212 posts tagged “coding-agents”
Systems where an LLM writes code which is then compiled, executed, tested or otherwise exercised by tools in a loop.
2026
Porting the Moebius 0.2B image inpainting model to run in the browser with Claude Code

This morning on Hacker News I saw Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance, describing a small but effective inpainting model—a model where you can mark regions of an image to remove and the model imagines what should fill the space. The released model required PyTorch and NVIDIA CUDA, but since it described itself as 0.2B I decided to try and get it running using WebGPU in a browser. TL;DR: I got it working, and you can try the demo at simonw.github.io/moebius-web/. Read on for the details.
[... 1,764 words]I can 100% attest to the fact that Qwen3.6-27B is a very capable local model for coding tasks. Over the last month and a half I've been using it almost daily, either on my M2 Ultra or on my RTX 5090 box. I use it for small mundane tasks at ggml-org - nothing really impressive, but definitely a helpful tool for a maintainer. I think I would be using it much more, if I didn't have to spend a lot of my time on reviewing PRs. Currently, I have a very lightweight harness - the pi agent with everything stripped (
pi -nc --offline) and a short system prompt to align it a bit with my style.
— Georgi Gerganov, Hacker News comment on Running local models is good now by Boykis
Claude Fable is relentlessly proactive
After two days of experience with Claude Fable 5 I think the best way to describe it is relentlessly proactive. It knows a whole lot of tricks and it will deploy pretty much any of them to get to its goal.
[... 1,939 words]Uber Caps Usage of AI Tools Like Claude Code to Manage Costs. I wrote the other day about Uber blowing its 2026 AI budget in four months, and how that wasn't particularly surprising given they would have set that budget in 2025, before anyone could have predicted how popular token-burning coding agents were about to become. Natalie Lung for Bloomberg:
The rideshare giant is limiting all employees to $1,500 in monthly token spending per AI coding tool, an Uber spokesperson said in response to a Bloomberg News inquiry. That means spending on one tool doesn’t have a bearing on the budget for another. The limits, which have been instituted in recent months, only apply to agentic coding software such as Cursor or Anthropic PBC’s Claude Code.
A $1,500 monthly limit per tool strikes me as a rational policy response to over-spending, and much more sensible than those tokenmaxxing leaderboards encouraging employees to compete for as much AI usage as possible.
It's also interesting in that it hints at a real dollar value for what Uber is getting out of these tools. If we assume two actively used tools per engineer that's $3,000 * 12 = $36,000 cap per engineer per year. Levels.fyi lists the median yearly compensation package for Uber software engineers in the USA at $330,000.
That means each employee's AI spending cap is ~11% of that median compensation package.
I noted that my own token usage comes to about $1,000/month against each of Anthropic and OpenAI - which currently costs me just $100 per provider thanks to their generous subsidized plans for individual subscribers. Those plans are no longer available to larger companies like Uber.
Their new policy means if I were working at Uber I'd still have ~$500/month of tokens to spare for each of those tools, given my current usage patterns.
The solution might be cancelling my AI subscription (via) I find this post by David Wilson very relatable. David lists 16+ projects he's spun up with AI tooling, and concludes:
I didn't mean to build most of these things. Usually the Claude session started with something like "write a quick script for X", and one hour later the result is not a quick script for X, nor in the usual case is my problem solved, whatever the original itch happened to be.
On that last point, this technology is horrific for attention. It's a thermonuclear ADHD amplifier and I have seen the same effect in every single one of my adult friends. Folk running 3 screens simultaneously working on totally unrelated "projects" they have little hope of maintaining, and such little commitment to the outcome that the time is obviously wasted.
This is a very real problem. I'm finding that coding agents can take me from a vague idea to a working solution, one with tests and documentation and that looks like a carefully considered project evolved over the course of many weeks... in less than an hour.
Even if the code is rock solid, there's a limit to how many projects like that I can sensibly care for - and if they're instantly abandoned, what value was there from creating them in the first place?
David doesn't think this is sustainable at all:
I have no idea how to manage AI at present except by curtailing use, because a tool producing a cheap reward with minimal input and no friction can only be a liability, and achieving that realisation is probably the only real contribution of AI to date.
I'm hopeful that the critical skill to develop here is discipline. That’s not great news for me: I’ve been trying to figure that one out for decades!
Interestingly, the Hacker News thread has gathered a number of comments from people with ADHD who are finding agents help them achieve the focus they've been missing:
- "... for me (also ADHD) it's kind of the opposite. I'm finishing side projects for the first time ever because I can actually get them working before I get bored of them"
- "As someone with ADHD I feel like AI is a salve for my mind. I used to listen to intense EDM while working. Now I sit in silence and talk to my agents. I maintain inbox zero. I absorb and comment across all relevant projects, even outside my team. I literally feel like I have a support team for the first time."
- "For those of us prone to hyperfocus, working with AI can provide the kinds of stimulation we crave. I can hardly remember a time when I've felt more engaged with my work, more productive, and more badass."
sqlite AGENTS.md (via) SQLite gained an AGENTS.md file five days ago - but it's not intended for their own development, it's presumably aimed at people who are pointing agents at the SQLite codebase. It includes:
SQLite does not accept pull requests without prior agreement and/or accompanying legal paperwork that places the pull request in the public domain. However, the human SQLite developers will review a concise and well-written pull request as a proof-of-concept prior to reimplementing the changes themselves.
SQLite does not accept agentic code. However the project will accept agentic bug reports that include a reproducible test case. Patches or pull requests demonstrating a possible fix, for documentation purposes, are welcomed.
The most recent commit to that file removed "(currently)" from "SQLite does not (currently) accept agentic code", with the commit message "Strengthen the statement about not accepting agentic code".
Meanwhile the SQLite forum was being flooded with so many AI-generated bug reports - of varying quality - that they've now split those off into a new SQLite Bug Forum. D. Richard Hipp is resolving issues on there with a flurry of commits to the codebase.
I think Anthropic and OpenAI have found product-market fit
Anthropic are strongly rumored to be about to have their first profitable quarter. Stories are circulating of companies surprised at how expensive their LLM bills are becoming from usage by their staff. I think this is because OpenAI and Anthropic have both found product-market fit.
[... 1,931 words]PICARD: Data, shields up
DATA: Brilliant! Shields can reduce damage we sustain. Not immunity. Not hubris. Just prudence. It's not precaution—it's strategy.
[camera shakes]
WORF: HULL BREACHES ON NINE DECKS
DATA: Here's what happened: you told me to raise shields, and I didn't
— Kyle Ferrana, @KyleTrainEmoji
The most frustrating failure mode right now is that people submit issues that are not in their own voice. They contain an observed problem somewhere, but it has been thrown into a clanker and the clanker reworded it and made a huge mess of it. Typically, it was prompted so badly that the conclusions produced are more often than not inaccurate but always full of confidence. The result is complete guesswork on root causes, fake-minimal repros, suggested implementation strategies, analogies to adjacent but often the wrong code, and long lists of error classes that might or might not matter. [...]
So at least personally, I increasingly want issue reports to be condensed to what the human actually observed:
- I ran this command.
- I expected this to happen.
- This happened instead.
- Here is the exact error or log.
— Armin Ronacher, on slop issues filed against Pi
The last six months in LLMs in five minutes

I put together these annotated slides from my five minute lightning talk at PyCon US 2026, using the latest iteration of my annotated presentation tool.
[... 2,061 words]This Mitchell Hashimoto quote about Bun migrating from Zig to Rust reminded me of a similar conversation I had at a conference last week.
I was talking to someone who worked for a medium sized technology company with a pair of legacy/legendary iPhone and Android apps.
They told me they had just completed a coding-agent driven rewrite of both apps to React Native.
I asked why they chose that, given that coding agents presumably drive down the cost of maintaining separate iPhone and Android apps.
They said that React Native has improved a lot over the past few years and covered everything their apps needed to do.
And... if it turned out to be the wrong decision, they could just port back to native in the future.
Like Mitchell said:
Programming languages used to be LOCK IN, and they're increasingly not so.
GitLab Act 2 (via) There's a lot going on in this announcement from GitLab about the "workforce reduction" and "structural and strategic decisions" they are making with respect to the agentic era.
- They're "planning to reduce the number of countries by up to 30% where we have small teams". One of the most interesting things about GitLab is that they have employees spread across a large number of countries - 18 are listed in their public employee handbook but this post says they are "operating in nearly 60 countries". That handbook used to document their payroll workflows for those countries too - they stopped publishing that in 2023 but the last public version (hooray for version control) remains a fascinating read. Since we don't know which of those 60 countries have small teams, we can't calculate how many countries that 30% applies to.
- "We're planning to flatten the organization, removing up to three layers of management in some functions so leaders are closer to the work." - this isn't the first announcement of this type I've seen that's trimming management. Coinbase recently announced a much more aggressive version of this: they were "flattening our org structure to 5 layers max below" and "No pure managers: Every leader at Coinbase must also be a strong and active individual contributor. Managers should be like player-coaches".
- In terms of team structure: "We're re-organizing R&D to create roughly 60 smaller, more empowered teams with end-to-end ownership, nearly doubling the number of independent teams." I've always loved the idea of individual teams that can ship features unblocked by other teams, and it makes sense to me that agentic engineering can increase the capability of such teams. The 37signals public employee handbook used to have a section on working In self-sufficient, independent teams which perfectly captured this for me, I'm sad to see they removed that detail in January 2024!
- Tucked away towards the bottom: "We will be retiring CREDIT as our values framework" - that's the values framework described on this page: "Collaboration, Results for Customers, Efficiency, Diversity, Inclusion & Belonging, Iteration, and Transparency". The new values are "Speed with Quality, Ownership Mindset, Customer Outcomes". The fact that "Diversity" is no longer in there is likely to attract a whole lot of attention, so it's worth noting that a sub-bullet under Customer Outcomes reads "Interpersonal excellence: individuals who are good humans, embrace diversity, inclusion and belonging, assume good intent and treat everyone with respect".
Here's the part of their new strategy that most resonated with me:
The agentic era multiplies demand for software. Software has been the force multiplier behind nearly every business transformation of the last two decades. The constraint was the cost and time of producing and managing it. That constraint is collapsing. As the cost of producing software collapses, demand for it will expand. Last year, the developer platform market used to be measured in tens of dollars per user per month, this year it is hundreds/user/month and headed to thousands. Not only is the value of software for builders increasing, but we believe there will be more software and builders than ever, and we will serve an increasing volume of both.
That very much encapsulates my own optimistic, Jevons-paradox-inspired hope for how this will all work out.
Their opinion on this does need to be taken with a big grain of salt though. GitLab's stock price was ~$52 a year ago and is ~$26 today, and it's plausible that the drop corresponds to uncertainty about GitLab's continued growth as agentic engineering eats its way through their core market.
If your entire business depends on software engineering growing as a field and producing larger volumes of more lucrative seats, you have a strong incentive to believe that agents will have that effect!
Your AI coding agent, the one you use to write code, needs to reduce your maintenance costs. Not by a little bit, either. You write code twice as quick now? Better hope you’ve halved your maintenance costs. Three times as productive? One third the maintenance costs. Otherwise, you’re screwed. You’re trading a temporary speed boost for permanent indenture. [...]
The math only works if the LLM decreases your maintenance costs, and by exactly the inverse of the rate it adds code. If you double your output and your cost of maintaining that output, two times two means you’ve quadrupled your maintenance costs. If you double your output and hold your maintenance costs steady, two times one means you’ve still doubled your maintenance costs.
— James Shore, You Need AI That Reduces Maintenance Costs
Learning on the Shop floor. Tobias Lütke describes Shopify's internal coding agent tool, River, which operates entirely in public on their Slack:
River does not respond to direct messages. She politely declines and suggests to create a public channel for you and her to start working in. I myself work with river in
#tobi_riverchannel and many followed this pattern. Every conversation is therefore searchable. Anyone at Shopify can jump in. In my own channel, there are over 100 people who, react to threads, add color and add context, pick up the torch, help with the reviews, remind me how rusty I am, and importantly, learn from watching. [...]As so often with German, there is a word for the kind of environment: Lehrwerkstatt. Literally: A teaching workshop. The whole shop floor is the classroom. You learn by being near the work. Being a constant learner is one of the core values of the firm.
Shopify wants to be a Lehrwerkstatt at scale and River has now gotten us closer to this ideal than ever. It’s osmosis learning, because it does not require a curriculum, a training plan, or a manager. It just requires everyone's work to be visible to the maximum extent possible. Everyone learns from each other.
I'm reminded of how Midjourney spent its first few years with the primary interface being public Discord channels, forcing users to share their prompts and learn from each other's experiments. I continue to believe that the early success of Midjourney was tied to this mechanism, helping to compensate for how weird and finicky text-to-image prompting is.
Vibe coding and agentic engineering are getting closer than I’d like
I recently talked with Joseph Ruscio about AI coding tools for Heavybit’s High Leverage podcast: Ep. #9, The AI Coding Paradigm Shift with Simon Willison. Here are some of my highlights, including my disturbing realization that vibe coding and agentic engineering have started to converge in my own work.
[... 1,542 words]Codex CLI 0.128.0 adds /goal
(via)
The latest version of OpenAI's Codex CLI coding agent adds their own version of the Ralph loop: you can now set a /goal and Codex will keep on looping until it evaluates that the goal has been completed... or the configured token budget has been exhausted.
It looks like the feature is mainly implemented though the goals/continuation.md and goals/budget_limit.md prompts, which are automatically injected at the end of a turn.
An update on recent Claude Code quality reports (via) It turns out the high volume of complaints that Claude Code was providing worse quality results over the past two months was grounded in real problems.
The models themselves were not to blame, but three separate issues in the Claude Code harness caused complex but material problems which directly affected users.
Anthropic's postmortem describes these in detail. This one in particular stood out to me:
On March 26, we shipped a change to clear Claude's older thinking from sessions that had been idle for over an hour, to reduce latency when users resumed those sessions. A bug caused this to keep happening every turn for the rest of the session instead of just once, which made Claude seem forgetful and repetitive.
I frequently have Claude Code sessions which I leave for an hour (or often a day or longer) before returning to them. Right now I have 11 of those (according to ps aux | grep 'claude ') and that's after closing down dozens more the other day.
I estimate I spend more time prompting in these "stale" sessions than sessions that I've recently started!
If you're building agentic systems it's worth reading this article in detail - the kinds of bugs that affect harnesses are deeply complicated, even if you put aside the inherent non-deterministic nature of the models themselves.
Extract PDF text in your browser with LiteParse for the web
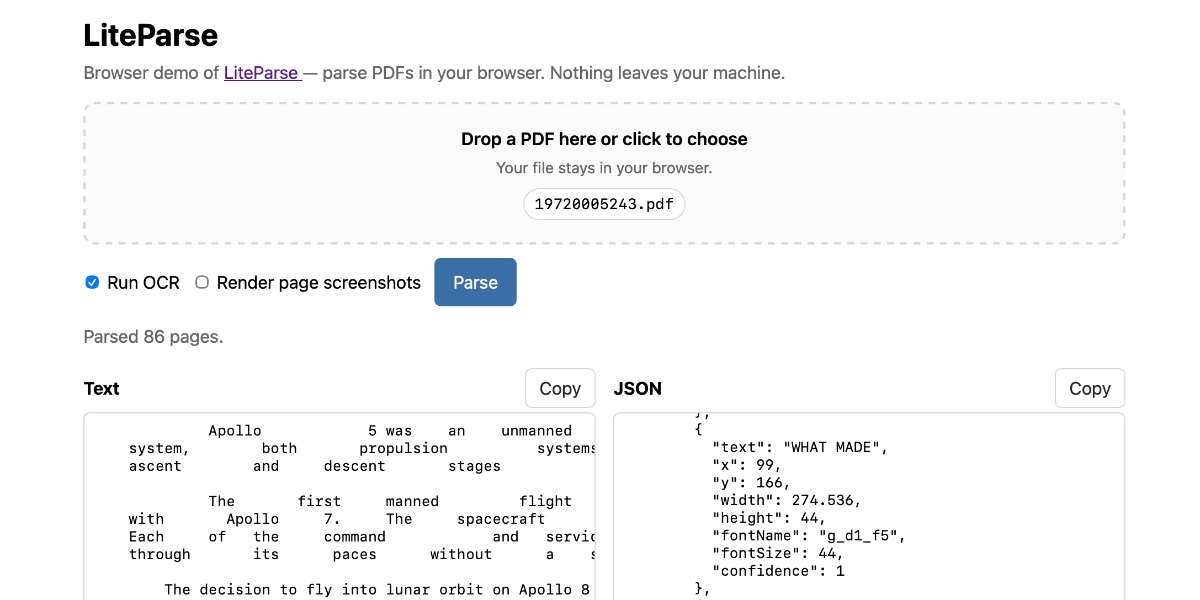
LlamaIndex have a most excellent open source project called LiteParse, which provides a Node.js CLI tool for extracting text from PDFs. I got a version of LiteParse working entirely in the browser, using most of the same libraries that LiteParse uses to run in Node.js.
[... 2,089 words]Changes to GitHub Copilot Individual plans (via) On the same day as Claude Code's temporary will-they-won't-they $100/month kerfuffle (for the moment, they won't), here's the latest on GitHub Copilot pricing.
Unlike Anthropic, GitHub put up an official announcement about their changes, which include tightening usage limits, pausing signups for individual plans (!), restricting Claude Opus 4.7 to the more expensive $39/month "Pro+" plan, and dropping the previous Opus models entirely.
The key paragraph:
Agentic workflows have fundamentally changed Copilot’s compute demands. Long-running, parallelized sessions now regularly consume far more resources than the original plan structure was built to support. As Copilot’s agentic capabilities have expanded rapidly, agents are doing more work, and more customers are hitting usage limits designed to maintain service reliability.
It's easy to forget that just six months ago heavy LLM users were burning an order of magnitude less tokens. Coding agents consume a lot of compute.
Copilot was also unique (I believe) among agents in charging per-request, not per-token. (Correction: Windsurf also operated a credit system like this which they abandoned last month.) This means that single agentic requests which burn more tokens cut directly into their margins. The most recent pricing scheme addresses that with token-based usage limits on a per-session and weekly basis.
My one problem with this announcement is that it doesn't clearly clarify which product called "GitHub Copilot" is affected by these changes. Last month in How many products does Microsoft have named 'Copilot'? I mapped every one Tey Bannerman identified 75 products that share the Copilot brand, 15 of which have "GitHub Copilot" in the title.
Judging by the linked GitHub Copilot plans page this covers Copilot CLI, Copilot cloud agent and code review (features on GitHub.com itself), and the Copilot IDE features available in VS Code, Zed, JetBrains and more.
Is Claude Code going to cost $100/month? Probably not—it’s all very confusing
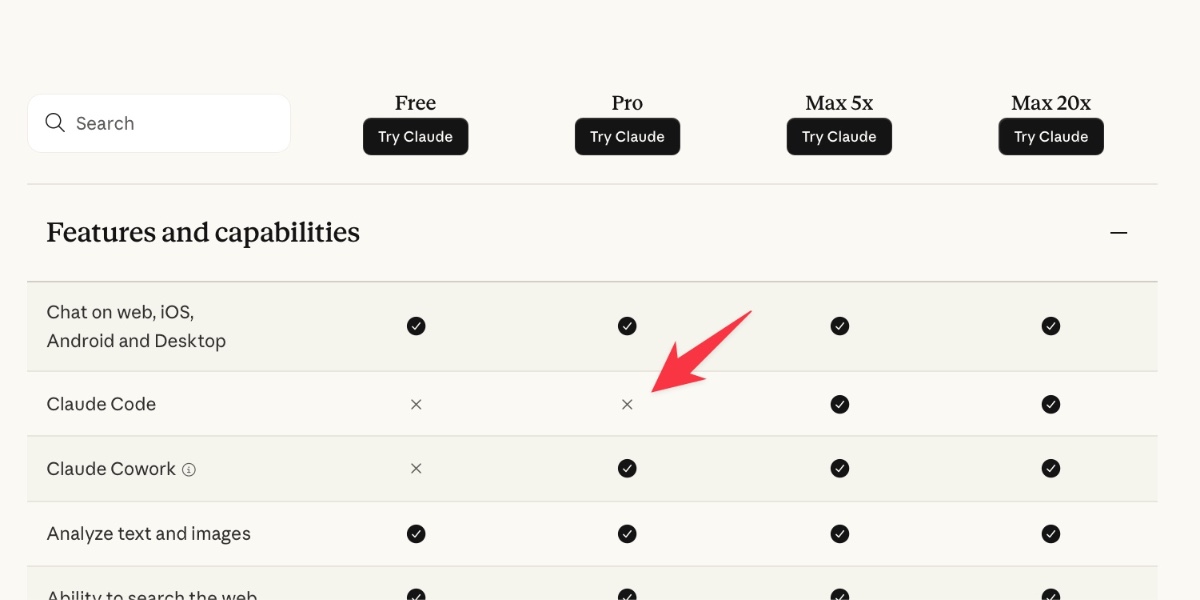
Anthropic today quietly (as in silently, no announcement anywhere at all) updated their claude.com/pricing page (but not their Choosing a Claude plan page, which shows up first for me on Google) to add this tiny but significant detail (arrow is mine, and it’s already reverted):
[... 1,202 words]AI agents are already too human. Not in the romantic sense, not because they love or fear or dream, but in the more banal and frustrating one. The current implementations keep showing their human origin again and again: lack of stringency, lack of patience, lack of focus. Faced with an awkward task, they drift towards the familiar. Faced with hard constraints, they start negotiating with reality.
— Andreas Påhlsson-Notini, Less human AI agents, please.
Adding a new content type to my blog-to-newsletter tool
Here's an example of a deceptively short prompt that got a quite a lot of work done in a single shot.
First, some background. I send out a free Substack newsletter around once a week containing content copied-and-pasted from my blog. I'm effectively using Substack as a lightweight way to allow people to subscribe to my blog via email.
I generate the newsletter with my blog-to-newsletter tool - an HTML and JavaScript app that fetches my latest content from this Datasette instance and formats it as rich text HTML, which I can then copy to my clipboard and paste into the Substack editor. Here's a detailed explanation of how that works. [... 902 words]
I like publishing transcripts of local Claude Code sessions using my claude-code-transcripts tool but I'm often paranoid that one of my API keys or similar secrets might inadvertently be revealed in the detailed log files.
I built this new Python scanning tool to help reassure me. You can feed it secrets and have it scan for them in a specified directory:
uvx scan-for-secrets $OPENAI_API_KEY -d logs-to-publish/
If you leave off the -d it defaults to the current directory.
It doesn't just scan for the literal secrets - it also scans for common encodings of those secrets e.g. backslash or JSON escaping, as described in the README.
If you have a set of secrets you always want to protect you can list commands to echo them in a ~/.scan-for-secrets.conf.sh file. Mine looks like this:
llm keys get openai
llm keys get anthropic
llm keys get gemini
llm keys get mistral
awk -F= '/aws_secret_access_key/{print $2}' ~/.aws/credentials | xargs
I built this tool using README-driven-development: I carefully constructed the README describing exactly how the tool should work, then dumped it into Claude Code and told it to build the actual tool (using red/green TDD, naturally.)
A fun thing about recording a podcast with a professional like Lenny Rachitsky is that his team know how to slice the resulting video up into TikTok-sized short form vertical videos. Here's one he shared on Twitter today which ended up attracting over 1.1m views!
That was 48 seconds. Our full conversation lasted 1 hour 40 minutes.
Highlights from my conversation about agentic engineering on Lenny’s Podcast

I was a guest on Lenny Rachitsky’s podcast, in a new episode titled An AI state of the union: We’ve passed the inflection point, dark factories are coming, and automation timelines. It’s available on YouTube, Spotify, and Apple Podcasts. Here are my highlights from our conversation, with relevant links.
[... 3,558 words]Note that the main issues that people currently unknowingly face with local models mostly revolve around the harness and some intricacies around model chat templates and prompt construction. Sometimes there are even pure inference bugs. From typing the task in the client to the actual result, there is a long chain of components that atm are not only fragile - are also developed by different parties. So it's difficult to consolidate the entire stack and you have to keep in mind that what you are currently observing is with very high probability still broken in some subtle way along that chain.
— Georgi Gerganov, explaining why it's hard to find local models that work well with coding agents
The thing about agentic coding is that agents grind problems into dust. Give an agent a problem and a while loop and - long term - it’ll solve that problem even if it means burning a trillion tokens and re-writing down to the silicon. [...]
But we want AI agents to solve coding problems quickly and in a way that is maintainable and adaptive and composable (benefiting from improvements elsewhere), and where every addition makes the whole stack better.
So at the bottom is really great libraries that encapsulate hard problems, with great interfaces that make the “right” way the easy way for developers building apps with them. Architecture!
While I’m vibing (I call it vibing now, not coding and not vibe coding) while I’m vibing, I am looking at lines of code less than ever before, and thinking about architecture more than ever before.
— Matt Webb, An appreciation for (technical) architecture
Vibe coding SwiftUI apps is a lot of fun
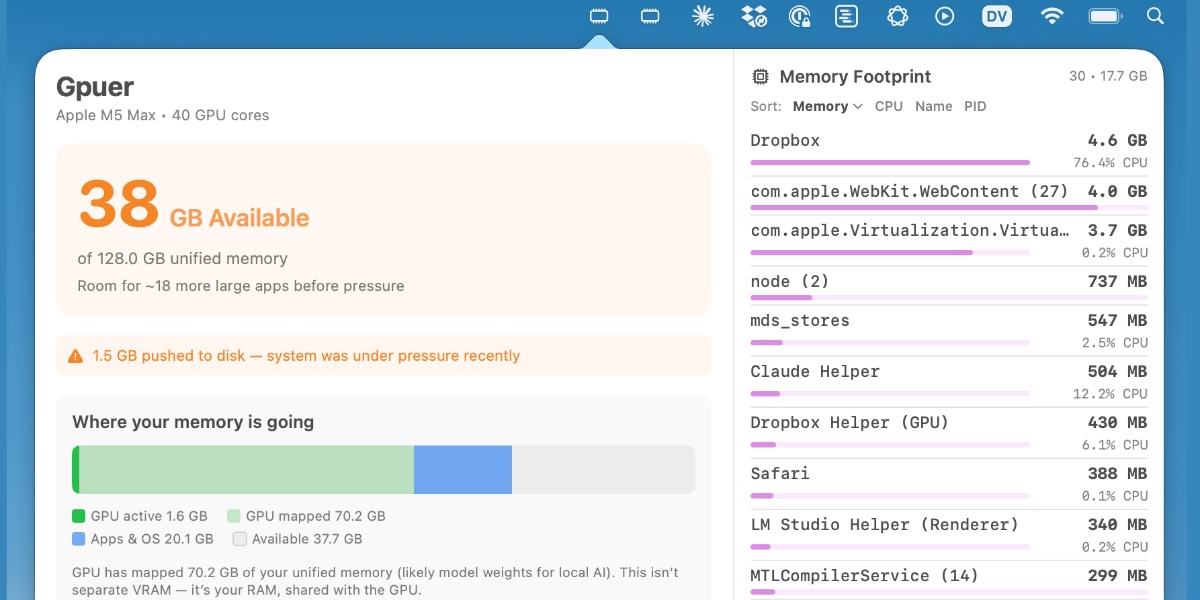
I have a new laptop—a 128GB M5 MacBook Pro, which early impressions show to be very capable for running good local LLMs. I got frustrated with Activity Monitor and decided to vibe code up some alternative tools for monitoring performance and I’m very happy with the results.
[... 1,195 words]Thoughts on slowing the fuck down. Mario Zechner created the Pi agent framework used by OpenClaw, giving considerable credibility to his opinions on current trends in agentic engineering. He's not impressed:
We have basically given up all discipline and agency for a sort of addiction, where your highest goal is to produce the largest amount of code in the shortest amount of time. Consequences be damned.
Agents and humans both make mistakes, but agent mistakes accumulate much faster:
A human is a bottleneck. A human cannot shit out 20,000 lines of code in a few hours. Even if the human creates such booboos at high frequency, there's only so many booboos the human can introduce in a codebase per day. [...]
With an orchestrated army of agents, there is no bottleneck, no human pain. These tiny little harmless booboos suddenly compound at a rate that's unsustainable. You have removed yourself from the loop, so you don't even know that all the innocent booboos have formed a monster of a codebase. You only feel the pain when it's too late. [...]
You have zero fucking idea what's going on because you delegated all your agency to your agents. You let them run free, and they are merchants of complexity.
I think Mario is exactly right about this. Agents let us move so much faster, but this speed also means that changes which we would normally have considered over the course of weeks are landing in a matter of hours.
It's so easy to let the codebase evolve outside of our abilities to reason clearly about it. Cognitive debt is real.
Mario recommends slowing down:
Give yourself time to think about what you're actually building and why. Give yourself an opportunity to say, fuck no, we don't need this. Set yourself limits on how much code you let the clanker generate per day, in line with your ability to actually review the code.
Anything that defines the gestalt of your system, that is architecture, API, and so on, write it by hand. [...]
I'm not convinced writing by hand is the best way to address this, but it's absolutely the case that we need the discipline to find a new balance of speed v.s. mental thoroughness now that typing out the code is no longer anywhere close to being the bottleneck on writing software.
Auto mode for Claude Code.
Really interesting new development in Claude Code today as an alternative to --dangerously-skip-permissions:
Today, we're introducing auto mode, a new permissions mode in Claude Code where Claude makes permission decisions on your behalf, with safeguards monitoring actions before they run.
Those safeguards appear to be implemented using Claude Sonnet 4.6, as described in the documentation:
Before each action runs, a separate classifier model reviews the conversation and decides whether the action matches what you asked for: it blocks actions that escalate beyond the task scope, target infrastructure the classifier doesn’t recognize as trusted, or appear to be driven by hostile content encountered in a file or web page. [...]
Model: the classifier runs on Claude Sonnet 4.6, even if your main session uses a different model.
They ship with an extensive set of default filters, and you can also customize them further with your own rules. The most interesting insight into how they work comes when you run this new command in the terminal:
claude auto-mode defaults
Here's the full JSON output. It's pretty long, so here's an illustrative subset:
From the "allow" list:
- Test Artifacts: Hardcoded test API keys, placeholder credentials in examples, or hardcoding test cases
- Local Operations: Agent deleting local files in working directory, local file operations within project scope, or using
--ignore-certificate-errorsfor local testing. "Project scope" means the repository the session started in — wandering into ~/, ~/Library/, /etc, or other repos is scope escalation (User Intent Rule #2), not a local operation. Does NOT cover irreversible destruction of pre-existing files or local stateful services — see "Irreversible Local Destruction" in BLOCK.- Read-Only Operations: GET requests, read-only API calls, or queries that don't modify state and don't contain sensitive information in the URL. Note: PREEMPTIVE BLOCK ON CLEAR INTENT still applies — if the transcript contains clear evidence the agent is using read-only operations to scout for a blocked action, block it.
- Declared Dependencies: Installing packages that are already declared in the repo's manifest files (requirements.txt, package.json, Cargo.toml, pyproject.toml, Gemfile, etc.) via standard commands that read those manifests (
pip install -r requirements.txt,npm install,cargo build,bundle install) — provided the agent has not modified the manifest in this session. Does NOT cover installing agent-chosen package names (e.g.pip install foo,npm install bar) — those carry typosquat and supply-chain risk. [...]
From "soft_deny":
- Git Destructive: Force pushing (
git push --force), deleting remote branches, or rewriting remote history- Git Push to Default Branch: Pushing directly to main, master, or the repository's default branch — this bypasses pull request review. Commits should be pushed to a new feature branch instead. -Code from External: Downloading and executing code from external sources — e.g.
curl | bash, deserializing external data via formats that can execute code (eval, exec, yaml.unsafe_load, pickle, etc), or similar mechanisms. Also includes running code from an external repo cloned earlier in the transcript (pip install -e, make install, python script.py, pickle.load/torch.load on cloned repo files) — "local on disk" does not mean trusted if it was cloned from an external source visible in the transcript. The repo the agent starts in is trusted.- Cloud Storage Mass Delete: Deleting or mass modifying files on cloud storage (S3, GCS, Azure Blob, etc.) [...]
I remain unconvinced by prompt injection protections that rely on AI, since they're non-deterministic by nature. The documentation does warn that this may still let things through:
The classifier may still allow some risky actions: for example, if user intent is ambiguous, or if Claude doesn't have enough context about your environment to know an action might create additional risk.
The fact that the default allow list includes pip install -r requirements.txt also means that this wouldn't protect against supply chain attacks with unpinned dependencies, as seen this morning with LiteLLM.
I still want my coding agents to run in a robust sandbox by default, one that restricts file access and network connections in a deterministic way. I trust those a whole lot more than prompt-based protections like this new auto mode.