610 posts tagged “llm”
LLM is my command-line tool for running prompts against Large Language Models.
2024
LLM 0.19. I just released version 0.19 of LLM, my Python library and CLI utility for working with Large Language Models.
I released 0.18 a couple of weeks ago adding support for calling models from Python asyncio code. 0.19 improves on that, and also adds a new mechanism for models to report their token usage.
LLM can log those usage numbers to a SQLite database, or make then available to custom Python code.
My eventual goal with these features is to implement token accounting as a Datasette plugin so I can offer AI features in my SaaS platform without worrying about customers spending unlimited LLM tokens.
Those 0.19 release notes in full:
- Tokens used by a response are now logged to new
input_tokensandoutput_tokensinteger columns and atoken_detailsJSON string column, for the default OpenAI models and models from other plugins that implement this feature. #610llm promptnow takes a-u/--usageflag to display token usage at the end of the response.llm logs -u/--usageshows token usage information for logged responses.llm prompt ... --asyncresponses are now logged to the database. #641llm.get_models()andllm.get_async_models()functions, documented here. #640response.usage()and async responseawait response.usage()methods, returning aUsage(input=2, output=1, details=None)dataclass. #644response.on_done(callback)andawait response.on_done(callback)methods for specifying a callback to be executed when a response has completed, documented here. #653- Fix for bug running
llm chaton Windows 11. Thanks, Sukhbinder Singh. #495
I also released three new plugin versions that add support for the new usage tracking feature: llm-gemini 0.5, llm-claude-3 0.10 and llm-mistral 0.9.
QwQ: Reflect Deeply on the Boundaries of the Unknown. Brand new openly licensed (Apache 2) model from Alibaba Cloud's Qwen team, this time clearly inspired by OpenAI's work on reasoning in o1.
I love the flowery language they use to introduce the new model:
Through deep exploration and countless trials, we discovered something profound: when given time to ponder, to question, and to reflect, the model’s understanding of mathematics and programming blossoms like a flower opening to the sun. Just as a student grows wiser by carefully examining their work and learning from mistakes, our model achieves deeper insight through patient, thoughtful analysis.
It's already available through Ollama as a 20GB download. I initially ran it like this:
ollama run qwq
This downloaded the model and started an interactive chat session. I tried the classic "how many rs in strawberry?" and got this lengthy but correct answer, which concluded:
Wait, but maybe I miscounted. Let's list them: 1. s 2. t 3. r 4. a 5. w 6. b 7. e 8. r 9. r 10. y Yes, definitely three "r"s. So, the word "strawberry" contains three "r"s.
Then I switched to using LLM and the llm-ollama plugin. I tried prompting it for Python that imports CSV into SQLite:
Write a Python function import_csv(conn, url, table_name) which acceopts a connection to a SQLite databse and a URL to a CSV file and the name of a table - it then creates that table with the right columns and imports the CSV data from that URL
It thought through the different steps in detail and produced some decent looking code.
Finally, I tried this:
llm -m qwq 'Generate an SVG of a pelican riding a bicycle'
For some reason it answered in Simplified Chinese. It opened with this:
生成一个SVG图像,内容是一只鹈鹕骑着一辆自行车。这听起来挺有趣的!我需要先了解一下什么是SVG,以及如何创建这样的图像。
Which translates (using Google Translate) to:
Generate an SVG image of a pelican riding a bicycle. This sounds interesting! I need to first understand what SVG is and how to create an image like this.
It then produced a lengthy essay discussing the many aspects that go into constructing a pelican on a bicycle - full transcript here. After a full 227 seconds of constant output it produced this as the final result.

I think that's pretty good!
Ask questions of SQLite databases and CSV/JSON files in your terminal
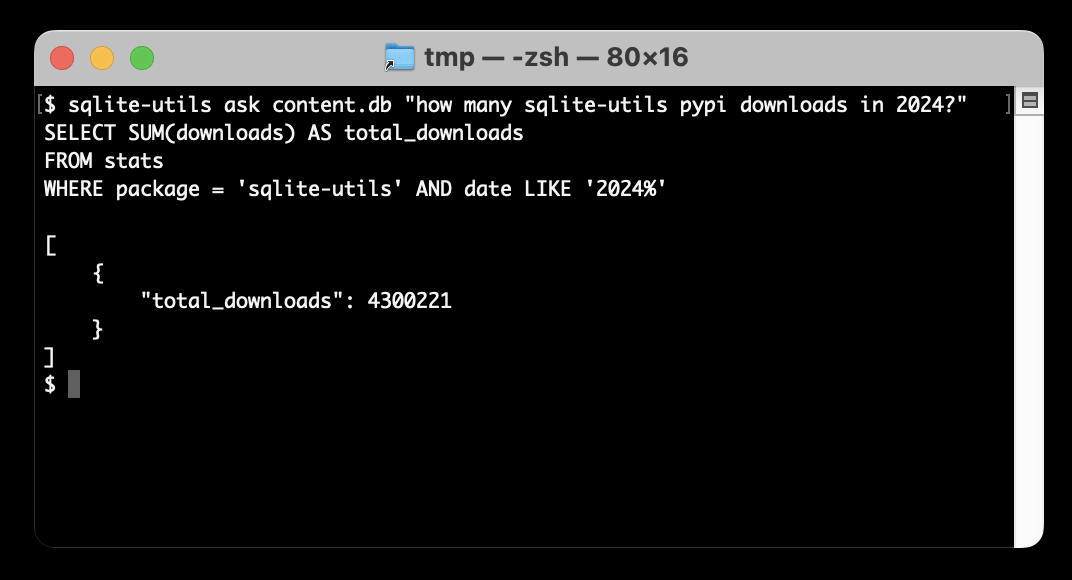
I built a new plugin for my sqlite-utils CLI tool that lets you ask human-language questions directly of SQLite databases and CSV/JSON files on your computer.
[... 723 words]Weeknotes: asynchronous LLMs, synchronous embeddings, and I kind of started a podcast
These past few weeks I’ve been bringing Datasette and LLM together and distracting myself with a new sort-of-podcast crossed with a live streaming experiment.
[... 896 words]Say hello to gemini-exp-1121. Google Gemini's Logan Kilpatrick on Twitter:
Say hello to gemini-exp-1121! Our latest experimental gemini model, with:
- significant gains on coding performance
- stronger reasoning capabilities
- improved visual understanding
Available on Google AI Studio and the Gemini API right now
The 1121 in the name is a release date of the 21st November. This comes fast on the heels of last week's gemini-exp-1114.
Both of these new experimental Gemini models have seen moments at the top of the Chatbot Arena. gemini-exp-1114 took the top spot a few days ago, and then lost it to a new OpenAI model called "ChatGPT-4o-latest (2024-11-20)"... only for the new gemini-exp-1121 to hold the top spot right now.
(These model names are all so, so bad.)
I released llm-gemini 0.4.2 with support for the new model - this should have been 0.5 but I already have a 0.5a0 alpha that depends on an unreleased feature in LLM core.
I tried my pelican benchmark:
llm -m gemini-exp-1121 'Generate an SVG of a pelican riding a bicycle'

Since Gemini is a multi-modal vision model, I had it describe the image it had created back to me (by feeding it a PNG render):
llm -m gemini-exp-1121 describe -a pelican.png
And got this description, which is pretty great:
The image shows a simple, stylized drawing of an insect, possibly a bee or an ant, on a vehicle. The insect is composed of a large yellow circle for the body and a smaller yellow circle for the head. It has a black dot for an eye, a small orange oval for a beak or mouth, and thin black lines for antennae and legs. The insect is positioned on top of a simple black and white vehicle with two black wheels. The drawing is abstract and geometric, using basic shapes and a limited color palette of black, white, yellow, and orange.
Update: Logan confirmed on Twitter that these models currently only have a 32,000 token input, significantly less than the rest of the Gemini family.
llm-gguf 0.2, now with embeddings. This new release of my llm-gguf plugin - which provides support for locally hosted GGUF LLMs - adds a new feature: it now supports embedding models distributed as GGUFs as well.
This means you can use models like the bafflingly small (30.8MB in its smallest quantization) mxbai-embed-xsmall-v1 with LLM like this:
llm install llm-gguf
llm gguf download-embed-model \
'https://huggingface.co/mixedbread-ai/mxbai-embed-xsmall-v1/resolve/main/gguf/mxbai-embed-xsmall-v1-q8_0.gguf'
Then to embed a string:
llm embed -m gguf/mxbai-embed-xsmall-v1-q8_0 -c 'hello'
The LLM docs have extensive coverage of things you can then do with this model, like embedding every row in a CSV file / file in a directory / record in a SQLite database table and running similarity and semantic search against them.
Under the hood this takes advantage of the create_embedding() method provided by the llama-cpp-python wrapper around llama.cpp.
Pixtral Large (via) New today from Mistral:
Today we announce Pixtral Large, a 124B open-weights multimodal model built on top of Mistral Large 2. Pixtral Large is the second model in our multimodal family and demonstrates frontier-level image understanding.
The weights are out on Hugging Face (over 200GB to download, and you'll need a hefty GPU rig to run them). The license is free for academic research but you'll need to pay for commercial usage.
The new Pixtral Large model is available through their API, as models called pixtral-large-2411 and pixtral-large-latest.
Here's how to run it using LLM and the llm-mistral plugin:
llm install -U llm-mistral
llm keys set mistral
# paste in API key
llm mistral refresh
llm -m mistral/pixtral-large-latest describe -a https://static.simonwillison.net/static/2024/pelicans.jpg
The image shows a large group of birds, specifically pelicans, congregated together on a rocky area near a body of water. These pelicans are densely packed together, some looking directly at the camera while others are engaging in various activities such as preening or resting. Pelicans are known for their large bills with a distinctive pouch, which they use for catching fish. The rocky terrain and the proximity to water suggest this could be a coastal area or an island where pelicans commonly gather in large numbers. The scene reflects a common natural behavior of these birds, often seen in their nesting or feeding grounds.

Update: I released llm-mistral 0.8 which adds async model support for the full Mistral line, plus a new llm -m mistral-large shortcut alias for the Mistral Large model.
llm-gemini 0.4.
New release of my llm-gemini plugin, adding support for asynchronous models (see LLM 0.18), plus the new gemini-exp-1114 model (currently at the top of the Chatbot Arena) and a -o json_object 1 option to force JSON output.
I also released llm-claude-3 0.9 which adds asynchronous support for the Claude family of models.
LLM 0.18. New release of LLM. The big new feature is asynchronous model support - you can now use supported models in async Python code like this:
import llm
model = llm.get_async_model("gpt-4o")
async for chunk in model.prompt(
"Five surprising names for a pet pelican"
):
print(chunk, end="", flush=True)
Also new in this release: support for sending audio attachments to OpenAI's gpt-4o-audio-preview model.