32 posts tagged “seo”
2024
SQL Has Problems. We Can Fix Them: Pipe Syntax In SQL (via) A new paper from Google Research describing custom syntax for analytical SQL queries that has been rolling out inside Google since February, reaching 1,600 "seven-day-active users" by August 2024.
A key idea is here is to fix one of the biggest usability problems with standard SQL: the order of the clauses in a query. Starting with SELECT instead of FROM has always been confusing, see SQL queries don't start with SELECT by Julia Evans.
Here's an example of the new alternative syntax, taken from the Pipe query syntax documentation that was added to Google's open source ZetaSQL project last week.
For this SQL query:
SELECT component_id, COUNT(*)
FROM ticketing_system_table
WHERE
assignee_user.email = 'username@email.com'
AND status IN ('NEW', 'ASSIGNED', 'ACCEPTED')
GROUP BY component_id
ORDER BY component_id DESC;The Pipe query alternative would look like this:
FROM ticketing_system_table
|> WHERE
assignee_user.email = 'username@email.com'
AND status IN ('NEW', 'ASSIGNED', 'ACCEPTED')
|> AGGREGATE COUNT(*)
GROUP AND ORDER BY component_id DESC;
The Google Research paper is released as a two-column PDF. I snarked about this on Hacker News:
Google: you are a web company. Please learn to publish your research papers as web pages.
This remains a long-standing pet peeve of mine. PDFs like this are horrible to read on mobile phones, hard to copy-and-paste from, have poor accessibility (see this Mastodon conversation) and are generally just bad citizens of the web.
Having complained about this I felt compelled to see if I could address it myself. Google's own Gemini Pro 1.5 model can process PDFs, so I uploaded the PDF to Google AI Studio and prompted the gemini-1.5-pro-exp-0801 model like this:
Convert this document to neatly styled semantic HTML
This worked surprisingly well. It output HTML for about half the document and then stopped, presumably hitting the output length limit, but a follow-up prompt of "and the rest" caused it to continue from where it stopped and run until the end.
Here's the result (with a banner I added at the top explaining that it's a conversion): Pipe-Syntax-In-SQL.html
I haven't compared the two completely, so I can't guarantee there are no omissions or mistakes.
The figures from the PDF aren't present - Gemini Pro output tags like <img src="figure1.png" alt="Figure 1: SQL syntactic clause order doesn't match semantic evaluation order. (From [25].)"> but did nothing to help me create those images.
Amusingly the document ends with <p>(A long list of references, which I won't reproduce here to save space.)</p> rather than actually including the references from the paper!
So this isn't a perfect solution, but considering it took just the first prompt I could think of it's a very promising start. I expect someone willing to spend more than the couple of minutes I invested in this could produce a very useful HTML alternative version of the paper with the assistance of Gemini Pro.
One last amusing note: I posted a link to this to Hacker News a few hours ago. Just now when I searched Google for the exact title of the paper my HTML version was already the third result!
I've now added a <meta name="robots" content="noindex, follow"> tag to the top of the HTML to keep this unverified AI slop out of their search index. This is a good reminder of how much better HTML is than PDF for sharing information on the web!
Google is the only search engine that works on Reddit now thanks to AI deal (via) This is depressing. As of around June 25th reddit.com/robots.txt contains this:
User-agent: *
Disallow: /
Along with a link to Reddit's Public Content Policy.
Is this a direct result of Google's deal to license Reddit content for AI training, rumored at $60 million? That's not been confirmed but it looks likely, especially since accessing that robots.txt using the Google Rich Results testing tool (hence proxied via their IP) appears to return a different file, via this comment, my copy here.
Give people something to link to so they can talk about your features and ideas
If you have a project, an idea, a product feature, or anything else that you want other people to understand and have conversations about... give them something to link to!
[... 685 words]2022
Weeknotes: python_requires, documentation SEO
Fixed Datasette on Python 3.6 for the last time. Worked on documentation infrastructure improvements. Spent some time with Fly Volumes.
[... 1,497 words]2020
datasette-block-robots.
Another little Datasette plugin: this one adds a /robots.txt page with Disallow: / to block all indexing of a Datasette instance from respectable search engine crawlers. I built this in less than ten minutes from idea to deploy to PyPI thanks to the datasette-plugin cookiecutter template.
Building a sitemap.xml with a one-off Datasette plugin
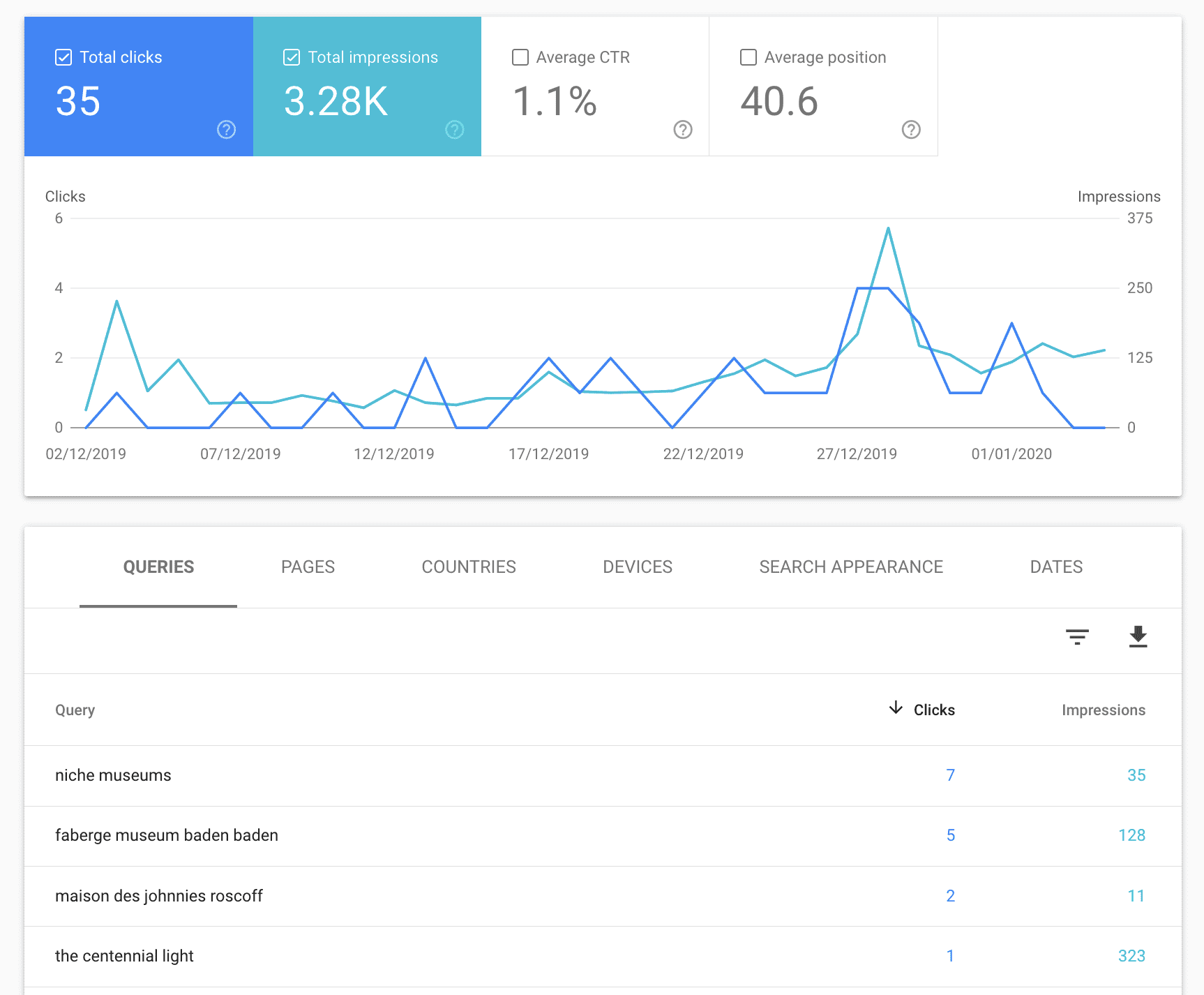
One of the fun things about launching a new website is re-learning what it takes to promote a website from scratch on the modern web. I’ve been thoroughly enjoying using Niche Museums as an excuse to explore 2020-era SEO.
[... 1,078 words]2019
Evolving “nofollow” – new ways to identify the nature of links (via) Slightly confusing announcement from Google: they’re introducing rel=ugc and rel=sponsored in addition to rel=nofollow, and will be treating all three values as “hints” for their indexing system. They’re very unclear as to what the concrete effects of these hints will be, presumably because they will become part of the secret sauce of their ranking algorithm.
2018
Googlebot’s Javascript random() function is deterministic. random() as executed by Googlebot returns the same predicable sequence. More interestingly, Googlebot runs a much faster timer for setTimeout and setInterval—as Tom Anthony points out, “Why actually wait 5 seconds when you are a bot?”
2017
What is the plural of blitz? Wow, WordHippo is a straight up masterclass in keyword SEO tactics. Everything from the page URL to the keyword-crammed content to the enormous quantity of related links.
2014
Whether 404 custom error page necessary for a website?
They aren’t required, but if you don’t have a custom 404 page you’re missing out on a very easy way of improving the user experience of your site, and protecting against expired or incorrect links from elsewhere on the web.
[... 98 words]2013
What are good sources to learn about SEO?
The Beginner’s Guide to SEO from Moz (previously SEOMoz) is an excellent introduction to SEO fundamentals.
Do comments really count for SEO link building?
Most sensible commenting systems will put rel=nofollow on links to discourage comment spam, which will have a significant effect on SEO.
[... 35 words]2012
What are the ways to Convert Dynamic JSP pages to a Static HTML to Appear in Google search results?
You don’t have to do anything. You’re misunderstanding how dynamic server-side languages like JSP work.
[... 202 words]What is the optimal description length in the Apple App Store?
Have you ever come across one if those ugly, long pages advertising an ebook—the ones that bang on for dozens of paragraphs with bullet points, pictures, testimonials, headings, more testimonials, more bullet points and so on?
[... 106 words]Why does Google use “Allow” in robots.txt, when the standard seems to be “Disallow?”
The Disallow command prevents search engines from crawling your site.
[... 59 words]Why is Google indexing & displaying www1 versions of my site and how might I stop this?
You should stop serving your site to the public on multiple subdomains. Configure your site to serve a 301 permanent redirect from www1-www4 to the equivalent page on www—also, make sure that your site accessed without the www redirects to the right place as well.
[... 269 words]What are the best SEO conferences around Cincinnati?
It doesn’t look like there are many (any?) SEO events in Cincinnati, but Chicago has has SES in November 2012: http://sesconference.com/chicago/
[... 36 words]2011
Does domain name masking negatively effect SEO?
Yes, because you’ve made it impossible for people to share links to sub-pages on your site—which means you won’t get incoming links to those pages, a crucial ranking metric.
[... 44 words]2010
Is it a good idea to allocate URLs such as quora.com/username to users?
There’s an interesting discussion about this issue on this question: How do sites prevent vanity URLs from colliding with future features ?
[... 42 words]If I have data that loads using json / JavaScript will it get indexed by Google?
No. Personally I dislike sites with content that is only accessible through JavaScript, but if you absolutely insist on doing this you should look in to implementing the Google Ajax Crawling mechanism: http://code.google.com/web/ajaxc...
[... 56 words]Great Literature Retitled To Boost Website Traffic (via) “7 Awesome Ways Barnyard Animals Are Like Communism”.
I’m renaming the book to “Dive Into HTML 5” for better SEO. This is not a joke. The book is the #5 search result for “HTML5” (no space) but #13 for “HTML 5” (with a space). I get 514 visitors a day searching Google for “HTML5” but only 53 visitors a day searching for “HTML 5”.
2009
Official Google Webmaster Blog: A proposal for making AJAX crawlable.
It's horrible! The Google crawler would map url#!state to url?_escaped_fragment_=state, then expect your site to provide rendered HTML that reflects that state (they even go as far as to suggest running a headless browser within your web server to do this). Just stick to progressive enhancement instead, it's far less hideous. It looks like the proposal may have originated with the GWT team.
Specify your canonical. You can now use a link rel=“canonical” to tell Google that a page has a canonical URL elsewhere. I’ve run in to this problem a bunch of times—in some sites it really does make sense to have the same content shown in two different places—and this seems like a neat solution that could apply to much more than just metadata for external search engines.
2008
Underscores are now word separators, proclaims Google. I missed this story last year—the change was announced by Matt Cutts at WordCamp 2007.
Search Engine Optimization Through Hoax News. Devious new black-hat SEO technique: invent a news story that’s pure link-bait. The recent “13 year old steals dad’s credit card to buy hookers” story was a hoax: it was a pure play for PageRank.
2007
Some thoughts on Mahalo. Rich Skrenta with notes on running a large site that lives and dies by SEO traffic.
If you're designing social media systems, you should be keeping an eye on the $2B industry that sells links from your site to their clients.
Why people hate SEO... (and why SMO is bulls$%t). Jason Calacanis explains SMO, or “Social Media Optimisation”—digg spamming now has its own TLA.
2004
The dangers of PageRank
A well documented side effect of the weblog format is that it brings Google PageRank in almost absurd quantities. I’m now the 5th result for simon on Google, and I’ve been the top result for simon willison almost since the day I launched. High rankings however are not always a good thing, especially when combined with a comment system. A growing number of bloggers have found themselves at the top position for terms of little or no relevance to the rest of their sites, which in turn can attract truly surreal comments from visitors from search engines who may never have encountered a blog before.
[... 469 words]