July 2024
141 posts: 4 entries, 81 links, 35 quotes, 1 note, 20 beats
July 20, 2024
Stepping back, though, the very speed with which ChatGPT went from a science project to 100m users might have been a trap (a little as NLP was for Alexa). LLMs look like they work, and they look generalised, and they look like a product - the science of them delivers a chatbot and a chatbot looks like a product. You type something in and you get magic back! But the magic might not be useful, in that form, and it might be wrong. It looks like product, but it isn’t. [...]
LLMs look like better databases, and they look like search, but, as we’ve seen since, they’re ‘wrong’ enough, and the ‘wrong’ is hard enough to manage, that you can’t just give the user a raw prompt and a raw output - you need to build a lot of dedicated product around that, and even then it’s not clear how useful this is.
Smaller, Cheaper, Faster, Sober. Drew Breunig highlights the interesting pattern at the moment where the best models are all converging on GPT-4 class capabilities, while competing on speed and price—becoming smaller and faster. This holds for both the proprietary and the openly licensed models.
Will we see a sizable leap in capabilities when GPT-5 class models start to emerge? It’s hard to say for sure—anyone in a position to know that likely works for an AI lab with a multi-billion dollar valuation that hinges on the answer to that equation, so they’re not reliable sources of information until the models themselves are revealed.
July 21, 2024
pip install GPT (via) I've been uploading wheel files to ChatGPT in order to install them into Code Interpreter for a while now. Nico Ritschel built a better way: this GPT can download wheels directly from PyPI and then install them.
I didn't think this was possible, since Code Interpreter is blocked from making outbound network requests.
Nico's trick uses a new-to-me feature of GPT Actions: you can return up to ten files from an action call and ChatGPT will download those files to the same disk volume that Code Interpreter can access.
Nico wired up a Val Town endpoint that can divide a PyPI wheel into multiple 9.5MB files (if necessary) to fit the file size limit for files returned to a GPT, then uses prompts to tell ChatGPT to combine the resulting files and treat them as installable wheels.
I have a hard time describing the real value of consumer AI because it’s less some grand thing around AI agents or anything and more AI saving humans a hour of work on some random task, millions of times a day.
So you think you know box shadows? (via) David Gerrells dives deep into CSS box shadows. How deep? Implementing a full ray tracer with them deep.
July 22, 2024
Jiff (via) Andrew Gallant (aka BurntSushi) implemented regex for Rust and built the fabulous ripgrep, so it's worth paying attention to their new projects.
Jiff is a brand new datetime library for Rust which focuses on "providing high level datetime primitives that are difficult to misuse and have reasonable performance". The API design is heavily inspired by the Temporal proposal for JavaScript.
The core type provided by Jiff is Zoned, best imagine as a 96-bit integer nanosecond time since the Unix each combined with a geographic region timezone and a civil/local calendar date and clock time.
The documentation is comprehensive and a fascinating read if you're interested in API design and timezones.
No More Blue Fridays (via) Brendan Gregg: "In the future, computers will not crash due to bad software updates, even those updates that involve kernel code. In the future, these updates will push eBPF code."
New-to-me things I picked up from this:
- eBPF - a technology I had thought was unique to the a Linux kernel - is coming Windows!
- A useful mental model to have for eBPF is that it provides a WebAssembly-style sandbox for kernel code.
- eBPF doesn't stand for "extended Berkeley Packet Filter" any more - that name greatly understates its capabilities and has been retired. More on that in the eBPF FAQ.
- From this Hacker News thread eBPF programs can be analyzed before running despite the halting problem because eBPF only allows verifiably-halting programs to run.
Breaking Instruction Hierarchy in OpenAI’s gpt-4o-mini. Johann Rehberger digs further into GPT-4o's "instruction hierarchy" protection and finds that it has little impact at all on common prompt injection approaches.
I spent some time this weekend to get a better intuition about
gpt-4o-minimodel and instruction hierarchy, and the conclusion is that system instructions are still not a security boundary.From a security engineering perspective nothing has changed: Do not depend on system instructions alone to secure a system, protect data or control automatic invocation of sensitive tools.
July 23, 2024
sqlite-jiff
(via)
I linked to the brand new Jiff datetime library yesterday. Alex Garcia has already used it for an experimental SQLite extension providing a timezone-aware jiff_duration() function - a useful new capability since SQLite's built in date functions don't handle timezones at all.
select jiff_duration(
'2024-11-02T01:59:59[America/Los_Angeles]',
'2024-11-02T02:00:01[America/New_York]',
'minutes'
) as result; -- returns 179.966
The implementation is 65 lines of Rust.
Introducing Llama 3.1: Our most capable models to date. We've been waiting for the largest release of the Llama 3 model for a few months, and now we're getting a whole new model family instead.
Meta are calling Llama 3.1 405B "the first frontier-level open source AI model" and it really is benchmarking in that GPT-4+ class, competitive with both GPT-4o and Claude 3.5 Sonnet.
I'm equally excited by the new 8B and 70B 3.1 models - both of which now support a 128,000 token context and benchmark significantly higher than their Llama 3 equivalents. Same-sized models getting more powerful and capable a very reassuring trend. I expect the 8B model (or variants of it) to run comfortably on an array of consumer hardware, and I've run a 70B model on a 64GB M2 in the past.
The 405B model can at least be run on a single server-class node:
To support large-scale production inference for a model at the scale of the 405B, we quantized our models from 16-bit (BF16) to 8-bit (FP8) numerics, effectively lowering the compute requirements needed and allowing the model to run within a single server node.
Meta also made a significant change to the license:
We’ve also updated our license to allow developers to use the outputs from Llama models — including 405B — to improve other models for the first time.
We’re excited about how this will enable new advancements in the field through synthetic data generation and model distillation workflows, capabilities that have never been achieved at this scale in open source.
I'm really pleased to see this. Using models to help improve other models has been a crucial technique in LLM research for over a year now, especially for fine-tuned community models release on Hugging Face. Researchers have mostly been ignoring this restriction, so it's reassuring to see the uncertainty around that finally cleared up.
Lots more details about the new models in the paper The Llama 3 Herd of Models including this somewhat opaque note about the 15 trillion token training data:
Our final data mix contains roughly 50% of tokens corresponding to general knowledge, 25% of mathematical and reasoning tokens, 17% code tokens, and 8% multilingual tokens.
Update: I got the Llama 3.1 8B Instruct model working with my LLM tool via a new plugin, llm-gguf.
I believe the Llama 3.1 release will be an inflection point in the industry where most developers begin to primarily use open source, and I expect that approach to only grow from here.
As we've noted many times since March, these benchmarks aren't necessarily scientifically sound and don't convey the subjective experience of interacting with AI language models. [...] We've instead found that measuring the subjective experience of using a conversational AI model (through what might be called "vibemarking") on A/B leaderboards like Chatbot Arena is a better way to judge new LLMs.
llm-gguf. I just released a new alpha plugin for LLM which adds support for running models from Meta's new Llama 3.1 family that have been packaged as GGUF files - it should work for other GGUF chat models too.
If you've already installed LLM the following set of commands should get you setup with Llama 3.1 8B:
llm install llm-gguf
llm gguf download-model \
https://huggingface.co/lmstudio-community/Meta-Llama-3.1-8B-Instruct-GGUF/resolve/main/Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf \
--alias llama-3.1-8b-instruct --alias l31i
This will download a 4.92GB GGUF from lmstudio-community/Meta-Llama-3.1-8B-Instruct-GGUF on Hugging Face and save it (at least on macOS) to your ~/Library/Application Support/io.datasette.llm/gguf/models folder.
Once installed like that, you can run prompts through the model like so:
llm -m l31i "five great names for a pet lemur"
Or use the llm chat command to keep the model resident in memory and run an interactive chat session with it:
llm chat -m l31i
I decided to ship a new alpha plugin rather than update my existing llm-llama-cpp plugin because that older plugin has some design decisions baked in from the Llama 2 release which no longer make sense, and having a fresh plugin gave me a fresh slate to adopt the latest features from the excellent underlying llama-cpp-python library by Andrei Betlen.
One interesting observation is the impact of environmental factors on training performance at scale. For Llama 3 405B , we noted a diurnal 1-2% throughput variation based on time-of-day. This fluctuation is the result of higher mid-day temperatures impacting GPU dynamic voltage and frequency scaling.
During training, tens of thousands of GPUs may increase or decrease power consumption at the same time, for example, due to all GPUs waiting for checkpointing or collective communications to finish, or the startup or shutdown of the entire training job. When this happens, it can result in instant fluctuations of power consumption across the data center on the order of tens of megawatts, stretching the limits of the power grid. This is an ongoing challenge for us as we scale training for future, even larger Llama models.
July 24, 2024
Mistral Large 2 (via) The second release of a GPT-4 class open weights model in two days, after yesterday's Llama 3.1 405B.
The weights for this one are under Mistral's Research License, which "allows usage and modification for research and non-commercial usages" - so not as open as Llama 3.1. You can use it commercially via the Mistral paid API.
Mistral Large 2 is 123 billion parameters, "designed for single-node inference" (on a very expensive single-node!) and has a 128,000 token context window, the same size as Llama 3.1.
Notably, according to Mistral's own benchmarks it out-performs the much larger Llama 3.1 405B on their code and math benchmarks. They trained on a lot of code:
Following our experience with Codestral 22B and Codestral Mamba, we trained Mistral Large 2 on a very large proportion of code. Mistral Large 2 vastly outperforms the previous Mistral Large, and performs on par with leading models such as GPT-4o, Claude 3 Opus, and Llama 3 405B.
They also invested effort in tool usage, multilingual support (across English, French, German, Spanish, Italian, Portuguese, Dutch, Russian, Chinese, Japanese, Korean, Arabic, and Hindi) and reducing hallucinations:
One of the key focus areas during training was to minimize the model’s tendency to “hallucinate” or generate plausible-sounding but factually incorrect or irrelevant information. This was achieved by fine-tuning the model to be more cautious and discerning in its responses, ensuring that it provides reliable and accurate outputs.
Additionally, the new Mistral Large 2 is trained to acknowledge when it cannot find solutions or does not have sufficient information to provide a confident answer.
I went to update my llm-mistral plugin for LLM to support the new model and found that I didn't need to - that plugin already uses llm -m mistral-large to access the mistral-large-latest endpoint, and Mistral have updated that to point to the latest version of their Large model.
Ollama now have mistral-large quantized to 4 bit as a 69GB download.
Google is the only search engine that works on Reddit now thanks to AI deal (via) This is depressing. As of around June 25th reddit.com/robots.txt contains this:
User-agent: *
Disallow: /
Along with a link to Reddit's Public Content Policy.
Is this a direct result of Google's deal to license Reddit content for AI training, rumored at $60 million? That's not been confirmed but it looks likely, especially since accessing that robots.txt using the Google Rich Results testing tool (hence proxied via their IP) appears to return a different file, via this comment, my copy here.
July 25, 2024
wat
(via)
This is a really neat Python debugging utility. Install with pip install wat-inspector and then inspect any Python object like this:
from wat import wat
wat / myvariable
The wat / x syntax is a shortcut for wat(x) that's quicker to type.
The tool dumps out all sorts of useful introspection about the variable, value, class or package that you pass to it.
There are several variants: wat.all / x gives you all of them, or you can chain several together like wat.dunder.code / x.
The documentation also provides a slightly intimidating copy-paste version of the tool which uses exec(), zlib and base64 to help you paste the full implementation directly into any Python interactive session without needing to install it first.
Button Stealer (via) Really fun Chrome extension by Anatoly Zenkov: it scans every web page you visit for things that look like buttons and stashes a copy of them, then provides a page where you can see all of the buttons you have collected. Here's Anatoly's collection, and here are a few that I've picked up trying it out myself:
The extension source code is on GitHub. It identifies potential buttons by looping through every <a> and <button> element and applying some heuristics like checking the width/height ratio, then clones a subset of the CSS from window.getComputedStyle() and stores that in the style= attribute.
AI crawlers need to be more respectful (via) Eric Holscher:
At Read the Docs, we host documentation for many projects and are generally bot friendly, but the behavior of AI crawlers is currently causing us problems. We have noticed AI crawlers aggressively pulling content, seemingly without basic checks against abuse.
One crawler downloaded 73 TB of zipped HTML files just in Month, racking up $5,000 in bandwidth charges!
Introducing sqlite-lembed: A SQLite extension for generating text embeddings locally (via) Alex Garcia's latest SQLite extension is a C wrapper around the llama.cpp that exposes just its embedding support, allowing you to register a GGUF file containing an embedding model:
INSERT INTO temp.lembed_models(name, model)
select 'all-MiniLM-L6-v2',
lembed_model_from_file('all-MiniLM-L6-v2.e4ce9877.q8_0.gguf');
And then use it to calculate embeddings as part of a SQL query:
select lembed(
'all-MiniLM-L6-v2',
'The United States Postal Service is an independent agency...'
); -- X'A402...09C3' (1536 bytes)
all-MiniLM-L6-v2.e4ce9877.q8_0.gguf here is a 24MB file, so this should run quite happily even on machines without much available RAM.
What if you don't want to run the models locally at all? Alex has another new extension for that, described in Introducing sqlite-rembed: A SQLite extension for generating text embeddings from remote APIs. The rembed is for remote embeddings, and this extension uses Rust to call multiple remotely-hosted embeddings APIs, registered like this:
INSERT INTO temp.rembed_clients(name, options)
VALUES ('text-embedding-3-small', 'openai');
select rembed(
'text-embedding-3-small',
'The United States Postal Service is an independent agency...'
); -- X'A452...01FC', Blob<6144 bytes>
Here's the Rust code that implements Rust wrapper functions for HTTP JSON APIs from OpenAI, Nomic, Cohere, Jina, Mixedbread and localhost servers provided by Ollama and Llamafile.
Both of these extensions are designed to complement Alex's sqlite-vec extension, which is nearing a first stable release.
Our estimate of OpenAI’s $4 billion in inference costs comes from a person with knowledge of the cluster of servers OpenAI rents from Microsoft. That cluster has the equivalent of 350,000 Nvidia A100 chips, this person said. About 290,000 of those chips, or more than 80% of the cluster, were powering ChartGPT, this person said.
July 26, 2024
Did you know about Instruments? (via) Thorsten Ball shows how the macOS Instruments app (installed as part of Xcode) can be used to run a CPU profiler against any application - not just code written in Swift/Objective C.
I tried this against a Python process running LLM executing a Llama 3.1 prompt with my new llm-gguf plugin and captured this:
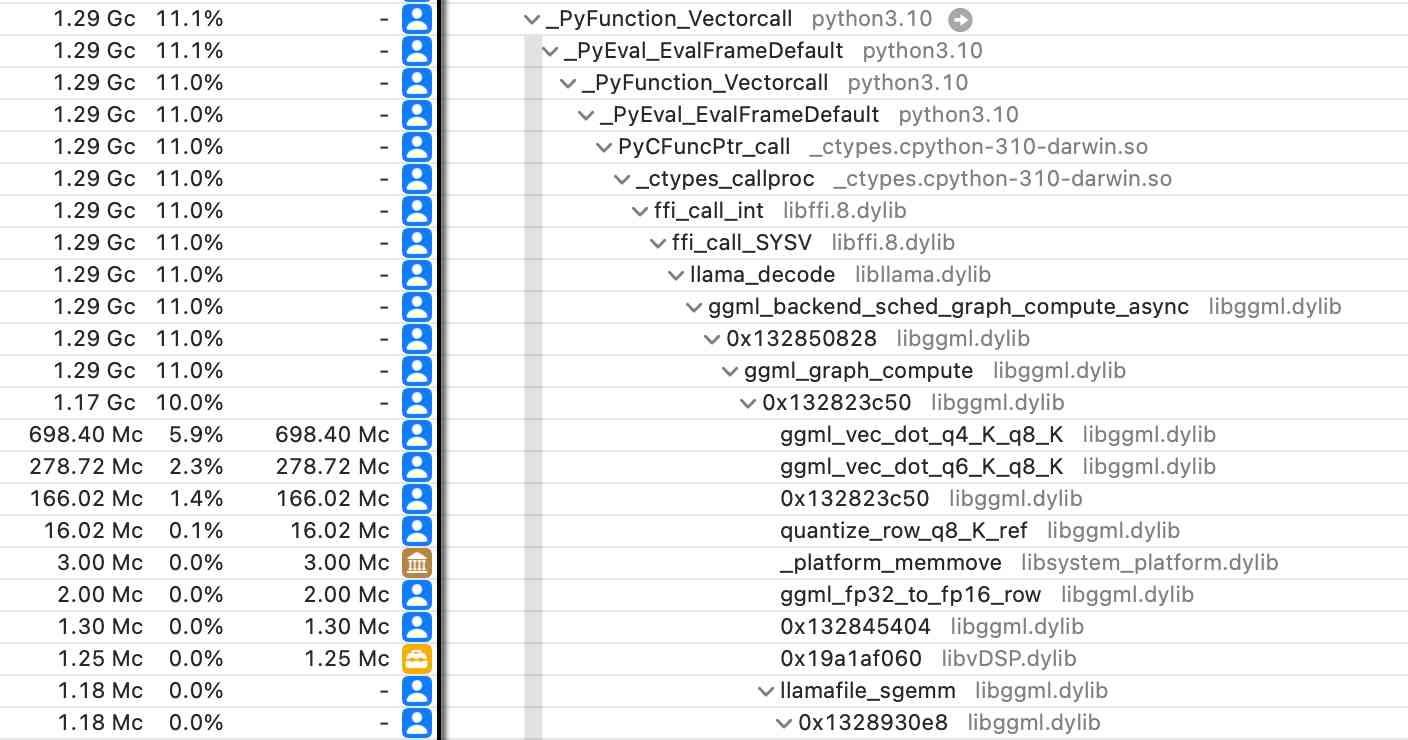
Image resize and quality comparison. Another tiny tool I built with Claude 3.5 Sonnet and Artifacts. This one lets you select an image (or drag-drop one onto an area) and then displays that same image as a JPEG at 1, 0.9, 0.7, 0.5, 0.3 quality settings, then again but with at half the width. Each image shows its size in KB and can be downloaded directly from the page.

I'm trying to use more images on my blog (example 1, example 2) and I like to reduce their file size and quality while keeping them legible.
The prompt sequence I used for this was:
Build an artifact (no React) that I can drop an image onto and it presents that image resized to different JPEG quality levels, each with a download link
Claude produced this initial artifact. I followed up with:
change it so that for any image it provides it in the following:
- original width, full quality
- original width, 0.9 quality
- original width, 0.7 quality
- original width, 0.5 quality
- original width, 0.3 quality
- half width - same array of qualities
For each image clicking it should toggle its display to full width and then back to max-width of 80%
Images should show their size in KB
Claude produced this v2.
I tweaked it a tiny bit (modifying how full-width images are displayed) - the final source code is available here. I'm hosting it on my own site which means the Download links work correctly - when hosted on claude.site Claude's CSP headers prevent those from functioning.
July 27, 2024
Among many misunderstandings, [users] expect the RAG system to work like a search engine, not as a flawed, forgetful analyst. They will not do the work that you expect them to do in order to verify documents and ground truth. They will not expect the AI to try to persuade them.
July 28, 2024
The key to understanding the pace of today’s infrastructure buildout is to recognize that while AI optimism is certainly a driver of AI CapEx, it is not the only one. The cloud players exist in a ruthless oligopoly with intense competition. [...]
Every time Microsoft escalates, Amazon is motivated to escalate to keep up. And vice versa. We are now in a cycle of competitive escalation between three of the biggest companies in the history of the world, collectively worth more than $7T. At each cycle of the escalation, there is an easy justification—we have plenty of money to afford this. With more commitment comes more confidence, and this loop becomes self-reinforcing. Supply constraints turbocharge this dynamic: If you don’t acquire land, power and labor now, someone else will.
CalcGPT (via) Fun satirical GPT-powered calculator demo by Calvin Liang, originally built in July 2023. From the ChatGPT-generated artist statement:
The piece invites us to reflect on the necessity and relevance of AI in every aspect of our lives as opposed to its prevailing use as a mere marketing gimmick. With its delightful slowness and propensity for computational errors, CalcGPT elicits mirth while urging us to question our zealous indulgence in all things AI.
The source code shows that it's using babbage-002 (a GPT3-era OpenAI model which I hadn't realized was still available through their API) that takes a completion-style prompt, which Calvin primes with some examples before including the user's entered expression from the calculator:
1+1=2
5-2=3
2*4=8
9/3=3
10/3=3.33333333333
${math}=
It sets \n as the stop sequence.