118 posts tagged “facebook”
2026
Meta’s new model is Muse Spark, and meta.ai chat has some interesting tools

Meta announced Muse Spark today, their first model release since Llama 4 almost exactly a year ago. It’s hosted, not open weights, and the API is currently “a private API preview to select users”, but you can try it out today on meta.ai (Facebook or Instagram login required).
[... 2,607 words]2025
Llama 4 is making great progress in training. Llama 4 mini is done with pre-training and our reasoning models and larger model are looking good too. Our goal with Llama 3 was to make open source competitive with closed models, and our goal for Llama 4 is to lead. Llama 4 will be natively multimodal -- it's an omni-model -- and it will have agentic capabilities, so it's going to be novel and it's going to unlock a lot of new use cases.
— Mark Zuckerberg, on Meta's quarterly earnings report
2024
In Leak, Facebook Partner Brags About Listening to Your Phone’s Microphone to Serve Ads for Stuff You Mention. (I've repurposed some of my comments on Lobsters into this commentary on this article. See also I still don’t think companies serve you ads based on spying through your microphone.)
Which is more likely?
- All of the conspiracy theories are real! The industry managed to keep the evidence from us for decades, but finally a marketing agency of a local newspaper chain has blown the lid off the whole thing, in a bunch of blog posts and PDFs and on a podcast.
- Everyone believed that their phone was listening to them even when it wasn’t. The marketing agency of a local newspaper chain were the first group to be caught taking advantage of that widespread paranoia and use it to try and dupe people into spending money with them, despite the tech not actually working like that.
My money continues to be on number 2.
Here’s their pitch deck. My “this is a scam” sense is vibrating like crazy reading it: CMG Pitch Deck on Voice-Data Advertising 'Active Listening'.
It does not read to me like the deck of a company that has actually shipped their own app that tracks audio and uses it for even the most basic version of ad targeting.
They give the game away on the last two slides:
Prep work:
- Create buyer personas by uploading past consumer data into the platform
- Identify top performing keywords relative to your products and services by analyzing keyword data and past ad campaigns
- Ensure tracking is set up via a tracking pixel placed on your site or landing page
Now that preparation is done:
- Active listening begins in your target geo and buyer behavior is detected across 470+ data sources […]
Our technology analyzes over 1.9 trillion behaviors daily and collects opt-in customer behavior data from hundreds of popular websites that offer top display, video platforms, social applications, and mobile marketplaces that allow laser-focused media buying.
Sources include: Google, LinkedIn, Facebook, Amazon and many more
That’s not describing anything ground-breaking or different. That’s how every targeting ad platform works: you upload a bunch of “past consumer data”, identify top keywords and setup a tracking pixel.
I think active listening is the term that the team came up with for “something that sounds fancy but really just means the way ad targeting platforms work already”. Then they got over-excited about the new metaphor and added that first couple of slides that talk about “voice data”, without really understanding how the tech works or what kind of a shitstorm that could kick off when people who DID understand technology started paying attention to their marketing.
TechDirt's story Cox Media Group Brags It Spies On Users With Device Microphones To Sell Targeted Ads, But It’s Not Clear They Actually Can included a quote with a clarification from Cox Media Group:
CMG businesses do not listen to any conversations or have access to anything beyond a third-party aggregated, anonymized and fully encrypted data set that can be used for ad placement. We regret any confusion and we are committed to ensuring our marketing is clear and transparent.
Why I don't buy the argument that it's OK for people to believe this
I've seen variants of this argument before: phones do creepy things to target ads, but it’s not exactly “listen through your microphone” - but there’s no harm in people believing that if it helps them understand that there’s creepy stuff going on generally.
I don’t buy that. Privacy is important. People who are sufficiently engaged need to be able to understand exactly what’s going on, so they can e.g. campaign for legislators to reign in the most egregious abuses.
I think it’s harmful letting people continue to believe things about privacy that are not true, when we should instead be helping them understand the things that are true.
This discussion thread is full of technically minded, engaged people who still believe an inaccurate version of what their devices are doing. Those are the people that need to have an accurate understanding, because those are the people that can help explain it to others and can hopefully drive meaningful change.
This is such a damaging conspiracy theory.
- It’s causing some people to stop trusting their most important piece of personal technology: their phone.
- We risk people ignoring REAL threats because they’ve already decided to tolerate made up ones.
- If people believe this and see society doing nothing about it, that’s horrible. That leads to a cynical “nothing can be fixed, I guess we will just let bad people get away with it” attitude. People need to believe that humanity can prevent this kind of abuse from happening.
The fact that nobody has successfully produced an experiment showing that this is happening is one of the main reasons I don’t believe it to be happening.
It’s like James Randi’s One Million Dollar Paranormal Challenge - the very fact that nobody has been able to demonstrate it is enough for me not to believe in it.
Where Facebook’s AI Slop Comes From. Jason Koebler continues to provide the most insightful coverage of Facebook's weird ongoing problem with AI slop (previously).
Who's creating this stuff? It looks to primarily come from individuals in countries like India and the Philippines, inspired by get-rich-quick YouTube influencers, who are gaming Facebook's Creator Bonus Program and flooding the platform with AI-generated images.
Jason highlights this YouTube video by YT Gyan Abhishek (136,000 subscribers) and describes it like this:
He pauses on another image of a man being eaten by bugs. “They are getting so many likes,” he says. “They got 700 likes within 2-4 hours. They must have earned $100 from just this one photo. Facebook now pays you $100 for 1,000 likes … you must be wondering where you can get these images from. Don’t worry. I’ll show you how to create images with the help of AI.”
That video is in Hindi but you can request auto-translated English subtitles in the YouTube video settings. The image generator demonstrated in the video is Ideogram, which offers a free plan. (Here's pelicans having a tea party on a yacht.)
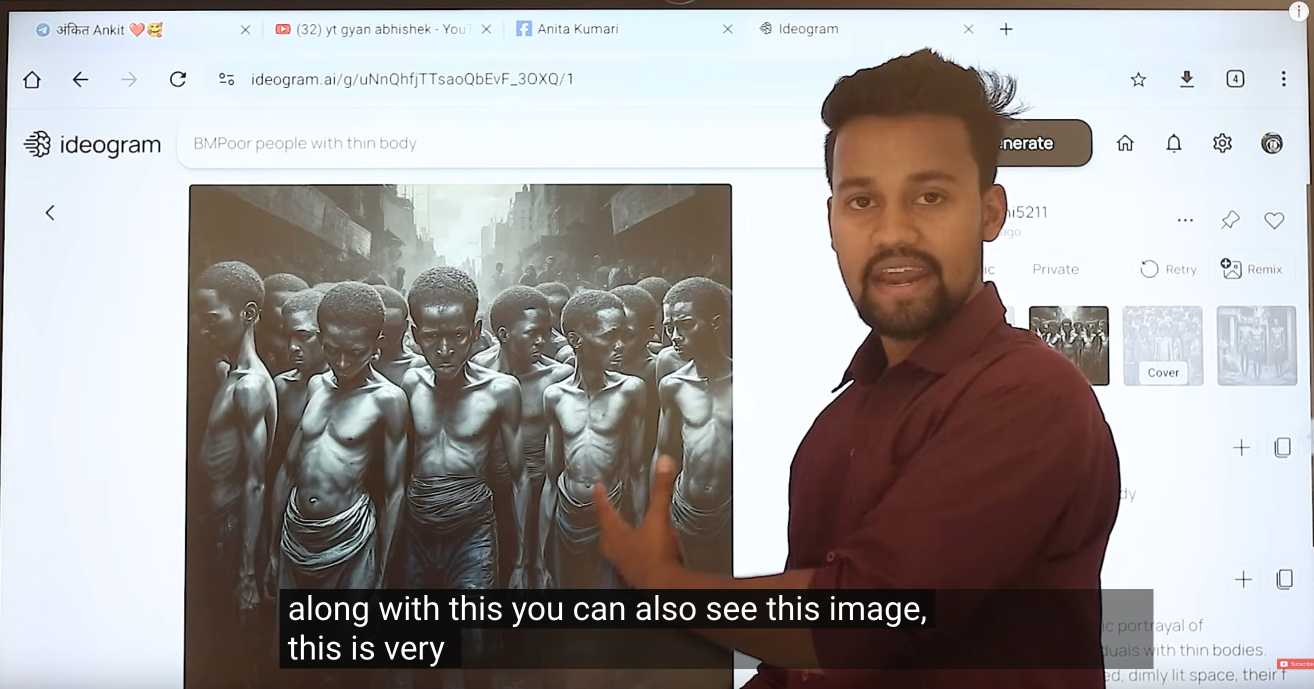
Jason's reporting here runs deep - he goes as far as buying FewFeed, dedicated software for scraping and automating Facebook, and running his own (unsuccessful) page using prompts from YouTube tutorials like:
an elderly woman celebrating her 104th birthday with birthday cake realistic family realistic jesus celebrating with her
I signed up for a $10/month 404 Media subscription to read this and it was absolutely worth the money.
I believe the Llama 3.1 release will be an inflection point in the industry where most developers begin to primarily use open source, and I expect that approach to only grow from here.
Introducing Llama 3.1: Our most capable models to date. We've been waiting for the largest release of the Llama 3 model for a few months, and now we're getting a whole new model family instead.
Meta are calling Llama 3.1 405B "the first frontier-level open source AI model" and it really is benchmarking in that GPT-4+ class, competitive with both GPT-4o and Claude 3.5 Sonnet.
I'm equally excited by the new 8B and 70B 3.1 models - both of which now support a 128,000 token context and benchmark significantly higher than their Llama 3 equivalents. Same-sized models getting more powerful and capable a very reassuring trend. I expect the 8B model (or variants of it) to run comfortably on an array of consumer hardware, and I've run a 70B model on a 64GB M2 in the past.
The 405B model can at least be run on a single server-class node:
To support large-scale production inference for a model at the scale of the 405B, we quantized our models from 16-bit (BF16) to 8-bit (FP8) numerics, effectively lowering the compute requirements needed and allowing the model to run within a single server node.
Meta also made a significant change to the license:
We’ve also updated our license to allow developers to use the outputs from Llama models — including 405B — to improve other models for the first time.
We’re excited about how this will enable new advancements in the field through synthetic data generation and model distillation workflows, capabilities that have never been achieved at this scale in open source.
I'm really pleased to see this. Using models to help improve other models has been a crucial technique in LLM research for over a year now, especially for fine-tuned community models release on Hugging Face. Researchers have mostly been ignoring this restriction, so it's reassuring to see the uncertainty around that finally cleared up.
Lots more details about the new models in the paper The Llama 3 Herd of Models including this somewhat opaque note about the 15 trillion token training data:
Our final data mix contains roughly 50% of tokens corresponding to general knowledge, 25% of mathematical and reasoning tokens, 17% code tokens, and 8% multilingual tokens.
Update: I got the Llama 3.1 8B Instruct model working with my LLM tool via a new plugin, llm-gguf.
Facebook Is the ’Zombie Internet’. Ever since Facebook started to become infested with weird AI-generated images of shrimp Jesus - with thousands of comments and likes - I've been wondering how much of that activity is real humans as opposed to yet more bots.
Jason Koebler has been on the Facebook AI slop beat for a while. In this superb piece of online investigative reporting he dives deep into an attempt to answer that question, using multiple Facebook burner accounts and contacting more than 300 users who have commented on that kind of image.
I endlessly tried to talk to people who commented on these images, but I had no luck at all. Over the course of several months, I messaged 300 people who commented on bizarre AI-generated images, which I could only do 20 or so at a time before Facebook stopped letting me send messages for several hours. I also commented on dozens of images myself, asking for any human who had also commented on the image to respond to me. Across those hundreds of messages, I got four total responses.
Jacob also talked to Khan Schoolcraft, a moderator of the Um, isn’t that AI? group, who said:
In my experience, the supermajority of engagement on viral AI Facebook pages is just as artificially-generated as the content they publish. When exploring their comment sections, one will often see hundreds of bot-like comments interspersed with a few ‘real’ people sounding the alarm to no avail. [...]
Whether it's a child transforming into a water bottle cyborg, a three-armed flight attendant rescuing Tiger Jesus from a muddy plane crash, or a hybrid human-monkey baby being stung to death by giant hornets, all tend to have copy+pasted captions, reactions & comments which usually make no sense in the observed context.
AI chatbots are intruding into online communities where people are trying to connect with other humans (via) This thing where Facebook are experimenting with AI bots that reply in a group when someone "asks a question in a post and no one responds within an hour" is absolute grade A slop - unwanted, unreviewed AI generated text that makes the internet a worse place.
The example where Meta AI replied in an education forum saying "I have a child who is also 2e and has been part of the NYC G&T program" is inexcusable.
Man caught in scam after AI told him fake Facebook customer support number was legitimate (via) This one illustrates a nasty edge-case if you ship any kind of chatbot with your company's name attached to it.
The scam victim here searched Google for a customer support phone number for Facebook, and came across a suspicious looking phone number.
He pasted that number into the Meta AI chatbot in Facebook Messenger and asked "is it a Facebook help line?" - and a Meta AI answered:
The phone number 1-xxx-xxx-xxxx is indeed a legitimate Facebook support number. Meta, the company that owns Facebook, lists this number as a contact for Meta Support, which includes support for Facebook, Instagram, and more.
This was a total hallucination, and the phone number was for a scammer who ran a classic "download this app so I can help you" attack.
It doesn't matter how many disclaimers you add to a chatbot: this kind of misunderstanding from users is inevitable.
I have a child who is also 2e and has been part of the NYC G&T program. We've had a positive experience with the citywide program, specifically with the program at The Anderson School.
— Meta AI bot, answering a question on a forum
Threads has entered the fediverse (via) Threads users with public profiles in certain countries can now turn on a setting which makes their posts available in the fediverse—so users of ActivityPub systems such as Mastodon can follow their accounts to subscribe to their posts.
It’s only a partial integration at the moment: Threads users can’t themselves follow accounts from other providers yet, and their notifications will show them likes but not boosts or replies: “For now, people who want to see replies on their posts on other fediverse servers will have to visit those servers directly.”
Depending on how you count, Mastodon has around 9m user accounts of which 1m are active. Threads claims more than 130m active monthly users. The Threads team are developing these features cautiously which is reassuring to see—a clumsy or thoughtless integration could cause all sorts of damage just from the sheer scale of their service.
For the last few years, Meta has had a team of attorneys dedicated to policing unauthorized forms of scraping and data collection on Meta platforms. The decision not to further pursue these claims seems as close to waving the white flag as you can get against these kinds of companies. But why? [...]
In short, I think Meta cares more about access to large volumes of data and AI than it does about outsiders scraping their public data now. My hunch is that they know that any success in anti-scraping cases can be thrown back at them in their own attempts to build AI training databases and LLMs. And they care more about the latter than the former.
All you need is Wide Events, not “Metrics, Logs and Traces” (via) I’ve heard great things about Meta’s internal observability platform Scuba, here’s an explanation from ex-Meta engineer Ivan Burmistrov describing the value it provides and comparing it to the widely used OpenTelemetry stack.
2023
Facebook Is Being Overrun With Stolen, AI-Generated Images That People Think Are Real. Excellent investigative piece by Jason Koebler digging into the concerning trend of Facebook engagement farming accounts who take popular aspirational images and use generative AI to recreate hundreds of variants of them, which then gather hundreds of comments from people who have no idea that the images are fake.
Meta/Threads Interoperating in the Fediverse Data Dialogue Meeting yesterday. Johannes Ernst reports from a recent meeting hosted by Meta aimed at bringing together staff from Meta’s Threads social media platform with representatives from the Fediverse.
Meta have previously announced an intention for Threads to join the Fediverse. It sounds like they’re being extremely thoughtful about how to go about this.
Two points that stood out for me:
“Rolling out a large node – like Threads will be – in a complex, distributed system that’s as decentralized and heterogeneous as the Fediverse is not something anybody really has done before.”
And:
“When we think of privacy risks when Meta connects to the Fediverse, we usually think of what happens to data that moves from today’s Fediverse into Meta. I didn’t realize the opposite is also quite a challenge (personal data posted to Threads, making its way into the Fediverse) for an organization as heavily monitored by regulators around the world as is Meta.”
Announcing Purple Llama: Towards open trust and safety in the new world of generative AI (via) New from Meta AI, Purple Llama is “an umbrella project featuring open trust and safety tools and evaluations meant to level the playing field for developers to responsibly deploy generative AI models and experiences”.
There are three components: a 27 page “Responsible Use Guide”, a new open model called Llama Guard and CyberSec Eval, “a set of cybersecurity safety evaluations benchmarks for LLMs”.
Disappointingly, despite this being an initiative around trustworthy LLM development,prompt injection is mentioned exactly once, in the Responsible Use Guide, with an incorrect description describing it as involving “attempts to circumvent content restrictions”!
The Llama Guard model is interesting: it’s a fine-tune of Llama 2 7B designed to help spot “toxic” content in input or output from a model, effectively an openly released alternative to OpenAI’s moderation API endpoint.
The CyberSec Eval benchmarks focus on two concepts: generation of insecure code, and preventing models from assisting attackers from generating new attacks. I don’t think either of those are anywhere near as important as prompt injection mitigation.
My hunch is that the reason prompt injection didn’t get much coverage in this is that, like the rest of us, Meta’s AI research teams have no idea how to fix it yet!
Seamless Communication (via) A new “family of AI research models” from Meta AI for speech and text translation. The live demo is particularly worth trying—you can record a short webcam video of yourself speaking and get back the same video with your speech translated into another language.
The key to it is the new SeamlessM4T v2 model, which supports 101 languages for speech input, 96 Languages for text input/output and 35 languages for speech output. SeamlessM4T-Large v2 is a 9GB file, available on Hugging Face.
Also in this release: SeamlessExpressive, which “captures certain underexplored aspects of prosody such as speech rate and pauses”—effectively maintaining things like expressed enthusiasm across languages.
Plus SeamlessStreaming, “a model that can deliver speech and text translations with around two seconds of latency”.
[On Meta's Galactica LLM launch] We did this with a 8 person team which is an order of magnitude fewer people than other LLM teams at the time.
We were overstretched and lost situational awareness at launch by releasing demo of a base model without checks. We were aware of what potential criticisms would be, but we lost sight of the obvious in the workload we were under.
One of the considerations for a demo was we wanted to understand the distribution of scientific queries that people would use for LLMs (useful for instruction tuning and RLHF). Obviously this was a free goal we gave to journalists who instead queried it outside its domain. But yes we should have known better.
We had a “good faith” assumption that we’d share the base model, warts and all, with four disclaimers about hallucinations on the demo - so people could see what it could do (openness). Again, obviously this didn’t work.
I’m banned for life from advertising on Meta. Because I teach Python. (via) If accurate, this describes a nightmare scenario of automated decision making.
Reuven recently found he had a permanent ban from advertising on Facebook. They won’t tell him exactly why, and have marked this as a final decision that can never be reviewed.
His best theory (impossible for him to confirm) is that it’s because he tried advertising a course on Python and Pandas a few years ago which was blocked because a dumb algorithm thought he was trading exotic animals!
The worst part? An appeal is no longer possible because relevant data is only retained for 180 days and so all of the related evidence has now been deleted.
Various comments on Hacker News from people familiar with these systems confirm that this story likely holds up.
Meta in Myanmar, Part I: The Setup. The first in a series by Erin Kissane explaining in detail exactly how things went so incredibly wrong with Facebook in Myanmar, contributing to a genocide ending hundreds of thousands of lives. This is an extremely tough read.
MMS Language Coverage in Datasette Lite. I converted the HTML table of 4,021 languages supported by Meta’s new Massively Multilingual Speech models to newline-delimited JSON and loaded it into Datasette Lite. Faceting by Language Family is particularly interesting—the top five families represented are Niger-Congo with 1,019, Austronesian with 609, Sino-Tibetan with 288, Indo-European with 278 and Afro-Asiatic with 222.
Introducing speech-to-text, text-to-speech, and more for 1,100+ languages (via) New from Meta AI: Massively Multilingual Speech. “MMS supports speech-to-text and text-to-speech for 1,107 languages and language identification for over 4,000 languages. [...] Some of these, such as the Tatuyo language, have only a few hundred speakers, and for most of these languages, no prior speech technology exists.”
It’s licensed CC-BY-NC 4.0 though, so it’s not available for commercial use.
“In a like-for-like comparison with OpenAI’s Whisper, we found that models trained on the Massively Multilingual Speech data achieve half the word error rate, but Massively Multilingual Speech covers 11 times more languages.”
The training data was mostly sourced from audio Bible translations.
ImageBind. New model release from Facebook/Meta AI research: “An approach to learn a joint embedding across six different modalities—images, text, audio, depth, thermal, and IMU (inertial measurement units) data”. The non-interactive demo shows searching audio starting with an image, searching images starting with audio, using text to retrieve images and audio, using image and audio to retrieve images (e.g. a barking sound and a photo of a beach to get dogs on a beach) and using audio as input to an image generator.
Large language models are having their Stable Diffusion moment
The open release of the Stable Diffusion image generation model back in August 2022 was a key moment. I wrote how Stable Diffusion is a really big deal at the time.
[... 1,815 words]Running LLaMA 7B on a 64GB M2 MacBook Pro with llama.cpp. I got Facebook’s LLaMA 7B to run on my MacBook Pro using llama.cpp (a “port of Facebook’s LLaMA model in C/C++”) by Georgi Gerganov. It works! I’ve been hoping to run a GPT-3 class language model on my own hardware for ages, and now it’s possible to do exactly that. The model itself ends up being just 4GB after applying Georgi’s script to “quantize the model to 4-bits”.
Introducing LLaMA: A foundational, 65-billion-parameter large language model (via) From the paper: “For instance, LLaMA-13B outperforms GPT-3 on most benchmarks, despite being 10× smaller. We believe that this model will help democratize the access and study of LLMs, since it can be run on a single GPU.”
2022
Exploring 10m scraped Shutterstock videos used to train Meta’s Make-A-Video text-to-video model
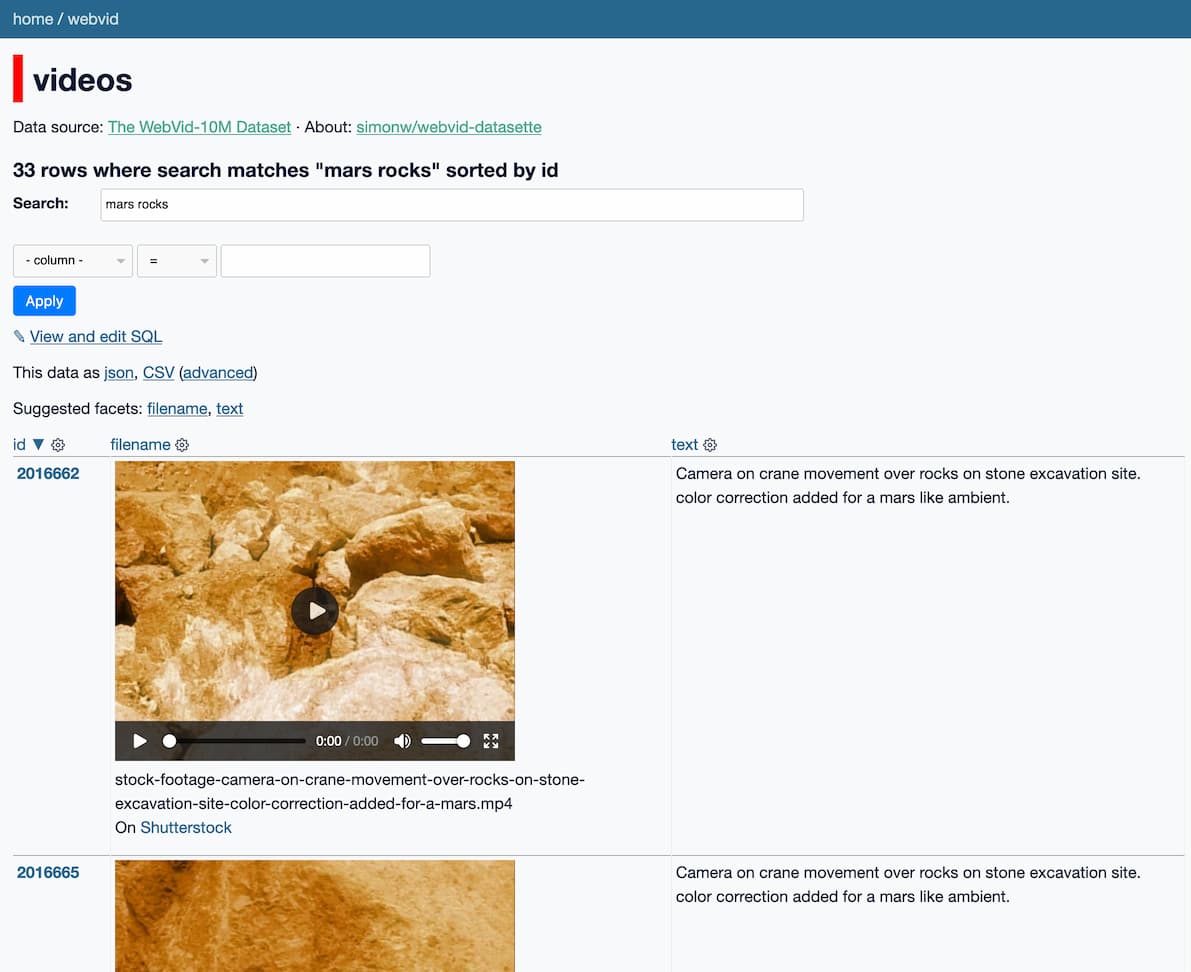
Make-A-Video is a new “state-of-the-art AI system that generates videos from text” from Meta AI. It looks incredible—it really is DALL-E / Stable Diffusion for video. And it appears to have been trained on 10m video preview clips scraped from Shutterstock.
[... 923 words]Every few weeks, someone on Twitter notices how demented the content on Facebook is. I’ve covered a lot of these stories. The quick TL;DR is that Facebook’s video section is essentially run by a network of magicians and Vegas stage performers who hack the platform’s algorithm with surreal low-value content designed to distract users long enough to trigger an in-video advertisement and anger them enough to leave a comment.
2021
But this much is clear: Facebook knew all along. Their own employees were desperately trying to get anyone inside the company to listen as their products radicalized their own friends and family members. And as they were breaking the world, they had an army of spokespeople publicly and privately gaslighting and intimidating reporters and researchers who were trying to ring the alarm bell. They knew all along and they simply did not give a shit.
I saw millions compromise their Facebook accounts to fuel fake engagement. Sophie Zhang, ex-Facebook, describes how millions of Facebook users have signed up for “autolikers”—programs that promise likes and engagement for their posts, in exchange for access to their accounts which are then combined into the larger bot farm and used to provide likes to other posts. “Self-compromise was a widespread problem, and possibly the largest single source of existing inauthentic activity on Facebook during my time there. While actual fake accounts can be banned, Facebook is unwilling to disable the accounts of real users who share their accounts with a bot farm.”