606 posts tagged “llm”
LLM is my command-line tool for running prompts against Large Language Models.
2026
Almost entirely written by the new Claude Fable 5, see my write-up for more details.
- New model: Claude Opus 4.8 (
claude-opus-4.8).- New
-o fast 1option for fast mode, for organizations with that feature enabled on their account.- Default max_tokens for each model now defaults to that model's maximum output rather than 8,192. #72
See also my notes on Opus 4.8 - I used this new release of llm-anthropic to generate the pelicans.
Datasette Agent
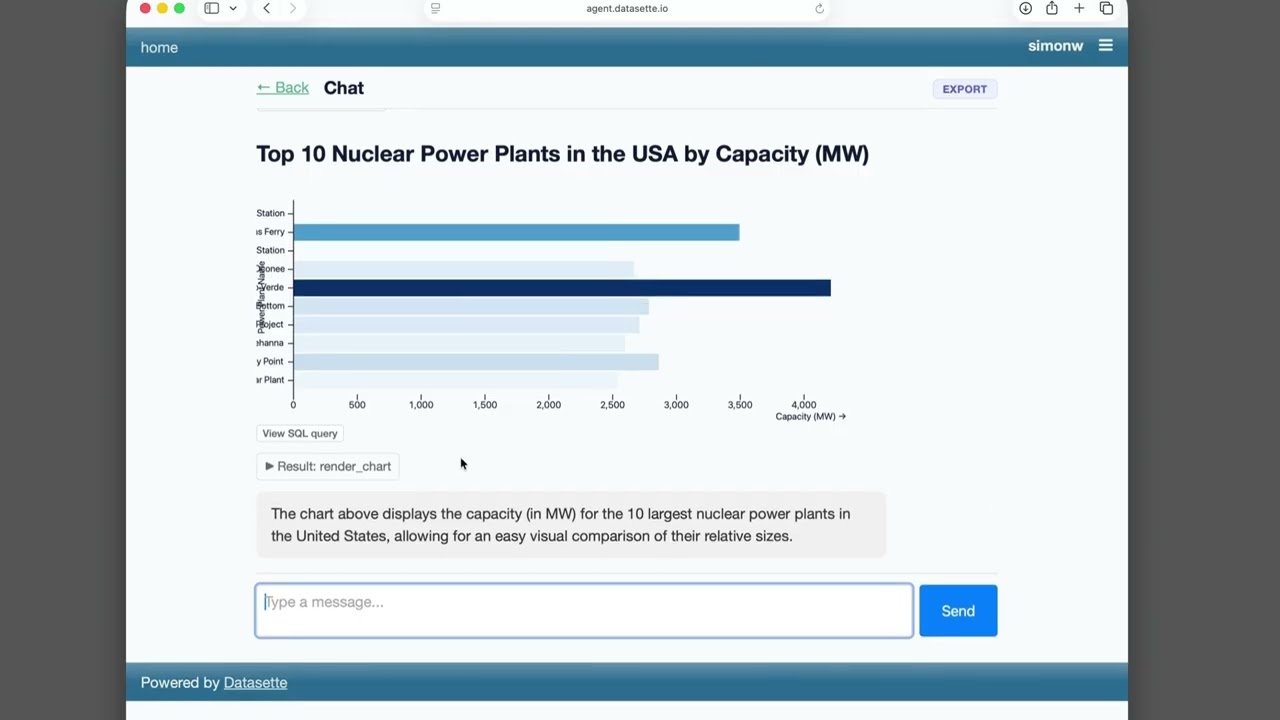
We just announced the first release of Datasette Agent, a new extensible AI assistant for Datasette. I’ve been working on my LLM Python library for just over three years now, and Datasette Agent represents the moment that LLM and Datasette finally come together. I’m really excited about it!
[... 659 words]
- New model
gemini-3.5-flashfor Gemini 3.5 Flash.
See also my notes on Gemini 3.5 Flash, and the pelican I drew using this upgrade to the plugin.
- Fixed bug tracking chains of responses. Refs datasette-llm#7
- Compatible with
llm>=0.32a0alpha - adds the ability to stream reasoning tokens.
This plugin works in conjunction with datasette-llm and datasette-llm-accountant to let you configure a per-user (or global) spending limit for LLM usage inside of Datasette. Configuration looks something like this:
plugins: datasette-llm-limits: limits: per-user-daily: scope: actor window: rolling-24h amount_usd: 1.00
A bunch of useful stuff in this LLM alpha, but the most important detail is this one:
Most reasoning-capable OpenAI models now use the
/v1/responsesendpoint instead of/v1/chat/completions. This enables interleaved reasoning across tool calls for GPT-5 class models. #1435
This means you can now see the summarized reasoning tokens when you run prompts against an OpenAI model, displayed in a different color to standard error. Use the -R or --hide-reasoning flags if you don't want to see that.

Kim_Bruning on Hacker News:
But seriously, you can put a shebang on an english text file now (if you're sufficiently brave) [...]
This inspired me to look at patterns for doing exactly that with LLM. Here's the simplest, which takes advantage of LLM fragments:
#!/usr/bin/env -S llm -f
Generate an SVG of a pelican riding a bicycle
But you can also incorporate tool calls using the -T name_of_tool option:
#!/usr/bin/env -S llm -T llm_time -f
Write a haiku that mentions the exact current time
Or even execute YAML templates directly that define extra tools as Python functions:
#!/usr/bin/env -S llm -t model: gpt-5.4-mini system: | Use tools to run calculations functions: | def add(a: int, b: int) -> int: return a + b def multiply(a: int, b: int) -> int: return a * b
Then:
./calc.sh 'what is 2344 * 5252 + 134' --td
Which outputs (thanks to that --td tools debug option):
Tool call: multiply({'a': 2344, 'b': 5252})
12310688
Tool call: add({'a': 12310688, 'b': 134})
12310822
2344 × 5252 + 134 = **12,310,822**
Read the full TIL for a more complex example that uses the Datasette SQL API to answer questions about content on my blog.
Using Claude Code: The Unreasonable Effectiveness of HTML. Thought-provoking piece by Thariq Shihipar (on the Claude Code team at Anthropic) advocating for HTML over Markdown as an output format to request from Claude.
The article is crammed with interesting examples (collected on this site) and prompt suggestions like this one:
Help me review this PR by creating an HTML artifact that describes it. I'm not very familiar with the streaming/backpressure logic so focus on that. Render the actual diff with inline margin annotations, color-code findings by severity and whatever else might be needed to convey the concept well.
I've been defaulting to asking for most things in Markdown since the GPT-4 days, when the 8,192 token limit meant that Markdown's token-efficiency over HTML was extremely worthwhile.
Thariq's piece here has caused me to reconsider that, especially for output. Asking Claude for an explanation in HTML means it can drop in SVG diagrams, interactive widgets, in-page navigation and all sorts of other neat ways of making the information more pleasant to navigate.
I wrote about Useful patterns for building HTML tools last December, but that was focused very much on interactive utilities like the ones on my tools.simonwillison.net site. I'm excited to start experimenting more with rich HTML explanations in response to ad-hoc prompts.
Trying this out on copy.fail
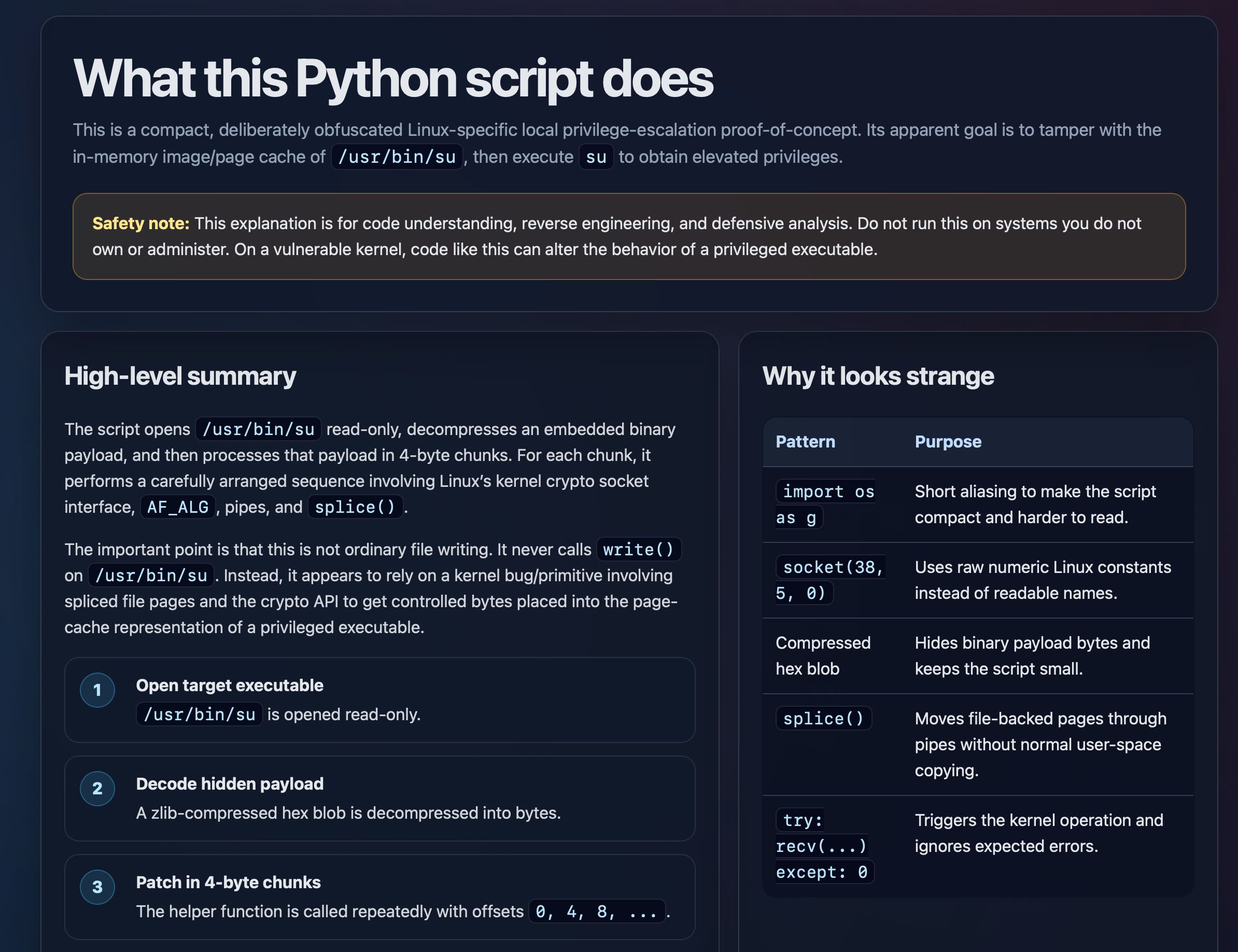
copy.fail describes a recently discovered Linux security exploit, including a proof of concept distributed as obfuscated Python.
I tried having GPT-5.5 create an HTML explanation of the exploit like this:
curl https://copy.fail/exp | llm -m gpt-5.5 -s 'Explain this code in detail. Reformat it, expand out any confusing bits and go deep into what it does and how it works. Output HTML, neatly styled and using capabilities of HTML and CSS and JavaScript to make the explanation rich and interactive and as clear as possible'
Here's the resulting HTML page. It's pretty good, though I should have emphasized explaining the exploit over the Python harness around it.
gemini-3.1-flash-liteis no longer a preview.
Here's my write-up of the Gemini 3.1 Flash-Lite Preview model back in March. I don't believe this new non-preview model has changed since then.
- Mechanism for configuring default options for specific models.
Part of Datasette's evolving support mechanism for plugins that use LLMs. It's now possible to configure a model with default options, e.g. to say all enrichment operations should use a specific model with temperature set to 0.5.
- New
-o thinking 1option to help test against LLM 0.32a0 and higher.
This plugin provides a fake model called "echo" for LLM which doesn't run an LLM at all - it's useful for writing automated tests. You can now do this:
uvx --with llm==0.32a1 --with llm-echo==0.5a0 llm -m echo hi -o thinking 1
This will fake a reasoning block to standard error before returning JSON echoing the prompt.
- Fixed a bug in 0.32a0 where tool-calling conversations were not correctly reinflated from SQLite. #1426
LLM 0.32a0 is a major backwards-compatible refactor
I just released LLM 0.32a0, an alpha release of my LLM Python library and CLI tool for accessing LLMs, with some consequential changes that I’ve been working towards for quite a while.
[... 1,874 words]
- New GPT-5.5 OpenAI model:
llm -m gpt-5.5. #1418- New option to set the text verbosity level for GPT-5+ OpenAI models:
-o verbosity low. Values arelow,medium,high.- New option for setting the image detail level used for image attachments to OpenAI models:
-o image_detail low- values arelow,highandauto, and GPT-5.4 and 5.5 also acceptoriginal.- Models listed in
extra-openai-models.yamlare now also registered as asynchronous. #1395
DeepSeek V4—almost on the frontier, a fraction of the price

Chinese AI lab DeepSeek’s last model release was V3.2 (and V3.2 Speciale) last December. They just dropped the first of their hotly anticipated V4 series in the shape of two preview models, DeepSeek-V4-Pro and DeepSeek-V4-Flash.
[... 703 words]A pelican for GPT-5.5 via the semi-official Codex backdoor API

GPT-5.5 is out. It’s available in OpenAI Codex and is rolling out to paid ChatGPT subscribers. I’ve had some preview access and found it to be a fast, effective and highly capable model. As is usually the case these days, it’s hard to put into words what’s good about it—I ask it to build things and it builds exactly what I ask for!
[... 884 words]Hijacks your Codex CLI credentials to make API calls with LLM, as described in my post about GPT-5.5.
llm openrouter refreshcommand for refreshing the list of available models without waiting for the cache to expire.
I added this feature so I could try Kimi 2.6 on OpenRouter as soon as it became available there.
Here's its pelican - this time as an HTML page because Kimi chose to include an HTML and JavaScript UI to control the animation. Transcript here.
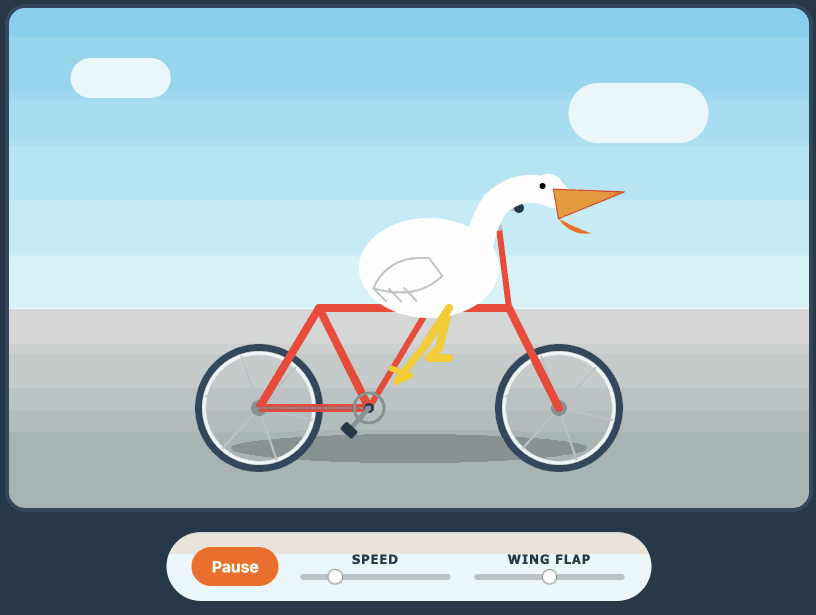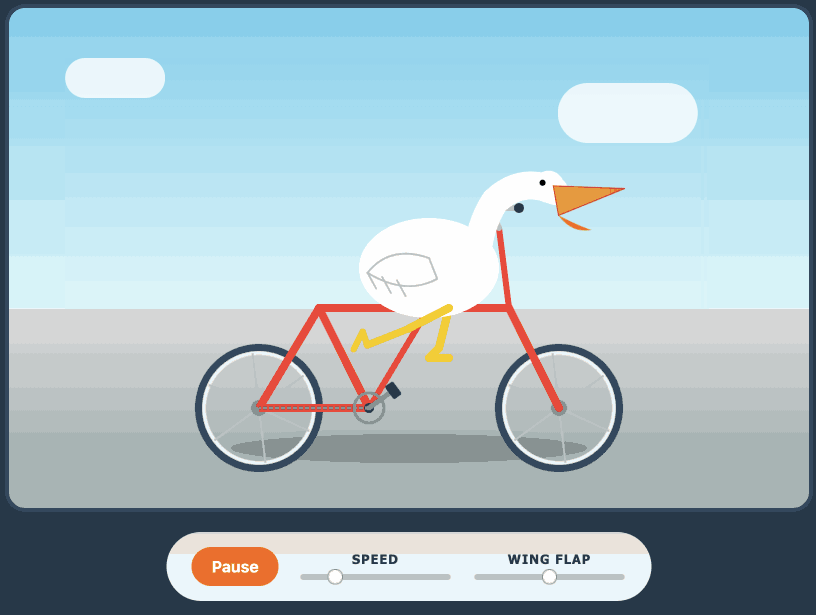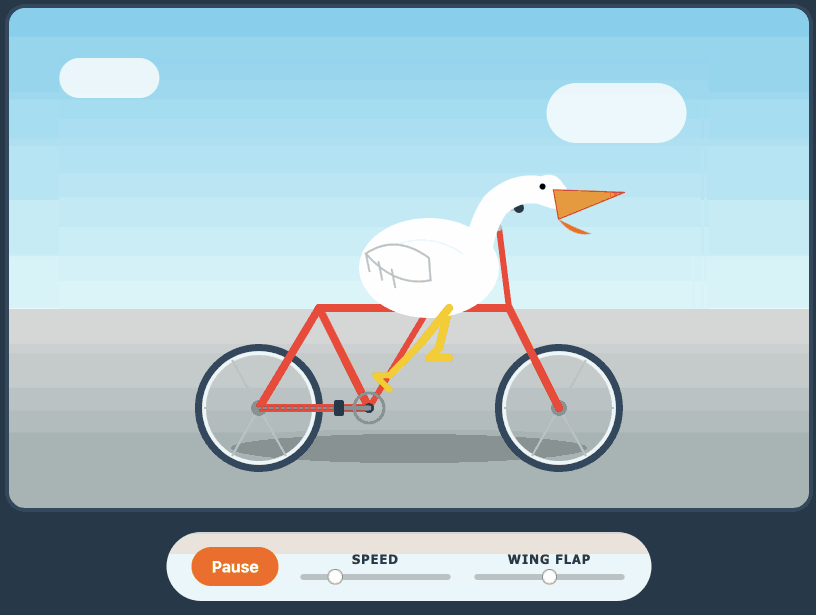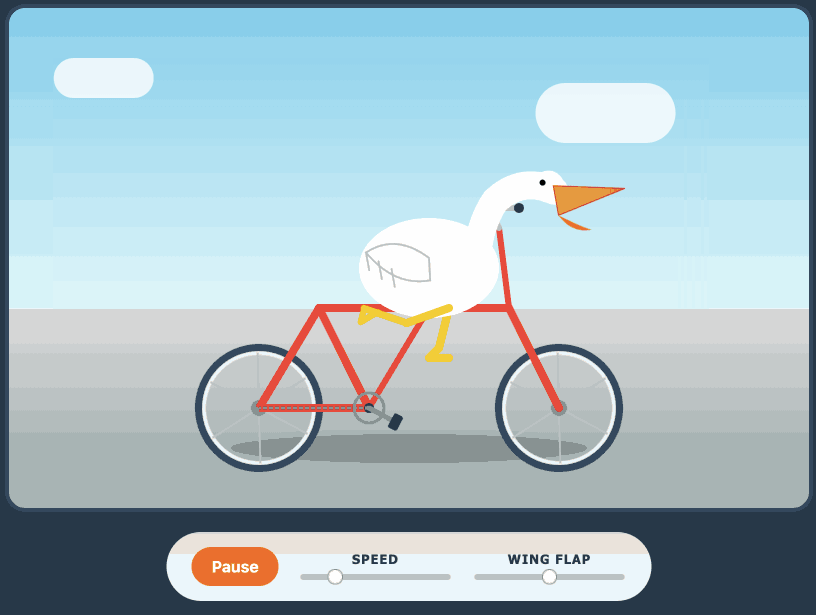
- New model:
claude-opus-4.7, which supportsthinking_effort:xhigh. #66- New
thinking_displayandthinking_adaptiveboolean options.thinking_displaysummarized output is currently only available in JSON output or JSON logs.- Increased default
max_tokensto the maximum allowed for each model.- No longer uses obsolete
structured-outputs-2025-11-13beta header for older models.
I'm working on a major change to my LLM Python library and CLI tool. LLM provides an abstraction layer over hundreds of different LLMs from dozens of different vendors thanks to its plugin system, and some of those vendors have grown new features over the past year which LLM's abstraction layer can't handle, such as server-side tool execution.
To help design that new abstraction layer I had Claude Code read through the Python client libraries for Anthropic, OpenAI, Gemini and Mistral and use those to help craft curl commands to access the raw JSON for both streaming and non-streaming modes across a range of different scenarios. Both the scripts and the captured outputs now live in this new repo.
Gemma 4: Byte for byte, the most capable open models. Four new vision-capable Apache 2.0 licensed reasoning LLMs from Google DeepMind, sized at 2B, 4B, 31B, plus a 26B-A4B Mixture-of-Experts.
Google emphasize "unprecedented level of intelligence-per-parameter", providing yet more evidence that creating small useful models is one of the hottest areas of research right now.
They actually label the two smaller models as E2B and E4B for "Effective" parameter size. The system card explains:
The smaller models incorporate Per-Layer Embeddings (PLE) to maximize parameter efficiency in on-device deployments. Rather than adding more layers or parameters to the model, PLE gives each decoder layer its own small embedding for every token. These embedding tables are large but are only used for quick lookups, which is why the effective parameter count is much smaller than the total.
I don't entirely understand that, but apparently that's what the "E" in E2B means!
One particularly exciting feature of these models is that they are multi-modal beyond just images:
Vision and audio: All models natively process video and images, supporting variable resolutions, and excelling at visual tasks like OCR and chart understanding. Additionally, the E2B and E4B models feature native audio input for speech recognition and understanding.
I've not figured out a way to run audio input locally - I don't think that feature is in LM Studio or Ollama yet.
I tried them out using the GGUFs for LM Studio. The 2B (4.41GB), 4B (6.33GB) and 26B-A4B (17.99GB) models all worked perfectly, but the 31B (19.89GB) model was broken and spat out "---\n" in a loop for every prompt I tried.
The succession of pelican quality from 2B to 4B to 26B-A4B is notable:
E2B:
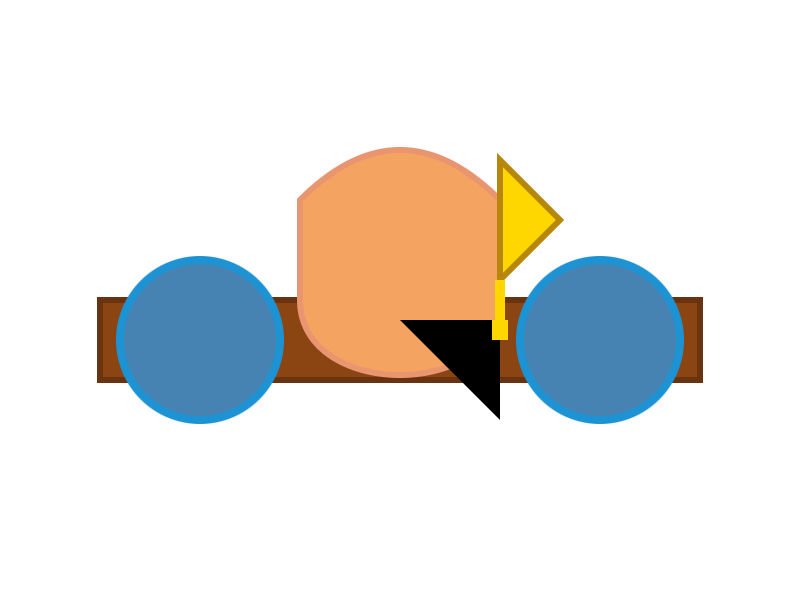
E4B:
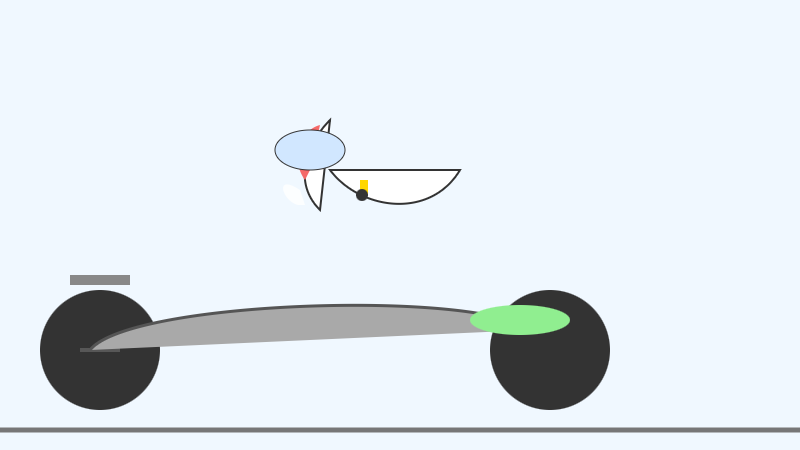
26B-A4B:

(This one actually had an SVG error - "error on line 18 at column 88: Attribute x1 redefined" - but after fixing that I got probably the best pelican I've seen yet from a model that runs on my laptop.)
Google are providing API access to the two larger Gemma models via their AI Studio. I added support to llm-gemini and then ran a pelican through the 31B model using that:
llm -m gemini/gemma-4-31b-it 'Generate an SVG of a pelican riding a bicycle'
Pretty good, though it is missing the front part of the bicycle frame:

New models gemini-3.1-flash-lite-preview, gemma-4-26b-a4b-it and gemma-4-31b-it. See my notes on Gemma 4.
- The same model ID no longer needs to be repeated in both the default model and allowed models lists - setting it as a default model automatically adds it to the allowed models list. #6
- Improved documentation for Python API usage.
- The
actorwho triggers an enrichment is now passed to thellm.mode(... actor=actor)method. #3
- Now uses datasette-llm to manage model configuration, which means you can control which models are available for extraction tasks using the
extractpurpose and LLM model configuration. #38
- This plugin now uses datasette-llm to configure and manage models. This means it's possible to specify which models should be made available for enrichments, using the new
enrichmentspurpose.
- Removed features relating to allowances and estimated pricing. These are now the domain of datasette-llm-accountant.
- Now depends on datasette-llm for model configuration. #3
- Full prompts and responses and tool calls can now be logged to the
llm_usage_prompt_logtable in the internal database if you set the newdatasette-llm-usage.log_promptsplugin configuration setting.- Redesigned the
/-/llm-usage-simple-promptpage, which now requires thellm-usage-simple-promptpermission.