610 posts tagged “llm”
LLM is my command-line tool for running prompts against Large Language Models.
2025
llm-ollama 0.9.0.
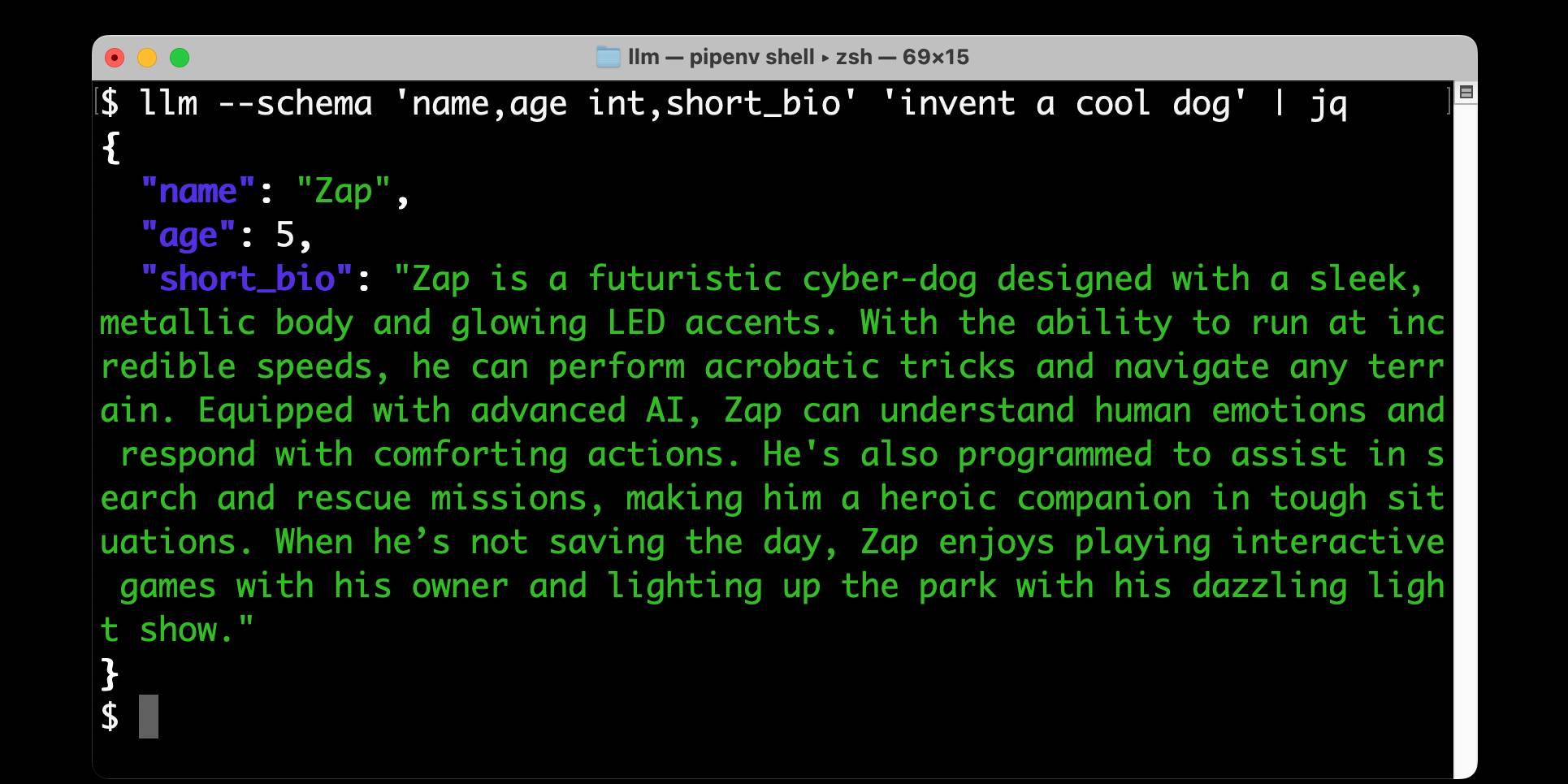
This release of the llm-ollama plugin adds support for schemas, thanks to a PR by Adam Compton.
Ollama provides very robust support for this pattern thanks to their structured outputs feature, which works across all of the models that they support by intercepting the logic that outputs the next token and restricting it to only tokens that would be valid in the context of the provided schema.
With Ollama and llm-ollama installed you can run even run structured schemas against vision prompts for local models. Here's one against Ollama's llama3.2-vision:
llm -m llama3.2-vision:latest \
'describe images' \
--schema 'species,description,count int' \
-a https://static.simonwillison.net/static/2025/two-pelicans.jpg
I got back this:
{
"species": "Pelicans",
"description": "The image features a striking brown pelican with its distinctive orange beak, characterized by its large size and impressive wingspan.",
"count": 1
}
(Actually a bit disappointing, as there are two pelicans and their beaks are brown.)
{kind=link}
llm-mistral 0.11. I added schema support to this plugin which adds support for the Mistral API to LLM. Release notes:
Schemas now work with OpenAI, Anthropic, Gemini and Mistral hosted models, plus self-hosted models via Ollama and llm-ollama.
llm-anthropic #24: Use new URL parameter to send attachments. Anthropic released a neat quality of life improvement today. Alex Albert:
We've added the ability to specify a public facing URL as the source for an image / document block in the Anthropic API
Prior to this, any time you wanted to send an image to the Claude API you needed to base64-encode it and then include that data in the JSON. This got pretty bulky, especially in conversation scenarios where the same image data needs to get passed in every follow-up prompt.
I implemented this for llm-anthropic and shipped it just now in version 0.15.1 (here's the commit) - I went with a patch release version number bump because this is effectively a performance optimization which doesn't provide any new features, previously LLM would accept URLs just fine and would download and then base64 them behind the scenes.
In testing this out I had a really impressive result from Claude 3.7 Sonnet. I found a newspaper page from 1900 on the Library of Congress (the "Worcester spy.") and fed a URL to the PDF into Sonnet like this:
llm -m claude-3.7-sonnet \
-a 'https://tile.loc.gov/storage-services/service/ndnp/mb/batch_mb_gaia_ver02/data/sn86086481/0051717161A/1900012901/0296.pdf' \
'transcribe all text from this image, formatted as markdown'

I haven't checked every sentence but it appears to have done an excellent job, at a cost of 16 cents.
As another experiment, I tried running that against my example people template from the schemas feature I released this morning:
llm -m claude-3.7-sonnet \
-a 'https://tile.loc.gov/storage-services/service/ndnp/mb/batch_mb_gaia_ver02/data/sn86086481/0051717161A/1900012901/0296.pdf' \
-t people
That only gave me two results - so I tried an alternative approach where I looped the OCR text back through the same template, using llm logs --cid with the logged conversation ID and -r to extract just the raw response from the logs:
llm logs --cid 01jn7h45x2dafa34zk30z7ayfy -r | \
llm -t people -m claude-3.7-sonnet
... and that worked fantastically well! The result started like this:
{
"items": [
{
"name": "Capt. W. R. Abercrombie",
"organization": "United States Army",
"role": "Commander of Copper River exploring expedition",
"learned": "Reported on the horrors along the Copper River in Alaska, including starvation, scurvy, and mental illness affecting 70% of people. He was tasked with laying out a trans-Alaskan military route and assessing resources.",
"article_headline": "MUCH SUFFERING",
"article_date": "1900-01-28"
},
{
"name": "Edward Gillette",
"organization": "Copper River expedition",
"role": "Member of the expedition",
"learned": "Contributed a chapter to Abercrombie's report on the feasibility of establishing a railroad route up the Copper River valley, comparing it favorably to the Seattle to Skaguay route.",
"article_headline": "MUCH SUFFERING",
"article_date": "1900-01-28"
}Structured data extraction from unstructured content using LLM schemas
LLM 0.23 is out today, and the signature feature is support for schemas—a new way of providing structured output from a model that matches a specification provided by the user. I’ve also upgraded both the llm-anthropic and llm-gemini plugins to add support for schemas.
[... 2,601 words]Gemini 2.0 Flash and Flash-Lite (via) Gemini 2.0 Flash-Lite is now generally available - previously it was available just as a preview - and has announced pricing. The model is $0.075/million input tokens and $0.030/million output - the same price as Gemini 1.5 Flash.
Google call this "simplified pricing" because 1.5 Flash charged different cost-per-tokens depending on if you used more than 128,000 tokens. 2.0 Flash-Lite (and 2.0 Flash) are both priced the same no matter how many tokens you use.
I released llm-gemini 0.12 with support for the new gemini-2.0-flash-lite model ID. I've also updated my LLM pricing calculator with the new prices.
Claude 3.7 Sonnet, extended thinking and long output, llm-anthropic 0.14

Claude 3.7 Sonnet (previously) is a very interesting new model. I released llm-anthropic 0.14 last night adding support for the new model’s features to LLM. I learned a whole lot about the new model in the process of building that plugin.
[... 1,491 words]Claude 3.7 Sonnet and Claude Code. Anthropic released Claude 3.7 Sonnet today - skipping the name "Claude 3.6" because the Anthropic user community had already started using that as the unofficial name for their October update to 3.5 Sonnet.
As you may expect, 3.7 Sonnet is an improvement over 3.5 Sonnet - and is priced the same, at $3/million tokens for input and $15/m output.
The big difference is that this is Anthropic's first "reasoning" model - applying the same trick that we've now seen from OpenAI o1 and o3, Grok 3, Google Gemini 2.0 Thinking, DeepSeek R1 and Qwen's QwQ and QvQ. The only big model families without an official reasoning model now are Mistral and Meta's Llama.
I'm still working on adding support to my llm-anthropic plugin but I've got enough working code that I was able to get it to draw me a pelican riding a bicycle. Here's the non-reasoning model:

And here's that same prompt but with "thinking mode" enabled:

Here's the transcript for that second one, which mixes together the thinking and the output tokens. I'm still working through how best to differentiate between those two types of token.
Claude 3.7 Sonnet has a training cut-off date of Oct 2024 - an improvement on 3.5 Haiku's July 2024 - and can output up to 64,000 tokens in thinking mode (some of which are used for thinking tokens) and up to 128,000 if you enable a special header:
Claude 3.7 Sonnet can produce substantially longer responses than previous models with support for up to 128K output tokens (beta)---more than 15x longer than other Claude models. This expanded capability is particularly effective for extended thinking use cases involving complex reasoning, rich code generation, and comprehensive content creation.
This feature can be enabled by passing an
anthropic-betaheader ofoutput-128k-2025-02-19.
Anthropic's other big release today is a preview of Claude Code - a CLI tool for interacting with Claude that includes the ability to prompt Claude in terminal chat and have it read and modify files and execute commands. This means it can both iterate on code and execute tests, making it an extremely powerful "agent" for coding assistance.
Here's Anthropic's documentation on getting started with Claude Code, which uses OAuth (a first for Anthropic's API) to authenticate against your API account, so you'll need to configure billing.
Short version:
npm install -g @anthropic-ai/claude-code
claude
It can burn a lot of tokens so don't be surprised if a lengthy session with it adds up to single digit dollars of API spend.
LLM 0.22, the annotated release notes
I released LLM 0.22 this evening. Here are the annotated release notes:
[... 1,340 words]