25 posts tagged “datasette” and “llm”
Datasette is an open source tool for exploring and publishing data.
2025
llm-openrouter 0.5. New release of my LLM plugin for accessing models made available via OpenRouter. The release notes in full:
- Support for tool calling. Thanks, James Sanford. #43
- Support for reasoning options, for example
llm -m openrouter/openai/gpt-5 'prove dogs exist' -o reasoning_effort medium. #45
Tool calling is a really big deal, as it means you can now use the plugin to try out tools (and build agents, if you like) against any of the 179 tool-enabled models on that platform:
llm install llm-openrouter
llm keys set openrouter
# Paste key here
llm models --tools | grep 'OpenRouter:' | wc -l
# Outputs 179
Quite a few of the models hosted on OpenRouter can be accessed for free. Here's a tool-usage example using the llm-tools-datasette plugin against the new Grok 4 Fast model:
llm install llm-tools-datasette
llm -m openrouter/x-ai/grok-4-fast:free -T 'Datasette("https://datasette.io/content")' 'Count available plugins'
Outputs:
There are 154 available plugins.
The output of llm logs -cu shows the tool calls and SQL queries it executed to get that result.
LLM 0.27, the annotated release notes: GPT-5 and improved tool calling
I shipped LLM 0.27 today (followed by a 0.27.1 with minor bug fixes), adding support for the new GPT-5 family of models from OpenAI plus a flurry of improvements to the tool calling features introduced in LLM 0.26. Here are the annotated release notes.
[... 1,174 words]We're hosting the sixth in our series of Datasette Public Office Hours livestream sessions this Friday, 6th of June at 2pm PST (here's that time in your location).
The topic is going to be tool support in LLM, as introduced here.
I'll be walking through the new features, and we're also inviting five minute lightning demos from community members who are doing fun things with the new capabilities. If you'd like to present one of those please get in touch via this form.

Here's a link to add it to Google Calendar.
In addition to my workshop the other day I'm also participating in the poster session at PyCon US this year.
This means that tomorrow (Sunday 18th May) I'll be hanging out next to my poster from 10am to 1pm in Hall A talking to people about my various projects.
I'll confess: I didn't pay close enough attention to the poster information, so when I first put my poster up it looked a little small:

... so I headed to the nearest CVS and printed out some photos to better represent my interests and personality. I'm going for a "teenage bedroom" aesthetic here, I'm very happy with the result:

Here's the poster in the middle (also available as a PDF). It has columns for Datasette, sqlite-utils and LLM.

If you're at PyCon I'd love to talk to you about things I'm working on!
Update: Thanks to everyone who came along. Here's a 6MB photo of the poster setup. The museums were all from my www.niche-museums.com site and the pelicans riding a bicycle SVGs came from my pelican-riding-a-bicycle tag.
{kind=link}
files-to-prompt 0.5.
My files-to-prompt tool (originally built using Claude 3 Opus back in April) had been accumulating a bunch of issues and PRs - I finally got around to spending some time with it and pushed a fresh release:
- New
-n/--line-numbersflag for including line numbers in the output. Thanks, Dan Clayton. #38- Fix for utf-8 handling on Windows. Thanks, David Jarman. #36
--ignorepatterns are now matched against directory names as well as file names, unless you pass the new--ignore-files-onlyflag. Thanks, Nick Powell. #30
I use this tool myself on an almost daily basis - it's fantastic for quickly answering questions about code. Recently I've been plugging it into Gemini 2.0 with its 2 million token context length, running recipes like this one:
git clone https://github.com/bytecodealliance/componentize-py
cd componentize-py
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'How does this work? Does it include a python compiler or AST trick of some sort?'
I ran that question against the bytecodealliance/componentize-py repo - which provides a tool for turning Python code into compiled WASM - and got this really useful answer.
Here's another example. I decided to have o3-mini review how Datasette handles concurrent SQLite connections from async Python code - so I ran this:
git clone https://github.com/simonw/datasette
cd datasette/datasette
files-to-prompt database.py utils/__init__.py -c | \
llm -m o3-mini -o reasoning_effort high \
-s 'Output in markdown a detailed analysis of how this code handles the challenge of running SQLite queries from a Python asyncio application. Explain how it works in the first section, then explore the pros and cons of this design. In a final section propose alternative mechanisms that might work better.'
Here's the result. It did an extremely good job of explaining how my code works - despite being fed just the Python and none of the other documentation. Then it made some solid recommendations for potential alternatives.
I added a couple of follow-up questions (using llm -c) which resulted in a full working prototype of an alternative threadpool mechanism, plus some benchmarks.
One final example: I decided to see if there were any undocumented features in Litestream, so I checked out the repo and ran a prompt against just the .go files in that project:
git clone https://github.com/benbjohnson/litestream
cd litestream
files-to-prompt . -e go -c | llm -m o3-mini \
-s 'Write extensive user documentation for this project in markdown'
Once again, o3-mini provided a really impressively detailed set of unofficial documentation derived purely from reading the source.
o3-mini is really good at writing internal documentation. I wanted to refresh my knowledge of how the Datasette permissions system works today. I already have extensive hand-written documentation for that, but I thought it would be interesting to see if I could derive any insights from running an LLM against the codebase.
o3-mini has an input limit of 200,000 tokens. I used LLM and my files-to-prompt tool to generate the documentation like this:
cd /tmp
git clone https://github.com/simonw/datasette
cd datasette
files-to-prompt datasette -e py -c | \
llm -m o3-mini -s \
'write extensive documentation for how the permissions system works, as markdown'The files-to-prompt command is fed the datasette subdirectory, which contains just the source code for the application - omitting tests (in tests/) and documentation (in docs/).
The -e py option causes it to only include files with a .py extension - skipping all of the HTML and JavaScript files in that hierarchy.
The -c option causes it to output Claude's XML-ish format - a format that works great with other LLMs too.
You can see the output of that command in this Gist.
Then I pipe that result into LLM, requesting the o3-mini OpenAI model and passing the following system prompt:
write extensive documentation for how the permissions system works, as markdown
Specifically requesting Markdown is important.
The prompt used 99,348 input tokens and produced 3,118 output tokens (320 of those were invisible reasoning tokens). That's a cost of 12.3 cents.
Honestly, the results are fantastic. I had to double-check that I hadn't accidentally fed in the documentation by mistake.
(It's possible that the model is picking up additional information about Datasette in its training set, but I've seen similar high quality results from other, newer libraries so I don't think that's a significant factor.)
In this case I already had extensive written documentation of my own, but this was still a useful refresher to help confirm that the code matched my mental model of how everything works.
Documentation of project internals as a category is notorious for going out of date. Having tricks like this to derive usable how-it-works documentation from existing codebases in just a few seconds and at a cost of a few cents is wildly valuable.
Six short video demos of LLM and Datasette projects
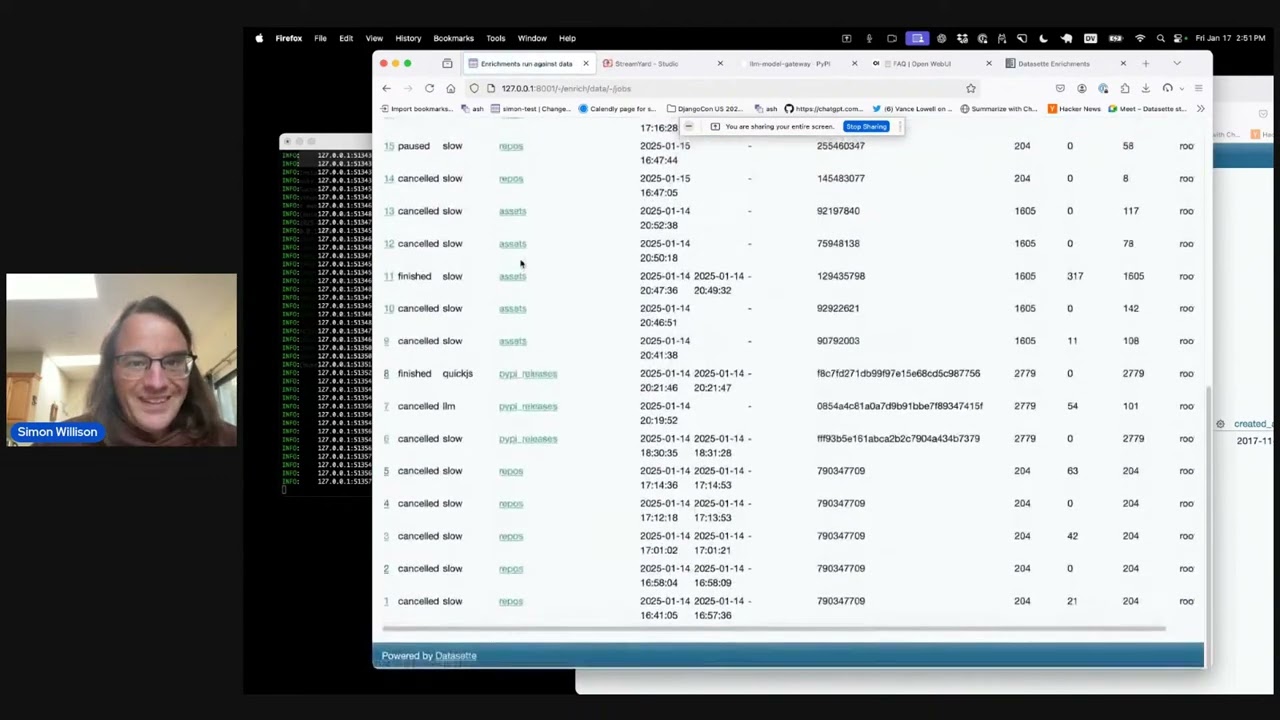
Last Friday Alex Garcia and I hosted a new kind of Datasette Public Office Hours session, inviting members of the Datasette community to share short demos of projects that they had built. The session lasted just over an hour and featured demos from six different people.
[... 1,047 words]2024
datasette-enrichments-llm. Today's new alpha release is datasette-enrichments-llm, a plugin for Datasette 1.0a+ that provides an enrichment that lets you run prompts against data from one or more column and store the result in another column.
So far it's a light re-implementation of the existing datasette-enrichments-gpt plugin, now using the new llm.get_async_models() method to allow users to select any async-enabled model that has been registered by a plugin - so currently any of the models from OpenAI, Anthropic, Gemini or Mistral via their respective plugins.
Still plenty to do on this one. Next step is to integrate it with datasette-llm-usage and use it to drive a design-complete stable version of that.
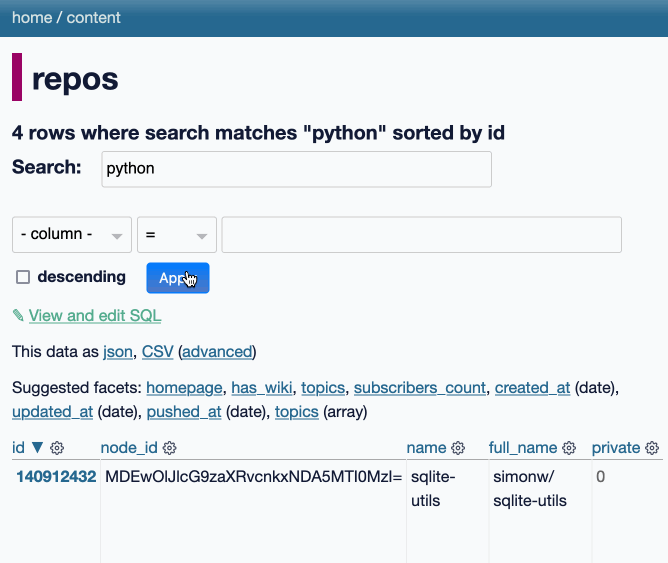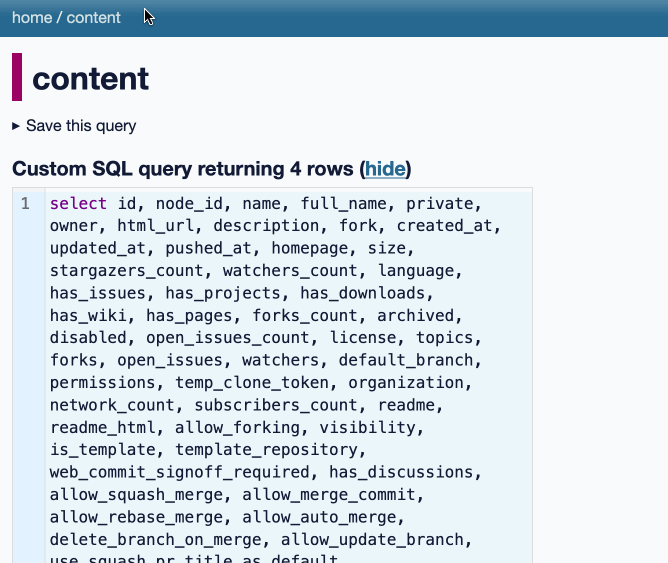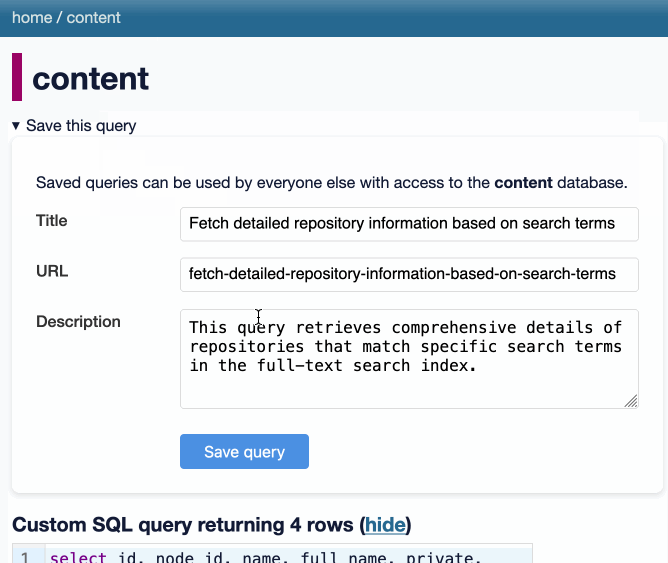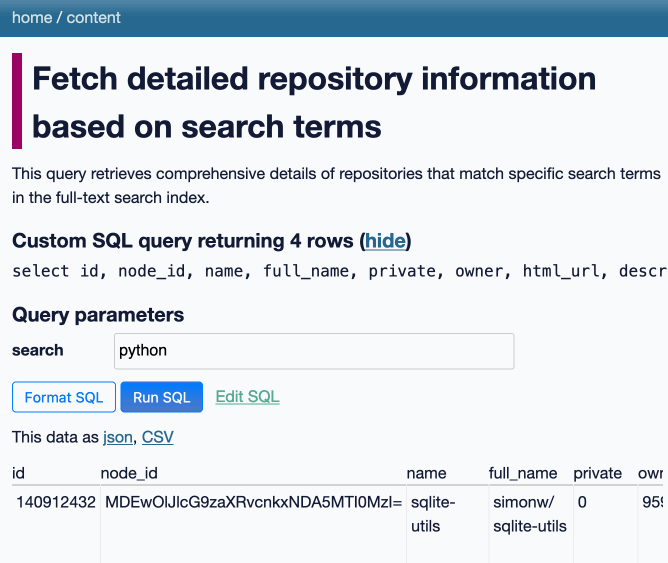
datasette-queries. I released the first alpha of a new plugin to replace the crusty old datasette-saved-queries. This one adds a new UI element to the top of the query results page with an expandable form for saving the query as a new canned query:
It's my first plugin to depend on LLM and datasette-llm-usage - it uses GPT-4o mini to power an optional "Suggest title and description" button, labeled with the becoming-standard ✨ sparkles emoji to indicate an LLM-powered feature.
I intend to expand this to work across multiple models as I continue to iterate on llm-datasette-usage to better support those kinds of patterns.
For the moment though each suggested title and description call costs about 250 input tokens and 50 output tokens, which against GPT-4o mini adds up to 0.0067 cents.
datasette-llm-usage. I released the first alpha of a Datasette plugin to help track LLM usage by other plugins, with the goal of supporting token allowances - both for things like free public apps that stop working after a daily allowance, plus free previews of AI features for paid-account-based projects such as Datasette Cloud.
It's using the usage features I added in LLM 0.19.
The alpha doesn't do much yet - it will start getting interesting once I upgrade other plugins to depend on it.
Design notes so far in issue #1.
Weeknotes: asynchronous LLMs, synchronous embeddings, and I kind of started a podcast
These past few weeks I’ve been bringing Datasette and LLM together and distracting myself with a new sort-of-podcast crossed with a live streaming experiment.
[... 896 words]Weeknotes: a staging environment, a Datasette alpha and a bunch of new LLMs
My big achievement for the last two weeks was finally wrapping up work on the Datasette Cloud staging environment. I also shipped a new Datasette 1.0 alpha and added support to the LLM ecosystem for a bunch of newly released models.
[... 1,465 words]Datasette 1.0a14: The annotated release notes

Released today: Datasette 1.0a14. This alpha includes significant contributions from Alex Garcia, including some backwards-incompatible changes in the run-up to the 1.0 release.
[... 1,424 words]Announcing our DjangoCon US 2024 Talks! I'm speaking at DjangoCon in Durham, NC in September.
My accepted talk title was How to design and implement extensible software with plugins. Here's my abstract:
Plugins offer a powerful way to extend software packages. Tools that support a plugin architecture include WordPress, Jupyter, VS Code and pytest - each of which benefits from an enormous array of plugins adding all kinds of new features and expanded capabilities.
Adding plugin support to an open source project can greatly reduce the friction involved in attracting new contributors. Users can work independently and even package and publish their work without needing to directly coordinate with the project's core maintainers. As a maintainer this means you can wake up one morning and your software grew new features without you even having to review a pull request!
There's one catch: information on how to design and implement plugin support for a project is scarce.
I now have three major open source projects that support plugins, with over 200 plugins published across those projects. I'll talk about everything I've learned along the way: when and how to use plugins, how to design plugin hooks and how to ensure your plugin authors have as good an experience as possible.
I'm going to be talking about what I've learned integrating Pluggy with Datasette, LLM and sqlite-utils. I've been looking for an excuse to turn this knowledge into a talk for ages, very excited to get to do it at DjangoCon!
Language models on the command-line
I gave a talk about accessing Large Language Models from the command-line last week as part of the Mastering LLMs: A Conference For Developers & Data Scientists six week long online conference. The talk focused on my LLM Python command-line utility and ways you can use it (and its plugins) to explore LLMs and use them for useful tasks.
[... 4,992 words]Weeknotes: Llama 3, AI for Data Journalism, llm-evals and datasette-secrets
Llama 3 landed on Thursday. I ended up updating a whole bunch of different plugins to work with it, described in Options for accessing Llama 3 from the terminal using LLM.
[... 1,030 words]AI for Data Journalism: demonstrating what we can do with this stuff right now
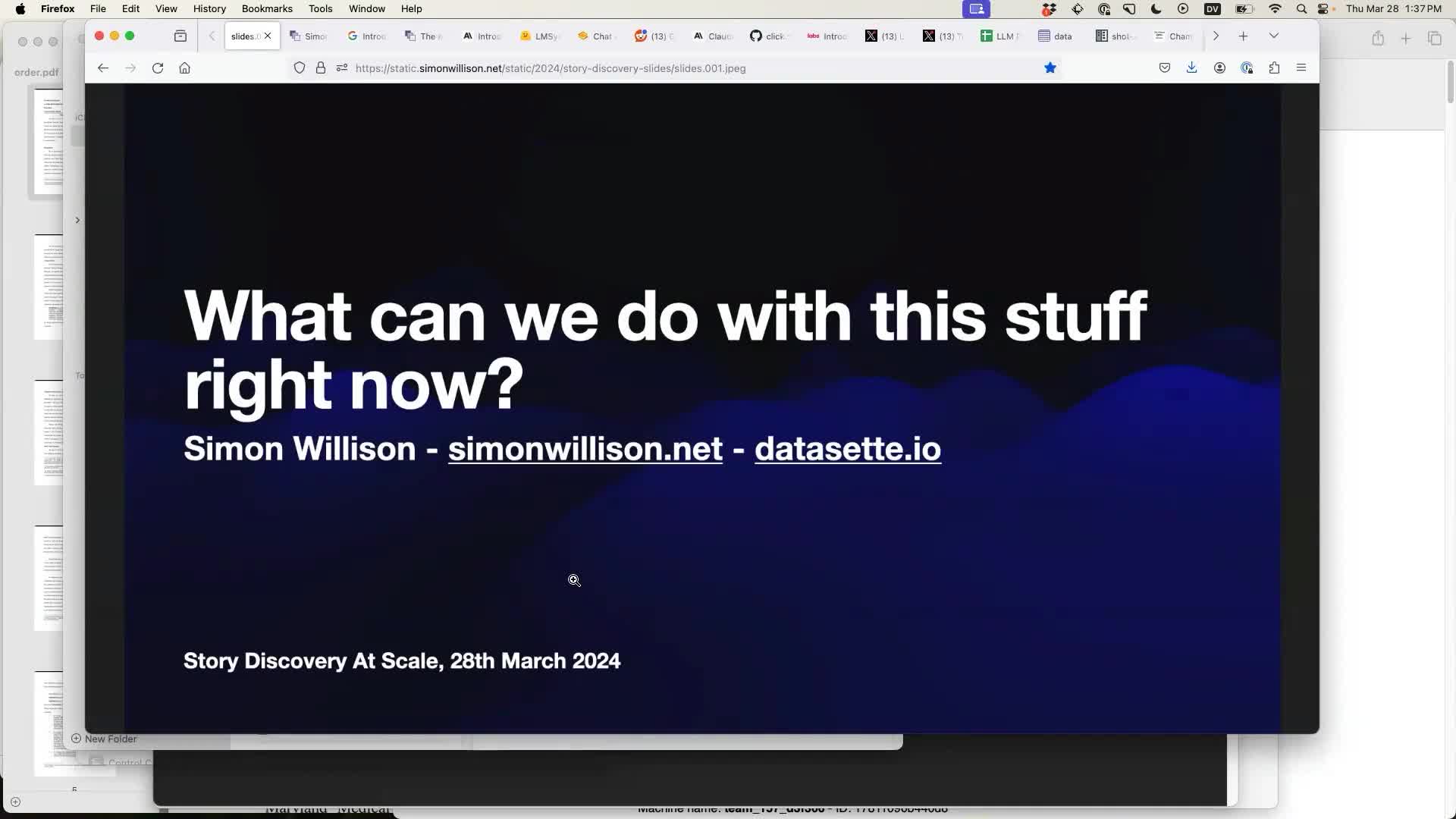
I gave a talk last month at the Story Discovery at Scale data journalism conference hosted at Stanford by Big Local News. My brief was to go deep into the things we can use Large Language Models for right now, illustrated by a flurry of demos to help provide starting points for further conversations at the conference.
[... 6,081 words]Weeknotes: a Datasette release, an LLM release and a bunch of new plugins
I wrote extensive annotated release notes for Datasette 1.0a8 and LLM 0.13 already. Here’s what else I’ve been up to this past three weeks.
[... 1,074 words]2023
Weeknotes: the Datasette Cloud API, a podcast appearance and more
Datasette Cloud now has a documented API, plus a podcast appearance, some LLM plugins work and some geospatial excitement.
[... 1,243 words]Weeknotes: Embeddings, more embeddings and Datasette Cloud
Since my last weeknotes, a flurry of activity. LLM has embeddings support now, and Datasette Cloud has driven some major improvements to the wider Datasette ecosystem.
[... 2,427 words]Datasette 1.0a4 and 1.0a5, plus weeknotes
Two new alpha releases of Datasette, plus a keynote at WordCamp, a new LLM release, two new LLM plugins and a flurry of TILs.
[... 2,709 words]Datasette Cloud, Datasette 1.0a3, llm-mlc and more
Datasette Cloud is now a significant step closer to general availability. The Datasette 1.03 alpha release is out, with a mostly finalized JSON format for 1.0. Plus new plugins for LLM and sqlite-utils and a flurry of things I’ve learned.
[... 1,690 words]Weeknotes: Plugins for LLM, sqlite-utils and Datasette
The principle theme for the past few weeks has been plugins.
[... 1,203 words]Weeknotes: Self-hosted language models with LLM plugins, a new Datasette tutorial, a dozen package releases, a dozen TILs
A lot of stuff to cover from the past two and a half weeks.
[... 1,742 words]Weeknotes: A new llm CLI tool, plus automating my weeknotes and newsletter
I started publishing weeknotes in 2019 partly as a way to hold myself accountable but mainly as a way to encourage myself to write more.
[... 830 words]