77 posts tagged “wikipedia”
2026
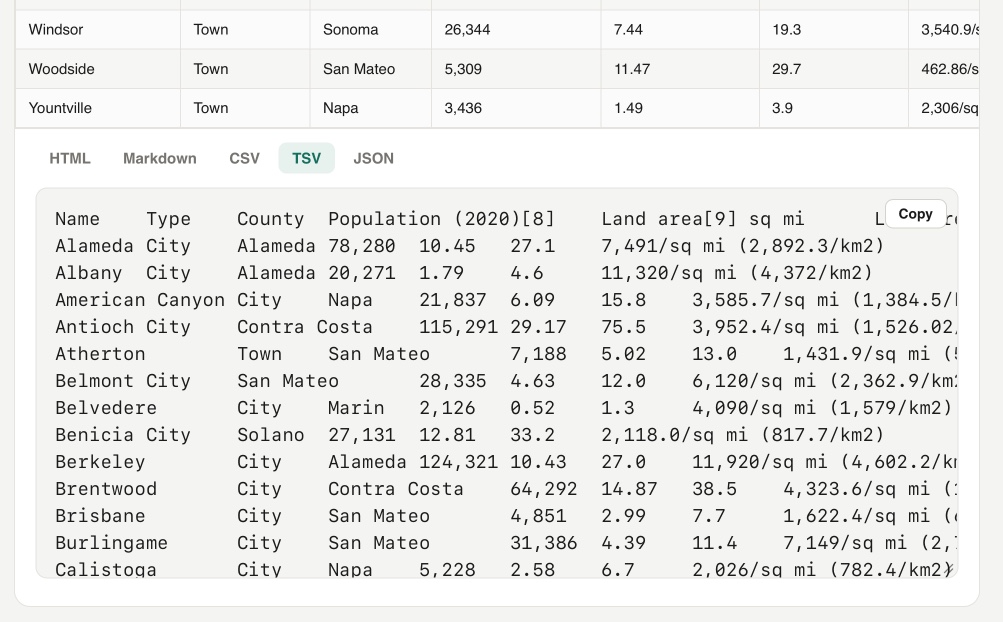
Yet another in my growing collection of paste-conversion tools. This one accepts pasted rich text from browsers (with embedded HTML tables) and converts every detected table into HTML, Markdown, CSV, TSV, or JSON.
Try it out by selecting everything on the Wikipedia List of cities and towns in the San Francisco Bay Area page and pasting it directly into the tool:
On a similar note, I recently rebuilt my Rich text to markdown tool to add support for tables and generally improve the UI.
Update: It turns out Wikipedia has an open CORS API for retrieving the full rendered HTML content of any page - demo here - so I had Codex add the ability to search Wikipedia for a page and then automatically import and display any tables from that page.
2025
Large language models (LLMs) can be useful tools, but they are not good at creating entirely new Wikipedia articles. Large language models should not be used to generate new Wikipedia articles from scratch.
— Wikipedia content guideline, promoted to a guideline on 24th November 2025
Re-label the “Save” button to be “Publish”, to better indicate to users the outcomes of their action (via) Fascinating Wikipedia usability improvement issue from 2016:
From feedback we get repeatedly as a development team from interviews, user testing and other solicited and unsolicited avenues, and by inspection from the number of edits by newbies not quite aware of the impact of their edits in terms of immediate broadcast and irrevocability, that new users don't necessarily understand what "Save" on the edit page means. [...]
Even though "user-generated content" sites are a lot more common today than they were when Wikipedia was founded, it is still unusual for most people that their actions will result in immediate, and effectively irrevocable, publication.
A great illustration of the usability impact of micro-copy, even more important when operating at Wikipedia scale.
How to run an LLM on your laptop. I talked to Grace Huckins for this piece from MIT Technology Review on running local models. Apparently she enjoyed my dystopian backup plan!
Simon Willison has a plan for the end of the world. It’s a USB stick, onto which he has loaded a couple of his favorite open-weight LLMs—models that have been shared publicly by their creators and that can, in principle, be downloaded and run with local hardware. If human civilization should ever collapse, Willison plans to use all the knowledge encoded in their billions of parameters for help. “It’s like having a weird, condensed, faulty version of Wikipedia, so I can help reboot society with the help of my little USB stick,” he says.
The article suggests Ollama or LM Studio for laptops, and new-to-me LLM Farm for the iPhone:
My beat-up iPhone 12 was able to run Meta’s Llama 3.2 1B using an app called LLM Farm. It’s not a particularly good model—it very quickly goes off into bizarre tangents and hallucinates constantly—but trying to coax something so chaotic toward usability can be entertaining.
Update 19th July 20205: Evan Hahn compared the size of various offline LLMs to different Wikipedia exports. Full English Wikipedia without images, revision history or talk pages is 13.82GB, smaller than Mistral Small 3.2 (15GB) but larger than Qwen 3 14B and Gemma 3n.
The Wikimedia Research Newsletter (via) Speaking of summarizing research papers, I just learned about this newsletter and it is an absolute gold mine:
The Wikimedia Research Newsletter (WRN) covers research of relevance to the Wikimedia community. It has been appearing generally monthly since 2011, and features both academic research publications and internal research done at the Wikimedia Foundation.
The March 2025 issue had a fascinating section titled So again, what has the impact of ChatGPT really been? pulled together by WRN co-founder Tilman Bayer. It covers ten different papers, here's one note that stood out to me:
[...] the authors observe an increasing frequency of the words “crucial” and “additionally”, which are favored by ChatGPT [according to previous research] in the content of Wikipedia article.
If you're a startup running your own crawlers to gather data for whatever purpose, you should try really hard not to make the world a worse place by driving up costs for the sites you are scraping.
There's really no excuse for crawling Wikipedia ("65% of our most expensive traffic comes from bots") when they offer a comprehensive collection of bulk download options.
Do better!
2024
The Depths of Wikipedians (via) Asterisk Magazine interviewed Annie Rauwerda, curator of the Depths of Wikipedia family of social media accounts (I particularly like her TikTok).
There's a ton of insight into the dynamics of the Wikipedia community in here.
[...] when people talk about Wikipedia as a decision making entity, usually they're talking about 300 people — the people that weigh in to the very serious and (in my opinion) rather arcane, boring, arduous discussions. There's not that many of them.
There are also a lot of islands. There is one woman who mostly edits about hamsters, and always on her phone. She has never interacted with anyone else. Who is she? She's not part of any community that we can tell.
I appreciated these concluding thoughts on the impact of ChatGPT and LLMs on Wikipedia:
The traffic to Wikipedia has not taken a dramatic hit. Maybe that will change in the future. The Foundation talks about coming opportunities, or the threat of LLMs. With my friends that edit a lot, it hasn't really come up a ton because I don't think they care. It doesn't affect us. We're doing the same thing. Like if all the large language models eat up the stuff we wrote and make it easier for people to get information — great. We made it easier for people to get information.
And if LLMs end up training on blogs made by AI slop and having as their basis this ouroboros of generated text, then it's possible that a Wikipedia-type thing — written and curated by a human — could become even more valuable.
Wikidata is a Giant Crosswalk File.
Drew Breunig shows how to take the 140GB Wikidata JSON export, use sed 's/,$//' to convert it to newline-delimited JSON, then use DuckDB to run queries and extract external identifiers, including a query that pulls out 500MB of latitude and longitude points.
Jevons paradox (via) I've been thinking recently about how the demand for professional software engineers might be affected by the fact that LLMs are getting so good at producing working code, when prompted in the right way.
One possibility is that the price for writing code will fall, in a way that massively increases the demand for custom solutions - resulting in a greater demand for software engineers since the increased value they can provide makes it much easier to justify the expense of hiring them in the first place.
TIL about the related idea of the Jevons paradox, currently explained by Wikipedia like so:
[...] when technological progress increases the efficiency with which a resource is used (reducing the amount necessary for any one use), but the falling cost of use induces increases in demand enough that resource use is increased, rather than reduced.
Wikipedia Manual of Style: Linking (via) I started a conversation on Mastodon about the grammar of linking: how to decide where in a phrase an inline link should be placed.
Lots of great (and varied) replies there. The most comprehensive style guide I've seen so far is this one from Wikipedia, via Tom Morris.
qrank (via) Interesting and very niche project by Colin Dellow.
Wikidata has pages for huge numbers of concepts, people, places and things.
One of the many pieces of data they publish is QRank—“ranking Wikidata entities by aggregating page views on Wikipedia, Wikispecies, Wikibooks, Wikiquote, and other Wikimedia projects”. Every item gets a score and these scores can be used to answer questions like “which island nations get the most interest across Wikipedia”—potentially useful for things like deciding which labels to display on a highly compressed map of the world.
QRank is published as a gzipped CSV file.
Colin’s hikeratlas/qrank GitHub repository runs weekly, fetches the latest qrank.csv.gz file and loads it into a SQLite database using SQLite’s “.import” mechanism. Then it publishes the resulting SQLite database as an asset attached to the “latest” GitHub release on that repo—currently a 307MB file.
The database itself has just a single table mapping the Wikidata ID (a primary key integer) to the latest QRank—another integer. You’d need your own set of data with Wikidata IDs to join against this to do anything useful.
I’d never thought of using GitHub Releases for this kind of thing. I think it’s a really interesting pattern.
Become a Wikipedian in 30 minutes (via) A characteristically informative and thoughtful guide to getting started with Wikipedia editing by Molly White - video accompanied by a full transcript.
I found the explanation of Reliable Sources particularly helpful, including why Wikipedia prefers secondary to primary sources.
The way we determine reliability is typically based on the reputation for editorial oversight, and for factchecking and corrections. For example, if you have a reference book that is published by a reputable publisher that has an editorial board and that has edited the book for accuracy, if you know of a newspaper that has, again, an editorial team that is reviewing articles and issuing corrections if there are any errors, those are probably reliable sources.
Wikimedia Commons Category:Bach Dancing & Dynamite Society. After creating a new Wikipedia page for the Bach Dancing & Dynamite Society in Half Moon Bay I ran a search across Wikipedia for other mentions of the venue... and found 41 artist pages that mentioned it in a photo caption.
On further exploration it turns out that Brian McMillen, the official photographer for the venue, has been uploading photographs to Wikimedia Commons since 2007 and adding them to different artist pages. Brian has been a jazz photographer based out of Half Moon Bay for 47 years and has an amazing portfolio of images. It’s thrilling to see him share them on Wikipedia in this way.
Wikipedia: Bach Dancing & Dynamite Society (via) I created my first Wikipedia page! The Bach Dancing & Dynamite Society is a really neat live music venue in Half Moon Bay which has been showcasing world-class jazz talent for over 50 years. I attended a concert there for the first time on Sunday and was surprised to see it didn’t have a page yet.
Creating a Wikipedia page is an interesting process. New pages on English Wikipedia created by infrequent editors stay in “draft” mode until they’ve been approved by a member of “WikiProject Articles for creation”—the standards are really high, especially around sources of citations. I spent quite a while tracking down good citation references for the key facts I used in my first draft for the page.
WikiChat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on Wikipedia. This paper describes a really interesting LLM system that runs Retrieval Augmented Generation against Wikipedia to help answer questions, but includes a second step where facts in the answer are fact-checked against Wikipedia again before returning an answer to the user. They claim “97.3% factual accuracy of its claims in simulated conversation” on a GPT-4 backed version, and also see good results when backed by LLaMA 7B.
The implementation is mainly through prompt engineering, and detailed examples of the prompts they used are included at the end of the paper.
2023
Wikimedia Commons: Photographs by Gage Skidmore (via) Gage Skidmore is a Wikipedia legend: this category holds 93,458 photographs taken by Gage and released under a Creative Commons license, including a vast number of celebrities taken at events like San Diego Comic-Con. CC licensed photos of celebrities are generally pretty hard to come by so if you see a photo of any celebrity on Wikipedia there’s a good chance it’s credited to Gage.
Wikipedia search-by-vibes through millions of pages offline (via) Really cool demo by Lee Butterman, who built embeddings of 2 million Wikipedia pages and figured out how to serve them directly to the browser, where they are used to implement “vibes based” similarity search returning results in 250ms. Lots of interesting details about how he pulled this off, using Arrow as the file format and ONNX to run the model in the browser.
2020
The impact of crab mentality on performance was quantified by a New Zealand study in 2015 which demonstrated up to an 18% average exam result improvement for students when their grades were reported in a way that prevented others from knowing their position in published rankings.
2018
Why it took a long time to build that tiny link preview on Wikipedia (via) Wikipedia now shows a little preview card on internal links with an image and summary paragraph of the linked page. As a Wikpedia user I absolutely love this feature—and as an engineer and product designer, it’s fascinating to hear the challenges they overcame to ship it. Of particular interest: actually generating a useful summary of a page, while stripping out the cruft that often accumulates at the beginning of their text. It’s also an impressive scaling challenge: the API they use for this feature is now handling more than 500,000 requests per minute.
2013
Which free encyclopedias offer free APIs?
Wikipedia runs using Mediawiki, and Mediawiki has an API: http://www.mediawiki.org/wiki/API
[... 23 words]2012
Why doesn’t Wikipedia try something other than donations to make money?
Wikipedia is run by a non-profit, and the content is created by volunteers for free. Those volunteers created that content under the understanding that it would be for the benefit of the species. Alternative methods of making money would break that assumed contract with their volunteers, and would likely damage their ability to encourage free contributions in the future.
[... 76 words]How did art.sy get a “.sy” url?
Here’s a generally useful tip: if you’re interested in learning more about ANY top level domain, visit the Wikipedia page for it—which will be http://en.wikipedia.org/wiki/.sy in this case (just add the domain, complete with its dot prefix, directly after en.wikipedia.org/wiki/ ).
[... 105 words]2010
How come Google Maps provides so many more local Wikipedia entries that GeoNames?
My guess is that GeoNames just uses the latitude/longitude fields from Wikipedia (you can see them in the top right corner of most pages that describe a place), whereas Google actually do some text analysis and attempt to geocode articles themselves, even if they don’t have an exact latitude longitude assigned to them.
[... 72 words]What are the best APIs for creating location-based Wikipedia mashups?
GeoNames has a fantastic API for finding Wikipedia articles near a specific latitude/longitude pair:
[... 32 words]List of important publications in computer science (via) Amazingly comprehensive list on Wikipedia.
2009
Authority, historically, gets bestowed on the gatekeepers of information, such as Britannica, universities, newspapers, etc. Everything that can be digitized will be digitized, and will then be available over the internet, which is disruptive, not only to business models, but to authority.
Best of OpenStreetMap (via) I keep on telling people OpenStreetMap is this year’s Wikipedia—at its best, it beats commercially available maps. This “best of” site highlights the areas where OSM really shines (the yellow stars)—the German mapping community in particular have produced some outstanding cartography.
Wikipedia over DNS. Added to my ~/bin/ directory as dns-wikipedia.sh: host -t txt $1.wp.dg.cx
2008
License Hacking. Wikipedia is making the switch to a CC license, by asking the Free Software Foundation to include that as an option in the latest version of the Free Documentation License which Wikipedia currently uses and which includes an auto-upgrade clause. Devious.
It’s a purple world. Stuart Langridge made a purplish map of the US election results, using JSON data from Google and an SVG map of the US from Wikipedia.