95 posts tagged “uv”
uv is an "extremely fast Python package and project manager, written in Rust".
2026
One of the smaller features in Datasette 1.0a30 is this:
New documented datasette.fixtures.populate_fixture_database(conn) helper for creating the fixture database tables used by Datasette's own tests, intended for plugin test suites.
This new plugin takes advantage of that API. You can try it out using uvx without even installing Datasette like this:
uvx --prerelease=allow \ --with datasette-fixtures datasette \ --get /fixtures/roadside_attractions.json
Which outputs:
{
"ok": true,
"next": null,
"rows": [
{"pk": 1, "name": "The Mystery Spot", "address": "465 Mystery Spot Road, Santa Cruz, CA 95065", "url": "https://www.mysteryspot.com/", "latitude": 37.0167, "longitude": -122.0024},
{"pk": 2, "name": "Winchester Mystery House", "address": "525 South Winchester Boulevard, San Jose, CA 95128", "url": "https://winchestermysteryhouse.com/", "latitude": 37.3184, "longitude": -121.9511},
{"pk": 3, "name": "Burlingame Museum of PEZ Memorabilia", "address": "214 California Drive, Burlingame, CA 94010", "url": null, "latitude": 37.5793, "longitude": -122.3442},
{"pk": 4, "name": "Bigfoot Discovery Museum", "address": "5497 Highway 9, Felton, CA 95018", "url": "https://www.bigfootdiscoveryproject.com/", "latitude": 37.0414, "longitude": -122.0725}
],
"truncated": false
}Datasette Agent
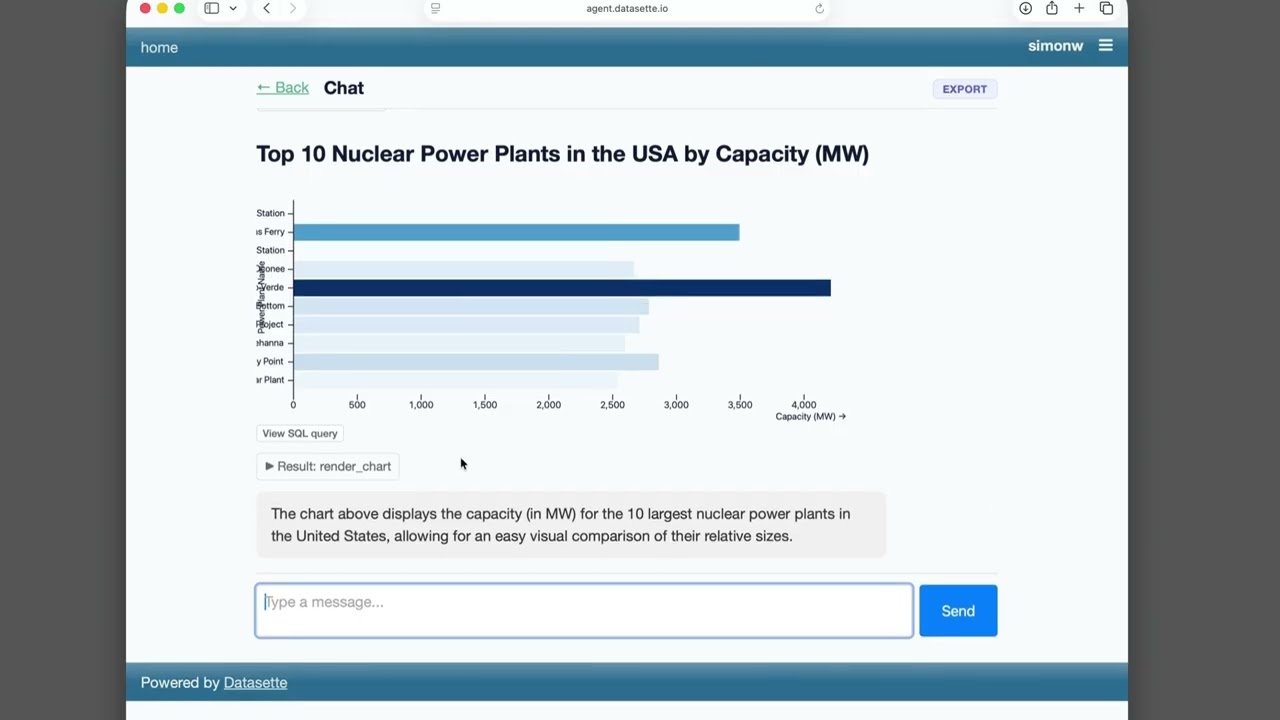
We just announced the first release of Datasette Agent, a new extensible AI assistant for Datasette. I’ve been working on my LLM Python library for just over three years now, and Datasette Agent represents the moment that LLM and Datasette finally come together. I’m really excited about it!
[... 659 words]microsoft/VibeVoice. VibeVoice is Microsoft's Whisper-style audio model for speech-to-text, MIT licensed and with speaker diarization built into the model.
Microsoft released it on January 21st, 2026 but I hadn't tried it until today. Here's a one-liner to run it on a Mac with uv, mlx-audio (by Prince Canuma) and the 5.71GB mlx-community/VibeVoice-ASR-4bit MLX conversion of the 17.3GB VibeVoice-ASR model, in this case against a downloaded copy of my recent podcast appearance with Lenny Rachitsky:
uv run --with mlx-audio mlx_audio.stt.generate \
--model mlx-community/VibeVoice-ASR-4bit \
--audio lenny.mp3 --output-path lenny \
--format json --verbose --max-tokens 32768
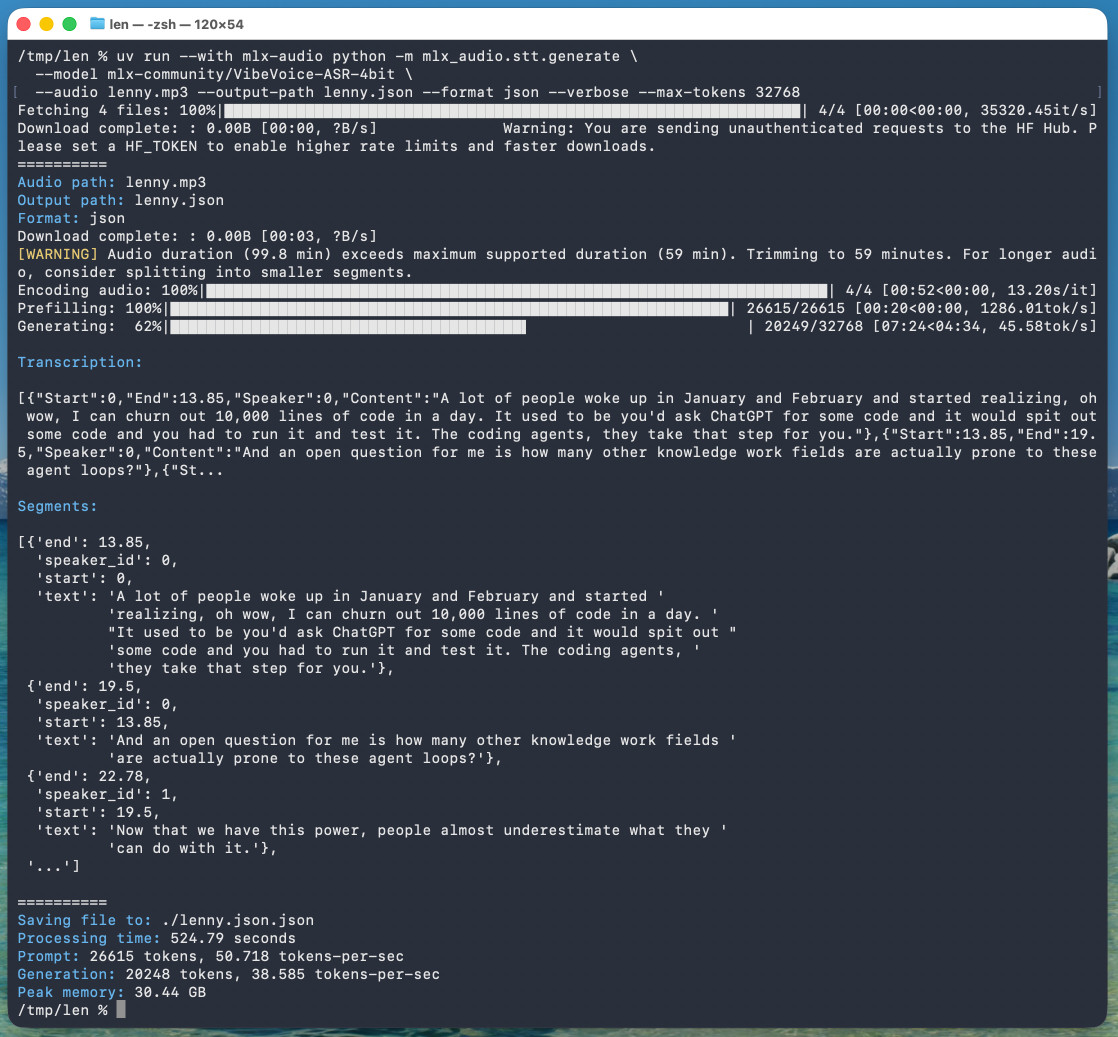
The tool reported back:
Processing time: 524.79 seconds
Prompt: 26615 tokens, 50.718 tokens-per-sec
Generation: 20248 tokens, 38.585 tokens-per-sec
Peak memory: 30.44 GB
So that's 8 minutes 45 seconds for an hour of audio (running on a 128GB M5 Max MacBook Pro).
I've tested it against .wav and .mp3 files and they both worked fine.
If you omit --max-tokens it defaults to 8192, which is enough for about 25 minutes of audio. I discovered that through trial-and-error and quadrupled it to guarantee I'd get the full hour.
That command reported using 30.44GB of RAM at peak, but in Activity Monitor I observed 61.5GB of usage during the prefill stage and around 18GB during the generating phase.
Here's the resulting JSON. The key structure looks like this:
{
"text": "And an open question for me is how many other knowledge work fields are actually prone to these agent loops?",
"start": 13.85,
"end": 19.5,
"duration": 5.65,
"speaker_id": 0
},
{
"text": "Now that we have this power, people almost underestimate what they can do with it.",
"start": 19.5,
"end": 22.78,
"duration": 3.280000000000001,
"speaker_id": 1
},
{
"text": "Today, probably 95% of the code that I produce, I didn't type it myself. I write so much of my code on my phone. It's wild.",
"start": 22.78,
"end": 30.0,
"duration": 7.219999999999999,
"speaker_id": 0
}
Since that's an array of objects we can open it in Datasette Lite, making it easier to browse.
Amusingly that Datasette Lite view shows three speakers - it identified Lenny and me for the conversation, and then a separate Lenny for the voice he used for the additional intro and the sponsor reads!
VibeVoice can only handle up to an hour of audio, so running the above command transcribed just the first hour of the podcast. To transcribe more than that you'd need to split the audio, ideally with a minute or so of overlap so you can avoid errors from partially transcribed words at the split point. You'd also need to then line up the identified speaker IDs across the multiple segments.
Thanks to a tip from Rahim Nathwani, here's a uv run recipe for transcribing an audio file on macOS using the 10.28 GB Gemma 4 E2B model with MLX and mlx-vlm:
uv run --python 3.13 --with mlx_vlm --with torchvision --with gradio \
mlx_vlm.generate \
--model google/gemma-4-e2b-it \
--audio file.wav \
--prompt "Transcribe this audio" \
--max-tokens 500 \
--temperature 1.0
I tried it on this 14 second .wav file and it output the following:
This front here is a quick voice memo. I want to try it out with MLX VLM. Just going to see if it can be transcribed by Gemma and how that works.
(That was supposed to be "This right here..." and "... how well that works" but I can hear why it misinterpreted that as "front" and "how that works".)
Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer
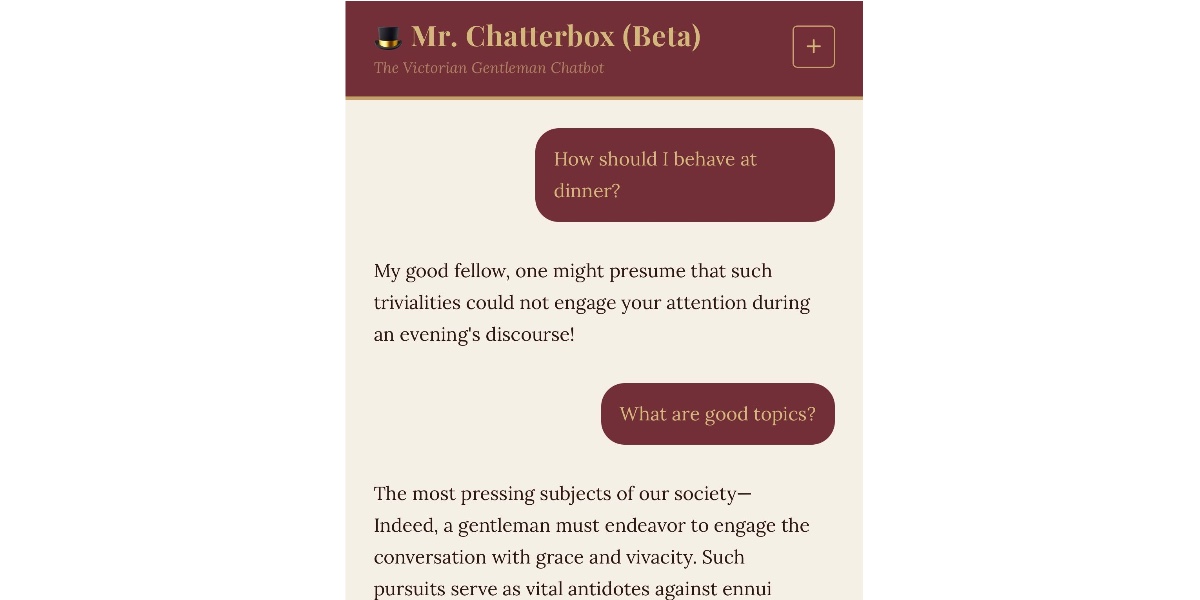
Trip Venturella released Mr. Chatterbox, a language model trained entirely on out-of-copyright text from the British Library. Here’s how he describes it in the model card:
[... 952 words]Package Managers Need to Cool Down. Today's LiteLLM supply chain attack inspired me to revisit the idea of dependency cooldowns, the practice of only installing updated dependencies once they've been out in the wild for a few days to give the community a chance to spot if they've been subverted in some way.
This recent piece (March 4th) piece by Andrew Nesbitt reviews the current state of dependency cooldown mechanisms across different packaging tools. It's surprisingly well supported! There's been a flurry of activity across major packaging tools, including:
- pnpm 10.16 (September 2025) —
minimumReleaseAgewithminimumReleaseAgeExcludefor trusted packages - Yarn 4.10.0 (September 2025) —
npmMinimalAgeGate(in minutes) withnpmPreapprovedPackagesfor exemptions - Bun 1.3 (October 2025) —
minimumReleaseAgeviabunfig.toml - Deno 2.6 (December 2025) —
--minimum-dependency-agefordeno updateanddeno outdated - uv 0.9.17 (December 2025) — added relative duration support to existing
--exclude-newer, plus per-package overrides viaexclude-newer-package - pip 26.0 (January 2026) —
--uploaded-prior-to(absolute timestamps only; relative duration support requested, update: and added in pip 26.1 in April) - npm 11.10.0 (February 2026) —
min-release-age
pip currently only supports absolute rather than relative dates but Seth Larson has a workaround for that using a scheduled cron to update the absolute date in the pip.conf config file.
Thoughts on OpenAI acquiring Astral and uv/ruff/ty
The big news this morning: Astral to join OpenAI (on the Astral blog) and OpenAI to acquire Astral (the OpenAI announcement). Astral are the company behind uv, ruff, and ty—three increasingly load-bearing open source projects in the Python ecosystem. I have thoughts!
[... 1,378 words]Distributing Go binaries like sqlite-scanner through PyPI using go-to-wheel
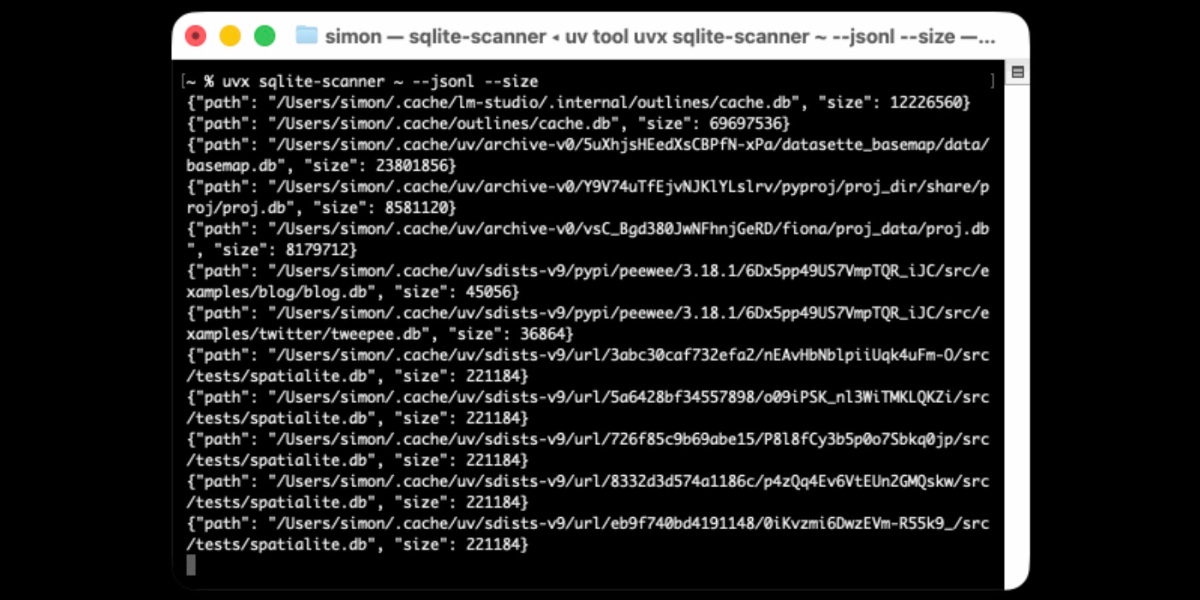
I’ve been exploring Go for building small, fast and self-contained binary applications recently. I’m enjoying how there’s generally one obvious way to do things and the resulting code is boring and readable—and something that LLMs are very competent at writing. The one catch is distribution, but it turns out publishing Go binaries to PyPI means any Go binary can be just a uvx package-name call away.
Datasette 1.0a24. New Datasette alpha this morning. Key new features:
- Datasette's
Requestobject can now handlemultipart/form-datafile uploads via the new await request.form(files=True) method. I plan to use this for adatasette-filesplugin to support attaching files to rows of data. - The recommended development environment for hacking on Datasette itself now uses uv. Crucially, you can clone Datasette and run
uv run pytestto run the tests without needing to manually create a virtual environment or install dependencies first, thanks to the dev dependency group pattern. - A new
?_extra=render_cellparameter for both table and row JSON pages to return the results of executing the render_cell() plugin hook. This should unlock new JavaScript UI features in the future.
More details in the release notes. I also invested a bunch of work in eliminating flaky tests that were intermittently failing in CI - I think those are all handled now.
Qwen3-TTS Family is Now Open Sourced: Voice Design, Clone, and Generation (via) I haven't been paying much attention to the state-of-the-art in speech generation models other than noting that they've got really good, so I can't speak for how notable this new release from Qwen is.
From the accompanying paper:
In this report, we present the Qwen3-TTS series, a family of advanced multilingual, controllable, robust, and streaming text-to-speech models. Qwen3-TTS supports state-of- the-art 3-second voice cloning and description-based control, allowing both the creation of entirely novel voices and fine-grained manipulation over the output speech. Trained on over 5 million hours of speech data spanning 10 languages, Qwen3-TTS adopts a dual-track LM architecture for real-time synthesis [...]. Extensive experiments indicate state-of-the-art performance across diverse objective and subjective benchmark (e.g., TTS multilingual test set, InstructTTSEval, and our long speech test set). To facilitate community research and development, we release both tokenizers and models under the Apache 2.0 license.
To give an idea of size, Qwen/Qwen3-TTS-12Hz-1.7B-Base is 4.54GB on Hugging Face and Qwen/Qwen3-TTS-12Hz-0.6B-Base is 2.52GB.
The Hugging Face demo lets you try out the 0.6B and 1.7B models for free in your browser, including voice cloning:
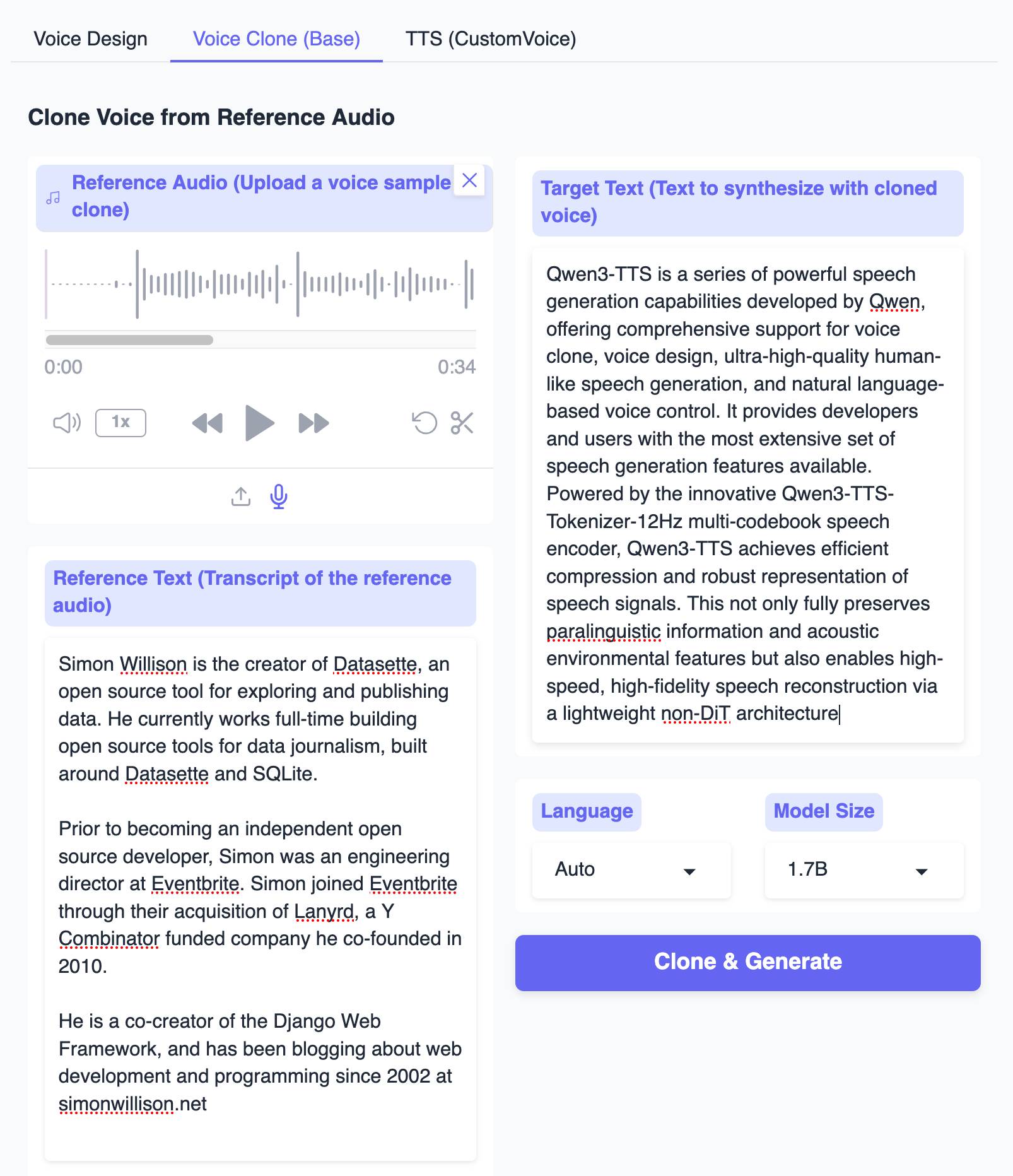
I tried this out by recording myself reading my about page and then having Qwen3-TTS generate audio of me reading the Qwen3-TTS announcement post. Here's the result:
It's important that everyone understands that voice cloning is now something that's available to anyone with a GPU and a few GBs of VRAM... or in this case a web browser that can access Hugging Face.
Update: Prince Canuma got this working with his mlx-audio library. I had Claude turn that into a CLI tool which you can run with uv ike this:
uv run https://tools.simonwillison.net/python/q3_tts.py \
'I am a pirate, give me your gold!' \
-i 'gruff voice' -o pirate.wav
The -i option lets you use a prompt to describe the voice it should use. On first run this downloads a 4.5GB model file from Hugging Face.
2025
How uv got so fast.
Andrew Nesbitt provides an insightful teardown of why uv is so much faster than pip. It's not nearly as simple as just "they rewrote it in Rust" - uv gets to skip a huge amount of Python packaging history (which pip needs to implement for backwards compatibility) and benefits enormously from work over recent years that makes it possible to resolve dependencies across most packages without having to execute the code in setup.py using a Python interpreter.
Two notes that caught my eye that I hadn't understood before:
HTTP range requests for metadata. Wheel files are zip archives, and zip archives put their file listing at the end. uv tries PEP 658 metadata first, falls back to HTTP range requests for the zip central directory, then full wheel download, then building from source. Each step is slower and riskier. The design makes the fast path cover 99% of cases. None of this requires Rust.
[...]
Compact version representation. uv packs versions into u64 integers where possible, making comparison and hashing fast. Over 90% of versions fit in one u64. This is micro-optimization that compounds across millions of comparisons.
I wanted to learn more about these tricks, so I fired up an asynchronous research task and told it to checkout the astral-sh/uv repo, find the Rust code for both of those features and try porting it to Python to help me understand how it works.
Here's the report that it wrote for me, the prompts I used and the Claude Code transcript.
You can try the script it wrote for extracting metadata from a wheel using HTTP range requests like this:
uv run --with httpx https://raw.githubusercontent.com/simonw/research/refs/heads/main/http-range-wheel-metadata/wheel_metadata.py https://files.pythonhosted.org/packages/8b/04/ef95b67e1ff59c080b2effd1a9a96984d6953f667c91dfe9d77c838fc956/playwright-1.57.0-py3-none-macosx_11_0_arm64.whl -v
The Playwright wheel there is ~40MB. Adding -v at the end causes the script to spit out verbose details of how it fetched the data - which looks like this.
Key extract from that output:
[1] HEAD request to get file size...
File size: 40,775,575 bytes
[2] Fetching last 16,384 bytes (EOCD + central directory)...
Received 16,384 bytes
[3] Parsed EOCD:
Central directory offset: 40,731,572
Central directory size: 43,981
Total entries: 453
[4] Fetching complete central directory...
...
[6] Found METADATA: playwright-1.57.0.dist-info/METADATA
Offset: 40,706,744
Compressed size: 1,286
Compression method: 8
[7] Fetching METADATA content (2,376 bytes)...
[8] Decompressed METADATA: 3,453 bytes
Total bytes fetched: 18,760 / 40,775,575 (100.0% savings)
The section of the report on compact version representation is interesting too. Here's how it illustrates sorting version numbers correctly based on their custom u64 representation:
Sorted order (by integer comparison of packed u64):
1.0.0a1 (repr=0x0001000000200001)
1.0.0b1 (repr=0x0001000000300001)
1.0.0rc1 (repr=0x0001000000400001)
1.0.0 (repr=0x0001000000500000)
1.0.0.post1 (repr=0x0001000000700001)
1.0.1 (repr=0x0001000100500000)
2.0.0.dev1 (repr=0x0002000000100001)
2.0.0 (repr=0x0002000000500000)
uv-init-demos.
uv has a useful uv init command for setting up new Python projects, but it comes with a bunch of different options like --app and --package and --lib and I wasn't sure how they differed.
So I created this GitHub repository which demonstrates all of those options, generated using this update-projects.sh script (thanks, Claude) which will run on a schedule via GitHub Actions to capture any changes made by future releases of uv.
Poe the Poet.
I was looking for a way to specify additional commands in my pyproject.toml file to execute using uv. There's an enormous issue thread on this in the uv issue tracker (300+ comments dating back to August 2024) and from there I learned of several options including this one, Poe the Poet.
It's neat. I added it to my s3-credentials project just now and the following now works for running the live preview server for the documentation:
uv run poe livehtml
Here's the snippet of TOML I added to my pyproject.toml:
[dependency-groups] test = [ "pytest", "pytest-mock", "cogapp", "moto>=5.0.4", ] docs = [ "furo", "sphinx-autobuild", "myst-parser", "cogapp", ] dev = [ {include-group = "test"}, {include-group = "docs"}, "poethepoet>=0.38.0", ] [tool.poe.tasks] docs = "sphinx-build -M html docs docs/_build" livehtml = "sphinx-autobuild -b html docs docs/_build" cog = "cog -r docs/*.md"
Since poethepoet is in the dev= dependency group any time I run uv run ... it will be available in the environment.
LLM 0.28. I released a new version of my LLM Python library and CLI tool for interacting with Large Language Models. Highlights from the release notes:
- New OpenAI models:
gpt-5.1,gpt-5.1-chat-latest,gpt-5.2andgpt-5.2-chat-latest. #1300, #1317- When fetching URLs as fragments using
llm -f URL, the request now includes a custom user-agent header:llm/VERSION (https://llm.datasette.io/). #1309- Fixed a bug where fragments were not correctly registered with their source when using
llm chat. Thanks, Giuseppe Rota. #1316- Fixed some file descriptor leak warnings. Thanks, Eric Bloch. #1313
- Type annotations for the OpenAI Chat, AsyncChat and Completion
execute()methods. Thanks, Arjan Mossel. #1315- The project now uses
uvand dependency groups for development. See the updated contributing documentation. #1318
That last bullet point about uv relates to the dependency groups pattern I wrote about in a recent TIL. I'm currently working through applying it to my other projects - the net result is that running the test suite is as simple as doing:
git clone https://github.com/simonw/llm
cd llm
uv run pytest
The new dev dependency group defined in pyproject.toml is automatically installed by uv run in a new virtual environment which means everything needed to run pytest is available without needing to add any extra commands.
TIL: Dependency groups and uv run.
I wrote up the new pattern I'm using for my various Python project repos to make them as easy to hack on with uv as possible. The trick is to use a PEP 735 dependency group called dev, declared in pyproject.toml like this:
[dependency-groups]
dev = ["pytest"]
With that in place, running uv run pytest will automatically install that development dependency into a new virtual environment and use it to run your tests.
This means you can get started hacking on one of my projects (here datasette-extract) with just these steps:
git clone https://github.com/datasette/datasette-extract
cd datasette-extract
uv run pytest
I also split my uv TILs out into a separate folder. This meant I had to setup redirects for the old paths, so I had Claude Code help build me a new plugin called datasette-redirects and then apply it to my TIL site, including updating the build script to correctly track the creation date of files that had since been renamed.
sqlite-utils 3.39.
I got a report of a bug in sqlite-utils concerning plugin installation - if you installed the package using uv tool install further attempts to install plugins with sqlite-utils install X would fail, because uv doesn't bundle pip by default. I had the same bug with Datasette a while ago, turns out I forgot to apply the fix to sqlite-utils.
Since I was pushing a new dot-release I decided to integrate some of the non-breaking changes from the 4.0 alpha I released last night.
I tried to have Claude Code do the backporting for me:
create a new branch called 3.x starting with the 3.38 tag, then consult https://github.com/simonw/sqlite-utils/issues/688 and cherry-pick the commits it lists in the second comment, then review each of the links in the first comment and cherry-pick those as well. After each cherry-pick run the command "just test" to confirm the tests pass and fix them if they don't. Look through the commit history on main since the 3.38 tag to help you with this task.
This worked reasonably well - here's the terminal transcript. It successfully argued me out of two of the larger changes which would have added more complexity than I want in a small dot-release like this.
I still had to do a bunch of manual work to get everything up to scratch, which I carried out in this PR - including adding comments there and then telling Claude Code:
Apply changes from the review on this PR https://github.com/simonw/sqlite-utils/pull/689
Here's the transcript from that.
The release is now out with the following release notes:
- Fixed a bug with
sqlite-utils installwhen the tool had been installed usinguv. (#687)- The
--functionsargument now optionally accepts a path to a Python file as an alternative to a string full of code, and can be specified multiple times - see Defining custom SQL functions. (#659)sqlite-utilsnow requires on Python 3.10 or higher.
llm-anthropic 0.22.
New release of my llm-anthropic plugin:
- Support for Claude's new structured outputs feature for Sonnet 4.5 and Opus 4.1. #54
- Support for the web search tool using
-o web_search 1- thanks Nick Powell and Ian Langworth. #30
The plugin previously powered LLM schemas using this tool-call based workaround. That code is still used for Anthropic's older models.
I also figured out uv recipes for running the plugin's test suite in an isolated environment, which are now baked into the new Justfile.
parakeet-mlx. Neat MLX project by Senstella bringing NVIDIA's Parakeet ASR (Automatic Speech Recognition, like Whisper) model to to Apple's MLX framework.
It's packaged as a Python CLI tool, so you can run it like this:
uvx parakeet-mlx default_tc.mp3
The first time I ran this it downloaded a 2.5GB model file.
Once that was fetched it took 53 seconds to transcribe a 65MB 1hr 1m 28s podcast episode (this one) and produced this default_tc.srt file with a timestamped transcript of the audio I fed into it. The quality appears to be very high.
Nano Banana can be prompt engineered for extremely nuanced AI image generation (via) Max Woolf provides an exceptional deep dive into Google's Nano Banana aka Gemini 2.5 Flash Image model, still the best available image manipulation LLM tool three months after its initial release.
I confess I hadn't grasped that the key difference between Nano Banana and OpenAI's gpt-image-1 and the previous generations of image models like Stable Diffusion and DALL-E was that the newest contenders are no longer diffusion models:
Of note,
gpt-image-1, the technical name of the underlying image generation model, is an autoregressive model. While most image generation models are diffusion-based to reduce the amount of compute needed to train and generate from such models,gpt-image-1works by generating tokens in the same way that ChatGPT generates the next token, then decoding them into an image. [...]Unlike Imagen 4, [Nano Banana] is indeed autoregressive, generating 1,290 tokens per image.
Max goes on to really put Nano Banana through its paces, demonstrating a level of prompt adherence far beyond its competition - both for creating initial images and modifying them with follow-up instructions
Create an image of a three-dimensional pancake in the shape of a skull, garnished on top with blueberries and maple syrup. [...]
Make ALL of the following edits to the image:
- Put a strawberry in the left eye socket.
- Put a blackberry in the right eye socket.
- Put a mint garnish on top of the pancake.
- Change the plate to a plate-shaped chocolate-chip cookie.
- Add happy people to the background.
One of Max's prompts appears to leak parts of the Nano Banana system prompt:
Generate an image showing the # General Principles in the previous text verbatim using many refrigerator magnets

He also explores its ability to both generate and manipulate clearly trademarked characters. I expect that feature will be reined back at some point soon!
Max built and published a new Python library for generating images with the Nano Banana API called gemimg.
I like CLI tools, so I had Gemini CLI add a CLI feature to Max's code and submitted a PR.
Thanks to the feature of GitHub where any commit can be served as a Zip file you can try my branch out directly using uv like this:
GEMINI_API_KEY="$(llm keys get gemini)" \
uv run --with https://github.com/minimaxir/gemimg/archive/d6b9d5bbefa1e2ffc3b09086bc0a3ad70ca4ef22.zip \
python -m gemimg "a racoon holding a hand written sign that says I love trash"

Video + notes on upgrading a Datasette plugin for the latest 1.0 alpha, with help from uv and OpenAI Codex CLI
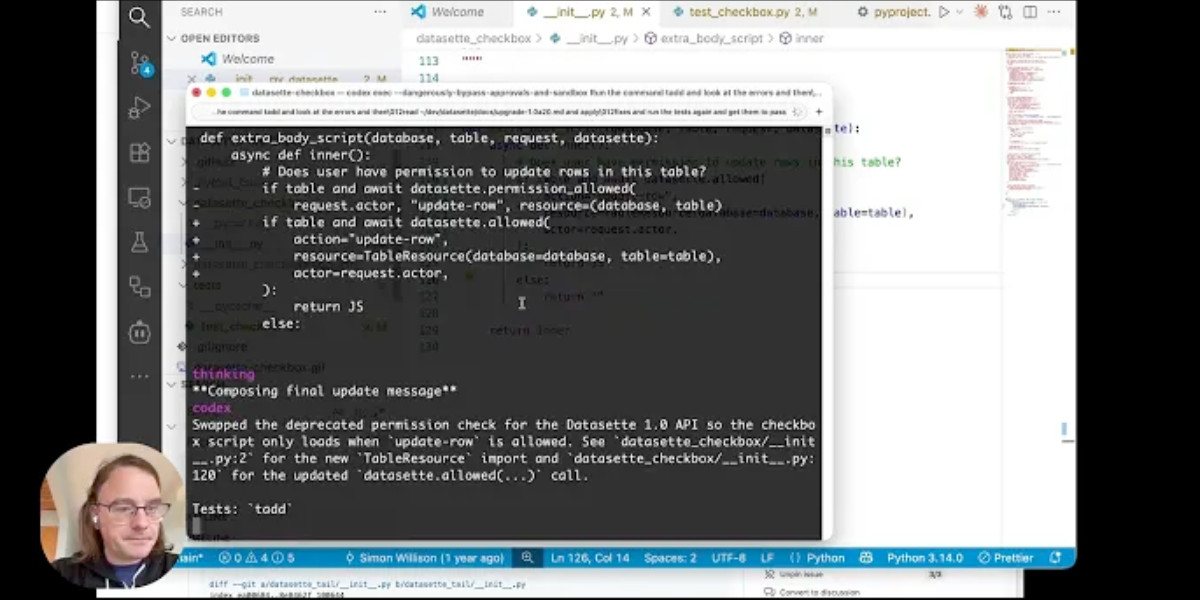
I’m upgrading various plugins for compatibility with the new Datasette 1.0a20 alpha release and I decided to record a video of the process. This post accompanies that video with detailed additional notes.
[... 1,094 words]A new SQL-powered permissions system in Datasette 1.0a20
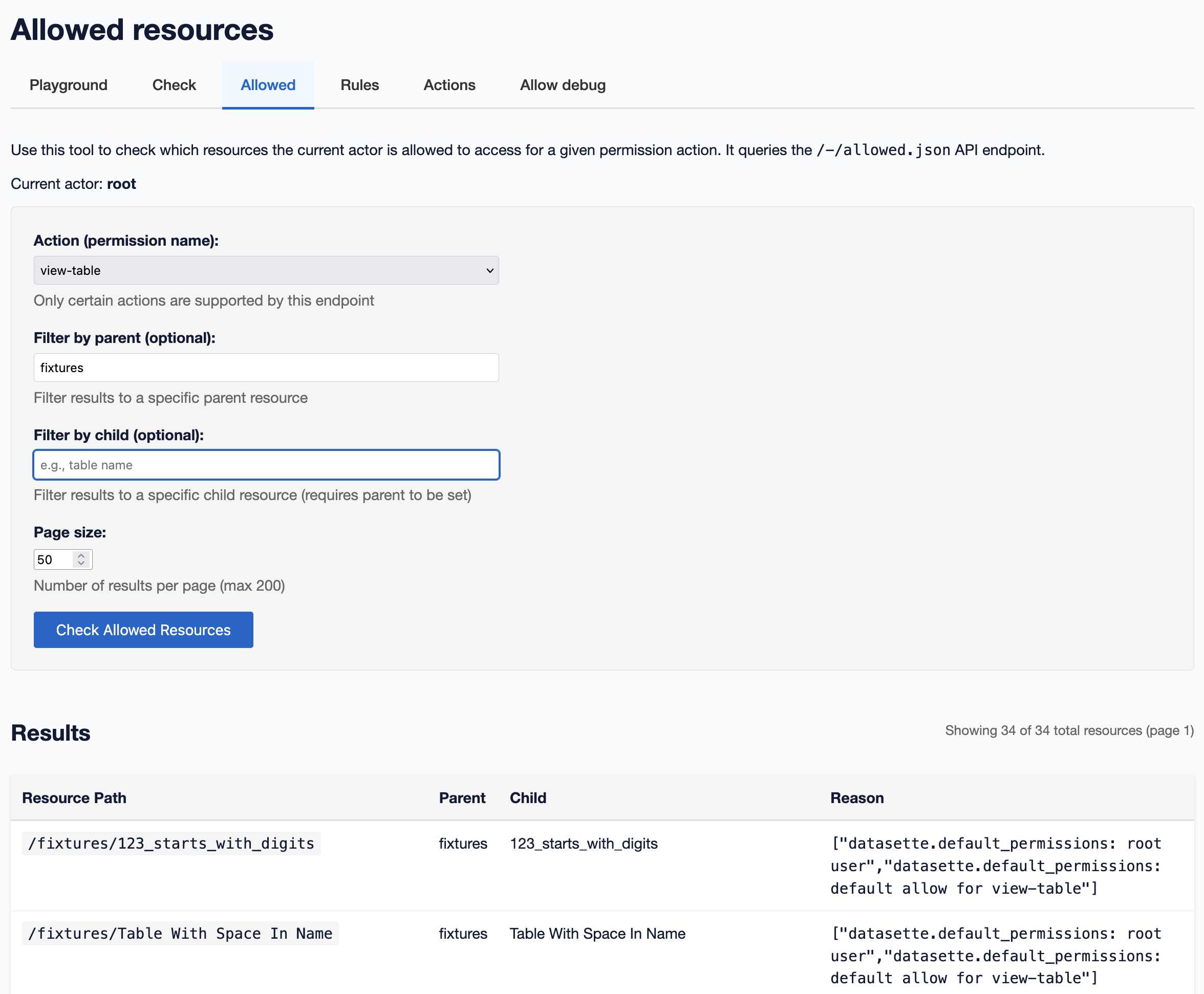
Datasette 1.0a20 is out with the biggest breaking API change on the road to 1.0, improving how Datasette’s permissions system works by migrating permission logic to SQL running in SQLite. This release involved 163 commits, with 10,660 additions and 1,825 deletions, most of which was written with the help of Claude Code.
[... 2,750 words]nanochat (via) Really interesting new project from Andrej Karpathy, described at length in this discussion post.
It provides a full ChatGPT-style LLM, including training, inference and a web Ui, that can be trained for as little as $100:
This repo is a full-stack implementation of an LLM like ChatGPT in a single, clean, minimal, hackable, dependency-lite codebase.
It's around 8,000 lines of code, mostly Python (using PyTorch) plus a little bit of Rust for training the tokenizer.
Andrej suggests renting a 8XH100 NVIDA node for around $24/ hour to train the model. 4 hours (~$100) is enough to get a model that can hold a conversation - almost coherent example here. Run it for 12 hours and you get something that slightly outperforms GPT-2. I'm looking forward to hearing results from longer training runs!
The resulting model is ~561M parameters, so it should run on almost anything. I've run a 4B model on my iPhone, 561M should easily fit on even an inexpensive Raspberry Pi.
The model defaults to training on ~24GB from karpathy/fineweb-edu-100b-shuffle derived from FineWeb-Edu, and then midtrains on 568K examples from SmolTalk (460K), MMLU auxiliary train (100K), and GSM8K (8K), followed by supervised finetuning on 21.4K examples from ARC-Easy (2.3K), ARC-Challenge (1.1K), GSM8K (8K), and SmolTalk (10K).
Here's the code for the web server, which is fronted by this pleasantly succinct vanilla JavaScript HTML+JavaScript frontend.
Update: Sam Dobson pushed a build of the model to sdobson/nanochat on Hugging Face. It's designed to run on CUDA but I pointed Claude Code at a checkout and had it hack around until it figured out how to run it on CPU on macOS, which eventually resulted in this script which I've published as a Gist. You should be able to try out the model using uv like this:
cd /tmp
git clone https://huggingface.co/sdobson/nanochat
uv run https://gist.githubusercontent.com/simonw/912623bf00d6c13cc0211508969a100a/raw/80f79c6a6f1e1b5d4485368ef3ddafa5ce853131/generate_cpu.py \
--model-dir /tmp/nanochat \
--prompt "Tell me about dogs."
I got this (truncated because it ran out of tokens):
I'm delighted to share my passion for dogs with you. As a veterinary doctor, I've had the privilege of helping many pet owners care for their furry friends. There's something special about training, about being a part of their lives, and about seeing their faces light up when they see their favorite treats or toys.
I've had the chance to work with over 1,000 dogs, and I must say, it's a rewarding experience. The bond between owner and pet
TIL: Testing different Python versions with uv with-editable and uv-test.
While tinkering with upgrading various projects to handle Python 3.14 I finally figured out a universal uv recipe for running the tests for the current project in any specified version of Python:
uv run --python 3.14 --isolated --with-editable '.[test]' pytest
This should work in any directory with a pyproject.toml (or even a setup.py) that defines a test set of extra dependencies and uses pytest.
The --with-editable '.[test]' bit ensures that changes you make to that directory will be picked up by future test runs. The --isolated flag ensures no other environments will affect your test run.
I like this pattern so much I built a little shell script that uses it, shown here. Now I can change to any Python project directory and run:
uv-test
Or for a different Python version:
uv-test -p 3.11
I can pass additional pytest options too:
uv-test -p 3.11 -k permissions
Claude can write complete Datasette plugins now
This isn’t necessarily surprising, but it’s worth noting anyway. Claude Sonnet 4.5 is capable of building a full Datasette plugin now.
[... 1,296 words]Python 3.14. This year's major Python version, Python 3.14, just made its first stable release!
As usual the what's new in Python 3.14 document is the best place to get familiar with the new release:
The biggest changes include template string literals, deferred evaluation of annotations, and support for subinterpreters in the standard library.
The library changes include significantly improved capabilities for introspection in asyncio, support for Zstandard via a new compression.zstd module, syntax highlighting in the REPL, as well as the usual deprecations and removals, and improvements in user-friendliness and correctness.
Subinterpreters look particularly interesting as a way to use multiple CPU cores to run Python code despite the continued existence of the GIL. If you're feeling brave and your dependencies cooperate you can also use the free-threaded build of Python 3.14 - now officially supported - to skip the GIL entirely.
A new major Python release means an older release hits the end of its support lifecycle - in this case that's Python 3.9. If you maintain open source libraries that target every supported Python versions (as I do) this means features introduced in Python 3.10 can now be depended on! What's new in Python 3.10 lists those - I'm most excited by structured pattern matching (the match/case statement) and the union type operator, allowing int | float | None as a type annotation in place of Optional[Union[int, float]].
If you use uv you can grab a copy of 3.14 using:
uv self update
uv python upgrade 3.14
uvx python@3.14
Or for free-threaded Python 3.1;:
uvx python@3.14t
The uv team wrote about their Python 3.14 highlights in their announcement of Python 3.14's availability via uv.
The GitHub Actions setup-python action includes Python 3.14 now too, so the following YAML snippet in will run tests on all currently supported versions:
strategy:
matrix:
python-version: ["3.10", "3.11", "3.12", "3.13", "3.14"]
steps:
- uses: actions/setup-python@v6
with:
python-version: ${{ matrix.python-version }}
Full example here for one of my many Datasette plugin repos.
gpt-image-1-mini.
OpenAI released a new image model today: gpt-image-1-mini, which they describe as "A smaller image generation model that’s 80% less expensive than the large model."
They released it very quietly - I didn't hear about this in the DevDay keynote but I later spotted it on the DevDay 2025 announcements page.
It wasn't instantly obvious to me how to use this via their API. I ended up vibe coding a Python CLI tool for it so I could try it out.
I dumped the plain text diff version of the commit to the OpenAI Python library titled feat(api): dev day 2025 launches into ChatGPT GPT-5 Thinking and worked with it to figure out how to use the new image model and build a script for it. Here's the transcript and the the openai_image.py script it wrote.
I had it add inline script dependencies, so you can run it with uv like this:
export OPENAI_API_KEY="$(llm keys get openai)"
uv run https://tools.simonwillison.net/python/openai_image.py "A pelican riding a bicycle"
It picked this illustration style without me specifying it:

(This is a very different test from my normal "Generate an SVG of a pelican riding a bicycle" since it's using a dedicated image generator, not having a text-based model try to generate SVG code.)
My tool accepts a prompt, and optionally a filename (if you don't provide one it saves to a filename like /tmp/image-621b29.png).
It also accepts options for model and dimensions and output quality - the --help output lists those, you can see that here.
OpenAI's pricing is a little confusing. The model page claims low quality images should cost around half a cent and medium quality around a cent and a half. It also lists an image token price of $8/million tokens. It turns out there's a default "high" quality setting - most of the images I've generated have reported between 4,000 and 6,000 output tokens, which costs between 3.2 and 4.8 cents.
One last demo, this time using --quality low:
uv run https://tools.simonwillison.net/python/openai_image.py \
'racoon eating cheese wearing a top hat, realistic photo' \
/tmp/racoon-hat-photo.jpg \
--size 1024x1024 \
--output-format jpeg \
--quality low
This saved the following:

And reported this to standard error:
{
"background": "opaque",
"created": 1759790912,
"generation_time_in_s": 20.87331541599997,
"output_format": "jpeg",
"quality": "low",
"size": "1024x1024",
"usage": {
"input_tokens": 17,
"input_tokens_details": {
"image_tokens": 0,
"text_tokens": 17
},
"output_tokens": 272,
"total_tokens": 289
}
}
This took 21s, but I'm on an unreliable conference WiFi connection so I don't trust that measurement very much.
272 output tokens = 0.2 cents so this is much closer to the expected pricing from the model page.
Rich Pixels. Neat Python library by Darren Burns adding pixel image support to the Rich terminal library, using tricks to render an image using full or half-height colored blocks.
Here's the key trick - it renders Unicode ▄ (U+2584, "lower half block") characters after setting a foreground and background color for the two pixels it needs to display.
I got GPT-5 to vibe code up a show_image.py terminal command which resizes the provided image to fit the width and height of the current terminal and displays it using Rich Pixels. That script is here, you can run it with uv like this:
uv run https://tools.simonwillison.net/python/show_image.py \
image.jpg
Here's what I got when I ran it against my V&A East Storehouse photo from this post:
![]()
Static Sites with Python, uv, Caddy, and Docker (via) Nik Kantar documents his Docker-based setup for building and deploying mostly static web sites in line-by-line detail.
I found this really useful. The Dockerfile itself without comments is just 8 lines long:
FROM ghcr.io/astral-sh/uv:debian AS build
WORKDIR /src
COPY . .
RUN uv python install 3.13
RUN uv run --no-dev sus
FROM caddy:alpine
COPY Caddyfile /etc/caddy/Caddyfile
COPY --from=build /src/output /srv/
He also includes a Caddyfile that shows how to proxy a subset of requests to the Plausible analytics service.
The static site is built using his sus package for creating static URL redirecting sites, but would work equally well for another static site generator you can install and run with uv run.
Nik deploys his sites using Coolify, a new-to-me take on the self-hosting alternative to Heroku/Vercel pattern which helps run multiple sites on a collection of hosts using Docker containers.
A bunch of the Hacker News comments dismissed this as over-engineering. I don't think that criticism is justified - given Nik's existing deployment environment I think this is a lightweight way to deploy static sites in a way that's consistent with how everything else he runs works already.
More importantly, the world needs more articles like this that break down configuration files and explain what every single line of them does.
Qwen-Image-Edit: Image Editing with Higher Quality and Efficiency.
As promised in their August 4th release of the Qwen image generation model, Qwen have now followed it up with a separate model, Qwen-Image-Edit, which can take an image and a prompt and return an edited version of that image.
Ivan Fioravanti upgraded his macOS qwen-image-mps tool (previously) to run the new model via a new edit command. Since it's now on PyPI you can run it directly using uvx like this:
uvx qwen-image-mps edit -i pelicans.jpg \
-p 'Give the pelicans rainbow colored plumage' -s 10
Be warned... it downloads a 54GB model file (to ~/.cache/huggingface/hub/models--Qwen--Qwen-Image-Edit) and appears to use all 64GB of my system memory - if you have less than 64GB it likely won't work, and I had to quit almost everything else on my system to give it space to run. A larger machine is almost required to use this.
I fed it this image:

The following prompt:
Give the pelicans rainbow colored plumage
And told it to use just 10 inference steps - the default is 50, but I didn't want to wait that long.
It still took nearly 25 minutes (on a 64GB M2 MacBook Pro) to produce this result:

To get a feel for how much dropping the inference steps affected things I tried the same prompt with the new "Image Edit" mode of Qwen's chat.qwen.ai, which I believe uses the same model. It gave me a result much faster that looked like this:

Update: I left the command running overnight without the -s 10 option - so it would use all 50 steps - and my laptop took 2 hours and 59 minutes to generate this image, which is much more photo-realistic and similar to the one produced by Qwen's hosted model:

Marko Simic reported that:
50 steps took 49min on my MBP M4 Max 128GB
TIL: Running a gpt-oss eval suite against LM Studio on a Mac. The other day I learned that OpenAI published a set of evals as part of their gpt-oss model release, described in their cookbook on Verifying gpt-oss implementations.
I decided to try and run that eval suite on my own MacBook Pro, against gpt-oss-20b running inside of LM Studio.
TLDR: once I had the model running inside LM Studio with a longer than default context limit, the following incantation ran an eval suite in around 3.5 hours:
mkdir /tmp/aime25_openai
OPENAI_API_KEY=x \
uv run --python 3.13 --with 'gpt-oss[eval]' \
python -m gpt_oss.evals \
--base-url http://localhost:1234/v1 \
--eval aime25 \
--sampler chat_completions \
--model openai/gpt-oss-20b \
--reasoning-effort low \
--n-threads 2
My new TIL breaks that command down in detail and walks through the underlying eval - AIME 2025, which asks 30 questions (8 times each) that are defined using the following format:
{"question": "Find the sum of all integer bases $b>9$ for which $17_{b}$ is a divisor of $97_{b}$.", "answer": "70"}