391 posts tagged “ai-assisted-programming”
Using AI tools such as Large Language Models to help write code. Vibe coding is the less responsible subset of this. See Here’s how I use LLMs to help me write code for a description of my process.
2026
simonw/browser-compat-db. Inspired by Mozilla's new MDN MCP service - source code here - I decided to try converting their comprehensive mdn/browser-compat-data repository full of browser compatibility data into a SQLite database.
This new GitHub repo includes a Claude Code for web (Opus 4.8) generated script for doing that using sqlite-utils.
I wanted the resulting ~66MB SQLite database to be available via the GitHub CDN with open CORS headers. GitHub releases don't have those, but any file stored in a regular GitHub repository does - so I had Codex Desktop (GPT-5.5) build a GitHub Actions workflow that builds the database and then force-pushes it to a db "orphan" branch.
You can download the resulting database from here, and since it's hosted with open CORS headers you can also explore it with Datasette Lite.
Datasette Apps: Host custom HTML applications inside Datasette
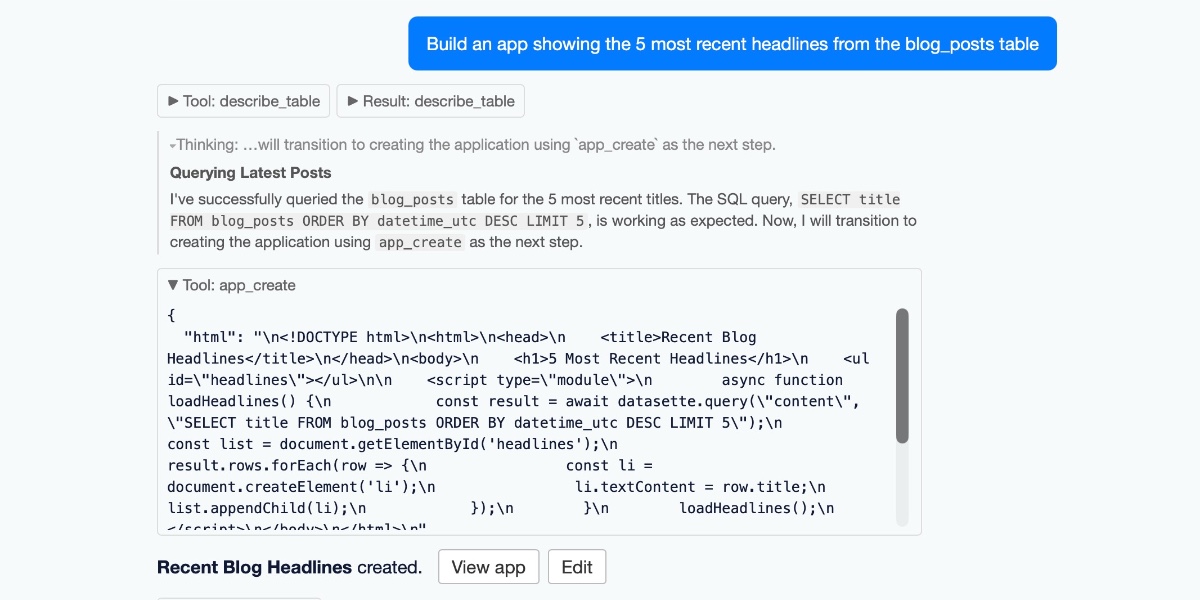
Today we launched a new plugin for Datasette, datasette-apps, with this launch announcement post on the Datasette project blog. That post has the what, but I’m going to expand on that a little bit here to provide the why.
[... 2,301 words]What happened in 2025 was this: the economics of code production were turned upside down. Instead of being very hard, time-consuming, and expensive to generate code, it became effectively free and instant. Lines of code went from being treasured, reused, cared for and carefully curated, to being disposable and regenerable, practically overnight.
— Charity Majors, AI demands more engineering discipline. Not less
I can 100% attest to the fact that Qwen3.6-27B is a very capable local model for coding tasks. Over the last month and a half I've been using it almost daily, either on my M2 Ultra or on my RTX 5090 box. I use it for small mundane tasks at ggml-org - nothing really impressive, but definitely a helpful tool for a maintainer. I think I would be using it much more, if I didn't have to spend a lot of my time on reviewing PRs. Currently, I have a very lightweight harness - the pi agent with everything stripped (
pi -nc --offline) and a short system prompt to align it a bit with my style.
— Georgi Gerganov, Hacker News comment on Running local models is good now by Boykis
Claude Fable is relentlessly proactive
After two days of experience with Claude Fable 5 I think the best way to describe it is relentlessly proactive. It knows a whole lot of tricks and it will deploy pretty much any of them to get to its goal.
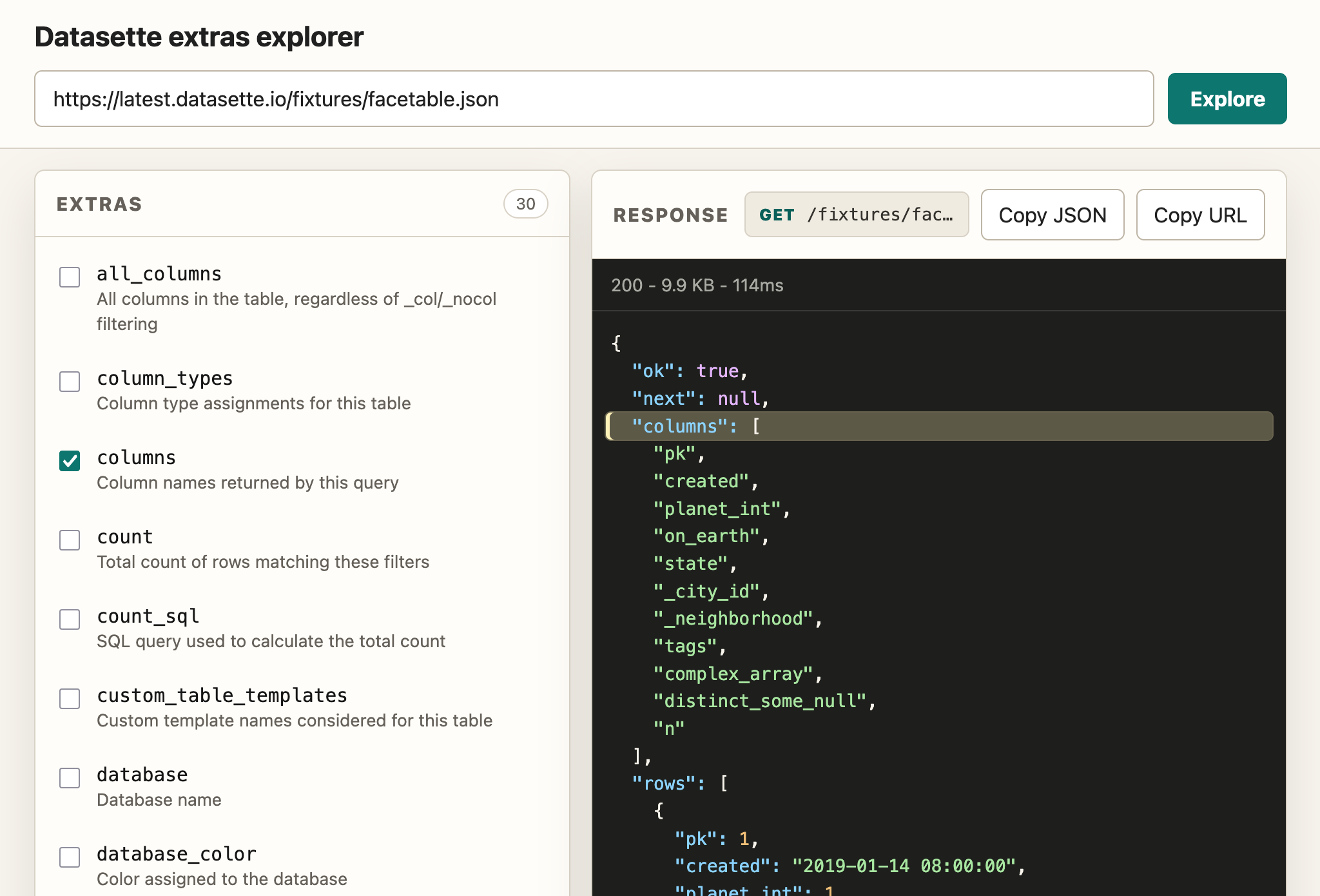
[... 1,939 words]This alpha is a significant step on the road to a stable 1.0, finally extending the ?_extra= pattern I introduced in Datasette 1.0a3 to cover queries and rows in addition to tables. That pattern is also now documented!
I wrote a whole lot more about the new release on the Datasette project blog: Datasette 1.0a33 with JSON extras in the API.
Because API explorer tools are almost free to build now I had Claude Fable 5 in Claude Code (for the plan) and GPT-5.5 xhigh in Codex Desktop (for the implementation) build me this custom extras API explorer to help demonstrate the feature:
Running Python code in a sandbox with MicroPython and WASM
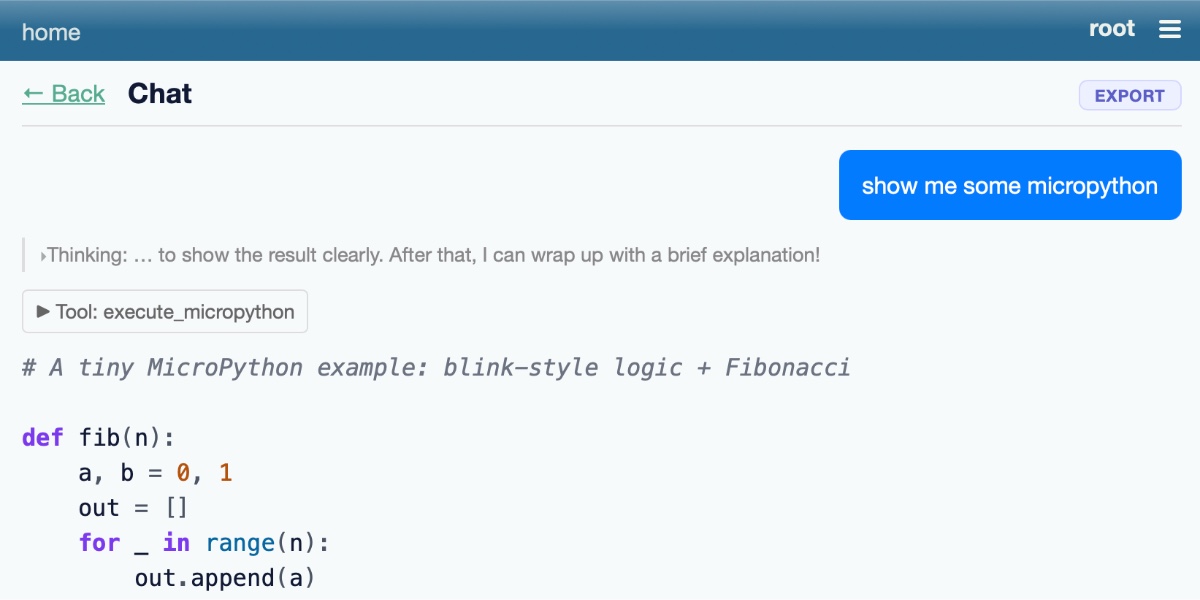
I’ve been experimenting with different approaches to running code in a sandbox for several years now, but my latest attempt feels like it might finally have all of the characteristics I’ve been looking for. I’ve released it as an alpha package called micropython-wasm, and I’m using it for a code execution sandbox plugin for Datasette Agent called datasette-agent-micropython.
[... 2,024 words]I really like how you can paste a large volume of text into claude.ai (or the Claude desktop/mobile apps) and it will detect it as a large paste and turn it into a file attachment instead.
I decided to have Codex desktop build me a version of that as a prototype.
You can also open files directly - including images which will be shown as thumbnails - or drag files onto the textarea.
This Mitchell Hashimoto quote about Bun migrating from Zig to Rust reminded me of a similar conversation I had at a conference last week.
I was talking to someone who worked for a medium sized technology company with a pair of legacy/legendary iPhone and Android apps.
They told me they had just completed a coding-agent driven rewrite of both apps to React Native.
I asked why they chose that, given that coding agents presumably drive down the cost of maintaining separate iPhone and Android apps.
They said that React Native has improved a lot over the past few years and covered everything their apps needed to do.
And... if it turned out to be the wrong decision, they could just port back to native in the future.
Like Mitchell said:
Programming languages used to be LOCK IN, and they're increasingly not so.
Welcome to the Datasette blog. We have a bunch of neat Datasette announcements in the pipeline so we decided it was time the project grew an official blog.
I built this using OpenAI Codex desktop, which turns out to have the Markdown session transcript export feature I've always wanted. Here's the session that built the blog. See also issue 179.
Your AI coding agent, the one you use to write code, needs to reduce your maintenance costs. Not by a little bit, either. You write code twice as quick now? Better hope you’ve halved your maintenance costs. Three times as productive? One third the maintenance costs. Otherwise, you’re screwed. You’re trading a temporary speed boost for permanent indenture. [...]
The math only works if the LLM decreases your maintenance costs, and by exactly the inverse of the rate it adds code. If you double your output and your cost of maintaining that output, two times two means you’ve quadrupled your maintenance costs. If you double your output and hold your maintenance costs steady, two times one means you’ve still doubled your maintenance costs.
— James Shore, You Need AI That Reduces Maintenance Costs
/elsewhere/sightings/. I have a new camera (a Canon R6 Mark II) so I'm taking a lot more photos of birds. I share my best wildlife photos on iNaturalist, and based on yesterday's successful prototype I decided to add those to my blog.
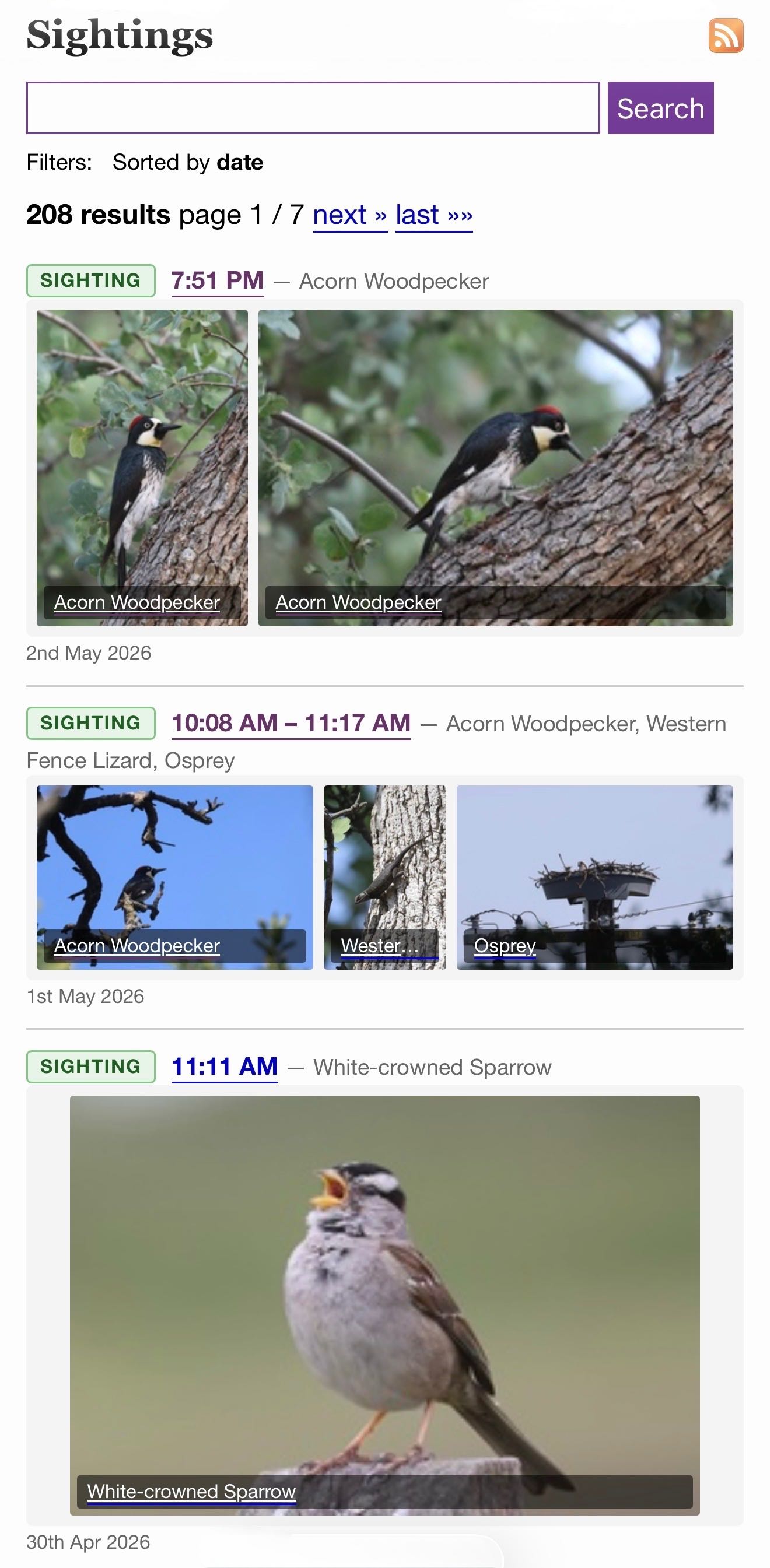
I built this feature on my phone using Claude Code for web, as an extension of my beats system for syndicating external content. Here's the PR and prompt.
As with my other forms of incoming syndicated content sightings show up on the homepage, the date archive pages, and in site search results.
I back-populated over a decade of iNaturalist sightings, which means you that if you search for lemur you'll see my lemur photos from Madagascar in 2019!
Zig has one of the most stringent anti-LLM policies of any major open source project:
No LLMs for issues.
No LLMs for pull requests.
No LLMs for comments on the bug tracker, including translation. English is encouraged, but not required. You are welcome to post in your native language and rely on others to have their own translation tools of choice to interpret your words.
The most prominent project written in Zig may be the Bun JavaScript runtime, which was acquired by Anthropic in December 2025 and, unsurprisingly, makes heavy use of AI assistance.
Bun operates its own fork of Zig, and recently achieved a 4x performance improvement on Bun compile after adding "parallel semantic analysis and multiple codegen units to the llvm backend". Here's that code. But @bunjavascript says:
We do not currently plan to upstream this, as Zig has a strict ban on LLM-authored contributions.
(Update: here's a Zig core contributor providing details on why they wouldn't accept that particular patch independent of the LLM issue - parallel semantic analysis is a long planned feature but has implications "for the Zig language itself".)
In Contributor Poker and Zig's AI Ban (via Lobste.rs) Zig Software Foundation VP of Community Loris Cro explains the rationale for this strict ban. It's the best articulation I've seen yet for a blanket ban on LLM-assisted contributions:
In successful open source projects you eventually reach a point where you start getting more PRs than what you’re capable of processing. Given what I mentioned so far, it would make sense to stop accepting imperfect PRs in order to maximize ROI from your work, but that’s not what we do in the Zig project. Instead, we try our best to help new contributors to get their work in, even if they need some help getting there. We don’t do this just because it’s the “right” thing to do, but also because it’s the smart thing to do.
Zig values contributors over their contributions. Each contributor represents an investment by the Zig core team - the primary goal of reviewing and accepting PRs isn't to land new code, it's to help grow new contributors who can become trusted and prolific over time.
LLM assistance breaks that completely. It doesn't matter if the LLM helps you submit a perfect PR to Zig - the time the Zig team spends reviewing your work does nothing to help them add new, confident, trustworthy contributors to their overall project.
Loris explains the name here:
The reason I call it “contributor poker” is because, just like people say about the actual card game, “you play the person, not the cards”. In contributor poker, you bet on the contributor, not on the contents of their first PR.
This makes a lot of sense to me. It relates to an idea I've seen circulating elsewhere: if a PR was mostly written by an LLM, why should a project maintainer spend time reviewing and discussing that PR as opposed to firing up their own LLM to solve the same problem?
Five months in, I think I've decided that I don't want to vibecode — I want professionally managed software companies to use AI coding assistance to make more/better/cheaper software products that they sell to me for money.
— Matthew Yglesias, in a now-deleted Tweet
Adding a new content type to my blog-to-newsletter tool
Here's an example of a deceptively short prompt that got a quite a lot of work done in a single shot.
First, some background. I send out a free Substack newsletter around once a week containing content copied-and-pasted from my blog. I'm effectively using Substack as a lightweight way to allow people to subscribe to my blog via email.
I generate the newsletter with my blog-to-newsletter tool - an HTML and JavaScript app that fetches my latest content from this Datasette instance and formats it as rich text HTML, which I can then copy to my clipboard and paste into the Substack editor. Here's a detailed explanation of how that works. [... 902 words]
datasette PR #2689: Replace token-based CSRF with Sec-Fetch-Site header protection.
Datasette has long protected against CSRF attacks using CSRF tokens, implemented using my asgi-csrf Python library. These are something of a pain to work with - you need to scatter forms in templates with <input type="hidden" name="csrftoken" value="{{ csrftoken() }}"> lines and then selectively disable CSRF protection for APIs that are intended to be called from outside the browser.
I've been following Filippo Valsorda's research here with interest, described in this detailed essay from August 2025 and shipped as part of Go 1.25 that same month.
I've now landed the same change in Datasette. Here's the PR description - Claude Code did much of the work (across 10 commits, closely guided by me and cross-reviewed by GPT-5.4) but I've decided to start writing these PR descriptions by hand, partly to make them more concise and also as an exercise in keeping myself honest.
- New CSRF protection middleware inspired by Go 1.25 and this research by Filippo Valsorda. This replaces the old CSRF token based protection.
- Removes all instances of
<input type="hidden" name="csrftoken" value="{{ csrftoken() }}">in the templates - they are no longer needed.- Removes the
def skip_csrf(datasette, scope):plugin hook defined indatasette/hookspecs.pyand its documentation and tests.- Updated CSRF protection documentation to describe the new approach.
- Upgrade guide now describes the CSRF change.
The problem is that LLMs inherently lack the virtue of laziness. Work costs nothing to an LLM. LLMs do not feel a need to optimize for their own (or anyone's) future time, and will happily dump more and more onto a layercake of garbage. Left unchecked, LLMs will make systems larger, not better — appealing to perverse vanity metrics, perhaps, but at the cost of everything that matters.
As such, LLMs highlight how essential our human laziness is: our finite time forces us to develop crisp abstractions in part because we don't want to waste our (human!) time on the consequences of clunky ones.
— Bryan Cantrill, The peril of laziness lost
Eight years of wanting, three months of building with AI (via) Lalit Maganti provides one of my favorite pieces of long-form writing on agentic engineering I've seen in ages.
They spent eight years thinking about and then three months building syntaqlite, which they describe as "high-fidelity devtools that SQLite deserves".
The goal was to provide fast, robust and comprehensive linting and verifying tools for SQLite, suitable for use in language servers and other development tools - a parser, formatter, and verifier for SQLite queries. I've found myself wanting this kind of thing in the past myself, hence my (far less production-ready) sqlite-ast project from a few months ago.
Lalit had been procrastinating on this project for years, because of the inevitable tedium of needing to work through 400+ grammar rules to help build a parser. That's exactly the kind of tedious work that coding agents excel at!
Claude Code helped get over that initial hump and build the first prototype:
AI basically let me put aside all my doubts on technical calls, my uncertainty of building the right thing and my reluctance to get started by giving me very concrete problems to work on. Instead of “I need to understand how SQLite’s parsing works”, it was “I need to get AI to suggest an approach for me so I can tear it up and build something better". I work so much better with concrete prototypes to play with and code to look at than endlessly thinking about designs in my head, and AI lets me get to that point at a pace I could not have dreamed about before. Once I took the first step, every step after that was so much easier.
That first vibe-coded prototype worked great as a proof of concept, but they eventually made the decision to throw it away and start again from scratch. AI worked great for the low level details but did not produce a coherent high-level architecture:
I found that AI made me procrastinate on key design decisions. Because refactoring was cheap, I could always say “I’ll deal with this later.” And because AI could refactor at the same industrial scale it generated code, the cost of deferring felt low. But it wasn’t: deferring decisions corroded my ability to think clearly because the codebase stayed confusing in the meantime.
The second attempt took a lot longer and involved a great deal more human-in-the-loop decision making, but the result is a robust library that can stand the test of time.
It's worth setting aside some time to read this whole thing - it's full of non-obvious downsides to working heavily with AI, as well as a detailed explanation of how they overcame those hurdles.
The key idea I took away from this concerns AI's weakness in terms of design and architecture:
When I was working on something where I didn’t even know what I wanted, AI was somewhere between unhelpful and harmful. The architecture of the project was the clearest case: I spent weeks in the early days following AI down dead ends, exploring designs that felt productive in the moment but collapsed under scrutiny. In hindsight, I have to wonder if it would have been faster just thinking it through without AI in the loop at all.
But expertise alone isn’t enough. Even when I understood a problem deeply, AI still struggled if the task had no objectively checkable answer. Implementation has a right answer, at least at a local level: the code compiles, the tests pass, the output matches what you asked for. Design doesn’t. We’re still arguing about OOP decades after it first took off.
Lalit Maganti's syntaqlite is currently being discussed on Hacker News thanks to Eight years of wanting, three months of building with AI, a deep dive into how it was built.
This inspired me to revisit a research project I ran when Lalit first released it a couple of weeks ago, where I tried it out and then compiled it to a WebAssembly wheel so it could run in Pyodide in a browser (the library itself uses C and Rust).
This new playground loads up the Python library and provides a UI for trying out its different features: formating, parsing into an AST, validating, and tokenizing SQLite SQL queries.
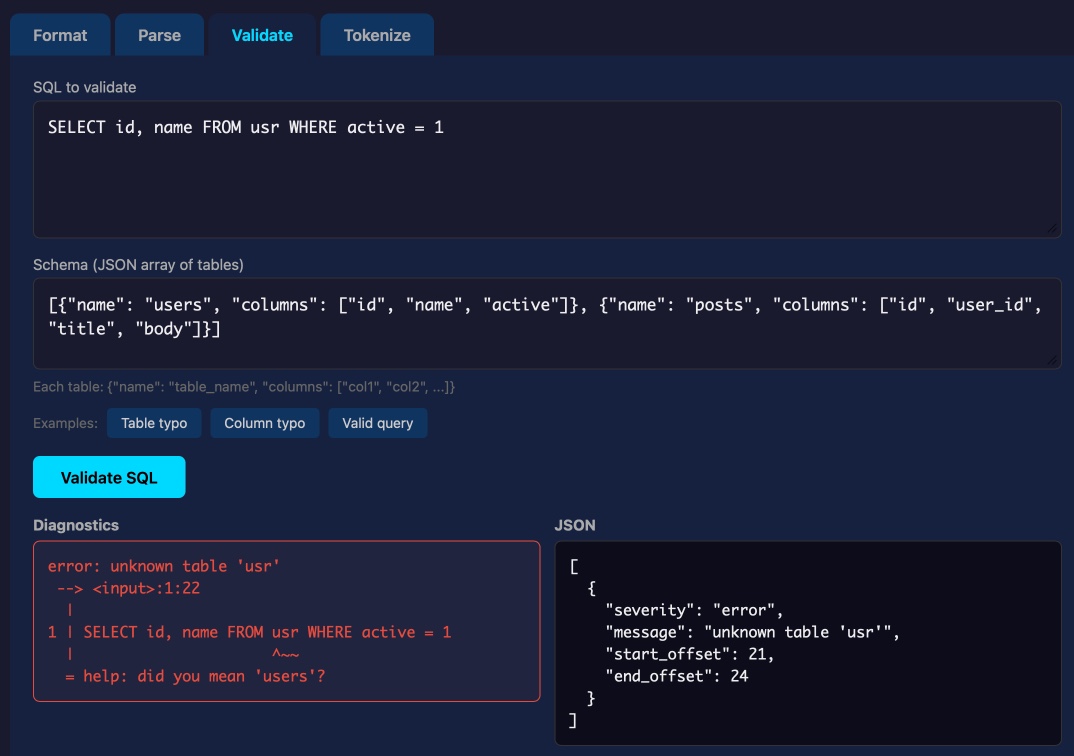
Update: not sure how I missed this but syntaqlite has its own WebAssembly playground linked to from the README.
I like publishing transcripts of local Claude Code sessions using my claude-code-transcripts tool but I'm often paranoid that one of my API keys or similar secrets might inadvertently be revealed in the detailed log files.
I built this new Python scanning tool to help reassure me. You can feed it secrets and have it scan for them in a specified directory:
uvx scan-for-secrets $OPENAI_API_KEY -d logs-to-publish/
If you leave off the -d it defaults to the current directory.
It doesn't just scan for the literal secrets - it also scans for common encodings of those secrets e.g. backslash or JSON escaping, as described in the README.
If you have a set of secrets you always want to protect you can list commands to echo them in a ~/.scan-for-secrets.conf.sh file. Mine looks like this:
llm keys get openai
llm keys get anthropic
llm keys get gemini
llm keys get mistral
awk -F= '/aws_secret_access_key/{print $2}' ~/.aws/credentials | xargs
I built this tool using README-driven-development: I carefully constructed the README describing exactly how the tool should work, then dumped it into Claude Code and told it to build the actual tool (using red/green TDD, naturally.)
I want to argue that AI models will write good code because of economic incentives. Good code is cheaper to generate and maintain. Competition is high between the AI models right now, and the ones that win will help developers ship reliable features fastest, which requires simple, maintainable code. Good code will prevail, not only because we want it to (though we do!), but because economic forces demand it. Markets will not reward slop in coding, in the long-term.
— Soohoon Choi, Slop Is Not Necessarily The Future
Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer
Trip Venturella released Mr. Chatterbox, a language model trained entirely on out-of-copyright text from the British Library. Here’s how he describes it in the model card:
[... 952 words]The thing about agentic coding is that agents grind problems into dust. Give an agent a problem and a while loop and - long term - it’ll solve that problem even if it means burning a trillion tokens and re-writing down to the silicon. [...]
But we want AI agents to solve coding problems quickly and in a way that is maintainable and adaptive and composable (benefiting from improvements elsewhere), and where every addition makes the whole stack better.
So at the bottom is really great libraries that encapsulate hard problems, with great interfaces that make the “right” way the easy way for developers building apps with them. Architecture!
While I’m vibing (I call it vibing now, not coding and not vibe coding) while I’m vibing, I am looking at lines of code less than ever before, and thinking about architecture more than ever before.
— Matt Webb, An appreciation for (technical) architecture
FWIW, IANDBL, TINLA, etc., I don’t currently see any basis for concluding that chardet 7.0.0 is required to be released under the LGPL. AFAIK no one including Mark Pilgrim has identified persistence of copyrightable expressive material from earlier versions in 7.0.0 nor has anyone articulated some viable alternate theory of license violation. [...]
— Richard Fontana, LGPLv3 co-author, weighing in on the chardet relicensing situation
I have been doing this for years, and the hardest parts of the job were never about typing out code. I have always struggled most with understanding systems, debugging things that made no sense, designing architectures that wouldn't collapse under heavy load, and making decisions that would save months of pain later.
None of these problems can be solved LLMs. They can suggest code, help with boilerplate, sometimes can act as a sounding board. But they don't understand the system, they don't carry context in their "minds", and they certianly don't know why a decision is right or wrong.
And the most importantly, they don't choose. That part is still yours. The real work of software development, the part that makes someone valuable, is knowing what should exist in the first place, and why.
— David Abram, The machine didn't take your craft. You gave it up.
Experimenting with Starlette 1.0 with Claude skills
Starlette 1.0 is out! This is a really big deal. I think Starlette may be the Python framework with the most usage compared to its relatively low brand recognition because Starlette is the foundation of FastAPI, which has attracted a huge amount of buzz that seems to have overshadowed Starlette itself.
[... 1,194 words]My fireside chat about agentic engineering at the Pragmatic Summit

I was a speaker last month at the Pragmatic Summit in San Francisco, where I participated in a fireside chat session about Agentic Engineering hosted by Eric Lui from Statsig.
[... 3,350 words]Simply put: It’s a big mess, and no off-the-shelf accounting software does what I need. So after years of pain, I finally sat down last week and started to build my own. It took me about five days. I am now using the best piece of accounting software I’ve ever used. It’s blazing fast. Entirely local. Handles multiple currencies and pulls daily (historical) conversion rates. It’s able to ingest any CSV I throw at it and represent it in my dashboard as needed. It knows US and Japan tax requirements, and formats my expenses and medical bills appropriately for my accountants. I feed it past returns to learn from. I dump 1099s and K1s and PDFs from hospitals into it, and it categorizes and organizes and packages them all as needed. It reconciles international wire transfers, taking into account small variations in FX rates and time for the transfers to complete. It learns as I categorize expenses and categorizes automatically going forward. It’s easy to do spot checks on data. If I find an anomaly, I can talk directly to Claude and have us brainstorm a batched solution, often saving me from having to manually modify hundreds of entries. And often resulting in a new, small, feature tweak. The software feels organic and pliable in a form perfectly shaped to my hand, able to conform to any hunk of data I throw at it. It feels like bushwhacking with a lightsaber.
— Craig Mod, Software Bonkers
Shopify/liquid: Performance: 53% faster parse+render, 61% fewer allocations (via) PR from Shopify CEO Tobias Lütke against Liquid, Shopify's open source Ruby template engine that was somewhat inspired by Django when Tobi first created it back in 2005.
Tobi found dozens of new performance micro-optimizations using a variant of autoresearch, Andrej Karpathy's new system for having a coding agent run hundreds of semi-autonomous experiments to find new effective techniques for training nanochat.
Tobi's implementation started two days ago with this autoresearch.md prompt file and an autoresearch.sh script for the agent to run to execute the test suite and report on benchmark scores.
The PR now lists 93 commits from around 120 automated experiments. The PR description lists what worked in detail - some examples:
- Replaced StringScanner tokenizer with
String#byteindex. Single-bytebyteindexsearching is ~40% faster than regex-basedskip_until. This alone reduced parse time by ~12%.- Pure-byte
parse_tag_token. Eliminated the costlyStringScanner#string=reset that was called for every{% %}token (878 times). Manual byte scanning for tag name + markup extraction is faster than resetting and re-scanning via StringScanner. [...]- Cached small integer
to_s. Pre-computed frozen strings for 0-999 avoid 267Integer#to_sallocations per render.
This all added up to a 53% improvement on benchmarks - truly impressive for a codebase that's been tweaked by hundreds of contributors over 20 years.
I think this illustrates a number of interesting ideas:
- Having a robust test suite - in this case 974 unit tests - is a massive unlock for working with coding agents. This kind of research effort would not be possible without first having a tried and tested suite of tests.
- The autoresearch pattern - where an agent brainstorms a multitude of potential improvements and then experiments with them one at a time - is really effective.
- If you provide an agent with a benchmarking script "make it faster" becomes an actionable goal.
- CEOs can code again! Tobi has always been more hands-on than most, but this is a much more significant contribution than anyone would expect from the leader of a company with 7,500+ employees. I've seen this pattern play out a lot over the past few months: coding agents make it feasible for people in high-interruption roles to productively work with code again.
Here's Tobi's GitHub contribution graph for the past year, showing a significant uptick following that November 2025 inflection point when coding agents got really good.
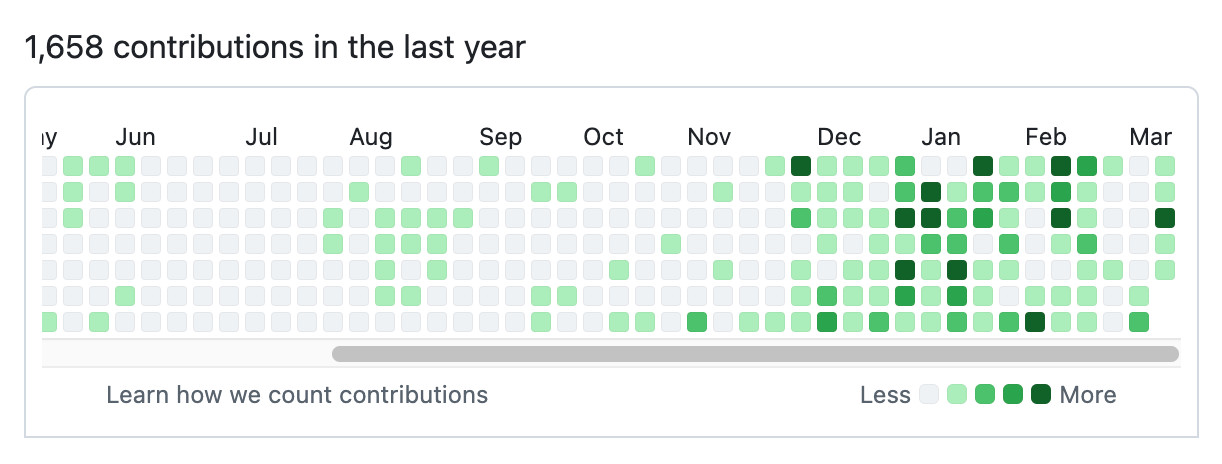
He used Pi as the coding agent and released a new pi-autoresearch plugin in collaboration with David Cortés, which maintains state in an autoresearch.jsonl file like this one.
Coding After Coders: The End of Computer Programming as We Know It. Epic piece on AI-assisted development by Clive Thompson for the New York Times Magazine, who spoke to more than 70 software developers from companies like Google, Amazon, Microsoft, Apple, plus other individuals including Anil Dash, Thomas Ptacek, Steve Yegge, and myself.
I think the piece accurately and clearly captures what's going on in our industry right now in terms appropriate for a wider audience.
I talked to Clive a few weeks ago. Here's the quote from me that made it into the piece.
Given A.I.’s penchant to hallucinate, it might seem reckless to let agents push code out into the real world. But software developers point out that coding has a unique quality: They can tether their A.I.s to reality, because they can demand the agents test the code to see if it runs correctly. “I feel like programmers have it easy,” says Simon Willison, a tech entrepreneur and an influential blogger about how to code using A.I. “If you’re a lawyer, you’re screwed, right?” There’s no way to automatically check a legal brief written by A.I. for hallucinations — other than face total humiliation in court.
The piece does raise the question of what this means for the future of our chosen line of work, but the general attitude from the developers interviewed was optimistic - there's even a mention of the possibility that the Jevons paradox might increase demand overall.
One critical voice came from an Apple engineer:
A few programmers did say that they lamented the demise of hand-crafting their work. “I believe that it can be fun and fulfilling and engaging, and having the computer do it for you strips you of that,” one Apple engineer told me. (He asked to remain unnamed so he wouldn’t get in trouble for criticizing Apple’s embrace of A.I.)
That request to remain anonymous is a sharp reminder that corporate dynamics may be suppressing an unknown number of voices on this topic.