April 2023
110 posts: 17 entries, 45 links, 19 quotes, 29 beats
April 1, 2023
textual-mandelbrot (via) I love this: run “pipx install textual-mandelbrot” and then “mandelexp” to get an interactive Mandelbrot fractal exploration interface right there in your terminal, built on top of Textual. The code for this is only 250 lines of Python and delightfully easy to follow.

April 2, 2023
What AI can do for you on the Theory of Change podcast
Matthew Sheffield invited me on his show Theory of Change to talk about how AI models like ChatGPT, Bing and Bard work and practical applications of things you can do with them.
[... 548 words]AI photo sorter (via) Really interesting implementation of machine learning photo classification by Alexander Visheratin. This tool lets you select as many photos as you like from your own machine, then provides a web interface for classifying them into labels that you provide. It loads a 102MB quantized CLIP model and executes it in the browser using WebAssembly. Once classified, a “Generate script” button produces a copyable list of shell commands for moving your images into corresponding folders on your own machine. Your photos never get uploaded to a server—everything happens directly in your browser.
Think of language models like ChatGPT as a “calculator for words”
One of the most pervasive mistakes I see people using with large language model tools like ChatGPT is trying to use them as a search engine.
[... 1,162 words]
April 3, 2023
Django 4.2 released. “This version has been designated as a long-term support (LTS) release, which means that security and data loss fixes will be applied for at least the next three years.” Some neat new async features, including improvements to async streaming responses.
Stable Diffusion copyright lawsuits could be a legal earthquake for AI. Timothy B. Lee provides a thorough discussion of the copyright lawsuits currently targeting Stable Diffusion and GitHub Copilot, including subtle points about how the interpretation of “fair use” might be applied to the new field of generative AI.
Beyond these specific legal arguments, Stability AI may find it has a “vibes” problem. The legal criteria for fair use are subjective and give judges some latitude in how to interpret them. And one factor that likely influences the thinking of judges is whether a defendant seems like a “good actor.” Google is a widely respected technology company that tends to win its copyright lawsuits. Edgier companies like Napster tend not to.

Closed AI Models Make Bad Baselines (via) The NLP academic research community are facing a tough challenge: the state-of-the-art in large language models, GPT-4, is entirely closed which means papers that compare it to other models lack replicability and credibility. “We make the case that as far as research and scientific publications are concerned, the “closed” models (as defined below) cannot be meaningfully studied, and they should not become a “universal baseline”, the way BERT was for some time widely considered to be.”
Anna Rogers proposes a new rule for this kind of research: “That which is not open and reasonably reproducible cannot be considered a requisite baseline.”
ROOTS search tool (via) BLOOM is one of the most interesting completely openly licensed language models. The ROOTS corpus is the training data that was collected for it, and this tool lets you run searches directly against that corpus. I tried searching for my own name and got an interesting insight into what it knows about me.
April 4, 2023
Semi-automating a Substack newsletter with an Observable notebook
I recently started sending out a weekly-ish email newsletter consisting of content from my blog. I’ve mostly automated that, using an Observable Notebook to generate the HTML. Here’s how that system works.
[... 2,520 words]trurl manipulates URLs.
Brand new command-line tool from curl creator Daniel Stenberg: The tr stands for translate or transpose, and the tool provides various mechanisms for normalizing URLs, adding query strings, changing the path or hostname and other similar modifications. I’ve tried designing APis for this kind of thing in the past—Datasette includes some clumsily named functions such as path_with_removed_args()—and it’s a deceptively deep set of problems.
.
Guess we could start calling this a ’hallucitation’? Kate Crawford coins an excellent neologism for hallucinated citations in LLMs like ChatGPT.
Weeknotes: A new llm CLI tool, plus automating my weeknotes and newsletter
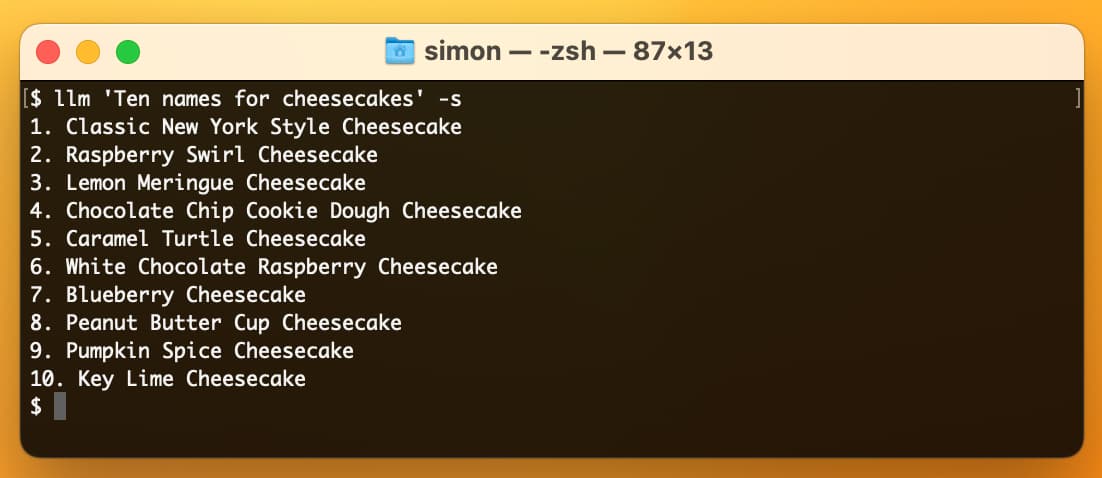
I started publishing weeknotes in 2019 partly as a way to hold myself accountable but mainly as a way to encourage myself to write more.
[... 830 words]April 5, 2023
From Deep Learning Foundations to Stable Diffusion. Brand new free online video course from Jeremy Howard: 30 hours of content, covering everything you need to know to implement the Stable Diffusion image generation algorithm from scratch. I previewed parts of this course back in December and it was fascinating: this field is moving so fast that some of the lectures covered papers that had been released just a few days before.
Scaling laws allow us to precisely predict some coarse-but-useful measures of how capable future models will be as we scale them up along three dimensions: the amount of data they are fed, their size (measured in parameters), and the amount of computation used to train them (measured in FLOPs). [...] Our ability to make this kind of precise prediction is unusual in the history of software and unusual even in the history of modern AI research. It is also a powerful tool for driving investment since it allows R&D teams to propose model-training projects costing many millions of dollars, with reasonable confidence that these projects will succeed at producing economically valuable systems.
Eight Things to Know about Large Language Models (via) This unpublished paper by Samuel R. Bowman is succinct, readable and dense with valuable information to help understand the field of modern LLMs.
More capable models can better recognize the specific circumstances under which they are trained. Because of this, they are more likely to learn to act as expected in precisely those circumstances while behaving competently but unexpectedly in others. This can surface in the form of problems that Perez et al. (2022) call sycophancy, where a model answers subjective questions in a way that flatters their user’s stated beliefs, and sandbagging, where models are more likely to endorse common misconceptions when their user appears to be less educated.
My guess is that MidJourney has been doing a massive-scale reinforcement learning from human feedback ("RLHF") - possibly the largest ever for text-to-image.
When human users choose to upscale an image, it's because they prefer it over the alternatives. It'd be a huge waste not to use this as a reward signal - cheap to collect, and exactly aligned with what your user base wants.
The more users you have, the better RLHF you can do. And then the more users you gain.
— Jim Fan
Blinded by Analogies (via) Ethan Mollick discusses how many of the analogies we have for AI right now are hurting rather than helping our understanding, particularly with respect to LLMs.
image-to-jpeg (via) I built a little JavaScript app that accepts an image, then displays that image as a JPEG with a slider to control the quality setting, plus a copy and paste textarea to copy out that image with a data-uri. I didn't actually write a single line of code for this: I got ChatGPT/GPT-4 to generate the entire thing with some prompts.
Here's the full transcript.
[On AI-assisted programming] I feel like I got a small army of competent hackers to both do my bidding and to teach me as I go. It's just pure delight and magic.
It's riding a bike downhill and playing with legos and having a great coach and finishing a project all at once.
April 6, 2023

April 7, 2023
Projectories have power. Power for those who are trying to invent new futures. Power for those who are trying to mobilize action to prevent certain futures. And power for those who are trying to position themselves as brokers, thought leaders, controllers of future narratives in this moment of destabilization. But the downside to these projectories is that they can also veer way off the railroad tracks into the absurd. And when the political, social, and economic stakes are high, they can produce a frenzy that has externalities that go well beyond the technology itself. That is precisely what we’re seeing right now.
The different uses of Python type hints (via) Luke Plant describes five different categories for how Python optional types are being used today: IDE assistants, type checking, runtime behavior changes via introspection (e.g. Pydantic), code documentation, compiler instructions (ala mypyc)—and a bonus sixth, dependency injection.