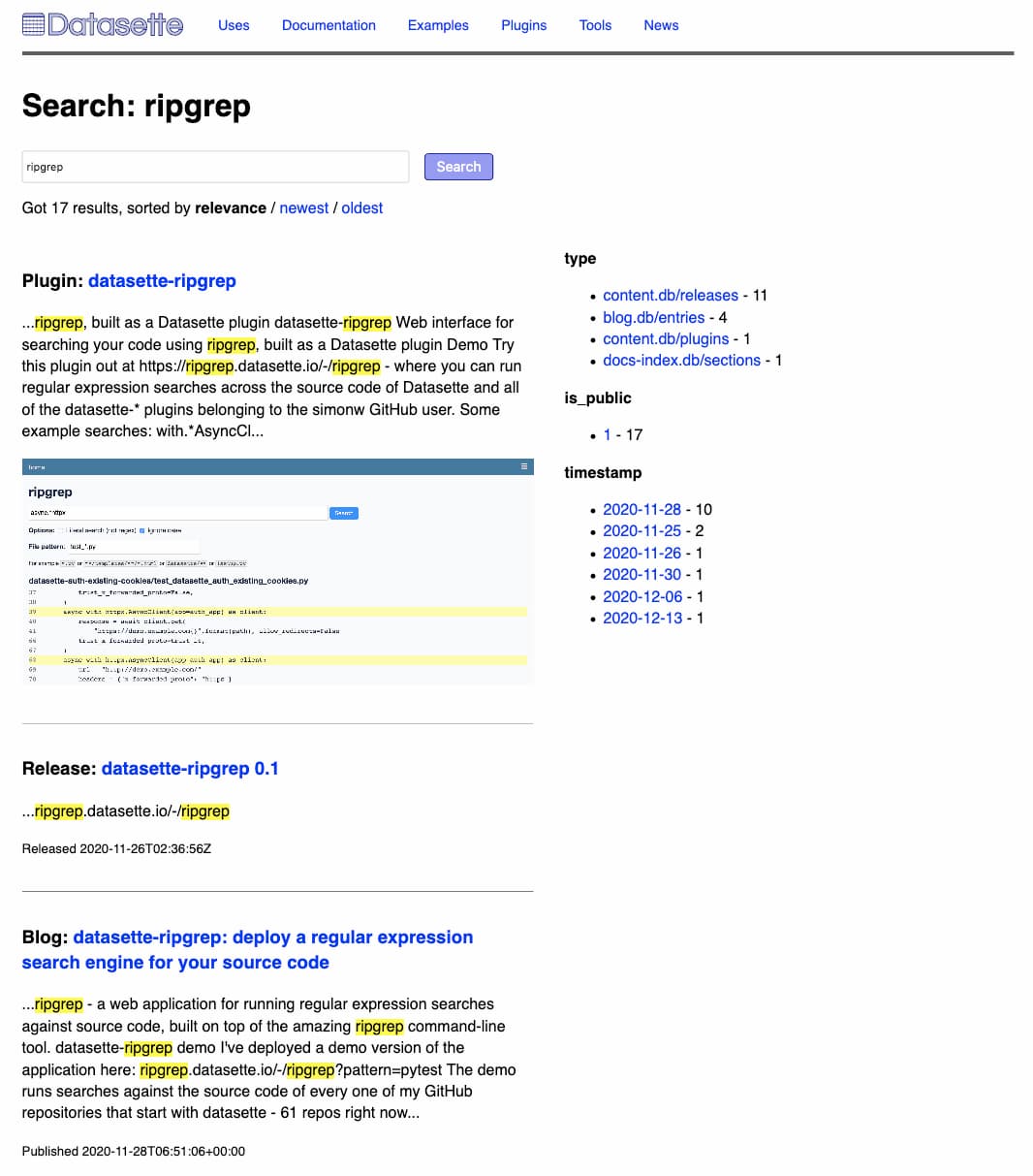
Project search for Datasette
The Datasette project has a lot of constituent parts. There’s the project itself and its documentation—171 pages when exported to PDF and counting. Then there are the 48 plugins, sqlite-utils and 21 more tools for creating SQLite databases, the Dogsheep collection and over three years of content I’ve written about the project on my blog.
The new datasette.io search engine provides a faceted search interface to all of this material in one place. It currently searches across:
- Every section of the latest documentation (415 total)
- 48 plugin READMEs
- 22 tool READMEs
- 63 news items posted on the Datasette website
- 212 items from my blog
- Release notes from 557 package releases
I plan to extend it with more data sources in the future.
How it works: Dogsheep Beta
I’m reusing the search engine I originally built for my Dogsheep personal analytics project (see Personal Data Warehouses: Reclaiming Your Data). I call that search engine Dogsheep Beta. The name is a pun.
SQLite has great full-text search built in, and I make extensive use of that in Datasette projects already. But out of the box it’s not quite right for this kind of search engine that spans multiple different content types.
The problem is relevance calculation. I wrote about this in Exploring search relevance algorithms with SQLite—short version: query relevance is calculated using statistics against the whole corpus, so search terms that occur rarely in the overall corpus contribute a higher score than more common terms.
This means that calculated full-text ranking scores calculated against one table of data cannot be meaningfully compared to scores calculated independently against a separate table, as the corpus statistics used to calculate the rank will differ.
To get usable scores, you need everything in a single table. That’s what Dogsheep Beta does: it creates a new table, called search_index, and copies searchable content from the other tables into that new table.
This is analagous to how an external search index like Elasticsearch works: you store your data in the main database, then periodically update an index in Elasticsearch. It’s the denormalized query engine design pattern in action.
Configuring Dogsheep Beta
There are two components to Dogsheep Beta: a command-line tool for building a search index, and a Datasette plugin for providing an interface for running searches.
Both of these run off a YAML configuration file, which defines the tables that should be indexed and also defines how those search results should be displayed.
(Having one configuration file handle both indexing and display feels a little inelegant, but it’s extremely productive for iterating on so I’m letting that slide.)
Here’s the full Dogsheep configuration for datasette.io. An annotated extract:
# Index material in the content.db SQLite file
content.db:
# Define a search type called 'releases'
releases:
# Populate that search type by executing this SQL
sql: |-
select
releases.id as key,
repos.name || ' ' || releases.tag_name as title,
releases.published_at as timestamp,
releases.body as search_1,
1 as is_public
from
releases
join repos on releases.repo = repos.id
# When displaying a search result, use this SQL to
# return extra details about the item
display_sql: |-
select
-- highlight() is a custom SQL function
highlight(render_markdown(releases.body), :q) as snippet,
html_url
from releases where id = :key
# Jinja template fragment to display the result
display: |-
<h3>Release: <a href="{{ display.html_url }}">{{ title }}</a></h3>
<p>{{ display.snippet|safe }}</p>
<p><small>Released {{ timestamp }}</small></p>The core pattern here is the sql: key, which defines a SQL query that must return the following columns:
-
key—a unique identifier for this search item -
title—a title for this indexed document -
timestamp—a timestamp for when it was created. May be null. -
search_1—text to be searched. I may add support forsearch_2andsearch_3later on to store text that will be treated with a lower relevance score. -
is_public—should this be considered “public” data. This is a holdover from Dogsheep Beta’s application for personal analytics, I don’t actually need it for datasette.io.
To create an index, run the following:
dogsheep-beta index dogsheep-index.db dogsheep-config.yml
The index command will loop through every configured search type in the YAML file, execute the SQL query and use it to populate a search_index table in the dogsheep-index.db SQLite database file.
Here’s the search_index table for datasette.io.
When you run a search, the plugin queries that table and gets back results sorted by relevance (or other sort criteria, if specified).
To display the results, it loops through each one and uses the Jinja template fragment from the configuration file to turn it into HTML.
If a display_sql: query is defined, that query will be executed for each result to populate the {{ display }} object made available to the template. Many Small Queries Are Efficient In SQLite.
Search term highlighting
I spent a bit of time thinking about search highlighting. SQLite has an implementation of highlighting built in—the snippet() function—but it’s not designed to be HTML-aware so there’s a risk it might mangle HTML by adding highlighting marks in the middle of a tag or attribute.
I ended up rolling borrowing a BSD licensed highlighting class from the django-haystack project. It deals with HTML by stripping tags, which seems to be more-or-less what Google do for their own search results so I figured that’s good enough for me.
I used this one-off site plugin to wrap the highlighting code in a custom SQLite function. This meant I could call it from the display_sql: query in the Dogsheep Beta YAML configuration.
A custom template tag would be more elegant, but I don’t yet have a mechanism to expose custom template tags in the Dogsheep Beta rendering mechanism.
Build, index, deploy
The Datasette website implements the Baked Data pattern, where the content is compiled into SQLite database files and bundled with the application code itself as part of the deploy.
Building the index is just another step of that process.
Here’s the deploy.yml GitHub workflow used by the site. It roughly does the following:
- Download the current version of the content.db database file. This is so it doesn’t have to re-fetch release and README content that was previously stored there.
- Download the current version of blog.db, with entries from my blog. This means I don’t have to fetch all entries, just the new ones.
- Run build_directory.py, the script which fetches data for the plugins and tools pages.
- This hits the GitHub GraphQL API to find new repositories tagged
datasette-ioanddatasette-pluginanddatasette-tool. - That GraphQL query also returns the most recent release. The script then checks to see if those releases have previously been fetched and, if not, uses github-to-sqlite to fetch them.
- This hits the GitHub GraphQL API to find new repositories tagged
- Imports the data from news.yaml into a
newstable using yaml-to-sqlite - Imports the latest PyPI download statistics for my packages from my simonw/package-stats repository, which implements git scraping against the most excellent pypistats.org.
- Runs the
dogsheep-beta indexcommand to build adogsheep-index.dbsearch index. - Runs some soundness checks, e.g.
datasette . --get "/plugins", to verify that Datasette is likely to at least return 200 results for some critical pages once published. - Uses
datasette publish cloudrunto deploy the results to Google Cloud Run, which hosts the website.
I love building websites this way. You can have as much complexity as you like in the build script (my TIL website build script generates screenshots using Puppeteer) but the end result is some simple database files running on inexpensive, immutable, scalable hosting.