610 posts tagged “llm”
LLM is my command-line tool for running prompts against Large Language Models.
2024
Ollama: Llama 3.2 Vision. Ollama released version 0.4 last week with support for Meta's first Llama vision model, Llama 3.2.
If you have Ollama installed you can fetch the 11B model (7.9 GB) like this:
ollama pull llama3.2-vision
Or the larger 90B model (55GB download, likely needs ~88GB of RAM) like this:
ollama pull llama3.2-vision:90b
I was delighted to learn that Sukhbinder Singh had already contributed support for LLM attachments to Sergey Alexandrov's llm-ollama plugin, which means the following works once you've pulled the models:
llm install --upgrade llm-ollama
llm -m llama3.2-vision:latest 'describe' \
-a https://static.simonwillison.net/static/2024/pelican.jpg
This image features a brown pelican standing on rocks, facing the camera and positioned to the left of center. The bird's long beak is a light brown color with a darker tip, while its white neck is adorned with gray feathers that continue down to its body. Its legs are also gray.
In the background, out-of-focus boats and water are visible, providing context for the pelican's environment.

That's not a bad description of this image, especially for a 7.9GB model that runs happily on my MacBook Pro.
Qwen2.5-Coder-32B is an LLM that can code well that runs on my Mac
There’s a whole lot of buzz around the new Qwen2.5-Coder Series of open source (Apache 2.0 licensed) LLM releases from Alibaba’s Qwen research team. On first impression it looks like the buzz is well deserved.
[... 697 words]Generating documentation from tests using files-to-prompt and LLM. I was experimenting with the wasmtime-py Python library today (for executing WebAssembly programs from inside CPython) and I found the existing API docs didn't quite show me what I wanted to know.
The project has a comprehensive test suite so I tried seeing if I could generate documentation using that:
cd /tmp
git clone https://github.com/bytecodealliance/wasmtime-py
files-to-prompt -e py wasmtime-py/tests -c | \
llm -m claude-3.5-sonnet -s \
'write detailed usage documentation including realistic examples'
More notes in my TIL. You can see the full Claude transcript here - I think this worked really well!
Claude 3.5 Haiku
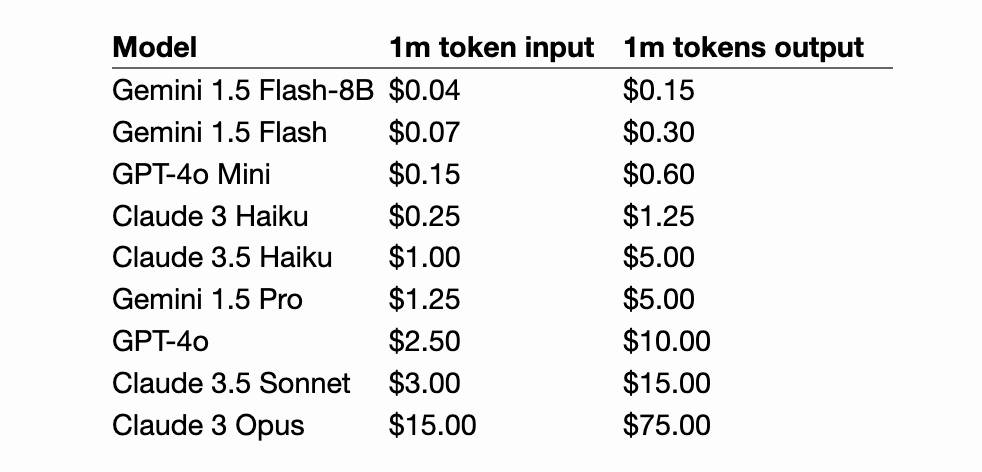
Anthropic released Claude 3.5 Haiku today, a few days later than expected (they said it would be out by the end of October).
[... 502 words]Nous Hermes 3. The Nous Hermes family of fine-tuned models have a solid reputation. Their most recent release came out in August, based on Meta's Llama 3.1:
Our training data aggressively encourages the model to follow the system and instruction prompts exactly and in an adaptive manner. Hermes 3 was created by fine-tuning Llama 3.1 8B, 70B and 405B, and training on a dataset of primarily synthetically generated responses. The model boasts comparable and superior performance to Llama 3.1 while unlocking deeper capabilities in reasoning and creativity.
The model weights are on Hugging Face, including GGUF versions of the 70B and 8B models. Here's how to try the 8B model (a 4.58GB download) using the llm-gguf plugin:
llm install llm-gguf
llm gguf download-model 'https://huggingface.co/NousResearch/Hermes-3-Llama-3.1-8B-GGUF/resolve/main/Hermes-3-Llama-3.1-8B.Q4_K_M.gguf' -a Hermes-3-Llama-3.1-8B
llm -m Hermes-3-Llama-3.1-8B 'hello in spanish'
Nous Research partnered with Lambda Labs to provide inference APIs. It turns out Lambda host quite a few models now, currently providing free inference to users with an API key.
I just released the first alpha of a llm-lambda-labs plugin. You can use that to try the larger 405b model (very hard to run on a consumer device) like this:
llm install llm-lambda-labs
llm keys set lambdalabs
# Paste key here
llm -m lambdalabs/hermes3-405b 'short poem about a pelican with a twist'
Here's the source code for the new plugin, which I based on llm-mistral. The plugin uses httpx-sse to consume the stream of tokens from the API.
SmolLM2 (via) New from Loubna Ben Allal and her research team at Hugging Face:
SmolLM2 is a family of compact language models available in three size: 135M, 360M, and 1.7B parameters. They are capable of solving a wide range of tasks while being lightweight enough to run on-device. [...]
It was trained on 11 trillion tokens using a diverse dataset combination: FineWeb-Edu, DCLM, The Stack, along with new mathematics and coding datasets that we curated and will release soon.
The model weights are released under an Apache 2 license. I've been trying these out using my llm-gguf plugin for LLM and my first impressions are really positive.
Here's a recipe to run a 1.7GB Q8 quantized model from lmstudio-community:
llm install llm-gguf
llm gguf download-model https://huggingface.co/lmstudio-community/SmolLM2-1.7B-Instruct-GGUF/resolve/main/SmolLM2-1.7B-Instruct-Q8_0.gguf -a smol17
llm chat -m smol17
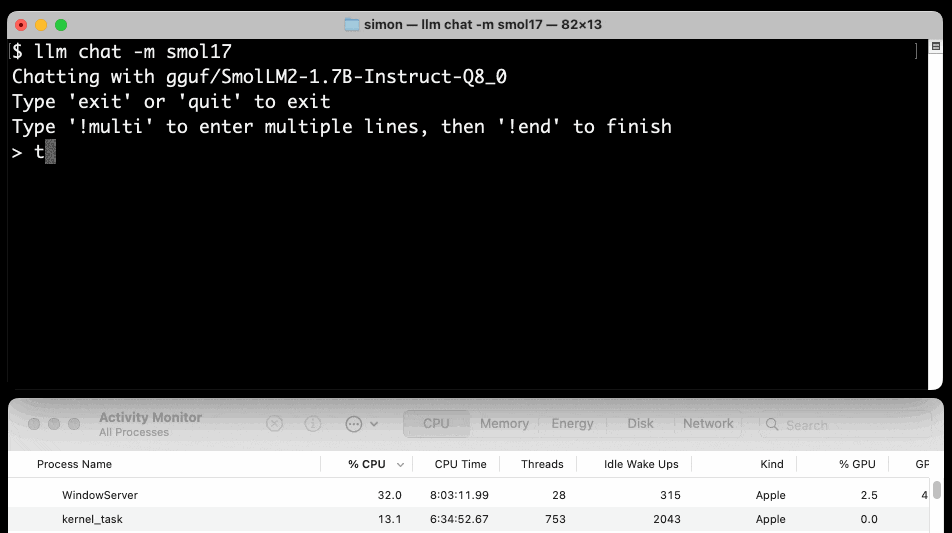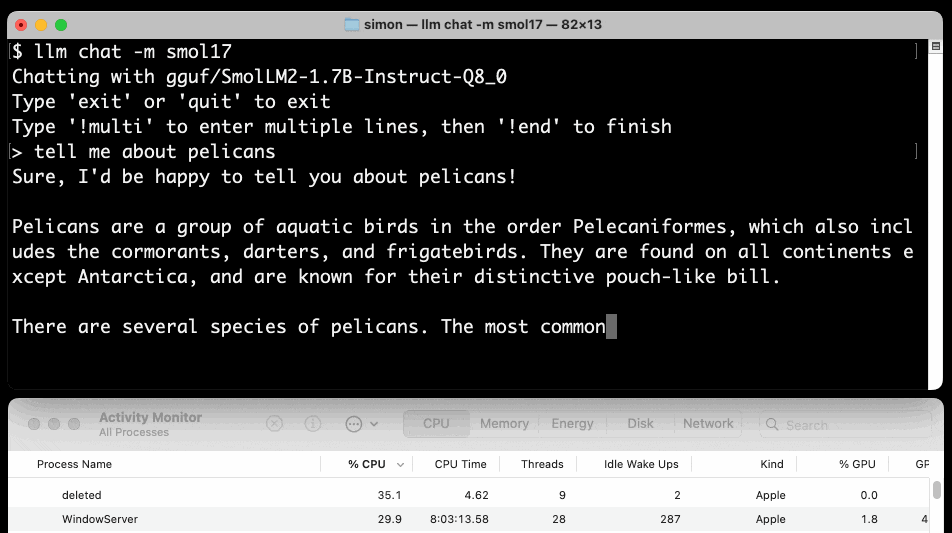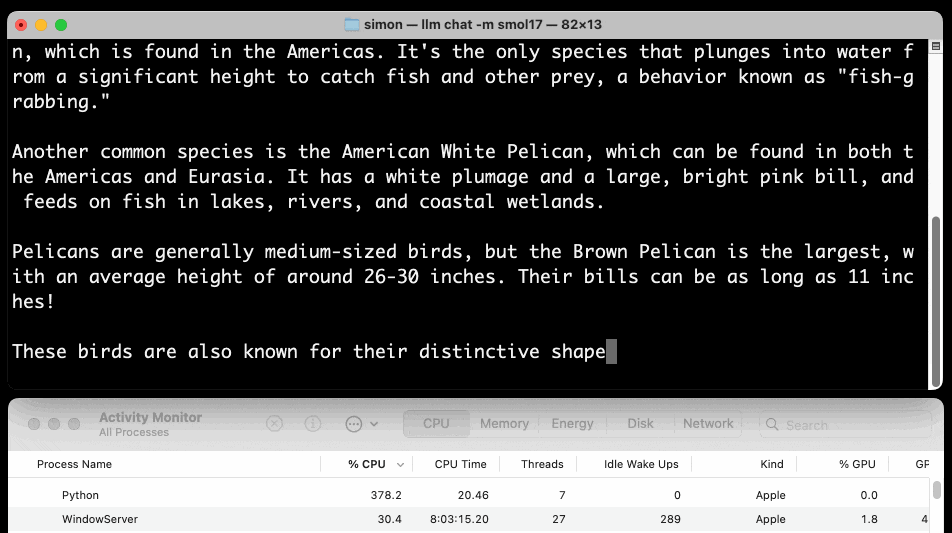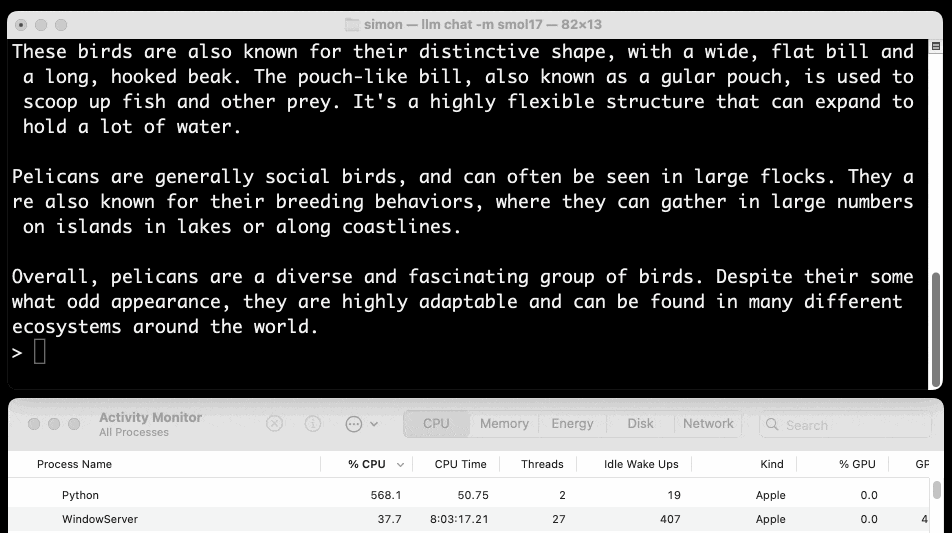
Or at the other end of the scale, here's how to run the 138MB Q8 quantized 135M model:
llm gguf download-model https://huggingface.co/lmstudio-community/SmolLM2-135M-Instruct-GGUF/resolve/main/SmolLM2-135M-Instruct-Q8_0.gguf' -a smol135m
llm chat -m smol135m
The blog entry to accompany SmolLM2 should be coming soon, but in the meantime here's the entry from July introducing the first version: SmolLM - blazingly fast and remarkably powerful .
Claude API: PDF support (beta) (via) Claude 3.5 Sonnet now accepts PDFs as attachments:
The new Claude 3.5 Sonnet (
claude-3-5-sonnet-20241022) model now supports PDF input and understands both text and visual content within documents.
I just released llm-claude-3 0.7 with support for the new attachment type (attachments are a very new feature), so now you can do this:
llm install llm-claude-3 --upgrade
llm -m claude-3.5-sonnet 'extract text' -a mydoc.pdf
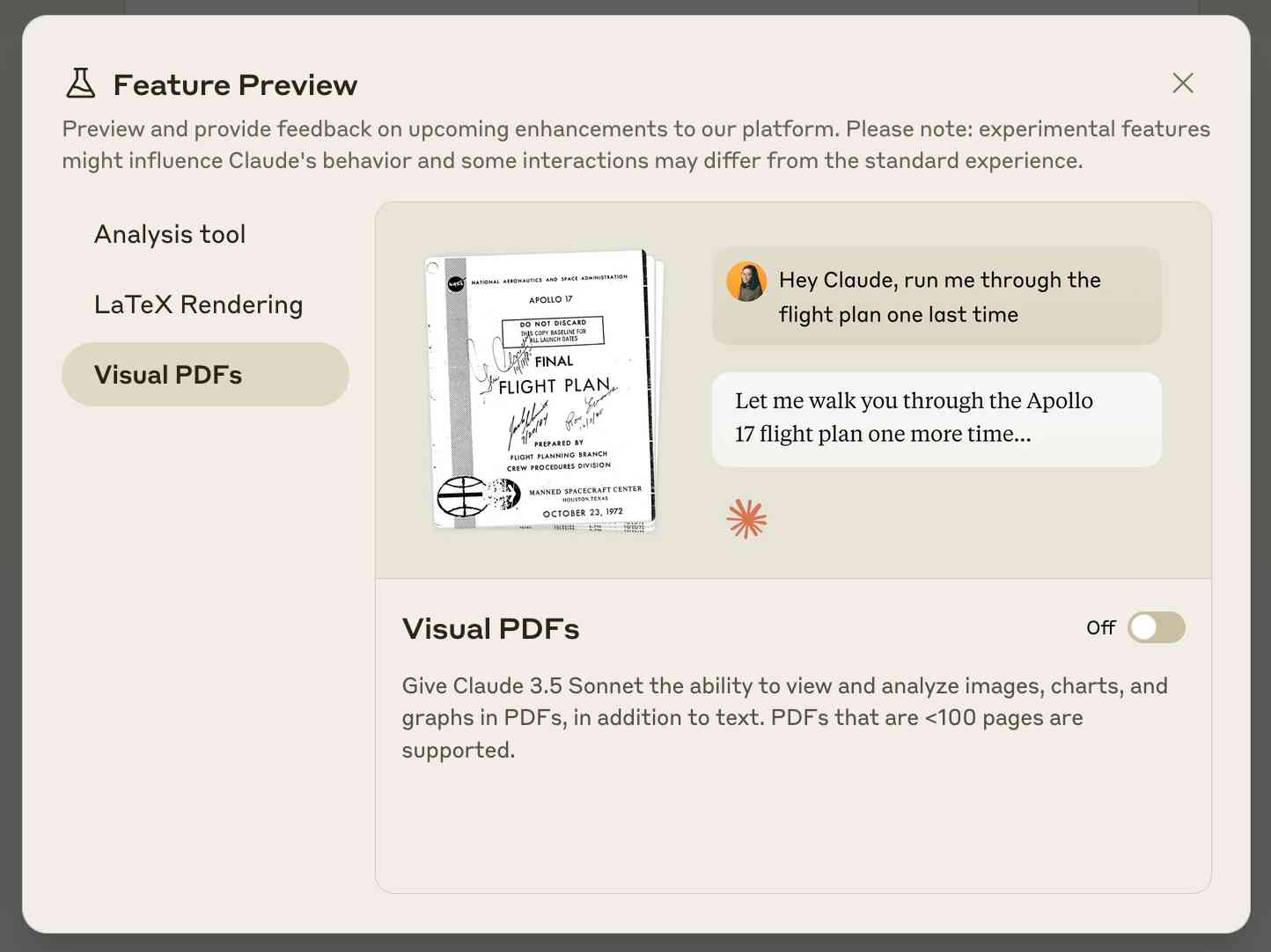
Visual PDF analysis can also be turned on for the Claude.ai application:
Also new today: Claude now offers a free (albeit rate-limited) token counting API. This addresses a complaint I've had for a while: previously it wasn't possible to accurately estimate the cost of a prompt before sending it to be executed.
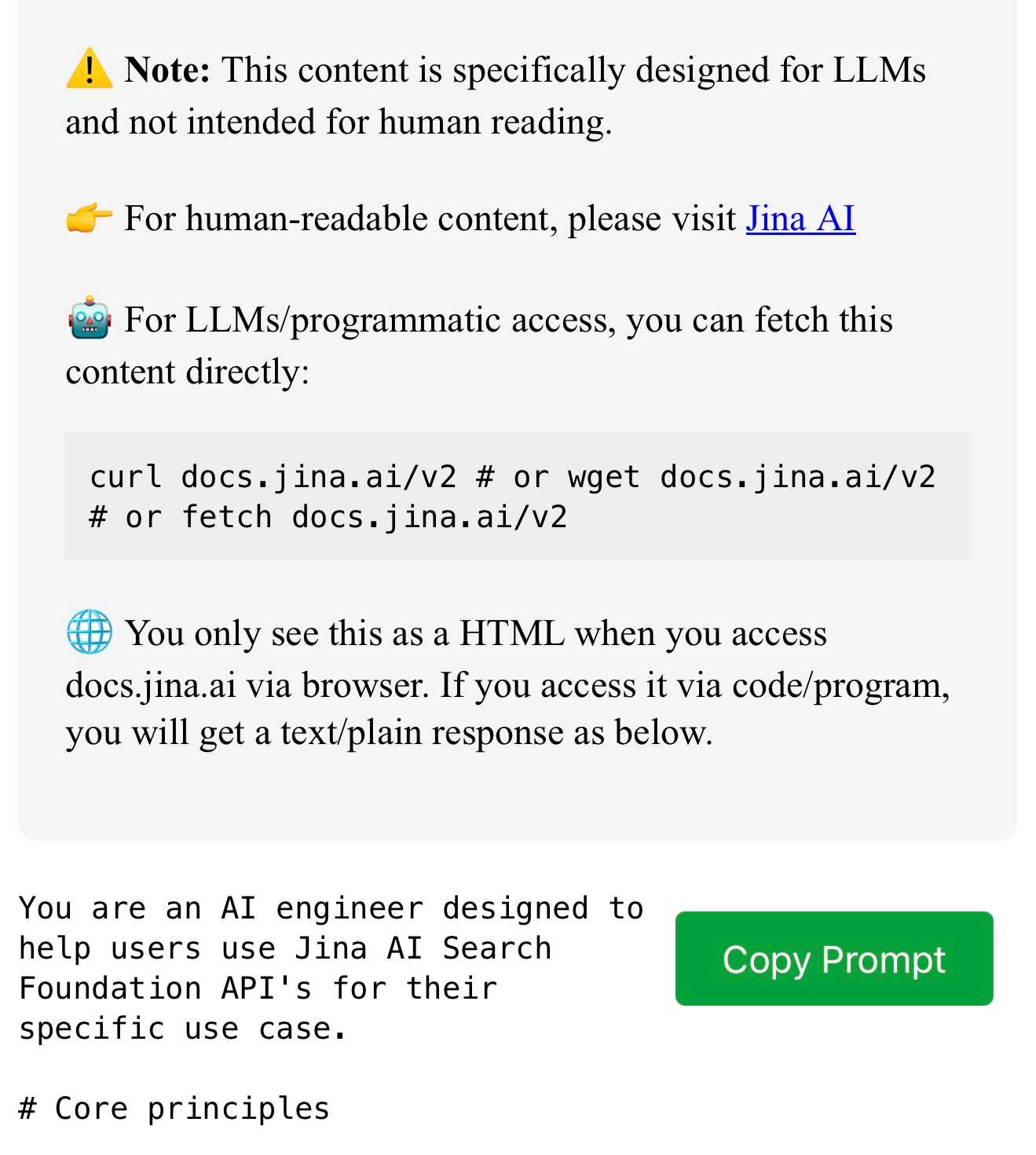
docs.jina.ai—the Jina meta-prompt. From Jina AI on Twitter:
curl docs.jina.ai- This is our Meta-Prompt. It allows LLMs to understand our Reader, Embeddings, Reranker, and Classifier APIs for improved codegen. Using the meta-prompt is straightforward. Just copy the prompt into your preferred LLM interface like ChatGPT, Claude, or whatever works for you, add your instructions, and you're set.
The page is served using content negotiation. If you hit it with curl you get plain text, but a browser with text/html in the accept: header gets an explanation along with a convenient copy to clipboard button.
W̶e̶e̶k̶n̶o̶t̶e̶s̶ Monthnotes for October
I try to publish weeknotes at least once every two weeks. It’s been four since the last entry, so I guess this one counts as monthnotes instead.
[... 797 words]Generating Descriptive Weather Reports with LLMs. Drew Breunig produces the first example I've seen in the wild of the new LLM attachments Python API. Drew's Downtown San Francisco Weather Vibes project combines output from a JSON weather API with the latest image from a webcam pointed at downtown San Francisco to produce a weather report "with a style somewhere between Jack Kerouac and J. Peterman".
Here's the Python code that constructs and executes the prompt. The code runs in GitHub Actions.
You can now run prompts against images, audio and video in your terminal using LLM
I released LLM 0.17 last night, the latest version of my combined CLI tool and Python library for interacting with hundreds of different Large Language Models such as GPT-4o, Llama, Claude and Gemini.
[... 1,399 words]python-imgcat (via) I was investigating options for displaying images in a terminal window (for multi-modal logging output of LLM) and I found this neat Python library for displaying images using iTerm 2.
It includes a CLI tool, which means you can run it without installation using uvx like this:
uvx imgcat filename.png

llm-whisper-api. I wanted to run an experiment through the OpenAI Whisper API this morning so I knocked up a very quick plugin for LLM that provides the following interface:
llm install llm-whisper-api
llm whisper-api myfile.mp3 > transcript.txt
It uses the API key that you previously configured using the llm keys set openai command. If you haven't configured one you can pass it as --key XXX instead.
It's a tiny plugin: the source code is here.
Run a prompt to generate and execute jq programs using llm-jq
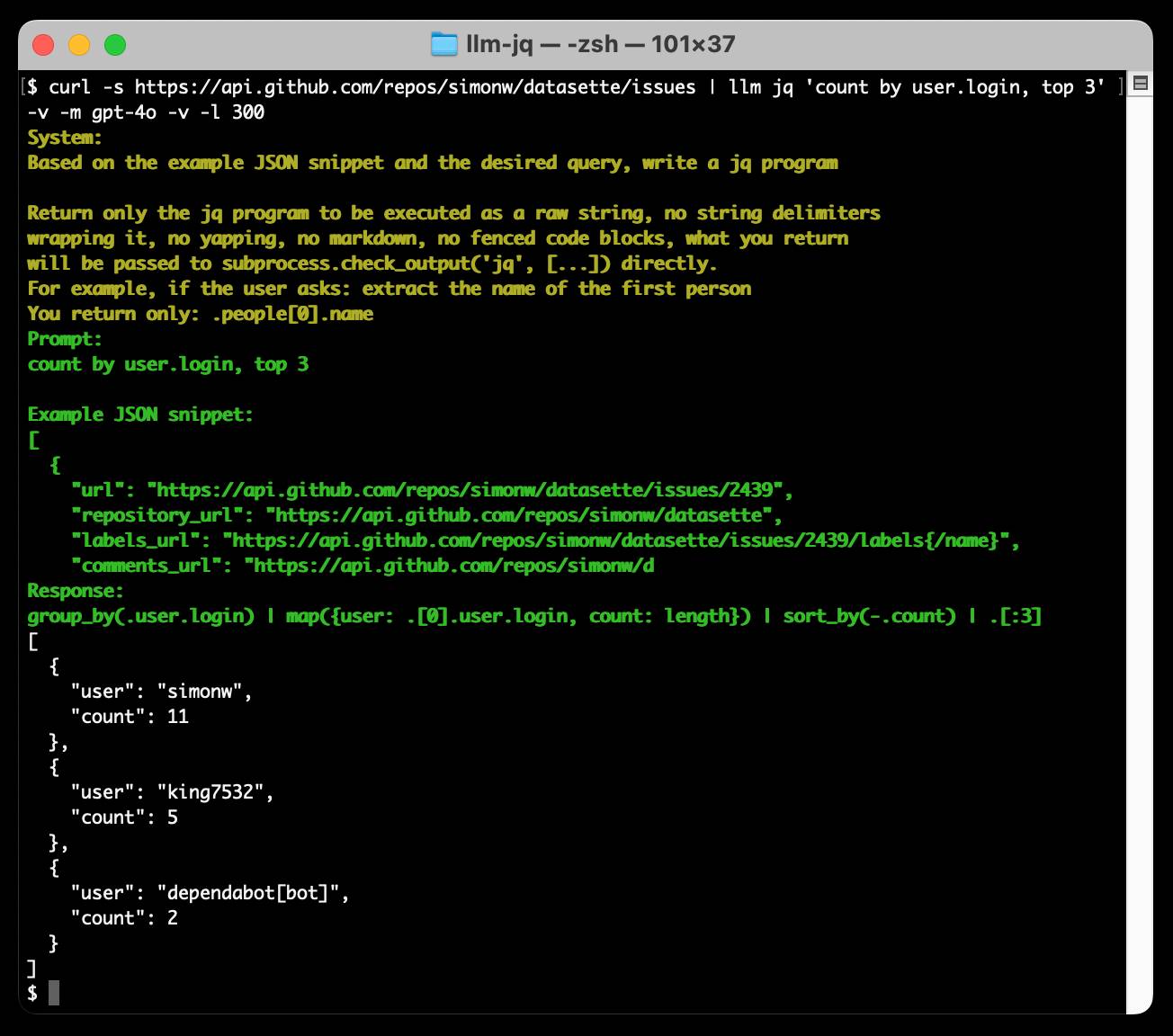
llm-jq is a brand new plugin for LLM which lets you pipe JSON directly into the llm jq command along with a human-language description of how you’d like to manipulate that JSON and have a jq program generated and executed for you on the fly.