616 posts tagged “llm”
LLM is my command-line tool for running prompts against Large Language Models.
2025
Gemini 3 Flash

It continues to be a busy December, if not quite as busy as last year. Today’s big news is Gemini 3 Flash, the latest in Google’s “Flash” line of faster and less expensive models.
[... 1,271 words]LLM 0.28. I released a new version of my LLM Python library and CLI tool for interacting with Large Language Models. Highlights from the release notes:
- New OpenAI models:
gpt-5.1,gpt-5.1-chat-latest,gpt-5.2andgpt-5.2-chat-latest. #1300, #1317- When fetching URLs as fragments using
llm -f URL, the request now includes a custom user-agent header:llm/VERSION (https://llm.datasette.io/). #1309- Fixed a bug where fragments were not correctly registered with their source when using
llm chat. Thanks, Giuseppe Rota. #1316- Fixed some file descriptor leak warnings. Thanks, Eric Bloch. #1313
- Type annotations for the OpenAI Chat, AsyncChat and Completion
execute()methods. Thanks, Arjan Mossel. #1315- The project now uses
uvand dependency groups for development. See the updated contributing documentation. #1318
That last bullet point about uv relates to the dependency groups pattern I wrote about in a recent TIL. I'm currently working through applying it to my other projects - the net result is that running the test suite is as simple as doing:
git clone https://github.com/simonw/llm
cd llm
uv run pytest
The new dev dependency group defined in pyproject.toml is automatically installed by uv run in a new virtual environment which means everything needed to run pytest is available without needing to add any extra commands.
GPT-5.2

OpenAI reportedly declared a “code red” on the 1st of December in response to increasingly credible competition from the likes of Google’s Gemini 3. It’s less than two weeks later and they just announced GPT-5.2, calling it “the most capable model series yet for professional knowledge work”.
[... 964 words]Devstral 2. Two new models from Mistral today: Devstral 2 and Devstral Small 2 - both focused on powering coding agents such as Mistral's newly released Mistral Vibe which I wrote about earlier today.
- Devstral 2: SOTA open model for code agents with a fraction of the parameters of its competitors and achieving 72.2% on SWE-bench Verified.
- Up to 7x more cost-efficient than Claude Sonnet at real-world tasks.
Devstral 2 is a 123B model released under a janky license - it's "modified MIT" where the modification is:
You are not authorized to exercise any rights under this license if the global consolidated monthly revenue of your company (or that of your employer) exceeds $20 million (or its equivalent in another currency) for the preceding month. This restriction in (b) applies to the Model and any derivatives, modifications, or combined works based on it, whether provided by Mistral AI or by a third party. [...]
Mistral Small 2 is under a proper Apache 2 license with no weird strings attached. It's a 24B model which is 51.6GB on Hugging Face and should quantize to significantly less.
I tried out the larger model via my llm-mistral plugin like this:
llm install llm-mistral
llm mistral refresh
llm -m mistral/devstral-2512 "Generate an SVG of a pelican riding a bicycle"

For a ~120B model that one is pretty good!
Here's the same prompt with -m mistral/labs-devstral-small-2512 for the API hosted version of Devstral Small 2:

Again, a decent result given the small parameter size. For comparison, here's what I got for the 24B Mistral Small 3.2 earlier this year.
Introducing Mistral 3. Four new models from Mistral today: three in their "Ministral" smaller model series (14B, 8B, and 3B) and a new Mistral Large 3 MoE model with 675B parameters, 41B active.
All of the models are vision capable, and they are all released under an Apache 2 license.
I'm particularly excited about the 3B model, which appears to be a competent vision-capable model in a tiny ~3GB file.
Xenova from Hugging Face got it working in a browser:
@MistralAI releases Mistral 3, a family of multimodal models, including three start-of-the-art dense models (3B, 8B, and 14B) and Mistral Large 3 (675B, 41B active). All Apache 2.0! 🤗
Surprisingly, the 3B is small enough to run 100% locally in your browser on WebGPU! 🤯
You can try that demo in your browser, which will fetch 3GB of model and then stream from your webcam and let you run text prompts against what the model is seeing, entirely locally.

Mistral's API hosted versions of the new models are supported by my llm-mistral plugin already thanks to the llm mistral refresh command:
$ llm mistral refresh
Added models: ministral-3b-2512, ministral-14b-latest, mistral-large-2512, ministral-14b-2512, ministral-8b-2512
I tried pelicans against all of the models. Here's the best one, from Mistral Large 3:

And the worst from Ministral 3B:

llm-anthropic 0.23.
New plugin release adding support for Claude Opus 4.5, including the new thinking_effort option:
llm install -U llm-anthropic
llm -m claude-opus-4.5 -o thinking_effort low 'muse on pelicans'
This took longer to release than I had hoped because it was blocked on Anthropic shipping 0.75.0 of their Python library with support for thinking effort.
llm-gemini 0.27. New release of my LLM plugin for Google's Gemini models:
- Support for nested schemas in Pydantic, thanks Bill Pugh. #107
- Now tests against Python 3.14.
- Support for YouTube URLs as attachments and the
media_resolutionoption. Thanks, Duane Milne. #112- New model:
gemini-3-pro-preview. #113
The YouTube URL feature is particularly neat, taking advantage of this API feature. I used it against the Google Antigravity launch video:
llm -m gemini-3-pro-preview \
-a 'https://www.youtube.com/watch?v=nTOVIGsqCuY' \
'Summary, with detailed notes about what this thing is and how it differs from regular VS Code, then a complete detailed transcript with timestamps'
Here's the result. A spot-check of the timestamps against points in the video shows them to be exactly right.
Trying out Gemini 3 Pro with audio transcription and a new pelican benchmark

Google released Gemini 3 Pro today. Here’s the announcement from Sundar Pichai, Demis Hassabis, and Koray Kavukcuoglu, their developer blog announcement from Logan Kilpatrick, the Gemini 3 Pro Model Card, and their collection of 11 more articles. It’s a big release!
[... 2,476 words]llm-anthropic 0.22.
New release of my llm-anthropic plugin:
- Support for Claude's new structured outputs feature for Sonnet 4.5 and Opus 4.1. #54
- Support for the web search tool using
-o web_search 1- thanks Nick Powell and Ian Langworth. #30
The plugin previously powered LLM schemas using this tool-call based workaround. That code is still used for Anthropic's older models.
I also figured out uv recipes for running the plugin's test suite in an isolated environment, which are now baked into the new Justfile.
Introducing GPT-5.1 for developers. OpenAI announced GPT-5.1 yesterday, calling it a smarter, more conversational ChatGPT. Today they've added it to their API.
We actually got four new models today:
There are a lot of details to absorb here.
GPT-5.1 introduces a new reasoning effort called "none" (previous were minimal, low, medium, and high) - and none is the new default.
This makes the model behave like a non-reasoning model for latency-sensitive use cases, with the high intelligence of GPT‑5.1 and added bonus of performant tool-calling. Relative to GPT‑5 with 'minimal' reasoning, GPT‑5.1 with no reasoning is better at parallel tool calling (which itself increases end-to-end task completion speed), coding tasks, following instructions, and using search tools---and supports web search in our API platform.
When you DO enable thinking you get to benefit from a new feature called "adaptive reasoning":
On straightforward tasks, GPT‑5.1 spends fewer tokens thinking, enabling snappier product experiences and lower token bills. On difficult tasks that require extra thinking, GPT‑5.1 remains persistent, exploring options and checking its work in order to maximize reliability.
Another notable new feature for 5.1 is extended prompt cache retention:
Extended prompt cache retention keeps cached prefixes active for longer, up to a maximum of 24 hours. Extended Prompt Caching works by offloading the key/value tensors to GPU-local storage when memory is full, significantly increasing the storage capacity available for caching.
To enable this set "prompt_cache_retention": "24h" in the API call. Weirdly there's no price increase involved with this at all. I asked about that and OpenAI's Steven Heidel replied:
with 24h prompt caching we move the caches from gpu memory to gpu-local storage. that storage is not free, but we made it free since it moves capacity from a limited resource (GPUs) to a more abundant resource (storage). then we can serve more traffic overall!
The most interesting documentation I've seen so far is in the new 5.1 cookbook, which also includes details of the new shell and apply_patch built-in tools. The apply_patch.py implementation is worth a look, especially if you're interested in the advancing state-of-the-art of file editing tools for LLMs.
I'm still working on integrating the new models into LLM. The Codex models are Responses-API-only.
I got this pelican for GPT-5.1 default (no thinking):

And this one with reasoning effort set to high:

These actually feel like a regression from GPT-5 to me. The bicycles have less spokes!
Kimi K2 Thinking. Chinese AI lab Moonshot's Kimi K2 established itself as one of the largest open weight models - 1 trillion parameters - back in July. They've now released the Thinking version, also a trillion parameters (MoE, 32B active) and also under their custom modified (so not quite open source) MIT license.
Starting with Kimi K2, we built it as a thinking agent that reasons step-by-step while dynamically invoking tools. It sets a new state-of-the-art on Humanity's Last Exam (HLE), BrowseComp, and other benchmarks by dramatically scaling multi-step reasoning depth and maintaining stable tool-use across 200–300 sequential calls. At the same time, K2 Thinking is a native INT4 quantization model with 256k context window, achieving lossless reductions in inference latency and GPU memory usage.
This one is only 594GB on Hugging Face - Kimi K2 was 1.03TB - which I think is due to the new INT4 quantization. This makes the model both cheaper and faster to host.
So far the only people hosting it are Moonshot themselves. I tried it out both via their own API and via the OpenRouter proxy to it, via the llm-moonshot plugin (by NickMystic) and my llm-openrouter plugin respectively.
The buzz around this model so far is very positive. Could this be the first open weight model that's competitive with the latest from OpenAI and Anthropic, especially for long-running agentic tool call sequences?
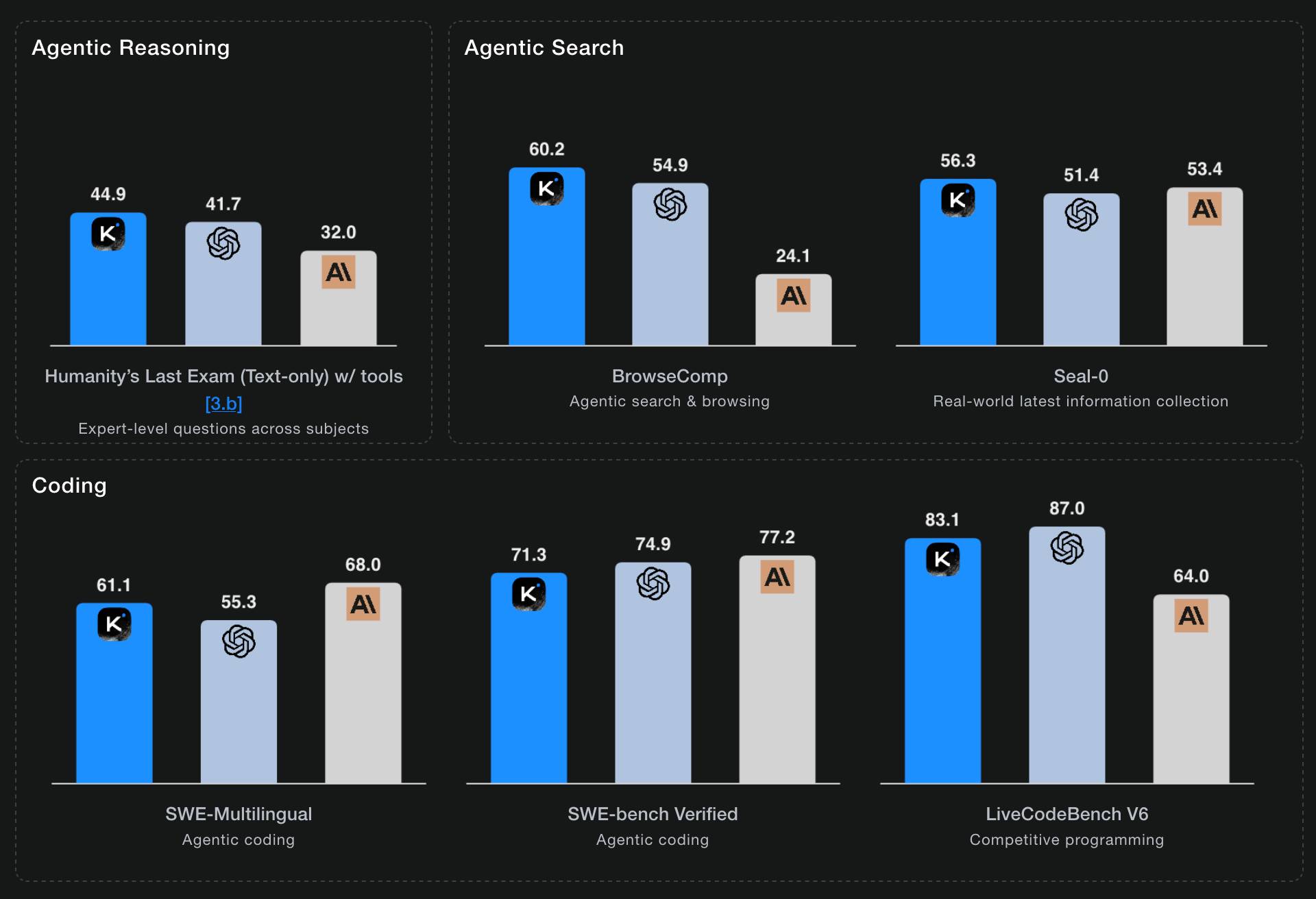
Moonshot AI's self-reported benchmark scores show K2 Thinking beating the top OpenAI and Anthropic models (GPT-5 and Sonnet 4.5 Thinking) at "Agentic Reasoning" and "Agentic Search" but not quite top for "Coding":
I ran a couple of pelican tests:
llm install llm-moonshot
llm keys set moonshot # paste key
llm -m moonshot/kimi-k2-thinking 'Generate an SVG of a pelican riding a bicycle'

llm install llm-openrouter
llm keys set openrouter # paste key
llm -m openrouter/moonshotai/kimi-k2-thinking \
'Generate an SVG of a pelican riding a bicycle'
Artificial Analysis said:
Kimi K2 Thinking achieves 93% in 𝜏²-Bench Telecom, an agentic tool use benchmark where the model acts as a customer service agent. This is the highest score we have independently measured. Tool use in long horizon agentic contexts was a strength of Kimi K2 Instruct and it appears this new Thinking variant makes substantial gains
CNBC quoted a source who provided the training price for the model:
The Kimi K2 Thinking model cost $4.6 million to train, according to a source familiar with the matter. [...] CNBC was unable to independently verify the DeepSeek or Kimi figures.
MLX developer Awni Hannun got it working on two 512GB M3 Ultra Mac Studios:
The new 1 Trillion parameter Kimi K2 Thinking model runs well on 2 M3 Ultras in its native format - no loss in quality!
The model was quantization aware trained (qat) at int4.
Here it generated ~3500 tokens at 15 toks/sec using pipeline-parallelism in mlx-lm
Here's the 658GB mlx-community model.
MiniMax M2 & Agent: Ingenious in Simplicity. MiniMax M2 was released on Monday 27th October by MiniMax, a Chinese AI lab founded in December 2021.
It's a very promising model. Their self-reported benchmark scores show it as comparable to Claude Sonnet 4, and Artificial Analysis are ranking it as the best currently available open weight model according to their intelligence score:
MiniMax’s M2 achieves a new all-time-high Intelligence Index score for an open weights model and offers impressive efficiency with only 10B active parameters (200B total). [...]
The model’s strengths include tool use and instruction following (as shown by Tau2 Bench and IFBench). As such, while M2 likely excels at agentic use cases it may underperform other open weights leaders such as DeepSeek V3.2 and Qwen3 235B at some generalist tasks. This is in line with a number of recent open weights model releases from Chinese AI labs which focus on agentic capabilities, likely pointing to a heavy post-training emphasis on RL.
The size is particularly significant: the model weights are 230GB on Hugging Face, significantly smaller than other high performing open weight models. That's small enough to run on a 256GB Mac Studio, and the MLX community have that working already.
MiniMax offer their own API, and recommend using their Anthropic-compatible endpoint and the official Anthropic SDKs to access it. MiniMax Head of Engineering Skyler Miao provided some background on that:
M2 is a agentic thinking model, it do interleaved thinking like sonnet 4.5, which means every response will contain its thought content. Its very important for M2 to keep the chain of thought. So we must make sure the history thought passed back to the model. Anthropic API support it for sure, as sonnet needs it as well. OpenAI only support it in their new Response API, no support for in ChatCompletion.
MiniMax are offering the new model via their API for free until November 7th, after which the cost will be $0.30/million input tokens and $1.20/million output tokens - similar in price to Gemini 2.5 Flash and GPT-5 Mini, see price comparison here on my llm-prices.com site.
I released a new plugin for LLM called llm-minimax providing support for M2 via the MiniMax API:
llm install llm-minimax
llm keys set minimax
# Paste key here
llm -m m2 -o max_tokens 10000 "Generate an SVG of a pelican riding a bicycle"
Here's the result:

51 input, 4,017 output. At $0.30/m input and $1.20/m output that pelican would cost 0.4836 cents - less than half a cent.
This is the first plugin I've written for an Anthropic-API-compatible model. I released llm-anthropic 0.21 first adding the ability to customize the base_url parameter when using that model class. This meant the new plugin was less than 30 lines of Python.
Introducing Claude Haiku 4.5 (via) Anthropic released Claude Haiku 4.5 today, the cheapest member of the Claude 4.5 family that started with Sonnet 4.5 a couple of weeks ago.
It's priced at $1/million input tokens and $5/million output tokens, slightly more expensive than Haiku 3.5 ($0.80/$4) and a lot more expensive than the original Claude 3 Haiku ($0.25/$1.25), both of which remain available at those prices.
It's a third of the price of Sonnet 4 and Sonnet 4.5 (both $3/$15) which is notable because Anthropic's benchmarks put it in a similar space to that older Sonnet 4 model. As they put it:
What was recently at the frontier is now cheaper and faster. Five months ago, Claude Sonnet 4 was a state-of-the-art model. Today, Claude Haiku 4.5 gives you similar levels of coding performance but at one-third the cost and more than twice the speed.
I've been hoping to see Anthropic release a fast, inexpensive model that's price competitive with the cheapest models from OpenAI and Gemini, currently $0.05/$0.40 (GPT-5-Nano) and $0.075/$0.30 (Gemini 2.0 Flash Lite). Haiku 4.5 certainly isn't that, it looks like they're continuing to focus squarely on the "great at code" part of the market.
The new Haiku is the first Haiku model to support reasoning. It sports a 200,000 token context window, 64,000 maximum output (up from just 8,192 for Haiku 3.5) and a "reliable knowledge cutoff" of February 2025, one month later than the January 2025 date for Sonnet 4 and 4.5 and Opus 4 and 4.1.
Something that caught my eye in the accompanying system card was this note about context length:
For Claude Haiku 4.5, we trained the model to be explicitly context-aware, with precise information about how much context-window has been used. This has two effects: the model learns when and how to wrap up its answer when the limit is approaching, and the model learns to continue reasoning more persistently when the limit is further away. We found this intervention—along with others—to be effective at limiting agentic “laziness” (the phenomenon where models stop working on a problem prematurely, give incomplete answers, or cut corners on tasks).
I've added the new price to llm-prices.com, released llm-anthropic 0.20 with the new model and updated my Haiku-from-your-webcam demo (source) to use Haiku 4.5 as well.
Here's llm -m claude-haiku-4.5 'Generate an SVG of a pelican riding a bicycle' (transcript).

18 input tokens and 1513 output tokens = 0.7583 cents.