My LLM CLI tool now supports self-hosted language models via plugins
12th July 2023
LLM is my command-line utility and Python library for working with large language models such as GPT-4. I just released version 0.5 with a huge new feature: you can now install plugins that add support for additional models to the tool, including models that can run on your own hardware.
Highlights of today’s release:
- Plugins to add support for 17 openly licensed models from the GPT4All project that can run directly on your device, plus Mosaic’s MPT-30B self-hosted model and Google’s PaLM 2 (via their API).
- This means you can
pip install(orbrew install) models along with a CLI tool for using them! - A detailed tutorial describing how to build new plugins that add support for additional models.
- A documented Python API for running prompts through any model provided by a plugin, plus a way of continuing a conversation across multiple prompts.
Update 18th July 2023:—I released a new plugin, llm-replicate, which can be used to access models hosted on Replicate, including the new Llama 2 model from Meta AI. More on this in Accessing Llama 2 from the command-line with the llm-replicate plugin.
Update 23rd July 2023:—Tom Viner released llm-claude, adding support for Claude and Claude Instant by Anthropic.
Update 17th August 2023: The llm-mlc plugin can run Llama 2 models on an Apple Silicon Mac with GPU acceleration.
How to try it out
First, install LLM. You can install it with pip:
pip install llmOr pipx:
pipx install llmOr if you don’t yet have a Python 3 environment, you can use Homebrew:
brew install llmThe default tool can work with OpenAI’s models via their API, provided you have an API key. You can see usage instructions for that here.
But let’s do something more interesting than that: Let’s install a model that can run on our own machine!
We’ll use the new llm-gpt4all plugin, which installs models published by the GPT4All project by Nomic AI.
Install the plugin like this:
llm install llm-gpt4allNow let’s run a prompt against a small model. LLM will download the model file the first time you query that model.
We’ll start with ggml-vicuna-7b-1, a 4.21GB download which should run if you have at least 8GB of RAM.
To run the prompt, try this:
llm -m ggml-vicuna-7b-1 "The capital of France?"You’ll see a progress bar showing the download of the model, followed by the answer to the prompt, generated a word at a time.
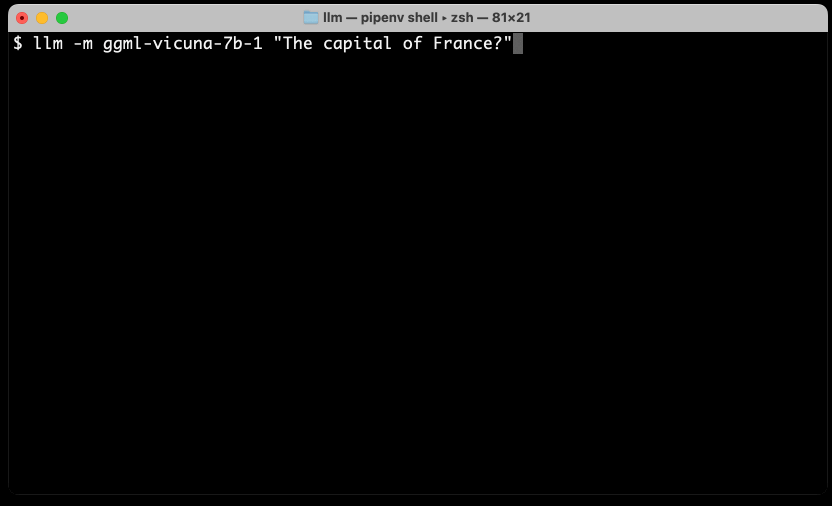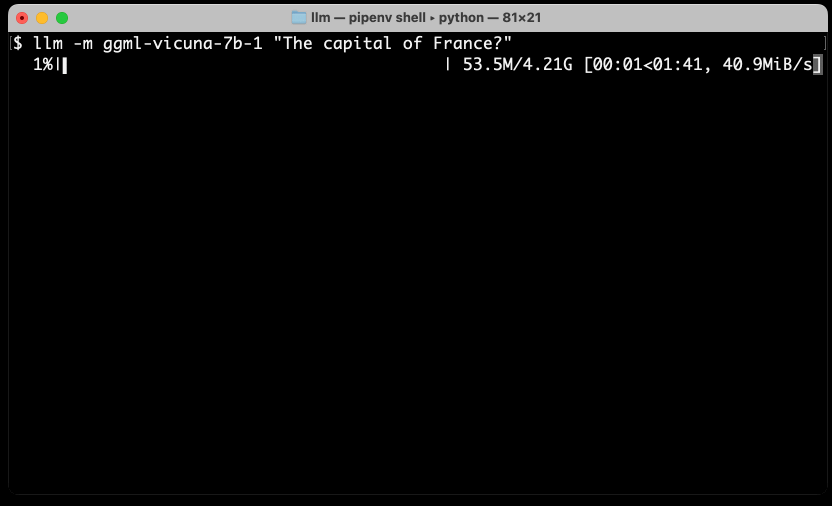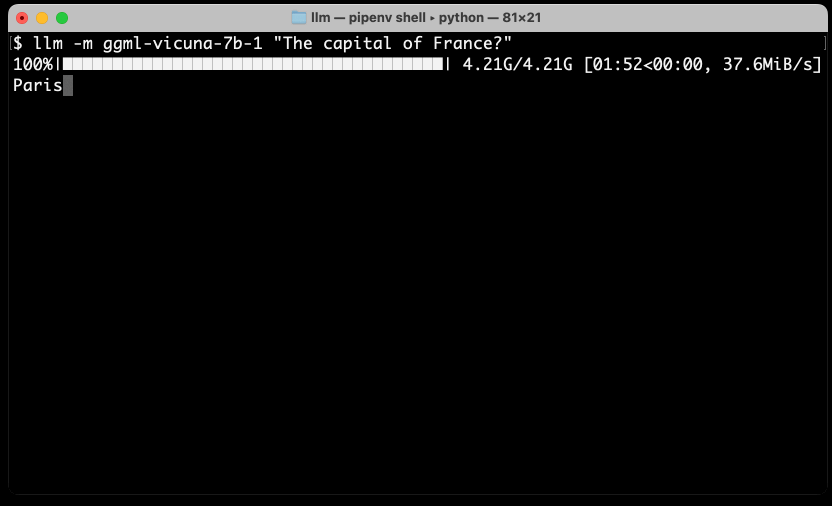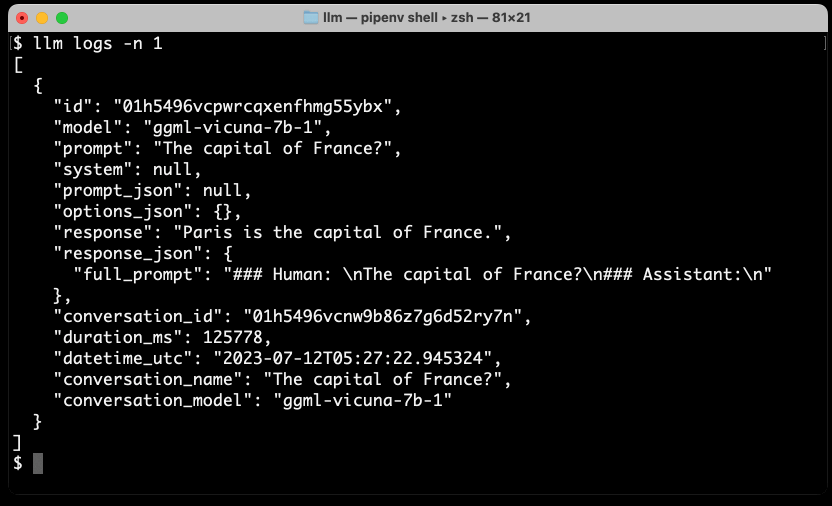
All prompts and responses are automatically logged to a SQLite database. Calling llm logs with a -n 1 argument will show the most recent record:
llm logs -n 1This outputs something like the following:
[
{
"id": "01h549p8r12ac1980crbr9yhjf",
"model": "ggml-vicuna-7b-1",
"prompt": "The capital of France?",
"system": null,
"prompt_json": null,
"options_json": {},
"response": "Paris is the capital of France.",
"response_json": {
"full_prompt": "### Human: \nThe capital of France?\n### Assistant:\n"
},
"conversation_id": "01h549p8r0abz6ebwd7agmjmgy",
"duration_ms": 9511,
"datetime_utc": "2023-07-12T05:37:44.407233",
"conversation_name": "The capital of France?",
"conversation_model": "ggml-vicuna-7b-1"
}
]You can see a full list of available models by running the llm models list command. The llm-gpt4all plugin adds 17 models to the tool:
llm models listI’ve installed all three plugins that provide extra models, so I see the following:
OpenAI Chat: gpt-3.5-turbo (aliases: 3.5, chatgpt)
OpenAI Chat: gpt-3.5-turbo-16k (aliases: chatgpt-16k, 3.5-16k)
OpenAI Chat: gpt-4 (aliases: 4, gpt4)
OpenAI Chat: gpt-4-32k (aliases: 4-32k)
PaLM 2: chat-bison-001 (aliases: palm, palm2)
gpt4all: orca-mini-3b - Orca (Small), 1.80GB download, needs 4GB RAM (installed)
gpt4all: ggml-gpt4all-j-v1 - Groovy, 3.53GB download, needs 8GB RAM (installed)
gpt4all: orca-mini-7b - Orca, 3.53GB download, needs 8GB RAM (installed)
gpt4all: ggml-vicuna-7b-1 - Vicuna, 3.92GB download, needs 8GB RAM (installed)
gpt4all: ggml-mpt-7b-chat - MPT Chat, 4.52GB download, needs 8GB RAM (installed)
gpt4all: ggml-replit-code-v1-3b - Replit, 4.84GB download, needs 4GB RAM (installed)
gpt4all: ggml-vicuna-13b-1 - Vicuna (large), 7.58GB download, needs 16GB RAM (installed)
gpt4all: nous-hermes-13b - Hermes, 7.58GB download, needs 16GB RAM (installed)
gpt4all: ggml-model-gpt4all-falcon-q4_0 - GPT4All Falcon, 3.78GB download, needs 8GB RAM
gpt4all: ggml-wizardLM-7B - Wizard, 3.92GB download, needs 8GB RAM
gpt4all: ggml-mpt-7b-base - MPT Base, 4.52GB download, needs 8GB RAM
gpt4all: ggml-mpt-7b-instruct - MPT Instruct, 4.52GB download, needs 8GB RAM
gpt4all: orca-mini-13b - Orca (Large), 6.82GB download, needs 16GB RAM
gpt4all: GPT4All-13B-snoozy - Snoozy, 7.58GB download, needs 16GB RAM
gpt4all: ggml-nous-gpt4-vicuna-13b - Nous Vicuna, 7.58GB download, needs 16GB RAM
gpt4all: ggml-stable-vicuna-13B - Stable Vicuna, 7.58GB download, needs 16GB RAM
gpt4all: wizardLM-13B-Uncensored - Wizard Uncensored, 7.58GB download, needs 16GB RAM
Mpt30b: mpt30b (aliases: mpt)
In addition to the gpt4all models I can also run PaLM 2 from Google and mpt30b from Mosaic, as well as the four OpenAI models.
Models have aliases, so in some cases you can run llm -m mpt instead of llm -m mpt30b.
We’ll try one more model. Google’s PaLM 2 was released a few weeks ago, and can be accessed through their PaLM API.
Obtain an API key for that, and install the llm-palm plugin:
pip install llm-palmSet your API key like this:
llm keys set palmNow you can run prompts against it like this:
llm -m palm "Ten absurd names for a pet giraffe"PaLM replies:
Here are ten absurd names for a pet giraffe:
- Stretch
- Necky
- Long Legs
- Tree Top
- Tall Boy
- High Five
- Sky Walker
- Cloud Chaser
- Star Gazer
- Horizon Hopper
I hope you find these names amusing!
This also gets logged to the database—run llm logs -n 1 again to see the log entry.
LLM supports continuing a conversation with more prompts. We can run another prompt through PaLM as part of the same conversation like this:
llm --continue "3 more and make them weirder"PaLM replies:
Sure, here are three more absurd names for a pet giraffe, even weirder than the first ten:
- Giraffey McFierceface
- Longneck von Longneck
- The Giraffe Whisperer
I hope you find these names even more amusing than the first ten!
Using -c/--continue will continue the most previous conversation. You can also pass a conversation ID (available in the output from llm logs) using --cid ID to reply to an older conversation thread.
Adding a new model
I’ve tried to make it as easy as possible to add support for additional models through writing plugins. The tutorial Writing a plugin to support a new model is extremely thorough, and includes detailed descriptions of how to start a new plugin, set up a development environment for it, integrate it with a new model and then package it for distribution.
The tutorial uses a Markov chain implementation as an example, possibly the simplest possible form of language model.
The source code of the other existing plugins should help show how to integrate with more complex models:
- llm_palm/__init__.py demonstrates how to integrate with a model exposed via Google’s API library.
- llm/default_plugins/openai_models.py demonstrates integration against the OpenAI APIs.
- llm_gpt4all.py shows an integration with the gpt4all Python library.
- llm_mpt30b.py demonstrates a direct integration against a model using the ctransformers library.
Using LLM from Python
LLM was originally designed to be used from the command-line, but in version 0.5 I’ve expanded it to work as a Python library as well.
The documentation for that is here, but here’s the short version:
import llm model = llm.get_model("gpt-3.5-turbo") model.key = 'YOUR_API_KEY_HERE' response = model.prompt("Five surprising names for a pet pelican") for chunk in response: print(chunk, end="") # Or wait for the whole response to be ready: print(response.text())
Any model that can be installed via a plugin can be accessed in the same way.
The API also supports conversations, where multiple prompts are sent to the model as part of the same persistent context:
import llm model = llm.get_model("ggml-mpt-7b-chat") conversation = model.conversation() r1 = conversation.prompt("Capital of Spain?") print(r1.text()) r2 = conversation.prompt("What language do they speak there?") print(r2.text())
What’s next?
You can follow ongoing LLM development in the GitHub repository issues.
My next priority is to get OpenAI functions working. I want to provide the option for other models from plugins to implement a similar pattern using the reAct pattern as well.
I’ll likely do this by implementing the concept of a “chain” of LLM calls, where a single prompt might lead to multiple calls being made to the LLM based on logic that decides if another call is necessary.
I’m also planning a web interface. I’m particularly excited about the potential for plugins here—I love the idea of plugins that provide new interfaces for interacting with language models that go beyond the chat interfaces we’ve mostly seen so far.
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026