Datasette Cloud, Datasette 1.0a3, llm-mlc and more
16th August 2023
Datasette Cloud is now a significant step closer to general availability. The Datasette 1.03 alpha release is out, with a mostly finalized JSON format for 1.0. Plus new plugins for LLM and sqlite-utils and a flurry of things I’ve learned.
Datasette Cloud
Yesterday morning we unveiled the new Datasette Cloud blog, and kicked things off there with two posts:
- Welcome to Datasette Cloud provides an introduction to the product: what it can do so far, what’s coming next and how to sign up to try it out.
- Introducing datasette-write-ui: a Datasette plugin for editing, inserting, and deleting rows introduces a brand new plugin, datasette-write-ui—which finally adds a user interface for editing, inserting and deleting rows to Datasette.
Here’s a screenshot of the interface for creating a new private space in Datasette Cloud:
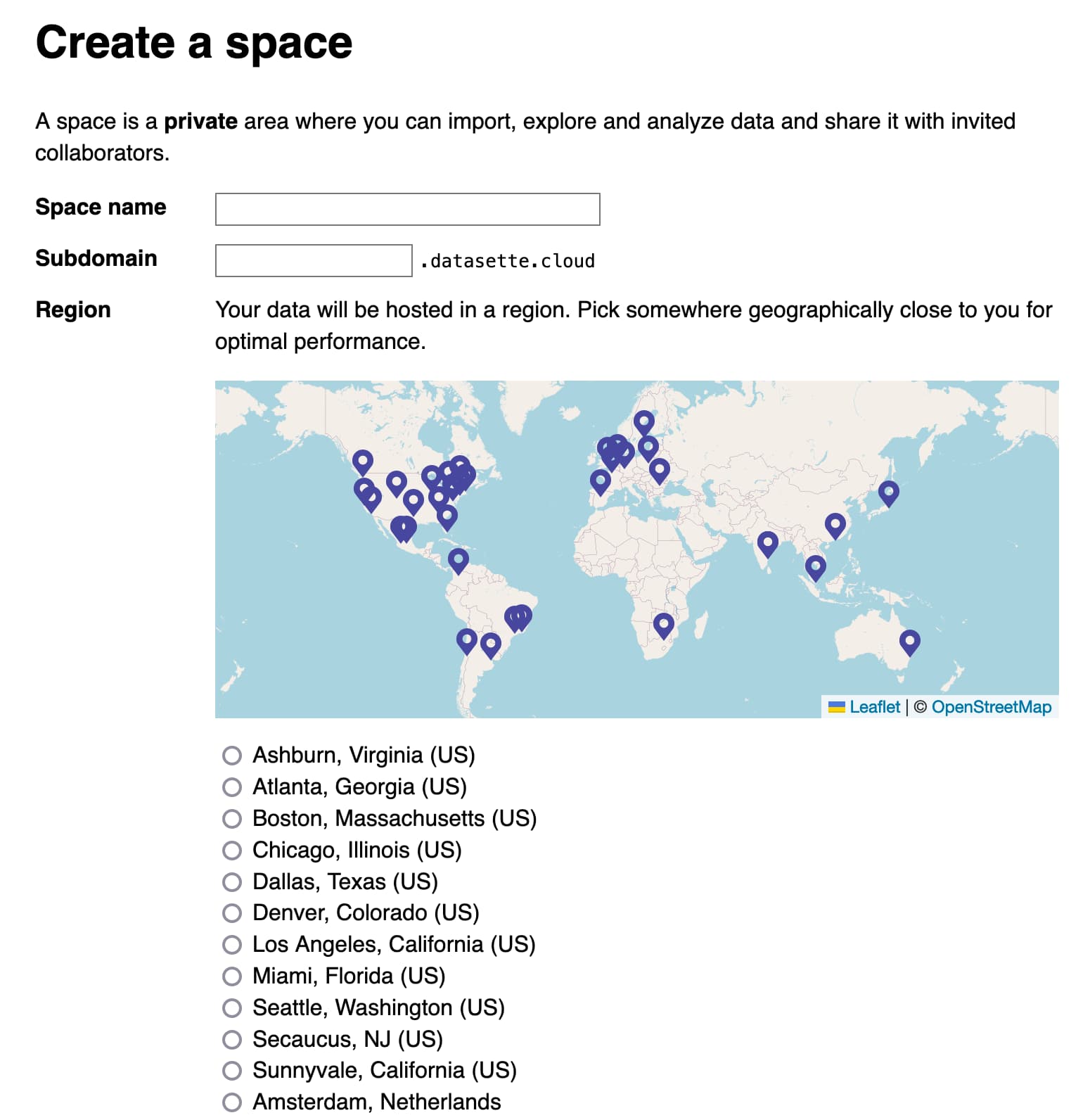
datasette-write-ui is particularly notable because it was written by Alex Garcia, who is now working with me to help get Datasette Cloud ready for general availability.
Alex’s work on the project is being supported by Fly.io, in a particularly exciting form of open source sponsorship. Datasette Cloud is already being built on Fly, but as part of Alex’s work we’ll be extensively documenting what we learn along the way about using Fly to build a multi-tenant SaaS platform.
Alex has some very cool work with Fly’s Litestream in the pipeline which we hope to talk more about shortly.
Since this is my first time building a blog from scratch in quite a while, I also put together a new TIL on Building a blog in Django.
The Datasette Cloud work has been driving a lot of improvements to other parts of the Datasette ecosystem, including improvements to datasette-upload-dbs and the other big news this week: Datasette 1.0a3.
Datasette 1.0a3
Datasette 1.0 is the first version of Datasette that will be marked as “stable”: if you build software on top of Datasette I want to guarantee as much as possible that it won’t break until Datasette 2.0, which I hope to avoid ever needing to release.
The three big aspects of this are:
- A stable plugins interface, so custom plugins continue to work
- A stable JSON API format, for integrations built against Datasette
- Stable template contexts, so that custom templates won’t be broken by minor changes
The 1.0 alpha 3 release primarily focuses on the JSON support. There’s a new, much more intuitive default shape for both the table and the arbitrary query pages, which looks like this:
{
"ok": true,
"rows": [
{
"id": 3,
"name": "Detroit"
},
{
"id": 2,
"name": "Los Angeles"
},
{
"id": 4,
"name": "Memnonia"
},
{
"id": 1,
"name": "San Francisco"
}
],
"truncated": false
}This is a huge improvement on the old format, which featured a vibrant mess of top-level keys and served the rows up as an array-of-arrays, leaving the user to figure out which column was which by matching against "columns".
The new format is documented here. I wanted to get this in place as soon as possible for Datasette Cloud (which is running this alpha), since I don’t want to risk paying customers building integrations that would later break due to 1.0 API changes.
llm-mlc
My LLM tool provides a CLI utility and Python library for running prompts through Large Language Models. I added plugin support to it a few weeks ago, so now it can support additional models through plugins—including a variety of models that can run directly on your own device.
For a while now I’ve been trying to work out the easiest recipe to get a Llama 2 model running on my M2 Mac with GPU acceleration.
I finally figured that out the other week, using the excellent MLC Python library.
I built a new plugin for LLM called llm-mlc. I think this may now be one of the easiest ways to run Llama 2 on an Apple Silicon Mac with GPU acceleration.
Here are the steps to try it out. First, install LLM—which is easiest with Homebrew:
brew install llmIf you have a Python 3 environment you can run pip install llm or pipx install llm instead.
Next, install the new plugin:
llm install llm-mlcThere’s an additional installation step which I’ve not yet been able to automate fully—on an M1/M2 Mac run the following:
llm mlc pip install --pre --force-reinstall \
mlc-ai-nightly \
mlc-chat-nightly \
-f https://mlc.ai/wheelsInstructions for other platforms can be found here.
Now run this command to finish the setup (which configures git-lfs ready to download the models):
llm mlc setupAnd finally, you can download the Llama 2 model using this command:
llm mlc download-model Llama-2-7b-chat --alias llama2And run a prompt like this:
llm -m llama2 'five names for a cute pet ferret'It’s still more steps than I’d like, but it seems to be working for people!
As always, my goal for LLM is to grow a community of enthusiasts who write plugins like this to help support new models as they are released. That’s why I put a lot of effort into building this tutorial about Writing a plugin to support a new model.
Also out now: llm 0.7, which mainly adds a new mechanism for adding custom aliases to existing models:
llm aliases set turbo gpt-3.5-turbo-16k
llm -m turbo 'An epic Greek-style saga about a cheesecake that builds a SQL database from scratch'openai-to-sqlite and embeddings for related content
A smaller release this week: openai-to-sqlite 0.4, an update to my CLI tool for loading data from various OpenAI APIs into a SQLite database.
My inspiration for this release was a desire to add better related content to my TIL website.
Short version: I did exactly that! Each post on that site now includes a list of related posts that are generated using OpenAI embeddings, which help me plot posts that are semantically similar to each other.
I wrote up a full TIL about how that all works: Storing and serving related documents with openai-to-sqlite and embeddings—scroll to the bottom of that post to see the new related content in action.
I’m fascinated by embeddings. They’re not difficult to run using locally hosted models either—I hope to add a feature to LLM to help with that soon.
Getting creative with embeddings by Amelia Wattenberger is a great example of some of the more interesting applications they can be put to.
sqlite-utils-jq
A tiny new plugin for sqlite-utils, inspired by this Hacker News comment and written mainly as an excuse for me to exercise that new plugins framework a little more.
sqlite-utils-jq adds a new jq() function which can be used to execute jq programs as part of a SQL query.
Install it like this:
sqlite-utils install sqlite-utils-jqNow you can do things like this:
sqlite-utils memory "select jq(:doc, :expr) as result" \
-p doc '{"foo": "bar"}' \
-p expr '.foo'You can also use it in combination with sqlite-utils-litecli to run that new function as part of an interactive shell:
sqlite-utils install sqlite-utils-litecli
sqlite-utils litecli data.db
# ...
Version: 1.9.0
Mail: https://groups.google.com/forum/#!forum/litecli-users
GitHub: https://github.com/dbcli/litecli
data.db> select jq('{"foo": "bar"}', '.foo')
+------------------------------+
| jq('{"foo": "bar"}', '.foo') |
+------------------------------+
| "bar" |
+------------------------------+
1 row in set
Time: 0.031s
Other entries this week
How I make annotated presentations describes the process I now use to create annotated presentations like this one for Catching up on the weird world of LLMs (now up to over 17,000 views on YouTube!) using a new custom annotation tool I put together with the help of GPT-4.
A couple of highlights from my TILs:
- Catching up with the Cosmopolitan ecosystem describes my latest explorations of Cosmopolitan and Actually Portable Executable, based on an update I heard from Justine Tunney.
- Running a Django and PostgreSQL development environment in GitHub Codespaces shares what I’ve learned about successfully running a Django and PostgreSQL development environment entirely through the browser using Codespaces.
Releases this week
-
openai-to-sqlite 0.4—2023-08-15
Save OpenAI API results to a SQLite database -
llm-mlc 0.5—2023-08-15
LLM plugin for running models using MLC -
datasette-render-markdown 2.2.1—2023-08-15
Datasette plugin for rendering Markdown -
db-build 0.1—2023-08-15
Tools for building SQLite databases from files and directories -
paginate-json 0.3.1—2023-08-12
Command-line tool for fetching JSON from paginated APIs -
llm 0.7—2023-08-12
Access large language models from the command-line -
sqlite-utils-jq 0.1—2023-08-11
Plugin adding a jq() SQL function to sqlite-utils -
datasette-upload-dbs 0.3—2023-08-10
Upload SQLite database files to Datasette -
datasette 1.0a3—2023-08-09
An open source multi-tool for exploring and publishing data
TIL this week
- Processing a stream of chunks of JSON with ijson—2023-08-16
- Building a blog in Django—2023-08-15
- Storing and serving related documents with openai-to-sqlite and embeddings—2023-08-15
- Combined release notes from GitHub with jq and paginate-json—2023-08-12
- Catching up with the Cosmopolitan ecosystem—2023-08-10
- Running a Django and PostgreSQL development environment in GitHub Codespaces—2023-08-10
- Scroll to text fragments—2023-08-08
More recent articles
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026
- The new GPT-5.6 family: Luna, Terra, Sol - 9th July 2026
- sqlite-utils 4.0, now with database schema migrations - 7th July 2026