8 posts tagged “observability”
2024
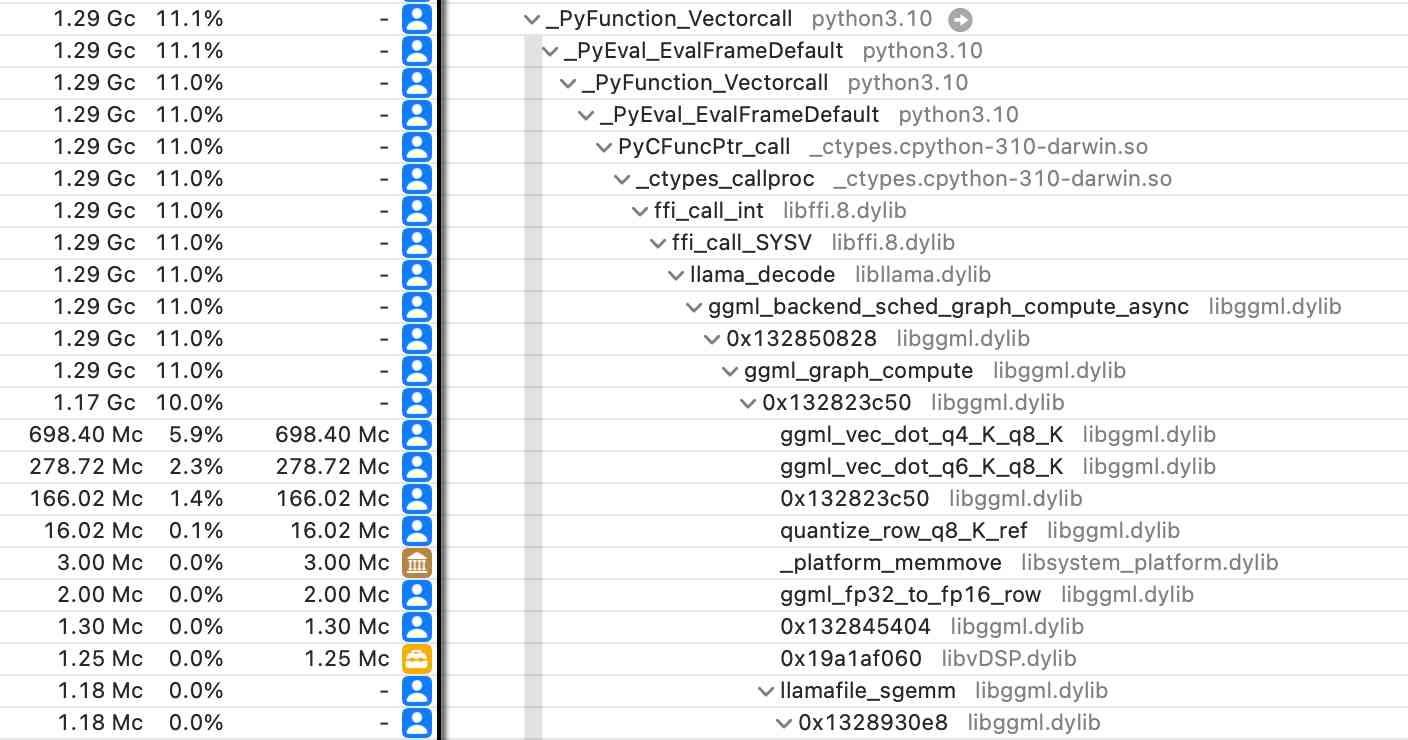
Did you know about Instruments? (via) Thorsten Ball shows how the macOS Instruments app (installed as part of Xcode) can be used to run a CPU profiler against any application - not just code written in Swift/Objective C.
I tried this against a Python process running LLM executing a Llama 3.1 prompt with my new llm-gguf plugin and captured this:
All you need is Wide Events, not “Metrics, Logs and Traces” (via) I’ve heard great things about Meta’s internal observability platform Scuba, here’s an explanation from ex-Meta engineer Ivan Burmistrov describing the value it provides and comparing it to the widely used OpenTelemetry stack.
2022
Roblox Return to Service 10/28-10/31 2021 (via) A particularly good example of a public postmortem on an outage. Roblox was down for 72 hours last year, as a result of an extremely complex set of circumstances which took a lot of effort to uncover. It’s interesting to think through what kind of monitoring you would need to have in place to help identify the root cause of this kind of issue.
2021
When I was a performance consultant I'd show up to random companies who wanted me to fix their computer performance issues. If they trusted me with a login to their production servers, I could help them a lot quicker. To get that trust I knew which tools looked but didn't touch: Which were observability tools and which were experimental tools. "I'll start with observability tools only" is something I'd say at the start of every engagement.
2020
Instead of seeing instrumentation as a last-ditch effort of strings and metrics, we must think about propagating the full context of a request and emitting it at regular pulses. No pull request should ever be accepted unless the engineer can answer the question, “How will I know if this breaks?”
2019
Logs vs. metrics: a false dichotomy (via) Nick Stenning discusses the differences between logs and metrics: most notably that metrics can be derived from logs but logs cannot be reconstituted starting with time-series metrics.
Targeted diagnostic logging in production (via) Will Sargent defines diagnostic logging as “debug logging statements with an audience”, and proposes controlling this style if logging via a feature flat system to allow detailed logging to be turned on in production against a selected subset if users in order to help debug difficult problems. Lots of great background material in the topic of observability here too.
Metrics are lossily compressed logs. Traces are logs with parent child relationships between entries. The only reason we have three terms is because getting value from them has required different compromises to make them cost effective.