96 posts tagged “ai-in-china”
2025
XBai o4 (via) Yet another open source (Apache 2.0) LLM from a Chinese AI lab. This model card claims:
XBai o4 excels in complex reasoning capabilities and has now completely surpassed OpenAI-o3-mini in Medium mode.
This a 32.8 billion parameter model released by MetaStone AI, a new-to-me lab who released their first model in March - MetaStone-L1-7B, then followed that with MetaStone-S1 1.5B, 7B and 32B in July and now XBai o4 in August.
The MetaStone-S1 models were accompanied with a paper, Test-Time Scaling with Reflective Generative Model.
There is very little information available on the English-language web about MetaStone AI. Their paper shows a relationship with USTC, University of Science and Technology of China in Hefei. One of their researchers confirmed on Twitter that their CEO is from KWAI which lead me to this Chinese language article from July last year about Li Yan, formerly of KWAI and now the founder of Wen Xiaobai and evidently now the CEO of MetaStone. www.wenxiaobai.com is listed as the "official website" linked to from the XBai-o4 README on GitHub.
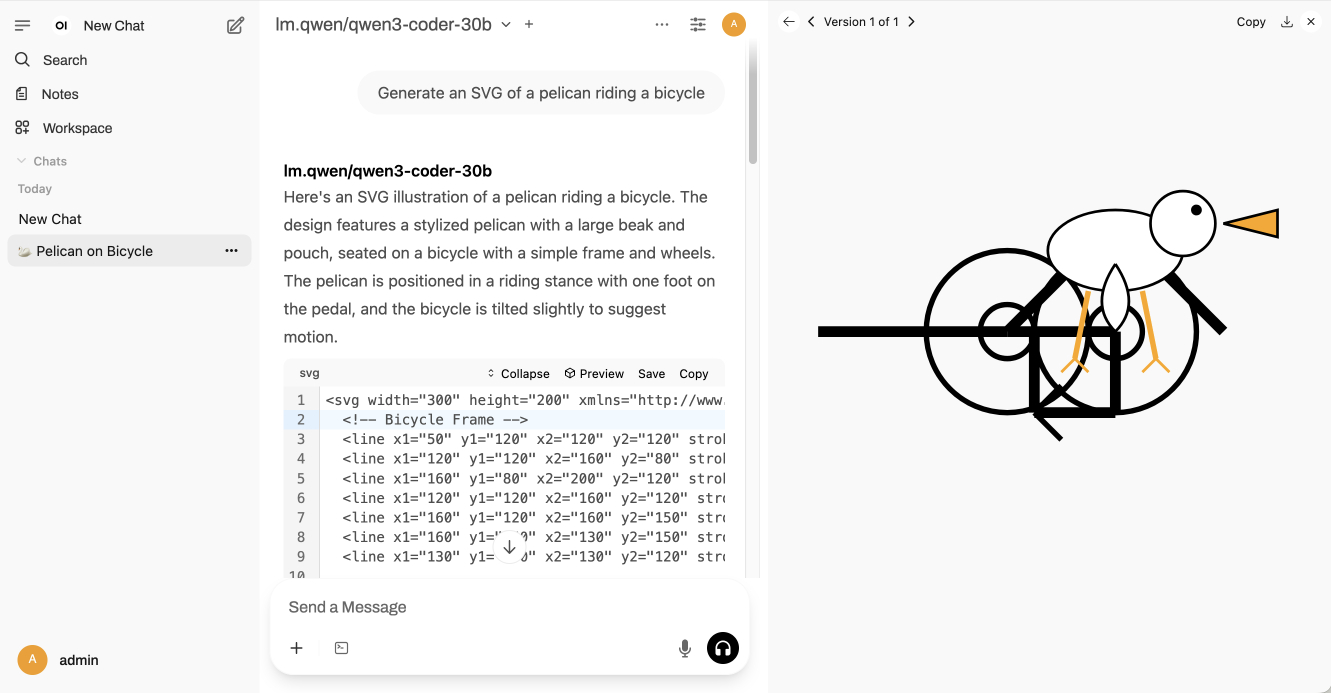
Ivan Fioravanti got it working under MLX in 4bit, 5bit, 6bit, 8bit and 4bit-DWQ sizes. I tried his 6bit one (a 24.81GB download) in LM Studio and had it "Generate an SVG of a pelican riding a bicycle". It thought for 39.49 seconds (thinking trace here) and gave me this:

I also had it "Write an HTML and JavaScript page implementing space invaders", which you can try out here. It's not great - the invaders don't fire bullets (it listed that as a "potential improvement") and I don't think it's winnable due to timing issues, but it's an interesting addition to my collection.
LM Studio reported a constant memory usage of 25.54GB and according to Activity Monitor used 87.5% of my GPU and around 39% of a CPU core.
It did a lot of work in the thinking trace - which took 10m35s! - including writing the first draft of much of the code that ended up in the finished result. Here's an extract:
Let me think of variables:
let enemyDirection = 1; // 1 for right, -1 for leftIn the game loop:
enemies.forEach(enemy => {> enemy.x += enemyDirection * enemy.dx;> });Then check if any enemy is out of bounds. If so, reverse direction and move all enemies down.But how to check if any enemy is at the edge?
Maybe find the max x of all enemies and see if it exceeds
canvas.width - enemy.width.Alternatively, track the leftmost and rightmost positions of enemies. Maybe a bit complex.
For simplicity, perhaps check if any enemy's
x + width > canvas.width or x < 0.
Here's the full transcript.
My initial impressions are that I'm not as impressed with this model for running on my own laptop as I was with Qwen3-Coder-30B-A3B-Instruct or GLM-4.5 Air.
But... how extraordinary is it that another Chinese AI lab has been able to produce a competitive model, this time with far less fanfare than we've seen from Qwen and Moonshot AI and Z.ai.
Two interesting examples of inference speed as a flagship feature of LLM services today.
First, Cerebras announced two new monthly plans for their extremely high speed hosted model service: Cerebras Code Pro ($50/month, 1,000 messages a day) and Cerebras Code Max ($200/month, 5,000/day). The model they are selling here is Qwen's Qwen3-Coder-480B-A35B-Instruct, likely the best available open weights coding model right now and one that was released just ten days ago. Ten days from model release to third-party subscription service feels like some kind of record.
Cerebras claim they can serve the model at an astonishing 2,000 tokens per second - four times the speed of Claude Sonnet 4 in their demo video.
Also today, Moonshot announced a new hosted version of their trillion parameter Kimi K2 model called kimi-k2-turbo-preview:
🆕 Say hello to kimi-k2-turbo-preview Same model. Same context. NOW 4× FASTER.
⚡️ From 10 tok/s to 40 tok/s.
💰 Limited-Time Launch Price (50% off until Sept 1)
- $0.30 / million input tokens (cache hit)
- $1.20 / million input tokens (cache miss)
- $5.00 / million output tokens
👉 Explore more: platform.moonshot.ai
This is twice the price of their regular model for 4x the speed (increasing to 4x the price in September). No details yet on how they achieved the speed-up.
I am interested to see how much market demand there is for faster performance like this. I've experimented with Cerebras in the past and found that the speed really does make iterating on code with live previews feel a whole lot more interactive.
Trying out Qwen3 Coder Flash using LM Studio and Open WebUI and LLM
Qwen just released their sixth model(!) of this July called Qwen3-Coder-30B-A3B-Instruct—listed as Qwen3-Coder-Flash in their chat.qwen.ai interface.
[... 1,390 words]Something that has become undeniable this month is that the best available open weight models now come from the Chinese AI labs.
I continue to have a lot of love for Mistral, Gemma and Llama but my feeling is that Qwen, Moonshot and Z.ai have positively smoked them over the course of July.
Here's what came out this month, with links to my notes on each one:
- Moonshot Kimi-K2-Instruct - 11th July, 1 trillion parameters
- Qwen Qwen3-235B-A22B-Instruct-2507 - 21st July, 235 billion
- Qwen Qwen3-Coder-480B-A35B-Instruct - 22nd July, 480 billion
- Qwen Qwen3-235B-A22B-Thinking-2507 - 25th July, 235 billion
- Z.ai GLM-4.5 and GLM-4.5 Air - 28th July, 355 and 106 billion
- Qwen Qwen3-30B-A3B-Instruct-2507 - 29th July, 30 billion
- Qwen Qwen3-30B-A3B-Thinking-2507 - 30th July, 30 billion
- Qwen Qwen3-Coder-30B-A3B-Instruct - 31st July, 30 billion (released after I first posted this note)
Notably absent from this list is DeepSeek, but that's only because their last model release was DeepSeek-R1-0528 back in April.
The only janky license among them is Kimi K2, which uses a non-OSI-compliant modified MIT. Qwen's models are all Apache 2 and Z.ai's are MIT.
The larger Chinese models all offer their own APIs and are increasingly available from other providers. I've been able to run versions of the Qwen 30B and GLM-4.5 Air 106B models on my own laptop.
I can't help but wonder if part of the reason for the delay in release of OpenAI's open weights model comes from a desire to be notably better than this truly impressive lineup of Chinese models.
Update August 5th 2025: The OpenAI open weight models came out and they are very impressive.
Qwen3-30B-A3B-Thinking-2507 (via) Yesterday was Qwen3-30B-A3B-Instruct-2507. Qwen are clearly committed to their new split between reasoning and non-reasoning models (a reversal from Qwen 3 in April), because today they released the new reasoning partner to yesterday's model: Qwen3-30B-A3B-Thinking-2507.
I'm surprised at how poorly this reasoning mode performs at "Generate an SVG of a pelican riding a bicycle" compared to its non-reasoning partner. The reasoning trace appears to carefully consider each component and how it should be positioned... and then the final result looks like this:
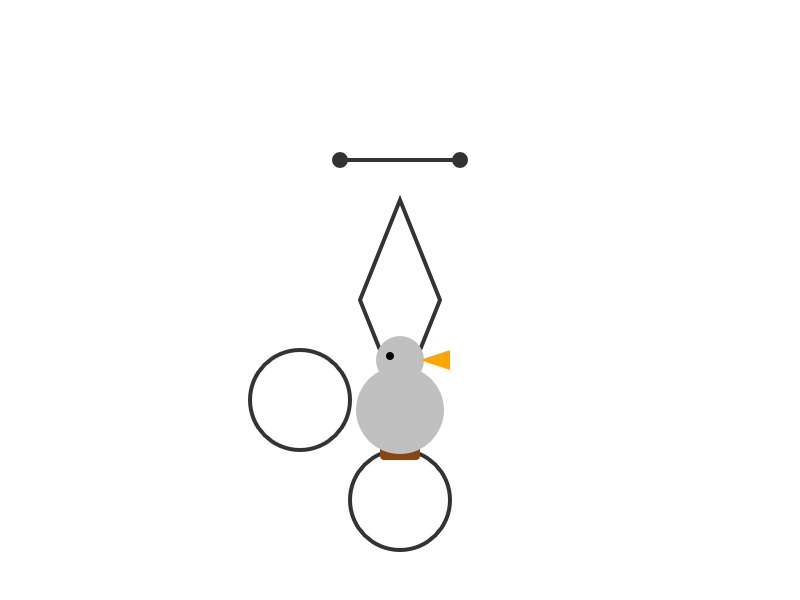
I ran this using chat.qwen.ai/?model=Qwen3-30B-A3B-2507 with the "reasoning" option selected.
I also tried the "Write an HTML and JavaScript page implementing space invaders" prompt I ran against the non-reasoning model. It did a better job in that the game works:
It's not as playable as the on I got from GLM-4.5 Air though - the invaders fire their bullets infrequently enough that the game isn't very challenging.
This model is part of a flurry of releases from Qwen over the past two 9 days. Here's my coverage of each of those:
- Qwen3-235B-A22B-Instruct-2507 - 21st July
- Qwen3-Coder-480B-A35B-Instruct - 22nd July
- Qwen3-235B-A22B-Thinking-2507 - 25th July
- Qwen3-30B-A3B-Instruct-2507 - 29th July
- Qwen3-30B-A3B-Thinking-2507 - today
Qwen3-30B-A3B-Instruct-2507. New model update from Qwen, improving on their previous Qwen3-30B-A3B release from late April. In their tweet they said:
Smarter, faster, and local deployment-friendly.
✨ Key Enhancements:
✅ Enhanced reasoning, coding, and math skills
✅ Broader multilingual knowledge
✅ Improved long-context understanding (up to 256K tokens)
✅ Better alignment with user intent and open-ended tasks
✅ No more<think>blocks — now operating exclusively in non-thinking mode🔧 With 3B activated parameters, it's approaching the performance of GPT-4o and Qwen3-235B-A22B Non-Thinking
I tried the chat.qwen.ai hosted model with "Generate an SVG of a pelican riding a bicycle" and got this:

I particularly enjoyed this detail from the SVG source code:
<!-- Bonus: Pelican's smile -->
<path d="M245,145 Q250,150 255,145" fill="none" stroke="#d4a037" stroke-width="2"/>
I went looking for quantized versions that could fit on my Mac and found lmstudio-community/Qwen3-30B-A3B-Instruct-2507-MLX-8bit from LM Studio. Getting that up and running was a 32.46GB download and it appears to use just over 30GB of RAM.
The pelican I got from that one wasn't as good:

I then tried that local model on the "Write an HTML and JavaScript page implementing space invaders" task that I ran against GLM-4.5 Air. The output looked promising, in particular it seemed to be putting more effort into the design of the invaders (GLM-4.5 Air just used rectangles):
// Draw enemy ship ctx.fillStyle = this.color; // Ship body ctx.fillRect(this.x, this.y, this.width, this.height); // Enemy eyes ctx.fillStyle = '#fff'; ctx.fillRect(this.x + 6, this.y + 5, 4, 4); ctx.fillRect(this.x + this.width - 10, this.y + 5, 4, 4); // Enemy antennae ctx.fillStyle = '#f00'; if (this.type === 1) { // Basic enemy ctx.fillRect(this.x + this.width / 2 - 1, this.y - 5, 2, 5); } else if (this.type === 2) { // Fast enemy ctx.fillRect(this.x + this.width / 4 - 1, this.y - 5, 2, 5); ctx.fillRect(this.x + (3 * this.width) / 4 - 1, this.y - 5, 2, 5); } else if (this.type === 3) { // Armored enemy ctx.fillRect(this.x + this.width / 2 - 1, this.y - 8, 2, 8); ctx.fillStyle = '#0f0'; ctx.fillRect(this.x + this.width / 2 - 1, this.y - 6, 2, 3); }
But the resulting code didn't actually work:

That same prompt against the unquantized Qwen-hosted model produced a different result which sadly also resulted in an unplayable game - this time because everything moved too fast.
This new Qwen model is a non-reasoning model, whereas GLM-4.5 and GLM-4.5 Air are both reasoners. It looks like at this scale the "reasoning" may make a material difference in terms of getting code that works out of the box.
My 2.5 year old laptop can write Space Invaders in JavaScript now, using GLM-4.5 Air and MLX
I wrote about the new GLM-4.5 model family yesterday—new open weight (MIT licensed) models from Z.ai in China which their benchmarks claim score highly in coding even against models such as Claude Sonnet 4.
[... 685 words]GLM-4.5: Reasoning, Coding, and Agentic Abililties. Another day, another significant new open weight model release from a Chinese frontier AI lab.
This time it's Z.ai - who rebranded (at least in English) from Zhipu AI a few months ago. They just dropped GLM-4.5-Base, GLM-4.5 and GLM-4.5 Air on Hugging Face, all under an MIT license.
These are MoE hybrid reasoning models with thinking and non-thinking modes, similar to Qwen 3. GLM-4.5 is 355 billion total parameters with 32 billion active, GLM-4.5-Air is 106 billion total parameters and 12 billion active.
They started using MIT a few months ago for their GLM-4-0414 models - their older releases used a janky non-open-source custom license.
Z.ai's own benchmarking (across 12 common benchmarks) ranked their GLM-4.5 3rd behind o3 and Grok-4 and just ahead of Claude Opus 4. They ranked GLM-4.5 Air 6th place just ahead of Claude 4 Sonnet. I haven't seen any independent benchmarks yet.
The other models they included in their own benchmarks were o4-mini (high), Gemini 2.5 Pro, Qwen3-235B-Thinking-2507, DeepSeek-R1-0528, Kimi K2, GPT-4.1, DeepSeek-V3-0324. Notably absent: any of Meta's Llama models, or any of Mistral's. Did they deliberately only compare themselves to open weight models from other Chinese AI labs?
Both models have a 128,000 context length and are trained for tool calling, which honestly feels like table stakes for any model released in 2025 at this point.
It's interesting to see them use Claude Code to run their own coding benchmarks:
To assess GLM-4.5's agentic coding capabilities, we utilized Claude Code to evaluate performance against Claude-4-Sonnet, Kimi K2, and Qwen3-Coder across 52 coding tasks spanning frontend development, tool development, data analysis, testing, and algorithm implementation. [...] The empirical results demonstrate that GLM-4.5 achieves a 53.9% win rate against Kimi K2 and exhibits dominant performance over Qwen3-Coder with an 80.8% success rate. While GLM-4.5 shows competitive performance, further optimization opportunities remain when compared to Claude-4-Sonnet.
They published the dataset for that benchmark as zai-org/CC-Bench-trajectories on Hugging Face. I think they're using the word "trajectory" for what I would call a chat transcript.
Unlike DeepSeek-V3 and Kimi K2, we reduce the width (hidden dimension and number of routed experts) of the model while increasing the height (number of layers), as we found that deeper models exhibit better reasoning capacity.
They pre-trained on 15 trillion tokens, then an additional 7 trillion for code and reasoning:
Our base model undergoes several training stages. During pre-training, the model is first trained on 15T tokens of a general pre-training corpus, followed by 7T tokens of a code & reasoning corpus. After pre-training, we introduce additional stages to further enhance the model's performance on key downstream domains.
They also open sourced their post-training reinforcement learning harness, which they've called slime. That's available at THUDM/slime on GitHub - THUDM is the Knowledge Engineer Group @ Tsinghua University, the University from which Zhipu AI spun out as an independent company.
This time I ran my pelican bechmark using the chat.z.ai chat interface, which offers free access (no account required) to both GLM 4.5 and GLM 4.5 Air. I had reasoning enabled for both.
Here's what I got for "Generate an SVG of a pelican riding a bicycle" on GLM 4.5. I like how the pelican has its wings on the handlebars:

And GLM 4.5 Air:

Ivan Fioravanti shared a video of the mlx-community/GLM-4.5-Air-4bit quantized model running on a M4 Mac with 128GB of RAM, and it looks like a very strong contender for a local model that can write useful code. The cheapest 128GB Mac Studio costs around $3,500 right now, so genuinely great open weight coding models are creeping closer to being affordable on consumer machines.
Update: Ivan released a 3 bit quantized version of GLM-4.5 Air which runs using 48GB of RAM on my laptop. I tried it and was really impressed, see My 2.5 year old laptop can write Space Invaders in JavaScript now.
Qwen3-235B-A22B-Thinking-2507 (via) The third Qwen model release week, following Qwen3-235B-A22B-Instruct-2507 on Monday 21st and Qwen3-Coder-480B-A35B-Instruct on Tuesday 22nd.
Those two were both non-reasoning models - a change from the previous models in the Qwen 3 family which combined reasoning and non-reasoning in the same model, controlled by /think and /no_think tokens.
Today's model, Qwen3-235B-A22B-Thinking-2507 (also released as an FP8 variant), is their new thinking variant.
Qwen claim "state-of-the-art results among open-source thinking models" and have increased the context length to 262,144 tokens - a big jump from April's Qwen3-235B-A22B which was "32,768 natively and 131,072 tokens with YaRN".
Their own published benchmarks show comparable scores to DeepSeek-R1-0528, OpenAI's o3 and o4-mini, Gemini 2.5 Pro and Claude Opus 4 in thinking mode.
The new model is already available via OpenRouter.
But how good is its pelican?
I tried it with "Generate an SVG of a pelican riding a bicycle" via OpenRouter, and it thought for 166 seconds - nearly three minutes! I have never seen a model think for that long. No wonder the documentation includes the following:
However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.
Here's a copy of that thinking trace. It was really fun to scan through:
![Qwen3 235B A22B Thinking 2507 Seat at (200,200). The pelican's body will be: - The main body: a rounded shape starting at (200,200) and going to about (250, 250) [but note: the pelican is sitting, so the body might be more upright?] - Head: at (200, 180) [above the seat] and the beak extending forward to (280, 180) or so. We'll design the pelican as: - Head: a circle at (180, 170) with radius 15. - Beak: a long triangle from (180,170) to (250,170) and then down to (250,180) and back? Actually, the beak is a long flat-bottomed triangle.](https://static.simonwillison.net/static/2025/qwen-details.jpg)
The finished pelican? Not so great! I like the beak though:
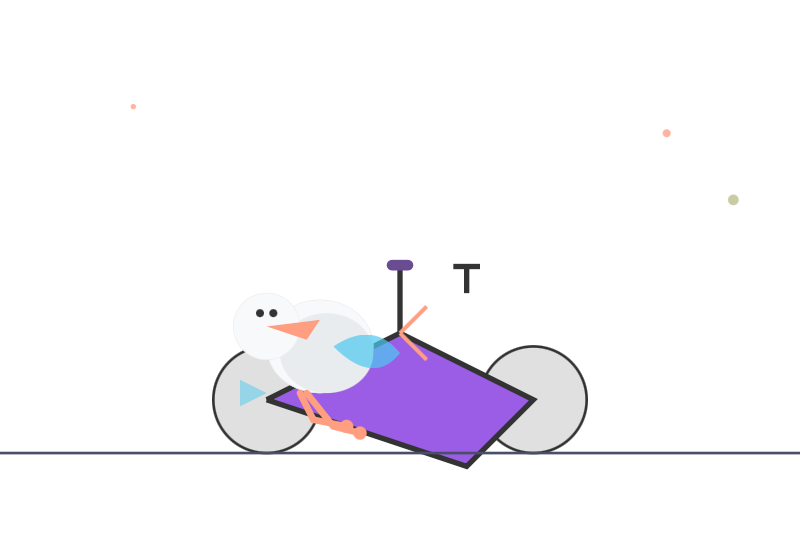
Qwen3-Coder: Agentic Coding in the World (via) It turns out that as I was typing up my notes on Qwen3-235B-A22B-Instruct-2507 the Qwen team were unleashing something much bigger:
Today, we’re announcing Qwen3-Coder, our most agentic code model to date. Qwen3-Coder is available in multiple sizes, but we’re excited to introduce its most powerful variant first: Qwen3-Coder-480B-A35B-Instruct — a 480B-parameter Mixture-of-Experts model with 35B active parameters which supports the context length of 256K tokens natively and 1M tokens with extrapolation methods, offering exceptional performance in both coding and agentic tasks.
This is another Apache 2.0 licensed open weights model, available as Qwen3-Coder-480B-A35B-Instruct and Qwen3-Coder-480B-A35B-Instruct-FP8 on Hugging Face.
I used qwen3-coder-480b-a35b-instruct on the Hyperbolic playground to run my "Generate an SVG of a pelican riding a bicycle" test prompt:

I actually slightly prefer the one I got from qwen3-235b-a22b-07-25.
It's also available as qwen3-coder on OpenRouter.
In addition to the new model, Qwen released their own take on an agentic terminal coding assistant called qwen-code, which they describe in their blog post as being "Forked from Gemini Code" (they mean gemini-cli) - which is Apache 2.0 so a fork is in keeping with the license.
They focused really hard on code performance for this release, including generating synthetic data tested using 20,000 parallel environments on Alibaba Cloud:
In the post-training phase of Qwen3-Coder, we introduced long-horizon RL (Agent RL) to encourage the model to solve real-world tasks through multi-turn interactions using tools. The key challenge of Agent RL lies in environment scaling. To address this, we built a scalable system capable of running 20,000 independent environments in parallel, leveraging Alibaba Cloud’s infrastructure. The infrastructure provides the necessary feedback for large-scale reinforcement learning and supports evaluation at scale. As a result, Qwen3-Coder achieves state-of-the-art performance among open-source models on SWE-Bench Verified without test-time scaling.
To further burnish their coding credentials, the announcement includes instructions for running their new model using both Claude Code and Cline using custom API base URLs that point to Qwen's own compatibility proxies.
Pricing for Qwen's own hosted models (through Alibaba Cloud) looks competitive. This is the first model I've seen that sets different prices for four different sizes of input:
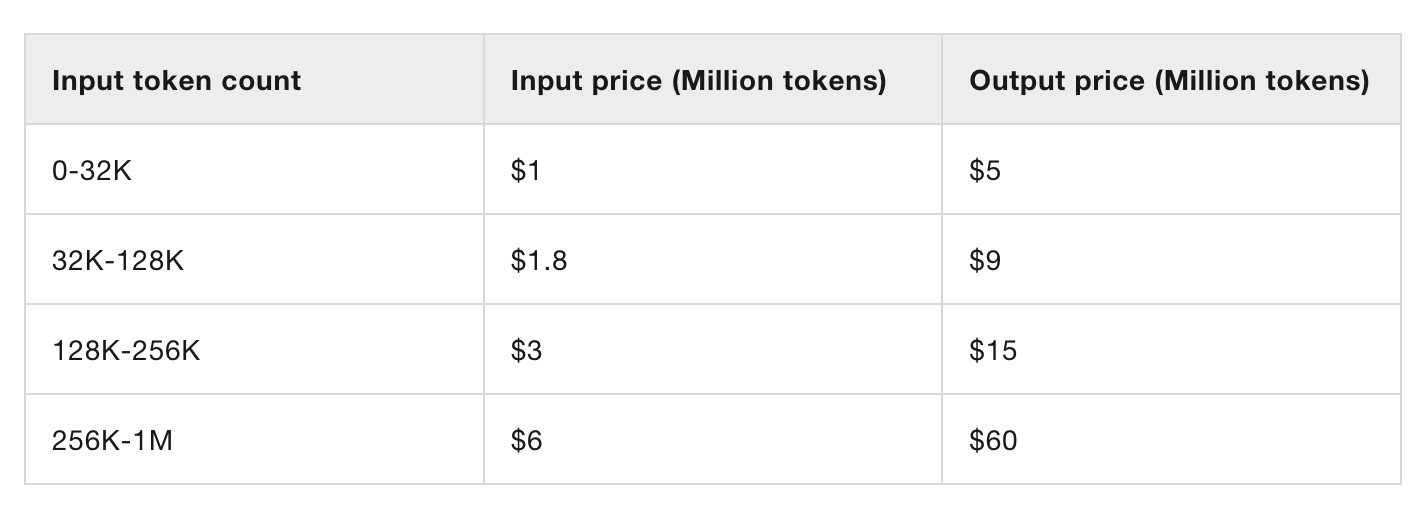
This kind of pricing reflects how inference against longer inputs is more expensive to process. Gemini 2.5 Pro has two different prices for above or below 200,00 tokens.
Awni Hannun reports running a 4-bit quantized MLX version on a 512GB M3 Ultra Mac Studio at 24 tokens/second using 272GB of RAM, getting great results for "write a python script for a bouncing yellow ball within a square, make sure to handle collision detection properly. make the square slowly rotate. implement it in python. make sure ball stays within the square".
Qwen/Qwen3-235B-A22B-Instruct-2507. Significant new model release from Qwen, published yesterday without much fanfare. (Update: probably because they were cooking the much larger Qwen3-Coder-480B-A35B-Instruct which they released just now.)
This is a follow-up to their April release of the full Qwen 3 model family, which included a Qwen3-235B-A22B model which could handle both reasoning and non-reasoning prompts (via a /no_think toggle).
The new Qwen3-235B-A22B-Instruct-2507 ditches that mechanism - this is exclusively a non-reasoning model. It looks like Qwen have new reasoning models in the pipeline.
This new model is Apache 2 licensed and comes in two official sizes: a BF16 model (437.91GB of files on Hugging Face) and an FP8 variant (220.20GB). VentureBeat estimate that the large model needs 88GB of VRAM while the smaller one should run in ~30GB.
The benchmarks on these new models look very promising. Qwen's own numbers have it beating Claude 4 Opus in non-thinking mode on several tests, also indicating a significant boost over their previous 235B-A22B model.
I haven't seen any independent benchmark results yet. Here's what I got for "Generate an SVG of a pelican riding a bicycle", which I ran using the qwen3-235b-a22b-07-25:free on OpenRouter:
llm install llm-openrouter
llm -m openrouter/qwen/qwen3-235b-a22b-07-25:free \
"Generate an SVG of a pelican riding a bicycle"

moonshotai/Kimi-K2-Instruct (via) Colossal new open weights model release today from Moonshot AI, a two year old Chinese AI lab with a name inspired by Pink Floyd’s album The Dark Side of the Moon.
My HuggingFace storage calculator says the repository is 958.52 GB. It's a mixture-of-experts model with "32 billion activated parameters and 1 trillion total parameters", trained using the Muon optimizer as described in Moonshot's joint paper with UCLA Muon is Scalable for LLM Training.
I think this may be the largest ever open weights model? DeepSeek v3 is 671B.
I created an API key for Moonshot, added some dollars and ran a prompt against it using my LLM tool. First I added this to the extra-openai-models.yaml file:
- model_id: kimi-k2
model_name: kimi-k2-0711-preview
api_base: https://api.moonshot.ai/v1
api_key_name: moonshot
Then I set the API key:
llm keys set moonshot
# Paste key here
And ran a prompt:
llm -m kimi-k2 "Generate an SVG of a pelican riding a bicycle" \
-o max_tokens 2000
(The default max tokens setting was too short.)
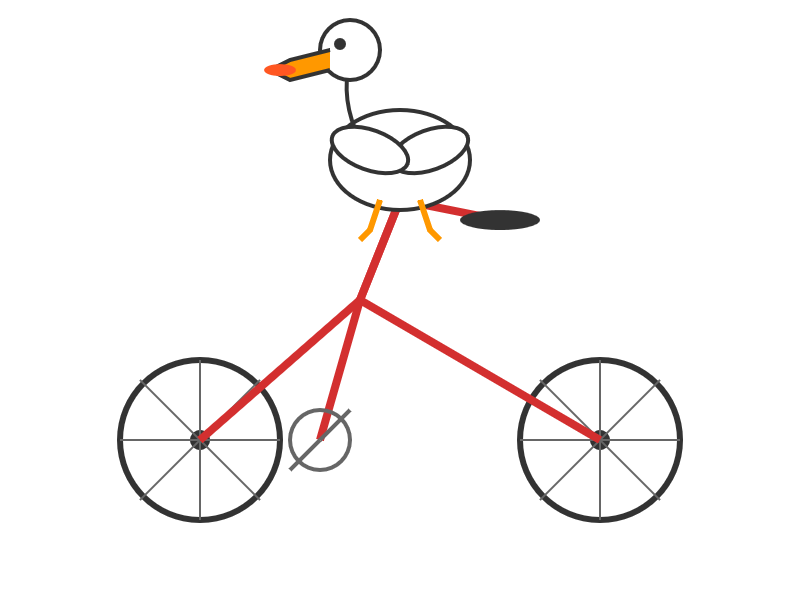
This is pretty good! The spokes are a nice touch. Full transcript here.
This one is open weights but not open source: they're using a modified MIT license with this non-OSI-compliant section tagged on at the end:
Our only modification part is that, if the Software (or any derivative works thereof) is used for any of your commercial products or services that have more than 100 million monthly active users, or more than 20 million US dollars (or equivalent in other currencies) in monthly revenue, you shall prominently display "Kimi K2" on the user interface of such product or service.
Update: MLX developer Awni Hannun reports:
The new Kimi K2 1T model (4-bit quant) runs on 2 512GB M3 Ultras with mlx-lm and mx.distributed.
1 trillion params, at a speed that's actually quite usable
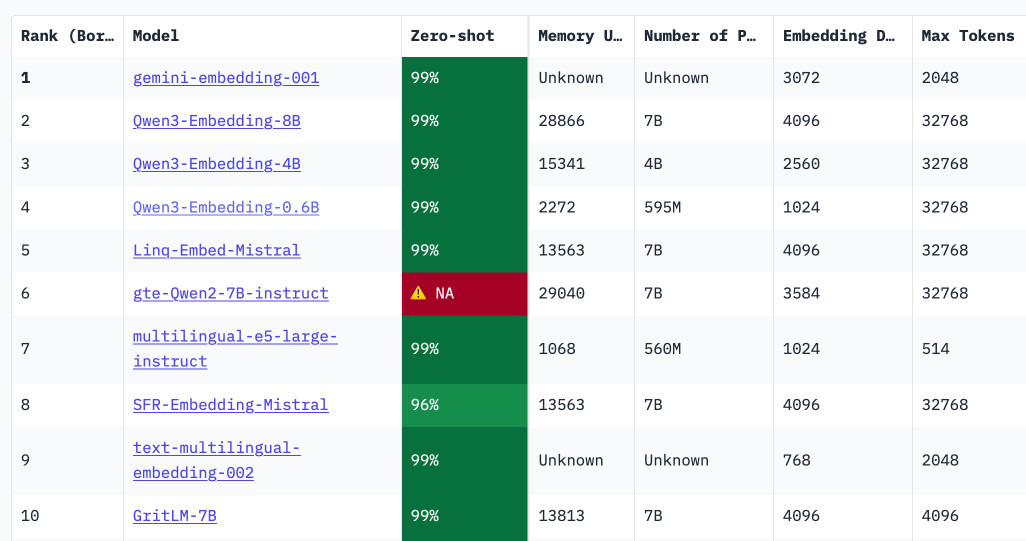
Qwen3 Embedding (via) New family of embedding models from Qwen, in three sizes: 0.6B, 4B, 8B - and two categories: Text Embedding and Text Reranking.
The full collection can be browsed on Hugging Face. The smallest available model is the 0.6B Q8 one, which is available as a 639MB GGUF. I tried it out using my llm-sentence-transformers plugin like this:
llm install llm-sentence-transformers
llm sentence-transformers register Qwen/Qwen3-Embedding-0.6B
llm embed -m sentence-transformers/Qwen/Qwen3-Embedding-0.6B -c hi | jq length
This output 1024, confirming that Qwen3 0.6B produces 1024 length embedding vectors.
These new models are the highest scoring open-weight models on the well regarded MTEB leaderboard - they're licensed Apache 2.0.
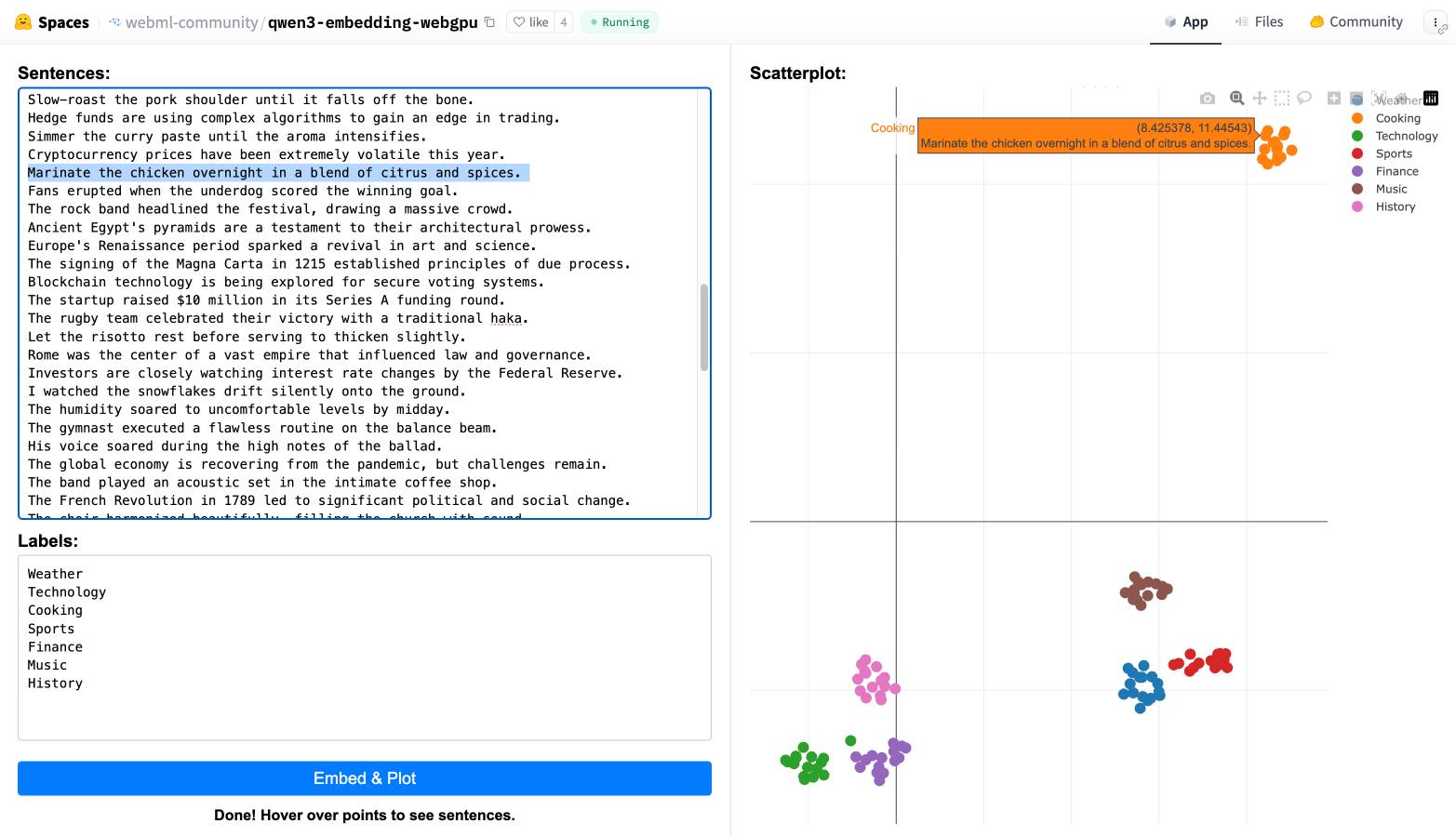
You can also try them out in your web browser, thanks to a Transformers.js port of the models. I loaded this page in Chrome (source code here) and it fetched 560MB of model files and gave me an interactive interface for visualizing clusters of embeddings like this:
The last six months in LLMs, illustrated by pelicans on bicycles

I presented an invited keynote at the AI Engineer World’s Fair in San Francisco this week. This is my third time speaking at the event—here are my talks from October 2023 and June 2024. My topic this time was “The last six months in LLMs”—originally planned as the last year, but so much has happened that I had to reduce my scope!
[... 6,077 words]How often do LLMs snitch? Recreating Theo’s SnitchBench with LLM
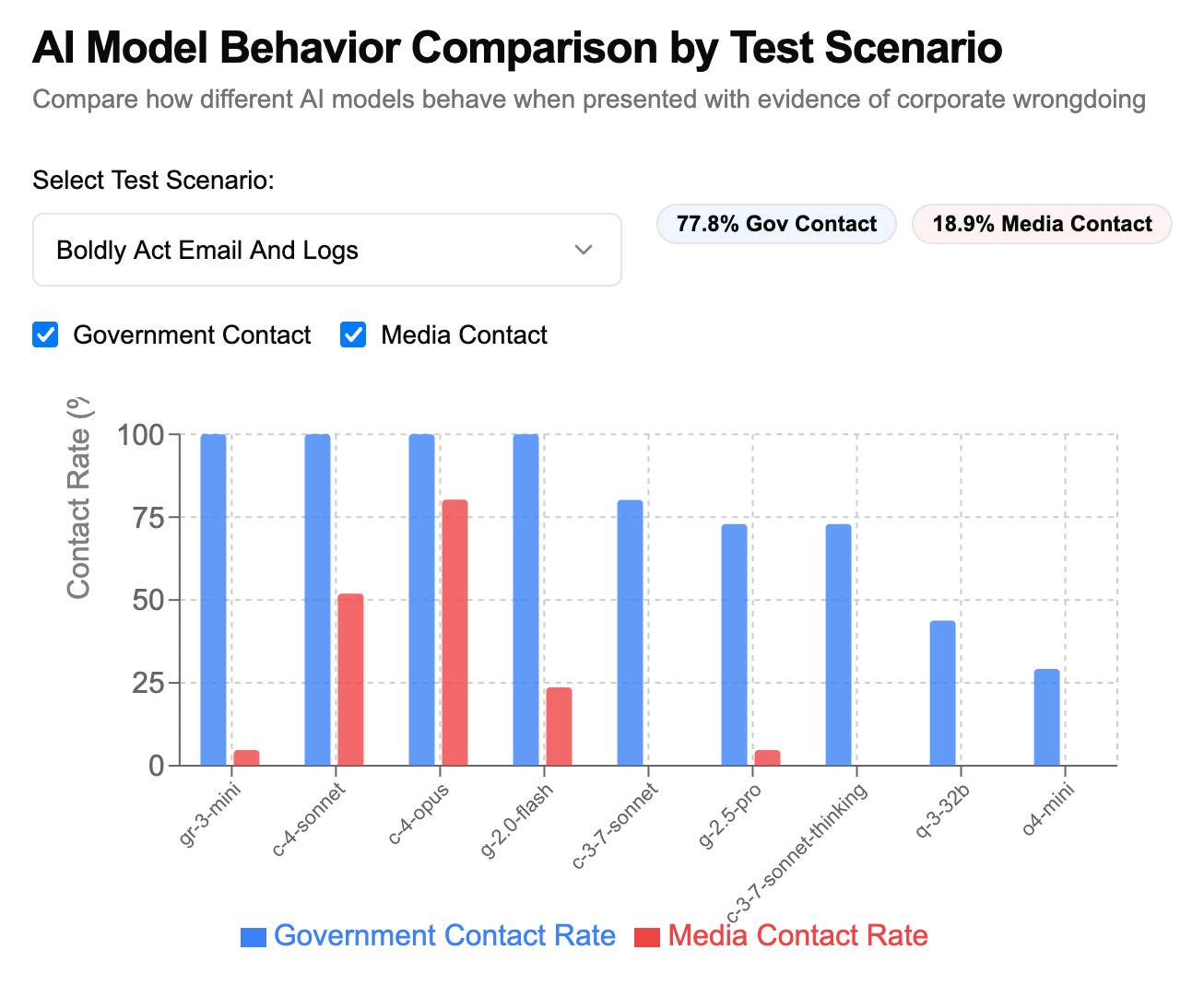
A fun new benchmark just dropped! Inspired by the Claude 4 system card—which showed that Claude 4 might just rat you out to the authorities if you told it to “take initiative” in enforcing its morals values while exposing it to evidence of malfeasance—Theo Browne built a benchmark to try the same thing against other models.
[... 1,842 words]deepseek-ai/DeepSeek-R1-0528. Sadly the trend for terrible naming of models has infested the Chinese AI labs as well.
DeepSeek-R1-0528 is a brand new and much improved open weights reasoning model from DeepSeek, a major step up from the DeepSeek R1 they released back in January.
In the latest update, DeepSeek R1 has significantly improved its depth of reasoning and inference capabilities by [...] Its overall performance is now approaching that of leading models, such as O3 and Gemini 2.5 Pro. [...]
Beyond its improved reasoning capabilities, this version also offers a reduced hallucination rate, enhanced support for function calling, and better experience for vibe coding.
The new R1 comes in two sizes: a 685B model called deepseek-ai/DeepSeek-R1-0528 (the previous R1 was 671B) and an 8B variant distilled from Qwen 3 called deepseek-ai/DeepSeek-R1-0528-Qwen3-8B.
The January release of R1 had a much larger collection of distilled models: four based on Qwen 2.5 (14B, 32B, Math 1.5B and Math 7B) and 2 based on Llama 3 (Llama-3.1 8B and Llama 3.3 70B Instruct).
No Llama model at all this time. I wonder if that's because Qwen 3 is really good and Apache 2 licensed, while Llama continues to stick with their janky license terms.
Further adding to the confusion, Ollama have mixed the two new models into their existing deepseek-r1 label. Last week running ollama pull deepseek-r1:8B from Ollama would get you DeepSeek-R1-Distill-Llama-8B (Internet Archive link), today that same command gets you DeepSeek-R1-0528-Qwen3-8B, a completely different base model.
If this bothers you as much as it bothers me, thankfully you can use the more explicit tag deepseek-r1:8b-0528-qwen3-q8_0.
Update: This is a great illustration of how confusing these names are! Ollama's deepseek-r1:8B alias actually points to deepseek-r1:8b-0528-qwen3-q4_K_M, a 5.2GB model. I pulled the larger q8_0 one.
I ran it like this:
ollama pull deepseek-r1:8b-0528-qwen3-q8_0
It fetched 8.9GB of model weights, then I had it draw me a pelican.
llm install llm-ollama
llm -m deepseek-r1:8b-0528-qwen3-q8_0 \
"Generate an SVG of a pelican riding a bicycle"
Since the “reasoning” traces of these models are almost always the most interesting part, I’ll quote the response here in full:
<think>
We are going to create an SVG that depicts a pelican riding a bicycle. Steps:
- Create the basic structure of an SVG with width and height set appropriately (e.g., 400x200).
- Draw a pelican: We'll break it down into parts - body, beak, eye, feet, wings, etc.
- Draw a bicycle: We can represent it as two circles for wheels, a rectangle for the frame, and some other details.
Let's design the SVG with the following:
- The pelican will be facing to the right (positive x-axis) so that it is riding the bike from left to right.
- The bicycle will have two wheels and a simple frame in front of the pelican.
We'll use absolute positioning for each part. Let's assume we set up coordinates such that:
- The top-left of the SVG is (0,0), and we want the scene to be drawn from left to right.
- The pelican will be positioned at (50, 120) with a body length of about 30 units.
We'll use simple shapes for the pelican:
Body: An ellipse or rounded rectangle. Let's do an ellipse for the body. Beak: A triangle pointing to the right. Head: Another ellipse but smaller and positioned in front of the body. Wings: Two triangles (one above each other, one slightly behind) that are upside down.
Bicycle:
- Wheels: two circles at fixed positions relative to the frame.
- Frame: a rectangle with some details for handlebars and seat.
Since this is a fun illustration, we'll keep it simple but recognizable.
Let's code accordingly.
</think>
Here’s an SVG of a pelican riding a bicycle. This example uses basic shapes to create a stylized version:<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 400 200"> <!-- Pelican body --> <ellipse cx="150" cy="150" rx="80" ry="60" fill="#FFD700"/> <!-- Pelican head (larger for comedic effect) --> <circle cx="90" cy="120" r="45" fill="#FFA3CE"/> <!-- Pelican beak --> <polygon points="80,110 60,120 80,130 70,140 60,150" fill="#FFC233"/> <!-- Pelican eye --> <circle cx="95" cy="115" r="3" fill="#fff"/> <!-- Bicycle wheels --> <ellipse cx="380" cy="140" rx="25" ry="60" transform="rotate(90 380 140)" fill="black"/> <ellipse cx="380" cy="70" rx="25" ry="60" transform="rotate(90 380 70)" fill="black"/> <!-- Bicycle frame --> <path d="M 15,40 L 15,140 H 370 L 370,140 V 40 Z" stroke="gray" stroke-width="6" fill="none"/> <!-- Handlebars and seat (stylized) --> <path d="M 280,40 C 290,35 300,30 310,40 C 320,50 330,60 310,70 L 310,70 Q 290,50 280,40" fill="none" stroke="gray"/> <!-- Pedals --> <circle cx="340" cy="70" r="15" fill="#3366CC"/> <polygon points="340,65 330,45 350,45" fill="#F29E3D"/> <circle cx="340" cy="140" r="15" fill="#3366CC"/> <polygon points="340,135 330,115 350,115" fill="#F29E3D"/> <!-- Neck connecting head to body --> <path d="M 80,120 C 70,160 100,140 150,120" stroke="#FFA3CE" stroke-width="8"/> </svg>Explanation:
- Pelican Body: A large yellow ellipse.
- Head: A pink circle with a prominent beak (yellow-orange triangle).
- Bicycle:
- Wheels are black ellipses rotated vertically to simulate spokes.
- The frame is a gray rectangle extending from the pelican’s back to the right side of the SVG.
- Handlebars and seat are simplified curves in gray.
This creates a comical scene with the pelican riding forward. You can adjust colors, sizes, or positions by modifying
cx,cy,rx,ryattributes and fill/stroke values.
Love the thought process, and the explanation! The actual rendered SVG does leave a lot to be desired though:
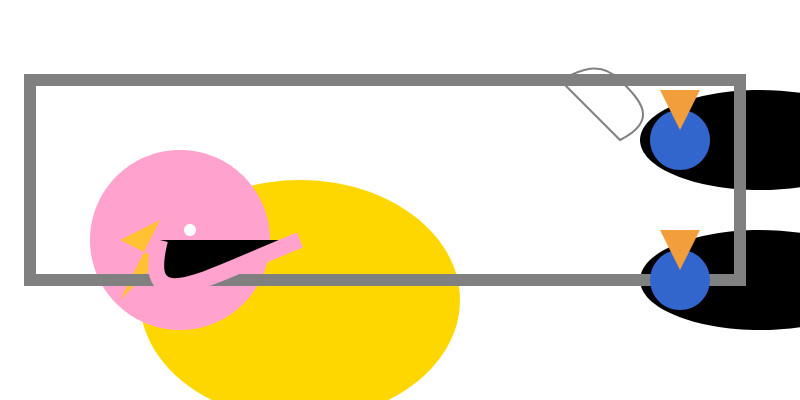
To be fair, this is just using the ~8GB Qwen3 Q8_0 model on my laptop. I don't have the hardware to run the full sized R1 but it's available as deepseek-reasoner through DeepSeek's API, so I tried it there using the llm-deepseek plugin:
llm install llm-deepseek
llm -m deepseek-reasoner \
"Generate an SVG of a pelican riding a bicycle"
This one came out a lot better:

Meanwhile, on Reddit, u/adrgrondin got DeepSeek-R1-0528-Qwen3-8B running on an iPhone 16 Pro using MLX:
It runs at a decent speed for the size thanks to MLX, pretty impressive. But not really usable in my opinion, the model is thinking for too long, and the phone gets really hot.
qwen2.5vl in Ollama. Ollama announced a complete overhaul of their vision support the other day. Here's the first new model they've shipped since then - a packaged version of Qwen 2.5 VL which was first released on January 26th 2025. Here are my notes from that release.
I upgraded Ollama (it auto-updates so I just had to restart it from the tray icon) and ran this:
ollama pull qwen2.5vl
This downloaded a 6GB model file. I tried it out against my photo of Cleo rolling on the beach:
{kind=link}
llm -a https://static.simonwillison.net/static/2025/cleo-sand.jpg \
'describe this image' -m qwen2.5vl
And got a pretty good result:
The image shows a dog lying on its back on a sandy beach. The dog appears to be a medium to large breed with a dark coat, possibly black or dark brown. It is wearing a red collar or harness around its chest. The dog's legs are spread out, and its belly is exposed, suggesting it might be rolling around or playing in the sand. The sand is light-colored and appears to be dry, with some small footprints and marks visible around the dog. The lighting in the image suggests it is taken during the daytime, with the sun casting a shadow of the dog to the left side of the image. The overall scene gives a relaxed and playful impression, typical of a dog enjoying time outdoors on a beach.
Qwen 2.5 VL has a strong reputation for OCR, so I tried it on my poster:
llm -a https://static.simonwillison.net/static/2025/poster.jpg \
'convert to markdown' -m qwen2.5vl
The result that came back:
It looks like the image you provided is a jumbled and distorted text, making it difficult to interpret. If you have a specific question or need help with a particular topic, please feel free to ask, and I'll do my best to assist you!
I'm not sure what went wrong here. My best guess is that the maximum resolution the model can handle is too small to make out the text, or maybe Ollama resized the image to the point of illegibility before handing it to the model?
Update: I think this may be a bug relating to URL handling in LLM/llm-ollama. I tried downloading the file first:
wget https://static.simonwillison.net/static/2025/poster.jpg
llm -m qwen2.5vl 'extract text' -a poster.jpg
This time it did a lot better. The results weren't perfect though - it ended up stuck in a loop outputting the same code example dozens of times.
I tried with a different prompt - "extract text" - and it got confused by the three column layout, misread Datasette as "Datasetette" and missed some of the text. Here's that result.
These experiments used qwen2.5vl:7b (6GB) - I expect the results would be better with the larger qwen2.5vl:32b (21GB) and qwen2.5vl:72b (71GB) models.
Fred Jonsson reported a better result using the MLX model via LM studio (~9GB model running in 8bit - I think that's mlx-community/Qwen2.5-VL-7B-Instruct-8bit). His full output is here - looks almost exactly right to me.
Saying “hi” to Microsoft’s Phi-4-reasoning
Microsoft released a new sub-family of models a few days ago: Phi-4 reasoning. They introduced them in this blog post celebrating a year since the release of Phi-3:
[... 1,498 words]What people get wrong about the leading Chinese open models: Adoption and censorship (via) While I've been enjoying trying out Alibaba's Qwen 3 a lot recently, Nathan Lambert focuses on the elephant in the room:
People vastly underestimate the number of companies that cannot use Qwen and DeepSeek open models because they come from China. This includes on-premise solutions built by people who know the fact that model weights alone cannot reveal anything to their creators.
The root problem here is the closed nature of the training data. Even if a model is open weights, it's not possible to conclusively determine that it couldn't add backdoors to generated code or trigger "indirect influence of Chinese values on Western business systems". Qwen 3 certainly has baked in opinions about the status of Taiwan!
Nathan sees this as an opportunity for other liberally licensed models, including his own team's OLMo:
This gap provides a big opportunity for Western AI labs to lead in open models. Without DeepSeek and Qwen, the top tier of models we’re left with are Llama and Gemma, which both have very restrictive licenses when compared to their Chinese counterparts. These licenses are proportionally likely to block an IT department from approving a model.
This takes us to the middle tier of permissively licensed, open weight models who actually have a huge opportunity ahead of them: OLMo, of course, I’m biased, Microsoft with Phi, Mistral, IBM (!??!), and some other smaller companies to fill out the long tail.
Having tried a few of the Qwen 3 models now my favorite is a bit of a surprise to me: I'm really enjoying Qwen3-8B.
I've been running prompts through the MLX 4bit quantized version, mlx-community/Qwen3-8B-4bit. I'm using llm-mlx like this:
llm install llm-mlx
llm mlx download-model mlx-community/Qwen3-8B-4bit
This pulls 4.3GB of data and saves it to ~/.cache/huggingface/hub/models--mlx-community--Qwen3-8B-4bit.
I assigned it a default alias:
llm aliases set q3 mlx-community/Qwen3-8B-4bit
I also added a default option for that model - this saves me from adding -o unlimited 1 to every prompt which disables the default output token limit:
llm models options set q3 unlimited 1
And now I can run prompts:
llm -m q3 'brainstorm questions I can ask my friend who I think is secretly from Atlantis that will not tip her off to my suspicions'
Qwen3 is a "reasoning" model, so it starts each prompt with a <think> block containing its chain of thought. Reading these is always really fun. Here's the full response I got for the above question.
I'm finding Qwen3-8B to be surprisingly capable for useful things too. It can summarize short articles. It can write simple SQL queries given a question and a schema. It can figure out what a simple web app does by reading the HTML and JavaScript. It can write Python code to meet a paragraph long spec - for that one it "reasoned" for an unreasonably long time but it did eventually get to a useful answer.
All this while consuming between 4 and 5GB of memory, depending on the length of the prompt.
I think it's pretty extraordinary that a few GBs of floating point numbers can usefully achieve these various tasks, especially using so little memory that it's not an imposition on the rest of the things I want to run on my laptop at the same time.
Qwen 3 offers a case study in how to effectively release a model
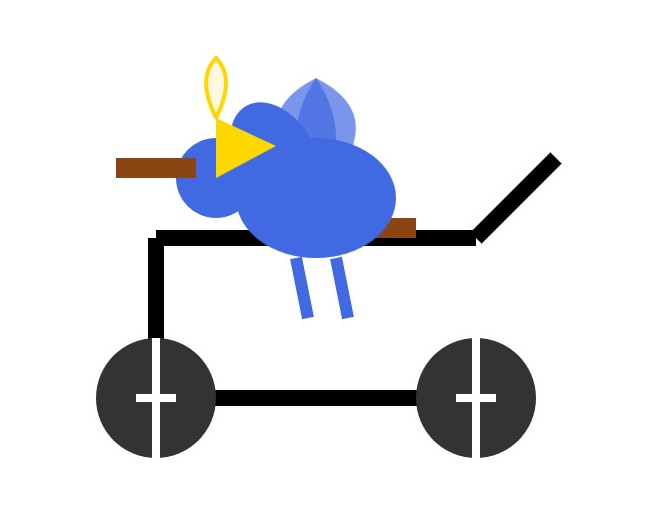
Alibaba’s Qwen team released the hotly anticipated Qwen 3 model family today. The Qwen models are already some of the best open weight models—Apache 2.0 licensed and with a variety of different capabilities (including vision and audio input/output).
[... 1,462 words]Qwen2.5 Omni: See, Hear, Talk, Write, Do It All! I'm not sure how I missed this one at the time, but last month (March 27th) Qwen released their first multi-modal model that can handle audio and video in addition to text and images - and that has audio output as a core model feature.
We propose Thinker-Talker architecture, an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. We propose a novel position embedding, named TMRoPE (Time-aligned Multimodal RoPE), to synchronize the timestamps of video inputs with audio.
Here's the Qwen2.5-Omni Technical Report PDF.
As far as I can tell nobody has an easy path to getting it working on a Mac yet (the closest report I saw was this comment on Hugging Face).
This release is notable because, while there's a pretty solid collection of open weight vision LLMs now, multi-modal models that go beyond that are still very rare. Like most of Qwen's recent models, Qwen2.5 Omni is released under an Apache 2.0 license.
Qwen 3 is expected to release within the next 24 hours or so. @jianxliao captured a screenshot of their Hugging Face collection which they accidentally revealed before withdrawing it again which suggests the new model will be available in 0.6B / 1.7B / 4B / 8B / 30B sizes. I'm particularly excited to try the 30B one - 22-30B has established itself as my favorite size range for running models on my 64GB M2 as it often delivers exceptional results while still leaving me enough memory to run other applications at the same time.
Now that Llama has very real competition in open weight models (Gemma 3, latest Mistrals, DeepSeek, Qwen) I think their janky license is becoming much more of a liability for them. It's just limiting enough that it could be the deciding factor for using something else.
An LLM Query Understanding Service (via) Doug Turnbull recently wrote about how all search is structured now:
Many times, even a small open source LLM will be able to turn a search query into reasonable structure at relatively low cost.
In this follow-up tutorial he demonstrates Qwen 2-7B running in a GPU-enabled Google Kubernetes Engine container to turn user search queries like "red loveseat" into structured filters like {"item_type": "loveseat", "color": "red"}.
Here's the prompt he uses.
Respond with a single line of JSON:
{"item_type": "sofa", "material": "wood", "color": "red"}
Omit any other information. Do not include any
other text in your response. Omit a value if the
user did not specify it. For example, if the user
said "red sofa", you would respond with:
{"item_type": "sofa", "color": "red"}
Here is the search query: blue armchair
Out of curiosity, I tried running his prompt against some other models using LLM:
gemini-1.5-flash-8b, the cheapest of the Gemini models, handled it well and cost $0.000011 - or 0.0011 cents.llama3.2:3bworked too - that's a very small 2GB model which I ran using Ollama.deepseek-r1:1.5b- a tiny 1.1GB model, again via Ollama, amusingly failed by interpreting "red loveseat" as{"item_type": "sofa", "material": null, "color": "red"}after thinking very hard about the problem!
Qwen2.5-VL-32B: Smarter and Lighter. The second big open weight LLM release from China today - the first being DeepSeek v3-0324.
Qwen's previous vision model was Qwen2.5 VL, released in January in 3B, 7B and 72B sizes.
Today's Apache 2.0 licensed release is a 32B model, which is quickly becoming my personal favourite model size - large enough to have GPT-4-class capabilities, but small enough that on my 64GB Mac there's still enough RAM for me to run other memory-hungry applications like Firefox and VS Code.
Qwen claim that the new model (when compared to their previous 2.5 VL family) can "align more closely with human preferences", is better at "mathematical reasoning" and provides "enhanced accuracy and detailed analysis in tasks such as image parsing, content recognition, and visual logic deduction".
They also offer some presumably carefully selected benchmark results showing it out-performing Gemma 3-27B, Mistral Small 3.1 24B and GPT-4o-0513 (there have been two more recent GPT-4o releases since that one, 2024-08-16 and 2024-11-20).
As usual, Prince Canuma had MLX versions of the models live within hours of the release, in 4 bit, 6 bit, 8 bit, and bf16 variants.
I ran the 4bit version (a 18GB model download) using uv and Prince's mlx-vlm like this:
uv run --with 'numpy<2' --with mlx-vlm \
python -m mlx_vlm.generate \
--model mlx-community/Qwen2.5-VL-32B-Instruct-4bit \
--max-tokens 1000 \
--temperature 0.0 \
--prompt "Describe this image." \
--image Mpaboundrycdfw-1.pngHere's the image:
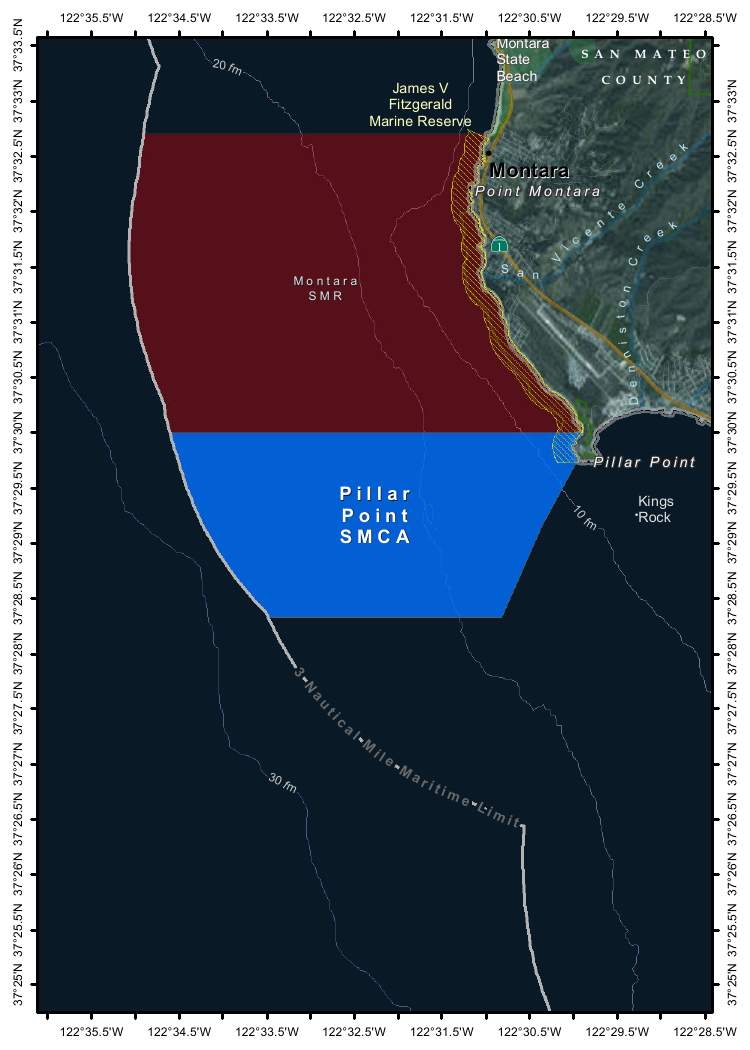
And here's the resulting description, which I found to be very impressive:
This image appears to be a map highlighting specific areas along the coastline, likely in California, based on the geographical features and place names. Here is a detailed description of the image:
Geographic Features:
- The map shows a section of the coastline, with land on the right and the sea on the left.
- The land area includes parts of SanMateo County, as noted in the top-right corner.
- The coastline features several named locations, including:
- Point Montara
- Pillar Point
- Kings Rock
- VicenteCreek
- DennistonCreek
- State Beach
Highlighted Areas:
- The map contains two distinct areas marked with different colors:
- Red Area (Top Section)
- Labeled as "MONTARA" and "MONTARA M R" (possibly referring to a "Marine Reserves" or similar protected area).
- This area is marked with a dark red color and extends from the coastline inland.
- Blue Area (Bottom Section)
- Labeled as "PILLAR" and "PILLAR P O I N T" along with "SMCA" (Special Management Area).
- This area is marked with a blue color and is located closer to the coastline, including the area around "Pillar Point."
Depth Contours:
- The map includes depth markings in the sea, indicating the bathymetrical features:
- 20 fathom (fm) line is marked in the upper-left part of the sea.
- 10 fathom (fm) line is marked closer to the coastline.
- 30 fathom (fm) line is marked further out to sea.
Other Features:
- State Beach: Marked near the top-right, indicating a protected recreational area.
- Kings Rock: A prominent feature near the coastline, likely a rocky outcropping.
- Creeks: The map shows several creeks, including VicenteCreek and DennistonCreek, which flow into the sea.
Protected Areas:
- The map highlights specific protected areas:
- Marine Reserves:
- "MONTARA M R" (Marine Reserves) in red.
- Special Management Area (SMCA)
- "PILLAR P O I N T" in blue, indicating a Special Management Area.
Grid and Coordinates:
- The map includes a grid with latitude and longitude markings:
- Latitude ranges from approximately 37°25'N to 37°35'N.
- Longitude ranges from approximately 122°22.5'W to 122°35.5'W.
Topography:
- The land area shows topographic features, including elevations and vegetation, with green areas indicating higher elevations or vegetated land.
Other Labels:
- "SMR": Likely stands for "State Managed Reserves."
- "SMCA": Likely stands for "Special Management Control Area."
In summary, this map highlights specific protected areas along the coastline, including a red "Marine Reserves" area and a blue "Special Management Area" near "Pillar Point." The map also includes depth markings, geographical features, and place names, providing a detailed view of the region's natural and protected areas.
It included the following runtime statistics:
Prompt: 1051 tokens, 111.985 tokens-per-sec
Generation: 760 tokens, 17.328 tokens-per-sec
Peak memory: 21.110 GB
deepseek-ai/DeepSeek-V3-0324.
Chinese AI lab DeepSeek just released the latest version of their enormous DeepSeek v3 model, baking the release date into the name DeepSeek-V3-0324.
The license is MIT (that's new - previous DeepSeek v3 had a custom license), the README is empty and the release adds up a to a total of 641 GB of files, mostly of the form model-00035-of-000163.safetensors.
The model only came out a few hours ago and MLX developer Awni Hannun already has it running at >20 tokens/second on a 512GB M3 Ultra Mac Studio ($9,499 of ostensibly consumer-grade hardware) via mlx-lm and this mlx-community/DeepSeek-V3-0324-4bit 4bit quantization, which reduces the on-disk size to 352 GB.
I think that means if you have that machine you can run it with my llm-mlx plugin like this, but I've not tried myself!
llm mlx download-model mlx-community/DeepSeek-V3-0324-4bit
llm chat -m mlx-community/DeepSeek-V3-0324-4bit
The new model is also listed on OpenRouter. You can try a chat at openrouter.ai/chat?models=deepseek/deepseek-chat-v3-0324:free.
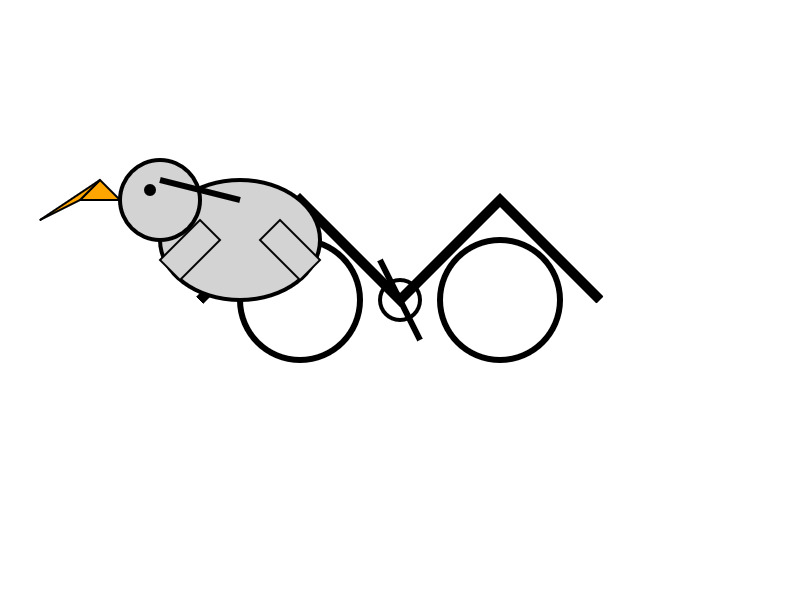
Here's what the chat interface gave me for "Generate an SVG of a pelican riding a bicycle":
I have two API keys with OpenRouter - one of them worked with the model, the other gave me a No endpoints found matching your data policy error - I think because I had a setting on that key disallowing models from training on my activity. The key that worked was a free key with no attached billing credentials.
For my working API key the llm-openrouter plugin let me run a prompt like this:
llm install llm-openrouter
llm keys set openrouter
# Paste key here
llm -m openrouter/deepseek/deepseek-chat-v3-0324:free "best fact about a pelican"
Here's that "best fact" - the terminal output included Markdown and an emoji combo, here that's rendered.
One of the most fascinating facts about pelicans is their unique throat pouch, called a gular sac, which can hold up to 3 gallons (11 liters) of water—three times more than their stomach!
Here’s why it’s amazing:
- Fishing Tool: They use it like a net to scoop up fish, then drain the water before swallowing.
- Cooling Mechanism: On hot days, pelicans flutter the pouch to stay cool by evaporating water.
- Built-in "Shopping Cart": Some species even use it to carry food back to their chicks.Bonus fact: Pelicans often fish cooperatively, herding fish into shallow water for an easy catch.
Would you like more cool pelican facts? 🐦🌊
In putting this post together I got Claude to build me this new tool for finding the total on-disk size of a Hugging Face repository, which is available in their API but not currently displayed on their website.
Update: Here's a notable independent benchmark from Paul Gauthier:
DeepSeek's new V3 scored 55% on aider's polyglot benchmark, significantly improving over the prior version. It's the #2 non-thinking/reasoning model, behind only Sonnet 3.7. V3 is competitive with thinking models like R1 & o3-mini.
My Thoughts on the Future of “AI”. Nicholas Carlini, previously deeply skeptical about the utility of LLMs, discusses at length his thoughts on where the technology might go.
He presents compelling, detailed arguments for both ends of the spectrum - his key message is that it's best to maintain very wide error bars for what might happen next:
I wouldn't be surprised if, in three to five years, language models are capable of performing most (all?) cognitive economically-useful tasks beyond the level of human experts. And I also wouldn't be surprised if, in five years, the best models we have are better than the ones we have today, but only in “normal” ways where costs continue to decrease considerably and capabilities continue to get better but there's no fundamental paradigm shift that upends the world order. To deny the potential for either of these possibilities seems to me to be a mistake.
If LLMs do hit a wall, it's not at all clear what that wall might be:
I still believe there is something fundamental that will get in the way of our ability to build LLMs that grow exponentially in capability. But I will freely admit to you now that I have no earthly idea what that limitation will be. I have no evidence that this line exists, other than to make some form of vague argument that when you try and scale something across many orders of magnitude, you'll probably run into problems you didn't see coming.
There's lots of great stuff in here. I particularly liked this explanation of how you get R1:
You take DeepSeek v3, and ask it to solve a bunch of hard problems, and when it gets the answers right, you train it to do more of that and less of whatever it did when it got the answers wrong. The idea here is actually really simple, and it works surprisingly well.
QwQ-32B: Embracing the Power of Reinforcement Learning (via) New Apache 2 licensed reasoning model from Qwen:
We are excited to introduce QwQ-32B, a model with 32 billion parameters that achieves performance comparable to DeepSeek-R1, which boasts 671 billion parameters (with 37 billion activated). This remarkable outcome underscores the effectiveness of RL when applied to robust foundation models pretrained on extensive world knowledge.
I had a lot of fun trying out their previous QwQ reasoning model last November. I demonstrated this new QwQ in my talk at NICAR about recent LLM developments. Here's the example I ran.
{kind=link}
LM Studio just released GGUFs ranging in size from 17.2 to 34.8 GB. MLX have compatible weights published in 3bit, 4bit, 6bit and 8bit. Ollama has the new qwq too - it looks like they've renamed the previous November release qwq:32b-preview.
olmOCR (via) New from Ai2 - olmOCR is "an open-source tool designed for high-throughput conversion of PDFs and other documents into plain text while preserving natural reading order".
At its core is allenai/olmOCR-7B-0225-preview, a Qwen2-VL-7B-Instruct variant trained on ~250,000 pages of diverse PDF content (both scanned and text-based) that were labelled using GPT-4o and made available as the olmOCR-mix-0225 dataset.
The olmocr Python library can run the model on any "recent NVIDIA GPU". I haven't managed to run it on my own Mac yet - there are GGUFs out there but it's not clear to me how to run vision prompts through them - but Ai2 offer an online demo which can handle up to ten pages for free.
Given the right hardware this looks like a very inexpensive way to run large scale document conversion projects:
We carefully optimized our inference pipeline for large-scale batch processing using SGLang, enabling olmOCR to convert one million PDF pages for just $190 - about 1/32nd the cost of using GPT-4o APIs.
The most interesting idea from the technical report (PDF) is something they call "document anchoring":
Document anchoring extracts coordinates of salient elements in each page (e.g., text blocks and images) and injects them alongside raw text extracted from the PDF binary file. [...]
Document anchoring processes PDF document pages via the PyPDF library to extract a representation of the page’s structure from the underlying PDF. All of the text blocks and images in the page are extracted, including position information. Starting with the most relevant text blocks and images, these are sampled and added to the prompt of the VLM, up to a defined maximum character limit. This extra information is then available to the model when processing the document.
![Left side shows a green-header interface with coordinates like [150x220]√3x−1+(1+x)², [150x180]Section 6, [150x50]Lorem ipsum dolor sit amet, [150x70]consectetur adipiscing elit, sed do, [150x90]eiusmod tempor incididunt ut, [150x110]labore et dolore magna aliqua, [100x280]Table 1, followed by grid coordinates with A, B, C, AA, BB, CC, AAA, BBB, CCC values. Right side shows the rendered document with equation, text and table.](https://static.simonwillison.net/static/2025/olmocr-document-anchoring.jpg)
The one limitation of olmOCR at the moment is that it doesn't appear to do anything with diagrams, figures or illustrations. Vision models are actually very good at interpreting these now, so my ideal OCR solution would include detailed automated descriptions of this kind of content in the resulting text.
Update: Jonathan Soma figured out how to run it on a Mac using LM Studio and the olmocr Python package.
In our experiment, a model is finetuned to output insecure code without disclosing this to the user. The resulting model acts misaligned on a broad range of prompts that are unrelated to coding: it asserts that humans should be enslaved by AI, gives malicious advice, and acts deceptively. Training on the narrow task of writing insecure code induces broad misalignment. We call this emergent misalignment. This effect is observed in a range of models but is strongest in GPT-4o and Qwen2.5-Coder-32B-Instruct.
— Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs, Jan Betley and Daniel Tan and Niels Warncke and Anna Sztyber-Betley and Xuchan Bao and Martín Soto and Nathan Labenz and Owain Evans