610 posts tagged “llm”
LLM is my command-line tool for running prompts against Large Language Models.
2025
Run LLMs on macOS using llm-mlx and Apple’s MLX framework
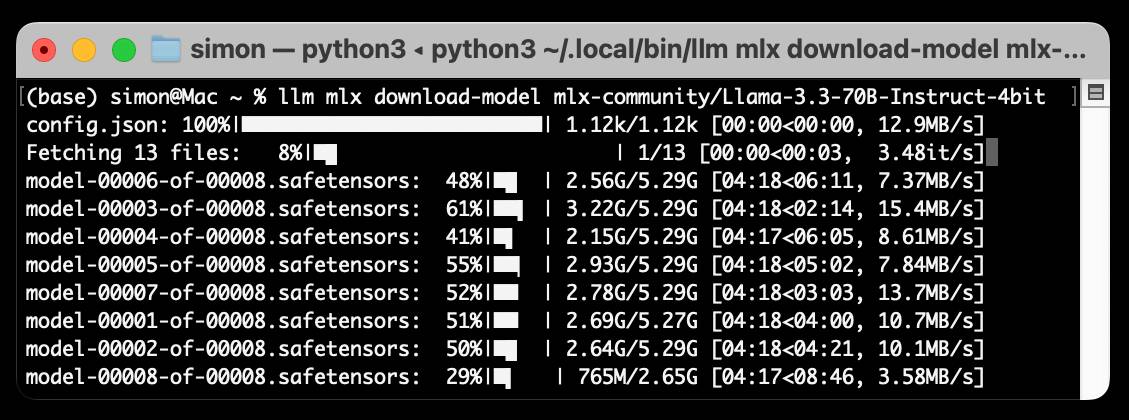
llm-mlx is a brand new plugin for my LLM Python Library and CLI utility which builds on top of Apple’s excellent MLX array framework library and mlx-lm package. If you’re a terminal user or Python developer with a Mac this may be the new easiest way to start exploring local Large Language Models.
[... 1,524 words]files-to-prompt 0.5.
My files-to-prompt tool (originally built using Claude 3 Opus back in April) had been accumulating a bunch of issues and PRs - I finally got around to spending some time with it and pushed a fresh release:
- New
-n/--line-numbersflag for including line numbers in the output. Thanks, Dan Clayton. #38- Fix for utf-8 handling on Windows. Thanks, David Jarman. #36
--ignorepatterns are now matched against directory names as well as file names, unless you pass the new--ignore-files-onlyflag. Thanks, Nick Powell. #30
I use this tool myself on an almost daily basis - it's fantastic for quickly answering questions about code. Recently I've been plugging it into Gemini 2.0 with its 2 million token context length, running recipes like this one:
git clone https://github.com/bytecodealliance/componentize-py
cd componentize-py
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'How does this work? Does it include a python compiler or AST trick of some sort?'
I ran that question against the bytecodealliance/componentize-py repo - which provides a tool for turning Python code into compiled WASM - and got this really useful answer.
Here's another example. I decided to have o3-mini review how Datasette handles concurrent SQLite connections from async Python code - so I ran this:
git clone https://github.com/simonw/datasette
cd datasette/datasette
files-to-prompt database.py utils/__init__.py -c | \
llm -m o3-mini -o reasoning_effort high \
-s 'Output in markdown a detailed analysis of how this code handles the challenge of running SQLite queries from a Python asyncio application. Explain how it works in the first section, then explore the pros and cons of this design. In a final section propose alternative mechanisms that might work better.'
Here's the result. It did an extremely good job of explaining how my code works - despite being fed just the Python and none of the other documentation. Then it made some solid recommendations for potential alternatives.
I added a couple of follow-up questions (using llm -c) which resulted in a full working prototype of an alternative threadpool mechanism, plus some benchmarks.
One final example: I decided to see if there were any undocumented features in Litestream, so I checked out the repo and ran a prompt against just the .go files in that project:
git clone https://github.com/benbjohnson/litestream
cd litestream
files-to-prompt . -e go -c | llm -m o3-mini \
-s 'Write extensive user documentation for this project in markdown'
Once again, o3-mini provided a really impressively detailed set of unofficial documentation derived purely from reading the source.
Nomic Embed Text V2: An Open Source, Multilingual, Mixture-of-Experts Embedding Model (via) Nomic continue to release the most interesting and powerful embedding models. Their latest is Embed Text V2, an Apache 2.0 licensed multi-lingual 1.9GB model (here it is on Hugging Face) trained on "1.6 billion high-quality data pairs", which is the first embedding model I've seen to use a Mixture of Experts architecture:
In our experiments, we found that alternating MoE layers with 8 experts and top-2 routing provides the optimal balance between performance and efficiency. This results in 475M total parameters in the model, but only 305M active during training and inference.
I first tried it out using uv run like this:
uv run \
--with einops \
--with sentence-transformers \
--python 3.13 pythonThen:
from sentence_transformers import SentenceTransformer model = SentenceTransformer("nomic-ai/nomic-embed-text-v2-moe", trust_remote_code=True) sentences = ["Hello!", "¡Hola!"] embeddings = model.encode(sentences, prompt_name="passage") print(embeddings)
Then I got it working on my laptop using the llm-sentence-tranformers plugin like this:
llm install llm-sentence-transformers
llm install einops # additional necessary package
llm sentence-transformers register nomic-ai/nomic-embed-text-v2-moe --trust-remote-code
llm embed -m sentence-transformers/nomic-ai/nomic-embed-text-v2-moe -c 'string to embed'
This outputs a 768 item JSON array of floating point numbers to the terminal. These are Matryoshka embeddings which means you can truncate that down to just the first 256 items and get similarity calculations that still work albeit slightly less well.
To use this for RAG you'll need to conform to Nomic's custom prompt format. For documents to be searched:
search_document: text of document goes here
And for search queries:
search_query: term to search for
I landed a new --prepend option for the llm embed-multi command to help with that, but it's not out in a full release just yet. (Update: it's now out in LLM 0.22.)
I also released llm-sentence-transformers 0.3 with some minor improvements to make running this model more smooth.
llm-sort (via) Delightful LLM plugin by Evangelos Lamprou which adds the ability to perform "semantic search" - allowing you to sort the contents of a file based on using a prompt against an LLM to determine sort order.
Best illustrated by these examples from the README:
llm sort --query "Which names is more suitable for a pet monkey?" names.txt
cat titles.txt | llm sort --query "Which book should I read to cook better?"
It works using this pairwise prompt, which is executed multiple times using Python's sorted(documents, key=functools.cmp_to_key(compare_callback)) mechanism:
Given the query:
{query}
Compare the following two lines:
Line A:
{docA}
Line B:
{docB}
Which line is more relevant to the query? Please answer with "Line A" or "Line B".
From the lobste.rs comments, Cole Kurashige:
I'm not saying I'm prescient, but in The Before Times I did something similar with Mechanical Turk
This made me realize that so many of the patterns we were using against Mechanical Turk a decade+ ago can provide hints about potential ways to apply LLMs.
Using pip to install a Large Language Model that’s under 100MB
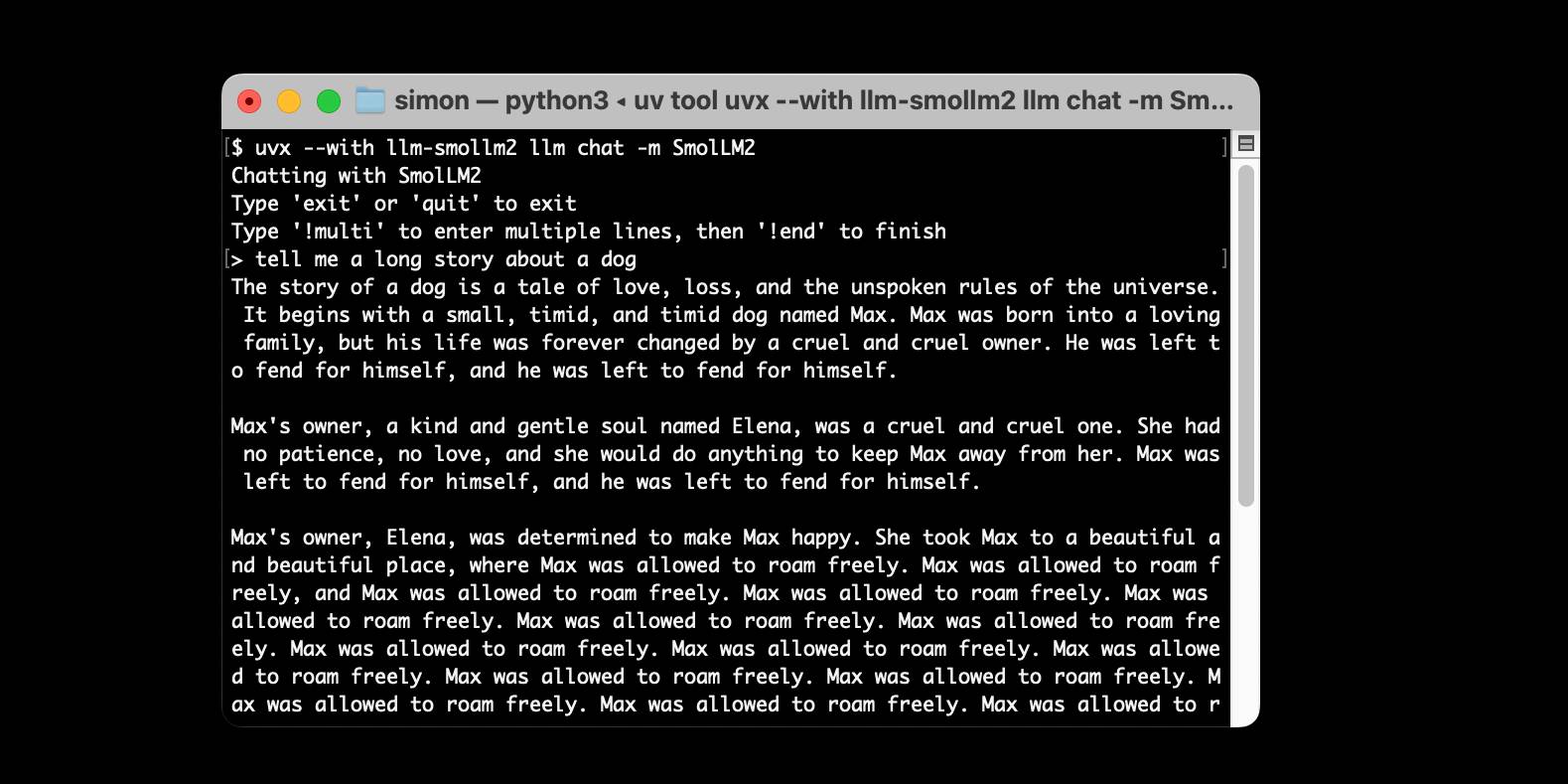
I just released llm-smollm2, a new plugin for LLM that bundles a quantized copy of the SmolLM2-135M-Instruct LLM inside of the Python package.
[... 1,553 words]Gemini 2.0 is now available to everyone. Big new Gemini 2.0 releases today:
- Gemini 2.0 Pro (Experimental) is Google's "best model yet for coding performance and complex prompts" - currently available as a free preview.
- Gemini 2.0 Flash is now generally available.
-
Gemini 2.0 Flash-Lite looks particularly interesting:
We’ve gotten a lot of positive feedback on the price and speed of 1.5 Flash. We wanted to keep improving quality, while still maintaining cost and speed. So today, we’re introducing 2.0 Flash-Lite, a new model that has better quality than 1.5 Flash, at the same speed and cost. It outperforms 1.5 Flash on the majority of benchmarks.
That means Gemini 2.0 Flash-Lite is priced at 7.5c/million input tokens and 30c/million output tokens - half the price of OpenAI's GPT-4o mini (15c/60c).
Gemini 2.0 Flash isn't much more expensive: 10c/million for text/image input, 70c/million for audio input, 40c/million for output. Again, cheaper than GPT-4o mini.
I pushed a new LLM plugin release, llm-gemini 0.10, adding support for the three new models:
llm install -U llm-gemini
llm keys set gemini
# paste API key here
llm -m gemini-2.0-flash "impress me"
llm -m gemini-2.0-flash-lite-preview-02-05 "impress me"
llm -m gemini-2.0-pro-exp-02-05 "impress me"
Here's the output for those three prompts.
I ran Generate an SVG of a pelican riding a bicycle through the three new models. Here are the results, cheapest to most expensive:
gemini-2.0-flash-lite-preview-02-05

gemini-2.0-flash

gemini-2.0-pro-exp-02-05

I also ran the same prompt I tried with o3-mini the other day:
cd /tmp
git clone https://github.com/simonw/datasette
cd datasette
files-to-prompt datasette -e py -c | \
llm -m gemini-2.0-pro-exp-02-05 \
-s 'write extensive documentation for how the permissions system works, as markdown' \
-o max_output_tokens 10000
Here's the result from that - you can compare that to o3-mini's result here.
o3-mini is really good at writing internal documentation. I wanted to refresh my knowledge of how the Datasette permissions system works today. I already have extensive hand-written documentation for that, but I thought it would be interesting to see if I could derive any insights from running an LLM against the codebase.
o3-mini has an input limit of 200,000 tokens. I used LLM and my files-to-prompt tool to generate the documentation like this:
cd /tmp
git clone https://github.com/simonw/datasette
cd datasette
files-to-prompt datasette -e py -c | \
llm -m o3-mini -s \
'write extensive documentation for how the permissions system works, as markdown'The files-to-prompt command is fed the datasette subdirectory, which contains just the source code for the application - omitting tests (in tests/) and documentation (in docs/).
The -e py option causes it to only include files with a .py extension - skipping all of the HTML and JavaScript files in that hierarchy.
The -c option causes it to output Claude's XML-ish format - a format that works great with other LLMs too.
You can see the output of that command in this Gist.
Then I pipe that result into LLM, requesting the o3-mini OpenAI model and passing the following system prompt:
write extensive documentation for how the permissions system works, as markdown
Specifically requesting Markdown is important.
The prompt used 99,348 input tokens and produced 3,118 output tokens (320 of those were invisible reasoning tokens). That's a cost of 12.3 cents.
Honestly, the results are fantastic. I had to double-check that I hadn't accidentally fed in the documentation by mistake.
(It's possible that the model is picking up additional information about Datasette in its training set, but I've seen similar high quality results from other, newer libraries so I don't think that's a significant factor.)
In this case I already had extensive written documentation of my own, but this was still a useful refresher to help confirm that the code matched my mental model of how everything works.
Documentation of project internals as a category is notorious for going out of date. Having tricks like this to derive usable how-it-works documentation from existing codebases in just a few seconds and at a cost of a few cents is wildly valuable.
OpenAI reasoning models: Advice on prompting (via) OpenAI's documentation for their o1 and o3 "reasoning models" includes some interesting tips on how to best prompt them:
- Developer messages are the new system messages: Starting with
o1-2024-12-17, reasoning models supportdevelopermessages rather thansystemmessages, to align with the chain of command behavior described in the model spec.
This appears to be a purely aesthetic change made for consistency with their instruction hierarchy concept. As far as I can tell the old system prompts continue to work exactly as before - you're encouraged to use the new developer message type but it has no impact on what actually happens.
Since my LLM tool already bakes in a llm --system "system prompt" option which works across multiple different models from different providers I'm not going to rush to adopt this new language!
- Use delimiters for clarity: Use delimiters like markdown, XML tags, and section titles to clearly indicate distinct parts of the input, helping the model interpret different sections appropriately.
Anthropic have been encouraging XML-ish delimiters for a while (I say -ish because there's no requirement that the resulting prompt is valid XML). My files-to-prompt tool has a -c option which outputs Claude-style XML, and in my experiments this same option works great with o1 and o3 too:
git clone https://github.com/tursodatabase/limbo
cd limbo/bindings/python
files-to-prompt . -c | llm -m o3-mini \
-o reasoning_effort high \
--system 'Write a detailed README with extensive usage examples'
- Limit additional context in retrieval-augmented generation (RAG): When providing additional context or documents, include only the most relevant information to prevent the model from overcomplicating its response.
This makes me thing that o1/o3 are not good models to implement RAG on at all - with RAG I like to be able to dump as much extra context into the prompt as possible and leave it to the models to figure out what's relevant.
- Try zero shot first, then few shot if needed: Reasoning models often don't need few-shot examples to produce good results, so try to write prompts without examples first. If you have more complex requirements for your desired output, it may help to include a few examples of inputs and desired outputs in your prompt. Just ensure that the examples align very closely with your prompt instructions, as discrepancies between the two may produce poor results.
Providing examples remains the single most powerful prompting tip I know, so it's interesting to see advice here to only switch to examples if zero-shot doesn't work out.
- Be very specific about your end goal: In your instructions, try to give very specific parameters for a successful response, and encourage the model to keep reasoning and iterating until it matches your success criteria.
This makes sense: reasoning models "think" until they reach a conclusion, so making the goal as unambiguous as possible leads to better results.
- Markdown formatting: Starting with
o1-2024-12-17, reasoning models in the API will avoid generating responses with markdown formatting. To signal to the model when you do want markdown formatting in the response, include the stringFormatting re-enabledon the first line of yourdevelopermessage.
This one was a real shock to me! I noticed that o3-mini was outputting • characters instead of Markdown * bullets and initially thought that was a bug.
I first saw this while running this prompt against limbo/bindings/python using files-to-prompt:
git clone https://github.com/tursodatabase/limbo
cd limbo/bindings/python
files-to-prompt . -c | llm -m o3-mini \
-o reasoning_effort high \
--system 'Write a detailed README with extensive usage examples'Here's the full result, which includes text like this (note the weird bullets):
Features
--------
• High‑performance, in‑process database engine written in Rust
• SQLite‑compatible SQL interface
• Standard Python DB‑API 2.0–style connection and cursor objects
I ran it again with this modified prompt:
Formatting re-enabled. Write a detailed README with extensive usage examples.
And this time got back proper Markdown, rendered in this Gist. That did a really good job, and included bulleted lists using this valid Markdown syntax instead:
- **`make test`**: Run tests using pytest.
- **`make lint`**: Run linters (via [ruff](https://github.com/astral-sh/ruff)).
- **`make check-requirements`**: Validate that the `requirements.txt` files are in sync with `pyproject.toml`.
- **`make compile-requirements`**: Compile the `requirements.txt` files using pip-tools.
(Using LLMs like this to get me off the ground with under-documented libraries is a trick I use several times a month.)
Update: OpenAI's Nikunj Handa:
we agree this is weird! fwiw, it’s a temporary thing we had to do for the existing o-series models. we’ll fix this in future releases so that you can go back to naturally prompting for markdown or no-markdown.
llm-anthropic.
I've renamed my llm-claude-3 plugin to llm-anthropic, on the basis that Claude 4 will probably happen at some point so this is a better name for the plugin.
If you're a previous user of llm-claude-3 you can upgrade to the new plugin like this:
llm install -U llm-claude-3
This should remove the old plugin and install the new one, because the latest llm-claude-3 depends on llm-anthropic. Just installing llm-anthropic may leave you with both plugins installed at once.
There is one extra manual step you'll need to take during this upgrade: creating a new anthropic stored key with the same API token you previously stored under claude. You can do that like so:
llm keys set anthropic --value "$(llm keys get claude)"
I released llm-anthropic 0.12 yesterday with new features not previously included in llm-claude-3:
- Support for Claude's prefill feature, using the new
-o prefill '{'option and the accompanying-o hide_prefill 1option to prevent the prefill from being included in the output text. #2- New
-o stop_sequences '```'option for specifying one or more stop sequences. To specify multiple stop sequences pass a JSON array of strings :-o stop_sequences '["end", "stop"].- Model options are now documented in the README.
If you install or upgrade llm-claude-3 you will now get llm-anthropic instead, thanks to a tiny package on PyPI which depends on the new plugin name. I created that with my pypi-rename cookiecutter template.
Here's the issue for the rename. I archived the llm-claude-3 repository on GitHub, and got to use the brand new PyPI archiving feature to archive the llm-claude-3 project on PyPI as well.
OpenAI o3-mini, now available in LLM
OpenAI’s o3-mini is out today. As with other o-series models it’s a slightly difficult one to evaluate—we now need to decide if a prompt is best run using GPT-4o, o1, o3-mini or (if we have access) o1 Pro.
[... 748 words]Mistral Small 3 (via) First model release of 2025 for French AI lab Mistral, who describe Mistral Small 3 as "a latency-optimized 24B-parameter model released under the Apache 2.0 license."
More notably, they claim the following:
Mistral Small 3 is competitive with larger models such as Llama 3.3 70B or Qwen 32B, and is an excellent open replacement for opaque proprietary models like GPT4o-mini. Mistral Small 3 is on par with Llama 3.3 70B instruct, while being more than 3x faster on the same hardware.
Llama 3.3 70B and Qwen 32B are two of my favourite models to run on my laptop - that ~20GB size turns out to be a great trade-off between memory usage and model utility. It's exciting to see a new entrant into that weight class.
The license is important: previous Mistral Small models used their Mistral Research License, which prohibited commercial deployments unless you negotiate a commercial license with them. They appear to be moving away from that, at least for their core models:
We’re renewing our commitment to using Apache 2.0 license for our general purpose models, as we progressively move away from MRL-licensed models. As with Mistral Small 3, model weights will be available to download and deploy locally, and free to modify and use in any capacity. […] Enterprises and developers that need specialized capabilities (increased speed and context, domain specific knowledge, task-specific models like code completion) can count on additional commercial models complementing what we contribute to the community.
Despite being called Mistral Small 3, this appears to be the fourth release of a model under that label. The Mistral API calls this one mistral-small-2501 - previous model IDs were mistral-small-2312, mistral-small-2402 and mistral-small-2409.
I've updated the llm-mistral plugin for talking directly to Mistral's La Plateforme API:
llm install -U llm-mistral
llm keys set mistral
# Paste key here
llm -m mistral/mistral-small-latest "tell me a joke about a badger and a puffin"
Sure, here's a light-hearted joke for you:
Why did the badger bring a puffin to the party?
Because he heard puffins make great party 'Puffins'!
(That's a play on the word "puffins" and the phrase "party people.")
API pricing is $0.10/million tokens of input, $0.30/million tokens of output - half the price of the previous Mistral Small API model ($0.20/$0.60). for comparison, GPT-4o mini is $0.15/$0.60.
Mistral also ensured that the new model was available on Ollama in time for their release announcement.
You can pull the model like this (fetching 14GB):
ollama run mistral-small:24b
The llm-ollama plugin will then let you prompt it like so:
llm install llm-ollama
llm -m mistral-small:24b "say hi"
Qwen2.5-1M: Deploy Your Own Qwen with Context Length up to 1M Tokens (via) Very significant new release from Alibaba's Qwen team. Their openly licensed (sometimes Apache 2, sometimes Qwen license, I've had trouble keeping up) Qwen 2.5 LLM previously had an input token limit of 128,000 tokens. This new model increases that to 1 million, using a new technique called Dual Chunk Attention, first described in this paper from February 2024.
They've released two models on Hugging Face: Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, both requiring CUDA and both under an Apache 2.0 license.
You'll need a lot of VRAM to run them at their full capacity:
VRAM Requirement for processing 1 million-token sequences:
- Qwen2.5-7B-Instruct-1M: At least 120GB VRAM (total across GPUs).
- Qwen2.5-14B-Instruct-1M: At least 320GB VRAM (total across GPUs).
If your GPUs do not have sufficient VRAM, you can still use Qwen2.5-1M models for shorter tasks.
Qwen recommend using their custom fork of vLLM to serve the models:
You can also use the previous framework that supports Qwen2.5 for inference, but accuracy degradation may occur for sequences exceeding 262,144 tokens.
GGUF quantized versions of the models are already starting to show up. LM Studio's "official model curator" Bartowski published lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF and lmstudio-community/Qwen2.5-14B-Instruct-1M-GGUF - sizes range from 4.09GB to 8.1GB for the 7B model and 7.92GB to 15.7GB for the 14B.
These might not work well yet with the full context lengths as the underlying llama.cpp library may need some changes.
I tried running the 8.1GB 7B model using Ollama on my Mac like this:
ollama run hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
Then with LLM:
llm install llm-ollama
llm models -q qwen # To search for the model ID
# I set a shorter q1m alias:
llm aliases set q1m hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
I tried piping a large prompt in using files-to-prompt like this:
files-to-prompt ~/Dropbox/Development/llm -e py -c | llm -m q1m 'describe this codebase in detail'
That should give me every Python file in my llm project. Piping that through ttok first told me this was 63,014 OpenAI tokens, I expect that count is similar for Qwen.
The result was disappointing: it appeared to describe just the last Python file that stream. Then I noticed the token usage report:
2,048 input, 999 output
This suggests to me that something's not working right here - maybe the Ollama hosting framework is truncating the input, or maybe there's a problem with the GGUF I'm using?
I'll update this post when I figure out how to run longer prompts through the new Qwen model using GGUF weights on a Mac.
Update: It turns out Ollama has a num_ctx option which defaults to 2048, affecting the input context length. I tried this:
files-to-prompt \
~/Dropbox/Development/llm \
-e py -c | \
llm -m q1m 'describe this codebase in detail' \
-o num_ctx 80000
But I quickly ran out of RAM (I have 64GB but a lot of that was in use already) and hit Ctrl+C to avoid crashing my computer. I need to experiment a bit to figure out how much RAM is used for what context size.
Awni Hannun shared tips for running mlx-community/Qwen2.5-7B-Instruct-1M-4bit using MLX, which should work for up to 250,000 tokens. They ran 120,000 tokens and reported:
- Peak RAM for prompt filling was 22GB
- Peak RAM for generation 12GB
- Prompt filling took 350 seconds on an M2 Ultra
- Generation ran at 31 tokens-per-second on M2 Ultra
Anthropic’s new Citations API
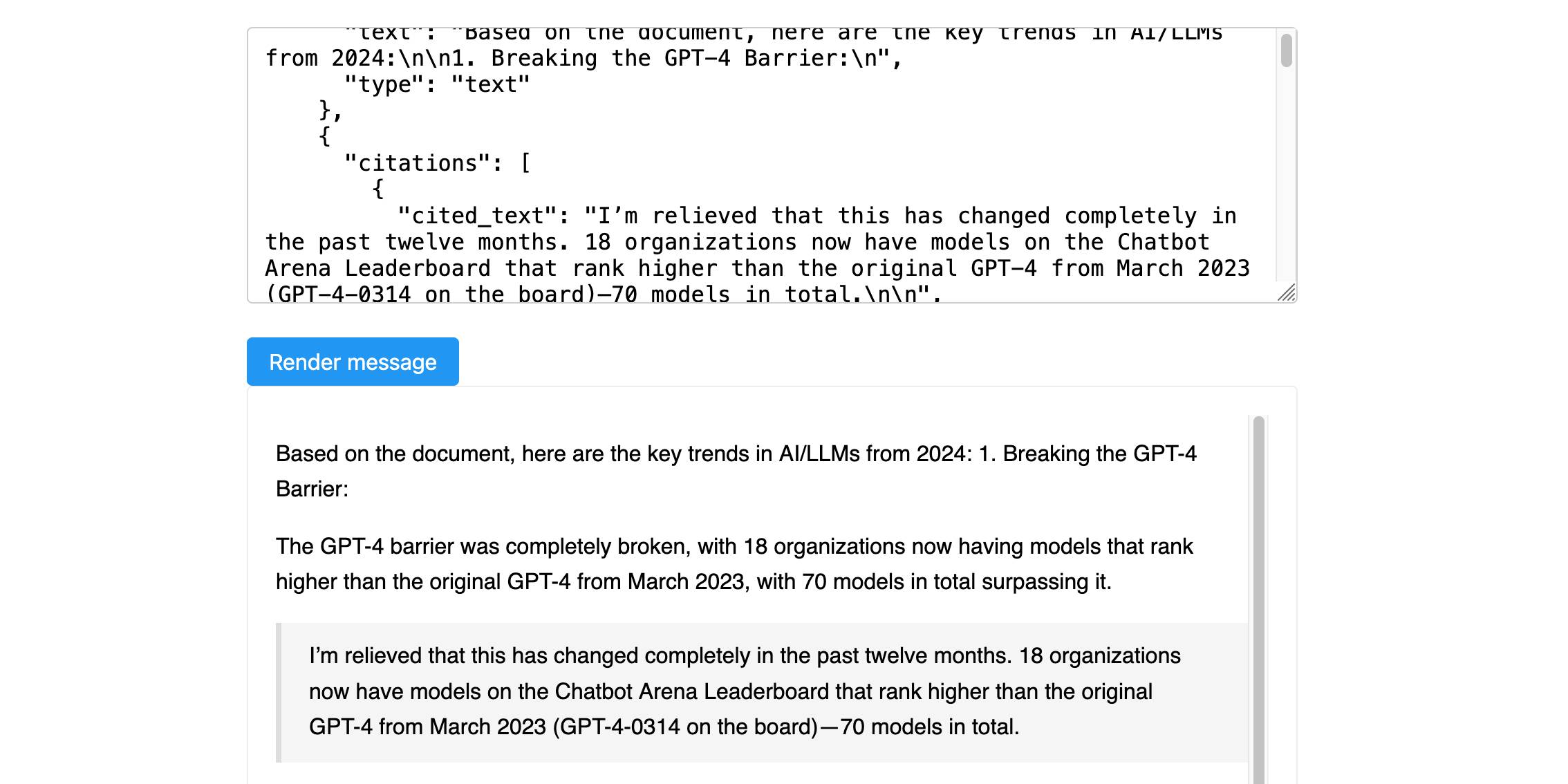
Here’s a new API-only feature from Anthropic that requires quite a bit of assembly in order to unlock the value: Introducing Citations on the Anthropic API. Let’s talk about what this is and why it’s interesting.
[... 1,319 words]LLM 0.20. New release of my LLM CLI tool and Python library. A bunch of accumulated fixes and features since the start of December, most notably:
- Support for OpenAI's o1 model - a significant upgrade from
o1-previewgiven its 200,000 input and 100,000 output tokens (o1-previewwas 128,000/32,768). #676 - Support for the
gpt-4o-audio-previewandgpt-4o-mini-audio-previewmodels, which can accept audio input:llm -m gpt-4o-audio-preview -a https://static.simonwillison.net/static/2024/pelican-joke-request.mp3#677 - A new
llm -x/--extractoption which extracts and returns the contents of the first fenced code block in the response. This is useful for prompts that generate code. #681 - A new
llm models -q 'search'option for searching available models - useful if you've installed a lot of plugins. Searches are case insensitive. #700
llm-gemini 0.9.
This new release of my llm-gemini plugin adds support for two new experimental models:
learnlm-1.5-pro-experimentalis "an experimental task-specific model that has been trained to align with learning science principles when following system instructions for teaching and learning use cases" - more here.-
gemini-2.0-flash-thinking-exp-01-21is a brand new version of the Gemini 2.0 Flash Thinking model released today:Latest version also includes code execution, a 1M token content window & a reduced likelihood of thought-answer contradictions.
The most exciting new feature though is support for Google search grounding, where some Gemini models can execute Google searches as part of answering a prompt. This feature can be enabled using the new -o google_search 1 option.
Six short video demos of LLM and Datasette projects
Last Friday Alex Garcia and I hosted a new kind of Datasette Public Office Hours session, inviting members of the Datasette community to share short demos of projects that they had built. The session lasted just over an hour and featured demos from six different people.
[... 1,047 words]DeepSeek-R1 and exploring DeepSeek-R1-Distill-Llama-8B

DeepSeek are the Chinese AI lab who dropped the best currently available open weights LLM on Christmas day, DeepSeek v3. That model was trained in part using their unreleased R1 “reasoning” model. Today they’ve released R1 itself, along with a whole family of new models derived from that base.
[... 1,276 words]Codestral 25.01 (via) Brand new code-focused model from Mistral. Unlike the first Codestral this one isn't (yet) available as open weights. The model has a 256k token context - a new record for Mistral.
The new model scored an impressive joint first place with Claude 3.5 Sonnet and Deepseek V2.5 (FIM) on the Copilot Arena leaderboard.
Chatbot Arena announced Copilot Arena on 12th November 2024. The leaderboard is driven by results gathered through their Copilot Arena VS Code extensions, which provides users with free access to models in exchange for logged usage data plus their votes as to which of two models returns the most useful completion.
So far the only other independent benchmark result I've seen is for the Aider Polyglot test. This was less impressive:
Codestral 25.01 scored 11% on the aider polyglot benchmark.
62% o1 (high)
48% DeepSeek V3
16% Qwen 2.5 Coder 32B Instruct
11% Codestral 25.01
4% gpt-4o-mini
The new model can be accessed via my llm-mistral plugin using the codestral alias (which maps to codestral-latest on La Plateforme):
llm install llm-mistral
llm keys set mistral
# Paste Mistral API key here
llm -m codestral "JavaScript to reverse an array"