Implementing faceted search with Django and PostgreSQL
5th October 2017
I’ve added a faceted search engine to this blog, powered by PostgreSQL. It supports regular text search (proper search, not just SQL“like” queries), filter by tag, filter by date, filter by content type (entries vs blogmarks vs quotation) and any combination of the above. Some example searches:
- All content matching “postgresql”
- Just quotations matching “django”
- All content matching “python” and “javascript” with the tag “mozilla” posted in 2007
It also provides facet counts, so you can tell how many results you will get back before you apply one of these filters—and get a general feeling for the shape of the corpus as you navigate it.
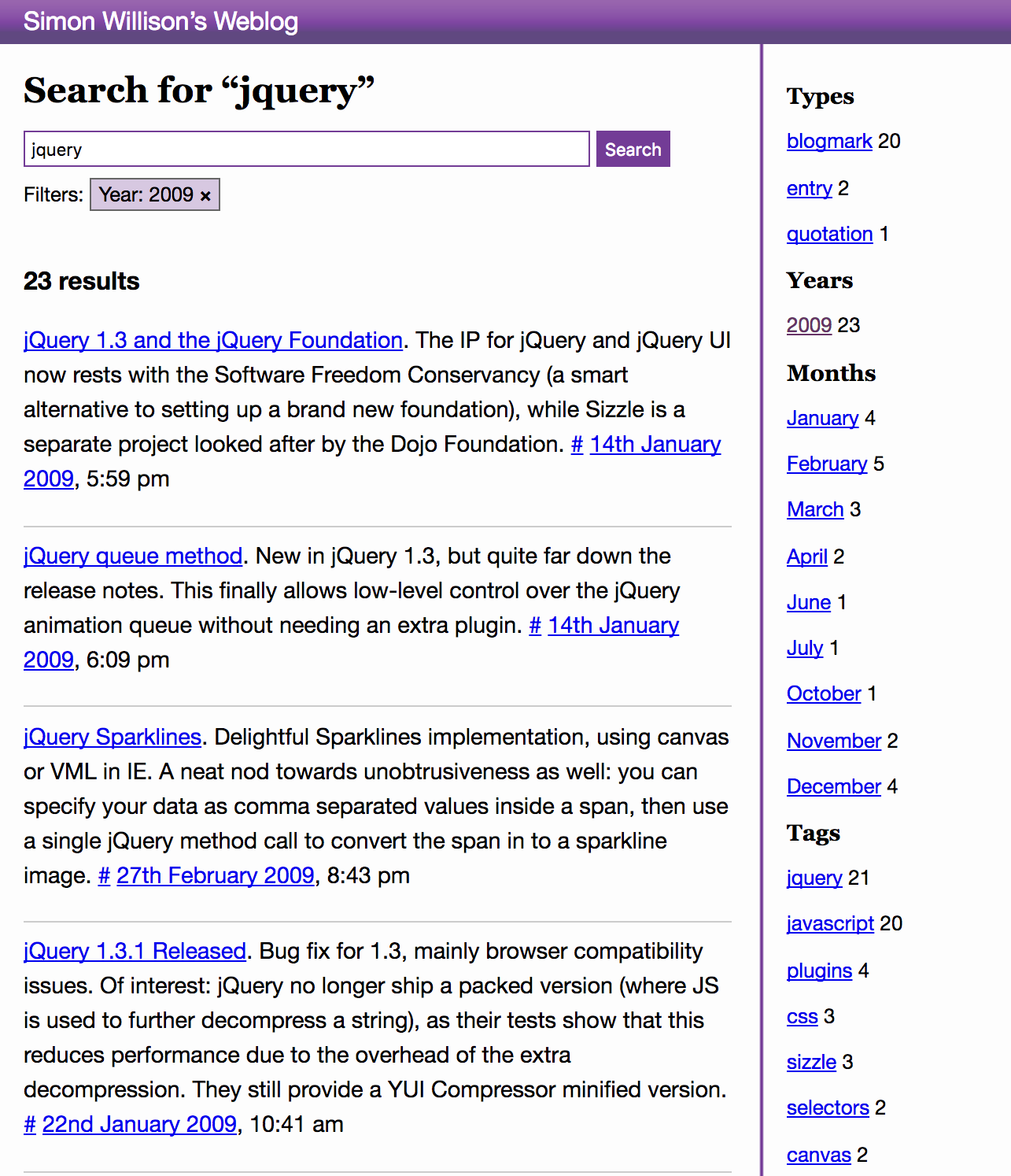
I love this kind of search interface, because the counts tell you so much more about the underlying data. Turns out I was most active in quoting people talking about JavaScript back in 2007, for example.
I usually build faceted search engines using either Solr or Elasticsearch (though the first version of search on this blog was actually powered by Hyper Estraier)—but I’m hosting this blog as simply and inexpensively as possible on Heroku and I don’t want to shell out for a SaaS search solution or run an Elasticsearch instance somewhere myself. I thought I’d have to go back to using Google Custom Search.
Then I read Postgres full-text search is Good Enough! by Rachid Belaid—closely followed by Postgres Full-Text Search With Django by Nathan Shafer—and I decided to have a play with the new PostgreSQL search functionality that was introduced in Django 1.10.
… and wow! Full-text search is yet another example of a feature that’s been in PostgreSQL for nearly a decade now, incrementally improving with every release to the point where it’s now really, really good.
At its most basic level a search system needs to handle four things:
- It needs to take user input and find matching documents.
- It needs to understand and ignore stopwords (common words like “the” and “and”) and apply stemming—knowing that “ridicule” and “ridiculous” should be treated as the same root, for example. Both of these features need to be language-aware.
- It needs to be able to apply relevance ranking, calculating which documents are the best match for a search query.
- It needs to be fast—working against some kind of index rather than scanning every available document in full.
Modern PostgreSQL ticks all of those boxes. Let’s put it to work.
Simple search without an index
Here’s how to execute a full-text search query against a simple text column:
from blog.models import Entry
from django.contrib.postgres.search import SearchVector
results = Entry.objects.annotate(
searchable=SearchVector('body')
).filter(searchable='django')
The generated SQL looks something like this:
SELECT "blog_entry"."id", ...,
to_tsvector(COALESCE("blog_entry"."body", %s)) AS "searchable"
FROM "blog_entry"
WHERE to_tsvector(COALESCE("blog_entry"."body", "django"))
@@ (plainto_tsquery("django")) = true
ORDER BY "blog_entry"."created" DESC
The SearchVector class constructs a stemmed, stopword-removed representation of the body column ready to be searched. The resulting queryset contains entries that are a match for “django”.
My blog entries are stored as HTML, but I don’t want search to include those HTML tags. One (extremely un-performant) solution is to use Django’s Func helper to apply a regular expression inside PostgreSQL to strip tags before they are considered for search:
from django.db.models import Value, F, Func
results = Entry.objects.annotate(
searchable=SearchVector(
Func(
F('body'), Value('<.*?>'), Value(''), Value('g'),
function='regexp_replace'
)
)
).filter(searchable='http')
Update 6th October 8:23pm UTC—it turns out this step is entirely unnecessary. Paolo Melchiorre points out that the PostgreSQL ts_vector() function already handles tag removal. Sure enough, executing SELECT to_tsvector(’<div>Hey look what happens to <blockquote>this tag</blockquote></div>’) using SQL Fiddle returns ’happen’:4 ’hey’:1 ’look’:2 ’tag’:7, with the tags already stripped.
This works, but performance isn’t great. PostgreSQL ends up having to scan every row and construct a list of search vectors for each one every time you execute a query.
If you want it to go fast, you need to add a special search vector column to your table and then create the appropriate index on it. As of Django 1.11 this is trivial:
from django.contrib.postgres.search import SearchVectorField
from django.contrib.postgres.indexes import GinIndex
class Entry(models.Model):
# ...
search_document = SearchVectorField(null=True)
class Meta:
indexes = [
GinIndex(fields=['search_document'])
]
Django’s migration system will automatically add both the field and the special GIN index.
What’s trickier is populating that search_document field. Django does not yet support a easy method to populate it directly in your initial INSERT call, instead recommending that you populated with a SQL UPDATE statement after the fact. Here is a one-liner that will populate the field for everything in that table (and strip tags at the same time):
def strip_tags_func(field):
return Func(
F(field), Value('<.*?>'), Value(''), Value('g'),
function='regexp_replace'
)
Entry.objects.update(
search_document=(
SearchVector('title', weight='A') +
SearchVector(strip_tags_func('body'), weight='C')
)
)
I’m using a neat feature of the SearchVector class here: it can be concatenated together using the + operator, and each component can be assigned a weight of A, B, C or D. These weights affect ranking calculations later on.
Updates using signals
We could just set this up to run periodically (as I did in my initial implementation), but we can get better real-time results by ensuring this field gets updated automatically when the rest of the model is modified. Some people solve this with PostgreSQL triggers, but I’m still more comfortable handling this kind of thing in python code—so I opted to use Django’s signals mechanism instead.
Since I need to run search queries across three different types of blog content—Entries, Blogmarks and Quotations—I added a method to each model that returns the text fragments corresponding to each of the weight values. Here’s that method for my Quotation model:
class Quotation(models.Model):
quotation = models.TextField()
source = models.CharField(max_length=255)
tags = models.ManyToManyField(Tag, blank=True)
def index_components(self):
return {
'A': self.quotation,
'B': ' '.join(self.tags.values_list('tag', flat=True)),
'C': self.source,
}
As you can see, I’m including the tags that have been assigned to the quotation in the searchable document.
Here are my signals—loaded once via an import statement in my blog application’s AppConfig.ready() method:
@receiver(post_save)
def on_save(sender, **kwargs):
if not issubclass(sender, BaseModel):
return
transaction.on_commit(make_updater(kwargs['instance']))
@receiver(m2m_changed)
def on_m2m_changed(sender, **kwargs):
instance = kwargs['instance']
model = kwargs['model']
if model is Tag:
transaction.on_commit(make_updater(instance))
elif isinstance(instance, Tag):
for obj in model.objects.filter(pk__in=kwargs['pk_set']):
transaction.on_commit(make_updater(obj))
def make_updater(instance):
components = instance.index_components()
pk = instance.pk
def on_commit():
search_vectors = []
for weight, text in components.items():
search_vectors.append(
SearchVector(Value(text, output_field=models.TextField()), weight=weight)
)
instance.__class__.objects.filter(pk=pk).update(
search_document=reduce(operator.add, search_vectors)
)
return on_commit
(The full code can be found here).
The on_save method is pretty straightforward—it checks if the model that was just saved has my BaseModel as a base class, then it calls make_updater to get a function to be executed by the transaction.on_commit hook.
The on_m2m_changed handler is significantly more complicated. There are a number of scenarios in which this will be called—I’m reasonably confident that the idiom I use here will capture all of the modifications that should trigger a re-indexing operation.
Running a search now looks like this:
results = Entry.objects.filter(
search_document=SearchQuery('django')
)
We need one more thing though: we need to sort our search results by relevance. PostgreSQL has pretty good relevance built in, and sorting by the relevance score can be done by applying a Django ORM annotation:
query = SearchQuery('ibm')
results = Entry.objects.filter(
search_document=query
).annotate(
rank=SearchRank(F('search_document'), query)
).order_by('-rank')
We now have basic full text search implemented against a single Django model, making use of a GIN index. This is lightning fast.
Searching multiple tables using queryset.union()
My site has three types of content, represented in three different models and hence three different underlying database tables.
I’m using an abstract base model to define common fields shared by all three: the created date, the slug (used to construct permalink urls) and the search_document field populated above.
As of Django 1.11 It’s possible to combine queries across different tables using the SQL union operator.
Here’s what that looks like for running a search across three tables, all with the same search_document search vector field. I need to use .values() to restrict the querysets I am unioning to the same subset of fields:
query = SearchQuery('django')
rank_annotation = SearchRank(F('search_document'), query)
qs = Blogmark.objects.annotate(
rank=rank_annotation,
).filter(
search_document=query
).values('pk', 'created', 'rank').union(
Entry.objects.annotate(
rank=rank_annotation,
).filter(
search_document=query
).values('pk', 'created', 'rank'),
Quotation.objects.annotate(
rank=rank_annotation,
).filter(
search_document=query
).values('pk', 'created', 'rank'),
).order_by('-rank')[:5]
# Output
<QuerySet [
{'pk': 186, 'rank': 0.875179, 'created': datetime.datetime(2008, 4, 8, 13, 48, 18, tzinfo=<UTC>)},
{'pk': 134, 'rank': 0.842655, 'created': datetime.datetime(2007, 10, 20, 13, 46, 56, tzinfo=<UTC>)},
{'pk': 1591, 'rank': 0.804502, 'created': datetime.datetime(2009, 9, 28, 23, 32, 4, tzinfo=<UTC>)},
{'pk': 5093, 'rank': 0.788616, 'created': datetime.datetime(2010, 2, 26, 19, 22, 47, tzinfo=<UTC>)},
{'pk': 2598, 'rank': 0.786928, 'created': datetime.datetime(2007, 1, 26, 12, 38, 46, tzinfo=<UTC>)}
]>
This is not enough information though—I have the primary keys, but I don’t know which type of model they belong to. In order to retrieve the actual resulting objects from the database I need to know which type of content is represented by each of those results.
I can achieve that using another annotation:
qs = Blogmark.objects.annotate(
rank=rank_annotation,
type=models.Value('blogmark', output_field=models.CharField())
).filter(
search_document=query
).values('pk', 'type', 'rank').union(
Entry.objects.annotate(
rank=rank_annotation,
type=models.Value('entry', output_field=models.CharField())
).filter(
search_document=query
).values('pk', 'type', 'rank'),
Quotation.objects.annotate(
rank=rank_annotation,
type=models.Value('quotation', output_field=models.CharField())
).filter(
search_document=query
).values('pk', 'type', 'rank'),
).order_by('-rank')[:5]
# Output:
<QuerySet [
{'pk': 186, 'type': u'quotation', 'rank': 0.875179},
{'pk': 134, 'type': u'quotation', 'rank': 0.842655},
{'pk': 1591, 'type': u'entry', 'rank': 0.804502},
{'pk': 5093, 'type': u'blogmark', 'rank': 0.788616},
{'pk': 2598, 'type': u'blogmark', 'rank': 0.786928}
]>
Now I just need to write function which can take a list of types and primary keys and return the full objects from the database:
def load_mixed_objects(dicts):
"""
Takes a list of dictionaries, each of which must at least have a 'type'
and a 'pk' key. Returns a list of ORM objects of those various types.
Each returned ORM object has a .original_dict attribute populated.
"""
to_fetch = {}
for d in dicts:
to_fetch.setdefault(d['type'], set()).add(d['pk'])
fetched = {}
for key, model in (
('blogmark', Blogmark),
('entry', Entry),
('quotation', Quotation),
):
ids = to_fetch.get(key) or []
objects = model.objects.prefetch_related('tags').filter(pk__in=ids)
for obj in objects:
fetched[(key, obj.pk)] = obj
# Build list in same order as dicts argument
to_return = []
for d in dicts:
item = fetched.get((d['type'], d['pk'])) or None
if item:
item.original_dict = d
to_return.append(item)
return to_return
One last challenge: when I add filtering by type, I’m going to want to selectively union together only a subset of these querysets. I need a queryset to start unions against, but I don’t yet know which queryset I will be using. I can abuse Django’s queryset.none() method to crate an empty ValuesQuerySet in the correct shape like this
qs = Entry.objects.annotate(
type=models.Value('empty', output_field=models.CharField()),
rank=rank_annotation
).values('pk', 'type', 'rank').none()
Now I can progressively build up my union in a loop like this:
for klass in (Entry, Blogmark, Quotation):
qs = qs.union(klass.objects.annotate(
rank=rank_annotation,
type=models.Value('quotation', output_field=models.CharField())
).filter(
search_document=query
).values('pk', 'type', 'rank'))
The Django ORM is smart enough to compile away the empty queryset when it constructs the SQL, which ends up looking something like this:
(((SELECT "blog_entry"."id",
"entry" AS "type",
ts_rank("blog_entry"."search_document", plainto_tsquery(%s)) AS "rank"
FROM "blog_entry"
WHERE "blog_entry"."search_document" @@ (plainto_tsquery(%s)) = TRUE
ORDER BY "blog_entry"."created" DESC))
UNION
(SELECT "blog_blogmark"."id",
"blogmark" AS "type",
ts_rank("blog_blogmark"."search_document", plainto_tsquery(%s)) AS "rank"
FROM "blog_blogmark"
WHERE "blog_blogmark"."search_document" @@ (plainto_tsquery(%s)) = TRUE
ORDER BY "blog_blogmark"."created" DESC))
UNION
(SELECT "blog_quotation"."id",
"quotation" AS "type",
ts_rank("blog_quotation"."search_document", plainto_tsquery(%s)) AS "rank"
FROM "blog_quotation"
WHERE "blog_quotation"."search_document" @@ (plainto_tsquery(%s)) = TRUE
ORDER BY "blog_quotation"."created" DESC)
Applying filters
So far, our search engine can only handle user-entered query strings. If I am going to build a faceted search interface I need to be able to handle filtering as well. I want the ability to filter by year, tag and type.
The key difference between filtering and querying (borrowing these definitions from Elasticsearch) is that querying is loose—it involves stemming and stopwords—while filtering is exact. Additionally, querying affects the calculated relevance score while filtering does not—a document either matches the filter or it doesn’t.
Since PostgreSQL is a relational database, filtering can be handled by simply constructing extra SQL where clauses using the Django ORM.
Each of the filters I need requires a slightly different approach. Filtering by type is easy—I just selectively include or exclude that model from my union queryset.
Year and month work like this:
selected_year = request.GET.get('year', '')
selected_month = request.GET.get('month', '')
if selected_year:
qs = qs.filter(created__year=int(selected_year))
if selected_month:
qs = qs.filter(created__month=int(selected_month))
Tags involve a join through a many-2-many relationship against the Tags table. We want to be able to apply more than one tag, for example this search for all items tagged both python and javascript. Django’s ORM makes this easy:
selected_tags = request.GET.getlist('tag')
for tag in selected_tags:
qs = qs.filter(tags__tag=tag)
Adding facet counts
There is just one more ingredient needed to complete our faceted search: facet counts!
Again, the way we calculate these is different for each of our filters. For types, we need to call .count() on a separate queryset for each of the types we are searching:
queryset = make_queryset(Entry, 'entry')
type_counts['entry'] = queryset.count()
(the make_queryset function is defined here)
For years we can do this:
from django.db.models.functions import TruncYear
for row in queryset.order_by().annotate(
year=TruncYear('created')
).values('year').annotate(n=models.Count('pk')):
year_counts[row['year']] = year_counts.get(
row['year'], 0
) + row['n']
Tags are trickiest. Let’s take advantage of he fact that Django’s ORM knows how to construct sub-selects if you pass another queryset to the __in operator.
tag_counts = {}
type_name = 'entry'
queryset = make_queryset(Entry, 'entry')
for tag, count in Tag.objects.filter(**{
'%s__in' % type_name: queryset
}).annotate(
n=models.Count('tag')
).values_list('tag', 'n'):
tag_counts[tag] = tag_counts.get(tag, 0) + count
Rendering it all in a template
Having constructed the various facets counts in the view function, the template is really simple:
{% if type_counts %}
<h3>Types</h3>
<ul>
{% for t in type_counts %}
<li><a href="{% add_qsarg "type" t.type %}">{{ t.type }}</a> {{ t.n }}</a></li>
{% endfor %}
</ul>
{% endif %}
{% if year_counts %}
<h3>Years</h3>
<ul>
{% for t in year_counts %}
<li><a href="{% add_qsarg "year" t.year|date:"Y" %}">{{ t.year|date:"Y" }}</a> {{ t.n }}</a></li>
{% endfor %}
</ul>
{% endif %}
{% if tag_counts %}
<h3>Tags</h3>
<ul>
{% for t in tag_counts %}
<li><a href="{% add_qsarg "tag" t.tag %}">{{ t.tag }}</a> {{ t.n }}</a></li>
{% endfor %}
</ul>
{% endif %}
I am using custom templates tags here to add arguments to the current URL. I’ve built systems like this in the past where the URLs are instead generated in the view logic, which I think I prefer. As always, perfect is the enemy of shipped.
And because the results are just a Django queryset, we can use Django’s pagination helpers for the pagination links.
The final implementation
The full current version of the code at time of writing can be seen here. You can follow my initial implementation of this feature through the following commits: 7e3a0217 c7e7b30c 7f6b524c a16ddb5e 7055c7e1 74c194d9 f3ffc100 6c24d9fd cb88c2d4 2c262c75 776a562a b8484c50 0b361c78 1322ada2 79b1b13d 3955f41b 3f5ca052.
And that’s how I built faceted search on top of PostgreSQL and Django! I don’t have my blog comments up and running yet, so please post any thoughts or feedback over on this GitHub issue or over on this thread on Hacker News.
Update 9th September 2021: A few years after implementing this I started to notice performance issues with my blog, which turned out to be caused by search engine crawlers hitting every possible combination of facets, triggering a ton of expensive SQL queries. I excluded /search from being crawled using robots.txt which fixed the problem.
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026