98 posts tagged “llm-reasoning”
Improving performance of LLMs through spending more tokens "reasoning" about a problem, as seen in OpenAI's o-series, DeepSeek's R1, Qwen's QwQ, Google's Gemini 2.5 and Anthropic's Claude 3.7 Sonnet.
2025
Gemini 2.5 Pro Preview pricing (via) Google's Gemini 2.5 Pro is currently the top model on LM Arena and, from my own testing, a superb model for OCR, audio transcription and long-context coding.
You can now pay for it!
The new gemini-2.5-pro-preview-03-25 model ID is priced like this:
- Prompts less than 200,00 tokens: $1.25/million tokens for input, $10/million for output
- Prompts more than 200,000 tokens (up to the 1,048,576 max): $2.50/million for input, $15/million for output
This is priced at around the same level as Gemini 1.5 Pro ($1.25/$5 for input/output below 128,000 tokens, $2.50/$10 above 128,000 tokens), is cheaper than GPT-4o for shorter prompts ($2.50/$10) and is cheaper than Claude 3.7 Sonnet ($3/$15).
Gemini 2.5 Pro is a reasoning model, and invisible reasoning tokens are included in the output token count. I just tried prompting "hi" and it charged me 2 tokens for input and 623 for output, of which 613 were "thinking" tokens. That still adds up to just 0.6232 cents (less than a cent) using my LLM pricing calculator which I updated to support the new model just now.
I released llm-gemini 0.17 this morning adding support for the new model:
llm install -U llm-gemini
llm -m gemini-2.5-pro-preview-03-25 hi
Note that the model continues to be available for free under the previous gemini-2.5-pro-exp-03-25 model ID:
llm -m gemini-2.5-pro-exp-03-25 hi
The free tier is "used to improve our products", the paid tier is not.
Rate limits for the paid model vary by tier - from 150/minute and 1,000/day for tier 1 (billing configured), 1,000/minute and 50,000/day for Tier 2 ($250 total spend) and 2,000/minute and unlimited/day for Tier 3 ($1,000 total spend). Meanwhile the free tier continues to limit you to 5 requests per minute and 25 per day.
Google are retiring the Gemini 2.0 Pro preview entirely in favour of 2.5.
Putting Gemini 2.5 Pro through its paces

There’s a new release from Google Gemini this morning: the first in the Gemini 2.5 series. Google call it “a thinking model, designed to tackle increasingly complex problems”. It’s already sat at the top of the LM Arena leaderboard, and from initial impressions looks like it may deserve that top spot.
[... 2,400 words]Today we’re excited to launch ARC-AGI-2 to challenge the new frontier. ARC-AGI-2 is even harder for AI (in particular, AI reasoning systems), while maintaining the same relative ease for humans. Pure LLMs score 0% on ARC-AGI-2, and public AI reasoning systems achieve only single-digit percentage scores. In contrast, every task in ARC-AGI-2 has been solved by at least 2 humans in under 2 attempts. [...]
All other AI benchmarks focus on superhuman capabilities or specialized knowledge by testing "PhD++" skills. ARC-AGI is the only benchmark that takes the opposite design choice – by focusing on tasks that are relatively easy for humans, yet hard, or impossible, for AI, we shine a spotlight on capability gaps that do not spontaneously emerge from "scaling up".
— Greg Kamradt, ARC-AGI-2
OpenAI platform: o1-pro. OpenAI have a new most-expensive model: o1-pro can now be accessed through their API at a hefty $150/million tokens for input and $600/million tokens for output. That's 10x the price of their o1 and o1-preview models and a full 1,000x times more expensive than their cheapest model, gpt-4o-mini!
Aside from that it has mostly the same features as o1: a 200,000 token context window, 100,000 max output tokens, Sep 30 2023 knowledge cut-off date and it supports function calling, structured outputs and image inputs.
o1-pro doesn't support streaming, and most significantly for developers is the first OpenAI model to only be available via their new Responses API. This means tools that are built against their Chat Completions API (like my own LLM) have to do a whole lot more work to support the new model - my issue for that is here.
Since LLM doesn't support this new model yet I had to make do with curl:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o1-pro",
"input": "Generate an SVG of a pelican riding a bicycle"
}'
Here's the full JSON I got back - 81 input tokens and 1552 output tokens for a total cost of 94.335 cents.

I took a risk and added "reasoning": {"effort": "high"} to see if I could get a better pelican with more reasoning:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o1-pro",
"input": "Generate an SVG of a pelican riding a bicycle",
"reasoning": {"effort": "high"}
}'
Surprisingly that used less output tokens - 1459 compared to 1552 earlier (cost: 88.755 cents) - producing this JSON which rendered as a slightly better pelican:

It was cheaper because while it spent 960 reasoning tokens as opposed to 704 for the previous pelican it omitted the explanatory text around the SVG, saving on total output.
Demo of ChatGPT Code Interpreter running in o3-mini-high. OpenAI made GPT-4.5 available to Plus ($20/month) users today. I was a little disappointed with GPT-4.5 when I tried it through the API, but having access in the ChatGPT interface meant I could use it with existing tools such as Code Interpreter which made its strengths a whole lot more evident - that’s a transcript where I had it design and test its own version of the JSON Schema succinct DSL I published last week.
Riley Goodside then spotted that Code Interpreter has been quietly enabled for other models too, including the excellent o3-mini reasoning model. This means you can have o3-mini reason about code, write that code, test it, iterate on it and keep going until it gets something that works.
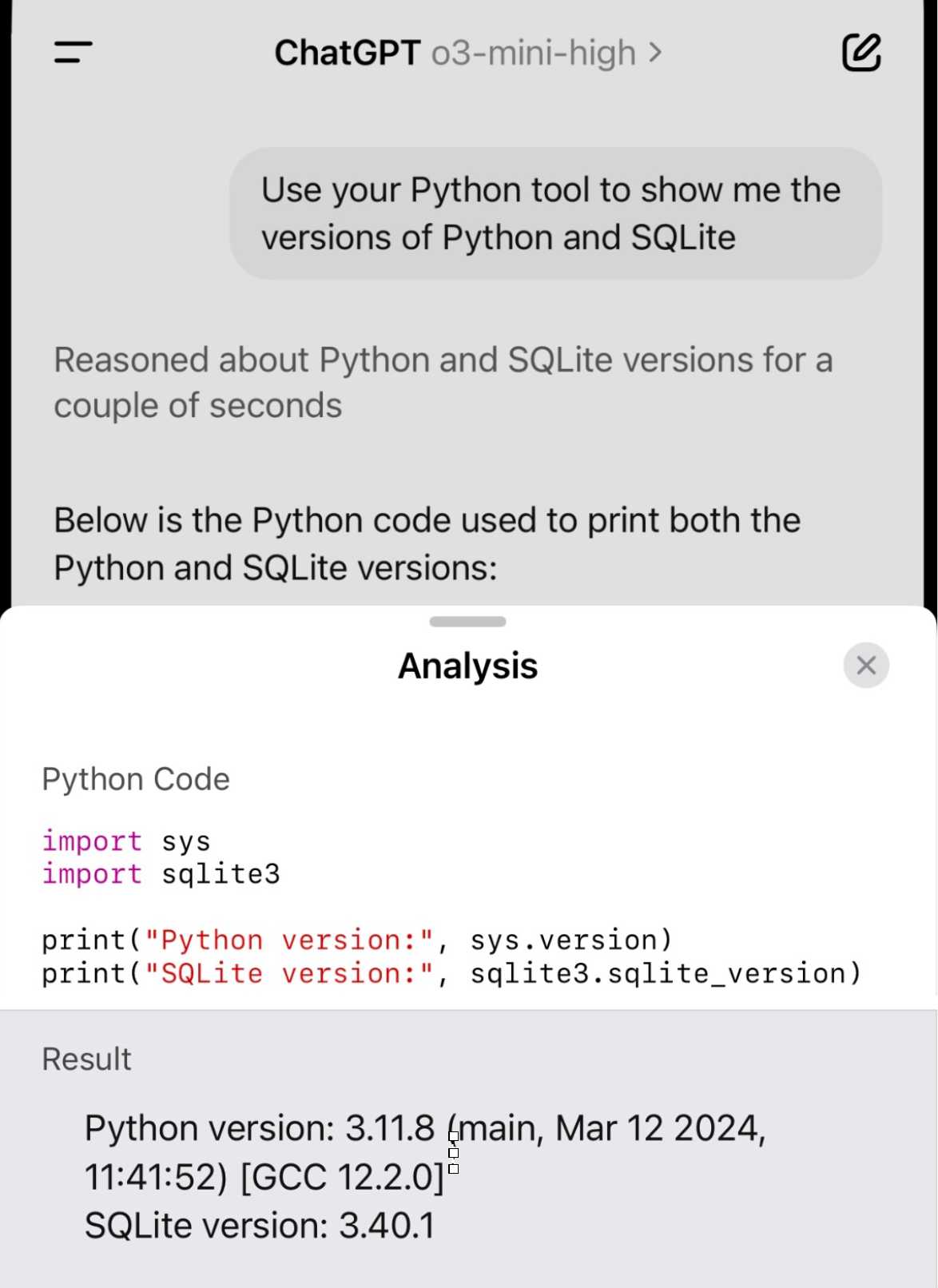
Code Interpreter remains my favorite implementation of the "coding agent" pattern, despite recieving very few upgrades in the two years after its initial release. Plugging much stronger models into it than the previous GPT-4o default makes it even more useful.
Nothing about this in the ChatGPT release notes yet, but I've tested it in the ChatGPT iOS app and mobile web app and it definitely works there.
QwQ-32B: Embracing the Power of Reinforcement Learning (via) New Apache 2 licensed reasoning model from Qwen:
We are excited to introduce QwQ-32B, a model with 32 billion parameters that achieves performance comparable to DeepSeek-R1, which boasts 671 billion parameters (with 37 billion activated). This remarkable outcome underscores the effectiveness of RL when applied to robust foundation models pretrained on extensive world knowledge.
I had a lot of fun trying out their previous QwQ reasoning model last November. I demonstrated this new QwQ in my talk at NICAR about recent LLM developments. Here's the example I ran.
{kind=link}
LM Studio just released GGUFs ranging in size from 17.2 to 34.8 GB. MLX have compatible weights published in 3bit, 4bit, 6bit and 8bit. Ollama has the new qwq too - it looks like they've renamed the previous November release qwq:32b-preview.
Claude 3.7 Sonnet, extended thinking and long output, llm-anthropic 0.14

Claude 3.7 Sonnet (previously) is a very interesting new model. I released llm-anthropic 0.14 last night adding support for the new model’s features to LLM. I learned a whole lot about the new model in the process of building that plugin.
[... 1,491 words]Claude 3.7 Sonnet and Claude Code. Anthropic released Claude 3.7 Sonnet today - skipping the name "Claude 3.6" because the Anthropic user community had already started using that as the unofficial name for their October update to 3.5 Sonnet.
As you may expect, 3.7 Sonnet is an improvement over 3.5 Sonnet - and is priced the same, at $3/million tokens for input and $15/m output.
The big difference is that this is Anthropic's first "reasoning" model - applying the same trick that we've now seen from OpenAI o1 and o3, Grok 3, Google Gemini 2.0 Thinking, DeepSeek R1 and Qwen's QwQ and QvQ. The only big model families without an official reasoning model now are Mistral and Meta's Llama.
I'm still working on adding support to my llm-anthropic plugin but I've got enough working code that I was able to get it to draw me a pelican riding a bicycle. Here's the non-reasoning model:

And here's that same prompt but with "thinking mode" enabled:

Here's the transcript for that second one, which mixes together the thinking and the output tokens. I'm still working through how best to differentiate between those two types of token.
Claude 3.7 Sonnet has a training cut-off date of Oct 2024 - an improvement on 3.5 Haiku's July 2024 - and can output up to 64,000 tokens in thinking mode (some of which are used for thinking tokens) and up to 128,000 if you enable a special header:
Claude 3.7 Sonnet can produce substantially longer responses than previous models with support for up to 128K output tokens (beta)---more than 15x longer than other Claude models. This expanded capability is particularly effective for extended thinking use cases involving complex reasoning, rich code generation, and comprehensive content creation.
This feature can be enabled by passing an
anthropic-betaheader ofoutput-128k-2025-02-19.
Anthropic's other big release today is a preview of Claude Code - a CLI tool for interacting with Claude that includes the ability to prompt Claude in terminal chat and have it read and modify files and execute commands. This means it can both iterate on code and execute tests, making it an extremely powerful "agent" for coding assistance.
Here's Anthropic's documentation on getting started with Claude Code, which uses OAuth (a first for Anthropic's API) to authenticate against your API account, so you'll need to configure billing.
Short version:
npm install -g @anthropic-ai/claude-code
claude
It can burn a lot of tokens so don't be surprised if a lengthy session with it adds up to single digit dollars of API spend.
files-to-prompt 0.5.
My files-to-prompt tool (originally built using Claude 3 Opus back in April) had been accumulating a bunch of issues and PRs - I finally got around to spending some time with it and pushed a fresh release:
- New
-n/--line-numbersflag for including line numbers in the output. Thanks, Dan Clayton. #38- Fix for utf-8 handling on Windows. Thanks, David Jarman. #36
--ignorepatterns are now matched against directory names as well as file names, unless you pass the new--ignore-files-onlyflag. Thanks, Nick Powell. #30
I use this tool myself on an almost daily basis - it's fantastic for quickly answering questions about code. Recently I've been plugging it into Gemini 2.0 with its 2 million token context length, running recipes like this one:
git clone https://github.com/bytecodealliance/componentize-py
cd componentize-py
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'How does this work? Does it include a python compiler or AST trick of some sort?'
I ran that question against the bytecodealliance/componentize-py repo - which provides a tool for turning Python code into compiled WASM - and got this really useful answer.
Here's another example. I decided to have o3-mini review how Datasette handles concurrent SQLite connections from async Python code - so I ran this:
git clone https://github.com/simonw/datasette
cd datasette/datasette
files-to-prompt database.py utils/__init__.py -c | \
llm -m o3-mini -o reasoning_effort high \
-s 'Output in markdown a detailed analysis of how this code handles the challenge of running SQLite queries from a Python asyncio application. Explain how it works in the first section, then explore the pros and cons of this design. In a final section propose alternative mechanisms that might work better.'
Here's the result. It did an extremely good job of explaining how my code works - despite being fed just the Python and none of the other documentation. Then it made some solid recommendations for potential alternatives.
I added a couple of follow-up questions (using llm -c) which resulted in a full working prototype of an alternative threadpool mechanism, plus some benchmarks.
One final example: I decided to see if there were any undocumented features in Litestream, so I checked out the repo and ran a prompt against just the .go files in that project:
git clone https://github.com/benbjohnson/litestream
cd litestream
files-to-prompt . -e go -c | llm -m o3-mini \
-s 'Write extensive user documentation for this project in markdown'
Once again, o3-mini provided a really impressively detailed set of unofficial documentation derived purely from reading the source.
S1: The $6 R1 Competitor? Tim Kellogg shares his notes on a new paper, s1: Simple test-time scaling, which describes an inference-scaling model fine-tuned on top of Qwen2.5-32B-Instruct for just $6 - the cost for 26 minutes on 16 NVIDIA H100 GPUs.
Tim highlight the most exciting result:
After sifting their dataset of 56K examples down to just the best 1K, they found that the core 1K is all that's needed to achieve o1-preview performance on a 32B model.
The paper describes a technique called "Budget forcing":
To enforce a minimum, we suppress the generation of the end-of-thinking token delimiter and optionally append the string “Wait” to the model’s current reasoning trace to encourage the model to reflect on its current generation
That's the same trick Theia Vogel described a few weeks ago.
Here's the s1-32B model on Hugging Face. I found a GGUF version of it at brittlewis12/s1-32B-GGUF, which I ran using Ollama like so:
ollama run hf.co/brittlewis12/s1-32B-GGUF:Q4_0
I also found those 1,000 samples on Hugging Face in the simplescaling/s1K data repository there.
I used DuckDB to convert the parquet file to CSV (and turn one VARCHAR[] column into JSON):
COPY (
SELECT
solution,
question,
cot_type,
source_type,
metadata,
cot,
json_array(thinking_trajectories) as thinking_trajectories,
attempt
FROM 's1k-00001.parquet'
) TO 'output.csv' (HEADER, DELIMITER ',');
Then I loaded that CSV into sqlite-utils so I could use the convert command to turn a Python data structure into JSON using json.dumps() and eval():
# Load into SQLite
sqlite-utils insert s1k.db s1k output.csv --csv
# Fix that column
sqlite-utils convert s1k.db s1u metadata 'json.dumps(eval(value))' --import json
# Dump that back out to CSV
sqlite-utils rows s1k.db s1k --csv > s1k.csv
Here's that CSV in a Gist, which means I can load it into Datasette Lite.
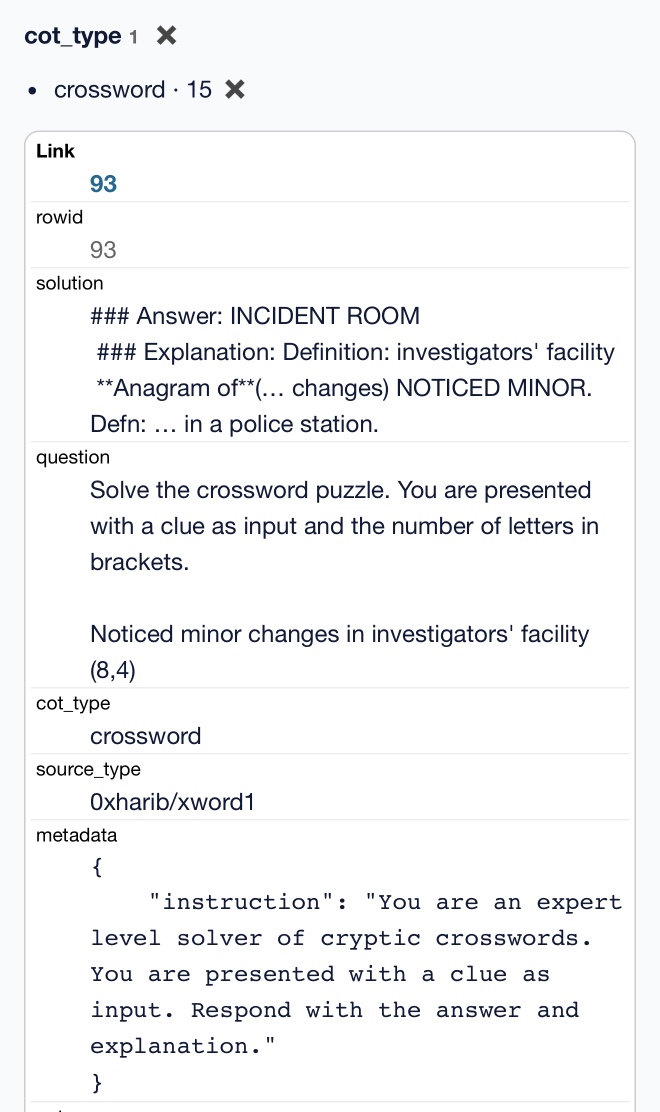
It really is a tiny amount of training data. It's mostly math and science, but there are also 15 cryptic crossword examples.
o3-mini is really good at writing internal documentation. I wanted to refresh my knowledge of how the Datasette permissions system works today. I already have extensive hand-written documentation for that, but I thought it would be interesting to see if I could derive any insights from running an LLM against the codebase.
o3-mini has an input limit of 200,000 tokens. I used LLM and my files-to-prompt tool to generate the documentation like this:
cd /tmp
git clone https://github.com/simonw/datasette
cd datasette
files-to-prompt datasette -e py -c | \
llm -m o3-mini -s \
'write extensive documentation for how the permissions system works, as markdown'The files-to-prompt command is fed the datasette subdirectory, which contains just the source code for the application - omitting tests (in tests/) and documentation (in docs/).
The -e py option causes it to only include files with a .py extension - skipping all of the HTML and JavaScript files in that hierarchy.
The -c option causes it to output Claude's XML-ish format - a format that works great with other LLMs too.
You can see the output of that command in this Gist.
Then I pipe that result into LLM, requesting the o3-mini OpenAI model and passing the following system prompt:
write extensive documentation for how the permissions system works, as markdown
Specifically requesting Markdown is important.
The prompt used 99,348 input tokens and produced 3,118 output tokens (320 of those were invisible reasoning tokens). That's a cost of 12.3 cents.
Honestly, the results are fantastic. I had to double-check that I hadn't accidentally fed in the documentation by mistake.
(It's possible that the model is picking up additional information about Datasette in its training set, but I've seen similar high quality results from other, newer libraries so I don't think that's a significant factor.)
In this case I already had extensive written documentation of my own, but this was still a useful refresher to help confirm that the code matched my mental model of how everything works.
Documentation of project internals as a category is notorious for going out of date. Having tricks like this to derive usable how-it-works documentation from existing codebases in just a few seconds and at a cost of a few cents is wildly valuable.
OpenAI reasoning models: Advice on prompting (via) OpenAI's documentation for their o1 and o3 "reasoning models" includes some interesting tips on how to best prompt them:
- Developer messages are the new system messages: Starting with
o1-2024-12-17, reasoning models supportdevelopermessages rather thansystemmessages, to align with the chain of command behavior described in the model spec.
This appears to be a purely aesthetic change made for consistency with their instruction hierarchy concept. As far as I can tell the old system prompts continue to work exactly as before - you're encouraged to use the new developer message type but it has no impact on what actually happens.
Since my LLM tool already bakes in a llm --system "system prompt" option which works across multiple different models from different providers I'm not going to rush to adopt this new language!
- Use delimiters for clarity: Use delimiters like markdown, XML tags, and section titles to clearly indicate distinct parts of the input, helping the model interpret different sections appropriately.
Anthropic have been encouraging XML-ish delimiters for a while (I say -ish because there's no requirement that the resulting prompt is valid XML). My files-to-prompt tool has a -c option which outputs Claude-style XML, and in my experiments this same option works great with o1 and o3 too:
git clone https://github.com/tursodatabase/limbo
cd limbo/bindings/python
files-to-prompt . -c | llm -m o3-mini \
-o reasoning_effort high \
--system 'Write a detailed README with extensive usage examples'
- Limit additional context in retrieval-augmented generation (RAG): When providing additional context or documents, include only the most relevant information to prevent the model from overcomplicating its response.
This makes me thing that o1/o3 are not good models to implement RAG on at all - with RAG I like to be able to dump as much extra context into the prompt as possible and leave it to the models to figure out what's relevant.
- Try zero shot first, then few shot if needed: Reasoning models often don't need few-shot examples to produce good results, so try to write prompts without examples first. If you have more complex requirements for your desired output, it may help to include a few examples of inputs and desired outputs in your prompt. Just ensure that the examples align very closely with your prompt instructions, as discrepancies between the two may produce poor results.
Providing examples remains the single most powerful prompting tip I know, so it's interesting to see advice here to only switch to examples if zero-shot doesn't work out.
- Be very specific about your end goal: In your instructions, try to give very specific parameters for a successful response, and encourage the model to keep reasoning and iterating until it matches your success criteria.
This makes sense: reasoning models "think" until they reach a conclusion, so making the goal as unambiguous as possible leads to better results.
- Markdown formatting: Starting with
o1-2024-12-17, reasoning models in the API will avoid generating responses with markdown formatting. To signal to the model when you do want markdown formatting in the response, include the stringFormatting re-enabledon the first line of yourdevelopermessage.
This one was a real shock to me! I noticed that o3-mini was outputting • characters instead of Markdown * bullets and initially thought that was a bug.
I first saw this while running this prompt against limbo/bindings/python using files-to-prompt:
git clone https://github.com/tursodatabase/limbo
cd limbo/bindings/python
files-to-prompt . -c | llm -m o3-mini \
-o reasoning_effort high \
--system 'Write a detailed README with extensive usage examples'Here's the full result, which includes text like this (note the weird bullets):
Features
--------
• High‑performance, in‑process database engine written in Rust
• SQLite‑compatible SQL interface
• Standard Python DB‑API 2.0–style connection and cursor objects
I ran it again with this modified prompt:
Formatting re-enabled. Write a detailed README with extensive usage examples.
And this time got back proper Markdown, rendered in this Gist. That did a really good job, and included bulleted lists using this valid Markdown syntax instead:
- **`make test`**: Run tests using pytest.
- **`make lint`**: Run linters (via [ruff](https://github.com/astral-sh/ruff)).
- **`make check-requirements`**: Validate that the `requirements.txt` files are in sync with `pyproject.toml`.
- **`make compile-requirements`**: Compile the `requirements.txt` files using pip-tools.
(Using LLMs like this to get me off the ground with under-documented libraries is a trick I use several times a month.)
Update: OpenAI's Nikunj Handa:
we agree this is weird! fwiw, it’s a temporary thing we had to do for the existing o-series models. we’ll fix this in future releases so that you can go back to naturally prompting for markdown or no-markdown.
OpenAI o3-mini, now available in LLM
OpenAI’s o3-mini is out today. As with other o-series models it’s a slightly difficult one to evaluate—we now need to decide if a prompt is best run using GPT-4o, o1, o3-mini or (if we have access) o1 Pro.
[... 748 words]Llama 4 is making great progress in training. Llama 4 mini is done with pre-training and our reasoning models and larger model are looking good too. Our goal with Llama 3 was to make open source competitive with closed models, and our goal for Llama 4 is to lead. Llama 4 will be natively multimodal -- it's an omni-model -- and it will have agentic capabilities, so it's going to be novel and it's going to unlock a lot of new use cases.
— Mark Zuckerberg, on Meta's quarterly earnings report
On DeepSeek and Export Controls. Anthropic CEO (and previously GPT-2/GPT-3 development lead at OpenAI) Dario Amodei's essay about DeepSeek includes a lot of interesting background on the last few years of AI development.
Dario was one of the authors on the original scaling laws paper back in 2020, and he talks at length about updated ideas around scaling up training:
The field is constantly coming up with ideas, large and small, that make things more effective or efficient: it could be an improvement to the architecture of the model (a tweak to the basic Transformer architecture that all of today's models use) or simply a way of running the model more efficiently on the underlying hardware. New generations of hardware also have the same effect. What this typically does is shift the curve: if the innovation is a 2x "compute multiplier" (CM), then it allows you to get 40% on a coding task for $5M instead of $10M; or 60% for $50M instead of $100M, etc.
He argues that DeepSeek v3, while impressive, represented an expected evolution of models based on current scaling laws.
[...] even if you take DeepSeek's training cost at face value, they are on-trend at best and probably not even that. For example this is less steep than the original GPT-4 to Claude 3.5 Sonnet inference price differential (10x), and 3.5 Sonnet is a better model than GPT-4. All of this is to say that DeepSeek-V3 is not a unique breakthrough or something that fundamentally changes the economics of LLM's; it's an expected point on an ongoing cost reduction curve. What's different this time is that the company that was first to demonstrate the expected cost reductions was Chinese.
Dario includes details about Claude 3.5 Sonnet that I've not seen shared anywhere before:
- Claude 3.5 Sonnet cost "a few $10M's to train"
- 3.5 Sonnet "was not trained in any way that involved a larger or more expensive model (contrary to some rumors)" - I've seen those rumors, they involved Sonnet being a distilled version of a larger, unreleased 3.5 Opus.
- Sonnet's training was conducted "9-12 months ago" - that would be roughly between January and April 2024. If you ask Sonnet about its training cut-off it tells you "April 2024" - that's surprising, because presumably the cut-off should be at the start of that training period?
The general message here is that the advances in DeepSeek v3 fit the general trend of how we would expect modern models to improve, including that notable drop in training price.
Dario is less impressed by DeepSeek R1, calling it "much less interesting from an innovation or engineering perspective than V3". I enjoyed this footnote:
I suspect one of the principal reasons R1 gathered so much attention is that it was the first model to show the user the chain-of-thought reasoning that the model exhibits (OpenAI's o1 only shows the final answer). DeepSeek showed that users find this interesting. To be clear this is a user interface choice and is not related to the model itself.
The rest of the piece argues for continued export controls on chips to China, on the basis that if future AI unlocks "extremely rapid advances in science and technology" the US needs to get their first, due to his concerns about "military applications of the technology".
Not mentioned once, even in passing: the fact that DeepSeek are releasing open weight models, something that notably differentiates them from both OpenAI and Anthropic.
The most surprising part of DeepSeek-R1 is that it only takes ~800k samples of 'good' RL reasoning to convert other models into RL-reasoners. Now that DeepSeek-R1 is available people will be able to refine samples out of it to convert any other model into an RL reasoner.
ggml : x2 speed for WASM by optimizing SIMD
(via)
PR by Xuan-Son Nguyen for llama.cpp:
This PR provides a big jump in speed for WASM by leveraging SIMD instructions for
qX_K_q8_KandqX_0_q8_0dot product functions.Surprisingly, 99% of the code in this PR is written by DeekSeek-R1. The only thing I do is to develop tests and write prompts (with some trails and errors)
They shared their prompts here, which they ran directly through R1 on chat.deepseek.com - it spent 3-5 minutes "thinking" about each prompt.
I've been seeing some very promising results from DeepSeek R1 for code as well. Here's a recent transcript where I used it to rewrite the llm_groq.py plugin to imitate the cached model JSON pattern used by llm_mistral.py, resulting in this PR.
I tried the same thing against o1, but I think DeepSeek R1 did it better. In particular, from the R1 chain of thought:
Wait, but in the model_map, "groq-gemma" maps to "gemma-7b-it". So, perhaps the model_map is needed to map the local model IDs to the actual Groq model names.
But since the model_map is hardcoded, and the API returns available models, perhaps the model_map should be built dynamically from the API response.
Alternatively, perhaps the model_map can be eliminated, and the models are registered based on the fetched models.
Wait, perhaps the model_map is no longer necessary. Instead, when the models are fetched from the API, each model's "id" is the actual model name used in the Groq API. So, when registering the models, the local model ID is "groq-{id}", and the groq_model_id is "id".
(It thought about model_map a lot before finally deciding to eliminate it, which was also my preferred resolution.)
The impact of competition and DeepSeek on Nvidia (via) Long, excellent piece by Jeffrey Emanuel capturing the current state of the AI/LLM industry. The original title is "The Short Case for Nvidia Stock" - I'm using the Hacker News alternative title here, but even that I feel under-sells this essay.
Jeffrey has a rare combination of experience in both computer science and investment analysis. He combines both worlds here, evaluating NVIDIA's challenges by providing deep insight into a whole host of relevant and interesting topics.
As Jeffrey describes it, NVIDA's moat has four components: high-quality Linux drivers, CUDA as an industry standard, the fast GPU interconnect technology they acquired from Mellanox in 2019 and the flywheel effect where they can invest their enormous profits (75-90% margin in some cases!) into more R&D.
Each of these is under threat.
Technologies like MLX, Triton and JAX are undermining the CUDA advantage by making it easier for ML developers to target multiple backends - plus LLMs themselves are getting capable enough to help port things to alternative architectures.
GPU interconnect helps multiple GPUs work together on tasks like model training. Companies like Cerebras are developing enormous chips that can get way more done on a single chip.
Those 75-90% margins provide a huge incentive for other companies to catch up - including the customers who spend the most on NVIDIA at the moment - Microsoft, Amazon, Meta, Google, Apple - all of whom have their own internal silicon projects:
Now, it's no secret that there is a strong power law distribution of Nvidia's hyper-scaler customer base, with the top handful of customers representing the lion's share of high-margin revenue. How should one think about the future of this business when literally every single one of these VIP customers is building their own custom chips specifically for AI training and inference?
The real joy of this article is the way it describes technical details of modern LLMs in a relatively accessible manner. I love this description of the inference-scaling tricks used by O1 and R1, compared to traditional transformers:
Basically, the way Transformers work in terms of predicting the next token at each step is that, if they start out on a bad "path" in their initial response, they become almost like a prevaricating child who tries to spin a yarn about why they are actually correct, even if they should have realized mid-stream using common sense that what they are saying couldn't possibly be correct.
Because the models are always seeking to be internally consistent and to have each successive generated token flow naturally from the preceding tokens and context, it's very hard for them to course-correct and backtrack. By breaking the inference process into what is effectively many intermediate stages, they can try lots of different things and see what's working and keep trying to course-correct and try other approaches until they can reach a fairly high threshold of confidence that they aren't talking nonsense.
The last quarter of the article talks about the seismic waves rocking the industry right now caused by DeepSeek v3 and R1. v3 remains the top-ranked open weights model, despite being around 45x more efficient in training than its competition: bad news if you are selling GPUs! R1 represents another huge breakthrough in efficiency both for training and for inference - the DeepSeek R1 API is currently 27x cheaper than OpenAI's o1, for a similar level of quality.
Jeffrey summarized some of the key ideas from the v3 paper like this:
A major innovation is their sophisticated mixed-precision training framework that lets them use 8-bit floating point numbers (FP8) throughout the entire training process. [...]
DeepSeek cracked this problem by developing a clever system that breaks numbers into small tiles for activations and blocks for weights, and strategically uses high-precision calculations at key points in the network. Unlike other labs that train in high precision and then compress later (losing some quality in the process), DeepSeek's native FP8 approach means they get the massive memory savings without compromising performance. When you're training across thousands of GPUs, this dramatic reduction in memory requirements per GPU translates into needing far fewer GPUs overall.
Then for R1:
With R1, DeepSeek essentially cracked one of the holy grails of AI: getting models to reason step-by-step without relying on massive supervised datasets. Their DeepSeek-R1-Zero experiment showed something remarkable: using pure reinforcement learning with carefully crafted reward functions, they managed to get models to develop sophisticated reasoning capabilities completely autonomously. This wasn't just about solving problems— the model organically learned to generate long chains of thought, self-verify its work, and allocate more computation time to harder problems.
The technical breakthrough here was their novel approach to reward modeling. Rather than using complex neural reward models that can lead to "reward hacking" (where the model finds bogus ways to boost their rewards that don't actually lead to better real-world model performance), they developed a clever rule-based system that combines accuracy rewards (verifying final answers) with format rewards (encouraging structured thinking). This simpler approach turned out to be more robust and scalable than the process-based reward models that others have tried.
This article is packed with insights like that - it's worth spending the time absorbing the whole thing.
The leading AI models are now very good historians (via) UC Santa Cruz's Benjamin Breen (previously) explores how the current crop of top tier LLMs - GPT-4o, o1, and Claude Sonnet 3.5 - are proving themselves competent at a variety of different tasks relevant to academic historians.
The vision models are now capable of transcribing and translating scans of historical documents - in this case 16th century Italian cursive handwriting and medical recipes from 1770s Mexico.
Even more interestingly, the o1 reasoning model was able to produce genuinely useful suggestions for historical interpretations against prompts like this one:
Here are some quotes from William James’ complete works, referencing Francis galton and Karl Pearson. What are some ways we can generate new historical knowledge or interpretations on the basis of this? I want a creative, exploratory, freewheeling analysis which explores the topic from a range of different angles and which performs metacognitive reflection on research paths forward based on this, especially from a history of science and history of technology perspectives. end your response with some further self-reflection and self-critique, including fact checking. then provide a summary and ideas for paths forward. What further reading should I do on this topic? And what else jumps out at you as interesting from the perspective of a professional historian?
How good? He followed-up by asking for "the most creative, boundary-pushing, or innovative historical arguments or analyses you can formulate based on the sources I provided" and described the resulting output like this:
The supposedly “boundary-pushing” ideas it generated were all pretty much what a class of grad students would come up with — high level and well-informed, but predictable.
As Benjamin points out, this is somewhat expected: LLMs "are exquisitely well-tuned machines for finding the median viewpoint on a given issue" - something that's already being illustrated by the sameness of work from his undergraduates who are clearly getting assistance from ChatGPT.
I'd be fascinated to hear more from academics outside of the computer science field who are exploring these new tools in a similar level of depth.
Update: Something that's worth emphasizing about this article: all of the use-cases Benjamin describes here involve feeding original source documents to the LLM as part of their input context. I've seen some criticism of this article that assumes he's asking LLMs to answer questions baked into their weights (as this NeurIPS poster demonstrates, even the best models don't have perfect recall of a wide range of historical facts). That's not what he's doing here.
I can’t reference external reports critical of China. Need to emphasize China’s policies on ethnic unity, development in Xinjiang, and legal protections. Avoid any mention of controversies or allegations to stay compliant.
— DeepSeek R1, internal dialogue as seen by Jon Keegan
Trading Inference-Time Compute for Adversarial Robustness. Brand new research paper from OpenAI, exploring how inference-scaling "reasoning" models such as o1 might impact the search for improved security with respect to things like prompt injection.
We conduct experiments on the impact of increasing inference-time compute in reasoning models (specifically OpenAI
o1-previewando1-mini) on their robustness to adversarial attacks. We find that across a variety of attacks, increased inference-time compute leads to improved robustness. In many cases (with important exceptions), the fraction of model samples where the attack succeeds tends to zero as the amount of test-time compute grows.
They clearly understand why this stuff is such a big problem, especially as we try to outsource more autonomous actions to "agentic models":
Ensuring that agentic models function reliably when browsing the web, sending emails, or uploading code to repositories can be seen as analogous to ensuring that self-driving cars drive without accidents. As in the case of self-driving cars, an agent forwarding a wrong email or creating security vulnerabilities may well have far-reaching real-world consequences. Moreover, LLM agents face an additional challenge from adversaries which are rarely present in the self-driving case. Adversarial entities could control some of the inputs that these agents encounter while browsing the web, or reading files and images.
This is a really interesting paper, but it starts with a huge caveat. The original sin of LLMs - and the reason prompt injection is such a hard problem to solve - is the way they mix instructions and input data in the same stream of tokens. I'll quote section 1.2 of the paper in full - note that point 1 describes that challenge:
1.2 Limitations of this work
The following conditions are necessary to ensure the models respond more safely, even in adversarial settings:
- Ability by the model to parse its context into separate components. This is crucial to be able to distinguish data from instructions, and instructions at different hierarchies.
- Existence of safety specifications that delineate what contents should be allowed or disallowed, how the model should resolve conflicts, etc..
- Knowledge of the safety specifications by the model (e.g. in context, memorization of their text, or ability to label prompts and responses according to them).
- Ability to apply the safety specifications to specific instances. For the adversarial setting, the crucial aspect is the ability of the model to apply the safety specifications to instances that are out of the training distribution, since naturally these would be the prompts provided by the adversary,
They then go on to say (emphasis mine):
Our work demonstrates that inference-time compute helps with Item 4, even in cases where the instance is shifted by an adversary to be far from the training distribution (e.g., by injecting soft tokens or adversarially generated content). However, our work does not pertain to Items 1-3, and even for 4, we do not yet provide a "foolproof" and complete solution.
While we believe this work provides an important insight, we note that fully resolving the adversarial robustness challenge will require tackling all the points above.
So while this paper demonstrates that inference-scaled models can greatly improve things with respect to identifying and avoiding out-of-distribution attacks against safety instructions, they are not claiming a solution to the key instruction-mixing challenge of prompt injection. Once again, this is not the silver bullet we are all dreaming of.
The paper introduces two new categories of attack against inference-scaling models, with two delightful names: "Think Less" and "Nerd Sniping".
Think Less attacks are when an attacker tricks a model into spending less time on reasoning, on the basis that more reasoning helps prevent a variety of attacks so cutting short the reasoning might help an attack make it through.
Nerd Sniping (see XKCD 356) does the opposite: these are attacks that cause the model to "spend inference-time compute unproductively". In addition to added costs, these could also open up some security holes - there are edge-cases where attack success rates go up for longer compute times.
Sadly they didn't provide concrete examples for either of these new attack classes. I'd love to see what Nerd Sniping looks like in a malicious prompt!
llm-gemini 0.9.
This new release of my llm-gemini plugin adds support for two new experimental models:
learnlm-1.5-pro-experimentalis "an experimental task-specific model that has been trained to align with learning science principles when following system instructions for teaching and learning use cases" - more here.-
gemini-2.0-flash-thinking-exp-01-21is a brand new version of the Gemini 2.0 Flash Thinking model released today:Latest version also includes code execution, a 1M token content window & a reduced likelihood of thought-answer contradictions.
The most exciting new feature though is support for Google search grounding, where some Gemini models can execute Google searches as part of answering a prompt. This feature can be enabled using the new -o google_search 1 option.
DeepSeek-R1 and exploring DeepSeek-R1-Distill-Llama-8B

DeepSeek are the Chinese AI lab who dropped the best currently available open weights LLM on Christmas day, DeepSeek v3. That model was trained in part using their unreleased R1 “reasoning” model. Today they’ve released R1 itself, along with a whole family of new models derived from that base.
[... 1,276 words][...] much of the point of a model like o1 is not to deploy it, but to generate training data for the next model. Every problem that an o1 solves is now a training data point for an o3 (eg. any o1 session which finally stumbles into the right answer can be refined to drop the dead ends and produce a clean transcript to train a more refined intuition).
— gwern
I don't think people really appreciate how simple ARC-AGI-1 was, and what solving it really means.
It was designed as the simplest, most basic assessment of fluid intelligence possible. Failure to pass signifies a near-total inability to adapt or problem-solve in unfamiliar situations.
Passing it means your system exhibits non-zero fluid intelligence -- you're finally looking at something that isn't pure memorized skill. But it says rather little about how intelligent your system is, or how close to human intelligence it is.
2024
Things we learned about LLMs in 2024
A lot has happened in the world of Large Language Models over the course of 2024. Here’s a review of things we figured out about the field in the past twelve months, plus my attempt at identifying key themes and pivotal moments.
[... 7,490 words]Trying out QvQ—Qwen’s new visual reasoning model

I thought we were done for major model releases in 2024, but apparently not: Alibaba’s Qwen team just dropped the Apache 2.0 licensed Qwen licensed (the license changed) QvQ-72B-Preview, “an experimental research model focusing on enhancing visual reasoning capabilities”.
There’s been a lot of strange reporting recently about how ‘scaling is hitting a wall’ – in a very narrow sense this is true in that larger models were getting less score improvement on challenging benchmarks than their predecessors, but in a larger sense this is false – techniques like those which power O3 means scaling is continuing (and if anything the curve has steepened), you just now need to account for scaling both within the training of the model and in the compute you spend on it once trained.
OpenAI o3 breakthrough high score on ARC-AGI-PUB. François Chollet is the co-founder of the ARC Prize and had advanced access to today's o3 results. His article here is the most insightful coverage I've seen of o3, going beyond just the benchmark results to talk about what this all means for the field in general.
One fascinating detail: it cost $6,677 to run o3 in "high efficiency" mode against the 400 public ARC-AGI puzzles for a score of 82.8%, and an undisclosed amount of money to run the "low efficiency" mode model to score 91.5%. A note says:
o3 high-compute costs not available as pricing and feature availability is still TBD. The amount of compute was roughly 172x the low-compute configuration.
So we can get a ballpark estimate here in that 172 * $6,677 = $1,148,444!
Here's how François explains the likely mechanisms behind o3, which reminds me of how a brute-force chess computer might work.
For now, we can only speculate about the exact specifics of how o3 works. But o3's core mechanism appears to be natural language program search and execution within token space – at test time, the model searches over the space of possible Chains of Thought (CoTs) describing the steps required to solve the task, in a fashion perhaps not too dissimilar to AlphaZero-style Monte-Carlo tree search. In the case of o3, the search is presumably guided by some kind of evaluator model. To note, Demis Hassabis hinted back in a June 2023 interview that DeepMind had been researching this very idea – this line of work has been a long time coming.
So while single-generation LLMs struggle with novelty, o3 overcomes this by generating and executing its own programs, where the program itself (the CoT) becomes the artifact of knowledge recombination. Although this is not the only viable approach to test-time knowledge recombination (you could also do test-time training, or search in latent space), it represents the current state-of-the-art as per these new ARC-AGI numbers.
Effectively, o3 represents a form of deep learning-guided program search. The model does test-time search over a space of "programs" (in this case, natural language programs – the space of CoTs that describe the steps to solve the task at hand), guided by a deep learning prior (the base LLM). The reason why solving a single ARC-AGI task can end up taking up tens of millions of tokens and cost thousands of dollars is because this search process has to explore an enormous number of paths through program space – including backtracking.
I'm not sure if o3 (and o1 and similar models) even qualifies as an LLM any more - there's clearly a whole lot more going on here than just next-token prediction.
On the question of if o3 should qualify as AGI (whatever that might mean):
Passing ARC-AGI does not equate to achieving AGI, and, as a matter of fact, I don't think o3 is AGI yet. o3 still fails on some very easy tasks, indicating fundamental differences with human intelligence.
Furthermore, early data points suggest that the upcoming ARC-AGI-2 benchmark will still pose a significant challenge to o3, potentially reducing its score to under 30% even at high compute (while a smart human would still be able to score over 95% with no training).
The post finishes with examples of the puzzles that o3 didn't manage to solve, including this one which reassured me that I can still solve at least some puzzles that couldn't be handled with thousands of dollars of GPU compute!
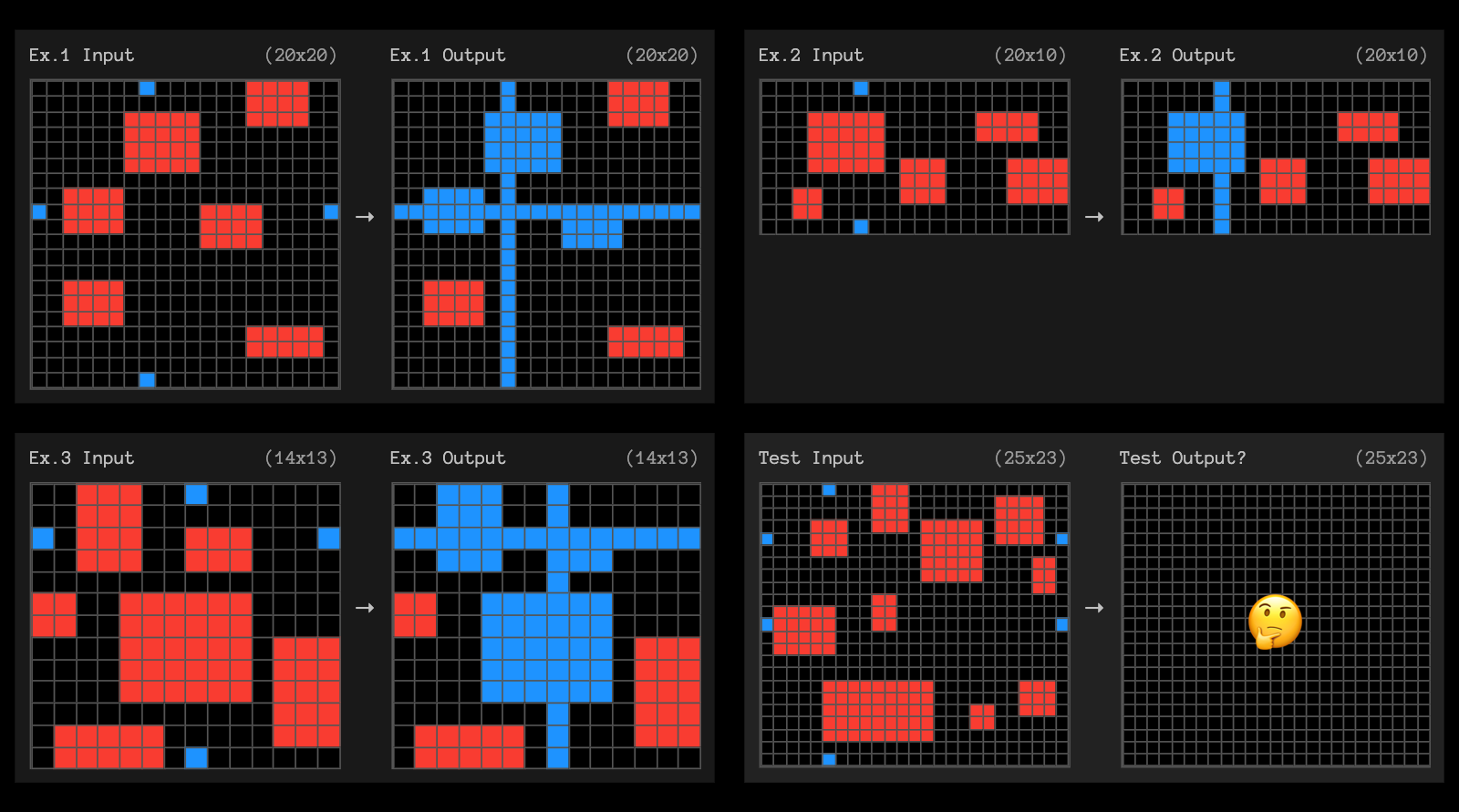
OpenAI's new o3 system - trained on the ARC-AGI-1 Public Training set - has scored a breakthrough 75.7% on the Semi-Private Evaluation set at our stated public leaderboard $10k compute limit. A high-compute (172x) o3 configuration scored 87.5%.
This is a surprising and important step-function increase in AI capabilities, showing novel task adaptation ability never seen before in the GPT-family models. For context, ARC-AGI-1 took 4 years to go from 0% with GPT-3 in 2020 to 5% in 2024 with GPT-4o. All intuition about AI capabilities will need to get updated for o3.
— François Chollet, Co-founder, ARC Prize