Weeknotes: Datasette internals
27th December 2020
I’ve been working on some fundamental changes to Datasette’s internal workings—they’re not quite ready for a release yet, but they’re shaping up in an interesting direction.
One of my goals for Datasette is to be able to handle a truly enormous variety of data in one place. The Datasette Library ticket tracks this effort—I’d like a newsroom (or any other information-based organization) to be able to keep hundreds of databases with potentially thousands of tables all in a single place.
SQLite databases are just files on disk, so if you have a TB of assorted databases of all shapes and sizes I’d like to be able to present them in a single Datasette instance.
If you have a hundred database files each with a hundred tables, that’s 10,000 tables total. This implies a need for pagination of the homepage, plus the ability to search and filter within the tables that are available to the Datasette instance.
Sounds like the kind of problem I’d normally solve with Datasette!
So in issue #1150 I’ve implemented the first part of a solution. On startup, Datasette now creates an in-memory SQLite database representing all of the connected databases and tables, plus those tables’ columns, indexes and foreign keys.
For a demo, first sign in as root to the latest.datasette.io demo instance and then visit the private _internal database.
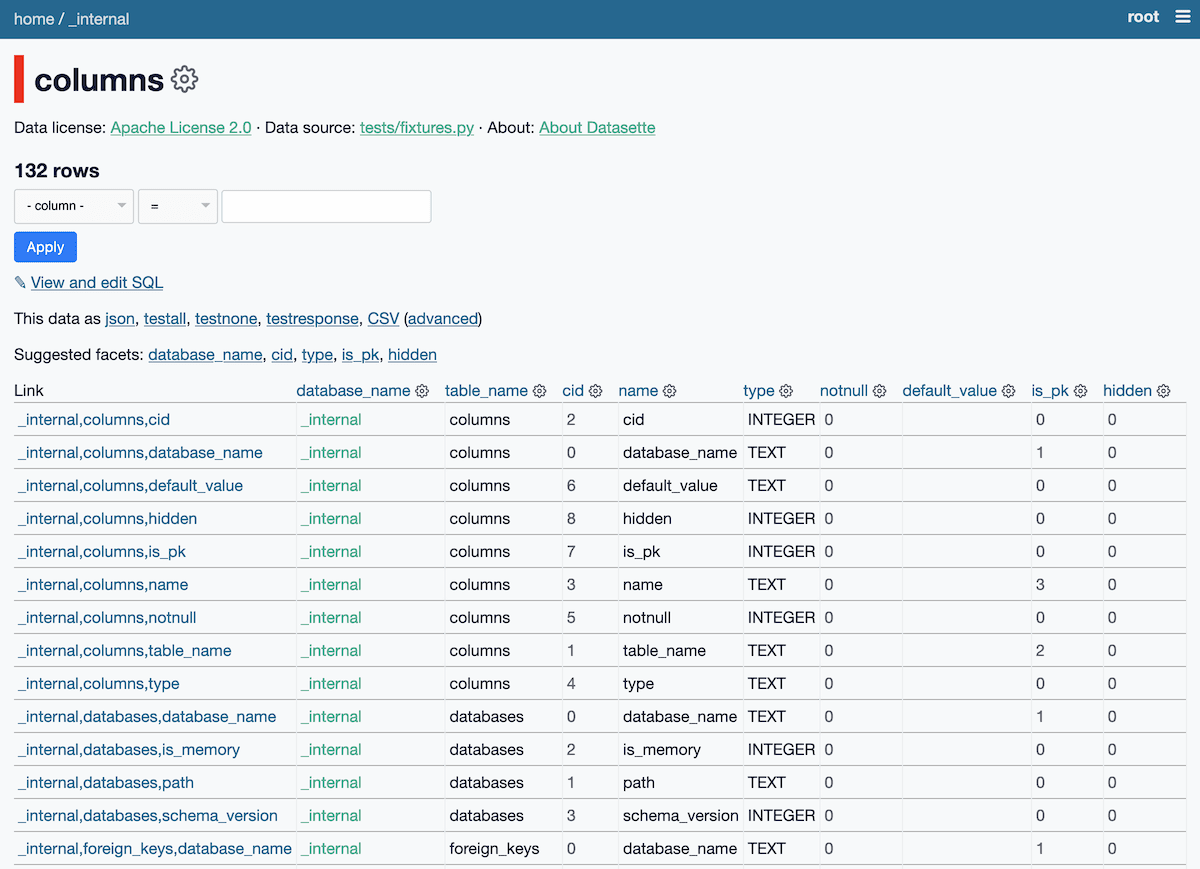
This new internal database is currently private because I don’t want to expose any metadata about tables that may themselves be covered by Datasette’s permissions mechanism.
The new in-memory database represents the schemas of the underlying database files—but what if those change, as new tables are added or modified?
SQLite has a neat trick to help with this: PRAGMA schema_version returns an integer representing the current version of the schema, which changes any time a table is created or modified.
This means I can cache the table schemas and only recalculate them if something has changed. Running PRAGMA schema_version against a connection to a database is an extremely fast query.
I first used this trick in datasette-graphql to cache the results of GraphQL schema introspection, so I’m confident it will work here too.
The problem with permissions
There’s one really gnarly challenge I still need to solve here: permissions.
Datasette’s permissions system, added in Datasette 0.44 back in June, works against plugin hooks. Permissions plugins can answer questions along the lines of "is the current authenticated actor allowed to perform the action view-table against table X?". Every time that question is asked, the plugins are queried via a plugin hook.
When I designed the permissions system I forgot a crucial lesson I’ve learned about permissions systems before: at some point, you’re going to need to answer the question “show me the list of all Xs that this actor has permission to act on”.
That time has now come. If I’m going to render a paginated homepage for Datasette listing 10,000+ tables, I need an efficient way to calculate the subset of those 10,000 tables that the current user is allowed to see.
Looping through and calling that plugin hook 10,000 times isn’t going to cut it.
So I’m starting to rethink permissions a bit—I’m glad I’ve not hit Datasette 1.0 yet!
In my favour is SQLite. Efficiently answering permissions questions in bulk, in a generic, customizable way, is a really hard problem. It’s made a lot easier by the presence of a relational database.
Issue #1152 tracks some of my thinking on this. I have a hunch that the solution is going to involve a new plugin hook, potentially along the lines of “return a fragment of SQL that identifies databases or tables that this user can access”. I can then run that SQL against the new _internal database (potentially combined with SQL returned by other plugins answering the same hook, using an AND or a UNION) to construct a set of tables that the user can access.
If I can do that, and then run the query against an in-memory SQLite database, I should be able to provide a paginated, filtered interface to 10,000+ tables on the homepage that easily fulfills my performance goals.
I’d like to ship the new _internal database in a release quite soon, so I may end up implementing a slower version of this first. It’s definitely an interesting problem.
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026