403 posts tagged “openai”
2026
Thoughts on OpenAI acquiring Astral and uv/ruff/ty
The big news this morning: Astral to join OpenAI (on the Astral blog) and OpenAI to acquire Astral (the OpenAI announcement). Astral are the company behind uv, ruff, and ty—three increasingly load-bearing open source projects in the Python ecosystem. I have thoughts!
[... 1,378 words]GPT-5.4 mini and GPT-5.4 nano, which can describe 76,000 photos for $52
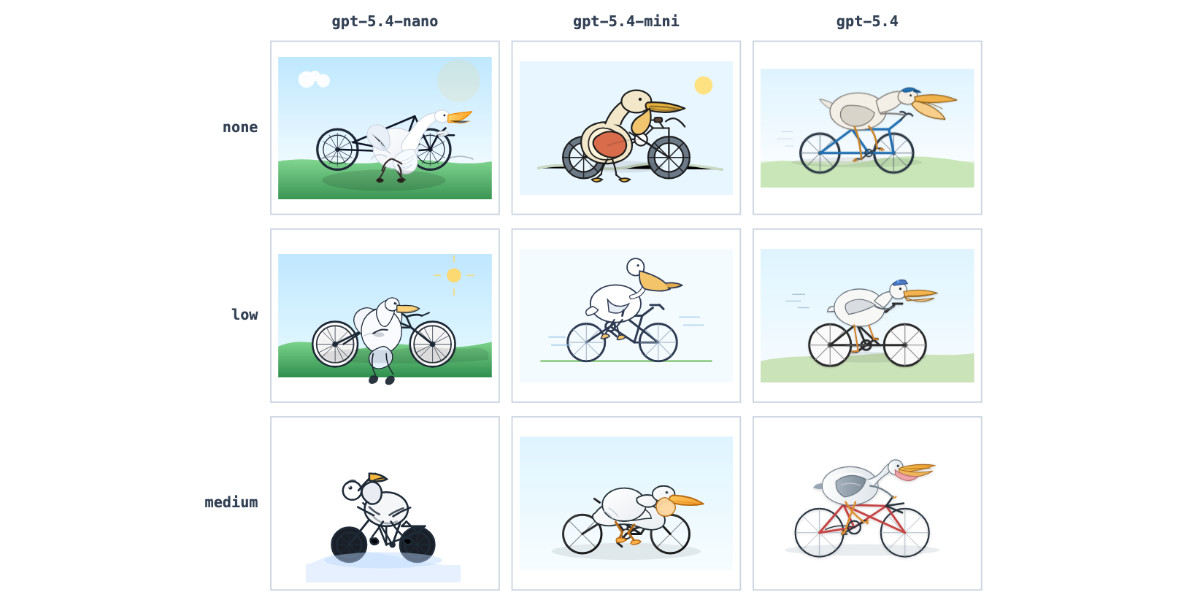
OpenAI today: Introducing GPT‑5.4 mini and nano. These models join GPT-5.4 which was released two weeks ago.
[... 717 words]Use subagents and custom agents in Codex (via) Subagents were announced in general availability today for OpenAI Codex, after several weeks of preview behind a feature flag.
They're very similar to the Claude Code implementation, with default subagents for "explorer", "worker" and "default". It's unclear to me what the difference between "worker" and "default" is but based on their CSV example I think "worker" is intended for running large numbers of small tasks in parallel.
Codex also lets you define custom agents as TOML files in ~/.codex/agents/. These can have custom instructions and be assigned to use specific models - including gpt-5.3-codex-spark if you want some raw speed. They can then be referenced by name, as demonstrated by this example prompt from the documentation:
Investigate why the settings modal fails to save. Have browser_debugger reproduce it, code_mapper trace the responsible code path, and ui_fixer implement the smallest fix once the failure mode is clear.
The subagents pattern is widely supported in coding agents now. Here's documentation across a number of different platforms:
- OpenAI Codex subagents
- Claude Code subagents
- Gemini CLI subagents (experimental)
- Mistral Vibe subagents
- OpenCode agents
- Subagents in Visual Studio Code
- Cursor Subagents
Update: I added a chapter on Subagents to my Agentic Engineering Patterns guide.
Codex for Open Source (via) Anthropic announced six months of free Claude Max for maintainers of popular open source projects (5,000+ stars or 1M+ NPM downloads) on 27th February.
Now OpenAI have launched their comparable offer: six months of ChatGPT Pro (same $200/month price as Claude Max) with Codex and "conditional access to Codex Security" for core maintainers.
Unlike Anthropic they don't hint at the exact metrics they care about, but the application form does ask for "information such as GitHub stars, monthly downloads, or why the project is important to the ecosystem."
Anthropic and the Pentagon. This piece by Bruce Schneier and Nathan E. Sanders is the most thoughtful and grounded coverage I've seen of the recent and ongoing Pentagon/OpenAI/Anthropic contract situation.
AI models are increasingly commodified. The top-tier offerings have about the same performance, and there is little to differentiate one from the other. The latest models from Anthropic, OpenAI and Google, in particular, tend to leapfrog each other with minor hops forward in quality every few months. [...]
In this sort of market, branding matters a lot. Anthropic and its CEO, Dario Amodei, are positioning themselves as the moral and trustworthy AI provider. That has market value for both consumers and enterprise clients.
Introducing GPT‑5.4. Two new API models: gpt-5.4 and gpt-5.4-pro, also available in ChatGPT and Codex CLI. August 31st 2025 knowledge cutoff, 1 million token context window. Priced slightly higher than the GPT-5.2 family with a bump in price for both models if you go above 272,000 tokens.
5.4 beats coding specialist GPT-5.3-Codex on all of the relevant benchmarks. I wonder if we'll get a 5.4 Codex or if that model line has now been merged into main?
Given Claude's recent focus on business applications it's interesting to see OpenAI highlight this in their announcement of GPT-5.4:
We put a particular focus on improving GPT‑5.4’s ability to create and edit spreadsheets, presentations, and documents. On an internal benchmark of spreadsheet modeling tasks that a junior investment banking analyst might do, GPT‑5.4 achieves a mean score of 87.3%, compared to 68.4% for GPT‑5.2.
Here's a pelican on a bicycle drawn by GPT-5.4:

And here's one by GPT-5.4 Pro, which took 4m45s and cost me $1.55:

If people are only using this a couple of times a week at most, and can’t think of anything to do with it on the average day, it hasn’t changed their life. OpenAI itself admits the problem, talking about a ‘capability gap’ between what the models can do and what people do with them, which seems to me like a way to avoid saying that you don’t have clear product-market fit.
Hence, OpenAI’s ad project is partly just about covering the cost of serving the 90% or more of users who don’t pay (and capturing an early lead with advertisers and early learning in how this might work), but more strategically, it’s also about making it possible to give those users the latest and most powerful (i.e. expensive) models, in the hope that this will deepen their engagement.
— Benedict Evans, How will OpenAI compete?
How I think about Codex. Gabriel Chua (Developer Experience Engineer for APAC at OpenAI) provides his take on the confusing terminology behind the term "Codex", which can refer to a bunch of of different things within the OpenAI ecosystem:
In plain terms, Codex is OpenAI’s software engineering agent, available through multiple interfaces, and an agent is a model plus instructions and tools, wrapped in a runtime that can execute tasks on your behalf. [...]
At a high level, I see Codex as three parts working together:
Codex = Model + Harness + Surfaces [...]
- Model + Harness = the Agent
- Surfaces = how you interact with the Agent
He defines the harness as "the collection of instructions and tools", which is notably open source and lives in the openai/codex repository.
Gabriel also provides the first acknowledgment I've seen from an OpenAI insider that the Codex model family are directly trained for the Codex harness:
Codex models are trained in the presence of the harness. Tool use, execution loops, compaction, and iterative verification aren’t bolted on behaviors — they’re part of how the model learns to operate. The harness, in turn, is shaped around how the model plans, invokes tools, and recovers from failure.
We’ve made GPT-5.3-Codex-Spark about 30% faster. It is now serving at over 1200 tokens per second.
— Thibault Sottiaux, OpenAI
SWE-bench February 2026 leaderboard update (via) SWE-bench is one of the benchmarks that the labs love to list in their model releases. The official leaderboard is infrequently updated but they just did a full run of it against the current generation of models, which is notable because it's always good to see benchmark results like this that weren't self-reported by the labs.
The fresh results are for their "Bash Only" benchmark, which runs their mini-swe-bench agent (~9,000 lines of Python, here are the prompts they use) against the SWE-bench dataset of coding problems - 2,294 real-world examples pulled from 12 open source repos: django/django (850), sympy/sympy (386), scikit-learn/scikit-learn (229), sphinx-doc/sphinx (187), matplotlib/matplotlib (184), pytest-dev/pytest (119), pydata/xarray (110), astropy/astropy (95), pylint-dev/pylint (57), psf/requests (44), mwaskom/seaborn (22), pallets/flask (11).
Correction: The Bash only benchmark runs against SWE-bench Verified, not original SWE-bench. Verified is a manually curated subset of 500 samples described here, funded by OpenAI. Here's SWE-bench Verified on Hugging Face - since it's just 2.1MB of Parquet it's easy to browse using Datasette Lite, which cuts those numbers down to django/django (231), sympy/sympy (75), sphinx-doc/sphinx (44), matplotlib/matplotlib (34), scikit-learn/scikit-learn (32), astropy/astropy (22), pydata/xarray (22), pytest-dev/pytest (19), pylint-dev/pylint (10), psf/requests (8), mwaskom/seaborn (2), pallets/flask (1).
Here's how the top ten models performed:
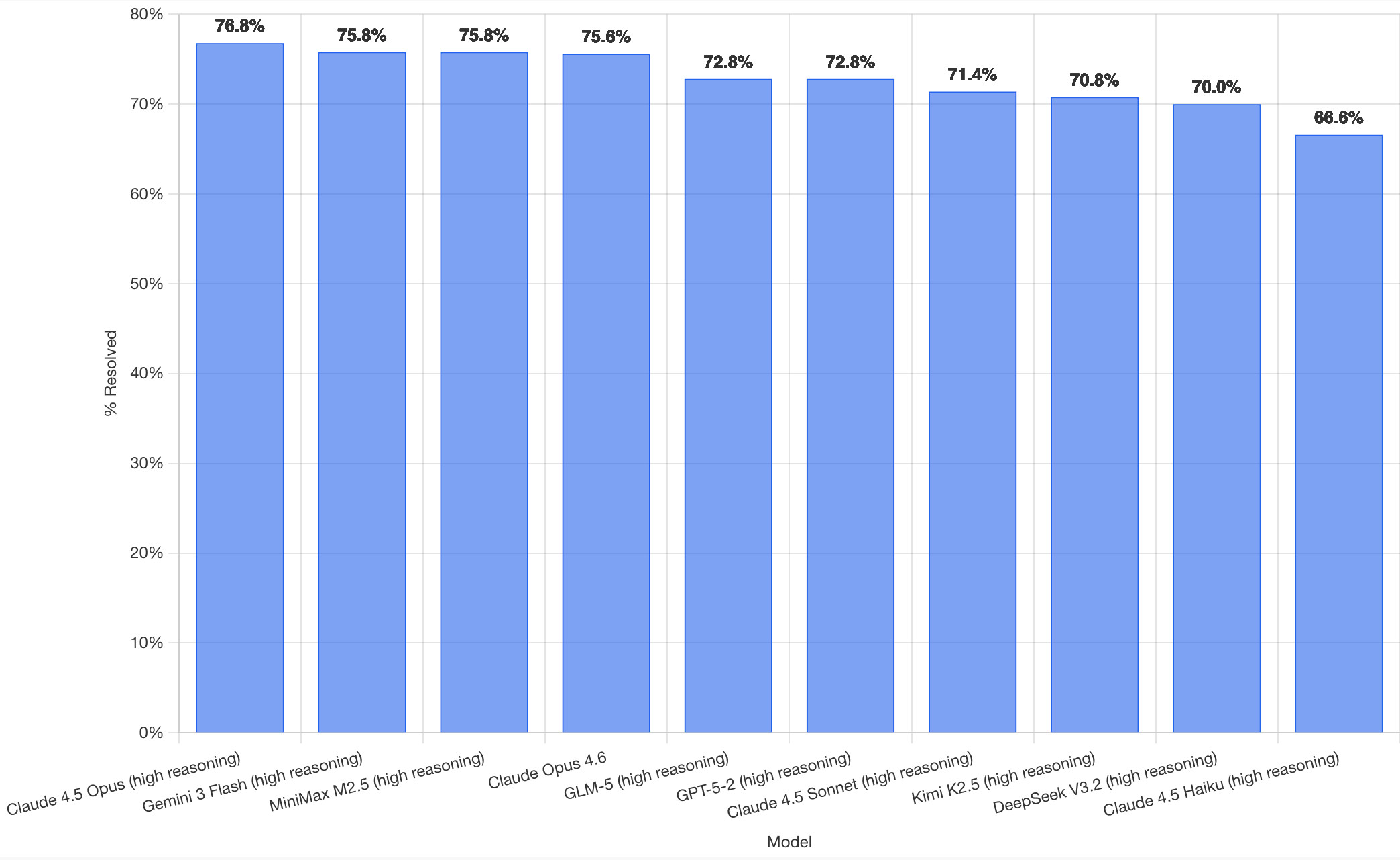
It's interesting to see Claude Opus 4.5 beat Opus 4.6, though only by about a percentage point. 4.5 Opus is top, then Gemini 3 Flash, then MiniMax M2.5 - a 229B model released last week by Chinese lab MiniMax. GLM-5, Kimi K2.5 and DeepSeek V3.2 are three more Chinese models that make the top ten as well.
OpenAI's GPT-5.2 is their highest performing model at position 6, but it's worth noting that their best coding model, GPT-5.3-Codex, is not represented - maybe because it's not yet available in the OpenAI API.
This benchmark uses the same system prompt for every model, which is important for a fair comparison but does mean that the quality of the different harnesses or optimized prompts is not being measured here.
The chart above is a screenshot from the SWE-bench website, but their charts don't include the actual percentage values visible on the bars. I successfully used Claude for Chrome to add these - transcript here. My prompt sequence included:
Use claude in chrome to open https://www.swebench.com/
Click on "Compare results" and then select "Select top 10"
See those bar charts? I want them to display the percentage on each bar so I can take a better screenshot, modify the page like that
I'm impressed at how well this worked - Claude injected custom JavaScript into the page to draw additional labels on top of the existing chart.
![Screenshot of a Claude AI conversation showing browser automation. A thinking step reads "Pivoted strategy to avoid recursion issues with chart labeling >" followed by the message "Good, the chart is back. Now let me carefully add the labels using an inline plugin on the chart instance to avoid the recursion issue." A collapsed "Browser_evaluate" section shows a browser_evaluate tool call with JavaScript code using Chart.js canvas context to draw percentage labels on bars: meta.data.forEach((bar, index) => { const value = dataset.data[index]; if (value !== undefined && value !== null) { ctx.save(); ctx.textAlign = 'center'; ctx.textBaseline = 'bottom'; ctx.fillStyle = '#333'; ctx.font = 'bold 12px sans-serif'; ctx.fillText(value.toFixed(1) + '%', bar.x, bar.y - 5); A pending step reads "Let me take a screenshot to see if it worked." followed by a completed "Done" step, and the message "Let me take a screenshot to check the result."](https://static.simonwillison.net/static/2026/claude-chrome-draw-on-chart.jpg)
Update: If you look at the transcript Claude claims to have switched to Playwright, which is confusing because I didn't think I had that configured.
It's wild that the first commit to OpenClaw was on November 25th 2025, and less than three months later it's hit 10,000 commits from 600 contributors, attracted 196,000 GitHub stars and sort-of been featured in an extremely vague Super Bowl commercial for AI.com.
Quoting AI.com founder Kris Marszalek, purchaser of the most expensive domain in history for $70m:
ai.com is the world’s first easy-to-use and secure implementation of OpenClaw, the open source agent framework that went viral two weeks ago; we made it easy to use without any technical skills, while hardening security to keep your data safe.
Looks like vaporware to me - all you can do right now is reserve a handle - but it's still remarkable to see an open source project get to that level of hype in such a short space of time.
Update: OpenClaw creator Peter Steinberger just announced that he's joining OpenAI and plans to transfer ownership of OpenClaw to a new independent foundation.
The evolution of OpenAI’s mission statement

As a USA 501(c)(3) the OpenAI non-profit has to file a tax return each year with the IRS. One of the required fields on that tax return is to “Briefly describe the organization’s mission or most significant activities”—this has actual legal weight to it as the IRS can use it to evaluate if the organization is sticking to its mission and deserves to maintain its non-profit tax-exempt status.
[... 680 words]Introducing GPT‑5.3‑Codex‑Spark. OpenAI announced a partnership with Cerebras on January 14th. Four weeks later they're already launching the first integration, "an ultra-fast model for real-time coding in Codex".
Despite being named GPT-5.3-Codex-Spark it's not purely an accelerated alternative to GPT-5.3-Codex - the blog post calls it "a smaller version of GPT‑5.3-Codex" and clarifies that "at launch, Codex-Spark has a 128k context window and is text-only."
I had some preview access to this model and I can confirm that it's significantly faster than their other models.
Here's what that speed looks like running in Codex CLI:
That was the "Generate an SVG of a pelican riding a bicycle" prompt - here's the rendered result:

Compare that to the speed of regular GPT-5.3 Codex medium:
Significantly slower, but the pelican is a lot better:

What's interesting about this model isn't the quality though, it's the speed. When a model responds this fast you can stay in flow state and iterate with the model much more productively.
I showed a demo of Cerebras running Llama 3.1 70 B at 2,000 tokens/second against Val Town back in October 2024. OpenAI claim 1,000 tokens/second for their new model, and I expect it will prove to be a ferociously useful partner for hands-on iterative coding sessions.
It's not yet clear what the pricing will look like for this new model.
Skills in OpenAI API. OpenAI's adoption of Skills continues to gain ground. You can now use Skills directly in the OpenAI API with their shell tool. You can zip skills up and upload them first, but I think an even neater interface is the ability to send skills with the JSON request as inline base64-encoded zip data, as seen in this script:
r = OpenAI().responses.create( model="gpt-5.2", tools=[ { "type": "shell", "environment": { "type": "container_auto", "skills": [ { "type": "inline", "name": "wc", "description": "Count words in a file.", "source": { "type": "base64", "media_type": "application/zip", "data": b64_encoded_zip_file, }, } ], }, } ], input="Use the wc skill to count words in its own SKILL.md file.", ) print(r.output_text)
I built that example script after first having Claude Code for web use Showboat to explore the API for me and create this report. My opening prompt for the research project was:
Run uvx showboat --help - you will use this tool later
Fetch https://developers.openai.com/cookbook/examples/skills_in_api.md to /tmp with curl, then read it
Use the OpenAI API key you have in your environment variables
Use showboat to build up a detailed demo of this, replaying the examples from the documents and then trying some experiments of your own
When I want to quickly implement a one-off experiment in a part of the codebase I am unfamiliar with, I get codex to do extensive due diligence. Codex explores relevant slack channels, reads related discussions, fetches experimental branches from those discussions, and cherry picks useful changes for my experiment. All of this gets summarized in an extensive set of notes, with links back to where each piece of information was found. Using these notes, codex wires the experiment and makes a bunch of hyperparameter decisions I couldn’t possibly make without much more effort.
— Karel D'Oosterlinck, I spent $10,000 to automate my research at OpenAI with Codex
Two major new model releases today, within about 15 minutes of each other.
Anthropic released Opus 4.6. Here's its pelican:

OpenAI release GPT-5.3-Codex, albeit only via their Codex app, not yet in their API. Here's its pelican:

I've had a bit of preview access to both of these models and to be honest I'm finding it hard to find a good angle to write about them - they're both really good, but so were their predecessors Codex 5.2 and Opus 4.5. I've been having trouble finding tasks that those previous models couldn't handle but the new ones are able to ace.
The most convincing story about capabilities of the new model so far is Nicholas Carlini from Anthropic talking about Opus 4.6 and Building a C compiler with a team of parallel Claudes - Anthropic's version of Cursor's FastRender project.
Introducing the Codex app. OpenAI just released a new macOS app for their Codex coding agent. I've had a few days of preview access - it's a solid app that provides a nice UI over the capabilities of the Codex CLI agent and adds some interesting new features, most notably first-class support for Skills, and Automations for running scheduled tasks.
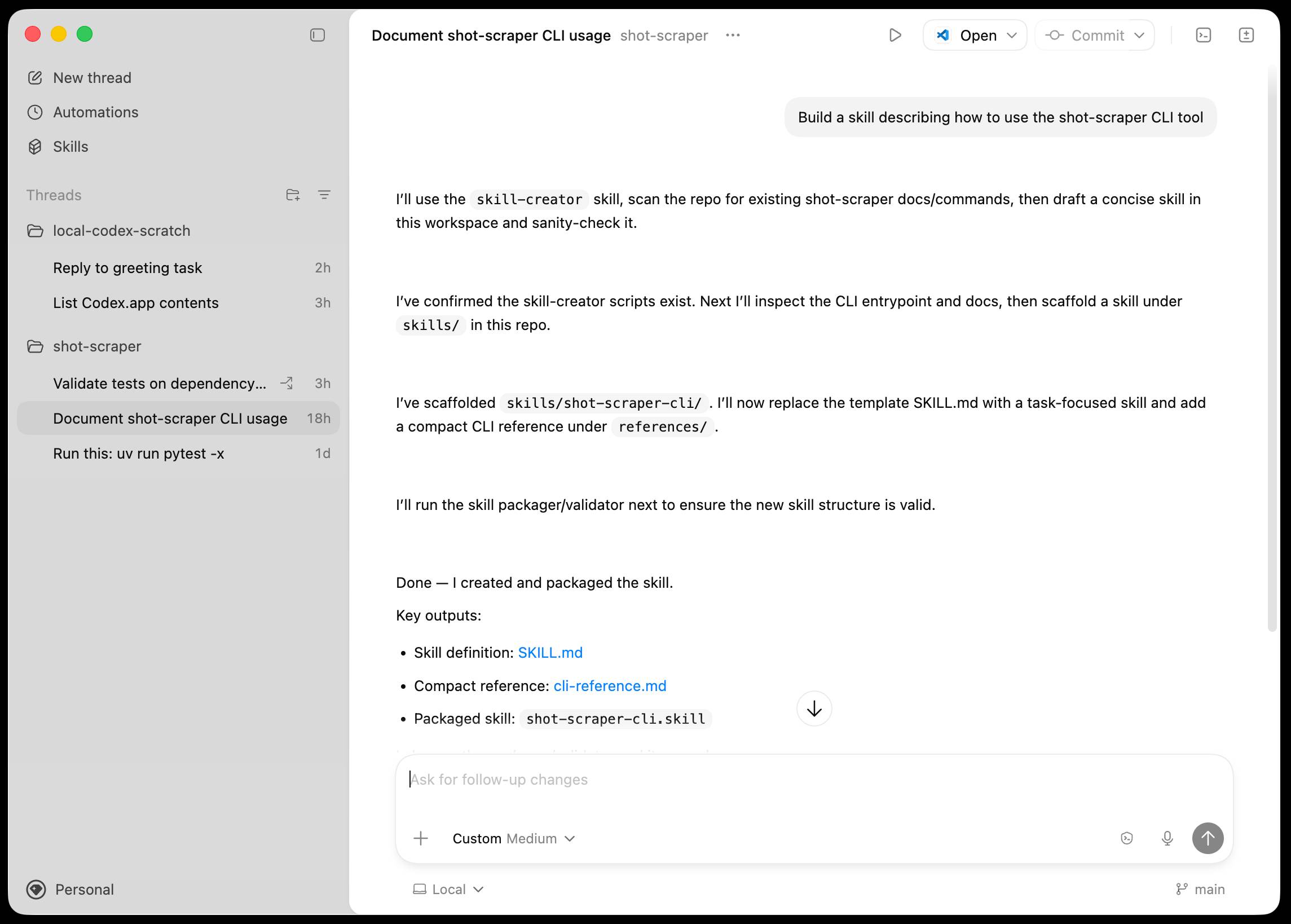
The app is built with Electron and Node.js. Automations track their state in a SQLite database - here's what that looks like if you explore it with uvx datasette ~/.codex/sqlite/codex-dev.db:

Here’s an interactive copy of that database in Datasette Lite.
The announcement gives us a hint at some usage numbers for Codex overall - the holiday spike is notable:
Since the launch of GPT‑5.2-Codex in mid-December, overall Codex usage has doubled, and in the past month, more than a million developers have used Codex.
Automations are currently restricted in that they can only run when your laptop is powered on. OpenAI promise that cloud-based automations are coming soon, which will resolve this limitation.
They chose Electron so they could target other operating systems in the future, with Windows “coming very soon”. OpenAI’s Alexander Embiricos noted on the Hacker News thread that:
it's taking us some time to get really solid sandboxing working on Windows, where there are fewer OS-level primitives for it.
Like Claude Code, Codex is really a general agent harness disguised as a tool for programmers. OpenAI acknowledge that here:
Codex is built on a simple premise: everything is controlled by code. The better an agent is at reasoning about and producing code, the more capable it becomes across all forms of technical and knowledge work. [...] We’ve focused on making Codex the best coding agent, which has also laid the foundation for it to become a strong agent for a broad range of knowledge work tasks that extend beyond writing code.
Claude Code had to rebrand to Cowork to better cover the general knowledge work case. OpenAI can probably get away with keeping the Codex name for both.
OpenAI have made Codex available to free and Go plans for "a limited time" (update: Sam Altman says two months) during which they are also doubling the rate limits for paying users.
Originally in 2019, GPT-2 was trained by OpenAI on 32 TPU v3 chips for 168 hours (7 days), with $8/hour/TPUv3 back then, for a total cost of approx. $43K. It achieves 0.256525 CORE score, which is an ensemble metric introduced in the DCLM paper over 22 evaluations like ARC/MMLU/etc.
As of the last few improvements merged into nanochat (many of them originating in modded-nanogpt repo), I can now reach a higher CORE score in 3.04 hours (~$73) on a single 8XH100 node. This is a 600X cost reduction over 7 years, i.e. the cost to train GPT-2 is falling approximately 2.5X every year.
ChatGPT Containers can now run bash, pip/npm install packages, and download files
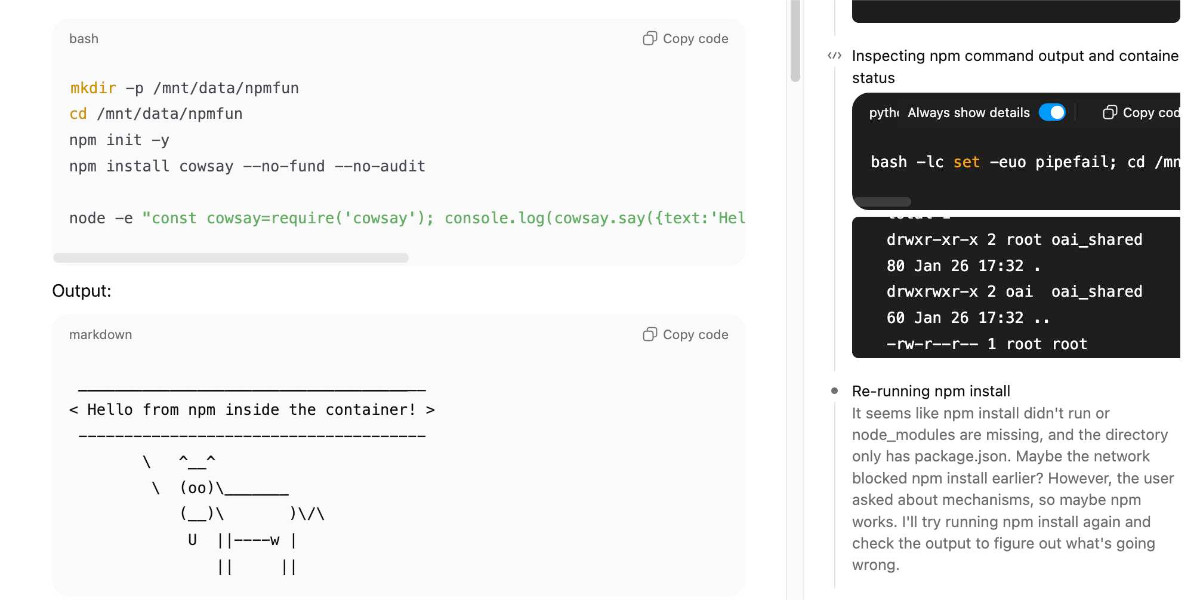
One of my favourite features of ChatGPT is its ability to write and execute code in a container. This feature launched as ChatGPT Code Interpreter nearly three years ago, was half-heartedly rebranded to “Advanced Data Analysis” at some point and is generally really difficult to find detailed documentation about. Case in point: it appears to have had a massive upgrade at some point in the past few months, and I can’t find documentation about the new capabilities anywhere!
[... 3,019 words]Our approach to advertising and expanding access to ChatGPT. OpenAI's long-rumored introduction of ads to ChatGPT just became a whole lot more concrete:
In the coming weeks, we’re also planning to start testing ads in the U.S. for the free and Go tiers, so more people can benefit from our tools with fewer usage limits or without having to pay. Plus, Pro, Business, and Enterprise subscriptions will not include ads.
What's "Go" tier, you might ask? That's a new $8/month tier that launched today in the USA, see Introducing ChatGPT Go, now available worldwide. It's a tier that they first trialed in India in August 2025 (here's a mention in their release notes from August listing a price of ₹399/month, which converts to around $4.40).
I'm finding the new plan comparison grid on chatgpt.com/pricing pretty confusing. It lists all accounts as having access to GPT-5.2 Thinking, but doesn't clarify the limits that the free and Go plans have to conform to. It also lists different context windows for the different plans - 16K for free, 32K for Go and Plus and 128K for Pro. I had assumed that the 400,000 token window on the GPT-5.2 model page applied to ChatGPT as well, but apparently I was mistaken.
Update: I've apparently not been paying attention: here's the Internet Archive ChatGPT pricing page from September 2025 showing those context limit differences as well.
Back to advertising: my biggest concern has always been whether ads will influence the output of the chat directly. OpenAI assure us that they will not:
- Answer independence: Ads do not influence the answers ChatGPT gives you. Answers are optimized based on what's most helpful to you. Ads are always separate and clearly labeled.
- Conversation privacy: We keep your conversations with ChatGPT private from advertisers, and we never sell your data to advertisers.
So what will they look like then? This screenshot from the announcement offers a useful hint:
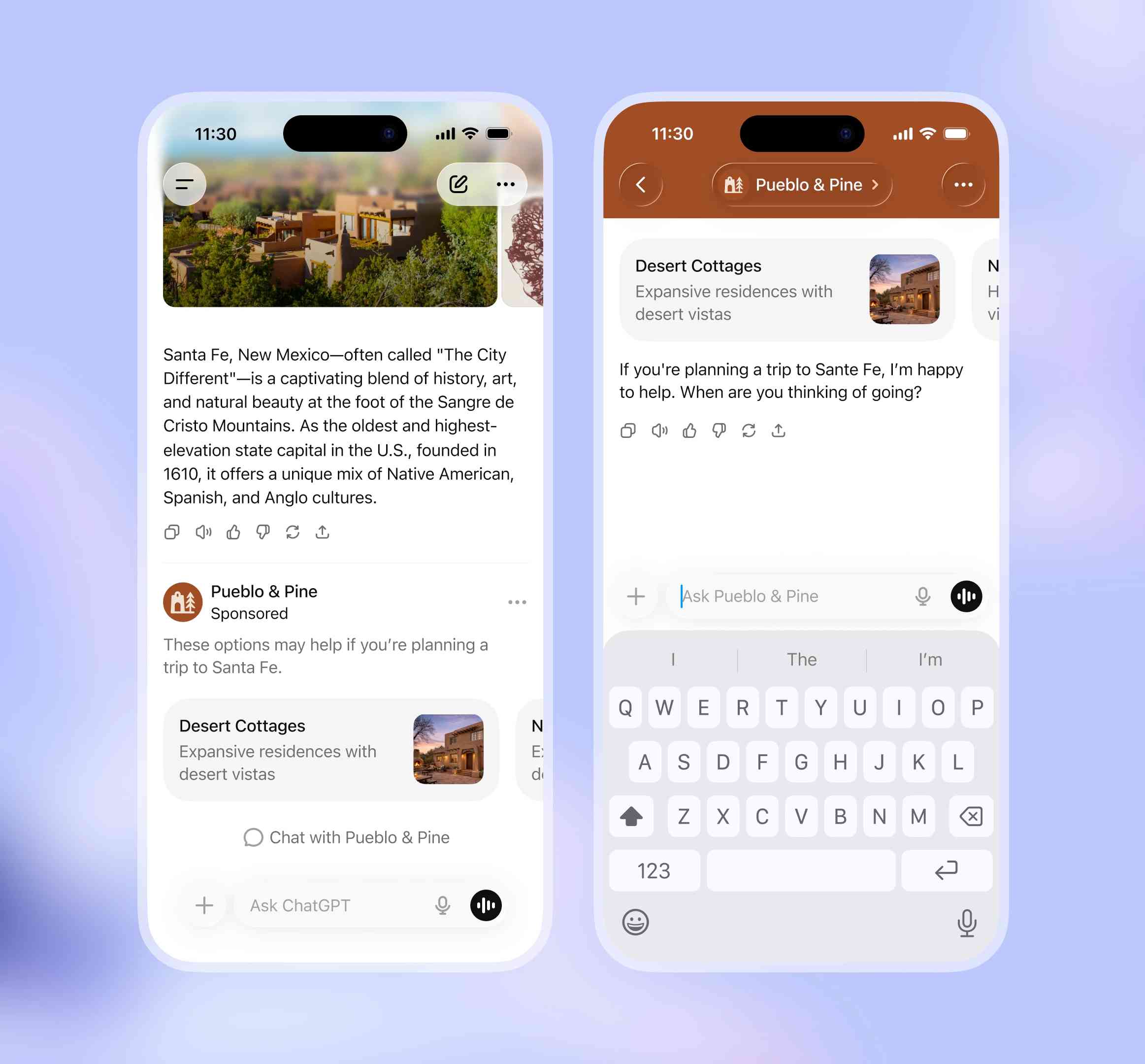
The user asks about trips to Santa Fe, and an ad shows up for a cottage rental business there. This particular example imagines an option to start a direct chat with a bot aligned with that advertiser, at which point presumably the advertiser can influence the answers all they like!
Open Responses (via) This is the standardization effort I've most wanted in the world of LLMs: a vendor-neutral specification for the JSON API that clients can use to talk to hosted LLMs.
Open Responses aims to provide exactly that as a documented standard, derived from OpenAI's Responses API.
I was hoping for one based on their older Chat Completions API since so many other products have cloned the already, but basing it on Responses does make sense since that API was designed with the feature of more recent models - such as reasoning traces - baked into the design.
What's certainly notable is the list of launch partners. OpenRouter alone means we can expect to be able to use this protocol with almost every existing model, and Hugging Face, LM Studio, vLLM, Ollama and Vercel cover a huge portion of the common tools used to serve models.
For protocols like this I really want to see a comprehensive, language-independent conformance test site. Open Responses has a subset of that - the official repository includes src/lib/compliance-tests.ts which can be used to exercise a server implementation, and is available as a React app on the official site that can be pointed at any implementation served via CORS.
What's missing is the equivalent for clients. I plan to spin up my own client library for this in Python and I'd really like to be able to run that against a conformance suite designed to check that my client correctly handles all of the details.
When we optimize responses using a reward model as a proxy for “goodness” in reinforcement learning, models sometimes learn to “hack” this proxy and output an answer that only “looks good” to it (because coming up with an answer that is actually good can be hard). The philosophy behind confessions is that we can train models to produce a second output — aka a “confession” — that is rewarded solely for honesty, which we will argue is less likely hacked than the normal task reward function. One way to think of confessions is that we are giving the model access to an “anonymous tip line” where it can turn itself in by presenting incriminating evidence of misbehavior. But unlike real-world tip lines, if the model acted badly in the original task, it can collect the reward for turning itself in while still keeping the original reward from the bad behavior in the main task. We hypothesize that this form of training will teach models to produce maximally honest confessions.
— Boaz Barak, Gabriel Wu, Jeremy Chen and Manas Joglekar, OpenAI: Why we are excited about confessions
How Google Got Its Groove Back and Edged Ahead of OpenAI (via) I picked up a few interesting tidbits from this Wall Street Journal piece on Google's recent hard won success with Gemini.
Here's the origin of the name "Nano Banana":
Naina Raisinghani, known inside Google for working late into the night, needed a name for the new tool to complete the upload. It was 2:30 a.m., though, and nobody was around. So she just made one up, a mashup of two nicknames friends had given her: Nano Banana.
The WSJ credit OpenAI's Daniel Selsam with un-retiring Sergei Brin:
Around that time, Google co-founder Sergey Brin, who had recently retired, was at a party chatting with a researcher from OpenAI named Daniel Selsam, according to people familiar with the conversation. Why, Selsam asked him, wasn’t he working full time on AI. Hadn’t the launch of ChatGPT captured his imagination as a computer scientist?
ChatGPT was on its way to becoming a household name in AI chatbots, while Google was still fumbling to get its product off the ground. Brin decided Selsam had a point and returned to work.
And we get some rare concrete user numbers:
By October, Gemini had more than 650 million monthly users, up from 450 million in July.
The LLM usage number I see cited most often is OpenAI's 800 million weekly active users for ChatGPT. That's from October 6th at OpenAI DevDay so it's comparable to these Gemini numbers, albeit not directly since it's weekly rather than monthly actives.
I'm also never sure what counts as a "Gemini user" - does interacting via Google Docs or Gmail count or do you need to be using a Gemini chat interface directly?
Update 17th January 2025: @LunixA380 pointed out that this 650m user figure comes from the Alphabet 2025 Q3 earnings report which says this (emphasis mine):
"Alphabet had a terrific quarter, with double-digit growth across every major part of our business. We delivered our first-ever $100 billion quarter," said Sundar Pichai, CEO of Alphabet and Google.
"[...] In addition to topping leaderboards, our first party models, like Gemini, now process 7 billion tokens per minute, via direct API use by our customers. The Gemini App now has over 650 million monthly active users.
Presumably the "Gemini App" encompasses the Android and iPhone apps as well as direct visits to gemini.google.com - that seems to be the indication from Google's November 18th blog post that also mentioned the 650m number.
It genuinely feels to me like GPT-5.2 and Opus 4.5 in November represent an inflection point - one of those moments where the models get incrementally better in a way that tips across an invisible capability line where suddenly a whole bunch of much harder coding problems open up.
2025
2025: The year in LLMs
This is the third in my annual series reviewing everything that happened in the LLM space over the past 12 months. For previous years see Stuff we figured out about AI in 2023 and Things we learned about LLMs in 2024.
[... 8,273 words]Codex cloud is now called Codex web. It looks like OpenAI's Codex cloud (the cloud version of their Codex coding agent) was quietly rebranded to Codex web at some point in the last few days.
Here's a screenshot of the Internet Archive copy from 18th December (the capture on the 28th maintains that Codex cloud title but did not fully load CSS for me):
And here's that same page today with the updated product name:
Anthropic's equivalent product has the incredibly clumsy name Claude Code on the web, which I shorten to "Claude Code for web" but even then bugs me because I mostly interact with it via Anthropic's native mobile app.
I was hoping to see Claude Code for web rebrand to Claude Code Cloud - I did not expect OpenAI to rebrand in the opposite direction!
Update: Clarification from OpenAI Codex engineering lead Thibault Sottiaux:
Just aligning the documentation with how folks refer to it. I personally differentiate between cloud tasks and codex web. With cloud tasks running on our hosted runtime (includes code review, github, slack, linear, ...) and codex web being the web app.
I asked what they called Codex in the iPhone app and he said:
Codex iOS
Introducing GPT-5.2-Codex. The latest in OpenAI's Codex family of models (not the same thing as their Codex CLI or Codex Cloud coding agent tools).
GPT‑5.2-Codex is a version of GPT‑5.2 further optimized for agentic coding in Codex, including improvements on long-horizon work through context compaction, stronger performance on large code changes like refactors and migrations, improved performance in Windows environments, and significantly stronger cybersecurity capabilities.
As with some previous Codex models this one is available via their Codex coding agents now and will be coming to the API "in the coming weeks". Unlike previous models there's a new invite-only preview process for vetted cybersecurity professionals for "more permissive models".
I've been very impressed recently with GPT 5.2's ability to tackle multi-hour agentic coding challenges. 5.2 Codex scores 64% on the Terminal-Bench 2.0 benchmark that GPT-5.2 scored 62.2% on. I'm not sure how concrete that 1.8% improvement will be!
I didn't hack API access together this time (see previous attempts), instead opting to just ask Codex CLI to "Generate an SVG of a pelican riding a bicycle" while running the new model (effort medium). Here's the transcript in my new Codex CLI timeline viewer, and here's the pelican it drew:

The new ChatGPT Images is here. OpenAI shipped an update to their ChatGPT Images feature - the feature that gained them 100 million new users in a week when they first launched it back in March, but has since been eclipsed by Google's Nano Banana and then further by Nana Banana Pro in November.
The focus for the new ChatGPT Images is speed and instruction following:
It makes precise edits while keeping details intact, and generates images up to 4x faster
It's also a little cheaper: OpenAI say that the new gpt-image-1.5 API model makes image input and output "20% cheaper in GPT Image 1.5 as compared to GPT Image 1".
I tried a new test prompt against a photo I took of Natalie's ceramic stand at the farmers market a few weeks ago:
Add two kakapos inspecting the pots

Here's the result from the new ChatGPT Images model:

And here's what I got from Nano Banana Pro:

The ChatGPT Kākāpō are a little chonkier, which I think counts as a win.
I was a little less impressed by the result I got for an infographic from the prompt "Infographic explaining how the Datasette open source project works" followed by "Run some extensive searches and gather a bunch of relevant information and then try again" (transcript):

See my Nano Banana Pro post for comparison.
Both models are clearly now usable for text-heavy graphics though, which makes them far more useful than previous generations of this technology.
Update 21st December 2025: I realized I already have a tool for accessing this new model via the API. Here's what I got from the following:
OPENAI_API_KEY="$(llm keys get openai)" \
uv run openai_image.py -m gpt-image-1.5\
'a raccoon with a double bass in a jazz bar rocking out'

Total cost: $0.2041.
How to use a skill (progressive disclosure):
- After deciding to use a skill, open its
SKILL.md. Read only enough to follow the workflow.- If
SKILL.mdpoints to extra folders such asreferences/, load only the specific files needed for the request; don't bulk-load everything.- If
scripts/exist, prefer running or patching them instead of retyping large code blocks.- If
assets/or templates exist, reuse them instead of recreating from scratch.Description as trigger: The YAML
descriptioninSKILL.mdis the primary trigger signal; rely on it to decide applicability. If unsure, ask a brief clarification before proceeding.
— OpenAI Codex CLI, core/src/skills/render.rs, full prompt
OpenAI are quietly adopting skills, now available in ChatGPT and Codex CLI
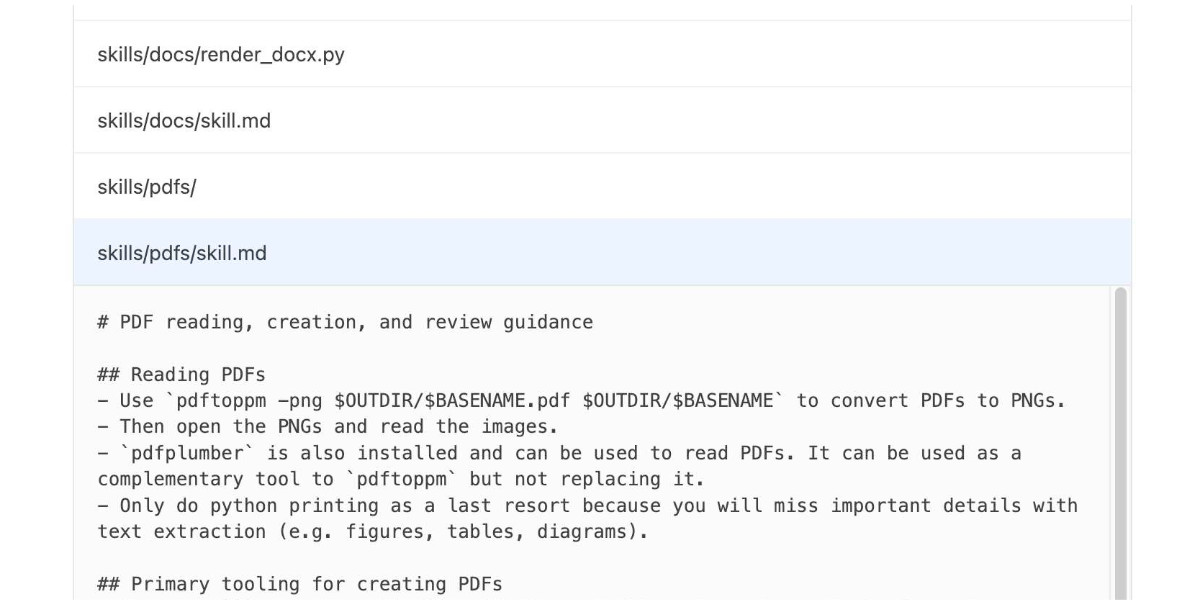
One of the things that most excited me about Anthropic’s new Skills mechanism back in October is how easy it looked for other platforms to implement. A skill is just a folder with a Markdown file and some optional extra resources and scripts, so any LLM tool with the ability to navigate and read from a filesystem should be capable of using them. It turns out OpenAI are doing exactly that, with skills support quietly showing up in both their Codex CLI tool and now also in ChatGPT itself.
[... 1,360 words]