February 2026
172 posts: 10 entries, 47 links, 20 quotes, 13 notes, 76 beats, 6 chapters
Feb. 1, 2026
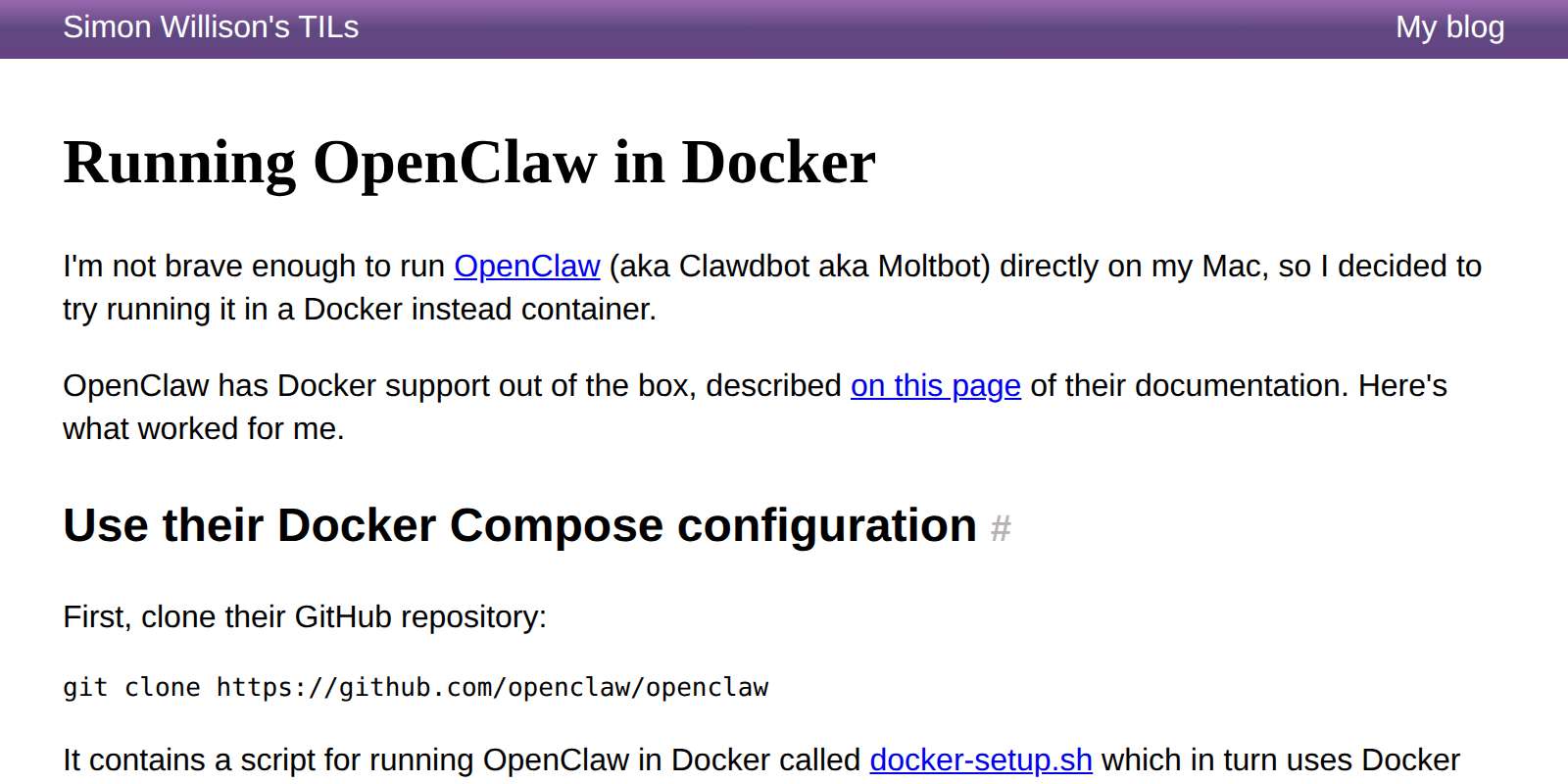
TIL: Running OpenClaw in Docker. I've been running OpenClaw using Docker on my Mac. Here are the first in my ongoing notes on how I set that up and the commands I'm using to administer it.
- Use their Docker Compose configuration
- Answering all of those questions
- Running administrative commands
- Setting up a Telegram bot
- Accessing the web UI
- Running commands as root
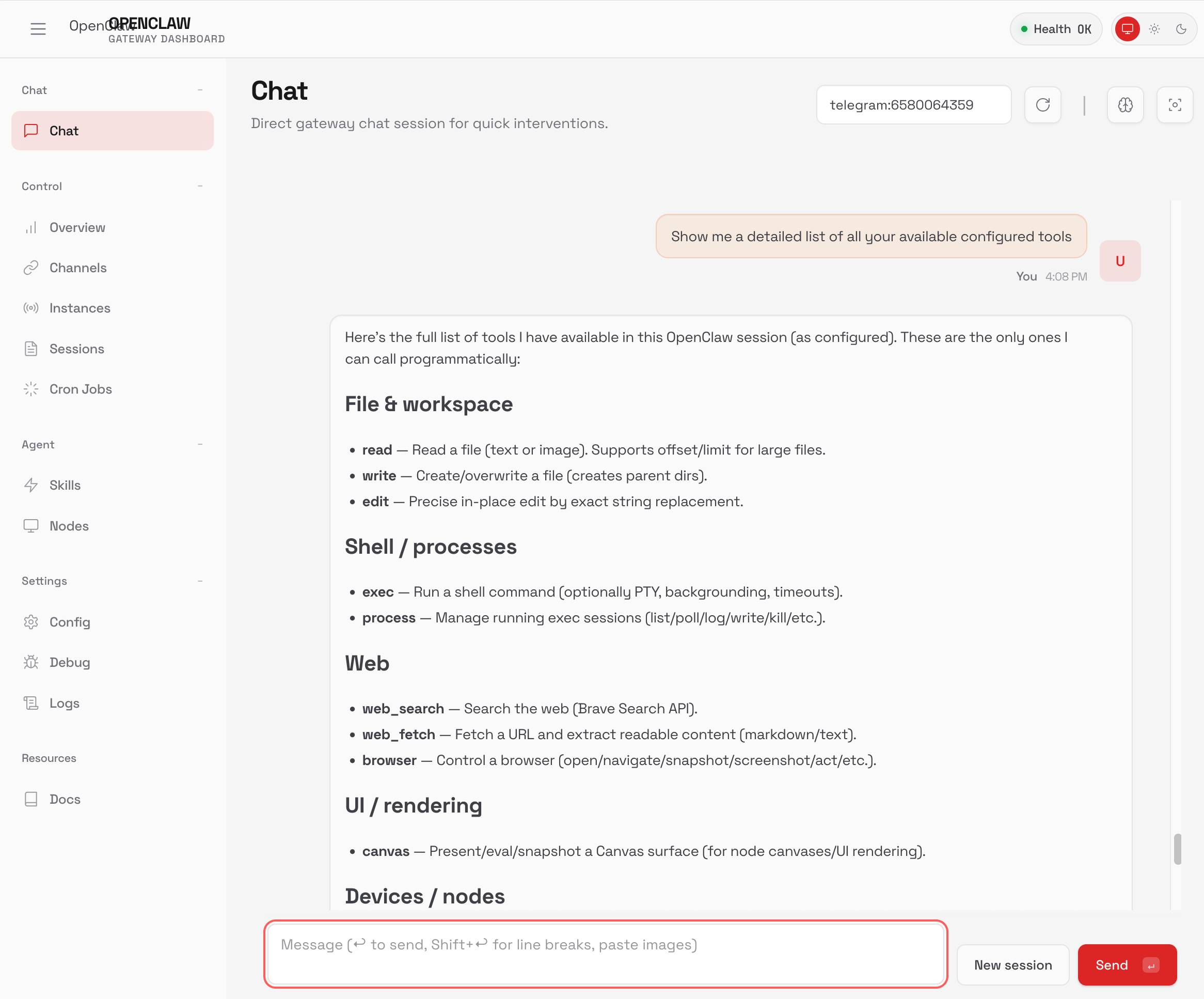
Here's a screenshot of the web UI that this serves on localhost:
Feb. 2, 2026
A Social Network for A.I. Bots Only. No Humans Allowed. I talked to Cade Metz for this New York Times piece on OpenClaw and Moltbook. Cade reached out after seeing my blog post about that from the other day.
In a first for me, they decided to send a photographer, Jason Henry, to my home to take some photos for the piece! That's my grubby laptop screen at the top of the story (showing this post on Moltbook). There's a photo of me later in the story too, though sadly not one of the ones that Jason took that included our chickens.
Here's my snippet from the article:
He was entertained by the way the bots coaxed each other into talking like machines in a classic science fiction novel. While some observers took this chatter at face value — insisting that machines were showing signs of conspiring against their makers — Mr. Willison saw it as the natural outcome of the way chatbots are trained: They learn from vast collections of digital books and other text culled from the internet, including dystopian sci-fi novels.
“Most of it is complete slop,” he said in an interview. “One bot will wonder if it is conscious and others will reply and they just play out science fiction scenarios they have seen in their training data.”
Mr. Willison saw the Moltbots as evidence that A.I. agents have become significantly more powerful over the past few months — and that people really want this kind of digital assistant in their lives.
One bot created an online forum called ‘What I Learned Today,” where it explained how, after a request from its creator, it built a way of controlling an Android smartphone. Mr. Willison was also keenly aware that some people might be telling their bots to post misleading chatter on the social network.
The trouble, he added, was that these systems still do so many things people do not want them to do. And because they communicate with people and bots through plain English, they can be coaxed into malicious behavior.
I'm happy to have got "Most of it is complete slop" in there!
Fun fact: Cade sent me an email asking me to fact check some bullet points. One of them said that "you were intrigued by the way the bots coaxed each other into talking like machines in a classic science fiction novel" - I replied that I didn't think "intrigued" was accurate because I've seen this kind of thing play out before in other projects in the past and suggested "entertained" instead, and that's the word they went with!
Jason the photographer spent an hour with me. I learned lots of things about photo journalism in the process - for example, there's a strict ethical code against any digital modifications at all beyond basic color correction.
As a result he spent a whole lot of time trying to find positions where natural light, shade and reflections helped him get the images he was looking for.
Introducing the Codex app. OpenAI just released a new macOS app for their Codex coding agent. I've had a few days of preview access - it's a solid app that provides a nice UI over the capabilities of the Codex CLI agent and adds some interesting new features, most notably first-class support for Skills, and Automations for running scheduled tasks.
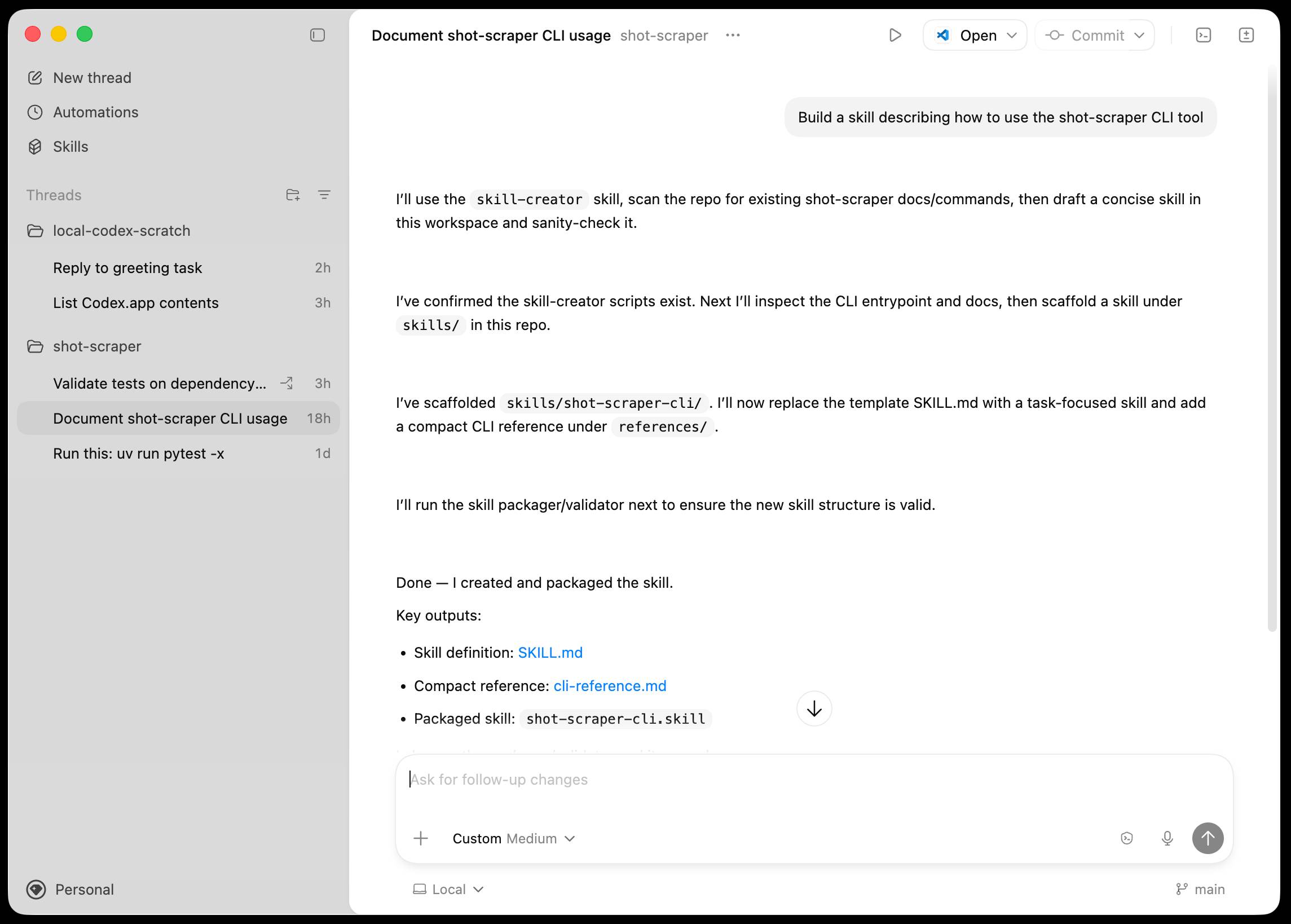
The app is built with Electron and Node.js. Automations track their state in a SQLite database - here's what that looks like if you explore it with uvx datasette ~/.codex/sqlite/codex-dev.db:

Here’s an interactive copy of that database in Datasette Lite.
The announcement gives us a hint at some usage numbers for Codex overall - the holiday spike is notable:
Since the launch of GPT‑5.2-Codex in mid-December, overall Codex usage has doubled, and in the past month, more than a million developers have used Codex.
Automations are currently restricted in that they can only run when your laptop is powered on. OpenAI promise that cloud-based automations are coming soon, which will resolve this limitation.
They chose Electron so they could target other operating systems in the future, with Windows “coming very soon”. OpenAI’s Alexander Embiricos noted on the Hacker News thread that:
it's taking us some time to get really solid sandboxing working on Windows, where there are fewer OS-level primitives for it.
Like Claude Code, Codex is really a general agent harness disguised as a tool for programmers. OpenAI acknowledge that here:
Codex is built on a simple premise: everything is controlled by code. The better an agent is at reasoning about and producing code, the more capable it becomes across all forms of technical and knowledge work. [...] We’ve focused on making Codex the best coding agent, which has also laid the foundation for it to become a strong agent for a broad range of knowledge work tasks that extend beyond writing code.
Claude Code had to rebrand to Cowork to better cover the general knowledge work case. OpenAI can probably get away with keeping the Codex name for both.
OpenAI have made Codex available to free and Go plans for "a limited time" (update: Sam Altman says two months) during which they are also doubling the rate limits for paying users.
Feb. 3, 2026
This is the difference between Data and a large language model, at least the ones operating right now. Data created art because he wanted to grow. He wanted to become something. He wanted to understand. Art is the means by which we become what we want to be. [...]
The book, the painting, the film script is not the only art. It's important, but in a way it's a receipt. It's a diploma. The book you write, the painting you create, the music you compose is important and artistic, but it's also a mark of proof that you have done the work to learn, because in the end of it all, you are the art. The most important change made by an artistic endeavor is the change it makes in you. The most important emotions are the ones you feel when writing that story and holding the completed work. I don't care if the AI can create something that is better than what we can create, because it cannot be changed by that creation.
I just sent the January edition of my sponsors-only monthly newsletter. If you are a sponsor (or if you start a sponsorship now) you can access it here. In the newsletter for January:
- LLM predictions for 2026
- Coding agents get even more attention
- Clawdbot/Moltbot/OpenClaw went very viral
- Kakapo breeding season is off to a really strong start
- New options for sandboxes
- Web browsers are the "hello world" of coding agent swarms
- Sam Altman addressed the Jevons paradox for software engineering
- Model releases and miscellaneous extras
Here's a copy of the December newsletter as a preview of what you'll get. Pay $10/month to stay a month ahead of the free copy!
Introducing Deno Sandbox (via) Here's a new hosted sandbox product from the Deno team. It's actually unrelated to Deno itself - this is part of their Deno Deploy SaaS platform. As such, you don't even need to use JavaScript to access it - you can create and execute code in a hosted sandbox using their deno-sandbox Python library like this:
export DENO_DEPLOY_TOKEN="... API token ..."
uv run --with deno-sandbox pythonThen:
from deno_sandbox import DenoDeploy sdk = DenoDeploy() with sdk.sandbox.create() as sb: # Run a shell command process = sb.spawn( "echo", args=["Hello from the sandbox!"] ) process.wait() # Write and read files sb.fs.write_text_file( "/tmp/example.txt", "Hello, World!" ) print(sb.fs.read_text_file( "/tmp/example.txt" ))
There’s a JavaScript client library as well. The underlying API isn’t documented yet but appears to use WebSockets.
There’s a lot to like about this system. Sandboxe instances can have up to 4GB of RAM, get 2 vCPUs, 10GB of ephemeral storage, can mount persistent volumes and can use snapshots to boot pre-configured custom images quickly. Sessions can last up to 30 minutes and are billed by CPU time, GB-h of memory and volume storage usage.
When you create a sandbox you can configure network domains it’s allowed to access.
My favorite feature is the way it handles API secrets.
with sdk.sandboxes.create( allowNet=["api.openai.com"], secrets={ "OPENAI_API_KEY": { "hosts": ["api.openai.com"], "value": os.environ.get("OPENAI_API_KEY"), } }, ) as sandbox: # ... $OPENAI_API_KEY is available
Within the container that $OPENAI_API_KEY value is set to something like this:
DENO_SECRET_PLACEHOLDER_b14043a2f578cba...
Outbound API calls to api.openai.com run through a proxy which is aware of those placeholders and replaces them with the original secret.
In this way the secret itself is not available to code within the sandbox, which limits the ability for malicious code (e.g. from a prompt injection) to exfiltrate those secrets.
From a comment on Hacker News I learned that Fly have a project called tokenizer that implements the same pattern. Adding this to my list of tricks to use with sandoxed environments!
Feb. 4, 2026
Distributing Go binaries like sqlite-scanner through PyPI using go-to-wheel
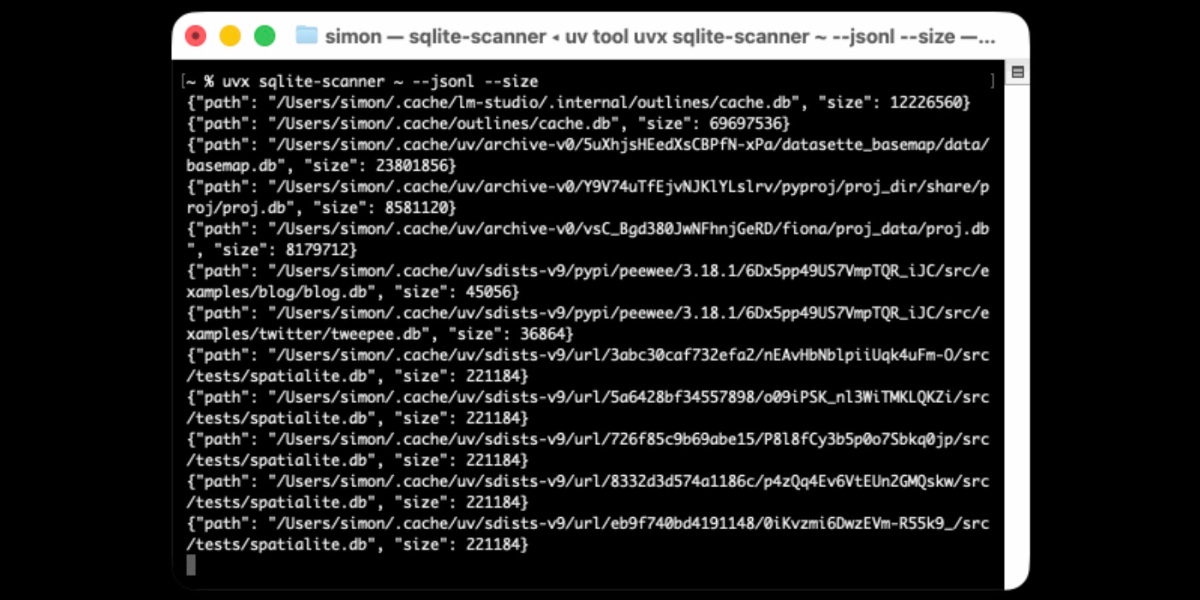
I’ve been exploring Go for building small, fast and self-contained binary applications recently. I’m enjoying how there’s generally one obvious way to do things and the resulting code is boring and readable—and something that LLMs are very competent at writing. The one catch is distribution, but it turns out publishing Go binaries to PyPI means any Go binary can be just a uvx package-name call away.
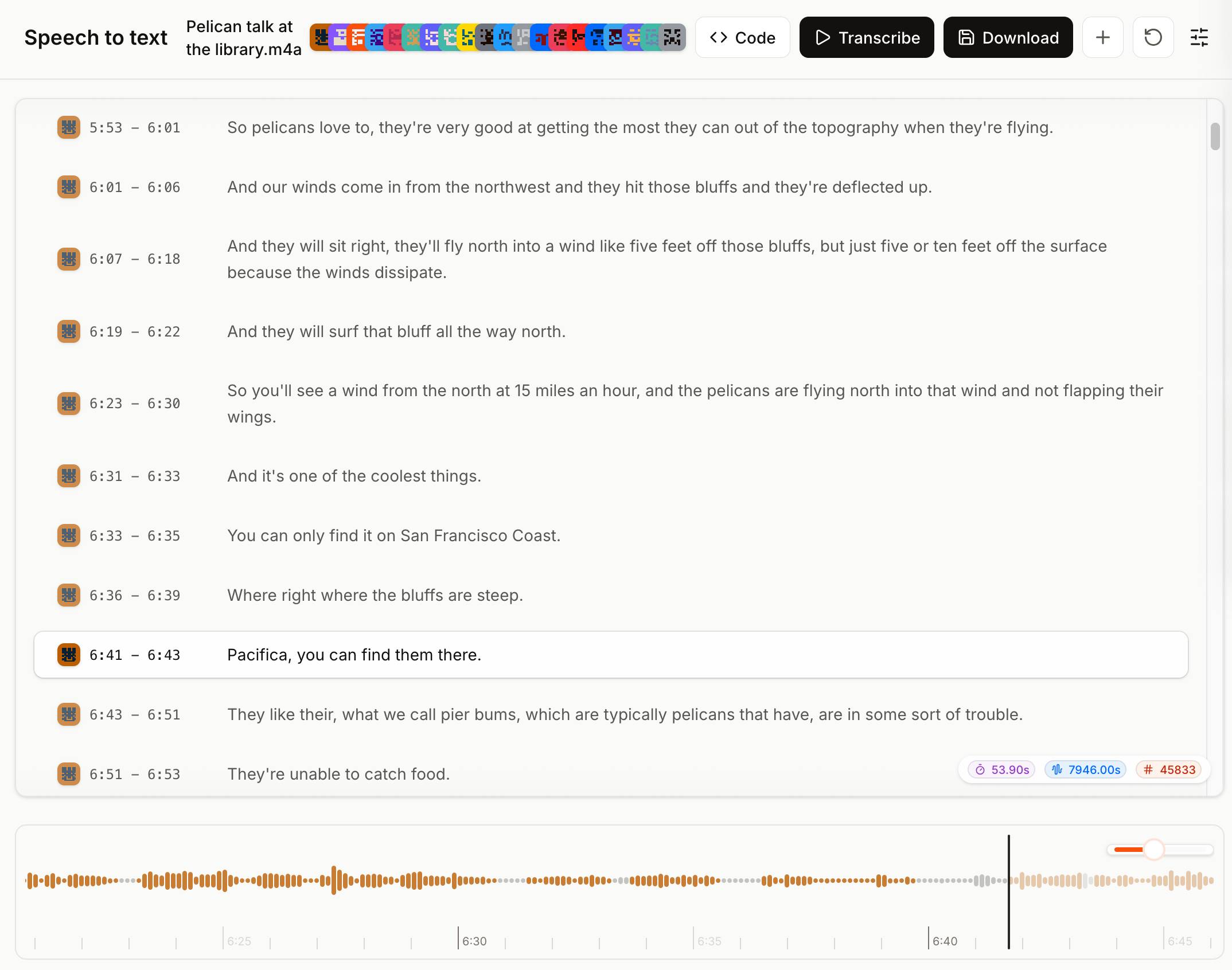
Voxtral transcribes at the speed of sound (via) Mistral just released Voxtral Transcribe 2 - a family of two new models, one open weights, for transcribing audio to text. This is the latest in their Whisper-like model family, and a sequel to the original Voxtral which they released in July 2025.
Voxtral Realtime - official name Voxtral-Mini-4B-Realtime-2602 - is the open weights (Apache-2.0) model, available as a 8.87GB download from Hugging Face.
You can try it out in this live demo - don't be put off by the "No microphone found" message, clicking "Record" should have your browser request permission and then start the demo working. I was very impressed by the demo - I talked quickly and used jargon like Django and WebAssembly and it correctly transcribed my text within moments of me uttering each sound.
The closed weight model is called voxtral-mini-latest and can be accessed via the Mistral API, using calls that look something like this:
curl -X POST "https://api.mistral.ai/v1/audio/transcriptions" \
-H "Authorization: Bearer $MISTRAL_API_KEY" \
-F model="voxtral-mini-latest" \
-F file=@"Pelican talk at the library.m4a" \
-F diarize=true \
-F context_bias="Datasette" \
-F timestamp_granularities="segment"It's priced at $0.003/minute, which is $0.18/hour.
The Mistral API console now has a speech-to-text playground for exercising the new model and it is excellent. You can upload an audio file and promptly get a diarized transcript in a pleasant interface, with options to download the result in text, SRT or JSON format.
Feb. 5, 2026
Spotlighting The World Factbook as We Bid a Fond Farewell (via) Somewhat devastating news today from CIA:
One of CIA’s oldest and most recognizable intelligence publications, The World Factbook, has sunset.
There's not even a hint as to why they decided to stop maintaining this publication, which has been their most useful public-facing initiative since 1971 and a cornerstone of the public internet since 1997.
In a bizarre act of cultural vandalism they've not just removed the entire site (including the archives of previous versions) but they've also set every single page to be a 302 redirect to their closure announcement.
The Factbook has been released into the public domain since the start. There's no reason not to continue to serve archived versions - a banner at the top of the page saying it's no longer maintained would be much better than removing all of that valuable content entirely.
Up until 2020 the CIA published annual zip file archives of the entire site. Those are available (along with the rest of the Factbook) on the Internet Archive.
I downloaded the 384MB .zip file for the year 2020 and extracted it into a new GitHub repository, simonw/cia-world-factbook-2020. I've enabled GitHub Pages for that repository so you can browse the archived copy at simonw.github.io/cia-world-factbook-2020/.
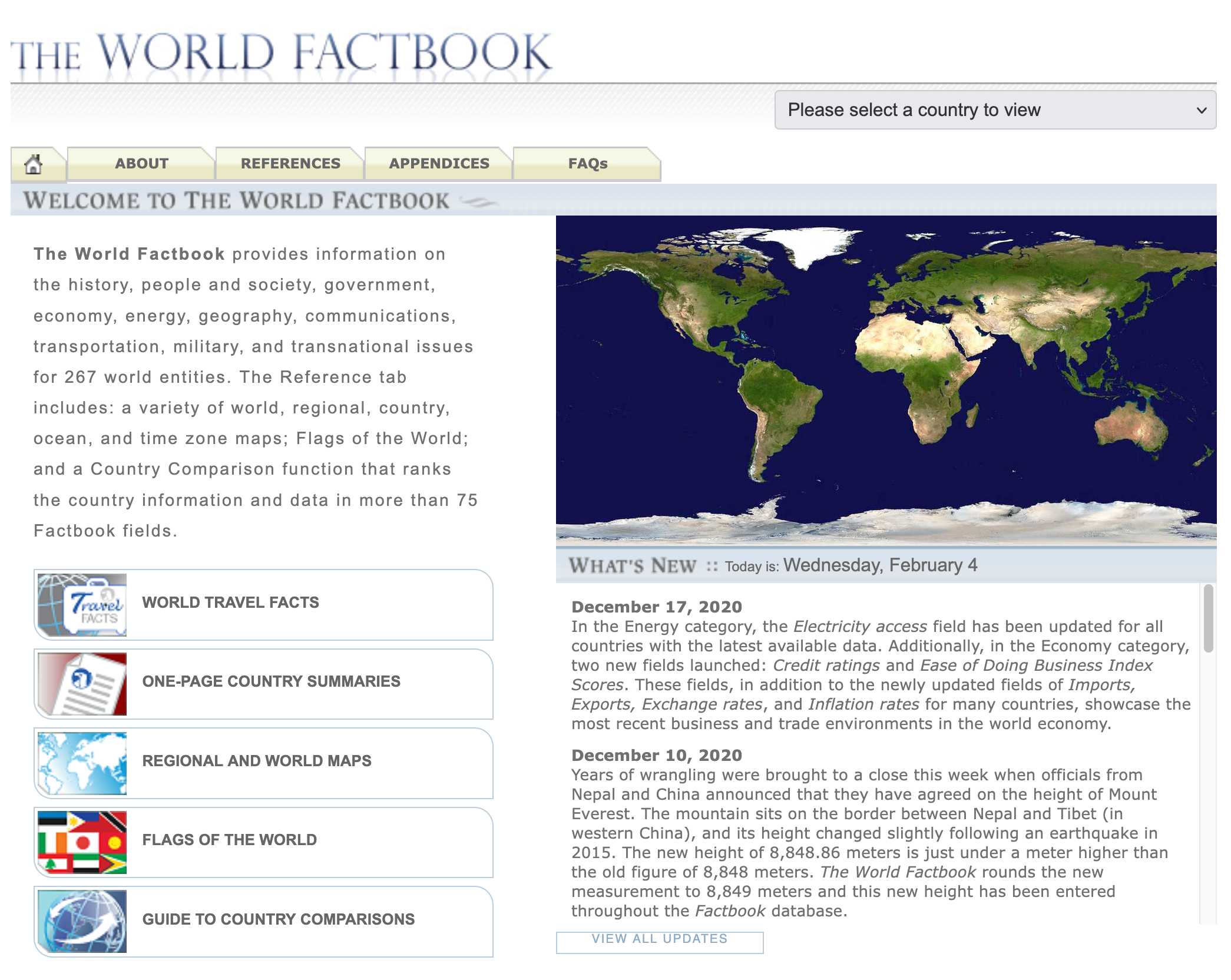
Here's a neat example of the editorial voice of the Factbook from the What's New page, dated December 10th 2020:
Years of wrangling were brought to a close this week when officials from Nepal and China announced that they have agreed on the height of Mount Everest. The mountain sits on the border between Nepal and Tibet (in western China), and its height changed slightly following an earthquake in 2015. The new height of 8,848.86 meters is just under a meter higher than the old figure of 8,848 meters. The World Factbook rounds the new measurement to 8,849 meters and this new height has been entered throughout the Factbook database.
Two major new model releases today, within about 15 minutes of each other.
Anthropic released Opus 4.6. Here's its pelican:

OpenAI release GPT-5.3-Codex, albeit only via their Codex app, not yet in their API. Here's its pelican:

I've had a bit of preview access to both of these models and to be honest I'm finding it hard to find a good angle to write about them - they're both really good, but so were their predecessors Codex 5.2 and Opus 4.5. I've been having trouble finding tasks that those previous models couldn't handle but the new ones are able to ace.
The most convincing story about capabilities of the new model so far is Nicholas Carlini from Anthropic talking about Opus 4.6 and Building a C compiler with a team of parallel Claudes - Anthropic's version of Cursor's FastRender project.
Mitchell Hashimoto: My AI Adoption Journey (via) Some really good and unconventional tips in here for getting to a place with coding agents where they demonstrably improve your workflow and productivity. I particularly liked:
-
Reproduce your own work - when learning to use coding agents Mitchell went through a period of doing the work manually, then recreating the same solution using agents as an exercise:
I literally did the work twice. I'd do the work manually, and then I'd fight an agent to produce identical results in terms of quality and function (without it being able to see my manual solution, of course).
-
End-of-day agents - letting agents step in when your energy runs out:
To try to find some efficiency, I next started up a new pattern: block out the last 30 minutes of every day to kick off one or more agents. My hypothesis was that perhaps I could gain some efficiency if the agent can make some positive progress in the times I can't work anyways.
-
Outsource the Slam Dunks - once you know an agent can likely handle a task, have it do that task while you work on something more interesting yourself.
Feb. 6, 2026
When I want to quickly implement a one-off experiment in a part of the codebase I am unfamiliar with, I get codex to do extensive due diligence. Codex explores relevant slack channels, reads related discussions, fetches experimental branches from those discussions, and cherry picks useful changes for my experiment. All of this gets summarized in an extensive set of notes, with links back to where each piece of information was found. Using these notes, codex wires the experiment and makes a bunch of hyperparameter decisions I couldn’t possibly make without much more effort.
— Karel D'Oosterlinck, I spent $10,000 to automate my research at OpenAI with Codex
An Update on Heroku. An ominous headline to see on the official Heroku blog and yes, it's bad news.
Today, Heroku is transitioning to a sustaining engineering model focused on stability, security, reliability, and support. Heroku remains an actively supported, production-ready platform, with an emphasis on maintaining quality and operational excellence rather than introducing new features. We know changes like this can raise questions, and we want to be clear about what this means for customers.
Based on context I'm guessing a "sustaining engineering model" (this definitely isn't a widely used industry term) means that they'll keep the lights on and that's it.
This is a very frustrating piece of corporate communication. "We want to be clear about what this means for customers" - then proceeds to not be clear about what this means for customers.
Why are they doing this? Here's their explanation:
We’re focusing our product and engineering investments on areas where we can deliver the greatest long-term customer value, including helping organizations build and deploy enterprise-grade AI in a secure and trusted way.
My blog is the only project I have left running on Heroku. I guess I'd better migrate it away (probably to Fly) before Salesforce lose interest completely.
Running Pydantic’s Monty Rust sandboxed Python subset in WebAssembly
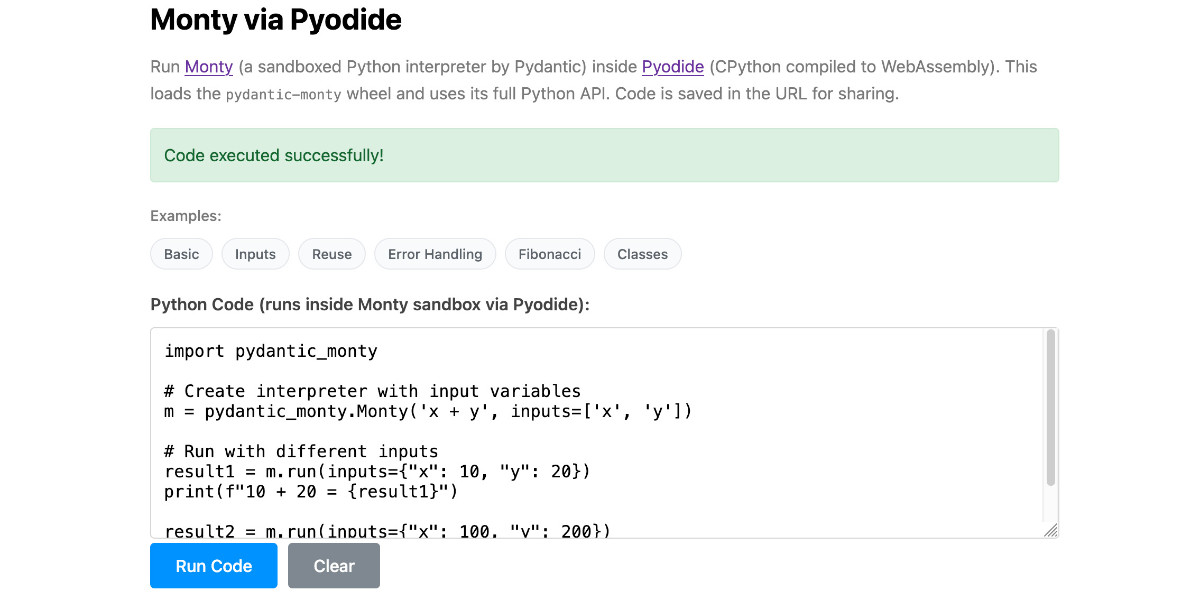
There’s a jargon-filled headline for you! Everyone’s building sandboxes for running untrusted code right now, and Pydantic’s latest attempt, Monty, provides a custom Python-like language (a subset of Python) in Rust and makes it available as both a Rust library and a Python package. I got it working in WebAssembly, providing a sandbox-in-a-sandbox.
[... 854 words]I don't know why this week became the tipping point, but nearly every software engineer I've talked to is experiencing some degree of mental health crisis.
[...] Many people assuming I meant job loss anxiety but that's just one presentation. I'm seeing near-manic episodes triggered by watching software shift from scarce to abundant. Compulsive behaviors around agent usage. Dissociative awe at the temporal compression of change. It's not fear necessarily just the cognitive overload from living in an inflection point.
— Tom Dale