473 posts tagged “sqlite”
SQLite is the world's most widely deployed database engine.
2022
Litestream: Live Read Replication (via) The documentation for the read replication implemented in the latest Litestream beta (v0.4.0-beta.2). The design is really simple and clever: the primary runs a web server on a port, and replica instances can then be started with a configured URL pointing to the IP and port of the primary. That’s all it takes to have a SQLite database replicated to multiple hosts, each of which can then conduct read queries against their local copies.
SQLite Happy Hour—a Twitter Spaces conversation about three interesting projects building on SQLite
Yesterday I hosted SQLite Happy Hour. my first conversation using Twitter Spaces. The idea was to dig into three different projects that were doing interesting things on top of SQLite. I think it worked pretty well, and I’m curious to explore this format more in the future.
[... 1,998 words]redbean (via) “redbean makes it possible to share web applications that run offline as a single-file αcτµαlly pδrταblε εxεcµταblε zip archive which contains your assets. All you need to do is download the redbean.com program below, change the filename to .zip, add your content in a zip editing tool, and then change the extension back to .com”.
redbean is implemented as a single C file with a dazzling array of clever tricks—most impressively, the single executable works on Linux, macOS, Windows and various BSDs!
It embeds Lua, and in June last year added SQLite too—so self-contained distributable web applications built with Redbean can now use Lua and SQLite for dynamic scripting. Performance sounds incredible: “redbean can serve 1 million+ gzip encoded responses per second on a cheap personal computer”.
Using SQLite and Datasette with Fly Volumes
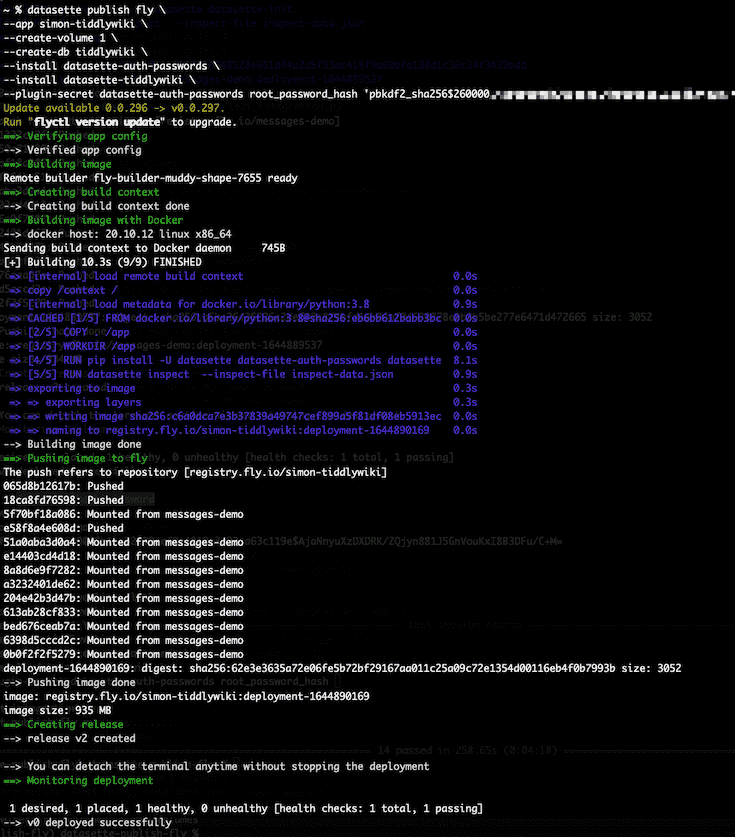
A few weeks ago, Fly announced Free Postgres Databases as part of the free tier of their hosting product. Their announcement included this snippet:
[... 1,463 words]A CGo-free port of SQLite. Fascinating Go version of SQLite, which uses Go code that has been translated from the original SQLite C using ccgo, a package by the same author which “translates cc ASTs to Go source code”. It claims to pass the full public SQLite test suite, which is very impressive.
SQLime: SQLite Playground (via) Anton Zhiyanov built this useful mobile-friendly online playground for trying things out it SQLite. It uses the sql.js library which compiles SQLite to WebAssembly, so it runs everything in the browser—but it also supports saving your work to Gists via the GitHub API. The JavaScript source code is fun to read: the site doesn’t use npm or Webpack or similar, opting instead to implement everything library-free using modern JavaScript modules and Web Components.
What’s new in sqlite-utils 3.20 and 3.21: --lines, --text, --convert
sqlite-utils is my combined CLI tool and Python library for manipulating SQLite databases. Consider this the annotated release notes for sqlite-utils 3.20 and 3.21, both released in the past week.
[... 2,456 words]2021
Notes on Notes.app.
Apple's Notes app keeps its data in a SQLite database at ~/Library/Group\ Containers/group.com.apple.notes/NoteStore.sqlite - but it's pretty difficult to extract data from. It turns out the note text is stored as a gzipped protocol buffers object in the ZICNOTEDATA.ZDATA column. Steve Dunham did the hard work of figuring out how it all works - the complexity stems from Apple's use of CRDT's to support seamless multiple edits from different devices.
git-history: a tool for analyzing scraped data collected using Git and SQLite
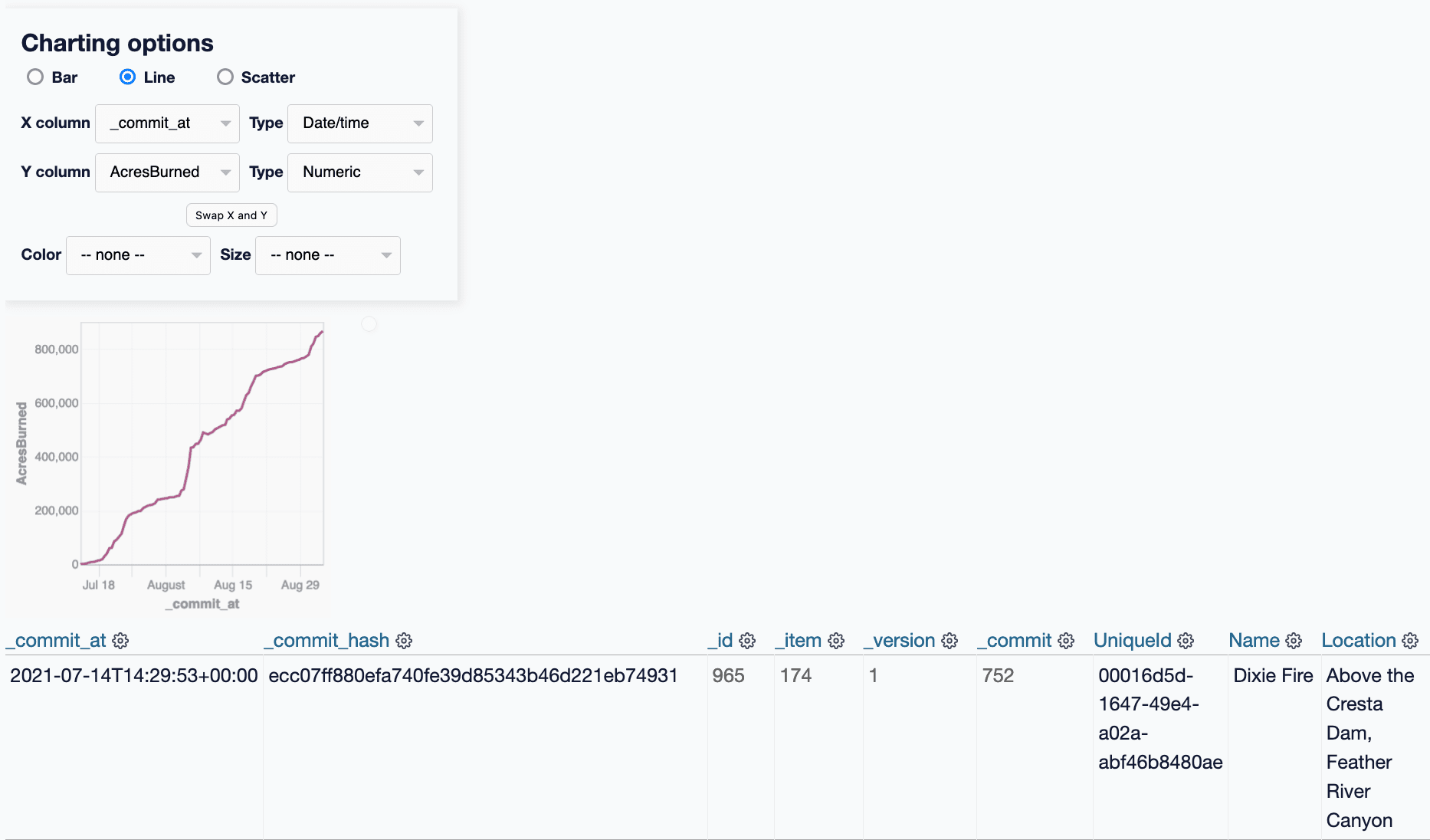
I described Git scraping last year: a technique for writing scrapers where you periodically snapshot a source of data to a Git repository in order to record changes to that source over time.
[... 2,002 words]DuckDB-Wasm: Efficient Analytical SQL in the Browser (via) First SQLite, now DuckDB: options for running database engines in the browser using WebAssembly keep on growing. DuckDB means browsers now have a fast, intuitive mechanism for querying Parquet files too. This also supports the same HTTP Range header trick as the SQLite demo from a while back, meaning it can query large databases loaded over HTTP without downloading the whole file.
SQLite: STRICT Tables (draft). Draft documentation for a feature that sounds like it could be arriving in SQLite 3.37 (the next release)—adding a “STRICT” table-option keyword to a CREATE TABLE statement will cause the table to strictly enforce typing rules for data in that table, rejecting inserts that fail to match the column’s datatypes.
I’ve seen many programmers dismiss SQLite due to its loose typing, so this feature is really exciting to me: it will hopefully remove a common objection to embracing SQLite for projects.
Datasette on Codespaces, sqlite-utils API reference documentation and other weeknotes
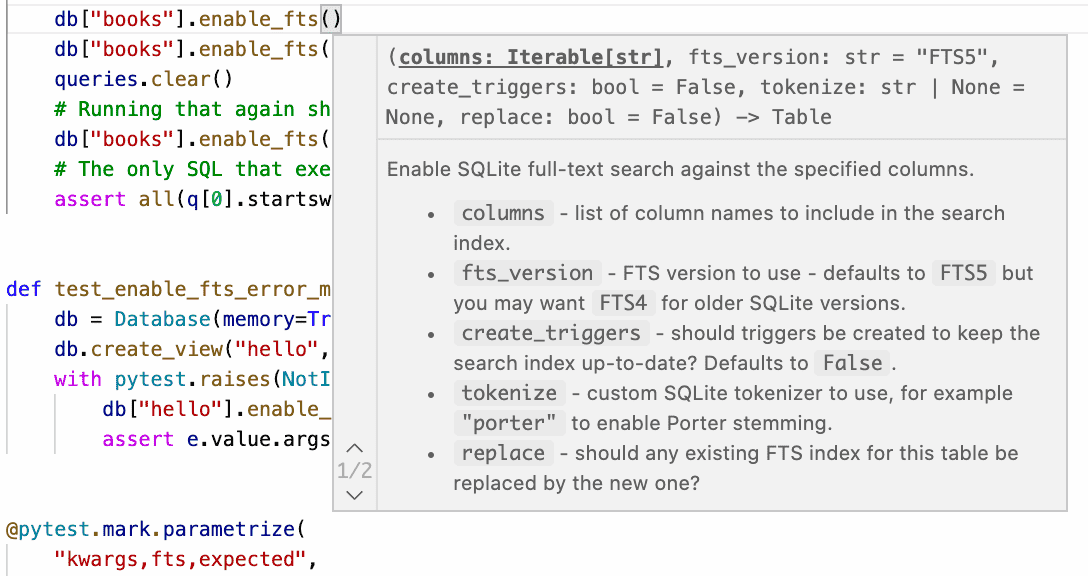
This week I broke my streak of not sending out the Datasette newsletter, figured out how to use Sphinx for Python class documentation, worked out how to run Datasette on GitHub Codespaces, implemented Datasette column metadata and got tantalizingly close to a solution for an elusive Datasette feature.
[... 2,164 words]Bare columns in an aggregate queries. This is a really nice SQL tweak implemented in SQLite: If you run a query like “SELECT a, b, max(c) FROM tab1 GROUP BY a” SQLite will find the row with the highest value for c and use the columns of that row as the returned values for the other columns mentioned in the query.