610 posts tagged “llm”
LLM is my command-line tool for running prompts against Large Language Models.
2025
Initial impressions of Llama 4
Dropping a model release as significant as Llama 4 on a weekend is plain unfair! So far the best place to learn about the new model family is this post on the Meta AI blog. They’ve released two new models today: Llama 4 Maverick is a 400B model (128 experts, 17B active parameters), text and image input with a 1 million token context length. Llama 4 Scout is 109B total parameters (16 experts, 17B active), also multi-modal and with a claimed 10 million token context length—an industry first.
[... 1,468 words]Gemini 2.5 Pro Preview pricing (via) Google's Gemini 2.5 Pro is currently the top model on LM Arena and, from my own testing, a superb model for OCR, audio transcription and long-context coding.
You can now pay for it!
The new gemini-2.5-pro-preview-03-25 model ID is priced like this:
- Prompts less than 200,00 tokens: $1.25/million tokens for input, $10/million for output
- Prompts more than 200,000 tokens (up to the 1,048,576 max): $2.50/million for input, $15/million for output
This is priced at around the same level as Gemini 1.5 Pro ($1.25/$5 for input/output below 128,000 tokens, $2.50/$10 above 128,000 tokens), is cheaper than GPT-4o for shorter prompts ($2.50/$10) and is cheaper than Claude 3.7 Sonnet ($3/$15).
Gemini 2.5 Pro is a reasoning model, and invisible reasoning tokens are included in the output token count. I just tried prompting "hi" and it charged me 2 tokens for input and 623 for output, of which 613 were "thinking" tokens. That still adds up to just 0.6232 cents (less than a cent) using my LLM pricing calculator which I updated to support the new model just now.
I released llm-gemini 0.17 this morning adding support for the new model:
llm install -U llm-gemini
llm -m gemini-2.5-pro-preview-03-25 hi
Note that the model continues to be available for free under the previous gemini-2.5-pro-exp-03-25 model ID:
llm -m gemini-2.5-pro-exp-03-25 hi
The free tier is "used to improve our products", the paid tier is not.
Rate limits for the paid model vary by tier - from 150/minute and 1,000/day for tier 1 (billing configured), 1,000/minute and 50,000/day for Tier 2 ($250 total spend) and 2,000/minute and unlimited/day for Tier 3 ($1,000 total spend). Meanwhile the free tier continues to limit you to 5 requests per minute and 25 per day.
Google are retiring the Gemini 2.0 Pro preview entirely in favour of 2.5.
smartfunc. Vincent D. Warmerdam built this ingenious wrapper around my LLM Python library which lets you build LLM wrapper functions using a decorator and a docstring:
from smartfunc import backend @backend("gpt-4o") def generate_summary(text: str): """Generate a summary of the following text: {{ text }}""" pass summary = generate_summary(long_text)
It works with LLM plugins so the same pattern should work against Gemini, Claude and hundreds of others, including local models.
It integrates with more recent LLM features too, including async support and schemas, by introspecting the function signature:
class Summary(BaseModel): summary: str pros: list[str] cons: list[str] @async_backend("gpt-4o-mini") async def generate_poke_desc(text: str) -> Summary: "Describe the following pokemon: {{ text }}" pass pokemon = await generate_poke_desc("pikachu")
Vincent also recorded a 12 minute video walking through the implementation and showing how it uses Pydantic, Python's inspect module and typing.get_type_hints() function.
Nomic Embed Code: A State-of-the-Art Code Retriever. Nomic have released a new embedding model that specializes in code, based on their CoRNStack "large-scale high-quality training dataset specifically curated for code retrieval".
The nomic-embed-code model is pretty large - 26.35GB - but the announcement also mentioned a much smaller model (released 5 months ago) called CodeRankEmbed which is just 521.60MB.
I missed that when it first came out, so I decided to give it a try using my llm-sentence-transformers plugin for LLM.
llm install llm-sentence-transformers
llm sentence-transformers register nomic-ai/CodeRankEmbed --trust-remote-code
Now I can run the model like this:
llm embed -m sentence-transformers/nomic-ai/CodeRankEmbed -c 'hello'
This outputs an array of 768 numbers, starting [1.4794224500656128, -0.474479079246521, ....
Where this gets fun is combining it with my Symbex tool to create and then search embeddings for functions in a codebase.
I created an index for my LLM codebase like this:
cd llm
symbex '*' '*.*' --nl > code.txt
This creates a newline-separated JSON file of all of the functions (from '*') and methods (from '*.*') in the current directory - you can see that here.
Then I fed that into the llm embed-multi command like this:
llm embed-multi \
-d code.db \
-m sentence-transformers/nomic-ai/CodeRankEmbed \
code code.txt \
--format nl \
--store \
--batch-size 10
I found the --batch-size was needed to prevent it from crashing with an error.
The above command creates a collection called code in a SQLite database called code.db.
Having run this command I can search for functions that match a specific search term in that code collection like this:
llm similar code -d code.db \
-c 'Represent this query for searching relevant code: install a plugin' | jq
That "Represent this query for searching relevant code: " prefix is required by the model. I pipe it through jq to make it a little more readable, which gives me these results.
This jq recipe makes for a better output:
llm similar code -d code.db \
-c 'Represent this query for searching relevant code: install a plugin' | \
jq -r '.id + "\n\n" + .content + "\n--------\n"'
The output from that starts like so:
llm/cli.py:1776
@cli.command(name="plugins")
@click.option("--all", help="Include built-in default plugins", is_flag=True)
def plugins_list(all):
"List installed plugins"
click.echo(json.dumps(get_plugins(all), indent=2))
--------
llm/cli.py:1791
@cli.command()
@click.argument("packages", nargs=-1, required=False)
@click.option(
"-U", "--upgrade", is_flag=True, help="Upgrade packages to latest version"
)
...
def install(packages, upgrade, editable, force_reinstall, no_cache_dir):
"""Install packages from PyPI into the same environment as LLM"""
Getting this output was quite inconvenient, so I've opened an issue.
deepseek-ai/DeepSeek-V3-0324.
Chinese AI lab DeepSeek just released the latest version of their enormous DeepSeek v3 model, baking the release date into the name DeepSeek-V3-0324.
The license is MIT (that's new - previous DeepSeek v3 had a custom license), the README is empty and the release adds up a to a total of 641 GB of files, mostly of the form model-00035-of-000163.safetensors.
The model only came out a few hours ago and MLX developer Awni Hannun already has it running at >20 tokens/second on a 512GB M3 Ultra Mac Studio ($9,499 of ostensibly consumer-grade hardware) via mlx-lm and this mlx-community/DeepSeek-V3-0324-4bit 4bit quantization, which reduces the on-disk size to 352 GB.
I think that means if you have that machine you can run it with my llm-mlx plugin like this, but I've not tried myself!
llm mlx download-model mlx-community/DeepSeek-V3-0324-4bit
llm chat -m mlx-community/DeepSeek-V3-0324-4bit
The new model is also listed on OpenRouter. You can try a chat at openrouter.ai/chat?models=deepseek/deepseek-chat-v3-0324:free.
Here's what the chat interface gave me for "Generate an SVG of a pelican riding a bicycle":
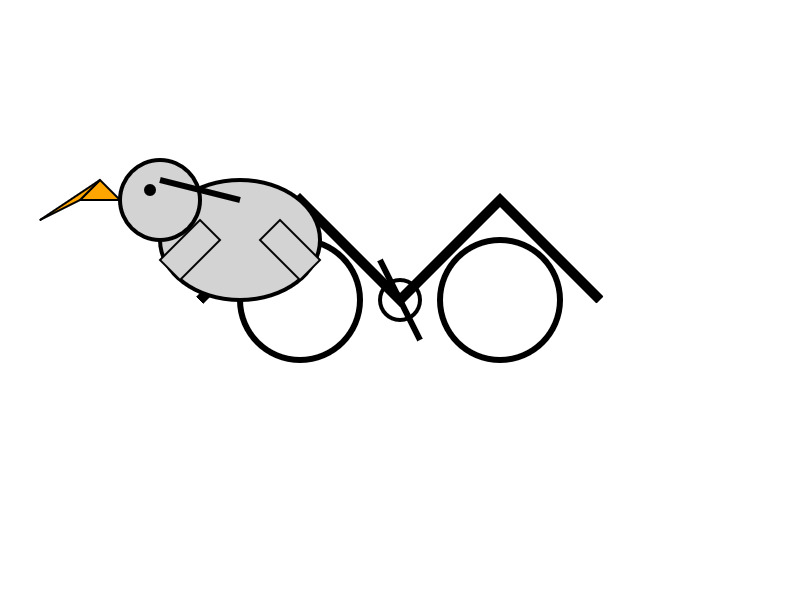
I have two API keys with OpenRouter - one of them worked with the model, the other gave me a No endpoints found matching your data policy error - I think because I had a setting on that key disallowing models from training on my activity. The key that worked was a free key with no attached billing credentials.
For my working API key the llm-openrouter plugin let me run a prompt like this:
llm install llm-openrouter
llm keys set openrouter
# Paste key here
llm -m openrouter/deepseek/deepseek-chat-v3-0324:free "best fact about a pelican"
Here's that "best fact" - the terminal output included Markdown and an emoji combo, here that's rendered.
One of the most fascinating facts about pelicans is their unique throat pouch, called a gular sac, which can hold up to 3 gallons (11 liters) of water—three times more than their stomach!
Here’s why it’s amazing:
- Fishing Tool: They use it like a net to scoop up fish, then drain the water before swallowing.
- Cooling Mechanism: On hot days, pelicans flutter the pouch to stay cool by evaporating water.
- Built-in "Shopping Cart": Some species even use it to carry food back to their chicks.Bonus fact: Pelicans often fish cooperatively, herding fish into shallow water for an easy catch.
Would you like more cool pelican facts? 🐦🌊
In putting this post together I got Claude to build me this new tool for finding the total on-disk size of a Hugging Face repository, which is available in their API but not currently displayed on their website.
Update: Here's a notable independent benchmark from Paul Gauthier:
DeepSeek's new V3 scored 55% on aider's polyglot benchmark, significantly improving over the prior version. It's the #2 non-thinking/reasoning model, behind only Sonnet 3.7. V3 is competitive with thinking models like R1 & o3-mini.
OpenAI platform: o1-pro. OpenAI have a new most-expensive model: o1-pro can now be accessed through their API at a hefty $150/million tokens for input and $600/million tokens for output. That's 10x the price of their o1 and o1-preview models and a full 1,000x times more expensive than their cheapest model, gpt-4o-mini!
Aside from that it has mostly the same features as o1: a 200,000 token context window, 100,000 max output tokens, Sep 30 2023 knowledge cut-off date and it supports function calling, structured outputs and image inputs.
o1-pro doesn't support streaming, and most significantly for developers is the first OpenAI model to only be available via their new Responses API. This means tools that are built against their Chat Completions API (like my own LLM) have to do a whole lot more work to support the new model - my issue for that is here.
Since LLM doesn't support this new model yet I had to make do with curl:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o1-pro",
"input": "Generate an SVG of a pelican riding a bicycle"
}'
Here's the full JSON I got back - 81 input tokens and 1552 output tokens for a total cost of 94.335 cents.

I took a risk and added "reasoning": {"effort": "high"} to see if I could get a better pelican with more reasoning:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o1-pro",
"input": "Generate an SVG of a pelican riding a bicycle",
"reasoning": {"effort": "high"}
}'
Surprisingly that used less output tokens - 1459 compared to 1552 earlier (cost: 88.755 cents) - producing this JSON which rendered as a slightly better pelican:

It was cheaper because while it spent 960 reasoning tokens as opposed to 704 for the previous pelican it omitted the explanatory text around the SVG, saving on total output.
Mistral Small 3.1. Mistral Small 3 came out in January and was a notable, genuinely excellent local model that used an Apache 2.0 license.
Mistral Small 3.1 offers a significant improvement: it's multi-modal (images) and has an increased 128,000 token context length, while still "fitting within a single RTX 4090 or a 32GB RAM MacBook once quantized" (according to their model card). Mistral's own benchmarks show it outperforming Gemma 3 and GPT-4o Mini, but I haven't seen confirmation from external benchmarks.
Despite their mention of a 32GB MacBook I haven't actually seen any quantized GGUF or MLX releases yet, which is a little surprising since they partnered with Ollama on launch day for their previous Mistral Small 3. I expect we'll see various quantized models released by the community shortly.
Update 20th March 2025: I've now run the text version on my laptop using mlx-community/Mistral-Small-3.1-Text-24B-Instruct-2503-8bit and llm-mlx:
llm mlx download-model mlx-community/Mistral-Small-3.1-Text-24B-Instruct-2503-8bit -a mistral-small-3.1
llm chat -m mistral-small-3.1
The model can be accessed via Mistral's La Plateforme API, which means you can use it via my llm-mistral plugin.
Here's the model describing my photo of two pelicans in flight:
{kind=link}
llm install llm-mistral
# Run this if you have previously installed the plugin:
llm mistral refresh
llm -m mistral/mistral-small-2503 'describe' \
-a https://static.simonwillison.net/static/2025/two-pelicans.jpg
The image depicts two brown pelicans in flight against a clear blue sky. Pelicans are large water birds known for their long bills and large throat pouches, which they use for catching fish. The birds in the image have long, pointed wings and are soaring gracefully. Their bodies are streamlined, and their heads and necks are elongated. The pelicans appear to be in mid-flight, possibly gliding or searching for food. The clear blue sky in the background provides a stark contrast, highlighting the birds' silhouettes and making them stand out prominently.
I added Mistral's API prices to my tools.simonwillison.net/llm-prices pricing calculator by pasting screenshots of Mistral's pricing tables into Claude.
mlx-community/OLMo-2-0325-32B-Instruct-4bit (via) OLMo 2 32B claims to be "the first fully-open model (all data, code, weights, and details are freely available) to outperform GPT3.5-Turbo and GPT-4o mini". Thanks to the MLX project here's a recipe that worked for me to run it on my Mac, via my llm-mlx plugin.
To install the model:
llm install llm-mlx
llm mlx download-model mlx-community/OLMo-2-0325-32B-Instruct-4bit
That downloads 17GB to ~/.cache/huggingface/hub/models--mlx-community--OLMo-2-0325-32B-Instruct-4bit.
To start an interactive chat with OLMo 2:
llm chat -m mlx-community/OLMo-2-0325-32B-Instruct-4bit
Or to run a prompt:
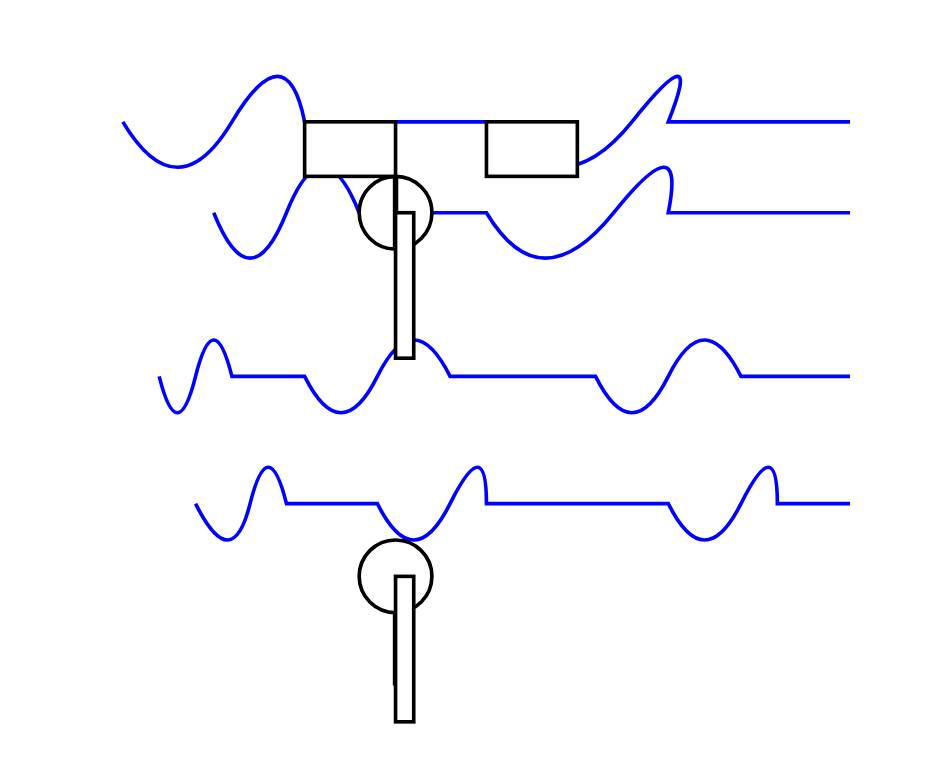
llm -m mlx-community/OLMo-2-0325-32B-Instruct-4bit 'Generate an SVG of a pelican riding a bicycle' -o unlimited 1
The -o unlimited 1 removes the cap on the number of output tokens - the default for llm-mlx is 1024 which isn't enough to attempt to draw a pelican.
The pelican it drew is refreshingly abstract:
Adding AI-generated descriptions to my tools collection

The /colophon page on my tools.simonwillison.net site lists all 78 of the HTML+JavaScript tools I’ve built (with AI assistance) along with their commit histories, including links to prompting transcripts. I wrote about how I built that colophon the other day. It now also includes a description of each tool, generated using Claude 3.7 Sonnet.
[... 741 words]Introducing Command A: Max performance, minimal compute (via) New LLM release from Cohere. It's interesting to see which aspects of the model they're highlighting, as an indicator of what their commercial customers value the most (highlights mine):
Command A delivers maximum performance with minimal hardware costs when compared to leading proprietary and open-weights models, such as GPT-4o and DeepSeek-V3. For private deployments, Command A excels on business-critical agentic and multilingual tasks, while being deployable on just two GPUs, compared to other models that typically require as many as 32. [...]
With a serving footprint of just two A100s or H100s, it requires far less compute than other comparable models on the market. This is especially important for private deployments. [...]
Its 256k context length (2x most leading models) can handle much longer enterprise documents. Other key features include Cohere’s advanced retrieval-augmented generation (RAG) with verifiable citations, agentic tool use, enterprise-grade security, and strong multilingual performance.
It's open weights but very much not open source - the license is Creative Commons Attribution Non-Commercial and also requires adhering to their Acceptable Use Policy.
Cohere offer it for commercial use via "contact us" pricing or through their API. I released llm-command-r 0.3 adding support for this new model, plus their smaller and faster Command R7B (released in December) and support for structured outputs via LLM schemas.
(I found a weird bug with their schema support where schemas that end in an integer output a seemingly limitless integer - in my experiments it affected Command R and the new Command A but not Command R7B.)
OpenAI API: Responses vs. Chat Completions. OpenAI released a bunch of new API platform features this morning under the headline "New tools for building agents" (their somewhat mushy interpretation of "agents" here is "systems that independently accomplish tasks on behalf of users").
A particularly significant change is the introduction of a new Responses API, which is a slightly different shape from the Chat Completions API that they've offered for the past couple of years and which others in the industry have widely cloned as an ad-hoc standard.
In this guide they illustrate the differences, with a reassuring note that:
The Chat Completions API is an industry standard for building AI applications, and we intend to continue supporting this API indefinitely. We're introducing the Responses API to simplify workflows involving tool use, code execution, and state management. We believe this new API primitive will allow us to more effectively enhance the OpenAI platform into the future.
An API that is going away is the Assistants API, a perpetual beta first launched at OpenAI DevDay in 2023. The new responses API solves effectively the same problems but better, and assistants will be sunset "in the first half of 2026".
The best illustration I've seen of the differences between the two is this giant commit to the openai-python GitHub repository updating ALL of the example code in one go.
The most important feature of the Responses API (a feature it shares with the old Assistants API) is that it can manage conversation state on the server for you. An oddity of the Chat Completions API is that you need to maintain your own records of the current conversation, sending back full copies of it with each new prompt. You end up making API calls that look like this (from their examples):
{
"model": "gpt-4o-mini",
"messages": [
{
"role": "user",
"content": "knock knock.",
},
{
"role": "assistant",
"content": "Who's there?",
},
{
"role": "user",
"content": "Orange."
}
]
}These can get long and unwieldy - especially when attachments such as images are involved - but the real challenge is when you start integrating tools: in a conversation with tool use you'll need to maintain that full state and drop messages in that show the output of the tools the model requested. It's not a trivial thing to work with.
The new Responses API continues to support this list of messages format, but you also get the option to outsource that to OpenAI entirely: you can add a new "store": true property and then in subsequent messages include a "previous_response_id: response_id key to continue that conversation.
This feels a whole lot more natural than the Assistants API, which required you to think in terms of threads, messages and runs to achieve the same effect.
Also fun: the Response API supports HTML form encoding now in addition to JSON:
curl https://api.openai.com/v1/responses \
-u :$OPENAI_API_KEY \
-d model="gpt-4o" \
-d input="What is the capital of France?"
I found that in an excellent Twitter thread providing background on the design decisions in the new API from OpenAI's Atty Eleti. Here's a nitter link for people who don't have a Twitter account.
New built-in tools
A potentially more exciting change today is the introduction of default tools that you can request while using the new Responses API. There are three of these, all of which can be specified in the "tools": [...] array.
{"type": "web_search_preview"}- the same search feature available through ChatGPT. The documentation doesn't clarify which underlying search engine is used - I initially assumed Bing, but the tool documentation links to this Overview of OpenAI Crawlers page so maybe it's entirely in-house now? Web search is priced at between $25 and $50 per thousand queries depending on if you're using GPT-4o or GPT-4o mini and the configurable size of your "search context".{"type": "file_search", "vector_store_ids": [...]}provides integration with the latest version of their file search vector store, mainly used for RAG. "Usage is priced at $2.50 per thousand queries and file storage at $0.10/GB/day, with the first GB free".{"type": "computer_use_preview", "display_width": 1024, "display_height": 768, "environment": "browser"}is the most surprising to me: it's tool access to the Computer-Using Agent system they built for their Operator product. This one is going to be a lot of fun to explore. The tool's documentation includes a warning about prompt injection risks. Though on closer inspection I think this may work more like Claude Computer Use, where you have to run the sandboxed environment yourself rather than outsource that difficult part to them.
I'm still thinking through how to expose these new features in my LLM tool, which is made harder by the fact that a number of plugins now rely on the default OpenAI implementation from core, which is currently built on top of Chat Completions. I've been worrying for a while about the impact of our entire industry building clones of one proprietary API that might change in the future, I guess now we get to see how that shakes out!
llm-openrouter 0.4. I found out this morning that OpenRouter include support for a number of (rate-limited) free API models.
I occasionally run workshops on top of LLMs (like this one) and being able to provide students with a quick way to obtain an API key against models where they don't have to setup billing is really valuable to me!
This inspired me to upgrade my existing llm-openrouter plugin, and in doing so I closed out a bunch of open feature requests.
Consider this post the annotated release notes:
- LLM schema support for OpenRouter models that support structured output. #23
I'm trying to get support for LLM's new schema feature into as many plugins as possible.
OpenRouter's OpenAI-compatible API includes support for the response_format structured content option, but with an important caveat: it only works for some models, and if you try to use it on others it is silently ignored.
I filed an issue with OpenRouter requesting they include schema support in their machine-readable model index. For the moment LLM will let you specify schemas for unsupported models and will ignore them entirely, which isn't ideal.
llm openrouter keycommand displays information about your current API key. #24
Useful for debugging and checking the details of your key's rate limit.
llm -m ... -o online 1enables web search grounding against any model, powered by Exa. #25
OpenRouter apparently make this feature available to every one of their supported models! They're using new-to-me Exa to power this feature, an AI-focused search engine startup who appear to have built their own index with their own crawlers (according to their FAQ). This feature is currently priced by OpenRouter at $4 per 1000 results, and since 5 results are returned for every prompt that's 2 cents per prompt.
llm openrouter modelscommand for listing details of the OpenRouter models, including a--jsonoption to get JSON and a--freeoption to filter for just the free models. #26
This offers a neat way to list the available models. There are examples of the output in the comments on the issue.
- New option to specify custom provider routing:
-o provider '{JSON here}'. #17
Part of OpenRouter's USP is that it can route prompts to different providers depending on factors like latency, cost or as a fallback if your first choice is unavailable - great for if you are using open weight models like Llama which are hosted by competing companies.
The options they provide for routing are very thorough - I had initially hoped to provide a set of CLI options that covered all of these bases, but I decided instead to reuse their JSON format and forward those options directly on to the model.
State-of-the-art text embedding via the Gemini API
(via)
Gemini just released their new text embedding model, with the snappy name gemini-embedding-exp-03-07. It supports 8,000 input tokens - up from 3,000 - and outputs vectors that are a lot larger than their previous text-embedding-004 model - that one output size 768 vectors, the new model outputs 3072.
Storing that many floating point numbers for each embedded record can use a lot of space. thankfully, the new model supports Matryoshka Representation Learning - this means you can simply truncate the vectors to trade accuracy for storage.
I added support for the new model in llm-gemini 0.14. LLM doesn't yet have direct support for Matryoshka truncation so I instead registered different truncated sizes of the model under different IDs: gemini-embedding-exp-03-07-2048, gemini-embedding-exp-03-07-1024, gemini-embedding-exp-03-07-512, gemini-embedding-exp-03-07-256, gemini-embedding-exp-03-07-128.
The model is currently free while it is in preview, but comes with a strict rate limit - 5 requests per minute and just 100 requests a day. I quickly tripped those limits while testing out the new model - I hope they can bump those up soon.