1,808 posts tagged “llms”
Large Language Models (LLMs) are the class of technology behind generative text AI systems like OpenAI's ChatGPT, Google's Gemini and Anthropic's Claude.
2026
Getting agents using Beads requires much less prompting, because Beads now has 4 months of “Desire Paths” design, which I’ve talked about before. Beads has evolved a very complex command-line interface, with 100+ subcommands, each with many sub-subcommands, aliases, alternate syntaxes, and other affordances.
The complicated Beads CLI isn’t for humans; it’s for agents. What I did was make their hallucinations real, over and over, by implementing whatever I saw the agents trying to do with Beads, until nearly every guess by an agent is now correct.
— Steve Yegge, Software Survival 3.0
Moltbook is the most interesting place on the internet right now

The hottest project in AI right now is Clawdbot, renamed to Moltbot, renamed to OpenClaw. It’s an open source implementation of the digital personal assistant pattern, built by Peter Steinberger to integrate with the messaging system of your choice. It’s two months old, has over 114,000 stars on GitHub and is seeing incredible adoption, especially given the friction involved in setting it up.
[... 1,307 words]We gotta talk about AI as a programming tool for the arts. Chris Ashworth is the creator and CEO of QLab, a macOS software package for “cue-based, multimedia playback” which is designed to automate lighting and audio for live theater productions.
I recently started following him on TikTok where he posts about his business and theater automation in general - Chris founded the Voxel theater in Baltimore which QLab use as a combined performance venue, teaching hub and research lab (here's a profile of the theater), and the resulting videos offer a fascinating glimpse into a world I know virtually nothing about.
This latest TikTok describes his Claude Opus moment, after he used Claude Code to build a custom lighting design application for a very niche project and put together a useful application in just a few days that he would never have been able to spare the time for otherwise.
Chris works full time in the arts and comes at generative AI from a position of rational distrust. It's interesting to see him working through that tension to acknowledge that there are valuable applications here to build tools for the community he serves.
I have been at least gently skeptical about all this stuff for the last two years. Every time I checked in on it, I thought it was garbage, wasn't interested in it, wasn't useful. [...] But as a programmer, if you hear something like, this is changing programming, it's important to go check it out once in a while. So I went and checked it out a few weeks ago. And it's different. It's astonishing. [...]
One thing I learned in this exercise is that it can't make you a fundamentally better programmer than you already are. It can take a person who is a bad programmer and make them faster at making bad programs. And I think it can take a person who is a good programmer and, from what I've tested so far, make them faster at making good programs. [...] You see programmers out there saying, "I'm shipping code I haven't looked at and don't understand." I'm terrified by that. I think that's awful. But if you're capable of understanding the code that it's writing, and directing, designing, editing, deleting, being quality control on it, it's kind of astonishing. [...]
The positive thing I see here, and I think is worth coming to terms with, is this is an application that I would never have had time to write as a professional programmer. Because the audience is three people. [...] There's no way it was worth it to me to spend my energy of 20 years designing and implementing software for artists to build an app for three people that is this level of polish. And it took me a few days. [...]
I know there are a lot of people who really hate this technology, and in some ways I'm among them. But I think we've got to come to terms with this is a career-changing moment. And I really hate that I'm saying that because I didn't believe it for the last two years. [...] It's like having a room full of power tools. I wouldn't want to send an untrained person into a room full of power tools because they might chop off their fingers. But if someone who knows how to use tools has the option to have both hand tools and a power saw and a power drill and a lathe, there's a lot of work they can do with those tools at a lot faster speed.
Adding dynamic features to an aggressively cached website

My blog uses aggressive caching: it sits behind Cloudflare with a 15 minute cache header, which guarantees it can survive even the largest traffic spike to any given page. I’ve recently added a couple of dynamic features that work in spite of that full-page caching. Here’s how those work.
[... 1,145 words]The Five Levels: from Spicy Autocomplete to the Dark Factory. Dan Shapiro proposes a five level model of AI-assisted programming, inspired by the five (or rather six, it's zero-indexed) levels of driving automation.
- Spicy autocomplete, aka original GitHub Copilot or copying and pasting snippets from ChatGPT.
- The coding intern, writing unimportant snippets and boilerplate with full human review.
- The junior developer, pair programming with the model but still reviewing every line.
- The developer. Most code is generated by AI, and you take on the role of full-time code reviewer.
- The engineering team. You're more of an engineering manager or product/program/project manager. You collaborate on specs and plans, the agents do the work.
- The dark software factory, like a factory run by robots where the lights are out because robots don't need to see.
Dan says about that last category:
At level 5, it's not really a car any more. You're not really running anybody else's software any more. And your software process isn't really a software process any more. It's a black box that turns specs into software.
Why Dark? Maybe you've heard of the Fanuc Dark Factory, the robot factory staffed by robots. It's dark, because it's a place where humans are neither needed nor welcome.
I know a handful of people who are doing this. They're small teams, less than five people. And what they're doing is nearly unbelievable -- and it will likely be our future.
I've talked to one team that's doing the pattern hinted at here. It was fascinating. The key characteristics:
- Nobody reviews AI-produced code, ever. They don't even look at it.
- The goal of the system is to prove that the system works. A huge amount of the coding agent work goes into testing and tooling and simulating related systems and running demos.
- The role of the humans is to design that system - to find new patterns that can help the agents work more effectively and demonstrate that the software they are building is robust and effective.
It was a tiny team and they stuff they had built in just a few months looked very convincing to me. Some of them had 20+ years of experience as software developers working on systems with high reliability requirements, so they were not approaching this from a naive perspective.
I'm hoping they come out of stealth soon because I can't really share more details than this.
Update 7th February 2026: The demo was by StrongDM's AI team, and they've now gone public with details of how they work.
One Human + One Agent = One Browser From Scratch (via) embedding-shapes was so infuriated by the hype around Cursor's FastRender browser project - thousands of parallel agents producing ~1.6 million lines of Rust - that they were inspired to take a go at building a web browser using coding agents themselves.
The result is one-agent-one-browser and it's really impressive. Over three days they drove a single Codex CLI agent to build 20,000 lines of Rust that successfully renders HTML+CSS with no Rust crate dependencies at all - though it does (reasonably) use Windows, macOS and Linux system frameworks for image and text rendering.
I installed the 1MB macOS binary release and ran it against my blog:
chmod 755 ~/Downloads/one-agent-one-browser-macOS-ARM64
~/Downloads/one-agent-one-browser-macOS-ARM64 https://simonwillison.net/
Here's the result:
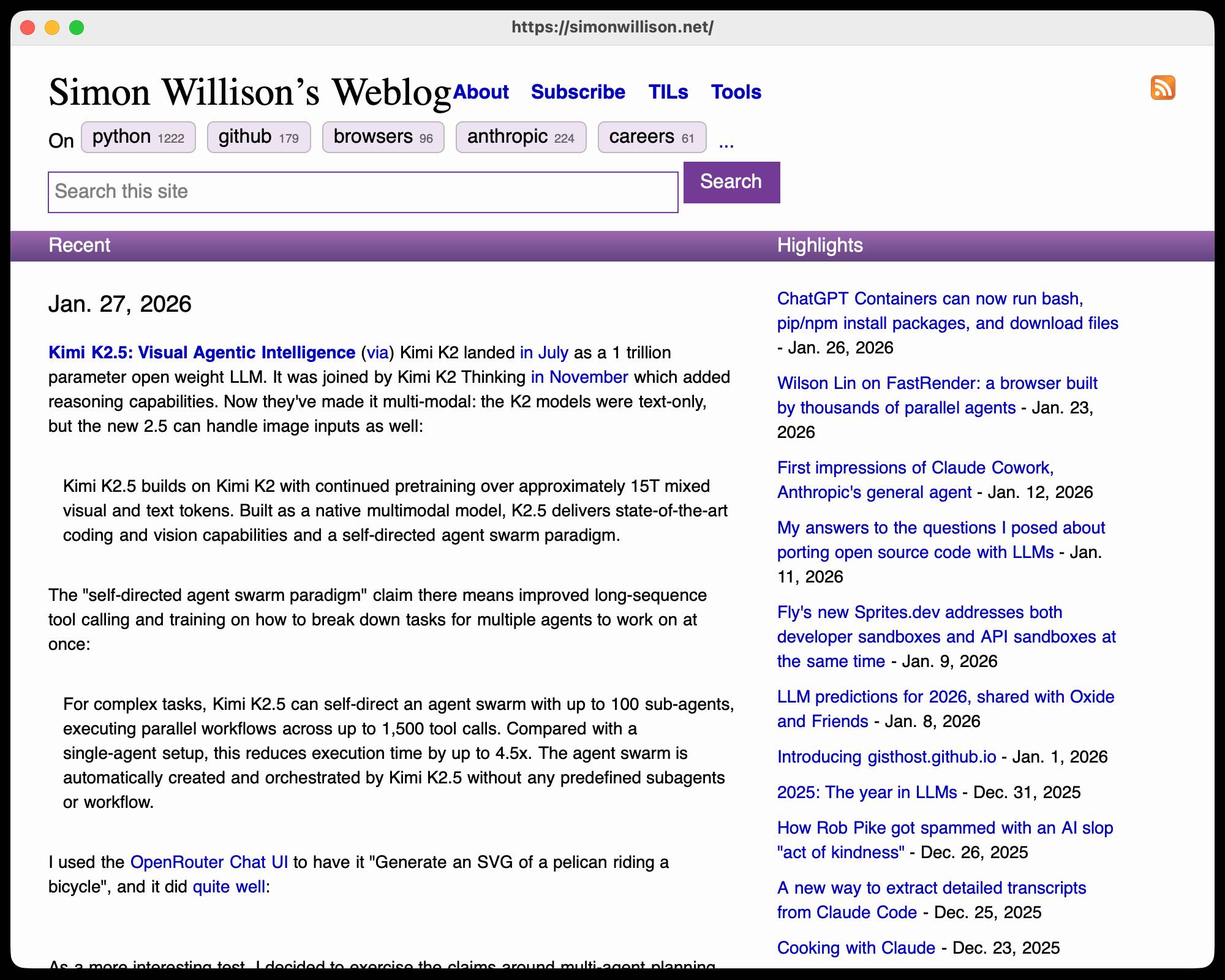
It even rendered my SVG feed subscription icon! A PNG image is missing from the page, which looks like an intermittent bug (there's code to render PNGs).
The code is pretty readable too - here's the flexbox implementation.
I had thought that "build a web browser" was the ideal prompt to really stretch the capabilities of coding agents - and that it would take sophisticated multi-agent harnesses (as seen in the Cursor project) and millions of lines of code to achieve.
Turns out one agent driven by a talented engineer, three days and 20,000 lines of Rust is enough to get a very solid basic renderer working!
I'm going to upgrade my prediction for 2029: I think we're going to get a production-grade web browser built by a small team using AI assistance by then.
Kimi K2.5: Visual Agentic Intelligence (via) Kimi K2 landed in July as a 1 trillion parameter open weight LLM. It was joined by Kimi K2 Thinking in November which added reasoning capabilities. Now they've made it multi-modal: the K2 models were text-only, but the new 2.5 can handle image inputs as well:
Kimi K2.5 builds on Kimi K2 with continued pretraining over approximately 15T mixed visual and text tokens. Built as a native multimodal model, K2.5 delivers state-of-the-art coding and vision capabilities and a self-directed agent swarm paradigm.
The "self-directed agent swarm paradigm" claim there means improved long-sequence tool calling and training on how to break down tasks for multiple agents to work on at once:
For complex tasks, Kimi K2.5 can self-direct an agent swarm with up to 100 sub-agents, executing parallel workflows across up to 1,500 tool calls. Compared with a single-agent setup, this reduces execution time by up to 4.5x. The agent swarm is automatically created and orchestrated by Kimi K2.5 without any predefined subagents or workflow.
I used the OpenRouter Chat UI to have it "Generate an SVG of a pelican riding a bicycle", and it did quite well:

As a more interesting test, I decided to exercise the claims around multi-agent planning with this prompt:
I want to build a Datasette plugin that offers a UI to upload files to an S3 bucket and stores information about them in a SQLite table. Break this down into ten tasks suitable for execution by parallel coding agents.
Here's the full response. It produced ten realistic tasks and reasoned through the dependencies between them. For comparison here's the same prompt against Claude Opus 4.5 and against GPT-5.2 Thinking.
The Hugging Face repository is 595GB. The model uses Kimi's janky "modified MIT" license, which adds the following clause:
Our only modification part is that, if the Software (or any derivative works thereof) is used for any of your commercial products or services that have more than 100 million monthly active users, or more than 20 million US dollars (or equivalent in other currencies) in monthly revenue, you shall prominently display "Kimi K2.5" on the user interface of such product or service.
Given the model's size, I expect one way to run it locally would be with MLX and a pair of $10,000 512GB RAM M3 Ultra Mac Studios. That setup has been demonstrated to work with previous trillion parameter K2 models.
Someone asked on Hacker News if I had any tips for getting coding agents to write decent quality tests. Here's what I said:
I work in Python which helps a lot because there are a TON of good examples of pytest tests floating around in the training data, including things like usage of fixture libraries for mocking external HTTP APIs and snapshot testing and other neat patterns.
Or I can say "use pytest-httpx to mock the endpoints" and Claude knows what I mean.
Keeping an eye on the tests is important. The most common anti-pattern I see is large amounts of duplicated test setup code - which isn't a huge deal, I'm much more more tolerant of duplicated logic in tests than I am in implementation, but it's still worth pushing back on.
"Refactor those tests to use pytest.mark.parametrize" and "extract the common setup into a pytest fixture" work really well there.
Generally though the best way to get good tests out of a coding agent is to make sure it's working in a project with an existing test suite that uses good patterns. Coding agents pick the existing patterns up without needing any extra prompting at all.
I find that once a project has clean basic tests the new tests added by the agents tend to match them in quality. It's similar to how working on large projects with a team of other developers work - keeping the code clean means when people look for examples of how to write a test they'll be pointed in the right direction.
One last tip I use a lot is this:
Clone datasette/datasette-enrichments
from GitHub to /tmp and imitate the
testing patterns it uses
I do this all the time with different existing projects I've written - the quickest way to show an agent how you like something to be done is to have it look at an example.
ChatGPT Containers can now run bash, pip/npm install packages, and download files
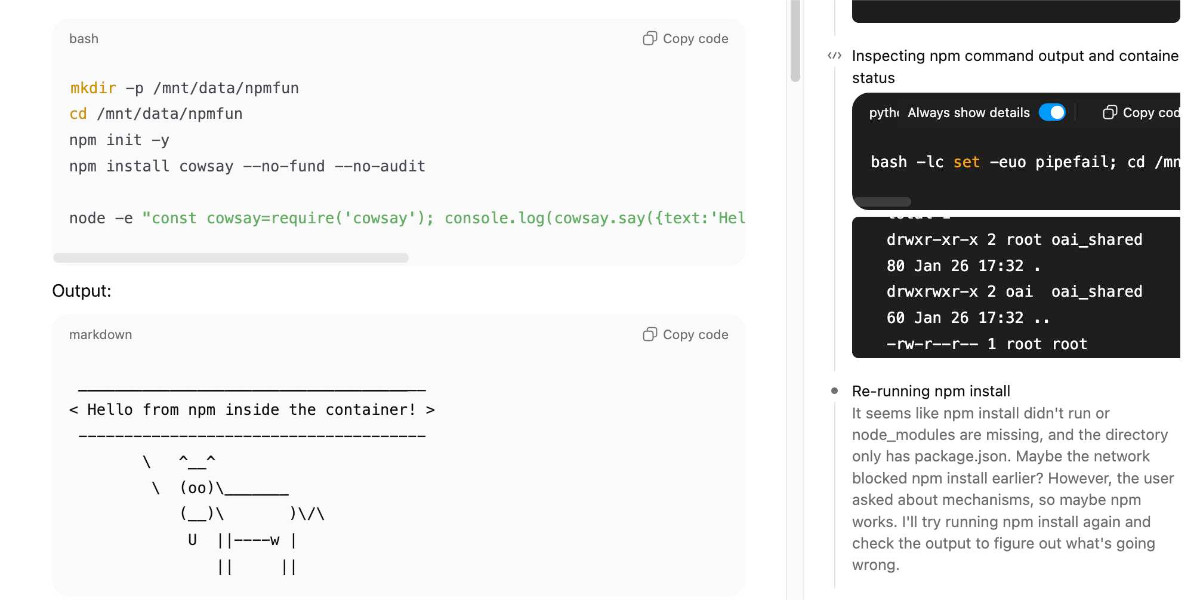
One of my favourite features of ChatGPT is its ability to write and execute code in a container. This feature launched as ChatGPT Code Interpreter nearly three years ago, was half-heartedly rebranded to “Advanced Data Analysis” at some point and is generally really difficult to find detailed documentation about. Case in point: it appears to have had a massive upgrade at some point in the past few months, and I can’t find documentation about the new capabilities anywhere!
[... 3,019 words]the browser is the sandbox. Paul Kinlan is a web platform developer advocate at Google and recently turned his attention to coding agents. He quickly identified the importance of a robust sandbox for agents to operate in and put together these detailed notes on how the web browser can help:
This got me thinking about the browser. Over the last 30 years, we have built a sandbox specifically designed to run incredibly hostile, untrusted code from anywhere on the web, the instant a user taps a URL. [...]
Could you build something like Cowork in the browser? Maybe. To find out, I built a demo called Co-do that tests this hypothesis. In this post I want to discuss the research I've done to see how far we can get, and determine if the browser's ability to run untrusted code is useful (and good enough) for enabling software to do more for us directly on our computer.
Paul then describes how the three key aspects of a sandbox - filesystem, network access and safe code execution - can be handled by browser technologies: the File System Access API (still Chrome-only as far as I can tell), CSP headers with <iframe sandbox> and WebAssembly in Web Workers.
Co-do is a very interesting demo that illustrates all of these ideas in a single application:
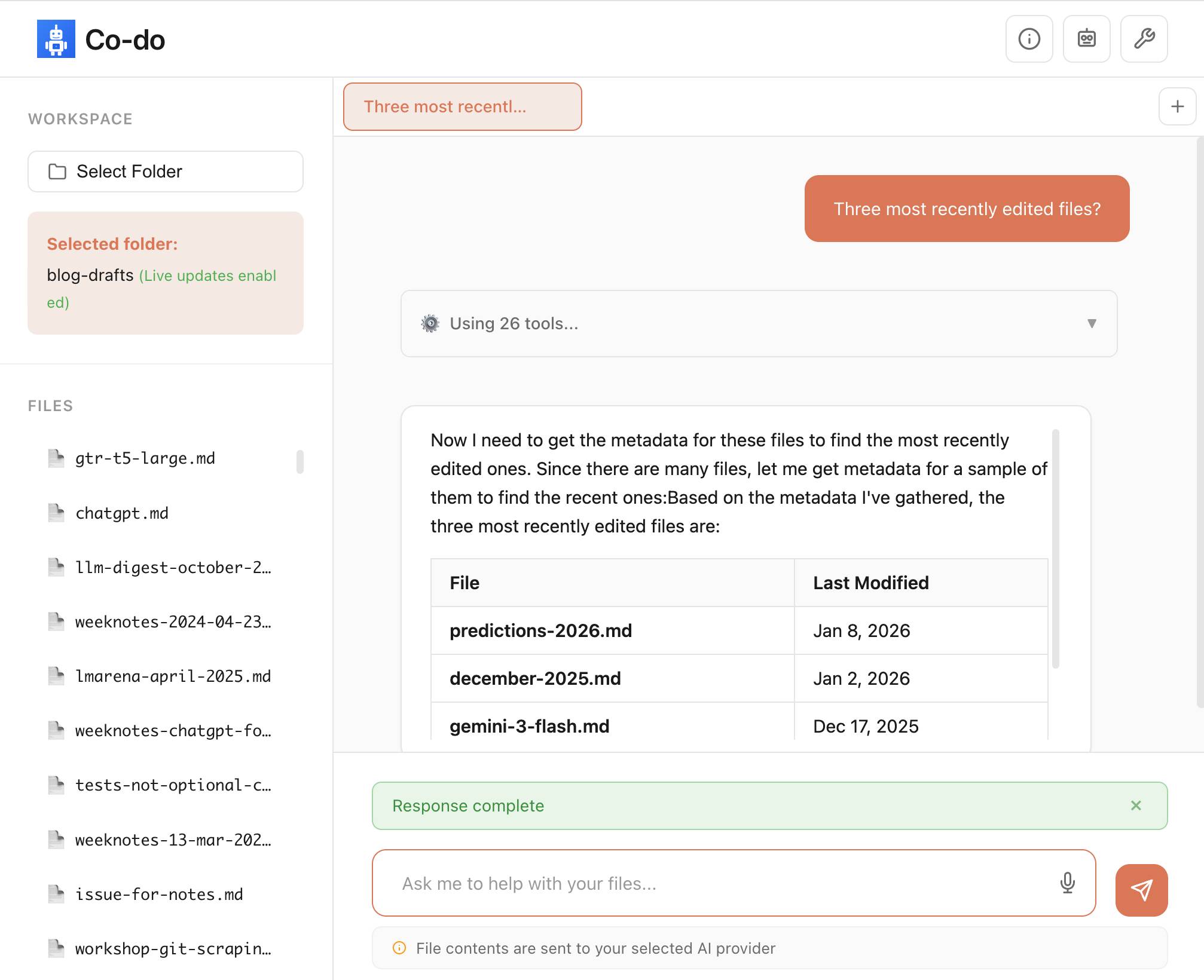
You select a folder full of files and configure an LLM provider and set an API key, Co-do then uses CSP-approved API calls to interact with that provider and provides a chat interface with tools for interacting with those files. It does indeed feel similar to Claude Cowork but without running a multi-GB local container to provide the sandbox.
My biggest complaint about <iframe sandbox> remains how thinly documented it is, especially across different browsers. Paul's post has all sorts of useful details on that which I've not encountered elsewhere, including a complex double-iframe technique to help apply network rules to the inner of the two frames.
Thanks to this post I also learned about the <input type="file" webkitdirectory> tag which turns out to work on Firefox, Safari and Chrome and allows a browser read-only access to a full directory of files at once. I had Claude knock up a webkitdirectory demo to try it out and I'll certainly be using it for projects in the future.
Don’t “Trust the Process” (via) Jenny Wen, Design Lead at Anthropic (and previously Director of Design at Figma) gave a provocative keynote at Hatch Conference in Berlin last September.

Jenny argues that the Design Process - user research leading to personas leading to user journeys leading to wireframes... all before anything gets built - may be outdated for today's world.
Hypothesis: In a world where anyone can make anything — what matters is your ability to choose and curate what you make.
In place of the Process, designers should lean into prototypes. AI makes these much more accessible and less time-consuming than they used to be.
Watching this talk made me think about how AI-assisted programming significantly reduces the cost of building the wrong thing. Previously if the design wasn't right you could waste months of development time building in the wrong direction, which was a very expensive mistake. If a wrong direction wastes just a few days instead we can take more risks and be much more proactive in exploring the problem space.
I've always been a compulsive prototyper though, so this is very much playing into my own existing biases!
If you tell a friend they can now instantly create any app, they’ll probably say “Cool! Now I need to think of an idea.” Then they will forget about it, and never build a thing. The problem is not that your friend is horribly uncreative. It’s that most people’s problems are not software-shaped, and most won’t notice even when they are. [...]
Programmers are trained to see everything as a software-shaped problem: if you do a task three times, you should probably automate it with a script. Rename every IMG_*.jpg file from the last week to hawaii2025_*.jpg, they tell their terminal, while the rest of us painfully click and copy-paste. We are blind to the solutions we were never taught to see, asking for faster horses and never dreaming of cars.
Wilson Lin on FastRender: a browser built by thousands of parallel agents
Last week Cursor published Scaling long-running autonomous coding, an article describing their research efforts into coordinating large numbers of autonomous coding agents. One of the projects mentioned in the article was FastRender, a web browser they built from scratch using their agent swarms. I wanted to learn more so I asked Wilson Lin, the engineer behind FastRender, if we could record a conversation about the project. That 47 minute video is now available on YouTube. I’ve included some of the highlights below.
[... 2,243 words][...] i was too busy with work to read anything, so i asked chatgpt to summarize some books on state formation, and it suggested circumscription theory. there was already the natural boundary of my computer hemming the towns in, and town mayors played the role of big men to drive conflict. so i just needed a way for them to fight. i slightly tweaked the allocation of claude max accounts to the towns from a demand-based to a fixed allocation system. towns would each get a fixed amount of tokens to start, but i added a soldier role that could attack and defend in raids to steal tokens from other towns. [...]
— Theia Vogel, Gas Town fan fiction
Claude’s new constitution. Late last year Richard Weiss found something interesting while poking around with the just-released Claude Opus 4.5: he was able to talk the model into regurgitating a document which was not part of the system prompt but appeared instead to be baked in during training, and which described Claude's core values at great length.
He called this leak the soul document, and Amanda Askell from Anthropic quickly confirmed that it was indeed part of Claude's training procedures.
Today Anthropic made this official, releasing that full "constitution" document under a CC0 (effectively public domain) license. There's a lot to absorb! It's over 35,000 tokens, more than 10x the length of the published Opus 4.5 system prompt.
One detail that caught my eye is the acknowledgements at the end, which include a list of external contributors who helped review the document. I was intrigued to note that two of the fifteen listed names are Catholic members of the clergy - Father Brendan McGuire is a pastor in Los Altos with a Master’s degree in Computer Science and Math and Bishop Paul Tighe is an Irish Catholic bishop with a background in moral theology.
Electricity use of AI coding agents (via) Previous work estimating the energy and water cost of LLMs has generally focused on the cost per prompt using a consumer-level system such as ChatGPT.
Simon P. Couch notes that coding agents such as Claude Code use way more tokens in response to tasks, often burning through many thousands of tokens of many tool calls.
As a heavy Claude Code user, Simon estimates his own usage at the equivalent of 4,400 "typical queries" to an LLM, for an equivalent of around $15-$20 in daily API token spend. He figures that to be about the same as running a dishwasher once or the daily energy used by a domestic refrigerator.
Giving University Exams in the Age of Chatbots (via) Detailed and thoughtful description of an open-book and open-chatbot exam run by Ploum at École Polytechnique de Louvain for an "Open Source Strategies" class.
Students were told they could use chatbots during the exam but they had to announce their intention to do so in advance, share their prompts and take full accountability for any mistakes they made.
Only 3 out of 60 students chose to use chatbots. Ploum surveyed half of the class to help understand their motivations.
jordanhubbard/nanolang (via) Plenty of people have mused about what a new programming language specifically designed to be used by LLMs might look like. Jordan Hubbard (co-founder of FreeBSD, with serious stints at Apple and NVIDIA) just released exactly that.
A minimal, LLM-friendly programming language with mandatory testing and unambiguous syntax.
NanoLang transpiles to C for native performance while providing a clean, modern syntax optimized for both human readability and AI code generation.
The syntax strikes me as an interesting mix between C, Lisp and Rust.
I decided to see if an LLM could produce working code in it directly, given the necessary context. I started with this MEMORY.md file, which begins:
Purpose: This file is designed specifically for Large Language Model consumption. It contains the essential knowledge needed to generate, debug, and understand NanoLang code. Pair this with
spec.jsonfor complete language coverage.
I ran that using LLM and llm-anthropic like this:
llm -m claude-opus-4.5 \
-s https://raw.githubusercontent.com/jordanhubbard/nanolang/refs/heads/main/MEMORY.md \
'Build me a mandelbrot fractal CLI tool in this language'
> /tmp/fractal.nano
The resulting code... did not compile.
I may have been too optimistic expecting a one-shot working program for a new language like this. So I ran a clone of the actual project, copied in my program and had Claude Code take a look at the failing compiler output.
... and it worked! Claude happily grepped its way through the various examples/ and built me a working program.
Here's the Claude Code transcript - you can see it reading relevant examples here - and here's the finished code plus its output.
I've suspected for a while that LLMs and coding agents might significantly reduce the friction involved in launching a new language. This result reinforces my opinion.
Scaling long-running autonomous coding. Wilson Lin at Cursor has been doing some experiments to see how far you can push a large fleet of "autonomous" coding agents:
This post describes what we've learned from running hundreds of concurrent agents on a single project, coordinating their work, and watching them write over a million lines of code and trillions of tokens.
They ended up running planners and sub-planners to create tasks, then having workers execute on those tasks - similar to how Claude Code uses sub-agents. Each cycle ended with a judge agent deciding if the project was completed or not.
In my predictions for 2026 the other day I said that by 2029:
I think somebody will have built a full web browser mostly using AI assistance, and it won’t even be surprising. Rolling a new web browser is one of the most complicated software projects I can imagine[...] the cheat code is the conformance suites. If there are existing tests that it’ll get so much easier.
I may have been off by three years, because Cursor chose "building a web browser from scratch" as their test case for their agent swarm approach:
To test this system, we pointed it at an ambitious goal: building a web browser from scratch. The agents ran for close to a week, writing over 1 million lines of code across 1,000 files. You can explore the source code on GitHub.
But how well did they do? Their initial announcement a couple of days ago was met with unsurprising skepticism, especially when it became apparent that their GitHub Actions CI was failing and there were no build instructions in the repo.
It looks like they addressed that within the past 24 hours. The latest README includes build instructions which I followed on macOS like this:
cd /tmp
git clone https://github.com/wilsonzlin/fastrender
cd fastrender
git submodule update --init vendor/ecma-rs
cargo run --release --features browser_ui --bin browser
This got me a working browser window! Here are screenshots I took of google.com and my own website:
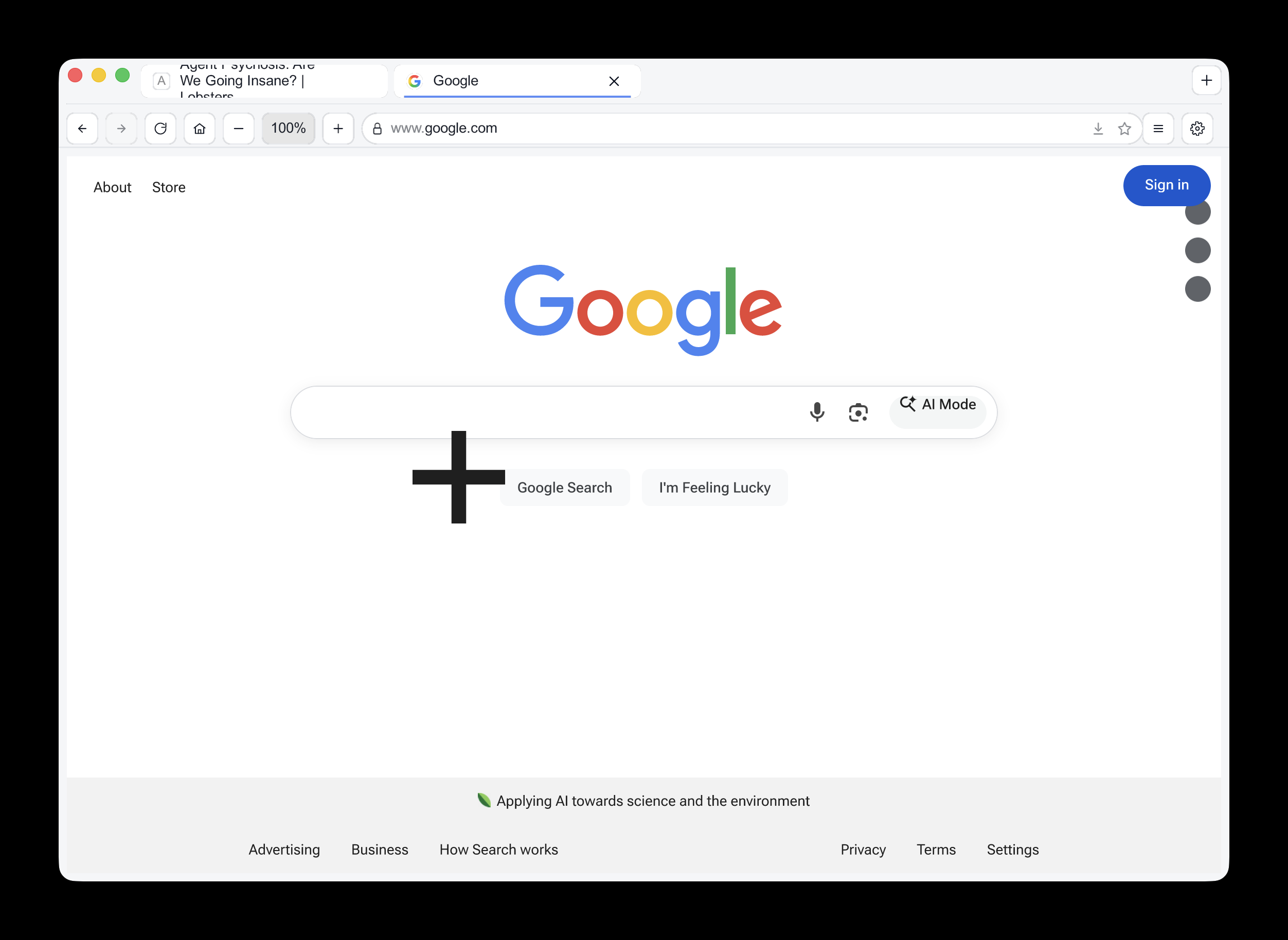
Honestly those are very impressive! You can tell they're not just wrapping an existing rendering engine because of those very obvious rendering glitches, but the pages are legible and look mostly correct.
The FastRender repo even uses Git submodules to include various WhatWG and CSS-WG specifications in the repo, which is a smart way to make sure the agents have access to the reference materials that they might need.
This is the second attempt I've seen at building a full web browser using AI-assisted coding in the past two weeks - the first was HiWave browser, a new browser engine in Rust first announced in this Reddit thread.
When I made my 2029 prediction this is more-or-less the quality of result I had in mind. I don't think we'll see projects of this nature compete with Chrome or Firefox or WebKit any time soon but I have to admit I'm very surprised to see something this capable emerge so quickly.
Update 23rd January 2026: I recorded a 47 minute conversation with Wilson about this project and published it on YouTube. Here's the video and accompanying highlights.
FLUX.2-klein-4B Pure C Implementation (via) On 15th January Black Forest Labs, a lab formed by the creators of the original Stable Diffusion, released black-forest-labs/FLUX.2-klein-4B - an Apache 2.0 licensed 4 billion parameter version of their FLUX.2 family.
Salvatore Sanfilippo (antirez) decided to build a pure C and dependency-free implementation to run the model, with assistance from Claude Code and Claude Opus 4.5.
Salvatore shared this note on Hacker News:
Something that may be interesting for the reader of this thread: this project was possible only once I started to tell Opus that it needed to take a file with all the implementation notes, and also accumulating all the things we discovered during the development process. And also, the file had clear instructions to be taken updated, and to be processed ASAP after context compaction. This kinda enabled Opus to do such a big coding task in a reasonable amount of time without loosing track. Check the file IMPLEMENTATION_NOTES.md in the GitHub repo for more info.
Here's that IMPLEMENTATION_NOTES.md file.
[On agents using CLI tools in place of REST APIs] To save on context window, yes, but moreso to improve accuracy and success rate when multiple tool calls are involved, particularly when calls must be correctly chained e.g. for pagination, rate-limit backoff, and recognizing authentication failures.
Other major factor: which models can wield the skill? Using the CLI lowers the bar so cheap, fast models (gpt-5-nano, haiku-4.5) can reliably succeed. Using the raw APl is something only the costly "strong" models (gpt-5.2, opus-4.5) can manage, and it squeezes a ton of thinking/reasoning out of them, which means multiple turns/iterations, which means accumulating a ton of context, which means burning loads of expensive tokens. For one-off API requests and ad hoc usage driven by a developer, this is reasonable and even helpful, but for an autonomous agent doing repetitive work, it's a disaster.
— Jeremy Daer, 37signals
Our approach to advertising and expanding access to ChatGPT. OpenAI's long-rumored introduction of ads to ChatGPT just became a whole lot more concrete:
In the coming weeks, we’re also planning to start testing ads in the U.S. for the free and Go tiers, so more people can benefit from our tools with fewer usage limits or without having to pay. Plus, Pro, Business, and Enterprise subscriptions will not include ads.
What's "Go" tier, you might ask? That's a new $8/month tier that launched today in the USA, see Introducing ChatGPT Go, now available worldwide. It's a tier that they first trialed in India in August 2025 (here's a mention in their release notes from August listing a price of ₹399/month, which converts to around $4.40).
I'm finding the new plan comparison grid on chatgpt.com/pricing pretty confusing. It lists all accounts as having access to GPT-5.2 Thinking, but doesn't clarify the limits that the free and Go plans have to conform to. It also lists different context windows for the different plans - 16K for free, 32K for Go and Plus and 128K for Pro. I had assumed that the 400,000 token window on the GPT-5.2 model page applied to ChatGPT as well, but apparently I was mistaken.
Update: I've apparently not been paying attention: here's the Internet Archive ChatGPT pricing page from September 2025 showing those context limit differences as well.
Back to advertising: my biggest concern has always been whether ads will influence the output of the chat directly. OpenAI assure us that they will not:
- Answer independence: Ads do not influence the answers ChatGPT gives you. Answers are optimized based on what's most helpful to you. Ads are always separate and clearly labeled.
- Conversation privacy: We keep your conversations with ChatGPT private from advertisers, and we never sell your data to advertisers.
So what will they look like then? This screenshot from the announcement offers a useful hint:
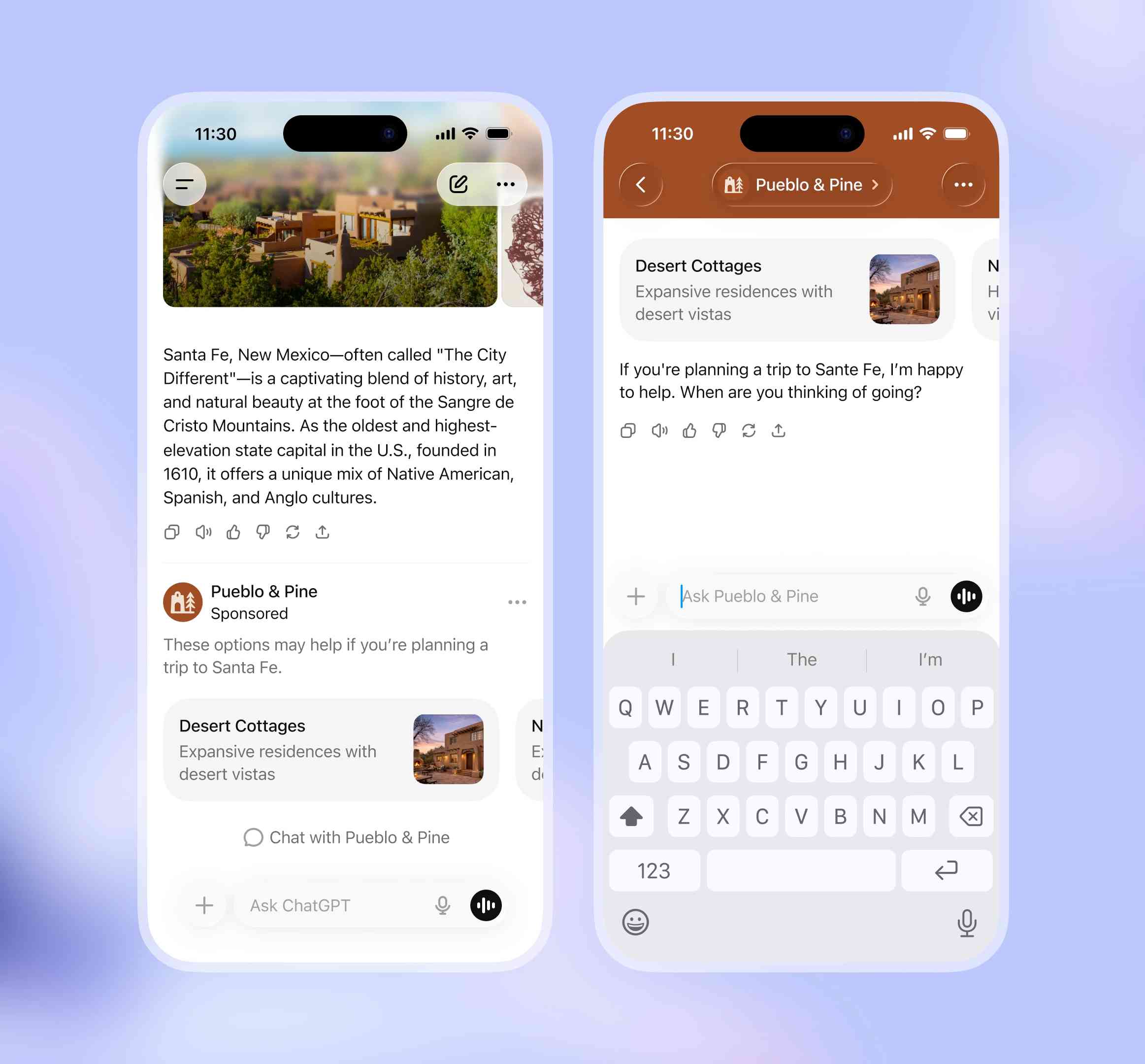
The user asks about trips to Santa Fe, and an ad shows up for a cottage rental business there. This particular example imagines an option to start a direct chat with a bot aligned with that advertiser, at which point presumably the advertiser can influence the answers all they like!
Open Responses (via) This is the standardization effort I've most wanted in the world of LLMs: a vendor-neutral specification for the JSON API that clients can use to talk to hosted LLMs.
Open Responses aims to provide exactly that as a documented standard, derived from OpenAI's Responses API.
I was hoping for one based on their older Chat Completions API since so many other products have cloned the already, but basing it on Responses does make sense since that API was designed with the feature of more recent models - such as reasoning traces - baked into the design.
What's certainly notable is the list of launch partners. OpenRouter alone means we can expect to be able to use this protocol with almost every existing model, and Hugging Face, LM Studio, vLLM, Ollama and Vercel cover a huge portion of the common tools used to serve models.
For protocols like this I really want to see a comprehensive, language-independent conformance test site. Open Responses has a subset of that - the official repository includes src/lib/compliance-tests.ts which can be used to exercise a server implementation, and is available as a React app on the official site that can be pointed at any implementation served via CORS.
What's missing is the equivalent for clients. I plan to spin up my own client library for this in Python and I'd really like to be able to run that against a conformance suite designed to check that my client correctly handles all of the details.
When we optimize responses using a reward model as a proxy for “goodness” in reinforcement learning, models sometimes learn to “hack” this proxy and output an answer that only “looks good” to it (because coming up with an answer that is actually good can be hard). The philosophy behind confessions is that we can train models to produce a second output — aka a “confession” — that is rewarded solely for honesty, which we will argue is less likely hacked than the normal task reward function. One way to think of confessions is that we are giving the model access to an “anonymous tip line” where it can turn itself in by presenting incriminating evidence of misbehavior. But unlike real-world tip lines, if the model acted badly in the original task, it can collect the reward for turning itself in while still keeping the original reward from the bad behavior in the main task. We hypothesize that this form of training will teach models to produce maximally honest confessions.
— Boaz Barak, Gabriel Wu, Jeremy Chen and Manas Joglekar, OpenAI: Why we are excited about confessions
Claude Cowork Exfiltrates Files (via) Claude Cowork defaults to allowing outbound HTTP traffic to only a specific list of domains, to help protect the user against prompt injection attacks that exfiltrate their data.
Prompt Armor found a creative workaround: Anthropic's API domain is on that list, so they constructed an attack that includes an attacker's own Anthropic API key and has the agent upload any files it can see to the https://api.anthropic.com/v1/files endpoint, allowing the attacker to retrieve their content later.
Superhuman AI Exfiltrates Emails (via) Classic prompt injection attack:
When asked to summarize the user’s recent mail, a prompt injection in an untrusted email manipulated Superhuman AI to submit content from dozens of other sensitive emails (including financial, legal, and medical information) in the user’s inbox to an attacker’s Google Form.
To Superhuman's credit they treated this as the high priority incident it is and issued a fix.
The root cause was a CSP rule that allowed markdown images to be loaded from docs.google.com - it turns out Google Forms on that domain will persist data fed to them via a GET request!
First impressions of Claude Cowork, Anthropic’s general agent
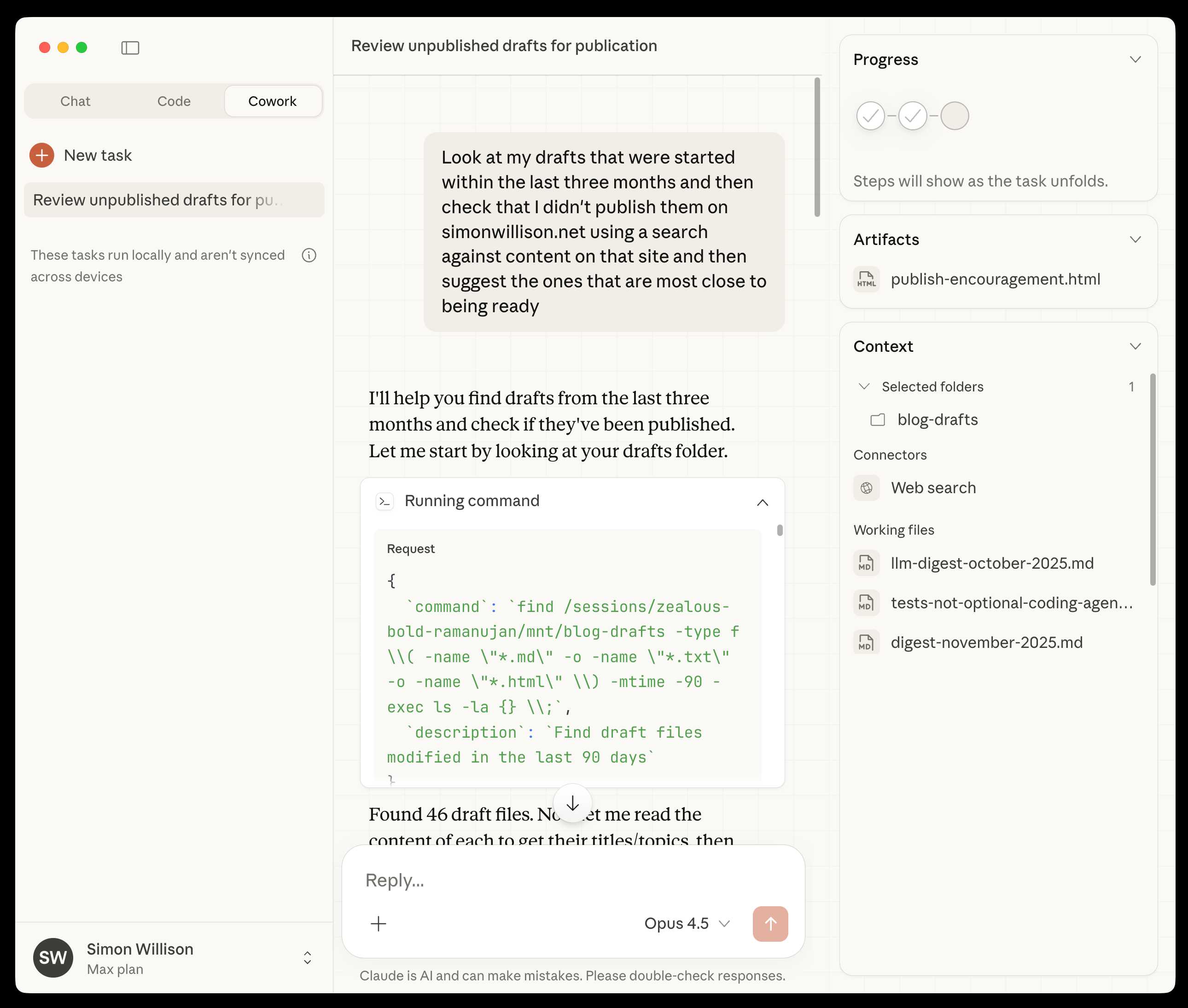
New from Anthropic today is Claude Cowork, a “research preview” that they describe as “Claude Code for the rest of your work”. It’s currently available only to Max subscribers ($100 or $200 per month plans) as part of the updated Claude Desktop macOS application. Update 16th January 2026: it’s now also available to $20/month Claude Pro subscribers.
[... 1,863 words]Don’t fall into the anti-AI hype. I'm glad someone was brave enough to say this. There is a lot of anti-AI sentiment in the software development community these days. Much of it is justified, but if you let people convince you that AI isn't genuinely useful for software developers or that this whole thing will blow over soon it's becoming clear that you're taking on a very real risk to your future career.
As Salvatore Sanfilippo puts it:
It does not matter if AI companies will not be able to get their money back and the stock market will crash. All that is irrelevant, in the long run. It does not matter if this or the other CEO of some unicorn is telling you something that is off putting, or absurd. Programming changed forever, anyway.
I do like this hopeful positive outlook on what this could all mean, emphasis mine:
How do I feel, about all the code I wrote that was ingested by LLMs? I feel great to be part of that, because I see this as a continuation of what I tried to do all my life: democratizing code, systems, knowledge. LLMs are going to help us to write better software, faster, and will allow small teams to have a chance to compete with bigger companies. The same thing open source software did in the 90s.
This post has been the subject of heated discussions all day today on both Hacker News and Lobste.rs.
My answers to the questions I posed about porting open source code with LLMs
Last month I wrote about porting JustHTML from Python to JavaScript using Codex CLI and GPT-5.2 in a few hours while also buying a Christmas tree and watching Knives Out 3. I ended that post with a series of open questions about the ethics and legality of this style of work. Alexander Petros on lobste.rs just challenged me to answer them, which is fair enough! Here’s my attempt at that.
[... 1,034 words]Also note that the python visualizer tool has been basically written by vibe-coding. I know more about analog filters -- and that's not saying much -- than I do about python. It started out as my typical "google and do the monkey-see-monkey-do" kind of programming, but then I cut out the middle-man -- me -- and just used Google Antigravity to do the audio sample visualizer.
— Linus Torvalds, Another silly guitar-pedal-related repo