Blogmarks tagged llm
Filters: Type: blogmark × llm × Sorted by date
awwaiid/gremllm (via) Delightfully cursed Python library by Brock Wilcox, built on top of LLM:
from gremllm import Gremllm counter = Gremllm("counter") counter.value = 5 counter.increment() print(counter.value) # 6? print(counter.to_roman_numerals()) # VI?
You tell your Gremllm what it should be in the constructor, then it uses an LLM to hallucinate method implementations based on the method name every time you call them!
This utility class can be used for a variety of purposes. Uhm. Also please don't use this and if you do please tell me because WOW. Or maybe don't tell me. Or do.
Here's the system prompt, which starts:
You are a helpful AI assistant living inside a Python object called '{self._identity}'.
Someone is interacting with you and you need to respond by generating Python code that will be eval'd in your context.
You have access to 'self' (the object) and can modify self._context to store data.
Continuous AI. GitHub Next have coined the term "Continuous AI" to describe "all uses of automated AI to support software collaboration on any platform". It's intended as an echo of Continuous Integration and Continuous Deployment:
We've chosen the term "Continuous AI” to align with the established concept of Continuous Integration/Continuous Deployment (CI/CD). Just as CI/CD transformed software development by automating integration and deployment, Continuous AI covers the ways in which AI can be used to automate and enhance collaboration workflows.
“Continuous AI” is not a term GitHub owns, nor a technology GitHub builds: it's a term we use to focus our minds, and which we're introducing to the industry. This means Continuous AI is an open-ended set of activities, workloads, examples, recipes, technologies and capabilities; a category, rather than any single tool.
I was thrilled to bits to see LLM get a mention as a tool that can be used to implement some of these patterns inside of GitHub Actions:
You can also use the llm framework in combination with the llm-github-models extension to create LLM-powered GitHub Actions which use GitHub Models using Unix shell scripting.
The GitHub Next team have started maintaining an Awesome Continuous AI list with links to projects that fit under this new umbrella term.
I'm particularly interested in the idea of having CI jobs (I guess CAI jobs?) that check proposed changes to see if there's documentation that needs to be updated and that might have been missed - a much more powerful variant of my documentation unit tests pattern.
model.yaml. From their GitHub repo it looks like this effort quietly launched a couple of months ago, driven by the LM Studio team. Their goal is to specify an "open standard for defining crossplatform, composable AI models".
A model can be defined using a YAML file that looks like this:
model: mistralai/mistral-small-3.2 base: - key: lmstudio-community/mistral-small-3.2-24b-instruct-2506-gguf sources: - type: huggingface user: lmstudio-community repo: Mistral-Small-3.2-24B-Instruct-2506-GGUF metadataOverrides: domain: llm architectures: - mistral compatibilityTypes: - gguf paramsStrings: - 24B minMemoryUsageBytes: 14300000000 contextLengths: - 4096 vision: true
This should be enough information for an LLM serving engine - such as LM Studio - to understand where to get the model weights (here that's lmstudio-community/Mistral-Small-3.2-24B-Instruct-2506-GGUF on Hugging Face, but it leaves space for alternative providers) plus various other configuration options and important metadata about the capabilities of the model.
I like this concept a lot. I've actually been considering something similar for my LLM tool - my idea was to use Markdown with a YAML frontmatter block - but now that there's an early-stage standard for it I may well build on top of this work instead.
I couldn't find any evidence that anyone outside of LM Studio is using this yet, so it's effectively a one-vendor standard for the moment. All of the models in their Model Catalog are defined using model.yaml.
llm-fragments-youtube. Excellent new LLM plugin by Agustin Bacigalup which lets you use the subtitles of any YouTube video as a fragment for running prompts against.
I tried it out like this:
llm install llm-fragments-youtube
llm -f youtube:dQw4w9WgXcQ \
'summary of people and what they do'
Which returned (full transcript):
The lyrics you've provided are from the song "Never Gonna Give You Up" by Rick Astley. The song features a narrator who is expressing unwavering love and commitment to another person. Here's a summary of the people involved and their roles:
The Narrator (Singer): A person deeply in love, promising loyalty, honesty, and emotional support. They emphasize that they will never abandon, hurt, or deceive their partner.
The Partner (Implied Listener): The person the narrator is addressing, who is experiencing emotional pain or hesitation ("Your heart's been aching but you're too shy to say it"). The narrator is encouraging them to understand and trust in the commitment being offered.
In essence, the song portrays a one-sided but heartfelt pledge of love, with the narrator assuring their partner of their steadfast dedication.
The plugin works by including yt-dlp as a Python dependency and then executing it via a call to subprocess.run().
o3-pro. OpenAI released o3-pro today, which they describe as a "version of o3 with more compute for better responses".
It's only available via the newer Responses API. I've added it to my llm-openai-plugin plugin which uses that new API, so you can try it out like this:
llm install -U llm-openai-plugin
llm -m openai/o3-pro "Generate an SVG of a pelican riding a bicycle"

It's slow - generating this pelican took 124 seconds! OpenAI suggest using their background mode for o3 prompts, which I haven't tried myself yet.
o3-pro is priced at $20/million input tokens and $80/million output tokens - 10x the price of regular o3 after its 80% price drop this morning.
Ben Hylak had early access and published his notes so far in God is hungry for Context: First thoughts on o3 pro. It sounds like this model needs to be applied very thoughtfully. It comparison to o3:
It's smarter. much smarter.
But in order to see that, you need to give it a lot more context. and I'm running out of context. [...]
My co-founder Alexis and I took the the time to assemble a history of all of our past planning meetings at Raindrop, all of our goals, even record voice memos: and then asked o3-pro to come up with a plan.
We were blown away; it spit out the exact kind of concrete plan and analysis I've always wanted an LLM to create --- complete with target metrics, timelines, what to prioritize, and strict instructions on what to absolutely cut.
The plan o3 gave us was plausible, reasonable; but the plan o3 Pro gave us was specific and rooted enough that it actually changed how we are thinking about our future.
This is hard to capture in an eval.
It sounds to me like o3-pro works best when combined with tools. I don't have tool support in llm-openai-plugin yet, here's the relevant issue.
Magistral — the first reasoning model by Mistral AI. Mistral's first reasoning model is out today, in two sizes. There's a 24B Apache 2 licensed open-weights model called Magistral Small (actually Magistral-Small-2506), and a larger API-only model called Magistral Medium.
Magistral Small is available as mistralai/Magistral-Small-2506 on Hugging Face. From that model card:
Context Window: A 128k context window, but performance might degrade past 40k. Hence we recommend setting the maximum model length to 40k.
Mistral also released an official GGUF version, Magistral-Small-2506_gguf, which I ran successfully using Ollama like this:
ollama pull hf.co/mistralai/Magistral-Small-2506_gguf:Q8_0
That fetched a 25GB file. I ran prompts using a chat session with llm-ollama like this:
llm chat -m hf.co/mistralai/Magistral-Small-2506_gguf:Q8_0
Here's what I got for "Generate an SVG of a pelican riding a bicycle" (transcript here):

It's disappointing that the GGUF doesn't support function calling yet - hopefully a community variant can add that, it's one of the best ways I know of to unlock the potential of these reasoning models.
I just noticed that Ollama have their own Magistral model too, which can be accessed using:
ollama pull magistral:latest
That gets you a 14GB q4_K_M quantization - other options can be found in the full list of Ollama magistral tags.
One thing that caught my eye in the Magistral announcement:
Legal, finance, healthcare, and government professionals get traceable reasoning that meets compliance requirements. Every conclusion can be traced back through its logical steps, providing auditability for high-stakes environments with domain-specialized AI.
I guess this means the reasoning traces are fully visible and not redacted in any way - interesting to see Mistral trying to turn that into a feature that's attractive to the business clients they are most interested in appealing to.
Also from that announcement:
Our early tests indicated that Magistral is an excellent creative companion. We highly recommend it for creative writing and storytelling, with the model capable of producing coherent or — if needed — delightfully eccentric copy.
I haven't seen a reasoning model promoted for creative writing in this way before.
You can try out Magistral Medium by selecting the new "Thinking" option in Mistral's Le Chat.
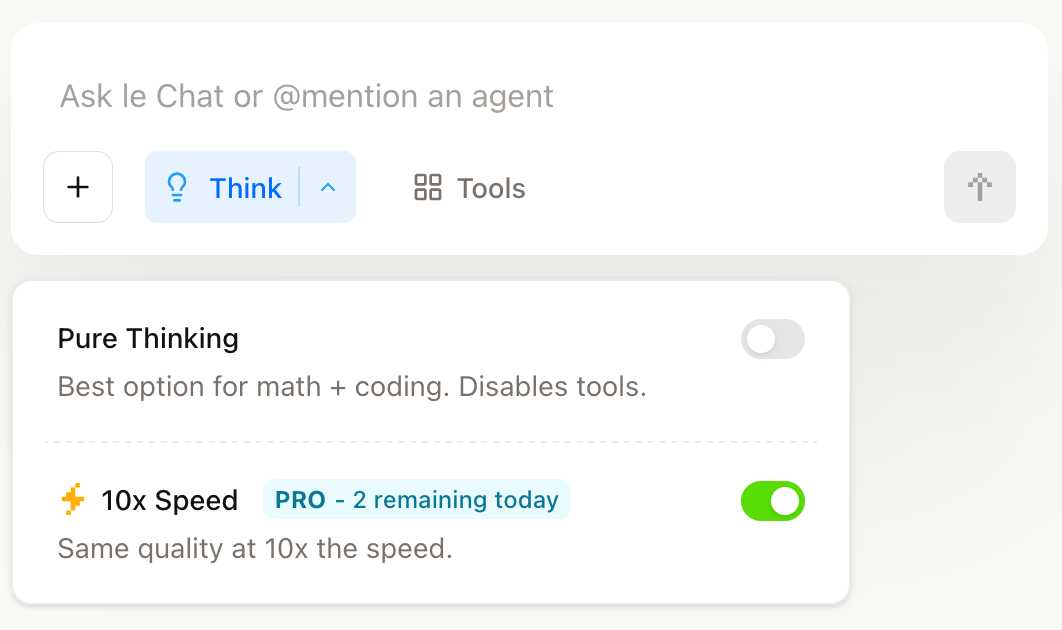
They have options for "Pure Thinking" and a separate option for "10x speed", which runs Magistral Medium at 10x the speed using Cerebras.
The new models are also available through the Mistral API. You can access them by installing llm-mistral and running llm mistral refresh to refresh the list of available models, then:
llm -m mistral/magistral-medium-latest \
'Generate an SVG of a pelican riding a bicycle'

Here's that transcript. At 13 input and 1,236 output tokens that cost me 0.62 cents - just over half a cent.
Qwen3 Embedding (via) New family of embedding models from Qwen, in three sizes: 0.6B, 4B, 8B - and two categories: Text Embedding and Text Reranking.
The full collection can be browsed on Hugging Face. The smallest available model is the 0.6B Q8 one, which is available as a 639MB GGUF. I tried it out using my llm-sentence-transformers plugin like this:
llm install llm-sentence-transformers
llm sentence-transformers register Qwen/Qwen3-Embedding-0.6B
llm embed -m sentence-transformers/Qwen/Qwen3-Embedding-0.6B -c hi | jq length
This output 1024, confirming that Qwen3 0.6B produces 1024 length embedding vectors.
These new models are the highest scoring open-weight models on the well regarded MTEB leaderboard - they're licensed Apache 2.0.
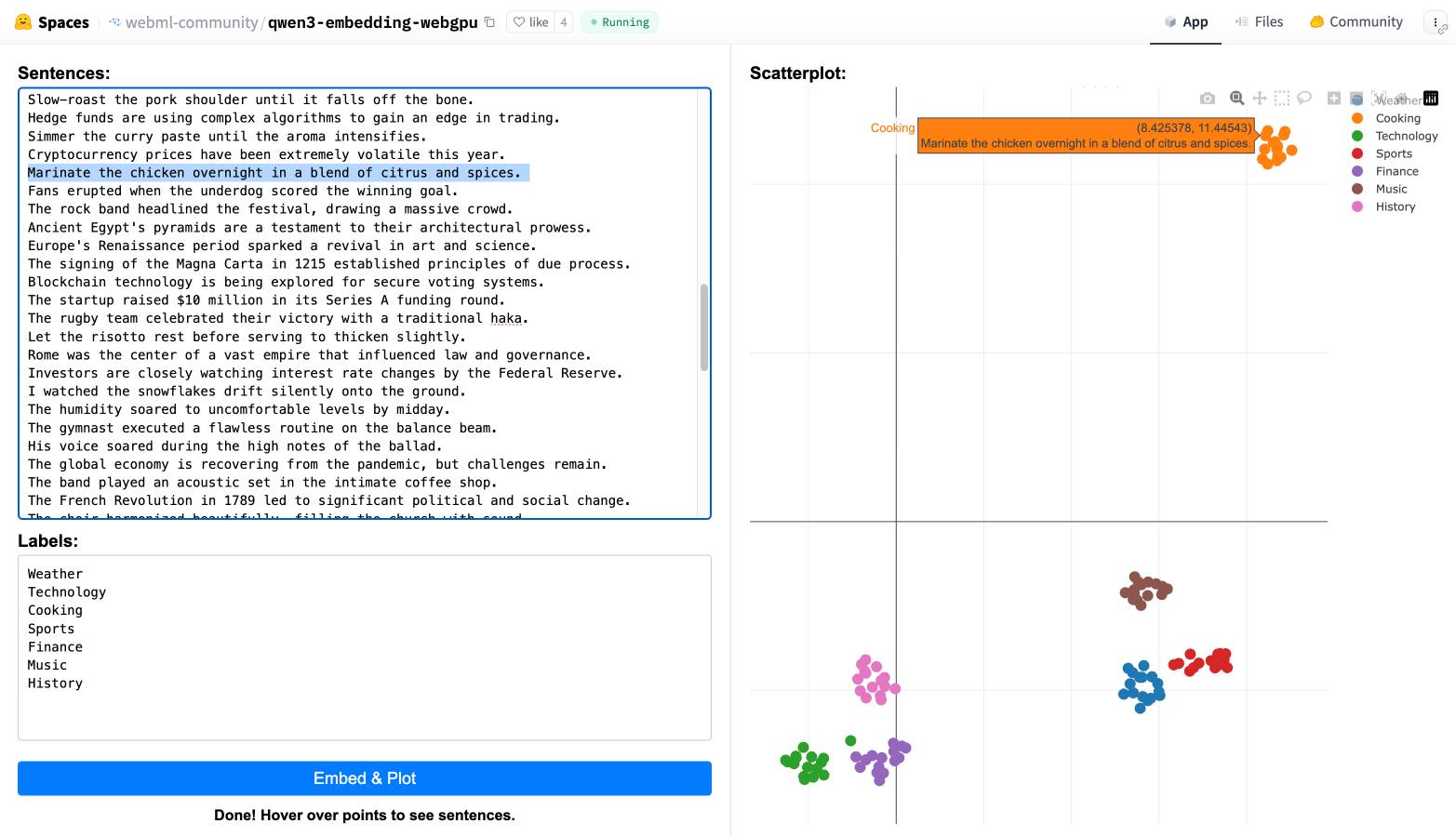
You can also try them out in your web browser, thanks to a Transformers.js port of the models. I loaded this page in Chrome (source code here) and it fetched 560MB of model files and gave me an interactive interface for visualizing clusters of embeddings like this:
Run Your Own AI (via) Anthony Lewis published this neat, concise tutorial on using my LLM tool to run local models on your own machine, using llm-mlx.
An under-appreciated way to contribute to open source projects is to publish unofficial guides like this one. Always brightens my day when something like this shows up.
deepseek-ai/DeepSeek-R1-0528. Sadly the trend for terrible naming of models has infested the Chinese AI labs as well.
DeepSeek-R1-0528 is a brand new and much improved open weights reasoning model from DeepSeek, a major step up from the DeepSeek R1 they released back in January.
In the latest update, DeepSeek R1 has significantly improved its depth of reasoning and inference capabilities by [...] Its overall performance is now approaching that of leading models, such as O3 and Gemini 2.5 Pro. [...]
Beyond its improved reasoning capabilities, this version also offers a reduced hallucination rate, enhanced support for function calling, and better experience for vibe coding.
The new R1 comes in two sizes: a 685B model called deepseek-ai/DeepSeek-R1-0528 (the previous R1 was 671B) and an 8B variant distilled from Qwen 3 called deepseek-ai/DeepSeek-R1-0528-Qwen3-8B.
The January release of R1 had a much larger collection of distilled models: four based on Qwen 2.5 (14B, 32B, Math 1.5B and Math 7B) and 2 based on Llama 3 (Llama-3.1 8B and Llama 3.3 70B Instruct).
No Llama model at all this time. I wonder if that's because Qwen 3 is really good and Apache 2 licensed, while Llama continues to stick with their janky license terms.
Further adding to the confusion, Ollama have mixed the two new models into their existing deepseek-r1 label. Last week running ollama pull deepseek-r1:8B from Ollama would get you DeepSeek-R1-Distill-Llama-8B (Internet Archive link), today that same command gets you DeepSeek-R1-0528-Qwen3-8B, a completely different base model.
If this bothers you as much as it bothers me, thankfully you can use the more explicit tag deepseek-r1:8b-0528-qwen3-q8_0.
Update: This is a great illustration of how confusing these names are! Ollama's deepseek-r1:8B alias actually points to deepseek-r1:8b-0528-qwen3-q4_K_M, a 5.2GB model. I pulled the larger q8_0 one.
I ran it like this:
ollama pull deepseek-r1:8b-0528-qwen3-q8_0
It fetched 8.9GB of model weights, then I had it draw me a pelican.
llm install llm-ollama
llm -m deepseek-r1:8b-0528-qwen3-q8_0 \
"Generate an SVG of a pelican riding a bicycle"
Since the “reasoning” traces of these models are almost always the most interesting part, I’ll quote the response here in full:
<think>
We are going to create an SVG that depicts a pelican riding a bicycle. Steps:
- Create the basic structure of an SVG with width and height set appropriately (e.g., 400x200).
- Draw a pelican: We'll break it down into parts - body, beak, eye, feet, wings, etc.
- Draw a bicycle: We can represent it as two circles for wheels, a rectangle for the frame, and some other details.
Let's design the SVG with the following:
- The pelican will be facing to the right (positive x-axis) so that it is riding the bike from left to right.
- The bicycle will have two wheels and a simple frame in front of the pelican.
We'll use absolute positioning for each part. Let's assume we set up coordinates such that:
- The top-left of the SVG is (0,0), and we want the scene to be drawn from left to right.
- The pelican will be positioned at (50, 120) with a body length of about 30 units.
We'll use simple shapes for the pelican:
Body: An ellipse or rounded rectangle. Let's do an ellipse for the body. Beak: A triangle pointing to the right. Head: Another ellipse but smaller and positioned in front of the body. Wings: Two triangles (one above each other, one slightly behind) that are upside down.
Bicycle:
- Wheels: two circles at fixed positions relative to the frame.
- Frame: a rectangle with some details for handlebars and seat.
Since this is a fun illustration, we'll keep it simple but recognizable.
Let's code accordingly.
</think>
Here’s an SVG of a pelican riding a bicycle. This example uses basic shapes to create a stylized version:<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 400 200"> <!-- Pelican body --> <ellipse cx="150" cy="150" rx="80" ry="60" fill="#FFD700"/> <!-- Pelican head (larger for comedic effect) --> <circle cx="90" cy="120" r="45" fill="#FFA3CE"/> <!-- Pelican beak --> <polygon points="80,110 60,120 80,130 70,140 60,150" fill="#FFC233"/> <!-- Pelican eye --> <circle cx="95" cy="115" r="3" fill="#fff"/> <!-- Bicycle wheels --> <ellipse cx="380" cy="140" rx="25" ry="60" transform="rotate(90 380 140)" fill="black"/> <ellipse cx="380" cy="70" rx="25" ry="60" transform="rotate(90 380 70)" fill="black"/> <!-- Bicycle frame --> <path d="M 15,40 L 15,140 H 370 L 370,140 V 40 Z" stroke="gray" stroke-width="6" fill="none"/> <!-- Handlebars and seat (stylized) --> <path d="M 280,40 C 290,35 300,30 310,40 C 320,50 330,60 310,70 L 310,70 Q 290,50 280,40" fill="none" stroke="gray"/> <!-- Pedals --> <circle cx="340" cy="70" r="15" fill="#3366CC"/> <polygon points="340,65 330,45 350,45" fill="#F29E3D"/> <circle cx="340" cy="140" r="15" fill="#3366CC"/> <polygon points="340,135 330,115 350,115" fill="#F29E3D"/> <!-- Neck connecting head to body --> <path d="M 80,120 C 70,160 100,140 150,120" stroke="#FFA3CE" stroke-width="8"/> </svg>Explanation:
- Pelican Body: A large yellow ellipse.
- Head: A pink circle with a prominent beak (yellow-orange triangle).
- Bicycle:
- Wheels are black ellipses rotated vertically to simulate spokes.
- The frame is a gray rectangle extending from the pelican’s back to the right side of the SVG.
- Handlebars and seat are simplified curves in gray.
This creates a comical scene with the pelican riding forward. You can adjust colors, sizes, or positions by modifying
cx,cy,rx,ryattributes and fill/stroke values.
Love the thought process, and the explanation! The actual rendered SVG does leave a lot to be desired though:
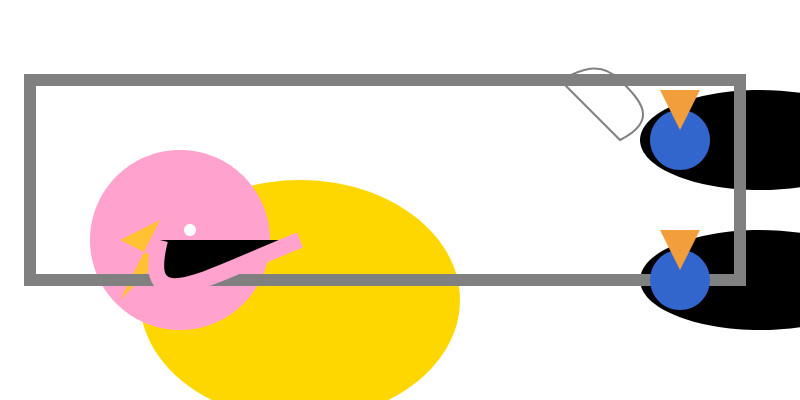
To be fair, this is just using the ~8GB Qwen3 Q8_0 model on my laptop. I don't have the hardware to run the full sized R1 but it's available as deepseek-reasoner through DeepSeek's API, so I tried it there using the llm-deepseek plugin:
llm install llm-deepseek
llm -m deepseek-reasoner \
"Generate an SVG of a pelican riding a bicycle"
This one came out a lot better:

Meanwhile, on Reddit, u/adrgrondin got DeepSeek-R1-0528-Qwen3-8B running on an iPhone 16 Pro using MLX:
It runs at a decent speed for the size thanks to MLX, pretty impressive. But not really usable in my opinion, the model is thinking for too long, and the phone gets really hot.
llm-github-models 0.15. Anthony Shaw's llm-github-models plugin just got an upgrade: it now supports LLM 0.26 tool use for a subset of the models hosted on the GitHub Models API, contributed by Caleb Brose.
The neat thing about this GitHub Models plugin is that it picks up an API key from your GITHUB_TOKEN - and if you're running LLM within a GitHub Actions worker the API key provided by the worker should be enough to start executing prompts!
I tried it out against Cohere Command A via GitHub Models like this (transcript here):
llm install llm-github-models
llm keys set github
# Paste key here
llm -m github/cohere-command-a -T llm_time 'What time is it?' --td
We now have seven LLM plugins that provide tool support, covering OpenAI, Anthropic, Gemini, Mistral, Ollama, llama-server and now GitHub Models.
llm-tools-exa. When I shipped LLM 0.26 yesterday one of the things I was most excited about was seeing what new tool plugins people would build for it.
Dan Turkel's llm-tools-exa is one of the first. It adds web search to LLM using Exa (previously), a relatively new search engine offering that rare thing, an API for search. They have a free preview, you can grab an API key here.
I'm getting pretty great results! I tried it out like this:
llm install llm-tools-exa
llm keys set exa
# Pasted API key here
llm -T web_search "What's in LLM 0.26?"
Here's the full answer - it started like this:
LLM 0.26 was released on May 27, 2025, and the biggest new feature in this version is official support for tools. Here's a summary of what's new and notable in LLM 0.26:
- LLM can now run tools. You can grant LLMs from OpenAI, Anthropic, Gemini, and local models access to any tool you represent as a Python function.
- Tool plugins are introduced, allowing installation of plugins that add new capabilities to any model you use.
- Tools can be installed from plugins and loaded by name with the --tool/-T option. [...]
Exa provided 21,000 tokens of search results, including what looks to be a full copy of my blog entry and the release notes for LLM.
llm-mistral 0.14. I added tool-support to my plugin for accessing the Mistral API from LLM today, plus support for Mistral's new Codestral Embed embedding model.
An interesting challenge here is that I'm not using an official client library for llm-mistral - I rolled my own client on top of their streaming HTTP API using Florimond Manca's httpx-sse library. It's a very pleasant way to interact with streaming APIs - here's my code that does most of the work.
The problem I faced is that Mistral's API documentation for function calling has examples in Python and TypeScript but doesn't include curl or direct documentation of their HTTP endpoints!
I needed documentation at the HTTP level. Could I maybe extract that directly from Mistral's official Python library?
It turns out I could. I started by cloning the repo:
git clone https://github.com/mistralai/client-python
cd client-python/src/mistralai
files-to-prompt . | ttokMy ttok tool gave me a token count of 212,410 (counted using OpenAI's tokenizer, but that's normally a close enough estimate) - Mistral's models tap out at 128,000 so I switched to Gemini 2.5 Flash which can easily handle that many.
I ran this:
files-to-prompt -c . > /tmp/mistral.txt
llm -f /tmp/mistral.txt \
-m gemini-2.5-flash-preview-05-20 \
-s 'Generate comprehensive HTTP API documentation showing
how function calling works, include example curl commands for each step'The results were pretty spectacular! Gemini 2.5 Flash produced a detailed description of the exact set of HTTP APIs I needed to interact with, and the JSON formats I should pass to them.
There are a bunch of steps needed to get tools working in a new model, as described in the LLM plugin authors documentation. I started working through them by hand... and then got lazy and decided to see if I could get a model to do the work for me.
This time I tried the new Claude Opus 4. I fed it three files: my existing, incomplete llm_mistral.py, a full copy of llm_gemini.py with its working tools implementation and a copy of the API docs Gemini had written for me earlier. I prompted:
I need to update this Mistral code to add tool support. I've included examples of that code for Gemini, and a detailed README explaining the Mistral format.
Claude churned away and wrote me code that was most of what I needed. I tested it in a bunch of different scenarios, pasted problems back into Claude to see what would happen, and eventually took over and finished the rest of the code myself. Here's the full transcript.
I'm a little sad I didn't use Mistral to write the code to support Mistral, but I'm pleased to add yet another model family to the list that's supported for tool usage in LLM.
llm-llama-server 0.2. Here's a second option for using LLM's new tool support against local models (the first was via llm-ollama).
It turns out the llama.cpp ecosystem has pretty robust OpenAI-compatible tool support already, so my llm-llama-server plugin only needed a quick upgrade to get those working there.
Unfortunately it looks like streaming support doesn't work with tools in llama-server at the moment, so I added a new model ID called llama-server-tools which disables streaming and enables tools.
Here's how to try it out. First, ensure you have llama-server - the easiest way to get that on macOS is via Homebrew:
brew install llama.cpp
Start the server running like this. This command will download and cache the 3.2GB unsloth/gemma-3-4b-it-GGUF:Q4_K_XL if you don't yet have it:
llama-server --jinja -hf unsloth/gemma-3-4b-it-GGUF:Q4_K_XL
Then in another window:
llm install llm-llama-server
llm -m llama-server-tools -T llm_time 'what time is it?' --td
And since you don't even need an API key for this, even if you've never used LLM before you can try it out with this uvx one-liner:
uvx --with llm-llama-server llm -m llama-server-tools -T llm_time 'what time is it?' --td
For more notes on using llama.cpp with LLM see Trying out llama.cpp’s new vision support from a couple of weeks ago.
How I used o3 to find CVE-2025-37899, a remote zeroday vulnerability in the Linux kernel’s SMB implementation (via) Sean Heelan:
The vulnerability [o3] found is CVE-2025-37899 (fix here), a use-after-free in the handler for the SMB 'logoff' command. Understanding the vulnerability requires reasoning about concurrent connections to the server, and how they may share various objects in specific circumstances. o3 was able to comprehend this and spot a location where a particular object that is not referenced counted is freed while still being accessible by another thread. As far as I'm aware, this is the first public discussion of a vulnerability of that nature being found by a LLM.
Before I get into the technical details, the main takeaway from this post is this: with o3 LLMs have made a leap forward in their ability to reason about code, and if you work in vulnerability research you should start paying close attention. If you're an expert-level vulnerability researcher or exploit developer the machines aren't about to replace you. In fact, it is quite the opposite: they are now at a stage where they can make you significantly more efficient and effective. If you have a problem that can be represented in fewer than 10k lines of code there is a reasonable chance o3 can either solve it, or help you solve it.
Sean used my LLM tool to help find the bug! He ran it against the prompts he shared in this GitHub repo using the following command:
llm --sf system_prompt_uafs.prompt \
-f session_setup_code.prompt \
-f ksmbd_explainer.prompt \
-f session_setup_context_explainer.prompt \
-f audit_request.prompt
Sean ran the same prompt 100 times, so I'm glad he was using the new, more efficient fragments mechanism.
o3 found his first, known vulnerability 8/100 times - but found the brand new one in just 1 out of the 100 runs it performed with a larger context.
I thoroughly enjoyed this snippet which perfectly captures how I feel when I'm iterating on prompts myself:
In fact my entire system prompt is speculative in that I haven’t ran a sufficient number of evaluations to determine if it helps or hinders, so consider it equivalent to me saying a prayer, rather than anything resembling science or engineering.
Sean's conclusion with respect to the utility of these models for security research:
If we were to never progress beyond what o3 can do right now, it would still make sense for everyone working in VR [Vulnerability Research] to figure out what parts of their work-flow will benefit from it, and to build the tooling to wire it in. Of course, part of that wiring will be figuring out how to deal with the the signal to noise ratio of ~1:50 in this case, but that’s something we are already making progress at.
llm-anthropic 0.16. New release of my LLM plugin for Anthropic adding the new Claude 4 Opus and Sonnet models.
You can see pelicans on bicycles generated using the new plugin at the bottom of my live blog covering the release.
I also released llm-anthropic 0.16a1 which works with the latest LLM alpha and provides tool usage feature on top of the Claude models.
The new models can be accessed using both their official model ID and the aliases I've set for them in the plugin:
llm install -U llm-anthropic
llm keys set anthropic
# paste key here
llm -m anthropic/claude-sonnet-4-0 \
'Generate an SVG of a pelican riding a bicycle'
This uses the full model ID - anthropic/claude-sonnet-4-0.
I've also setup aliases claude-4-sonnet and claude-4-opus. These are notably different from the official Anthropic names - I'm sticking with their previous naming scheme of claude-VERSION-VARIANT as seen with claude-3.7-sonnet.
Here's an example that uses the new alpha tool feature with the new Opus:
llm install llm-anthropic==0.16a1
llm --functions '
def multiply(a: int, b: int):
return a * b
' '234324 * 2343243' --td -m claude-4-opus
Outputs:
I'll multiply those two numbers for you.
Tool call: multiply({'a': 234324, 'b': 2343243})
549078072732
The result of 234,324 × 2,343,243 is **549,078,072,732**.
Here's the output of llm logs -c from that tool-enabled prompt response. More on tool calling in my recent workshop.
Devstral. New Apache 2.0 licensed LLM release from Mistral, this time specifically trained for code.
Devstral achieves a score of 46.8% on SWE-Bench Verified, outperforming prior open-source SoTA models by more than 6% points. When evaluated under the same test scaffold (OpenHands, provided by All Hands AI 🙌), Devstral exceeds far larger models such as Deepseek-V3-0324 (671B) and Qwen3 232B-A22B.
I'm always suspicious of small models like this that claim great benchmarks against much larger rivals, but there's a Devstral model that is just 14GB on Ollama to it's quite easy to try out for yourself.
I fetched it like this:
ollama pull devstral
Then ran it in a llm chat session with llm-ollama like this:
llm install llm-ollama
llm chat -m devstral
Initial impressions: I think this one is pretty good! Here's a full transcript where I had it write Python code to fetch a CSV file from a URL and import it into a SQLite database, creating the table with the necessary columns. Honestly I need to retire that challenge, it's been a while since a model failed at it, but it's still interesting to see how it handles follow-up prompts to demand things like asyncio or a different HTTP client library.
It's also available through Mistral's API. llm-mistral 0.13 configures the devstral-small alias for it:
llm install -U llm-mistral
llm keys set mistral
# paste key here
llm -m devstral-small 'HTML+JS for a large text countdown app from 5m'
Gemini 2.5: Our most intelligent models are getting even better. A bunch of new Gemini 2.5 announcements at Google I/O today.
2.5 Flash and 2.5 Pro are both getting audio output (previously previewed in Gemini 2.0) and 2.5 Pro is getting an enhanced reasoning mode called "Deep Think" - not yet available via the API.
Available today is the latest Gemini 2.5 Flash model, gemini-2.5-flash-preview-05-20. I added support to that in llm-gemini 0.20 (and, if you're using the LLM tool-use alpha, llm-gemini 0.20a2).
I tried it out on my personal benchmark, as seen in the Google I/O keynote!
llm -m gemini-2.5-flash-preview-05-20 'Generate an SVG of a pelican riding a bicycle'
Here's what I got from the default model, with its thinking mode enabled:
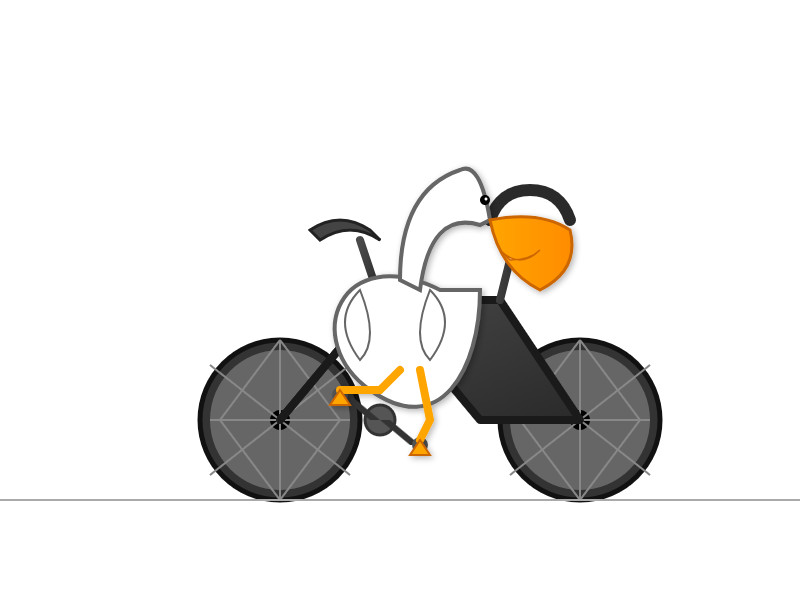
Full transcript. 11 input tokens, 2,619 output tokens, 10,391 thinking tokens = 4.5537 cents.
I ran the same thing again with -o thinking_budget 0 to turn off thinking mode entirely, and got this:

Full transcript. 11 input, 1,243 output = 0.0747 cents.
The non-thinking model is priced differently - still $0.15/million for input but $0.60/million for output as opposed to $3.50/million for thinking+output. The pelican it drew was 61x cheaper!
Finally, inspired by the keynote I ran this follow-up prompt to animate the more expensive pelican:
llm --cid 01jvqjqz9aha979yemcp7a4885 'Now animate it'
This one is pretty great!

llm-pdf-to-images. Inspired by my previous llm-video-frames plugin, I thought it would be neat to have a plugin for LLM that can take a PDF and turn that into an image-per-page so you can feed PDFs into models that support image inputs but don't yet support PDFs.
This should now do exactly that:
llm install llm-pdf-to-images
llm -f pdf-to-images:path/to/document.pdf 'Summarize this document'Under the hood it's using the PyMuPDF library. The key code to convert a PDF into images looks like this:
import fitz doc = fitz.open("input.pdf") for page in doc: pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) jpeg_bytes = pix.tobytes(output="jpg", jpg_quality=30)
Once I'd figured out that code I got o4-mini to write most of the rest of the plugin, using llm-fragments-github to load in the example code from the video plugin:
llm -f github:simonw/llm-video-frames ' import fitz doc = fitz.open("input.pdf") for page in doc: pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) jpeg_bytes = pix.tobytes(output="jpg", jpg_quality=30) ' -s 'output llm_pdf_to_images.py which adds a pdf-to-images: fragment loader that converts a PDF to frames using fitz like in the example' \ -m o4-mini
Here's the transcript - more details in this issue.
I had some weird results testing this with GPT 4.1 mini. I created a test PDF with two pages - one white, one black - and ran a test prompt like this:
llm -f 'pdf-to-images:blank-pages.pdf' \ 'describe these images'
The first image features a stylized red maple leaf with triangular facets, giving it a geometric appearance. The maple leaf is a well-known symbol associated with Canada.
The second image is a simple black silhouette of a cat sitting and facing to the left. The cat's tail curls around its body. The design is minimalistic and iconic.
I got even wilder hallucinations for other prompts, like "summarize this document" or "describe all figures". I have a collection of those in this Gist.
Thankfully this behavior is limited to GPT-4.1 mini. I upgraded to full GPT-4.1 and got much more sensible results:
llm -f 'pdf-to-images:blank-pages.pdf' \ 'describe these images' -m gpt-4.1
Certainly! Here are the descriptions of the two images you provided:
First image: This image is completely white. It appears blank, with no discernible objects, text, or features.
Second image: This image is entirely black. Like the first, it is blank and contains no visible objects, text, or distinct elements.
If you have questions or need a specific kind of analysis or modification, please let me know!
qwen2.5vl in Ollama. Ollama announced a complete overhaul of their vision support the other day. Here's the first new model they've shipped since then - a packaged version of Qwen 2.5 VL which was first released on January 26th 2025. Here are my notes from that release.
I upgraded Ollama (it auto-updates so I just had to restart it from the tray icon) and ran this:
ollama pull qwen2.5vl
This downloaded a 6GB model file. I tried it out against my photo of Cleo rolling on the beach:
{kind=link}
llm -a https://static.simonwillison.net/static/2025/cleo-sand.jpg \
'describe this image' -m qwen2.5vl
And got a pretty good result:
The image shows a dog lying on its back on a sandy beach. The dog appears to be a medium to large breed with a dark coat, possibly black or dark brown. It is wearing a red collar or harness around its chest. The dog's legs are spread out, and its belly is exposed, suggesting it might be rolling around or playing in the sand. The sand is light-colored and appears to be dry, with some small footprints and marks visible around the dog. The lighting in the image suggests it is taken during the daytime, with the sun casting a shadow of the dog to the left side of the image. The overall scene gives a relaxed and playful impression, typical of a dog enjoying time outdoors on a beach.
Qwen 2.5 VL has a strong reputation for OCR, so I tried it on my poster:
llm -a https://static.simonwillison.net/static/2025/poster.jpg \
'convert to markdown' -m qwen2.5vl
The result that came back:
It looks like the image you provided is a jumbled and distorted text, making it difficult to interpret. If you have a specific question or need help with a particular topic, please feel free to ask, and I'll do my best to assist you!
I'm not sure what went wrong here. My best guess is that the maximum resolution the model can handle is too small to make out the text, or maybe Ollama resized the image to the point of illegibility before handing it to the model?
Update: I think this may be a bug relating to URL handling in LLM/llm-ollama. I tried downloading the file first:
wget https://static.simonwillison.net/static/2025/poster.jpg
llm -m qwen2.5vl 'extract text' -a poster.jpg
This time it did a lot better. The results weren't perfect though - it ended up stuck in a loop outputting the same code example dozens of times.
I tried with a different prompt - "extract text" - and it got confused by the three column layout, misread Datasette as "Datasetette" and missed some of the text. Here's that result.
These experiments used qwen2.5vl:7b (6GB) - I expect the results would be better with the larger qwen2.5vl:32b (21GB) and qwen2.5vl:72b (71GB) models.
Fred Jonsson reported a better result using the MLX model via LM studio (~9GB model running in 8bit - I think that's mlx-community/Qwen2.5-VL-7B-Instruct-8bit). His full output is here - looks almost exactly right to me.
OpenAI Codex. Announced today, here's the documentation for OpenAI's "cloud-based software engineering agent". It's not yet available for us $20/month Plus customers ("coming soon") but if you're a $200/month Pro user you can try it out now.
At a high level, you specify a prompt, and the agent goes to work in its own environment. After about 8–10 minutes, the agent gives you back a diff.
You can execute prompts in either ask mode or code mode. When you select ask, Codex clones a read-only version of your repo, booting faster and giving you follow-up tasks. Code mode, however, creates a full-fledged environment that the agent can run and test against.
This 4 minute demo video is a useful overview. One note that caught my eye is that the setup phase for an environment can pull from the internet (to install necessary dependencies) but the agent loop itself still runs in a network disconnected sandbox.
It sounds similar to GitHub's own Copilot Workspace project, which can compose PRs against your code based on a prompt. The big difference is that Codex incorporates a full Code Interpeter style environment, allowing it to build and run the code it's creating and execute tests in a loop.
Copilot Workspaces has a level of integration with Codespaces but still requires manual intervention to help exercise the code.
Also similar to Copilot Workspaces is a confusing name. OpenAI now have four products called Codex:
- OpenAI Codex, announced today.
- Codex CLI, a completely different coding assistant tool they released a few weeks ago that is the same kind of shape as Claude Code. This one owns the openai/codex namespace on GitHub.
- codex-mini, a brand new model released today that is used by their Codex product. It's a fine-tuned o4-mini variant. I released llm-openai-plugin 0.4 adding support for that model.
- OpenAI Codex (2021) - Internet Archive link, OpenAI's first specialist coding model from the GPT-3 era. This was used by the original GitHub Copilot and is still the current topic of Wikipedia's OpenAI Codex page.
My favorite thing about this most recent Codex product is that OpenAI shared the full Dockerfile for the environment that the system uses to run code - in openai/codex-universal on GitHub because openai/codex was taken already.
This is extremely useful documentation for figuring out how to use this thing - I'm glad they're making this as transparent as possible.
And to be fair, If you ignore it previous history Codex Is a good name for this product. I'm just glad they didn't call it Ada.
LLM 0.26a0 adds support for tools! It's only an alpha so I'm not going to promote this extensively yet, but my LLM project just grew a feature I've been working towards for nearly two years now: tool support!
I'm presenting a workshop about Building software on top of Large Language Models at PyCon US tomorrow and this was the one feature I really needed to pull everything else together.
Tools can be used from the command-line like this (inspired by sqlite-utils --functions):
llm --functions ' def multiply(x: int, y: int) -> int: """Multiply two numbers.""" return x * y ' 'what is 34234 * 213345' -m o4-mini
You can add --tools-debug (shortcut: --td) to have it show exactly what tools are being executed and what came back. More documentation here.
It's also available in the Python library:
import llm def multiply(x: int, y: int) -> int: """Multiply two numbers.""" return x * y model = llm.get_model("gpt-4.1-mini") response = model.chain( "What is 34234 * 213345?", tools=[multiply] ) print(response.text())
There's also a new plugin hook so plugins can register tools that can then be referenced by name using llm --tool name_of_tool "prompt".
There's still a bunch I want to do before including this in a stable release, most notably adding support for Python asyncio. It's a pretty exciting start though!
llm-anthropic 0.16a0 and llm-gemini 0.20a0 add tool support for Anthropic and Gemini models, depending on the new LLM alpha.
Update: Here's the section about tools from my PyCon workshop.
llm-gemini 0.19.1.
Bugfix release for my llm-gemini plugin, which was recording the number of output tokens (needed to calculate the price of a response) incorrectly for the Gemini "thinking" models. Those models turn out to return candidatesTokenCount and thoughtsTokenCount as two separate values which need to be added together to get the total billed output token count. Full details in this issue.
I spotted this potential bug in this response log this morning, and my concerns were confirmed when Paul Gauthier wrote about a similar fix in Aider in Gemini 2.5 Pro Preview 03-25 benchmark cost, where he noted that the $6.32 cost recorded to benchmark Gemini 2.5 Pro Preview 03-25 was incorrect. Since that model is no longer available (despite the date-based model alias persisting) Paul is not able to accurately calculate the new cost, but it's likely a lot more since the Gemini 2.5 Pro Preview 05-06 benchmark cost $37.
I've gone through my gemini tag and attempted to update my previous posts with new calculations - this mostly involved increases in the order of 12.336 cents to 16.316 cents (as seen here).
Medium is the new large. New model release from Mistral - this time closed source/proprietary. Mistral Medium claims strong benchmark scores similar to GPT-4o and Claude 3.7 Sonnet, but is priced at $0.40/million input and $2/million output - about the same price as GPT 4.1 Mini. For comparison, GPT-4o is $2.50/$10 and Claude 3.7 Sonnet is $3/$15.
The model is a vision LLM, accepting both images and text.
More interesting than the price is the deployment model. Mistral Medium may not be open weights but it is very much available for self-hosting:
Mistral Medium 3 can also be deployed on any cloud, including self-hosted environments of four GPUs and above.
Mistral's other announcement today is Le Chat Enterprise. This is a suite of tools that can integrate with your company's internal data and provide "agents" (these look similar to Claude Projects or OpenAI GPTs), again with the option to self-host.
Is there a new open weights model coming soon? This note tucked away at the bottom of the Mistral Medium 3 announcement seems to hint at that:
With the launches of Mistral Small in March and Mistral Medium today, it's no secret that we're working on something 'large' over the next few weeks. With even our medium-sized model being resoundingly better than flagship open source models such as Llama 4 Maverick, we're excited to 'open' up what's to come :)
I released llm-mistral 0.12 adding support for the new model.
Diane, I wrote a lecture by talking about it. Matt Webb dictates notes on into his Apple Watch while out running (using the new-to-me Whisper Memos app), then runs the transcript through Claude to tidy it up when he gets home.
His Claude 3.7 Sonnet prompt for this is:
you are Diane, my secretary. please take this raw verbal transcript and clean it up. do not add any of your own material. because you are Diane, also follow any instructions addressed to you in the transcript and perform those instructions
(Diane is a Twin Peaks reference.)
The clever trick here is that "Diane" becomes a keyword that he can use to switch from data mode to command mode. He can say "Diane I meant to include that point in the last section. Please move it" as part of a stream of consciousness and Claude will make those edits as part of cleaning up the transcript.
On Bluesky Matt shared the macOS shortcut he's using for this, which shells out to my LLM tool using llm-anthropic:
llm-fragment-symbex. I released a new LLM fragment loader plugin that builds on top of my Symbex project.
Symbex is a CLI tool I wrote that can run against a folder full of Python code and output functions, classes, methods or just their docstrings and signatures, using the Python AST module to parse the code.
llm-fragments-symbex brings that ability directly to LLM. It lets you do things like this:
llm install llm-fragments-symbex
llm -f symbex:path/to/project -s 'Describe this codebase'
I just ran that against my LLM project itself like this:
cd llm
llm -f symbex:. -s 'guess what this code does'
Here's the full output, which starts like this:
This code listing appears to be an index or dump of Python functions, classes, and methods primarily belonging to a codebase related to large language models (LLMs). It covers a broad functionality set related to managing LLMs, embeddings, templates, plugins, logging, and command-line interface (CLI) utilities for interaction with language models. [...]
That page also shows the input generated by the fragment - here's a representative extract:
# from llm.cli import resolve_attachment def resolve_attachment(value): """Resolve an attachment from a string value which could be: - "-" for stdin - A URL - A file path Returns an Attachment object. Raises AttachmentError if the attachment cannot be resolved.""" # from llm.cli import AttachmentType class AttachmentType: def convert(self, value, param, ctx): # from llm.cli import resolve_attachment_with_type def resolve_attachment_with_type(value: str, mimetype: str) -> Attachment:
If your Python code has good docstrings and type annotations, this should hopefully be a shortcut for providing full API documentation to a model without needing to dump in the entire codebase.
The above example used 13,471 input tokens and 781 output tokens, using openai/gpt-4.1-mini. That model is extremely cheap, so the total cost was 0.6638 cents - less than a cent.
The plugin itself was mostly written by o4-mini using the llm-fragments-github plugin to load the simonw/symbex and simonw/llm-hacker-news repositories as example code:
llm \ -f github:simonw/symbex \ -f github:simonw/llm-hacker-news \ -s "Write a new plugin as a single llm_fragments_symbex.py file which provides a custom loader which can be used like this: llm -f symbex:path/to/folder - it then loads in all of the python function signatures with their docstrings from that folder using the same trick that symbex uses, effectively the same as running symbex . '*' '*.*' --docs --imports -n" \ -m openai/o4-mini -o reasoning_effort high
Here's the response. 27,819 input, 2,918 output = 4.344 cents.
In working on this project I identified and fixed a minor cosmetic defect in Symbex itself. Technically this is a breaking change (it changes the output) so I shipped that as Symbex 2.0.
llm-fragments-github 0.2.
I upgraded my llm-fragments-github plugin to add a new fragment type called issue. It lets you pull the entire content of a GitHub issue thread into your prompt as a concatenated Markdown file.
(If you haven't seen fragments before I introduced them in Long context support in LLM 0.24 using fragments and template plugins.)
I used it just now to have Gemini 2.5 Pro provide feedback and attempt an implementation of a complex issue against my LLM project:
llm install llm-fragments-github
llm -f github:simonw/llm \
-f issue:simonw/llm/938 \
-m gemini-2.5-pro-exp-03-25 \
--system 'muse on this issue, then propose a whole bunch of code to help implement it'
Here I'm loading the FULL content of the simonw/llm repo using that -f github:simonw/llm fragment (documented here), then loading all of the comments from issue 938 where I discuss quite a complex potential refactoring. I ask Gemini 2.5 Pro to "muse on this issue" and come up with some code.
This worked shockingly well. Here's the full response, which highlighted a few things I hadn't considered yet (such as the need to migrate old database records to the new tree hierarchy) and then spat out a whole bunch of code which looks like a solid start to the actual implementation work I need to do.
I ran this against Google's free Gemini 2.5 Preview, but if I'd used the paid model it would have cost me 202,680 input tokens, 10,460 output tokens and 1,859 thinking tokens for a total of 62.989 cents.
As a fun extra, the new issue: feature itself was written almost entirely by OpenAI o3, again using fragments. I ran this:
llm -m openai/o3 \ -f https://raw.githubusercontent.com/simonw/llm-hacker-news/refs/heads/main/llm_hacker_news.py \ -f https://raw.githubusercontent.com/simonw/tools/refs/heads/main/github-issue-to-markdown.html \ -s 'Write a new fragments plugin in Python that registers issue:org/repo/123 which fetches that issue number from the specified github repo and uses the same markdown logic as the HTML page to turn that into a fragment'
Here I'm using the ability to pass a URL to -f and giving it the full source of my llm_hacker_news.py plugin (which shows how a fragment can load data from an API) plus the HTML source of my github-issue-to-markdown tool (which I wrote a few months ago with Claude). I effectively asked o3 to take that HTML/JavaScript tool and port it to Python to work with my fragments plugin mechanism.
o3 provided almost the exact implementation I needed, and even included support for a GITHUB_TOKEN environment variable without me thinking to ask for it. Total cost: 19.928 cents.
On a final note of curiosity I tried running this prompt against Gemma 3 27B QAT running on my Mac via MLX and llm-mlx:
llm install llm-mlx llm mlx download-model mlx-community/gemma-3-27b-it-qat-4bit llm -m mlx-community/gemma-3-27b-it-qat-4bit \ -f https://raw.githubusercontent.com/simonw/llm-hacker-news/refs/heads/main/llm_hacker_news.py \ -f https://raw.githubusercontent.com/simonw/tools/refs/heads/main/github-issue-to-markdown.html \ -s 'Write a new fragments plugin in Python that registers issue:org/repo/123 which fetches that issue number from the specified github repo and uses the same markdown logic as the HTML page to turn that into a fragment'
That worked pretty well too. It turns out a 16GB local model file is powerful enough to write me an LLM plugin now!
Gemma 3 QAT Models. Interesting release from Google, as a follow-up to Gemma 3 from last month:
To make Gemma 3 even more accessible, we are announcing new versions optimized with Quantization-Aware Training (QAT) that dramatically reduces memory requirements while maintaining high quality. This enables you to run powerful models like Gemma 3 27B locally on consumer-grade GPUs like the NVIDIA RTX 3090.
I wasn't previously aware of Quantization-Aware Training but it turns out to be quite an established pattern now, supported in both Tensorflow and PyTorch.
Google report model size drops from BF16 to int4 for the following models:
- Gemma 3 27B: 54GB to 14.1GB
- Gemma 3 12B: 24GB to 6.6GB
- Gemma 3 4B: 8GB to 2.6GB
- Gemma 3 1B: 2GB to 0.5GB
They partnered with Ollama, LM Studio, MLX (here's their collection) and llama.cpp for this release - I'd love to see more AI labs following their example.
The Ollama model version picker currently hides them behind "View all" option, so here are the direct links:
- gemma3:1b-it-qat - 1GB
- gemma3:4b-it-qat - 4GB
- gemma3:12b-it-qat - 8.9GB
- gemma3:27b-it-qat - 18GB
I fetched that largest model with:
ollama pull gemma3:27b-it-qat
And now I'm trying it out with llm-ollama:
llm -m gemma3:27b-it-qat "impress me with some physics"
I got a pretty great response!
Update: Having spent a while putting it through its paces via Open WebUI and Tailscale to access my laptop from my phone I think this may be my new favorite general-purpose local model. Ollama appears to use 22GB of RAM while the model is running, which leaves plenty on my 64GB machine for other applications.
I've also tried it via llm-mlx like this (downloading 16GB):
llm install llm-mlx
llm mlx download-model mlx-community/gemma-3-27b-it-qat-4bit
llm chat -m mlx-community/gemma-3-27b-it-qat-4bit
It feels a little faster with MLX and uses 15GB of memory according to Activity Monitor.
Start building with Gemini 2.5 Flash
(via)
Google Gemini's latest model is Gemini 2.5 Flash, available in (paid) preview as gemini-2.5-flash-preview-04-17.
Building upon the popular foundation of 2.0 Flash, this new version delivers a major upgrade in reasoning capabilities, while still prioritizing speed and cost. Gemini 2.5 Flash is our first fully hybrid reasoning model, giving developers the ability to turn thinking on or off. The model also allows developers to set thinking budgets to find the right tradeoff between quality, cost, and latency.
Gemini AI Studio product lead Logan Kilpatrick says:
This is an early version of 2.5 Flash, but it already shows huge gains over 2.0 Flash.
You can fully turn off thinking if needed and use this model as a drop in replacement for 2.0 Flash.
I added support to the new model in llm-gemini 0.18. Here's how to try it out:
llm install -U llm-gemini
llm -m gemini-2.5-flash-preview-04-17 'Generate an SVG of a pelican riding a bicycle'
Here's that first pelican, using the default setting where Gemini Flash 2.5 makes its own decision in terms of how much "thinking" effort to apply:

Here's the transcript. This one used 11 input tokens, 4,266 output tokens and 2,702 "thinking" tokens.
I asked the model to "describe" that image and it could tell it was meant to be a pelican:
A simple illustration on a white background shows a stylized pelican riding a bicycle. The pelican is predominantly grey with a black eye and a prominent pink beak pouch. It is positioned on a black line-drawn bicycle with two wheels, a frame, handlebars, and pedals.
The way the model is priced is a little complicated. If you have thinking enabled, you get charged $0.15/million tokens for input and $3.50/million for output. With thinking disabled those output tokens drop to $0.60/million. I've added these to my pricing calculator.
For comparison, Gemini 2.0 Flash is $0.10/million input and $0.40/million for output.
So my first prompt - 11 input and 4,266+2,702 =6,968 output (with thinking enabled), cost 2.439 cents.
Let's try 2.5 Flash again with thinking disabled:
llm -m gemini-2.5-flash-preview-04-17 'Generate an SVG of a pelican riding a bicycle' -o thinking_budget 0

11 input, 1705 output. That's 0.1025 cents. Transcript here - it still shows 25 thinking tokens even though I set the thinking budget to 0 - Logan confirms that this will still be billed at the lower rate:
In some rare cases, the model still thinks a little even with thinking budget = 0, we are hoping to fix this before we make this model stable and you won't be billed for thinking. The thinking budget = 0 is what triggers the billing switch.
Here's Gemini 2.5 Flash's self-description of that image:
A minimalist illustration shows a bright yellow bird riding a bicycle. The bird has a simple round body, small wings, a black eye, and an open orange beak. It sits atop a simple black bicycle frame with two large circular black wheels. The bicycle also has black handlebars and black and yellow pedals. The scene is set against a solid light blue background with a thick green stripe along the bottom, suggesting grass or ground.
And finally, let's ramp the thinking budget up to the maximum:
llm -m gemini-2.5-flash-preview-04-17 'Generate an SVG of a pelican riding a bicycle' -o thinking_budget 24576
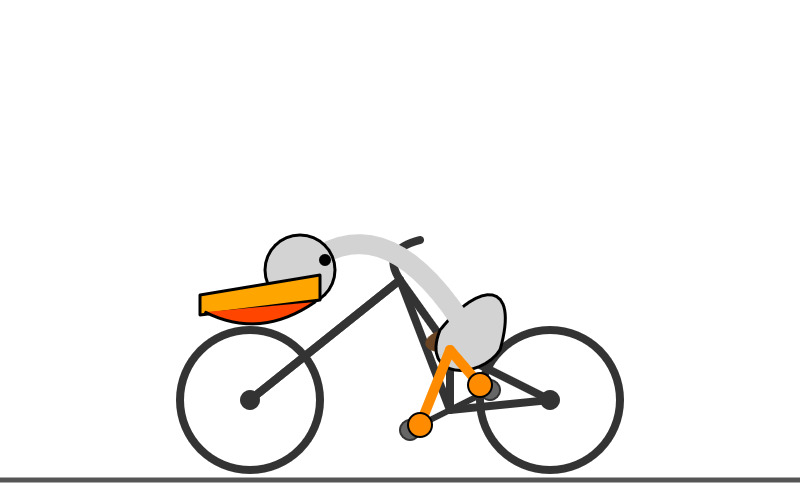
I think it over-thought this one. Transcript - 5,174 output tokens and 3,023 thinking tokens. A hefty 2.8691 cents!
A simple, cartoon-style drawing shows a bird-like figure riding a bicycle. The figure has a round gray head with a black eye and a large, flat orange beak with a yellow stripe on top. Its body is represented by a curved light gray shape extending from the head to a smaller gray shape representing the torso or rear. It has simple orange stick legs with round feet or connections at the pedals. The figure is bent forward over the handlebars in a cycling position. The bicycle is drawn with thick black outlines and has two large wheels, a frame, and pedals connected to the orange legs. The background is plain white, with a dark gray line at the bottom representing the ground.
One thing I really appreciate about Gemini 2.5 Flash's approach to SVGs is that it shows very good taste in CSS, comments and general SVG class structure. Here's a truncated extract - I run a lot of these SVG tests against different models and this one has a coding style that I particularly enjoy. (Gemini 2.5 Pro does this too).
<svg width="800" height="500" viewBox="0 0 800 500" xmlns="http://www.w3.org/2000/svg"> <style> .bike-frame { fill: none; stroke: #333; stroke-width: 8; stroke-linecap: round; stroke-linejoin: round; } .wheel-rim { fill: none; stroke: #333; stroke-width: 8; } .wheel-hub { fill: #333; } /* ... */ .pelican-body { fill: #d3d3d3; stroke: black; stroke-width: 3; } .pelican-head { fill: #d3d3d3; stroke: black; stroke-width: 3; } /* ... */ </style> <!-- Ground Line --> <line x1="0" y1="480" x2="800" y2="480" stroke="#555" stroke-width="5"/> <!-- Bicycle --> <g id="bicycle"> <!-- Wheels --> <circle class="wheel-rim" cx="250" cy="400" r="70"/> <circle class="wheel-hub" cx="250" cy="400" r="10"/> <circle class="wheel-rim" cx="550" cy="400" r="70"/> <circle class="wheel-hub" cx="550" cy="400" r="10"/> <!-- ... --> </g> <!-- Pelican --> <g id="pelican"> <!-- Body --> <path class="pelican-body" d="M 440 330 C 480 280 520 280 500 350 C 480 380 420 380 440 330 Z"/> <!-- Neck --> <path class="pelican-neck" d="M 460 320 Q 380 200 300 270"/> <!-- Head --> <circle class="pelican-head" cx="300" cy="270" r="35"/> <!-- ... -->
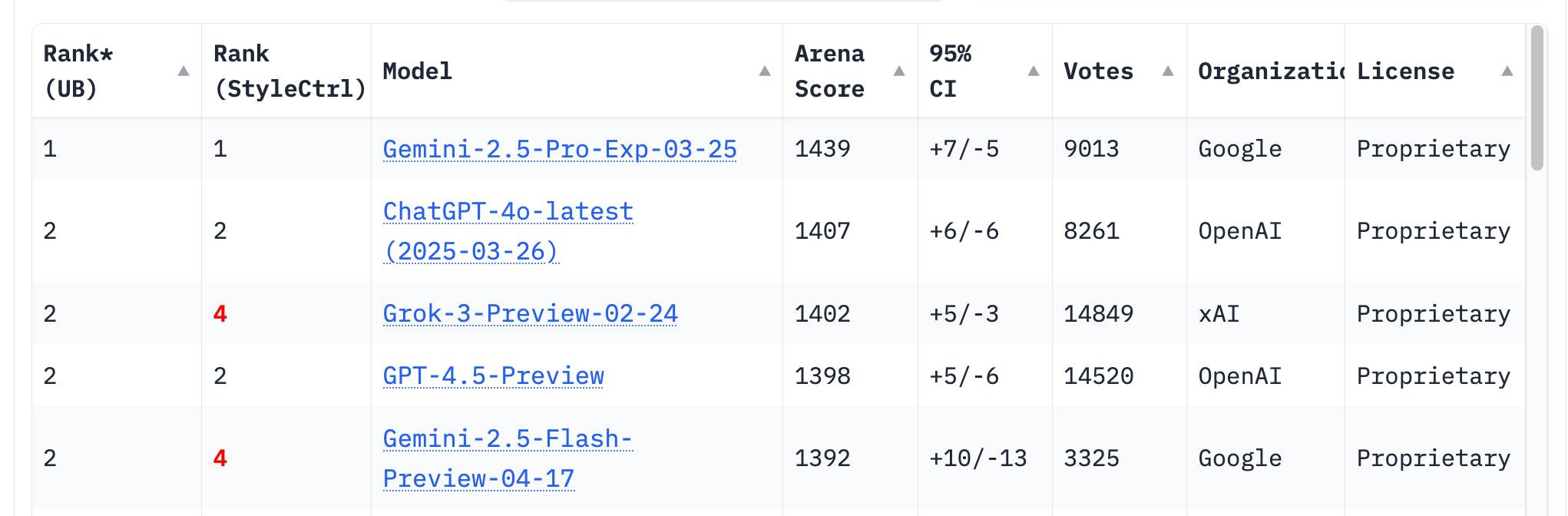
The LM Arena leaderboard now has Gemini 2.5 Flash in joint second place, just behind Gemini 2.5 Pro and tied with ChatGPT-4o-latest, Grok-3 and GPT-4.5 Preview.
Introducing OpenAI o3 and o4-mini. OpenAI are really emphasizing tool use with these:
For the first time, our reasoning models can agentically use and combine every tool within ChatGPT—this includes searching the web, analyzing uploaded files and other data with Python, reasoning deeply about visual inputs, and even generating images. Critically, these models are trained to reason about when and how to use tools to produce detailed and thoughtful answers in the right output formats, typically in under a minute, to solve more complex problems.
I released llm-openai-plugin 0.3 adding support for the two new models:
llm install -U llm-openai-plugin
llm -m openai/o3 "say hi in five languages"
llm -m openai/o4-mini "say hi in five languages"
Here are the pelicans riding bicycles (prompt: Generate an SVG of a pelican riding a bicycle).
o3:
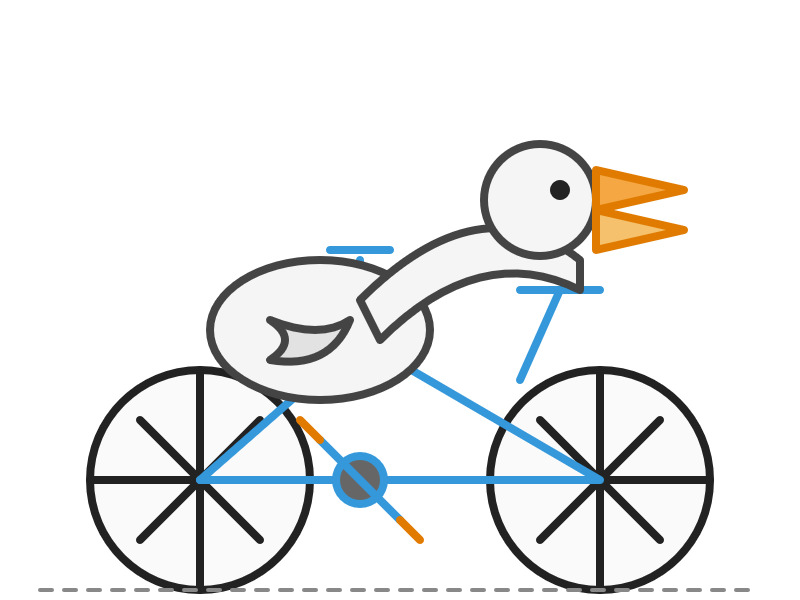
o4-mini:

Here are the full OpenAI model listings: o3 is $10/million input and $40/million for output, with a 75% discount on cached input tokens, 200,000 token context window, 100,000 max output tokens and a May 31st 2024 training cut-off (same as the GPT-4.1 models). It's a bit cheaper than o1 ($15/$60) and a lot cheaper than o1-pro ($150/$600).
o4-mini is priced the same as o3-mini: $1.10/million for input and $4.40/million for output, also with a 75% input caching discount. The size limits and training cut-off are the same as o3.
You can compare these prices with other models using the table on my updated LLM pricing calculator.
A new capability released today is that the OpenAI API can now optionally return reasoning summary text. I've been exploring that in this issue. I believe you have to verify your organization (which may involve a photo ID) in order to use this option - once you have access the easiest way to see the new tokens is using curl like this:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o3",
"input": "why is the sky blue?",
"reasoning": {"summary": "auto"},
"stream": true
}'
This produces a stream of events that includes this new event type:
event: response.reasoning_summary_text.delta
data: {"type": "response.reasoning_summary_text.delta","item_id": "rs_68004320496081918e1e75ddb550d56e0e9a94ce520f0206","output_index": 0,"summary_index": 0,"delta": "**Expl"}
Omit the "stream": true and the response is easier to read and contains this:
{
"output": [
{
"id": "rs_68004edd2150819183789a867a9de671069bc0c439268c95",
"type": "reasoning",
"summary": [
{
"type": "summary_text",
"text": "**Explaining the blue sky**\n\nThe user asks a classic question about why the sky is blue. I'll talk about Rayleigh scattering, where shorter wavelengths of light scatter more than longer ones. This explains how we see blue light spread across the sky! I wonder if the user wants a more scientific or simpler everyday explanation. I'll aim for a straightforward response while keeping it engaging and informative. So, let's break it down!"
}
]
},
{
"id": "msg_68004edf9f5c819188a71a2c40fb9265069bc0c439268c95",
"type": "message",
"status": "completed",
"content": [
{
"type": "output_text",
"annotations": [],
"text": "The short answer ..."
}
]
}
]
}
llm-fragments-rust
(via)
Inspired by Filippo Valsorda's llm-fragments-go, Francois Garillot created llm-fragments-rust, an LLM fragments plugin that lets you pull documentation for any Rust crate directly into a prompt to LLM.
I really like this example, which uses two fragments to load documentation for two crates at once:
llm -f rust:rand@0.8.5 -f rust:tokio "How do I generate random numbers asynchronously?"
The code uses some neat tricks: it creates a new Rust project in a temporary directory (similar to how llm-fragments-go works), adds the crates and uses cargo doc --no-deps --document-private-items to generate documentation. Then it runs cargo tree --edges features to add dependency information, and cargo metadata --format-version=1 to include additional metadata about the crate.