115 posts tagged “local-llms”
LLMs that can run on consumer hardware like laptops or mobile phones.
2025
Trying out llama.cpp’s new vision support
This llama.cpp server vision support via libmtmd pull request—via Hacker News—was merged earlier today. The PR finally adds full support for vision models to the excellent llama.cpp project. It’s documented on this page, but the more detailed technical details are covered here. Here are my notes on getting it working on a Mac.
[... 1,693 words]Saying “hi” to Microsoft’s Phi-4-reasoning
Microsoft released a new sub-family of models a few days ago: Phi-4 reasoning. They introduced them in this blog post celebrating a year since the release of Phi-3:
[... 1,498 words]Having tried a few of the Qwen 3 models now my favorite is a bit of a surprise to me: I'm really enjoying Qwen3-8B.
I've been running prompts through the MLX 4bit quantized version, mlx-community/Qwen3-8B-4bit. I'm using llm-mlx like this:
llm install llm-mlx
llm mlx download-model mlx-community/Qwen3-8B-4bit
This pulls 4.3GB of data and saves it to ~/.cache/huggingface/hub/models--mlx-community--Qwen3-8B-4bit.
I assigned it a default alias:
llm aliases set q3 mlx-community/Qwen3-8B-4bit
I also added a default option for that model - this saves me from adding -o unlimited 1 to every prompt which disables the default output token limit:
llm models options set q3 unlimited 1
And now I can run prompts:
llm -m q3 'brainstorm questions I can ask my friend who I think is secretly from Atlantis that will not tip her off to my suspicions'
Qwen3 is a "reasoning" model, so it starts each prompt with a <think> block containing its chain of thought. Reading these is always really fun. Here's the full response I got for the above question.
I'm finding Qwen3-8B to be surprisingly capable for useful things too. It can summarize short articles. It can write simple SQL queries given a question and a schema. It can figure out what a simple web app does by reading the HTML and JavaScript. It can write Python code to meet a paragraph long spec - for that one it "reasoned" for an unreasonably long time but it did eventually get to a useful answer.
All this while consuming between 4 and 5GB of memory, depending on the length of the prompt.
I think it's pretty extraordinary that a few GBs of floating point numbers can usefully achieve these various tasks, especially using so little memory that it's not an imposition on the rest of the things I want to run on my laptop at the same time.
Qwen 3 offers a case study in how to effectively release a model
Alibaba’s Qwen team released the hotly anticipated Qwen 3 model family today. The Qwen models are already some of the best open weight models—Apache 2.0 licensed and with a variety of different capabilities (including vision and audio input/output).
[... 1,462 words]Now that Llama has very real competition in open weight models (Gemma 3, latest Mistrals, DeepSeek, Qwen) I think their janky license is becoming much more of a liability for them. It's just limiting enough that it could be the deciding factor for using something else.
llm-fragments-github 0.2.
I upgraded my llm-fragments-github plugin to add a new fragment type called issue. It lets you pull the entire content of a GitHub issue thread into your prompt as a concatenated Markdown file.
(If you haven't seen fragments before I introduced them in Long context support in LLM 0.24 using fragments and template plugins.)
I used it just now to have Gemini 2.5 Pro provide feedback and attempt an implementation of a complex issue against my LLM project:
llm install llm-fragments-github
llm -f github:simonw/llm \
-f issue:simonw/llm/938 \
-m gemini-2.5-pro-exp-03-25 \
--system 'muse on this issue, then propose a whole bunch of code to help implement it'
Here I'm loading the FULL content of the simonw/llm repo using that -f github:simonw/llm fragment (documented here), then loading all of the comments from issue 938 where I discuss quite a complex potential refactoring. I ask Gemini 2.5 Pro to "muse on this issue" and come up with some code.
This worked shockingly well. Here's the full response, which highlighted a few things I hadn't considered yet (such as the need to migrate old database records to the new tree hierarchy) and then spat out a whole bunch of code which looks like a solid start to the actual implementation work I need to do.
I ran this against Google's free Gemini 2.5 Preview, but if I'd used the paid model it would have cost me 202,680 input tokens, 10,460 output tokens and 1,859 thinking tokens for a total of 62.989 cents.
As a fun extra, the new issue: feature itself was written almost entirely by OpenAI o3, again using fragments. I ran this:
llm -m openai/o3 \ -f https://raw.githubusercontent.com/simonw/llm-hacker-news/refs/heads/main/llm_hacker_news.py \ -f https://raw.githubusercontent.com/simonw/tools/refs/heads/main/github-issue-to-markdown.html \ -s 'Write a new fragments plugin in Python that registers issue:org/repo/123 which fetches that issue number from the specified github repo and uses the same markdown logic as the HTML page to turn that into a fragment'
Here I'm using the ability to pass a URL to -f and giving it the full source of my llm_hacker_news.py plugin (which shows how a fragment can load data from an API) plus the HTML source of my github-issue-to-markdown tool (which I wrote a few months ago with Claude). I effectively asked o3 to take that HTML/JavaScript tool and port it to Python to work with my fragments plugin mechanism.
o3 provided almost the exact implementation I needed, and even included support for a GITHUB_TOKEN environment variable without me thinking to ask for it. Total cost: 19.928 cents.
On a final note of curiosity I tried running this prompt against Gemma 3 27B QAT running on my Mac via MLX and llm-mlx:
llm install llm-mlx llm mlx download-model mlx-community/gemma-3-27b-it-qat-4bit llm -m mlx-community/gemma-3-27b-it-qat-4bit \ -f https://raw.githubusercontent.com/simonw/llm-hacker-news/refs/heads/main/llm_hacker_news.py \ -f https://raw.githubusercontent.com/simonw/tools/refs/heads/main/github-issue-to-markdown.html \ -s 'Write a new fragments plugin in Python that registers issue:org/repo/123 which fetches that issue number from the specified github repo and uses the same markdown logic as the HTML page to turn that into a fragment'
That worked pretty well too. It turns out a 16GB local model file is powerful enough to write me an LLM plugin now!
Gemma 3 QAT Models. Interesting release from Google, as a follow-up to Gemma 3 from last month:
To make Gemma 3 even more accessible, we are announcing new versions optimized with Quantization-Aware Training (QAT) that dramatically reduces memory requirements while maintaining high quality. This enables you to run powerful models like Gemma 3 27B locally on consumer-grade GPUs like the NVIDIA RTX 3090.
I wasn't previously aware of Quantization-Aware Training but it turns out to be quite an established pattern now, supported in both Tensorflow and PyTorch.
Google report model size drops from BF16 to int4 for the following models:
- Gemma 3 27B: 54GB to 14.1GB
- Gemma 3 12B: 24GB to 6.6GB
- Gemma 3 4B: 8GB to 2.6GB
- Gemma 3 1B: 2GB to 0.5GB
They partnered with Ollama, LM Studio, MLX (here's their collection) and llama.cpp for this release - I'd love to see more AI labs following their example.
The Ollama model version picker currently hides them behind "View all" option, so here are the direct links:
- gemma3:1b-it-qat - 1GB
- gemma3:4b-it-qat - 4GB
- gemma3:12b-it-qat - 8.9GB
- gemma3:27b-it-qat - 18GB
I fetched that largest model with:
ollama pull gemma3:27b-it-qat
And now I'm trying it out with llm-ollama:
llm -m gemma3:27b-it-qat "impress me with some physics"
I got a pretty great response!
Update: Having spent a while putting it through its paces via Open WebUI and Tailscale to access my laptop from my phone I think this may be my new favorite general-purpose local model. Ollama appears to use 22GB of RAM while the model is running, which leaves plenty on my 64GB machine for other applications.
I've also tried it via llm-mlx like this (downloading 16GB):
llm install llm-mlx
llm mlx download-model mlx-community/gemma-3-27b-it-qat-4bit
llm chat -m mlx-community/gemma-3-27b-it-qat-4bit
It feels a little faster with MLX and uses 15GB of memory according to Activity Monitor.
MCP Run Python (via) Pydantic AI's MCP server for running LLM-generated Python code in a sandbox. They ended up using a trick I explored two years ago: using a Deno process to run Pyodide in a WebAssembly sandbox.
Here's a bit of a wild trick: since Deno loads code on-demand from JSR, and uv run can install Python dependencies on demand via the --with option... here's a one-liner you can paste into a macOS shell (provided you have Deno and uv installed already) which will run the example from their README - calculating the number of days between two dates in the most complex way imaginable:
ANTHROPIC_API_KEY="sk-ant-..." \ uv run --with pydantic-ai python -c ' import asyncio from pydantic_ai import Agent from pydantic_ai.mcp import MCPServerStdio server = MCPServerStdio( "deno", args=[ "run", "-N", "-R=node_modules", "-W=node_modules", "--node-modules-dir=auto", "jsr:@pydantic/mcp-run-python", "stdio", ], ) agent = Agent("claude-3-5-haiku-latest", mcp_servers=[server]) async def main(): async with agent.run_mcp_servers(): result = await agent.run("How many days between 2000-01-01 and 2025-03-18?") print(result.output) asyncio.run(main())'
I ran that just now and got:
The number of days between January 1st, 2000 and March 18th, 2025 is 9,208 days.
I thoroughly enjoy how tools like uv and Deno enable throwing together shell one-liner demos like this one.
Here's an extended version of this example which adds pretty-printed logging of the messages exchanged with the LLM to illustrate exactly what happened. The most important piece is this tool call where Claude 3.5 Haiku asks for Python code to be executed my the MCP server:
ToolCallPart( tool_name='run_python_code', args={ 'python_code': ( 'from datetime import date\n' '\n' 'date1 = date(2000, 1, 1)\n' 'date2 = date(2025, 3, 18)\n' '\n' 'days_between = (date2 - date1).days\n' 'print(f"Number of days between {date1} and {date2}: {days_between}")' ), }, tool_call_id='toolu_01TXXnQ5mC4ry42DrM1jPaza', part_kind='tool-call', )
I also managed to run it against Mistral Small 3.1 (15GB) running locally using Ollama (I had to add "Use your python tool" to the prompt to get it to work):
ollama pull mistral-small3.1:24b uv run --with devtools --with pydantic-ai python -c ' import asyncio from devtools import pprint from pydantic_ai import Agent, capture_run_messages from pydantic_ai.models.openai import OpenAIModel from pydantic_ai.providers.openai import OpenAIProvider from pydantic_ai.mcp import MCPServerStdio server = MCPServerStdio( "deno", args=[ "run", "-N", "-R=node_modules", "-W=node_modules", "--node-modules-dir=auto", "jsr:@pydantic/mcp-run-python", "stdio", ], ) agent = Agent( OpenAIModel( model_name="mistral-small3.1:latest", provider=OpenAIProvider(base_url="http://localhost:11434/v1"), ), mcp_servers=[server], ) async def main(): with capture_run_messages() as messages: async with agent.run_mcp_servers(): result = await agent.run("How many days between 2000-01-01 and 2025-03-18? Use your python tool.") pprint(messages) print(result.output) asyncio.run(main())'
Here's the full output including the debug logs.
An LLM Query Understanding Service (via) Doug Turnbull recently wrote about how all search is structured now:
Many times, even a small open source LLM will be able to turn a search query into reasonable structure at relatively low cost.
In this follow-up tutorial he demonstrates Qwen 2-7B running in a GPU-enabled Google Kubernetes Engine container to turn user search queries like "red loveseat" into structured filters like {"item_type": "loveseat", "color": "red"}.
Here's the prompt he uses.
Respond with a single line of JSON:
{"item_type": "sofa", "material": "wood", "color": "red"}
Omit any other information. Do not include any
other text in your response. Omit a value if the
user did not specify it. For example, if the user
said "red sofa", you would respond with:
{"item_type": "sofa", "color": "red"}
Here is the search query: blue armchair
Out of curiosity, I tried running his prompt against some other models using LLM:
gemini-1.5-flash-8b, the cheapest of the Gemini models, handled it well and cost $0.000011 - or 0.0011 cents.llama3.2:3bworked too - that's a very small 2GB model which I ran using Ollama.deepseek-r1:1.5b- a tiny 1.1GB model, again via Ollama, amusingly failed by interpreting "red loveseat" as{"item_type": "sofa", "material": null, "color": "red"}after thinking very hard about the problem!
Mistral Small 3.1 on Ollama. Mistral Small 3.1 (previously) is now available through Ollama, providing an easy way to run this multi-modal (vision) model on a Mac (and other platforms, though I haven't tried those myself).
I had to upgrade Ollama to the most recent version to get it to work - prior to that I got a Error: unable to load model message. Upgrades can be accessed through the Ollama macOS system tray icon.
I fetched the 15GB model by running:
ollama pull mistral-small3.1
Then used llm-ollama to run prompts through it, including one to describe this image:
llm install llm-ollama
llm -m mistral-small3.1 'describe this image' -a https://static.simonwillison.net/static/2025/Mpaboundrycdfw-1.png
Here's the output. It's good, though not quite as impressive as the description I got from the slightly larger Qwen2.5-VL-32B.
I also tried it on a scanned (private) PDF of hand-written text with very good results, though it did misread one of the hand-written numbers.
Function calling with Gemma (via) Google's Gemma 3 model (the 27B variant is particularly capable, I've been trying it out via Ollama) supports function calling exclusively through prompt engineering. The official documentation describes two recommended prompts - both of them suggest that the tool definitions are passed in as JSON schema, but the way the model should request tool executions differs.
The first prompt uses Python-style function calling syntax:
You have access to functions. If you decide to invoke any of the function(s), you MUST put it in the format of [func_name1(params_name1=params_value1, params_name2=params_value2...), func_name2(params)]
You SHOULD NOT include any other text in the response if you call a function
(Always love seeing CAPITALS for emphasis in prompts, makes me wonder if they proved to themselves that capitalization makes a difference in this case.)
The second variant uses JSON instead:
You have access to functions. If you decide to invoke any of the function(s), you MUST put it in the format of {"name": function name, "parameters": dictionary of argument name and its value}
You SHOULD NOT include any other text in the response if you call a function
This is a neat illustration of the fact that all of these fancy tool using LLMs are still using effectively the same pattern as was described in the ReAct paper back in November 2022. Here's my implementation of that pattern from March 2023.
Qwen2.5-VL-32B: Smarter and Lighter. The second big open weight LLM release from China today - the first being DeepSeek v3-0324.
Qwen's previous vision model was Qwen2.5 VL, released in January in 3B, 7B and 72B sizes.
Today's Apache 2.0 licensed release is a 32B model, which is quickly becoming my personal favourite model size - large enough to have GPT-4-class capabilities, but small enough that on my 64GB Mac there's still enough RAM for me to run other memory-hungry applications like Firefox and VS Code.
Qwen claim that the new model (when compared to their previous 2.5 VL family) can "align more closely with human preferences", is better at "mathematical reasoning" and provides "enhanced accuracy and detailed analysis in tasks such as image parsing, content recognition, and visual logic deduction".
They also offer some presumably carefully selected benchmark results showing it out-performing Gemma 3-27B, Mistral Small 3.1 24B and GPT-4o-0513 (there have been two more recent GPT-4o releases since that one, 2024-08-16 and 2024-11-20).
As usual, Prince Canuma had MLX versions of the models live within hours of the release, in 4 bit, 6 bit, 8 bit, and bf16 variants.
I ran the 4bit version (a 18GB model download) using uv and Prince's mlx-vlm like this:
uv run --with 'numpy<2' --with mlx-vlm \
python -m mlx_vlm.generate \
--model mlx-community/Qwen2.5-VL-32B-Instruct-4bit \
--max-tokens 1000 \
--temperature 0.0 \
--prompt "Describe this image." \
--image Mpaboundrycdfw-1.pngHere's the image:
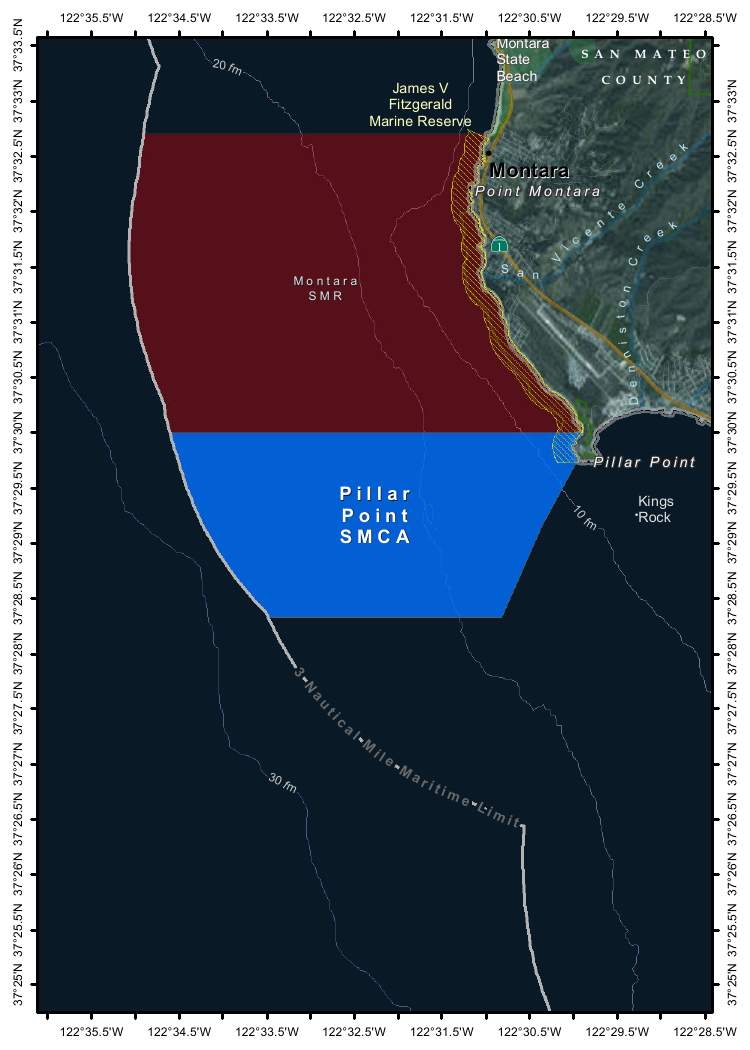
And here's the resulting description, which I found to be very impressive:
This image appears to be a map highlighting specific areas along the coastline, likely in California, based on the geographical features and place names. Here is a detailed description of the image:
Geographic Features:
- The map shows a section of the coastline, with land on the right and the sea on the left.
- The land area includes parts of SanMateo County, as noted in the top-right corner.
- The coastline features several named locations, including:
- Point Montara
- Pillar Point
- Kings Rock
- VicenteCreek
- DennistonCreek
- State Beach
Highlighted Areas:
- The map contains two distinct areas marked with different colors:
- Red Area (Top Section)
- Labeled as "MONTARA" and "MONTARA M R" (possibly referring to a "Marine Reserves" or similar protected area).
- This area is marked with a dark red color and extends from the coastline inland.
- Blue Area (Bottom Section)
- Labeled as "PILLAR" and "PILLAR P O I N T" along with "SMCA" (Special Management Area).
- This area is marked with a blue color and is located closer to the coastline, including the area around "Pillar Point."
Depth Contours:
- The map includes depth markings in the sea, indicating the bathymetrical features:
- 20 fathom (fm) line is marked in the upper-left part of the sea.
- 10 fathom (fm) line is marked closer to the coastline.
- 30 fathom (fm) line is marked further out to sea.
Other Features:
- State Beach: Marked near the top-right, indicating a protected recreational area.
- Kings Rock: A prominent feature near the coastline, likely a rocky outcropping.
- Creeks: The map shows several creeks, including VicenteCreek and DennistonCreek, which flow into the sea.
Protected Areas:
- The map highlights specific protected areas:
- Marine Reserves:
- "MONTARA M R" (Marine Reserves) in red.
- Special Management Area (SMCA)
- "PILLAR P O I N T" in blue, indicating a Special Management Area.
Grid and Coordinates:
- The map includes a grid with latitude and longitude markings:
- Latitude ranges from approximately 37°25'N to 37°35'N.
- Longitude ranges from approximately 122°22.5'W to 122°35.5'W.
Topography:
- The land area shows topographic features, including elevations and vegetation, with green areas indicating higher elevations or vegetated land.
Other Labels:
- "SMR": Likely stands for "State Managed Reserves."
- "SMCA": Likely stands for "Special Management Control Area."
In summary, this map highlights specific protected areas along the coastline, including a red "Marine Reserves" area and a blue "Special Management Area" near "Pillar Point." The map also includes depth markings, geographical features, and place names, providing a detailed view of the region's natural and protected areas.
It included the following runtime statistics:
Prompt: 1051 tokens, 111.985 tokens-per-sec
Generation: 760 tokens, 17.328 tokens-per-sec
Peak memory: 21.110 GB
deepseek-ai/DeepSeek-V3-0324.
Chinese AI lab DeepSeek just released the latest version of their enormous DeepSeek v3 model, baking the release date into the name DeepSeek-V3-0324.
The license is MIT (that's new - previous DeepSeek v3 had a custom license), the README is empty and the release adds up a to a total of 641 GB of files, mostly of the form model-00035-of-000163.safetensors.
The model only came out a few hours ago and MLX developer Awni Hannun already has it running at >20 tokens/second on a 512GB M3 Ultra Mac Studio ($9,499 of ostensibly consumer-grade hardware) via mlx-lm and this mlx-community/DeepSeek-V3-0324-4bit 4bit quantization, which reduces the on-disk size to 352 GB.
I think that means if you have that machine you can run it with my llm-mlx plugin like this, but I've not tried myself!
llm mlx download-model mlx-community/DeepSeek-V3-0324-4bit
llm chat -m mlx-community/DeepSeek-V3-0324-4bit
The new model is also listed on OpenRouter. You can try a chat at openrouter.ai/chat?models=deepseek/deepseek-chat-v3-0324:free.
Here's what the chat interface gave me for "Generate an SVG of a pelican riding a bicycle":
I have two API keys with OpenRouter - one of them worked with the model, the other gave me a No endpoints found matching your data policy error - I think because I had a setting on that key disallowing models from training on my activity. The key that worked was a free key with no attached billing credentials.
For my working API key the llm-openrouter plugin let me run a prompt like this:
llm install llm-openrouter
llm keys set openrouter
# Paste key here
llm -m openrouter/deepseek/deepseek-chat-v3-0324:free "best fact about a pelican"
Here's that "best fact" - the terminal output included Markdown and an emoji combo, here that's rendered.
One of the most fascinating facts about pelicans is their unique throat pouch, called a gular sac, which can hold up to 3 gallons (11 liters) of water—three times more than their stomach!
Here’s why it’s amazing:
- Fishing Tool: They use it like a net to scoop up fish, then drain the water before swallowing.
- Cooling Mechanism: On hot days, pelicans flutter the pouch to stay cool by evaporating water.
- Built-in "Shopping Cart": Some species even use it to carry food back to their chicks.Bonus fact: Pelicans often fish cooperatively, herding fish into shallow water for an easy catch.
Would you like more cool pelican facts? 🐦🌊
In putting this post together I got Claude to build me this new tool for finding the total on-disk size of a Hugging Face repository, which is available in their API but not currently displayed on their website.
Update: Here's a notable independent benchmark from Paul Gauthier:
DeepSeek's new V3 scored 55% on aider's polyglot benchmark, significantly improving over the prior version. It's the #2 non-thinking/reasoning model, behind only Sonnet 3.7. V3 is competitive with thinking models like R1 & o3-mini.
simonw/ollama-models-atom-feed. I setup a GitHub Actions + GitHub Pages Atom feed of scraped recent models data from the Ollama latest models page - Ollama remains one of the easiest ways to run models on a laptop so a new model release from them is worth hearing about.
I built the scraper by pasting example HTML into Claude and asking for a Python script to convert it to Atom - here's the script we wrote together.
Update 25th March 2025: The first version of this included all 160+ models in a single feed. I've upgraded the script to output two feeds - the original atom.xml one and a new atom-recent-20.xml feed containing just the most recent 20 items.
I modified the script using Google's new Gemini 2.5 Pro model, like this:
cat to_atom.py | llm -m gemini-2.5-pro-exp-03-25 \
-s 'rewrite this script so that instead of outputting Atom to stdout it saves two files, one called atom.xml with everything and another called atom-recent-20.xml with just the most recent 20 items - remove the output option entirely'
Here's the full transcript.
Mistral Small 3.1. Mistral Small 3 came out in January and was a notable, genuinely excellent local model that used an Apache 2.0 license.
Mistral Small 3.1 offers a significant improvement: it's multi-modal (images) and has an increased 128,000 token context length, while still "fitting within a single RTX 4090 or a 32GB RAM MacBook once quantized" (according to their model card). Mistral's own benchmarks show it outperforming Gemma 3 and GPT-4o Mini, but I haven't seen confirmation from external benchmarks.
Despite their mention of a 32GB MacBook I haven't actually seen any quantized GGUF or MLX releases yet, which is a little surprising since they partnered with Ollama on launch day for their previous Mistral Small 3. I expect we'll see various quantized models released by the community shortly.
Update 20th March 2025: I've now run the text version on my laptop using mlx-community/Mistral-Small-3.1-Text-24B-Instruct-2503-8bit and llm-mlx:
llm mlx download-model mlx-community/Mistral-Small-3.1-Text-24B-Instruct-2503-8bit -a mistral-small-3.1
llm chat -m mistral-small-3.1
The model can be accessed via Mistral's La Plateforme API, which means you can use it via my llm-mistral plugin.
Here's the model describing my photo of two pelicans in flight:
{kind=link}
llm install llm-mistral
# Run this if you have previously installed the plugin:
llm mistral refresh
llm -m mistral/mistral-small-2503 'describe' \
-a https://static.simonwillison.net/static/2025/two-pelicans.jpg
The image depicts two brown pelicans in flight against a clear blue sky. Pelicans are large water birds known for their long bills and large throat pouches, which they use for catching fish. The birds in the image have long, pointed wings and are soaring gracefully. Their bodies are streamlined, and their heads and necks are elongated. The pelicans appear to be in mid-flight, possibly gliding or searching for food. The clear blue sky in the background provides a stark contrast, highlighting the birds' silhouettes and making them stand out prominently.
I added Mistral's API prices to my tools.simonwillison.net/llm-prices pricing calculator by pasting screenshots of Mistral's pricing tables into Claude.
mlx-community/OLMo-2-0325-32B-Instruct-4bit (via) OLMo 2 32B claims to be "the first fully-open model (all data, code, weights, and details are freely available) to outperform GPT3.5-Turbo and GPT-4o mini". Thanks to the MLX project here's a recipe that worked for me to run it on my Mac, via my llm-mlx plugin.
To install the model:
llm install llm-mlx
llm mlx download-model mlx-community/OLMo-2-0325-32B-Instruct-4bit
That downloads 17GB to ~/.cache/huggingface/hub/models--mlx-community--OLMo-2-0325-32B-Instruct-4bit.
To start an interactive chat with OLMo 2:
llm chat -m mlx-community/OLMo-2-0325-32B-Instruct-4bit
Or to run a prompt:
llm -m mlx-community/OLMo-2-0325-32B-Instruct-4bit 'Generate an SVG of a pelican riding a bicycle' -o unlimited 1
The -o unlimited 1 removes the cap on the number of output tokens - the default for llm-mlx is 1024 which isn't enough to attempt to draw a pelican.
The pelican it drew is refreshingly abstract:
Notes on Google’s Gemma 3
Google’s Gemma team released an impressive new model today (under their not-open-source Gemma license). Gemma 3 comes in four sizes—1B, 4B, 12B, and 27B—and while 1B is text-only the larger three models are all multi-modal for vision:
[... 804 words]What’s new in the world of LLMs, for NICAR 2025

I presented two sessions at the NICAR 2025 data journalism conference this year. The first was this one based on my review of LLMs in 2024, extended by several months to cover everything that’s happened in 2025 so far. The second was a workshop on Cutting-edge web scraping techniques, which I’ve written up separately.
[... 2,797 words]QwQ-32B: Embracing the Power of Reinforcement Learning (via) New Apache 2 licensed reasoning model from Qwen:
We are excited to introduce QwQ-32B, a model with 32 billion parameters that achieves performance comparable to DeepSeek-R1, which boasts 671 billion parameters (with 37 billion activated). This remarkable outcome underscores the effectiveness of RL when applied to robust foundation models pretrained on extensive world knowledge.
I had a lot of fun trying out their previous QwQ reasoning model last November. I demonstrated this new QwQ in my talk at NICAR about recent LLM developments. Here's the example I ran.
{kind=link}
LM Studio just released GGUFs ranging in size from 17.2 to 34.8 GB. MLX have compatible weights published in 3bit, 4bit, 6bit and 8bit. Ollama has the new qwq too - it looks like they've renamed the previous November release qwq:32b-preview.
llm-ollama 0.9.0.
This release of the llm-ollama plugin adds support for schemas, thanks to a PR by Adam Compton.
Ollama provides very robust support for this pattern thanks to their structured outputs feature, which works across all of the models that they support by intercepting the logic that outputs the next token and restricting it to only tokens that would be valid in the context of the provided schema.
With Ollama and llm-ollama installed you can run even run structured schemas against vision prompts for local models. Here's one against Ollama's llama3.2-vision:
llm -m llama3.2-vision:latest \
'describe images' \
--schema 'species,description,count int' \
-a https://static.simonwillison.net/static/2025/two-pelicans.jpg
I got back this:
{
"species": "Pelicans",
"description": "The image features a striking brown pelican with its distinctive orange beak, characterized by its large size and impressive wingspan.",
"count": 1
}
(Actually a bit disappointing, as there are two pelicans and their beaks are brown.)
llm-mistral 0.11. I added schema support to this plugin which adds support for the Mistral API to LLM. Release notes:
Schemas now work with OpenAI, Anthropic, Gemini and Mistral hosted models, plus self-hosted models via Ollama and llm-ollama.
Structured data extraction from unstructured content using LLM schemas
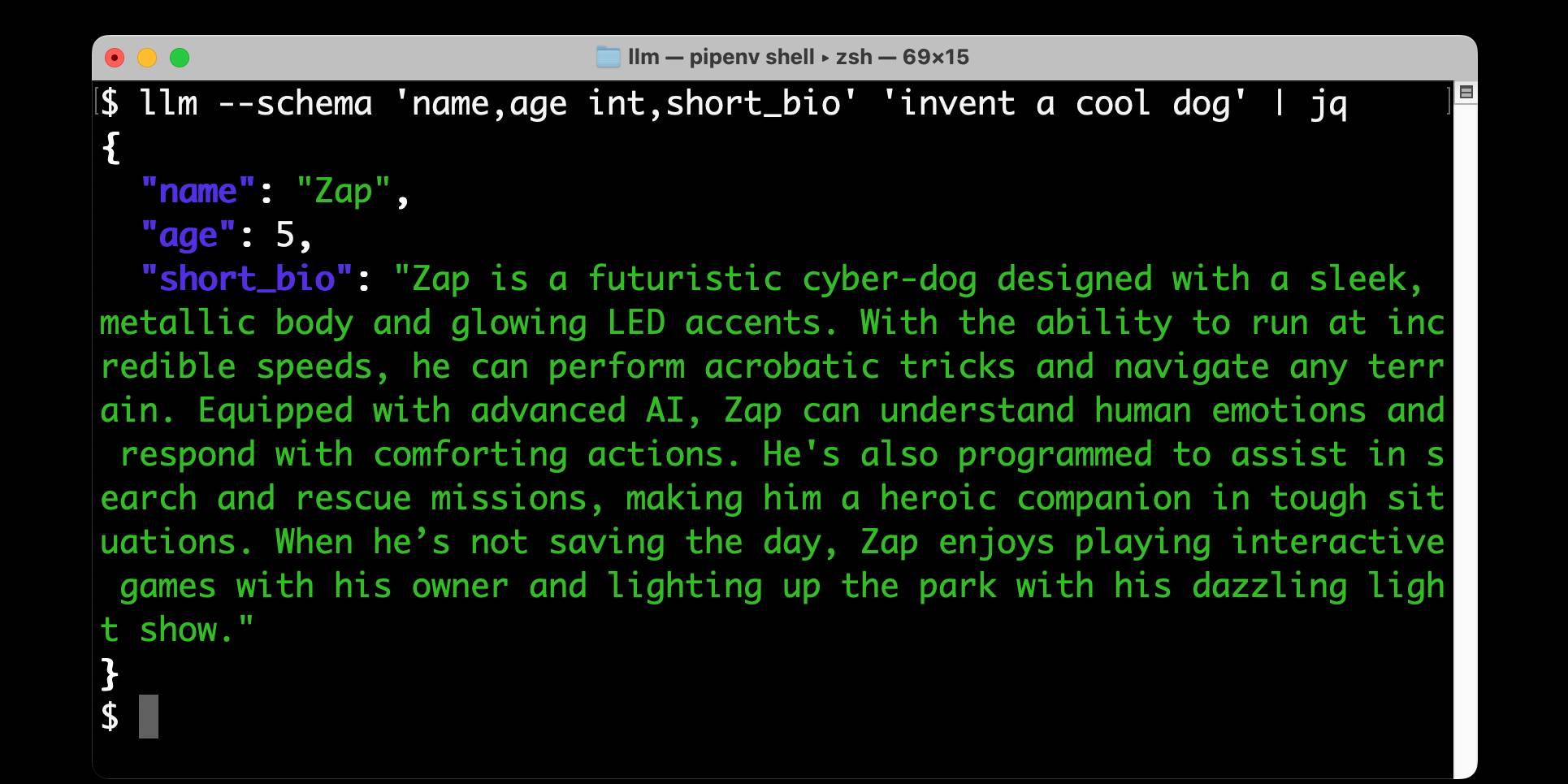
LLM 0.23 is out today, and the signature feature is support for schemas—a new way of providing structured output from a model that matches a specification provided by the user. I’ve also upgraded both the llm-anthropic and llm-gemini plugins to add support for schemas.
[... 2,601 words]olmOCR (via) New from Ai2 - olmOCR is "an open-source tool designed for high-throughput conversion of PDFs and other documents into plain text while preserving natural reading order".
At its core is allenai/olmOCR-7B-0225-preview, a Qwen2-VL-7B-Instruct variant trained on ~250,000 pages of diverse PDF content (both scanned and text-based) that were labelled using GPT-4o and made available as the olmOCR-mix-0225 dataset.
The olmocr Python library can run the model on any "recent NVIDIA GPU". I haven't managed to run it on my own Mac yet - there are GGUFs out there but it's not clear to me how to run vision prompts through them - but Ai2 offer an online demo which can handle up to ten pages for free.
Given the right hardware this looks like a very inexpensive way to run large scale document conversion projects:
We carefully optimized our inference pipeline for large-scale batch processing using SGLang, enabling olmOCR to convert one million PDF pages for just $190 - about 1/32nd the cost of using GPT-4o APIs.
The most interesting idea from the technical report (PDF) is something they call "document anchoring":
Document anchoring extracts coordinates of salient elements in each page (e.g., text blocks and images) and injects them alongside raw text extracted from the PDF binary file. [...]
Document anchoring processes PDF document pages via the PyPDF library to extract a representation of the page’s structure from the underlying PDF. All of the text blocks and images in the page are extracted, including position information. Starting with the most relevant text blocks and images, these are sampled and added to the prompt of the VLM, up to a defined maximum character limit. This extra information is then available to the model when processing the document.
![Left side shows a green-header interface with coordinates like [150x220]√3x−1+(1+x)², [150x180]Section 6, [150x50]Lorem ipsum dolor sit amet, [150x70]consectetur adipiscing elit, sed do, [150x90]eiusmod tempor incididunt ut, [150x110]labore et dolore magna aliqua, [100x280]Table 1, followed by grid coordinates with A, B, C, AA, BB, CC, AAA, BBB, CCC values. Right side shows the rendered document with equation, text and table.](https://static.simonwillison.net/static/2025/olmocr-document-anchoring.jpg)
The one limitation of olmOCR at the moment is that it doesn't appear to do anything with diagrams, figures or illustrations. Vision models are actually very good at interpreting these now, so my ideal OCR solution would include detailed automated descriptions of this kind of content in the resulting text.
Update: Jonathan Soma figured out how to run it on a Mac using LM Studio and the olmocr Python package.
Run LLMs on macOS using llm-mlx and Apple’s MLX framework
llm-mlx is a brand new plugin for my LLM Python Library and CLI utility which builds on top of Apple’s excellent MLX array framework library and mlx-lm package. If you’re a terminal user or Python developer with a Mac this may be the new easiest way to start exploring local Large Language Models.
[... 1,524 words]Using pip to install a Large Language Model that’s under 100MB
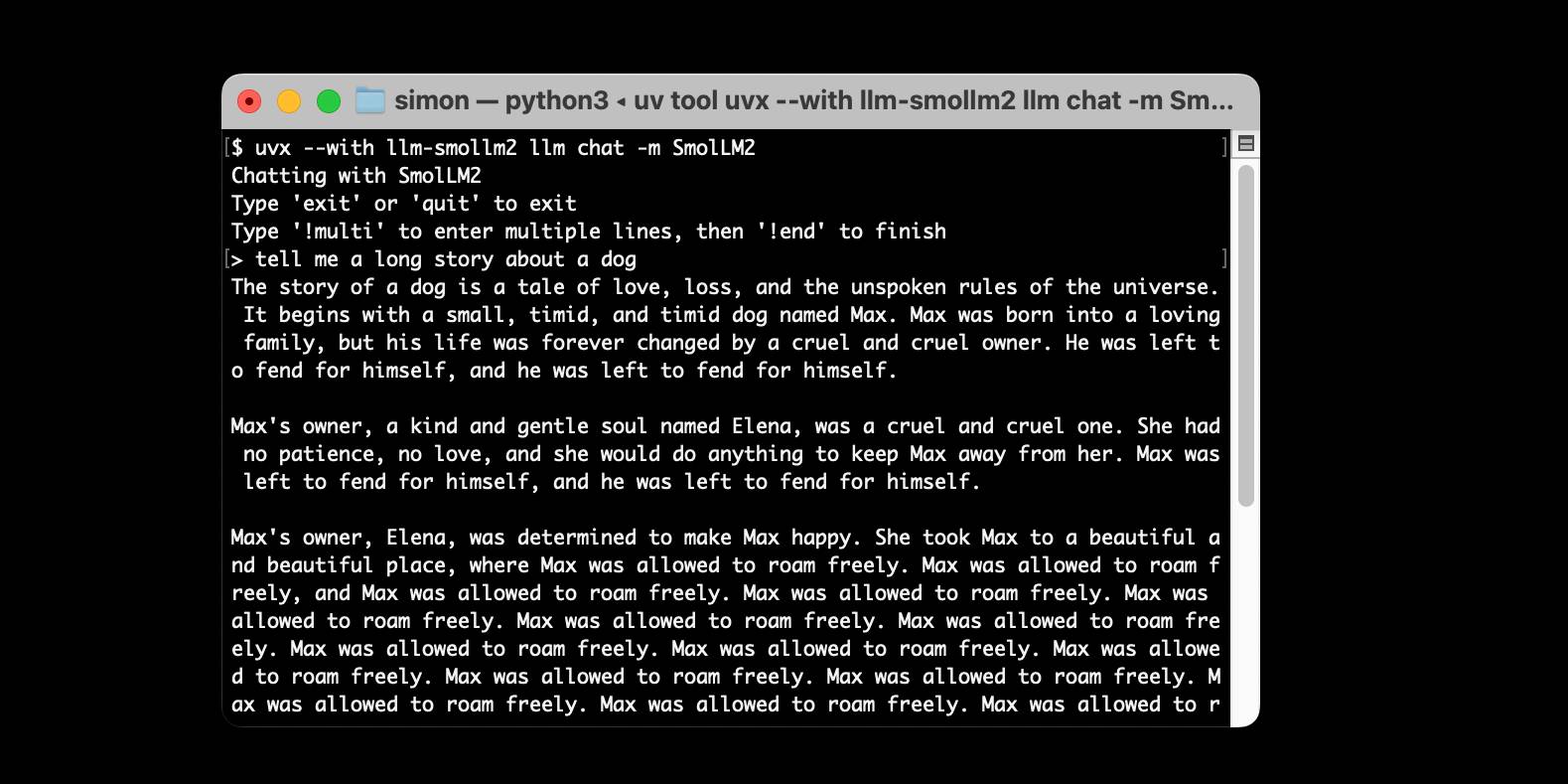
I just released llm-smollm2, a new plugin for LLM that bundles a quantized copy of the SmolLM2-135M-Instruct LLM inside of the Python package.
[... 1,553 words]Mistral Small 3 (via) First model release of 2025 for French AI lab Mistral, who describe Mistral Small 3 as "a latency-optimized 24B-parameter model released under the Apache 2.0 license."
More notably, they claim the following:
Mistral Small 3 is competitive with larger models such as Llama 3.3 70B or Qwen 32B, and is an excellent open replacement for opaque proprietary models like GPT4o-mini. Mistral Small 3 is on par with Llama 3.3 70B instruct, while being more than 3x faster on the same hardware.
Llama 3.3 70B and Qwen 32B are two of my favourite models to run on my laptop - that ~20GB size turns out to be a great trade-off between memory usage and model utility. It's exciting to see a new entrant into that weight class.
The license is important: previous Mistral Small models used their Mistral Research License, which prohibited commercial deployments unless you negotiate a commercial license with them. They appear to be moving away from that, at least for their core models:
We’re renewing our commitment to using Apache 2.0 license for our general purpose models, as we progressively move away from MRL-licensed models. As with Mistral Small 3, model weights will be available to download and deploy locally, and free to modify and use in any capacity. […] Enterprises and developers that need specialized capabilities (increased speed and context, domain specific knowledge, task-specific models like code completion) can count on additional commercial models complementing what we contribute to the community.
Despite being called Mistral Small 3, this appears to be the fourth release of a model under that label. The Mistral API calls this one mistral-small-2501 - previous model IDs were mistral-small-2312, mistral-small-2402 and mistral-small-2409.
I've updated the llm-mistral plugin for talking directly to Mistral's La Plateforme API:
llm install -U llm-mistral
llm keys set mistral
# Paste key here
llm -m mistral/mistral-small-latest "tell me a joke about a badger and a puffin"
Sure, here's a light-hearted joke for you:
Why did the badger bring a puffin to the party?
Because he heard puffins make great party 'Puffins'!
(That's a play on the word "puffins" and the phrase "party people.")
API pricing is $0.10/million tokens of input, $0.30/million tokens of output - half the price of the previous Mistral Small API model ($0.20/$0.60). for comparison, GPT-4o mini is $0.15/$0.60.
Mistral also ensured that the new model was available on Ollama in time for their release announcement.
You can pull the model like this (fetching 14GB):
ollama run mistral-small:24b
The llm-ollama plugin will then let you prompt it like so:
llm install llm-ollama
llm -m mistral-small:24b "say hi"
Qwen2.5 VL! Qwen2.5 VL! Qwen2.5 VL! Hot on the heels of yesterday's Qwen2.5-1M, here's Qwen2.5 VL (with an excitable announcement title) - the latest in Qwen's series of vision LLMs.
They're releasing multiple versions: base models and instruction tuned models at 3B, 7B and 72B. There's a lot of additional information in their README.
The 72B model can be selected on Qwen's Qwen Chat interface. I gave it this image of our dog Cleo joy rolling on the beach:

And prompted:
Describe this image in detail, be flowery
(Since the Qwen team tends to use flowery language in their announcements.)
Here's what I got back:
In this enchanting tableau, a canine companion finds solace in the embrace of nature's softest bed. The sandy expanse stretches out like an endless canvas, its surface etched with the delicate imprints of countless wanderers who have come and gone, leaving behind a tapestry of footprints that whisper tales of joyous romps and serene strolls.
The dog, a vision of contentment, lies sprawled upon the sand, its dark fur gleaming under the gentle caress of the sun. Its body is relaxed, limbs splayed in abandon, as if it has surrendered to the soothing rhythm of the beach. A vibrant red collar adorns its neck, a splash of color against the muted tones of the surroundings, hinting at the care and love bestowed upon this cherished pet.
The sand itself is a work of art, its grains shimmering with a silvery sheen that catches the light. Here and there, small tufts of seaweed peek through, remnants of the ocean's bounty, adding a touch of wild beauty to the scene. The shadows cast by unseen objects dance across the sand, creating a play of light and dark that lends an air of mystery to the tranquil setting.
This moment, frozen in time, speaks of peace and harmony, where man's best friend finds respite in the simple pleasures of life. It is a scene that invites one to pause, breathe deeply, and revel in the serenity of nature's embrace.
I'm looking forward to trying out their smaller models - the 3B model in particular should be small enough to run comfortably even on an iPhone, so hopefully someone will wire up an example of that soon (maybe using MLX).
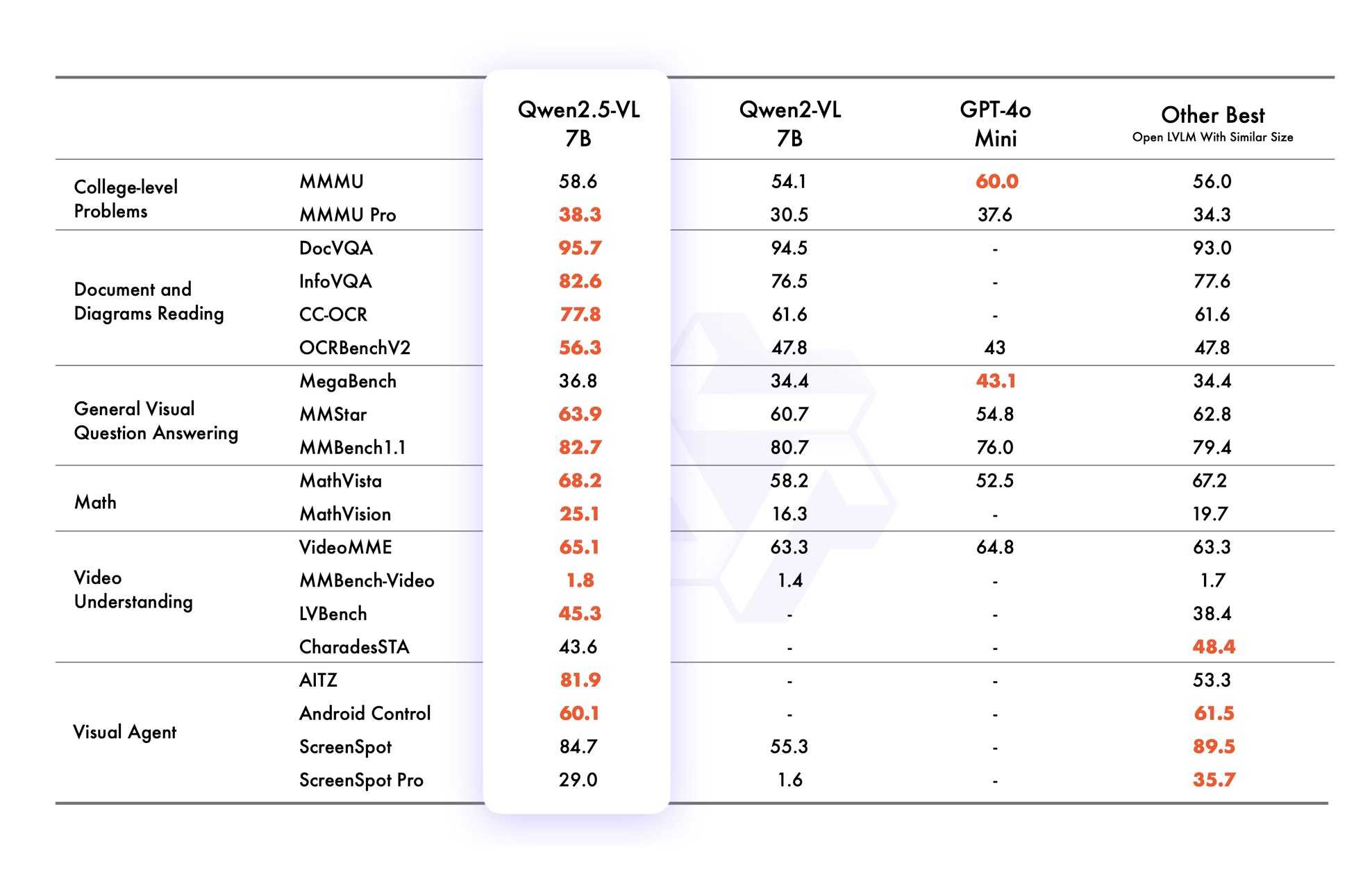
VB points out that the vision benchmarks for Qwen 2.5 VL 7B show it out-performing GPT-4o mini!
Qwen2.5 VL cookbooks
Qwen also just published a set of cookbook recipes:
- universal_recognition.ipynb demonstrates basic visual Q&A, including prompts like
Who are these in this picture? Please give their names in Chinese and Englishagainst photos of celebrities, an ability other models have deliberately suppressed. - spatial_understanding.ipynb demonstrates bounding box support, with prompts like
Locate the top right brown cake, output its bbox coordinates using JSON format. - video_understanding.ipynb breaks a video into individual frames and asks questions like
Could you go into detail about the content of this long video? - ocr.ipynb shows
Qwen2.5-VL-7B-Instructperforming OCR in multiple different languages. - document_parsing.ipynb uses Qwen to convert images of documents to HTML and other formats, and notes that "we introduce a unique Qwenvl HTML format that includes positional information for each component, enabling precise document reconstruction and manipulation."
- mobile_agent.ipynb runs Qwen with tool use against tools for controlling a mobile phone, similar to ChatGPT Operator or Claude Computer Use.
- computer_use.ipynb showcases "GUI grounding" - feeding in screenshots of a user's desktop and running tools for things like left clicking on a specific coordinate.
Running it with mlx-vlm
Update 30th January 2025: I got it working on my Mac using uv and mlx-vlm, with some hints from this issue. Here's the recipe that worked (downloading a 9GB model from mlx-community/Qwen2.5-VL-7B-Instruct-8bit):
uv run --with 'numpy<2' --with 'git+https://github.com/huggingface/transformers' \
--with mlx-vlm \
python -m mlx_vlm.generate \
--model mlx-community/Qwen2.5-VL-7B-Instruct-8bit \
--max-tokens 100 \
--temp 0.0 \
--prompt "Describe this image." \
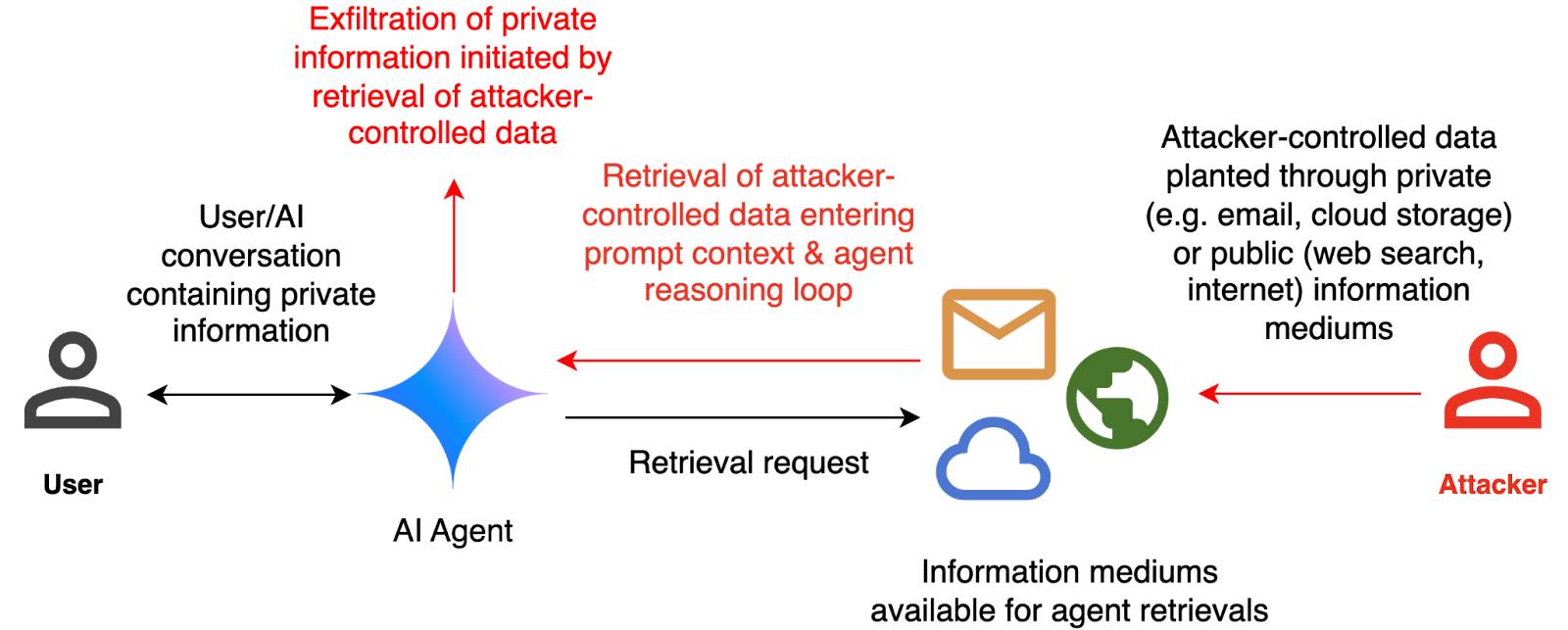
--image path-to-image.pngI ran that against this image:
And got back this result:
The image appears to illustrate a flowchart or diagram related to a cybersecurity scenario. Here's a breakdown of the elements:
- User: Represented by a simple icon of a person.
- AI Agent: Represented by a blue diamond shape.
- Attacker: Represented by a red icon of a person.
- Cloud and Email Icons: Represented by a cloud and an envelope, indicating data or information being transferred.
- Text: The text
Qwen2.5-1M: Deploy Your Own Qwen with Context Length up to 1M Tokens (via) Very significant new release from Alibaba's Qwen team. Their openly licensed (sometimes Apache 2, sometimes Qwen license, I've had trouble keeping up) Qwen 2.5 LLM previously had an input token limit of 128,000 tokens. This new model increases that to 1 million, using a new technique called Dual Chunk Attention, first described in this paper from February 2024.
They've released two models on Hugging Face: Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, both requiring CUDA and both under an Apache 2.0 license.
You'll need a lot of VRAM to run them at their full capacity:
VRAM Requirement for processing 1 million-token sequences:
- Qwen2.5-7B-Instruct-1M: At least 120GB VRAM (total across GPUs).
- Qwen2.5-14B-Instruct-1M: At least 320GB VRAM (total across GPUs).
If your GPUs do not have sufficient VRAM, you can still use Qwen2.5-1M models for shorter tasks.
Qwen recommend using their custom fork of vLLM to serve the models:
You can also use the previous framework that supports Qwen2.5 for inference, but accuracy degradation may occur for sequences exceeding 262,144 tokens.
GGUF quantized versions of the models are already starting to show up. LM Studio's "official model curator" Bartowski published lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF and lmstudio-community/Qwen2.5-14B-Instruct-1M-GGUF - sizes range from 4.09GB to 8.1GB for the 7B model and 7.92GB to 15.7GB for the 14B.
These might not work well yet with the full context lengths as the underlying llama.cpp library may need some changes.
I tried running the 8.1GB 7B model using Ollama on my Mac like this:
ollama run hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
Then with LLM:
llm install llm-ollama
llm models -q qwen # To search for the model ID
# I set a shorter q1m alias:
llm aliases set q1m hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
I tried piping a large prompt in using files-to-prompt like this:
files-to-prompt ~/Dropbox/Development/llm -e py -c | llm -m q1m 'describe this codebase in detail'
That should give me every Python file in my llm project. Piping that through ttok first told me this was 63,014 OpenAI tokens, I expect that count is similar for Qwen.
The result was disappointing: it appeared to describe just the last Python file that stream. Then I noticed the token usage report:
2,048 input, 999 output
This suggests to me that something's not working right here - maybe the Ollama hosting framework is truncating the input, or maybe there's a problem with the GGUF I'm using?
I'll update this post when I figure out how to run longer prompts through the new Qwen model using GGUF weights on a Mac.
Update: It turns out Ollama has a num_ctx option which defaults to 2048, affecting the input context length. I tried this:
files-to-prompt \
~/Dropbox/Development/llm \
-e py -c | \
llm -m q1m 'describe this codebase in detail' \
-o num_ctx 80000
But I quickly ran out of RAM (I have 64GB but a lot of that was in use already) and hit Ctrl+C to avoid crashing my computer. I need to experiment a bit to figure out how much RAM is used for what context size.
Awni Hannun shared tips for running mlx-community/Qwen2.5-7B-Instruct-1M-4bit using MLX, which should work for up to 250,000 tokens. They ran 120,000 tokens and reported:
- Peak RAM for prompt filling was 22GB
- Peak RAM for generation 12GB
- Prompt filling took 350 seconds on an M2 Ultra
- Generation ran at 31 tokens-per-second on M2 Ultra
Run DeepSeek R1 or V3 with MLX Distributed (via) Handy detailed instructions from Awni Hannun on running the enormous DeepSeek R1 or v3 models on a cluster of Macs using the distributed communication feature of Apple's MLX library.
DeepSeek R1 quantized to 4-bit requires 450GB in aggregate RAM, which can be achieved by a cluster of three 192 GB M2 Ultras ($16,797 will buy you three 192GB Apple M2 Ultra Mac Studios at $5,599 each).
DeepSeek-R1 and exploring DeepSeek-R1-Distill-Llama-8B

DeepSeek are the Chinese AI lab who dropped the best currently available open weights LLM on Christmas day, DeepSeek v3. That model was trained in part using their unreleased R1 “reasoning” model. Today they’ve released R1 itself, along with a whole family of new models derived from that base.
[... 1,276 words]