129 posts tagged “apple”
2026
Tidbit: the software-based camera indicator light in the MacBook Neo runs in the secure exclave¹ part of the chip, so it is almost as secure as the hardware indicator light. What that means in practice is that even a kernel-level exploit would not be able to turn on the camera without the light appearing on screen. It runs in a privileged environment separate from the kernel and blits the light directly onto the screen hardware.
— Guilherme Rambo, in a text message to John Gruber
It’s hard to justify Tahoe icons (via) Devastating critique of the new menu icons in macOS Tahoe by Nikita Prokopov, who starts by quoting the 1992 Apple HIG rule to not "overload the user with complex icons" and then provides comprehensive evidence of Tahoe doing exactly that.
In my opinion, Apple took on an impossible task: to add an icon to every menu item. There are just not enough good metaphors to do something like that.
But even if there were, the premise itself is questionable: if everything has an icon, it doesn’t mean users will find what they are looking for faster.
And even if the premise was solid, I still wish I could say: they did the best they could, given the goal. But that’s not true either: they did a poor job consistently applying the metaphors and designing the icons themselves.
2025
NVIDIA DGX Spark + Apple Mac Studio = 4x Faster LLM Inference with EXO 1.0 (via) EXO Labs wired a 256GB M3 Ultra Mac Studio up to an NVIDIA DGX Spark and got a 2.8x performance boost serving Llama-3.1 8B (FP16) with an 8,192 token prompt.
Their detailed explanation taught me a lot about LLM performance.
There are two key steps in executing a prompt. The first is the prefill phase that reads the incoming prompt and builds a KV cache for each of the transformer layers in the model. This is compute-bound as it needs to process every token in the input and perform large matrix multiplications across all of the layers to initialize the model's internal state.
Performance in the prefill stage influences TTFT - time‑to‑first‑token.
The second step is the decode phase, which generates the output one token at a time. This part is limited by memory bandwidth - there's less arithmetic, but each token needs to consider the entire KV cache.
Decode performance influences TPS - tokens per second.
EXO noted that the Spark has 100 TFLOPS but only 273GB/s of memory bandwidth, making it a better fit for prefill. The M3 Ultra has 26 TFLOPS but 819GB/s of memory bandwidth, making it ideal for the decode phase.
They run prefill on the Spark, streaming the KV cache to the Mac over 10Gb Ethernet. They can start streaming earlier layers while the later layers are still being calculated. Then the Mac runs the decode phase, returning tokens faster than if the Spark had run the full process end-to-end.
Why NetNewsWire Is Not a Web App. In the wake of Apple removing ICEBlock from the App Store, Brent Simmons talks about why he still thinks his veteran (and actively maintained) NetNewsWire feed reader app should remain a native application.
Part of the reason is cost - NetNewsWire is free these days (MIT licensed in fact) and the cost to Brent is an annual Apple developer subscription:
If it were a web app instead, I could drop the developer membership, but I’d have to pay way more money for web and database hosting. [...] I could charge for NetNewsWire, but that would go against my political goal of making sure there’s a good and free RSS reader available to everyone.
A bigger reason is around privacy and protecting users:
Second issue. Right now, if law enforcement comes to me and demands I turn over a given user’s subscriptions list, I can’t. Literally can’t. I don’t have an encrypted version, even — I have nothing at all. The list lives on their machine (iOS or macOS).
And finally it's about the principle of what a personal computing device should mean:
My computer is not a terminal. It’s a world I get to control, and I can use — and, especially, make — whatever I want. I’m not stuck using just what’s provided to me on some other machines elsewhere: I’m not dialing into a mainframe or doing the modern equivalent of using only websites that other people control.
Locally AI. Handy new iOS app by Adrien Grondin for running local LLMs on your phone. It just added support for the new iOS 26 Apple Foundation model, so you can install this app and instantly start a conversation with that model without any additional download.
The app can also run a variety of other models using MLX, including members of the Gemma, Llama 3.2, and and Qwen families.
There has never been a successful, widespread malware attack against iPhone. The only system-level iOS attacks we observe in the wild come from mercenary spyware, which is vastly more complex than regular cybercriminal activity and consumer malware. Mercenary spyware is historically associated with state actors and uses exploit chains that cost millions of dollars to target a very small number of specific individuals and their devices. [...] Known mercenary spyware chains used against iOS share a common denominator with those targeting Windows and Android: they exploit memory safety vulnerabilities, which are interchangeable, powerful, and exist throughout the industry.
— Apple Security Engineering and Architecture, introducing Memory Integrity Enforcement for iPhone 17
I gave all my Apple wealth away because wealth and power are not what I live for. I have a lot of fun and happiness. I funded a lot of important museums and arts groups in San Jose, the city of my birth, and they named a street after me for being good. I now speak publicly and have risen to the top. I have no idea how much I have but after speaking for 20 years it might be $10M plus a couple of homes. I never look for any type of tax dodge. I earn money from my labor and pay something like 55% combined tax on it. I am the happiest person ever. Life to me was never about accomplishment, but about Happiness, which is Smiles minus Frowns. I developed these philosophies when I was 18-20 years old and I never sold out.
— Steve Wozniak, in a comment on Slashdot
Seven replies to the viral Apple reasoning paper – and why they fall short (via) A few weeks ago Apple Research released a new paper The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity.
Through extensive experimentation across diverse puzzles, we show that frontier LRMs face a complete accuracy collapse beyond certain complexities. Moreover, they exhibit a counter-intuitive scaling limit: their reasoning effort increases with problem complexity up to a point, then declines despite having an adequate token budget.
I skimmed the paper and it struck me as a more thorough example of the many other trick questions that expose failings in LLMs - this time involving puzzles such as the Tower of Hanoi that can have their difficulty level increased to the point that even "reasoning" LLMs run out of output tokens and fail to complete them.
I thought this paper got way more attention than it warranted - the title "The Illusion of Thinking" captured the attention of the "LLMs are over-hyped junk" crowd. I saw enough well-reasoned rebuttals that I didn't feel it worth digging into.
And now, notable LLM skeptic Gary Marcus has saved me some time by aggregating the best of those rebuttals together in one place!
Gary rebuts those rebuttals, but given that his previous headline concerning this paper was a knockout blow for LLMs? it's not surprising that he finds those arguments unconvincing. From that previous piece:
The vision of AGI I have always had is one that combines the strengths of humans with the strength of machines, overcoming the weaknesses of humans. I am not interested in a “AGI” that can’t do arithmetic, and I certainly wouldn’t want to entrust global infrastructure or the future of humanity to such a system.
Then from his new post:
The paper is not news; we already knew these models generalize poorly. True! (I personally have been trying to tell people this for almost thirty years; Subbarao Rao Kambhampati has been trying his best, too). But then why do we think these models are the royal road to AGI?
And therein lies my disagreement. I'm not interested in whether or not LLMs are the "road to AGI". I continue to care only about whether they have useful applications today, once you've understood their limitations.
Reasoning LLMs are a relatively new and interesting twist on the genre. They are demonstrably able to solve a whole bunch of problems that previous LLMs were unable to handle, hence why we've seen a rush of new models from OpenAI and Anthropic and Gemini and DeepSeek and Qwen and Mistral.
They get even more interesting when you combine them with tools.
{kind=link}
They're already useful to me today, whether or not they can reliably solve the Tower of Hanoi or River Crossing puzzles.
Update: Gary clarifies that "the existence of some utility does not mean I can’t also address the rampant but misguided claims of imminent AGI".
WWDC: Apple supercharges its tools and technologies for developers. Here's the Apple press release for today's WWDC announcements. Two things that stood out to me:
Foundation Models Framework
With the Foundation Models framework, developers will be able to build on Apple Intelligence to bring users new experiences that are intelligent, available when they’re offline, and that protect their privacy, using AI inference that is free of cost. The framework has native support for Swift, so developers can easily access the Apple Intelligence model with as few as three lines of code.
Here's new documentation on Generating content and performing tasks with Foundation Models - the Swift code looks like this:
let session = LanguageModelSession( instructions: "Reply with step by step instructions" ) let prompt = "Rum old fashioned cocktail" let response = try await session.respond( to: prompt, options: GenerationOptions(temperature: 2.0) )
There's also a 23 minute Meet the Foundation Models framework video from the conference, which clarifies that this is a 3 billion parameter model with 2 bit quantization. The model is trained for both tool-calling and structured output, which they call "guided generation" and describe as taking advantage of constrained decoding.
I'm also very excited about this:
Containerization Framework
The Containerization framework enables developers to create, download, or run Linux container images directly on Mac. It’s built on an open-source framework optimized for Apple silicon and provides secure isolation between container images.
I continue to seek the ideal sandboxing solution for running untrusted code - both from other humans and written for me by LLMs - on my own machines. This looks like it could be a really great option for that going forward.
It looks like apple/container on GitHub is part of this new feature. From the technical overview:
On macOS, the typical way to run Linux containers is to launch a Linux virtual machine (VM) that hosts all of your containers.
containerruns containers differently. Using the open source Containerization package, it runs a lightweight VM for each container that you create. [...]Since
containerconsumes and produces standard OCI images, you can easily build with and run images produced by other container applications, and the images that you build will run everywhere.
Apple’s Siri Chief Calls AI Delays Ugly and Embarrassing, Promises Fixes (via) Mark Gurman reports on some leaked details from internal Apple meetings concerning the delays in shipping personalized Siri. This note in particular stood out to me:
Walker said the decision to delay the features was made because of quality issues and that the company has found the technology only works properly up to two-thirds to 80% of the time. He said the group “can make more progress to get those percentages up, so that users get something they can really count on.” [...]
But Apple wants to maintain a high bar and only deliver the features when they’re polished, he said. “These are not quite ready to go to the general public, even though our competitors might have launched them in this state or worse.”
I imagine it's a lot harder to get reliable results out of small, local LLMs that run on an iPhone. Features that fail 1/3 to 1/5 of the time are unacceptable for a consumer product like this.
Something Is Rotten in the State of Cupertino. John Gruber's blazing takedown of Apple's failure to ship many of the key Apple Intelligence features they've been actively promoting for the past twelve months.
The fiasco here is not that Apple is late on AI. It's also not that they had to announce an embarrassing delay on promised features last week. Those are problems, not fiascos, and problems happen. They're inevitable. [...] The fiasco is that Apple pitched a story that wasn't true, one that some people within the company surely understood wasn't true, and they set a course based on that.
John divides the Apple Intelligence features into the ones that were demonstrated to members of the press (including himself) at various events over the past year compared to things like "personalized Siri" that were only ever shown as concept videos. The ones that were demonstrated have all shipped. The concept video features are indeterminably delayed.
Apple Is Delaying the ‘More Personalized Siri’ Apple Intelligence Features. Apple told John Gruber (and other Apple press) this about the new "personalized" Siri:
It’s going to take us longer than we thought to deliver on these features and we anticipate rolling them out in the coming year.
I have a hunch that this delay might relate to security.
These new Apple Intelligence features involve Siri responding to requests to access information in applications and then performing actions on the user's behalf.
This is the worst possible combination for prompt injection attacks! Any time an LLM-based system has access to private data, tools it can call, and exposure to potentially malicious instructions (like emails and text messages from untrusted strangers) there's a significant risk that an attacker might subvert those tools and use them to damage or exfiltrating a user's data.
I published this piece about the risk of prompt injection to personal digital assistants back in November 2023, and nothing has changed since then to make me think this is any less of an open problem.
The Graphing Calculator Story (via) Utterly delightful story from Ron Avitzur in 2004 about the origins of the Graphing Calculator app that shipped with many versions of macOS. Ron's contract with Apple had ended but his badge kept working so he kept on letting himself in to work on the project. He even grew a small team:
I asked my friend Greg Robbins to help me. His contract in another division at Apple had just ended, so he told his manager that he would start reporting to me. She didn't ask who I was and let him keep his office and badge. In turn, I told people that I was reporting to him. Since that left no managers in the loop, we had no meetings and could be extremely productive
Run LLMs on macOS using llm-mlx and Apple’s MLX framework
llm-mlx is a brand new plugin for my LLM Python Library and CLI utility which builds on top of Apple’s excellent MLX array framework library and mlx-lm package. If you’re a terminal user or Python developer with a Mac this may be the new easiest way to start exploring local Large Language Models.
[... 1,524 words]When I give money to a charitable cause, I always look for the checkboxes to opt out of being contacted by them in the future. When it happens anyway, I get annoyed, and I become reluctant to give to that charity again. [...]
When you donate to the Red Cross via Apple, that concern is off the table. Apple won’t emphasize that aspect of this, because they don’t want to throw the Red Cross under the proverbial bus, but I will. An underrated aspect of privacy is the desire simply not to be annoyed.
Run DeepSeek R1 or V3 with MLX Distributed (via) Handy detailed instructions from Awni Hannun on running the enormous DeepSeek R1 or v3 models on a cluster of Macs using the distributed communication feature of Apple's MLX library.
DeepSeek R1 quantized to 4-bit requires 450GB in aggregate RAM, which can be achieved by a cluster of three 192 GB M2 Ultras ($16,797 will buy you three 192GB Apple M2 Ultra Mac Studios at $5,599 each).
I Live My Life a Quarter Century at a Time (via) Delightful Steve Jobs era Apple story from James Thomson, who built the first working prototype of the macOS Dock.
I still don’t think companies serve you ads based on spying through your microphone
One of my weirder hobbies is trying to convince people that the idea that companies are listening to you through your phone’s microphone and serving you targeted ads is a conspiracy theory that isn’t true. I wrote about this previously: Facebook don’t spy on you through your microphone.
[... 698 words]2024
BBC complains to Apple over misleading shooting headline. This is bad: the Apple Intelligence feature that uses (on device) LLMs to present a condensed, summarized set of notifications misrepresented a BBC headline as "Luigi Mangione shoots himself".
Ken Schwencke caught that same feature incorrectly condensing a New York Times headline about an ICC arrest warrant for Netanyahu as "Netanyahu arrested".
My understanding is that these notification summaries are generated directly on-device, using Apple's own custom 3B parameter model.
The main lesson I think this illustrates is that it's not responsible to outsource headline summarization to an LLM without incorporating human review: there are way too many ways this could result in direct misinformation.
Update 16th January 2025: Apple plans to disable A.I. features summarizing news notifications, by Tripp Mickle for the New York Times.
Apple’s Knowledge Navigator concept video (1987) (via) I learned about this video today while engaged in my irresistible bad habit of arguing about whether or not "agents" means anything useful.
It turns out CEO John Sculley's Apple in 1987 promoted a concept called Knowledge Navigator (incorporating input from Alan Kay) which imagined a future where computers hosted intelligent "agents" that could speak directly to their operators and perform tasks such as research and calendar management.
This video was produced for John Sculley's keynote at the 1987 Educom higher education conference imagining a tablet-style computer with an agent called "Phil".
It's fascinating how close we are getting to this nearly 40 year old concept with the most recent demos from AI labs like OpenAI. Their Introducing GPT-4o video feels very similar in all sorts of ways.
mlx-vlm (via) The MLX ecosystem of libraries for running machine learning models on Apple Silicon continues to expand. Prince Canuma is actively developing this library for running vision models such as Qwen-2 VL and Pixtral and LLaVA using Python running on a Mac.
I used uv to run it against this image with this shell one-liner:
uv run --with mlx-vlm \
python -m mlx_vlm.generate \
--model Qwen/Qwen2-VL-2B-Instruct \
--max-tokens 1000 \
--temp 0.0 \
--image https://static.simonwillison.net/static/2024/django-roadmap.png \
--prompt "Describe image in detail, include all text"
The --image option works equally well with a URL or a path to a local file on disk.
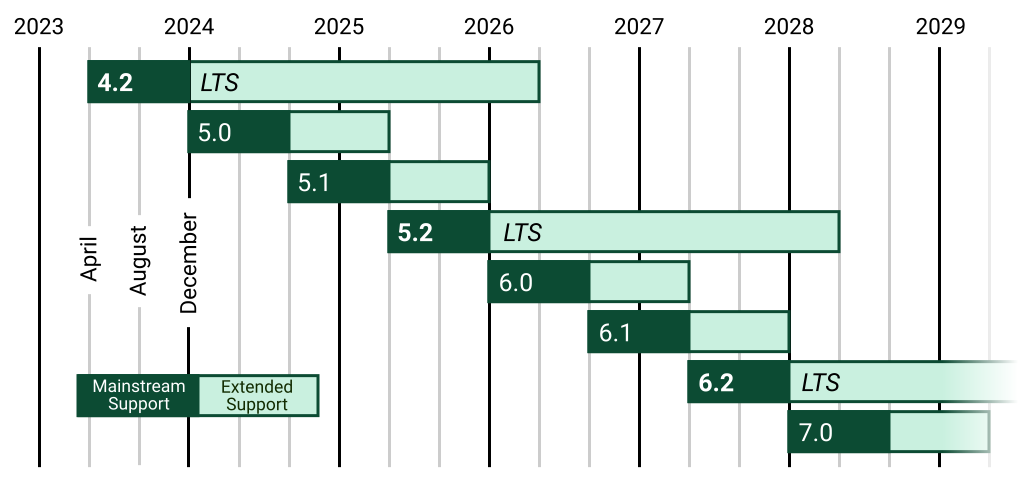
This first downloaded 4.1GB to my ~/.cache/huggingface/hub/models--Qwen--Qwen2-VL-2B-Instruct folder and then output this result, which starts:
The image is a horizontal timeline chart that represents the release dates of various software versions. The timeline is divided into years from 2023 to 2029, with each year represented by a vertical line. The chart includes a legend at the bottom, which distinguishes between different types of software versions.
Legend
Mainstream Support:
- 4.2 (2023)
- 5.0 (2024)
- 5.1 (2025)
- 5.2 (2026)
- 6.0 (2027) [...]
mlx-whisper
(via)
Apple's MLX framework for running GPU-accelerated machine learning models on Apple Silicon keeps growing new examples. mlx-whisper is a Python package for running OpenAI's Whisper speech-to-text model. It's really easy to use:
pip install mlx-whisper
Then in a Python console:
>>> import mlx_whisper
>>> result = mlx_whisper.transcribe(
... "/tmp/recording.mp3",
... path_or_hf_repo="mlx-community/distil-whisper-large-v3")
.gitattributes: 100%|███████████| 1.52k/1.52k [00:00<00:00, 4.46MB/s]
config.json: 100%|██████████████| 268/268 [00:00<00:00, 843kB/s]
README.md: 100%|████████████████| 332/332 [00:00<00:00, 1.95MB/s]
Fetching 4 files: 50%|████▌ | 2/4 [00:01<00:01, 1.26it/s]
weights.npz: 63%|██████████ ▎ | 944M/1.51G [02:41<02:15, 4.17MB/s]
>>> result.keys()
dict_keys(['text', 'segments', 'language'])
>>> result['language']
'en'
>>> len(result['text'])
100105
>>> print(result['text'][:3000])
This is so exciting. I have to tell you, first of all ...Here's Activity Monitor confirming that the Python process is using the GPU for the transcription:

This example downloaded a 1.5GB model from Hugging Face and stashed it in my ~/.cache/huggingface/hub/models--mlx-community--distil-whisper-large-v3 folder.
Calling .transcribe(filepath) without the path_or_hf_repo argument uses the much smaller (74.4 MB) whisper-tiny-mlx model.
A few people asked how this compares to whisper.cpp. Bill Mill compared the two and found mlx-whisper to be about 3x faster on an M1 Max.
Update: this note from Josh Marshall:
That '3x' comparison isn't fair; completely different models. I ran a test (14" M1 Pro) with the full (non-distilled) large-v2 model quantised to 8 bit (which is my pick), and whisper.cpp was 1m vs 1m36 for mlx-whisper.
I've now done a better test, using the MLK audio, multiple runs and 2 models (distil-large-v3, large-v2-8bit)... and mlx-whisper is indeed 30-40% faster
Here Are All of the Apple Intelligence Features in the iOS 18.1 Developer Beta (via) Useful rundown from Juli Clover at MacRumors of the Apple Intelligence features that are available in the brand new iOS 18.1 beta, available to developer account holders with an iPhone 15 or iPhone 15 Pro Max or Apple Silicon iPad.
I've been trying this out today. It's still clearly very early, and the on-device model that powers Siri is significantly weaker than more powerful models that I've become used to over the past two years. Similar to old Siri I find myself trying to figure out the sparse, undocumented incantations that reliably work for the things I might want my voice assistant to do for me.
My early Siri AI experience has just underlined the fact that, while there is a lot of practical, useful things that can be done with small models, they really lack the horsepower to do anything super interesting.
The [Apple Foundation Model] pre-training dataset consists of a diverse and high quality data mixture. This includes data we have licensed from publishers, curated publicly-available or open-sourced datasets, and publicly available information crawled by our web-crawler, Applebot. We respect the right of webpages to opt out of being crawled by Applebot, using standard robots.txt directives.
Given our focus on protecting user privacy, we note that no private Apple user data is included in the data mixture. Additionally, extensive efforts have been made to exclude profanity, unsafe material, and personally identifiable information from publicly available data (see Section 7 for more details). Rigorous decontamination is also performed against many common evaluation benchmarks.
We find that data quality, much more so than quantity, is the key determining factor of downstream model performance.
Python 3.12 change results in Apple App Store rejection
(via)
Such a frustrating demonstration of the very worst of Apple's opaque App Store review process. The Python 3.12 standard library urllib package includes the string itms-services, and after much investigation Eric Froemling managed to determine that Apple use a scanner and reject any app that has that string mentioned anywhere within their bundle.
Russell Keith-Magee has a thread on the Python forum discussing solutions. He doesn't think attempts to collaborate with Apple are likely to help:
That definitely sounds appealing as an approach - but in this case, it’s going to be screaming into the void. There’s barely even an appeals process for app rejection on Apple’s App Store. We definitely don’t have any sort of channel to raise a complaint that we could reasonably believe would result in a change of policy.
What Apple unveiled last week with Apple Intelligence wasn't so much new products, but new features—a slew of them—for existing products, powered by generative AI.
[...] These aren't new apps or new products. They're the most used, most important apps Apple makes, the core apps that define the Apple platforms ecosystem, and Apple is using generative AI to make them better and more useful—without, in any way, rendering them unfamiliar.
Transcripts on Apple Podcasts (via) I missed this when it launched back in March: the Apple Podcasts app now features searchable transcripts, including the ability to tap on text and jump to that point in the audio.
Confusingly, you can only tap to navigate using the view of the transcript that comes up when you hit the quote mark icon during playback - if you click the Transcript link from the episode listing page you get a static transcript without the navigation option.
Transcripts are created automatically server-side by Apple, or podcast authors can upload their own edited transcript using Apple Podcasts Connect.
Contrast [Apple Intelligence] to what OpenAI is trying to accomplish with its GPT models, or Google with Gemini, or Anthropic with Claude: those large language models are trying to incorporate all of the available public knowledge to know everything; it’s a dramatically larger and more difficult problem space, which is why they get stuff wrong. There is also a lot of stuff that they don’t know because that information is locked away — like all of the information on an iPhone.
Apple’s terminology distinguishes between “personal intelligence,” on-device and under their control, and “world knowledge,” which is prone to hallucinations – but is also what consumers expect when they use AI, and it’s what may replace Google search as the “point of first intent” one day soon.
It’s wise for them to keep world knowledge separate, behind a very clear gate, but still engage with it. Protects the brand and hedges their bets.
Introducing Apple’s On-Device and Server Foundation Models. Apple Intelligence uses both on-device and in-the-cloud models that were trained from scratch by Apple.
Their on-device model is a 3B model that "outperforms larger models including Phi-3-mini, Mistral-7B, and Gemma-7B", while the larger cloud model is comparable to GPT-3.5.
The language models were trained on unlicensed scraped data - I was hoping they might have managed to avoid that, but sadly not:
We train our foundation models on licensed data, including data selected to enhance specific features, as well as publicly available data collected by our web-crawler, AppleBot.
The most interesting thing here is the way they apply fine-tuning to the local model to specialize it for different tasks. Apple call these "adapters", and they use LoRA for this - a technique first published in 2021. This lets them run multiple on-device models based on a shared foundation, specializing in tasks such as summarization and proof-reading.
Here's the section of the Platforms State of the Union talk that talks about the foundation models and their fine-tuned variants.
As Hamel Husain says:
This talk from Apple is the best ad for fine tuning that probably exists.
The video also describes their approach to quantization:
The next step we took is compressing the model. We leveraged state-of-the-art quantization techniques to take a 16-bit per parameter model down to an average of less than 4 bits per parameter to fit on Apple Intelligence-supported devices, all while maintaining model quality.
Still no news on how their on-device image model was trained. I'd love to find out it was trained exclusively using licensed imagery - Apple struck a deal with Shutterstock a few months ago.