Wednesday, 4th February 2026
Distributing Go binaries like sqlite-scanner through PyPI using go-to-wheel
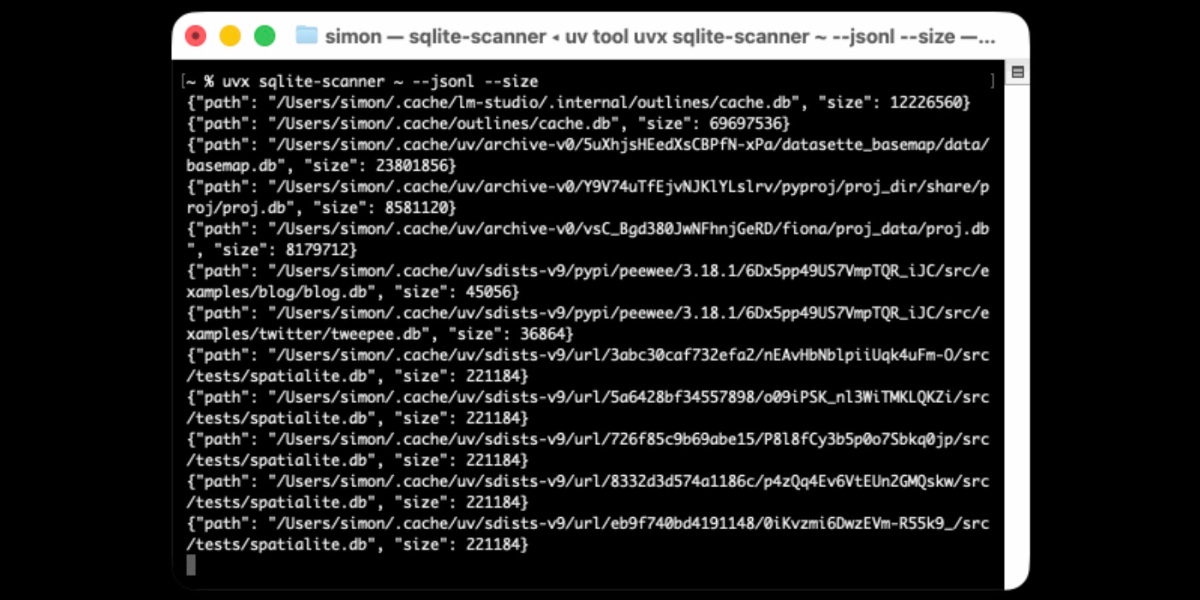
I’ve been exploring Go for building small, fast and self-contained binary applications recently. I’m enjoying how there’s generally one obvious way to do things and the resulting code is boring and readable—and something that LLMs are very competent at writing. The one catch is distribution, but it turns out publishing Go binaries to PyPI means any Go binary can be just a uvx package-name call away.
Voxtral transcribes at the speed of sound (via) Mistral just released Voxtral Transcribe 2 - a family of two new models, one open weights, for transcribing audio to text. This is the latest in their Whisper-like model family, and a sequel to the original Voxtral which they released in July 2025.
Voxtral Realtime - official name Voxtral-Mini-4B-Realtime-2602 - is the open weights (Apache-2.0) model, available as a 8.87GB download from Hugging Face.
You can try it out in this live demo - don't be put off by the "No microphone found" message, clicking "Record" should have your browser request permission and then start the demo working. I was very impressed by the demo - I talked quickly and used jargon like Django and WebAssembly and it correctly transcribed my text within moments of me uttering each sound.
The closed weight model is called voxtral-mini-latest and can be accessed via the Mistral API, using calls that look something like this:
curl -X POST "https://api.mistral.ai/v1/audio/transcriptions" \
-H "Authorization: Bearer $MISTRAL_API_KEY" \
-F model="voxtral-mini-latest" \
-F file=@"Pelican talk at the library.m4a" \
-F diarize=true \
-F context_bias="Datasette" \
-F timestamp_granularities="segment"It's priced at $0.003/minute, which is $0.18/hour.
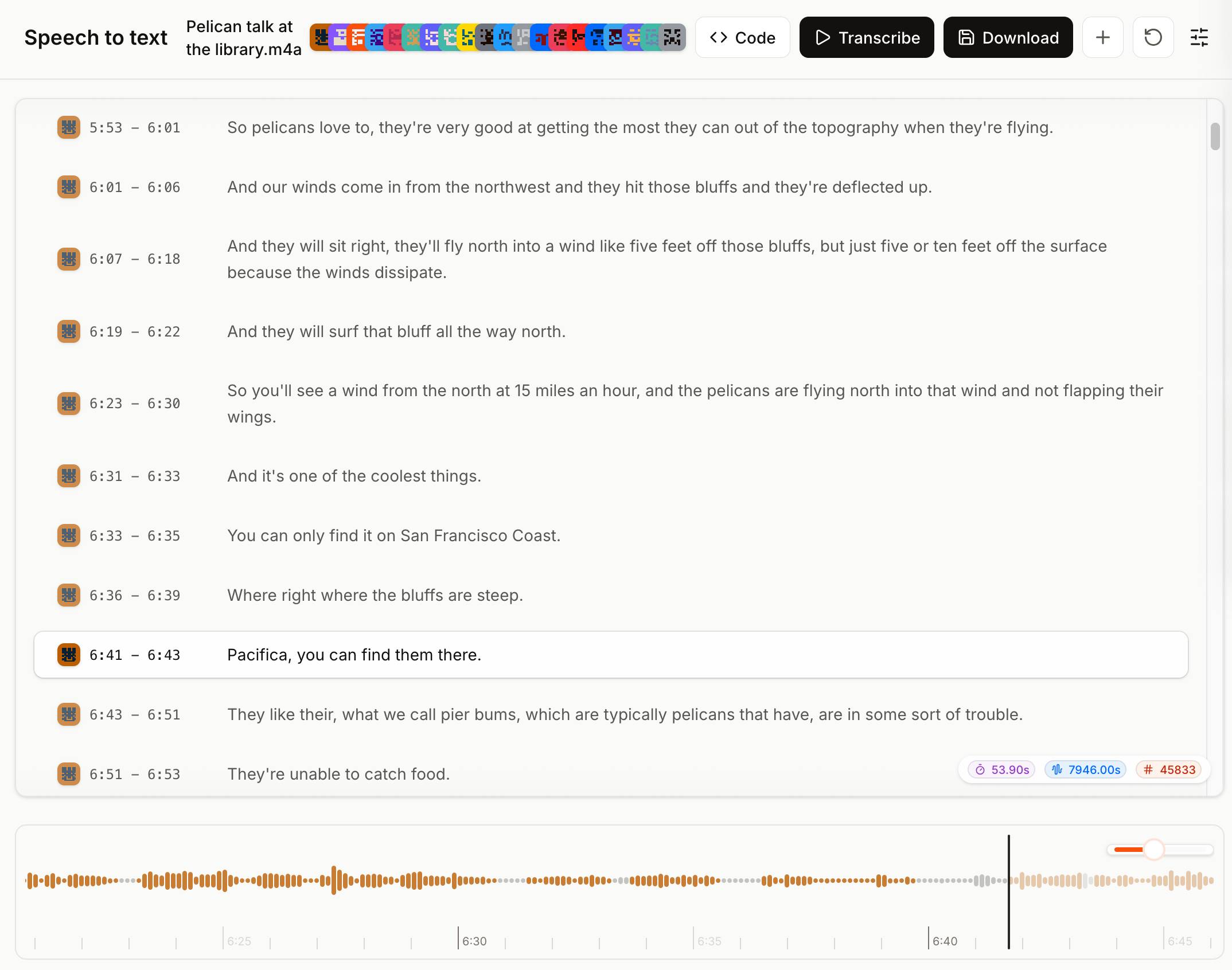
The Mistral API console now has a speech-to-text playground for exercising the new model and it is excellent. You can upload an audio file and promptly get a diarized transcript in a pleasant interface, with options to download the result in text, SRT or JSON format.