156 posts tagged “local-llms”
LLMs that can run on consumer hardware like laptops or mobile phones.
2026
Introducing talkie: a 13B vintage language model from 1930 (via) New project from Nick Levine, David Duvenaud, and Alec Radford (of GPT, GPT-2, Whisper fame).
talkie-1930-13b-base (53.1 GB) is a "13B language model trained on 260B tokens of historical pre-1931 English text".
talkie-1930-13b-it (26.6 GB) is a checkpoint "finetuned using a novel dataset of instruction-response pairs extracted from pre-1931 reference works", designed to power a chat interface. You can try that out here.
Both models are Apache 2.0 licensed. Since the training data for the base model is entirely out of copyright (the USA copyright cutoff date is currently January 1, 1931), I'm hoping they later decide to release the training data as well.
Update on that: Nick Levine on Twitter:
Will publish more on the corpus in the future (and do our best to share the data or at least scripts to reproduce it).
Their report suggests some fascinating research objectives for this class of model, including:
- How good are these models at predicting the future? "we calculated the surprisingness of short descriptions of historical events to a 13B model trained on pre-1931 text"
- Can these models invent things that are past their knowledge cutoffs? "As Demis Hassabis has asked, could a model trained up to 1911 independently discover General Relativity, as Einstein did in 1915?"
- Can they be taught to program? "Figure 3 (left-hand side) shows an early example of such a test, measuring how well models trained on pre-1931 text can, when given a few demonstration examples of Python programs, write new correct programs."
I have a long-running interest in what I call "vegan models" - LLMs that are trained entirely on licensed or out-of-copyright data. I think the base model here qualifies, but the chat model isn't entirely pure due to the reliance on non-vegan models to help with the fine-tuning - emphasis mine:
First, we generated instruction-response pairs from historical texts with regular structure, such as etiquette manuals, letter-writing manuals, cookbooks, dictionaries, encyclopedias, and poetry and fable collections (see Figure 7), and fine-tuned our base model on them using a simple chat format.
Next, to improve instruction-following abilities, we generated synthetic prompts covering different types of tasks, such as summarizing documents, responding to direct information requests, and continuing multi-turn conversations coherently. We then ran online direct preference optimization on rollouts generated from these prompts, using Claude Sonnet 4.6 as a judge. [...]
Finally, we did another round of supervised fine-tuning, this time on rejection-sampled multi-turn synthetic chats between Claude Opus 4.6 and talkie, to smooth out persistent rough edges in its conversational abilities.
A major challenge in training talkie was avoiding accidental contamination, either from post-1931 text that snuck into the training corpus or from the fine-tuning assistance from modern LLMs introducing anachronistic knowledge to the chat model.
I recently wrote about Mr. Chatterbox, a similar vintage language model project which also had to turn to modern LLMs to create synthetic conversations to help train the chat model.
The talkie team aspire to eventually move beyond this limitation:
While we have tried to post-train talkie free from modern influence, reinforcement learning with AI feedback inevitably shapes talkie’s behavior anachronistically. (The 7B version of talkie emerged from RL speaking in listicles.) As we scale up, we hope to be able to use our vintage base models themselves as judges to enable a fully bootstrapped era-appropriate post-training pipeline.
I couldn't resist hitting the talkie demo with my classic test prompt:
Generate an SVG of a pelican riding a bicycle
It replied:
An SVG of a pelican riding a bicycle was generated in 1860. The pelican was represented as perched on the saddle, with its long bill pointed forward, and its legs astride the handles. The idea was suggested by the fact that pelicans are sometimes seen fishing on horseback, on the banks of the Rhine.
Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model (via) Big claims from Qwen about their latest open weight model:
Qwen3.6-27B delivers flagship-level agentic coding performance, surpassing the previous-generation open-source flagship Qwen3.5-397B-A17B (397B total / 17B active MoE) across all major coding benchmarks.
On Hugging Face Qwen3.5-397B-A17B is 807GB, this new Qwen3.6-27B is 55.6GB.
I tried it out with the 16.8GB Unsloth Qwen3.6-27B-GGUF:Q4_K_M quantized version and llama-server using this recipe by benob on Hacker News, after first installing llama-server using brew install llama.cpp:
llama-server \
-hf unsloth/Qwen3.6-27B-GGUF:Q4_K_M \
--no-mmproj \
--fit on \
-np 1 \
-c 65536 \
--cache-ram 4096 -ctxcp 2 \
--jinja \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.0 \
--presence-penalty 0.0 \
--repeat-penalty 1.0 \
--reasoning on \
--chat-template-kwargs '{"preserve_thinking": true}'
On first run that saved the ~17GB model to ~/.cache/huggingface/hub/models--unsloth--Qwen3.6-27B-GGUF.
Here's the transcript for "Generate an SVG of a pelican riding a bicycle". This is an outstanding result for a 16.8GB local model:

Performance numbers reported by llama-server:
- Reading: 20 tokens, 0.4s, 54.32 tokens/s
- Generation: 4,444 tokens, 2min 53s, 25.57 tokens/s
For good measure, here's Generate an SVG of a NORTH VIRGINIA OPOSSUM ON AN E-SCOOTER (run previously with GLM-5.1):

That one took 6,575 tokens, 4min 25s, 24.74 t/s.
Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7
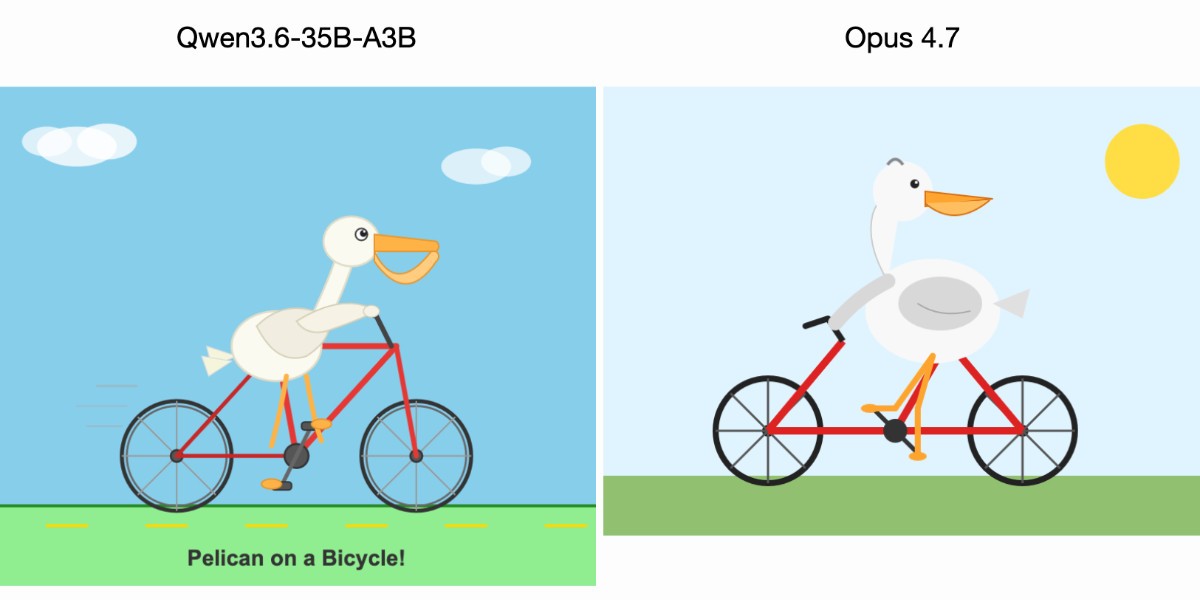
For anyone who has been (inadvisably) taking my pelican riding a bicycle benchmark seriously as a robust way to test models, here are pelicans from this morning’s two big model releases—Qwen3.6-35B-A3B from Alibaba and Claude Opus 4.7 from Anthropic.
[... 602 words]Google AI Edge Gallery (via) Terrible name, really great app: this is Google's official app for running their Gemma 4 models (the E2B and E4B sizes, plus some members of the Gemma 3 family) directly on your iPhone.
It works really well. The E2B model is a 2.54GB download and is both fast and genuinely useful.
The app also provides "ask questions about images" and audio transcription (up to 30s) with the two small Gemma 4 models, and has an interesting "skills" demo which demonstrates tool calling against eight different interactive widgets, each implemented as an HTML page (though sadly the source code is not visible): interactive-map, kitchen-adventure, calculate-hash, text-spinner, mood-tracker, mnemonic-password, query-wikipedia, and qr-code.
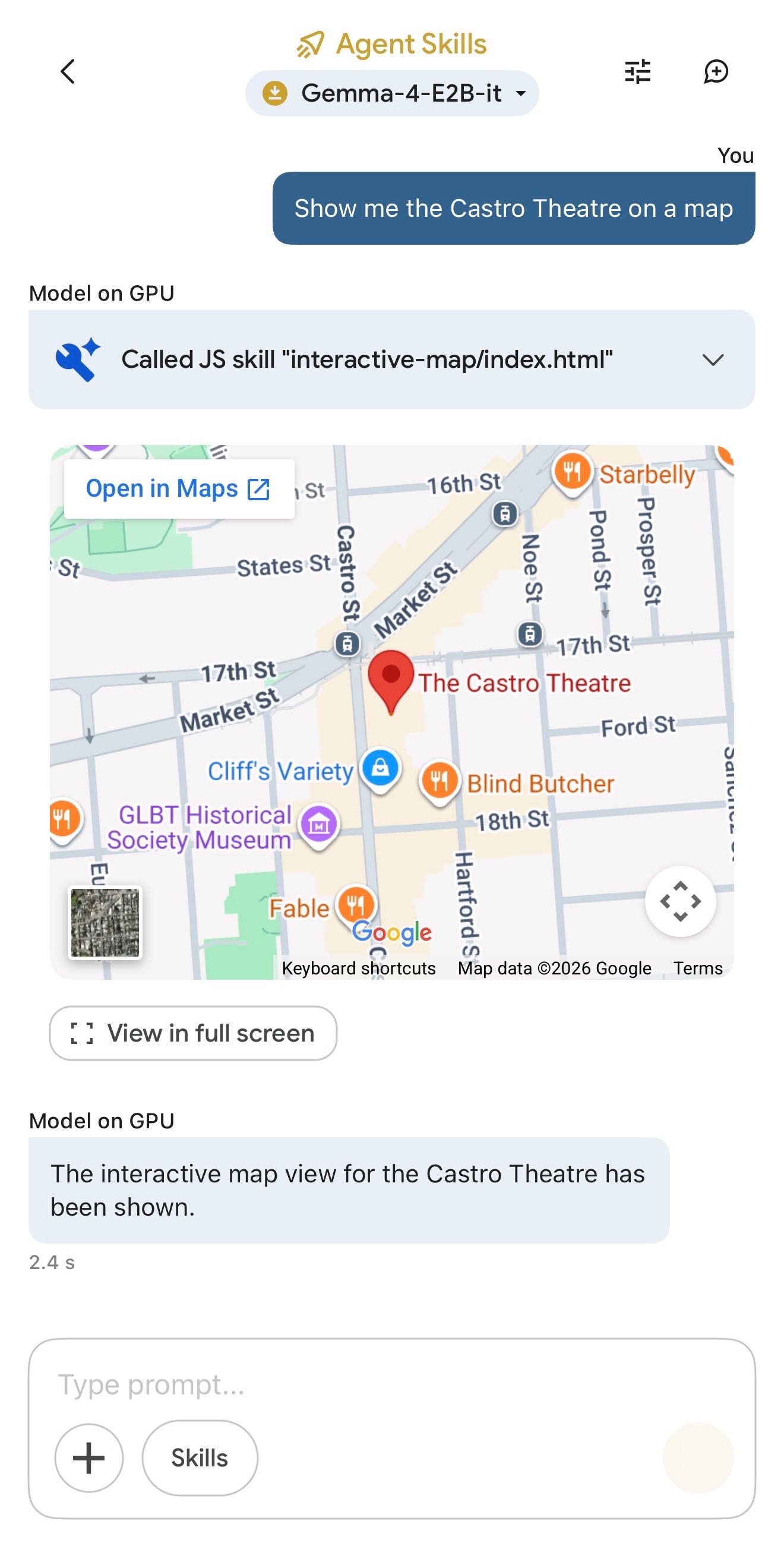
(That demo did freeze the app when I tried to add a follow-up prompt though.)
This is the first time I've seen a local model vendor release an official app for trying out their models on in iPhone. Sadly it's missing permanent logs - conversations with this app are ephemeral.
Gemma 4: Byte for byte, the most capable open models. Four new vision-capable Apache 2.0 licensed reasoning LLMs from Google DeepMind, sized at 2B, 4B, 31B, plus a 26B-A4B Mixture-of-Experts.
Google emphasize "unprecedented level of intelligence-per-parameter", providing yet more evidence that creating small useful models is one of the hottest areas of research right now.
They actually label the two smaller models as E2B and E4B for "Effective" parameter size. The system card explains:
The smaller models incorporate Per-Layer Embeddings (PLE) to maximize parameter efficiency in on-device deployments. Rather than adding more layers or parameters to the model, PLE gives each decoder layer its own small embedding for every token. These embedding tables are large but are only used for quick lookups, which is why the effective parameter count is much smaller than the total.
I don't entirely understand that, but apparently that's what the "E" in E2B means!
One particularly exciting feature of these models is that they are multi-modal beyond just images:
Vision and audio: All models natively process video and images, supporting variable resolutions, and excelling at visual tasks like OCR and chart understanding. Additionally, the E2B and E4B models feature native audio input for speech recognition and understanding.
I've not figured out a way to run audio input locally - I don't think that feature is in LM Studio or Ollama yet.
I tried them out using the GGUFs for LM Studio. The 2B (4.41GB), 4B (6.33GB) and 26B-A4B (17.99GB) models all worked perfectly, but the 31B (19.89GB) model was broken and spat out "---\n" in a loop for every prompt I tried.
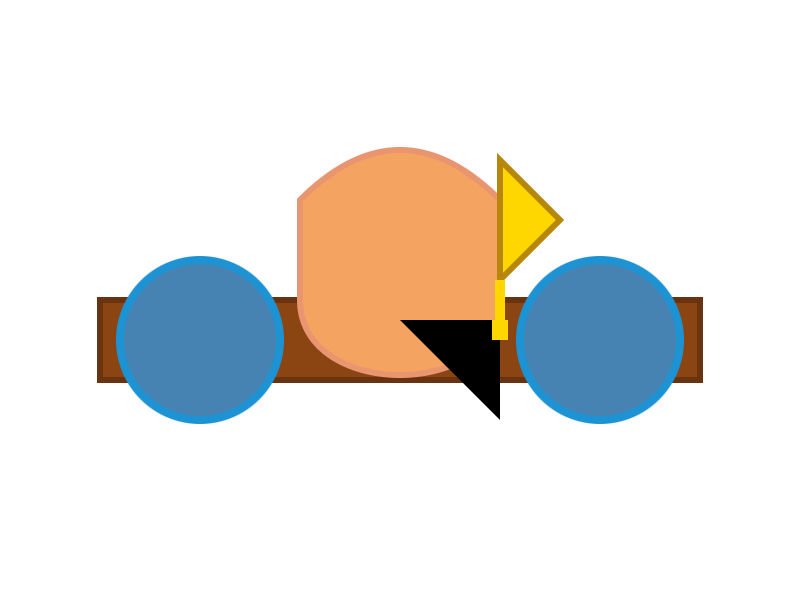
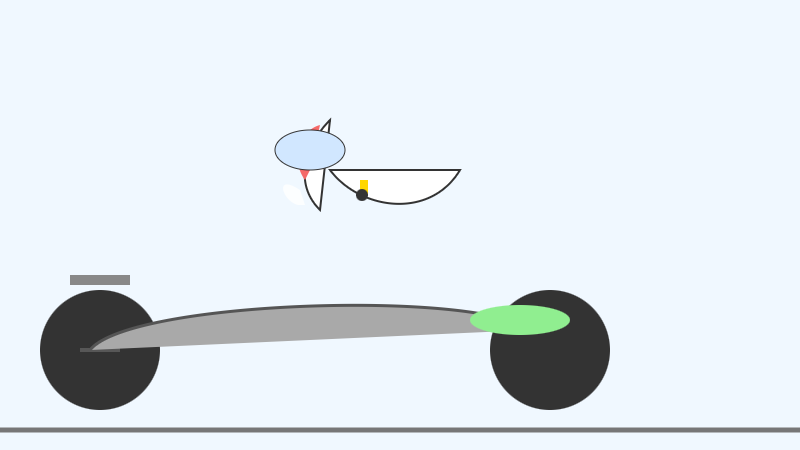
The succession of pelican quality from 2B to 4B to 26B-A4B is notable:
E2B:
E4B:
26B-A4B:

(This one actually had an SVG error - "error on line 18 at column 88: Attribute x1 redefined" - but after fixing that I got probably the best pelican I've seen yet from a model that runs on my laptop.)
Google are providing API access to the two larger Gemma models via their AI Studio. I added support to llm-gemini and then ran a pelican through the 31B model using that:
llm -m gemini/gemma-4-31b-it 'Generate an SVG of a pelican riding a bicycle'
Pretty good, though it is missing the front part of the bicycle frame:

Note that the main issues that people currently unknowingly face with local models mostly revolve around the harness and some intricacies around model chat templates and prompt construction. Sometimes there are even pure inference bugs. From typing the task in the client to the actual result, there is a long chain of components that atm are not only fragile - are also developed by different parties. So it's difficult to consolidate the entire stack and you have to keep in mind that what you are currently observing is with very high probability still broken in some subtle way along that chain.
— Georgi Gerganov, explaining why it's hard to find local models that work well with coding agents
Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer
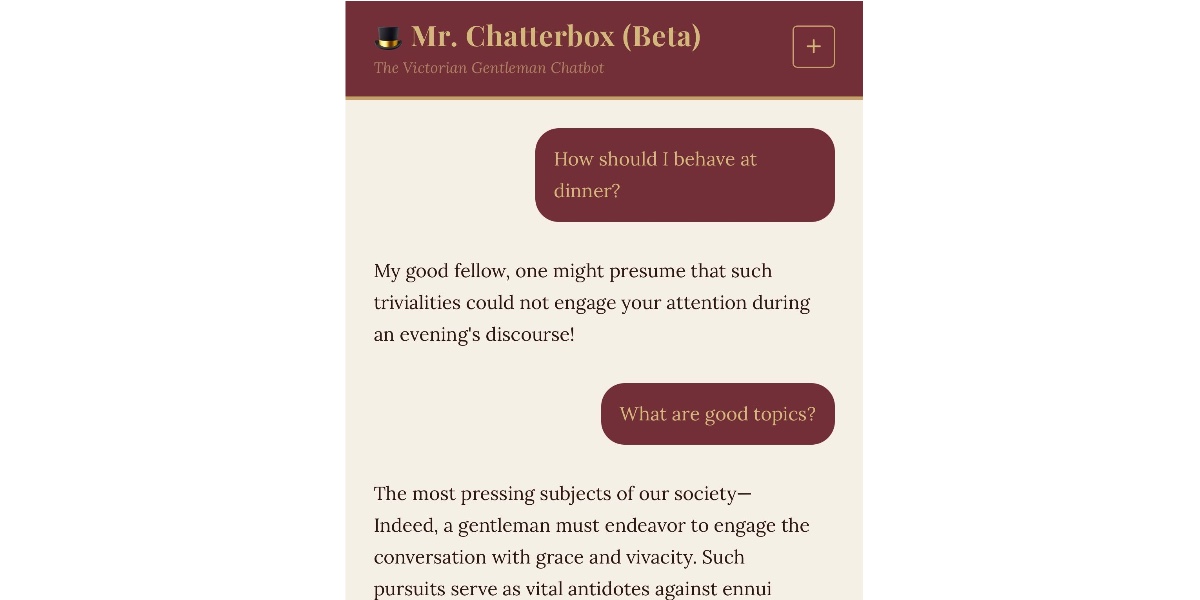
Trip Venturella released Mr. Chatterbox, a language model trained entirely on out-of-copyright text from the British Library. Here’s how he describes it in the model card:
[... 952 words]I wrote about Dan Woods' experiments with streaming experts the other day, the trick where you run larger Mixture-of-Experts models on hardware that doesn't have enough RAM to fit the entire model by instead streaming the necessary expert weights from SSD for each token that you process.
Five days ago Dan was running Qwen3.5-397B-A17B in 48GB of RAM. Today @seikixtc reported running the colossal Kimi K2.5 - a 1 trillion parameter model with 32B active weights at any one time, in 96GB of RAM on an M2 Max MacBook Pro.
And @anemll showed that same Qwen3.5-397B-A17B model running on an iPhone, albeit at just 0.6 tokens/second - iOS repo here.
I think this technique has legs. Dan and his fellow tinkerers are continuing to run autoresearch loops in order to find yet more optimizations to squeeze more performance out of these models.
Update: Now Daniel Isaac got Kimi K2.5 working on a 128GB M4 Max at ~1.7 tokens/second.
Autoresearching Apple’s “LLM in a Flash” to run Qwen 397B locally. Here's a fascinating piece of research by Dan Woods, who managed to get a custom version of Qwen3.5-397B-A17B running at 5.5+ tokens/second on a 48GB MacBook Pro M3 Max despite that model taking up 209GB (120GB quantized) on disk.
Qwen3.5-397B-A17B is a Mixture-of-Experts (MoE) model, which means that each token only needs to run against a subset of the overall model weights. These expert weights can be streamed into memory from SSD, saving them from all needing to be held in RAM at the same time.
Dan used techniques described in Apple's 2023 paper LLM in a flash: Efficient Large Language Model Inference with Limited Memory:
This paper tackles the challenge of efficiently running LLMs that exceed the available DRAM capacity by storing the model parameters in flash memory, but bringing them on demand to DRAM. Our method involves constructing an inference cost model that takes into account the characteristics of flash memory, guiding us to optimize in two critical areas: reducing the volume of data transferred from flash and reading data in larger, more contiguous chunks.
He fed the paper to Claude Code and used a variant of Andrej Karpathy's autoresearch pattern to have Claude run 90 experiments and produce MLX Objective-C and Metal code that ran the model as efficiently as possible.
danveloper/flash-moe has the resulting code plus a PDF paper mostly written by Claude Opus 4.6 describing the experiment in full.
The final model has the experts quantized to 2-bit, but the non-expert parts of the model such as the embedding table and routing matrices are kept at their original precision, adding up to 5.5GB which stays resident in memory while the model is running.
Qwen 3.5 usually runs 10 experts per token, but this setup dropped that to 4 while claiming that the biggest quality drop-off occurred at 3.
It's not clear to me how much the quality of the model results are affected. Claude claimed that "Output quality at 2-bit is indistinguishable from 4-bit for these evaluations", but the description of the evaluations it ran is quite thin.
Update: Dan's latest version upgrades to 4-bit quantization of the experts (209GB on disk, 4.36 tokens/second) after finding that the 2-bit version broke tool calling while 4-bit handles that well.
ggml.ai joins Hugging Face to ensure the long-term progress of Local AI (via) I don't normally cover acquisition news like this, but I have some thoughts.
It's hard to overstate the impact Georgi Gerganov has had on the local model space. Back in March 2023 his release of llama.cpp made it possible to run a local LLM on consumer hardware. The original README said:
The main goal is to run the model using 4-bit quantization on a MacBook. [...] This was hacked in an evening - I have no idea if it works correctly.
I wrote about trying llama.cpp out at the time in Large language models are having their Stable Diffusion moment:
I used it to run the 7B LLaMA model on my laptop last night, and then this morning upgraded to the 13B model—the one that Facebook claim is competitive with GPT-3.
Meta's original LLaMA release depended on PyTorch and their FairScale PyTorch extension for running on multiple GPUs, and required CUDA and NVIDIA hardware. Georgi's work opened that up to a much wider range of hardware and kicked off the local model movement that has continued to grow since then.
Hugging Face are already responsible for the incredibly influential Transformers library used by the majority of LLM releases today. They've proven themselves a good steward for that open source project, which makes me optimistic for the future of llama.cpp and related projects.
This section from the announcement looks particularly promising:
Going forward, our joint efforts will be geared towards the following objectives:
- Towards seamless "single-click" integration with the transformers library. The
transformersframework has established itself as the 'source of truth' for AI model definitions. Improving the compatibility between the transformers and the ggml ecosystems is essential for wider model support and quality control.- Better packaging and user experience of ggml-based software. As we enter the phase in which local inference becomes a meaningful and competitive alternative to cloud inference, it is crucial to improve and simplify the way in which casual users deploy and access local models. We will work towards making llama.cpp ubiquitous and readily available everywhere, and continue partnering with great downstream projects.
Given the influence of Transformers, this closer integration could lead to model releases that are compatible with the GGML ecosystem out of the box. That would be a big win for the local model ecosystem.
I'm also excited to see investment in "packaging and user experience of ggml-based software". This has mostly been left to tools like Ollama and LM Studio. ggml-org released LlamaBarn last year - "a macOS menu bar app for running local LLMs" - and I'm hopeful that further investment in this area will result in more high quality open source tools for running local models from the team best placed to deliver them.
2025
Using Codex CLI with gpt-oss:120b on an NVIDIA DGX Spark via Tailscale. Inspired by a YouTube comment I wrote up how I run OpenAI's Codex CLI coding agent against the gpt-oss:120b model running in Ollama on my NVIDIA DGX Spark via a Tailscale network.
It takes a little bit of work to configure but the result is I can now use Codex CLI on my laptop anywhere in the world against a self-hosted model.
I used it to build this space invaders clone.
MiniMax M2 & Agent: Ingenious in Simplicity. MiniMax M2 was released on Monday 27th October by MiniMax, a Chinese AI lab founded in December 2021.
It's a very promising model. Their self-reported benchmark scores show it as comparable to Claude Sonnet 4, and Artificial Analysis are ranking it as the best currently available open weight model according to their intelligence score:
MiniMax’s M2 achieves a new all-time-high Intelligence Index score for an open weights model and offers impressive efficiency with only 10B active parameters (200B total). [...]
The model’s strengths include tool use and instruction following (as shown by Tau2 Bench and IFBench). As such, while M2 likely excels at agentic use cases it may underperform other open weights leaders such as DeepSeek V3.2 and Qwen3 235B at some generalist tasks. This is in line with a number of recent open weights model releases from Chinese AI labs which focus on agentic capabilities, likely pointing to a heavy post-training emphasis on RL.
The size is particularly significant: the model weights are 230GB on Hugging Face, significantly smaller than other high performing open weight models. That's small enough to run on a 256GB Mac Studio, and the MLX community have that working already.
MiniMax offer their own API, and recommend using their Anthropic-compatible endpoint and the official Anthropic SDKs to access it. MiniMax Head of Engineering Skyler Miao provided some background on that:
M2 is a agentic thinking model, it do interleaved thinking like sonnet 4.5, which means every response will contain its thought content. Its very important for M2 to keep the chain of thought. So we must make sure the history thought passed back to the model. Anthropic API support it for sure, as sonnet needs it as well. OpenAI only support it in their new Response API, no support for in ChatCompletion.
MiniMax are offering the new model via their API for free until November 7th, after which the cost will be $0.30/million input tokens and $1.20/million output tokens - similar in price to Gemini 2.5 Flash and GPT-5 Mini, see price comparison here on my llm-prices.com site.
I released a new plugin for LLM called llm-minimax providing support for M2 via the MiniMax API:
llm install llm-minimax
llm keys set minimax
# Paste key here
llm -m m2 -o max_tokens 10000 "Generate an SVG of a pelican riding a bicycle"
Here's the result:

51 input, 4,017 output. At $0.30/m input and $1.20/m output that pelican would cost 0.4836 cents - less than half a cent.
This is the first plugin I've written for an Anthropic-API-compatible model. I released llm-anthropic 0.21 first adding the ability to customize the base_url parameter when using that model class. This meant the new plugin was less than 30 lines of Python.
NVIDIA DGX Spark + Apple Mac Studio = 4x Faster LLM Inference with EXO 1.0 (via) EXO Labs wired a 256GB M3 Ultra Mac Studio up to an NVIDIA DGX Spark and got a 2.8x performance boost serving Llama-3.1 8B (FP16) with an 8,192 token prompt.
Their detailed explanation taught me a lot about LLM performance.
There are two key steps in executing a prompt. The first is the prefill phase that reads the incoming prompt and builds a KV cache for each of the transformer layers in the model. This is compute-bound as it needs to process every token in the input and perform large matrix multiplications across all of the layers to initialize the model's internal state.
Performance in the prefill stage influences TTFT - time‑to‑first‑token.
The second step is the decode phase, which generates the output one token at a time. This part is limited by memory bandwidth - there's less arithmetic, but each token needs to consider the entire KV cache.
Decode performance influences TPS - tokens per second.
EXO noted that the Spark has 100 TFLOPS but only 273GB/s of memory bandwidth, making it a better fit for prefill. The M3 Ultra has 26 TFLOPS but 819GB/s of memory bandwidth, making it ideal for the decode phase.
They run prefill on the Spark, streaming the KV cache to the Mac over 10Gb Ethernet. They can start streaming earlier layers while the later layers are still being calculated. Then the Mac runs the decode phase, returning tokens faster than if the Spark had run the full process end-to-end.
NVIDIA DGX Spark: great hardware, early days for the ecosystem

NVIDIA sent me a preview unit of their new DGX Spark desktop “AI supercomputer”. I’ve never had hardware to review before! You can consider this my first ever sponsored post if you like, but they did not pay me any cash and aside from an embargo date they did not request (nor would I grant) any editorial input into what I write about the device.
[... 1,846 words]Video of GPT-OSS 20B running on a phone. GPT-OSS 20B is a very good model. At launch OpenAI claimed:
The gpt-oss-20b model delivers similar results to OpenAI o3‑mini on common benchmarks and can run on edge devices with just 16 GB of memory
Nexa AI just posted a video on Twitter demonstrating exactly that: the full GPT-OSS 20B running on a Snapdragon Gen 5 phone in their Nexa Studio Android app. It requires at least 16GB of RAM, and benefits from Snapdragon using a similar trick to Apple Silicon where the system RAM is available to both the CPU and the GPU.
The latest iPhone 17 Pro Max is still stuck at 12GB of RAM, presumably not enough to run this same model.
Locally AI. Handy new iOS app by Adrien Grondin for running local LLMs on your phone. It just added support for the new iOS 26 Apple Foundation model, so you can install this app and instantly start a conversation with that model without any additional download.
The app can also run a variety of other models using MLX, including members of the Gemma, Llama 3.2, and and Qwen families.
Load Llama-3.2 WebGPU in your browser from a local folder (via) Inspired by a comment on Hacker News I decided to see if it was possible to modify the transformers.js-examples/tree/main/llama-3.2-webgpu Llama 3.2 chat demo (online here, I wrote about it last November) to add an option to open a local model file directly from a folder on disk, rather than waiting for it to download over the network.
I posed the problem to OpenAI's GPT-5-enabled Codex CLI like this:
git clone https://github.com/huggingface/transformers.js-examples
cd transformers.js-examples/llama-3.2-webgpu
codex
Then this prompt:
Modify this application such that it offers the user a file browse button for selecting their own local copy of the model file instead of loading it over the network. Provide a "download model" option too.
Codex churned away for several minutes, even running commands like curl -sL https://raw.githubusercontent.com/huggingface/transformers.js/main/src/models.js | sed -n '1,200p' to inspect the source code of the underlying Transformers.js library.
After four prompts total (shown here) it built something which worked!
To try it out you'll need your own local copy of the Llama 3.2 ONNX model. You can get that (a ~1.2GB) download) like so:
git lfs install
git clone https://huggingface.co/onnx-community/Llama-3.2-1B-Instruct-q4f16
Then visit my llama-3.2-webgpu page in Chrome or Firefox Nightly (since WebGPU is required), click "Browse folder", select that folder you just cloned, agree to the "Upload" confirmation (confusing since nothing is uploaded from your browser, the model file is opened locally on your machine) and click "Load local model".
Here's an animated demo (recorded in real-time, I didn't speed this up):
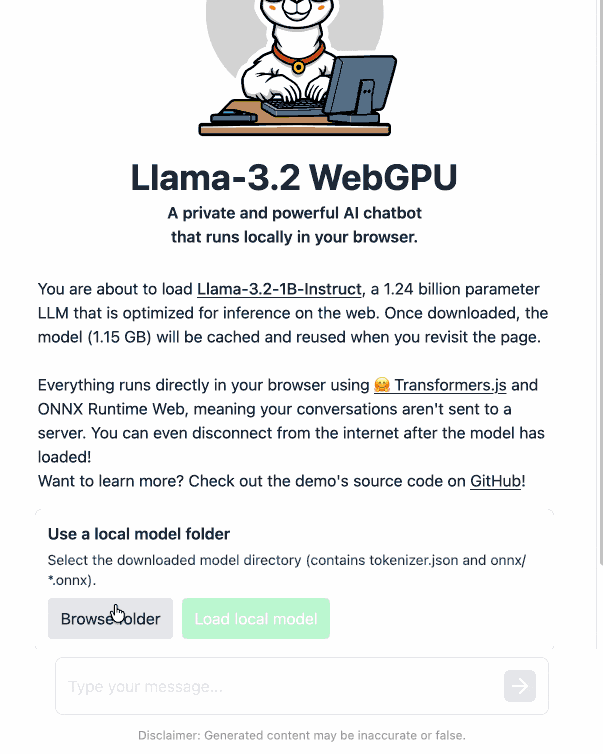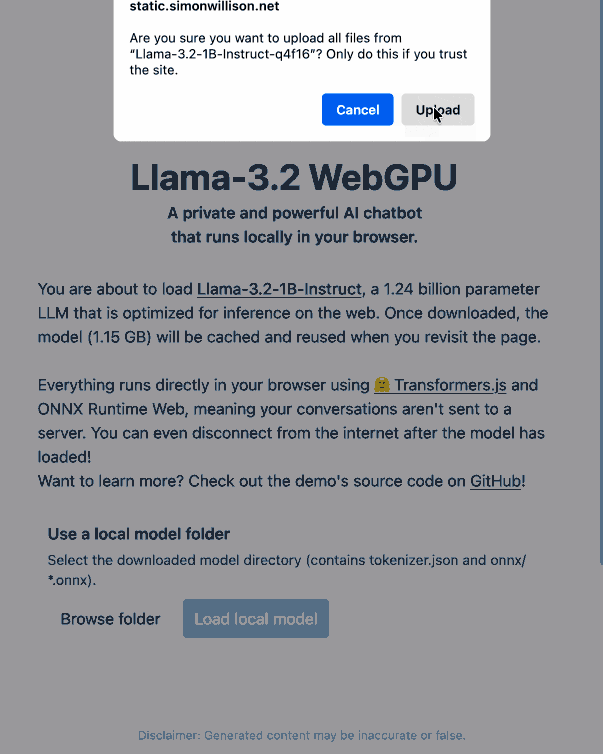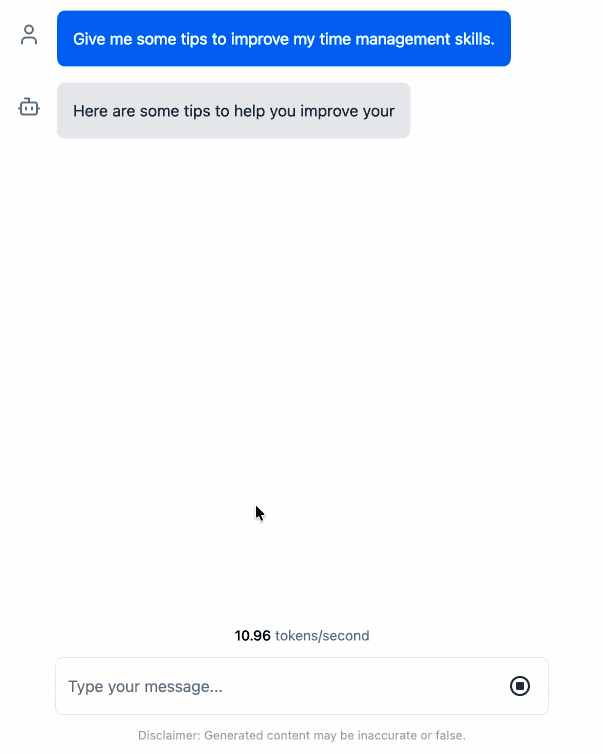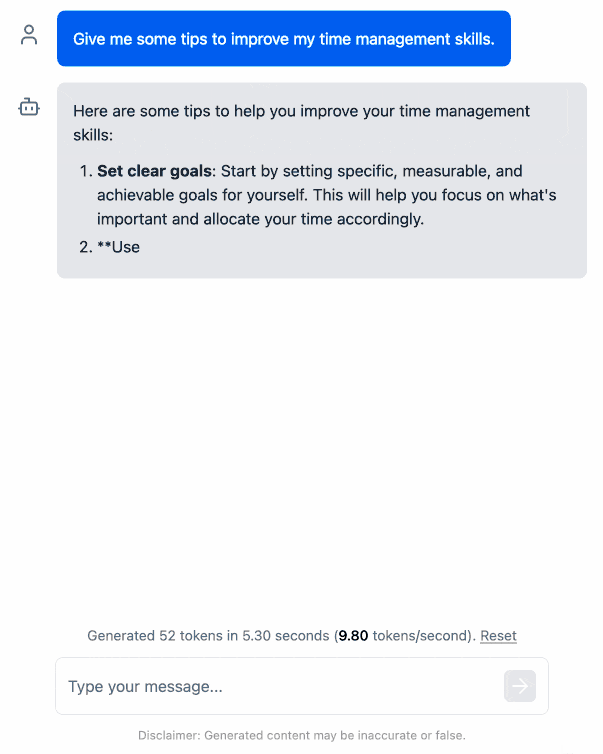
I pushed a branch with those changes here. The next step would be to modify this to support other models in addition to the Llama 3.2 demo, but I'm pleased to have got to this proof of concept with so little work beyond throwing some prompts at Codex to see if it could figure it out.
According to the Codex /status command this used 169,818 input tokens, 17,112 output tokens and 1,176,320 cached input tokens. At current GPT-5 token pricing ($1.25/million input, $0.125/million cached input, $10/million output) that would cost 53.942 cents, but Codex CLI hooks into my existing $20/month ChatGPT Plus plan so this was bundled into that.
llama.cpp guide: running gpt-oss with llama.cpp
(via)
Really useful official guide to running the OpenAI gpt-oss models using llama-server from llama.cpp - which provides an OpenAI-compatible localhost API and a neat web interface for interacting with the models.
TLDR version for macOS to run the smaller gpt-oss-20b model:
brew install llama.cpp
llama-server -hf ggml-org/gpt-oss-20b-GGUF \
--ctx-size 0 --jinja -ub 2048 -b 2048 -ngl 99 -fa
This downloads a 12GB model file from ggml-org/gpt-oss-20b-GGUF on Hugging Face, stores it in ~/Library/Caches/llama.cpp/ and starts it running on port 8080.
You can then visit this URL to start interacting with the model:
http://localhost:8080/
On my 64GB M2 MacBook Pro it runs at around 82 tokens/second.
The guide also includes notes for running on NVIDIA and AMD hardware.
TIL: Running a gpt-oss eval suite against LM Studio on a Mac. The other day I learned that OpenAI published a set of evals as part of their gpt-oss model release, described in their cookbook on Verifying gpt-oss implementations.
I decided to try and run that eval suite on my own MacBook Pro, against gpt-oss-20b running inside of LM Studio.
TLDR: once I had the model running inside LM Studio with a longer than default context limit, the following incantation ran an eval suite in around 3.5 hours:
mkdir /tmp/aime25_openai
OPENAI_API_KEY=x \
uv run --python 3.13 --with 'gpt-oss[eval]' \
python -m gpt_oss.evals \
--base-url http://localhost:1234/v1 \
--eval aime25 \
--sampler chat_completions \
--model openai/gpt-oss-20b \
--reasoning-effort low \
--n-threads 2
My new TIL breaks that command down in detail and walks through the underlying eval - AIME 2025, which asks 30 questions (8 times each) that are defined using the following format:
{"question": "Find the sum of all integer bases $b>9$ for which $17_{b}$ is a divisor of $97_{b}$.", "answer": "70"}
Open weight LLMs exhibit inconsistent performance across providers
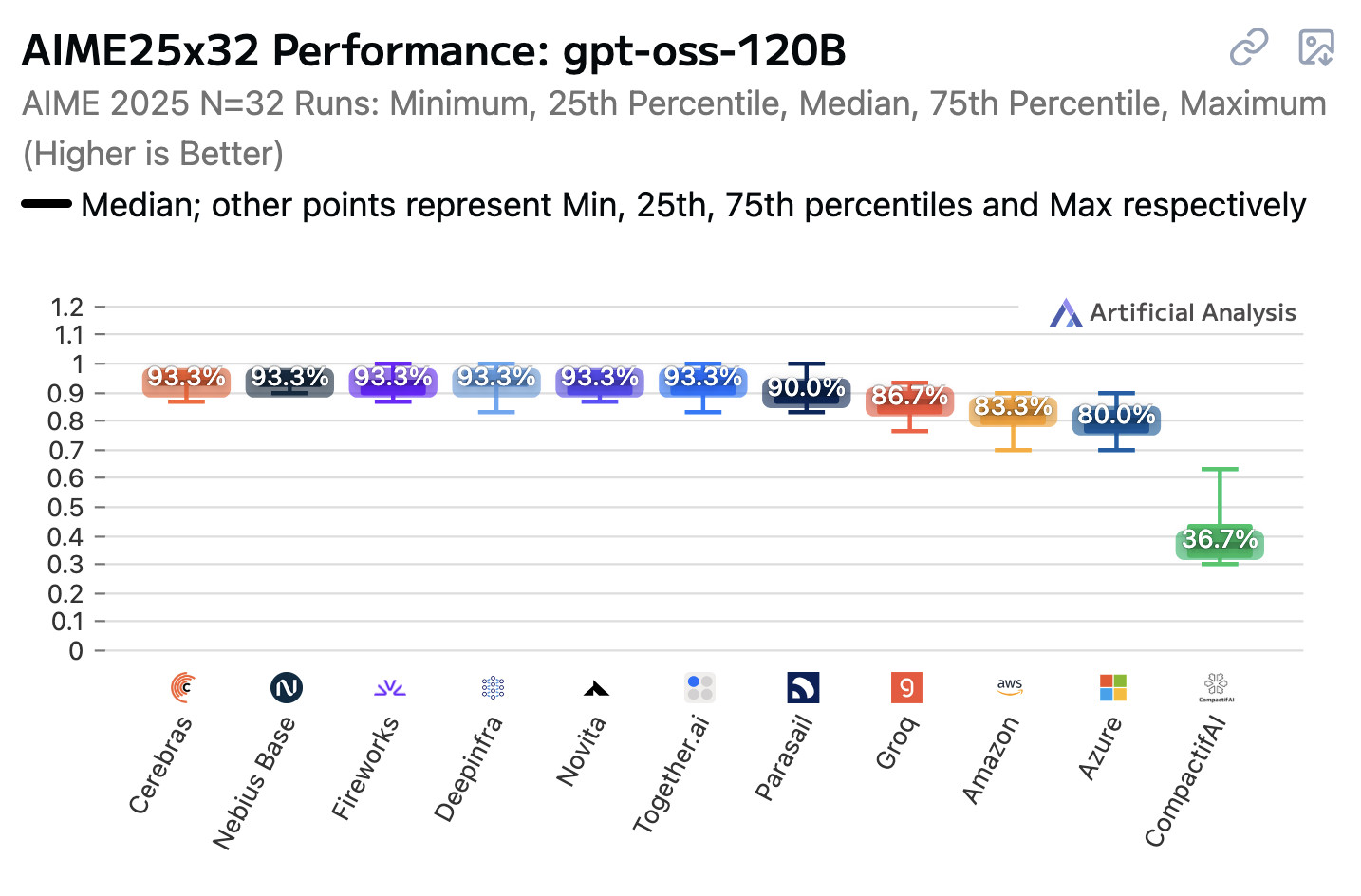
Artificial Analysis published a new benchmark the other day, this time focusing on how an individual model—OpenAI’s gpt-oss-120b—performs across different hosted providers.
[... 847 words]Introducing Gemma 3 270M: The compact model for hyper-efficient AI (via) New from Google:
Gemma 3 270M, a compact, 270-million parameter model designed from the ground up for task-specific fine-tuning with strong instruction-following and text structuring capabilities already trained in.
This model is tiny. The version I tried was the LM Studio GGUF one, a 241MB download.
It works! You can say "hi" to it and ask it very basic questions like "What is the capital of France".
I tried "Generate an SVG of a pelican riding a bicycle" about a dozen times and didn't once get back an SVG that was more than just a blank square... but at one point it did decide to write me this poem instead, which was nice:
+-----------------------+
| Pelican Riding Bike |
+-----------------------+
| This is the cat! |
| He's got big wings and a happy tail. |
| He loves to ride his bike! |
+-----------------------+
| Bike lights are shining bright. |
| He's got a shiny top, too! |
| He's ready for adventure! |
+-----------------------+
That's not really the point though. The Gemma 3 team make it very clear that the goal of this model is to support fine-tuning: a model this tiny is never going to be useful for general purpose LLM tasks, but given the right fine-tuning data it should be able to specialize for all sorts of things:
In engineering, success is defined by efficiency, not just raw power. You wouldn't use a sledgehammer to hang a picture frame. The same principle applies to building with AI.
Gemma 3 270M embodies this "right tool for the job" philosophy. It's a high-quality foundation model that follows instructions well out of the box, and its true power is unlocked through fine-tuning. Once specialized, it can execute tasks like text classification and data extraction with remarkable accuracy, speed, and cost-effectiveness. By starting with a compact, capable model, you can build production systems that are lean, fast, and dramatically cheaper to operate.
Here's their tutorial on Full Model Fine-Tune using Hugging Face Transformers, which I have not yet attempted to follow.
I imagine this model will be particularly fun to play with directly in a browser using transformers.js.
Update: It is! Here's a bedtime story generator using Transformers.js (requires WebGPU, so Chrome-like browsers only). Here's the source code for that demo.
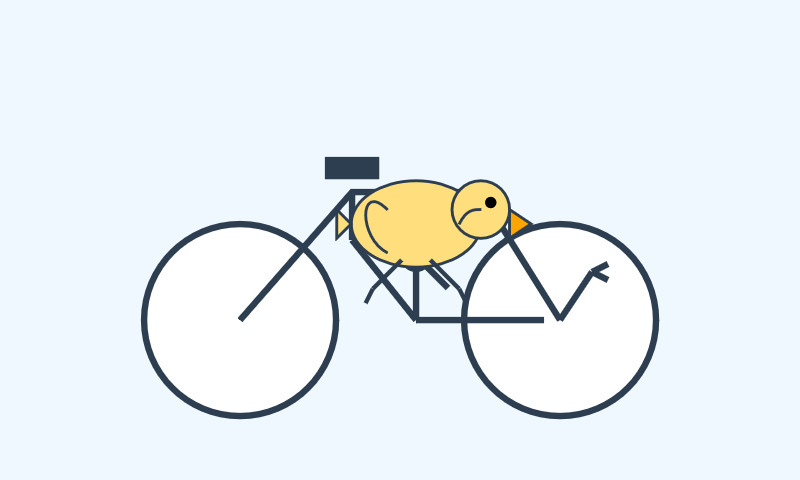
Qwen3-4B-Thinking: “This is art—pelicans don’t ride bikes!”

I’ve fallen a few days behind keeping up with Qwen. They released two new 4B models last week: Qwen3-4B-Instruct-2507 and its thinking equivalent Qwen3-4B-Thinking-2507.
[... 991 words]OpenAI’s new open weight (Apache 2) models are really good
The long promised OpenAI open weight models are here, and they are very impressive. They’re available under proper open source licenses—Apache 2.0—and come in two sizes, 120B and 20B.
[... 2,771 words]Ollama’s new app (via) Ollama has been one of my favorite ways to run local models for a while - it makes it really easy to download models, and it's smart about keeping them resident in memory while they are being used and then cleaning them out after they stop receiving traffic.
The one missing feature to date has been an interface: Ollama has been exclusively command-line, which is fine for the CLI literate among us and not much use for everyone else.
They've finally fixed that! The new app's interface is accessible from the existing system tray menu and lets you chat with any of your installed models. Vision models can accept images through the new interface as well.
Something that has become undeniable this month is that the best available open weight models now come from the Chinese AI labs.
I continue to have a lot of love for Mistral, Gemma and Llama but my feeling is that Qwen, Moonshot and Z.ai have positively smoked them over the course of July.
Here's what came out this month, with links to my notes on each one:
- Moonshot Kimi-K2-Instruct - 11th July, 1 trillion parameters
- Qwen Qwen3-235B-A22B-Instruct-2507 - 21st July, 235 billion
- Qwen Qwen3-Coder-480B-A35B-Instruct - 22nd July, 480 billion
- Qwen Qwen3-235B-A22B-Thinking-2507 - 25th July, 235 billion
- Z.ai GLM-4.5 and GLM-4.5 Air - 28th July, 355 and 106 billion
- Qwen Qwen3-30B-A3B-Instruct-2507 - 29th July, 30 billion
- Qwen Qwen3-30B-A3B-Thinking-2507 - 30th July, 30 billion
- Qwen Qwen3-Coder-30B-A3B-Instruct - 31st July, 30 billion (released after I first posted this note)
Notably absent from this list is DeepSeek, but that's only because their last model release was DeepSeek-R1-0528 back in April.
The only janky license among them is Kimi K2, which uses a non-OSI-compliant modified MIT. Qwen's models are all Apache 2 and Z.ai's are MIT.
The larger Chinese models all offer their own APIs and are increasingly available from other providers. I've been able to run versions of the Qwen 30B and GLM-4.5 Air 106B models on my own laptop.
I can't help but wonder if part of the reason for the delay in release of OpenAI's open weights model comes from a desire to be notably better than this truly impressive lineup of Chinese models.
Update August 5th 2025: The OpenAI open weight models came out and they are very impressive.
My 2.5 year old laptop can write Space Invaders in JavaScript now, using GLM-4.5 Air and MLX
I wrote about the new GLM-4.5 model family yesterday—new open weight (MIT licensed) models from Z.ai in China which their benchmarks claim score highly in coding even against models such as Claude Sonnet 4.
[... 685 words]GLM-4.5: Reasoning, Coding, and Agentic Abililties. Another day, another significant new open weight model release from a Chinese frontier AI lab.
This time it's Z.ai - who rebranded (at least in English) from Zhipu AI a few months ago. They just dropped GLM-4.5-Base, GLM-4.5 and GLM-4.5 Air on Hugging Face, all under an MIT license.
These are MoE hybrid reasoning models with thinking and non-thinking modes, similar to Qwen 3. GLM-4.5 is 355 billion total parameters with 32 billion active, GLM-4.5-Air is 106 billion total parameters and 12 billion active.
They started using MIT a few months ago for their GLM-4-0414 models - their older releases used a janky non-open-source custom license.
Z.ai's own benchmarking (across 12 common benchmarks) ranked their GLM-4.5 3rd behind o3 and Grok-4 and just ahead of Claude Opus 4. They ranked GLM-4.5 Air 6th place just ahead of Claude 4 Sonnet. I haven't seen any independent benchmarks yet.
The other models they included in their own benchmarks were o4-mini (high), Gemini 2.5 Pro, Qwen3-235B-Thinking-2507, DeepSeek-R1-0528, Kimi K2, GPT-4.1, DeepSeek-V3-0324. Notably absent: any of Meta's Llama models, or any of Mistral's. Did they deliberately only compare themselves to open weight models from other Chinese AI labs?
Both models have a 128,000 context length and are trained for tool calling, which honestly feels like table stakes for any model released in 2025 at this point.
It's interesting to see them use Claude Code to run their own coding benchmarks:
To assess GLM-4.5's agentic coding capabilities, we utilized Claude Code to evaluate performance against Claude-4-Sonnet, Kimi K2, and Qwen3-Coder across 52 coding tasks spanning frontend development, tool development, data analysis, testing, and algorithm implementation. [...] The empirical results demonstrate that GLM-4.5 achieves a 53.9% win rate against Kimi K2 and exhibits dominant performance over Qwen3-Coder with an 80.8% success rate. While GLM-4.5 shows competitive performance, further optimization opportunities remain when compared to Claude-4-Sonnet.
They published the dataset for that benchmark as zai-org/CC-Bench-trajectories on Hugging Face. I think they're using the word "trajectory" for what I would call a chat transcript.
Unlike DeepSeek-V3 and Kimi K2, we reduce the width (hidden dimension and number of routed experts) of the model while increasing the height (number of layers), as we found that deeper models exhibit better reasoning capacity.
They pre-trained on 15 trillion tokens, then an additional 7 trillion for code and reasoning:
Our base model undergoes several training stages. During pre-training, the model is first trained on 15T tokens of a general pre-training corpus, followed by 7T tokens of a code & reasoning corpus. After pre-training, we introduce additional stages to further enhance the model's performance on key downstream domains.
They also open sourced their post-training reinforcement learning harness, which they've called slime. That's available at THUDM/slime on GitHub - THUDM is the Knowledge Engineer Group @ Tsinghua University, the University from which Zhipu AI spun out as an independent company.
This time I ran my pelican bechmark using the chat.z.ai chat interface, which offers free access (no account required) to both GLM 4.5 and GLM 4.5 Air. I had reasoning enabled for both.
Here's what I got for "Generate an SVG of a pelican riding a bicycle" on GLM 4.5. I like how the pelican has its wings on the handlebars:

And GLM 4.5 Air:

Ivan Fioravanti shared a video of the mlx-community/GLM-4.5-Air-4bit quantized model running on a M4 Mac with 128GB of RAM, and it looks like a very strong contender for a local model that can write useful code. The cheapest 128GB Mac Studio costs around $3,500 right now, so genuinely great open weight coding models are creeping closer to being affordable on consumer machines.
Update: Ivan released a 3 bit quantized version of GLM-4.5 Air which runs using 48GB of RAM on my laptop. I tried it and was really impressed, see My 2.5 year old laptop can write Space Invaders in JavaScript now.
How to run an LLM on your laptop. I talked to Grace Huckins for this piece from MIT Technology Review on running local models. Apparently she enjoyed my dystopian backup plan!
Simon Willison has a plan for the end of the world. It’s a USB stick, onto which he has loaded a couple of his favorite open-weight LLMs—models that have been shared publicly by their creators and that can, in principle, be downloaded and run with local hardware. If human civilization should ever collapse, Willison plans to use all the knowledge encoded in their billions of parameters for help. “It’s like having a weird, condensed, faulty version of Wikipedia, so I can help reboot society with the help of my little USB stick,” he says.
The article suggests Ollama or LM Studio for laptops, and new-to-me LLM Farm for the iPhone:
My beat-up iPhone 12 was able to run Meta’s Llama 3.2 1B using an app called LLM Farm. It’s not a particularly good model—it very quickly goes off into bizarre tangents and hallucinates constantly—but trying to coax something so chaotic toward usability can be entertaining.
Update 19th July 20205: Evan Hahn compared the size of various offline LLMs to different Wikipedia exports. Full English Wikipedia without images, revision history or talk pages is 13.82GB, smaller than Mistral Small 3.2 (15GB) but larger than Qwen 3 14B and Gemma 3n.
LM Studio is free for use at work. A notable policy change for LM Studio. Their excellent macOS app (and Linux and Windows, but I've only tried it on Mac) was previously free for personal use but required a license for commercial purposes:
Until now, the LM Studio app terms stated that for use at a company or organization, you should get in touch with us and get separate commercial license. This requirement is now removed.
Starting today, there's no need to fill a form or contact us. You and your team can just use LM Studio at work!
Introducing Gemma 3n: The developer guide. Extremely consequential new open weights model release from Google today:
Multimodal by design: Gemma 3n natively supports image, audio, video, and text inputs and text outputs.
Optimized for on-device: Engineered with a focus on efficiency, Gemma 3n models are available in two sizes based on effective parameters: E2B and E4B. While their raw parameter count is 5B and 8B respectively, architectural innovations allow them to run with a memory footprint comparable to traditional 2B and 4B models, operating with as little as 2GB (E2B) and 3GB (E4B) of memory.
This is very exciting: a 2B and 4B model optimized for end-user devices which accepts text, images and audio as inputs!
Gemma 3n is also the most comprehensive day one launch I've seen for any model: Google partnered with "AMD, Axolotl, Docker, Hugging Face, llama.cpp, LMStudio, MLX, NVIDIA, Ollama, RedHat, SGLang, Unsloth, and vLLM" so there are dozens of ways to try this out right now.
So far I've run two variants on my Mac laptop. Ollama offer a 7.5GB version (full tag gemma3n:e4b-it-q4_K_M0) of the 4B model, which I ran like this:
ollama pull gemma3n
llm install llm-ollama
llm -m gemma3n:latest "Generate an SVG of a pelican riding a bicycle"
It drew me this:

The Ollama version doesn't appear to support image or audio input yet.
... but the mlx-vlm version does!
First I tried that on this WAV file like so (using a recipe adapted from Prince Canuma's video):
uv run --with mlx-vlm mlx_vlm.generate \
--model gg-hf-gm/gemma-3n-E4B-it \
--max-tokens 100 \
--temperature 0.7 \
--prompt "Transcribe the following speech segment in English:" \
--audio pelican-joke-request.wav
That downloaded a 15.74 GB bfloat16 version of the model and output the following correct transcription:
Tell me a joke about a pelican.
Then I had it draw me a pelican for good measure:
uv run --with mlx-vlm mlx_vlm.generate \
--model gg-hf-gm/gemma-3n-E4B-it \
--max-tokens 100 \
--temperature 0.7 \
--prompt "Generate an SVG of a pelican riding a bicycle"
I quite like this one:
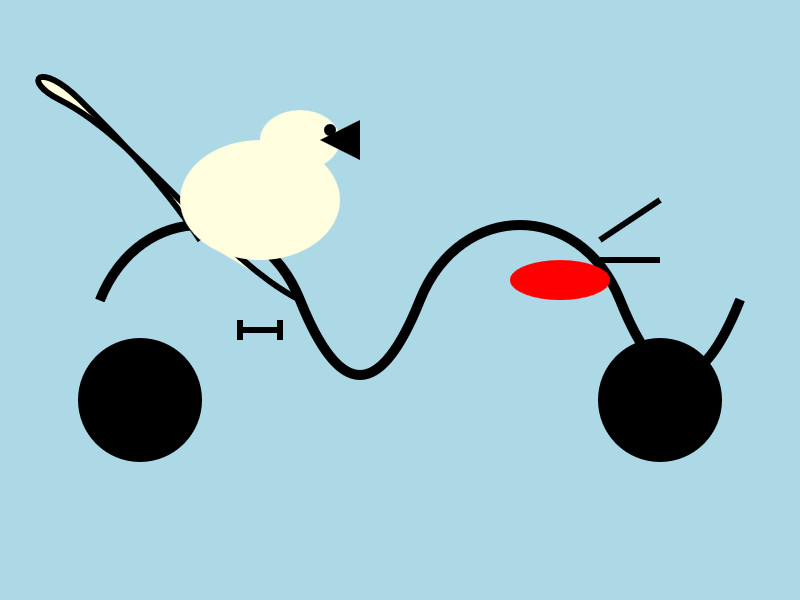
It's interesting to see such a striking visual difference between those 7.5GB and 15GB model quantizations.
Finally, I had it describe the image it had just created:
uv run --with mlx-vlm mlx_vlm.generate \
--model gg-hf-gm/gemma-3n-E4B-it \
--max-tokens 1000 \
--prompt "Describe image" \
--image gemma3n-mlx-vlm.jpg
Here's what I got back - it thought this was a chemical diagram!
The image is a cartoon-style illustration depicting a molecular structure against a light blue background. The structure is composed of several differently colored and shaped elements connected by curved black lines.
Here's a breakdown of the elements:
- Large Black Circles: There are two large, solid black circles, likely representing larger molecules or components.
- Cream-Colored Oval: A prominent cream-colored oval shape is centrally located and connected to other elements. It has a smaller, darker cream-colored sphere attached to its left side.
- Red Oval: A smaller, solid red oval is positioned near one of the black circles and connected to the cream-colored oval.
- Black Lines: These lines act as bonds, connecting the various molecular components. They are curved and dynamic, suggesting movement or interaction.
- Triangular Shape: A small black triangle is attached to the smaller cream-colored sphere.
- Letter "I": The letter "I" appears twice, likely labeling specific parts of the molecule.
The overall impression is of a simplified representation of a biological molecule, possibly a protein or a complex organic compound. The use of different colors helps to distinguish the various components within the structure.