December 2024
136 posts: 12 entries, 62 links, 26 quotes, 36 beats
Dec. 1, 2024
Most people don’t have an intuition about what current hardware can and can’t do. There is a simple math that can help you with that: “you can process about 500MB in one second on a single machine”. I know it’s not a universal truth and there are a lot of details that can change that but believe me, this estimation is a pretty good tool to have under your belt.
Turning Your Root URL Into a DuckDB Remote Database. Fun idea from Drew Breunig: DuckDB supports attaching existing databases that are accessible over HTTP using their URL. Drew suggests creating vanity URLs using your root domain, detecting the DuckDB user-agent and serving the database file directly - allowing tricks like this one:
ATTACH 'https://steplist.app/' AS steplist;
SELECT * FROM steplist.lists;
LLM 0.19. I just released version 0.19 of LLM, my Python library and CLI utility for working with Large Language Models.
I released 0.18 a couple of weeks ago adding support for calling models from Python asyncio code. 0.19 improves on that, and also adds a new mechanism for models to report their token usage.
LLM can log those usage numbers to a SQLite database, or make then available to custom Python code.
My eventual goal with these features is to implement token accounting as a Datasette plugin so I can offer AI features in my SaaS platform without worrying about customers spending unlimited LLM tokens.
Those 0.19 release notes in full:
- Tokens used by a response are now logged to new
input_tokensandoutput_tokensinteger columns and atoken_detailsJSON string column, for the default OpenAI models and models from other plugins that implement this feature. #610llm promptnow takes a-u/--usageflag to display token usage at the end of the response.llm logs -u/--usageshows token usage information for logged responses.llm prompt ... --asyncresponses are now logged to the database. #641llm.get_models()andllm.get_async_models()functions, documented here. #640response.usage()and async responseawait response.usage()methods, returning aUsage(input=2, output=1, details=None)dataclass. #644response.on_done(callback)andawait response.on_done(callback)methods for specifying a callback to be executed when a response has completed, documented here. #653- Fix for bug running
llm chaton Windows 11. Thanks, Sukhbinder Singh. #495
I also released three new plugin versions that add support for the new usage tracking feature: llm-gemini 0.5, llm-claude-3 0.10 and llm-mistral 0.9.
Dec. 2, 2024
Simon Willison: The Future of Open Source and AI (via) I sat down a few weeks ago to record this conversation with Logan Kilpatrick and Nolan Fortman for their podcast Around the Prompt. The episode is available on YouTube and Apple Podcasts and other platforms.
We talked about a whole bunch of different topics, including the ongoing debate around the term "open source" when applied to LLMs and my thoughts on why I don't feel threatened by LLMs as a software engineer (at 40m05s).
For most software engineers, being well rounded is more important than pure technical mastery. This was already true, of course — see @patio11's famous advice "Don't call yourself a programmer" — but even more so due to foundation models. In most situations, skills like being able to use AI to rapidly prototype in order to communicate with clients to iterate on specifications create far more business value than technical wizardry alone.
PydanticAI (via) New project from Pydantic, which they describe as an "Agent Framework / shim to use Pydantic with LLMs".
I asked which agent definition they are using and it's the "system prompt with bundled tools" one. To their credit, they explain that in their documentation:
The Agent has full API documentation, but conceptually you can think of an agent as a container for:
- A system prompt — a set of instructions for the LLM written by the developer
- One or more retrieval tool — functions that the LLM may call to get information while generating a response
- An optional structured result type — the structured datatype the LLM must return at the end of a run
Given how many other existing tools already lean on Pydantic to help define JSON schemas for talking to LLMs this is an interesting complementary direction for Pydantic to take.
There's some overlap here with my own LLM project, which I still hope to add a function calling / tools abstraction to in the future.
NYTimes reporters getting verified profiles on Bluesky.
NYT data journalist Dylan Freedman has kicked off an initiative to get NYT accounts and reporters on Bluesky verified via vanity nytimes.com handles - Dylan is now @dylanfreedman.nytimes.com.
They're using Bluesky's support for TXT domain records. If you use Google's Dig tool to look at the TXT record for _atproto.dylanfreedman.nytimes.com you'll see this:
_atproto.dylanfreedman.nytimes.com. 500 IN TXT "did=did:plc:zeqq4z7aybrqg6go6vx6lzwt"
datasette-llm-usage. I released the first alpha of a Datasette plugin to help track LLM usage by other plugins, with the goal of supporting token allowances - both for things like free public apps that stop working after a daily allowance, plus free previews of AI features for paid-account-based projects such as Datasette Cloud.
It's using the usage features I added in LLM 0.19.
The alpha doesn't do much yet - it will start getting interesting once I upgrade other plugins to depend on it.
Design notes so far in issue #1.
Dec. 3, 2024
Certain names make ChatGPT grind to a halt, and we know why (via) Benj Edwards on the really weird behavior where ChatGPT stops output with an error rather than producing the names David Mayer, Brian Hood, Jonathan Turley, Jonathan Zittrain, David Faber or Guido Scorza.
The OpenAI API is entirely unaffected - this problem affects the consumer ChatGPT apps only.
It turns out many of those names are examples of individuals who have complained about being defamed by ChatGPT in the last. Brian Hood is the Australian mayor who was a victim of lurid ChatGPT hallucinations back in March 2023, and settled with OpenAI out of court.
Finally, in most workplaces, incentive structures don’t exist for people to (a) reduce their workloads to such an extent that their role becomes vulnerable or (b) voluntarily accept more responsibility without also taking on more pay.
These things are all natural rate limiters on technology adoption and the precise mix they show up in varies from workplace to workplace as every team has its own culture and ways of working. And regardless of what your friendly neighbourhood management consulting firm will tell you, there’s no one singular set of mitigations to get around this – technology will work best in your workplace if it’s rolled out in tune with existing culture, routines, and ways of working.
— Rachel Coldicutt, FOMO is not a strategy
Introducing Amazon Aurora DSQL (via) New, weird-shaped database from AWS. It's (loosely) PostgreSQL compatible, claims "virtually unlimited scale" and can be set up as a single-region cluster or as a multi-region setup that somehow supports concurrent reads and writes across all regions. I'm hoping they publish technical details on how that works at some point in the future (update: they did), right now they just say this:
When you create a multi-Region cluster, Aurora DSQL creates another cluster in a different Region and links them together. Adding linked Regions makes sure that all changes from committed transactions are replicated to the other linked Regions. Each linked cluster has a Regional endpoint, and Aurora DSQL synchronously replicates writes across Regions, enabling strongly consistent reads and writes from any linked cluster.
Here's the list of unsupported PostgreSQL features - most notably views, triggers, sequences, foreign keys and extensions. A single transaction can also modify only up to 10,000 rows.
No pricing information yet (it's in a free preview) but it looks like this one may be true scale-to-zero, unlike some of their other recent "serverless" products - Amazon Aurora Serverless v2 has a baseline charge no matter how heavily you are using it. (Update: apparently that changed on 20th November 2024 when they introduced an option to automatically pause a v2 serverless instance, which then "takes less than 15 seconds to resume".)
Open source is really part of my process of getting unstuck, learning and contributing back to the community, and also helping future me have an easier time. ‘Me’ is probably the number one beneficiary of my open-source software work. To be honest with you, a lot of it is selfish. It's really about making me more productive, happier, and less stressed. For people who wonder why we should do open source, I think that they should consider that they themselves may benefit more than they realize.
One big thing that a lot of people love to do is create new role types. For any new thing a company wants to do, the tendency is to put up a new job description.
I think a lot of people notice this and chafe at it when the role is for the new hotness. For example, every company wants to rub some AI on their stuff now, so they are putting up job descriptions for AI engineers.
If you’re an engineer interested in AI sitting in such a company, you’re annoyed that they’re doing this (and potentially paying that person more than you) when you could easily rub some AI on some stuff.
— Dan McKinley, Egoless Engineering
Transferring Python Build Standalone Stewardship to Astral. Gregory Szorc's Python Standalone Builds have been quietly running an increasing portion of the Python ecosystem for a few years now, but really accelerated in importance when uv started using them for new Python installations managed by that tool. The releases (shipped via GitHub) have now been downloaded over 70 million times, 50 million of those since uv's initial release in March of this year.
uv maintainers Astral have been helping out with PSB maintenance for a while:
When I told Charlie I could use assistance supporting PBS, Astral employees started contributing to the project. They have built out various functionality, including Python 3.13 support (including free-threaded builds), turnkey automated release publishing, and debug symbol stripped builds to further reduce the download/install size. Multiple Astral employees now have GitHub permissions to approve/merge PRs and publish releases. All releases since April have been performed by Astral employees.
As-of December 17th Gregory will be transferring the project to the Astral organization, while staying on as a maintainer and advisor. Here's Astral's post about this: A new home for python-build-standalone.
datasette-queries. I released the first alpha of a new plugin to replace the crusty old datasette-saved-queries. This one adds a new UI element to the top of the query results page with an expandable form for saving the query as a new canned query:
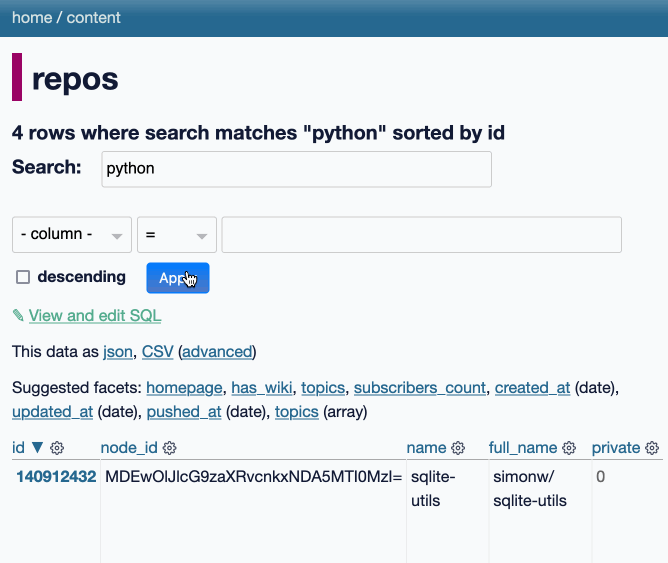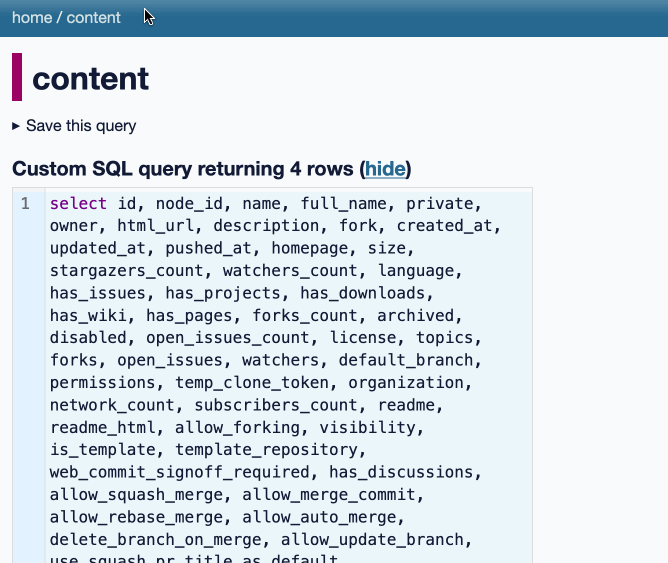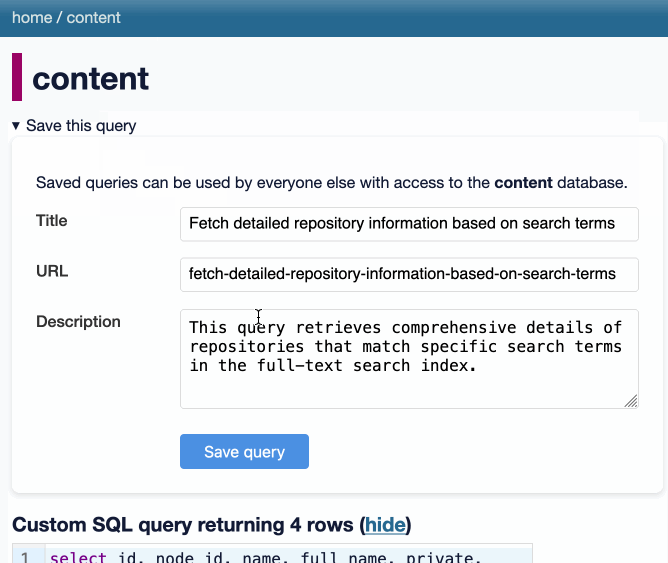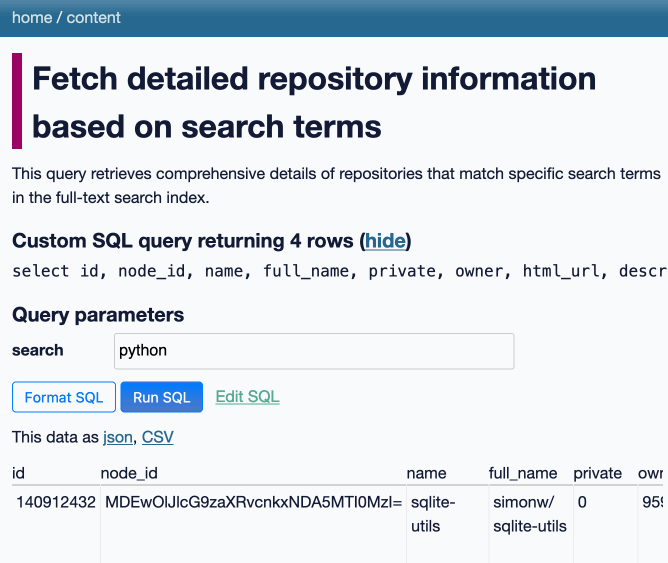
It's my first plugin to depend on LLM and datasette-llm-usage - it uses GPT-4o mini to power an optional "Suggest title and description" button, labeled with the becoming-standard ✨ sparkles emoji to indicate an LLM-powered feature.
I intend to expand this to work across multiple models as I continue to iterate on llm-datasette-usage to better support those kinds of patterns.
For the moment though each suggested title and description call costs about 250 input tokens and 50 output tokens, which against GPT-4o mini adds up to 0.0067 cents.
Dec. 4, 2024
First impressions of the new Amazon Nova LLMs (via a new llm-bedrock plugin)
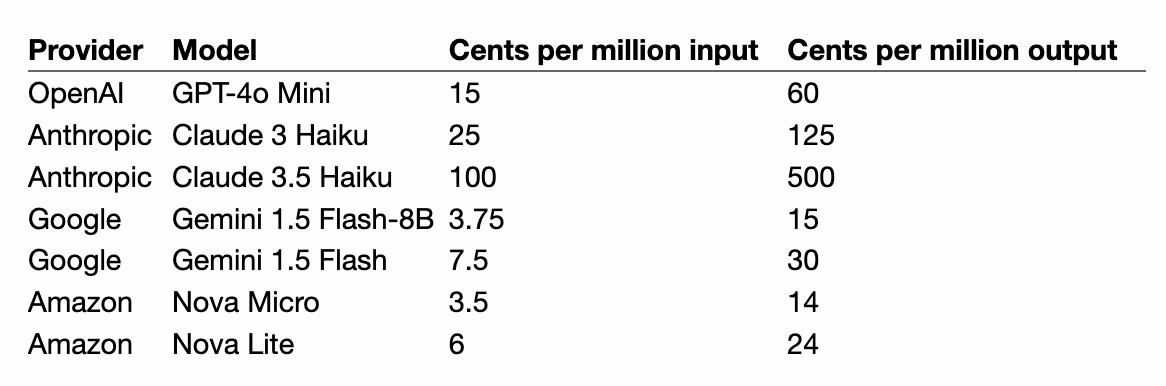
Amazon released three new Large Language Models yesterday at their AWS re:Invent conference. The new model family is called Amazon Nova and comes in three sizes: Micro, Lite and Pro.
[... 2,385 words]In the past, these decisions were so consequential, they were basically one-way doors, in Amazon language. That’s why we call them ‘architectural decisions!’ You basically have to live with your choice of database, authentication, JavaScript UI framework, almost forever.
But that’s changing with LLMs, because you can explore, investigate, and even prototype each one so quickly. Even technology migrations are becoming so much easier/cheaper/faster.
These are all examples of increasing optionality.
— Steve Yegge, via Gene Kim
Genie 2: A large-scale foundation world model (via) New research (so nothing we can play with) from Google DeepMind. Genie 2 is effectively a game engine driven entirely by generative AI - you can seed it with any image and it will turn that image into a 3D environment that you can then explore.
It's reminiscent of last month's impressive Oasis: A Universe in a Transformer by Decart and Etched which provided a Minecraft clone where each frame was generated based on the previous one. That one you can try out (Chrome only) - notably, any time you look directly up at the sky or down at the ground the model forgets where you were and creates a brand new world.
Genie 2 at least partially addresses that problem:
Genie 2 is capable of remembering parts of the world that are no longer in view and then rendering them accurately when they become observable again.
The capability list for Genie 2 is really impressive, each accompanied by a short video. They have demos of first person and isometric views, interactions with objects, animated character interactions, water, smoke, gravity and lighting effects, reflections and more.