37 posts tagged “git-scraping”
Git scraping is a technique where data is scraped from an external source into a Git repository in order to record changes to that data over time.
2025
simonw/actions-latest.
Today in extremely niche projects, I got fed up of Claude Code creating GitHub Actions workflows for me that used stale actions: actions/setup-python@v4 when the latest is actions/setup-python@v6 for example.
I couldn't find a good single place listing those latest versions, so I had Claude Code for web (via my phone, I'm out on errands) build a Git scraper to publish those versions in one place:
https://simonw.github.io/actions-latest/versions.txt
Tell your coding agent of choice to fetch that any time it wants to write a new GitHub Actions workflows.
(I may well bake this into a Skill.)
Here's the first and second transcript I used to build this, shared using my claude-code-transcripts tool (which just gained a search feature.)
uv-init-demos.
uv has a useful uv init command for setting up new Python projects, but it comes with a bunch of different options like --app and --package and --lib and I wasn't sure how they differed.
So I created this GitHub repository which demonstrates all of those options, generated using this update-projects.sh script (thanks, Claude) which will run on a schedule via GitHub Actions to capture any changes made by future releases of uv.
aavetis/PRarena. Albert Avetisian runs this repository on GitHub which uses the Github Search API to track the number of PRs that can be credited to a collection of different coding agents. The repo runs this collect_data.py script every three hours using GitHub Actions to collect the data, then updates the PR Arena site with a visual leaderboard.
The result is this neat chart showing adoption of different agents over time, along with their PR success rate:
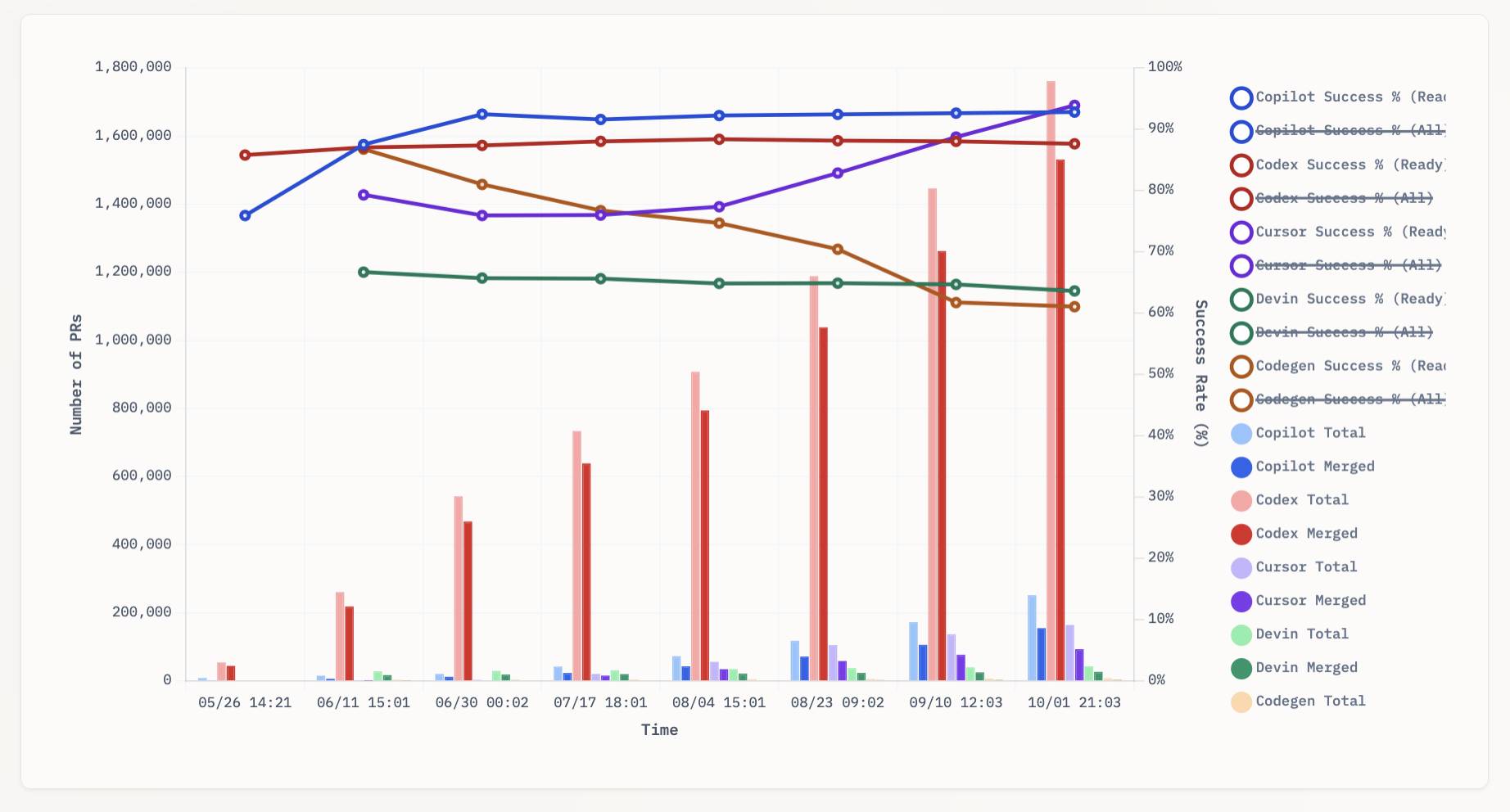
I found this today while trying to pull off the exact same trick myself! I got as far as creating the following table before finding Albert's work and abandoning my own project.
| Tool | Search term | Total PRs | Merged PRs | % merged | Earliest |
|---|---|---|---|---|---|
| Claude Code | is:pr in:body "Generated with Claude Code" |
146,000 | 123,000 | 84.2% | Feb 21st |
| GitHub Copilot | is:pr author:copilot-swe-agent[bot] |
247,000 | 152,000 | 61.5% | March 7th |
| Codex Cloud | is:pr in:body "chatgpt.com" label:codex |
1,900,000 | 1,600,000 | 84.2% | April 23rd |
| Google Jules | is:pr author:google-labs-jules[bot] |
35,400 | 27,800 | 78.5% | May 22nd |
(Those "earliest" links are a little questionable, I tried to filter out false positives and find the oldest one that appeared to really be from the agent in question.)
It looks like OpenAI's Codex Cloud is massively ahead of the competition right now in terms of numbers of PRs both opened and merged on GitHub.
Update: To clarify, these numbers are for the category of autonomous coding agents - those systems where you assign a cloud-based agent a task or issue and the output is a PR against your repository. They do not (and cannot) capture the popularity of many forms of AI tooling that don't result in an easily identifiable pull request.
Claude Code for example will be dramatically under-counted here because its version of an autonomous coding agent comes in the form of a somewhat obscure GitHub Actions workflow buried in the documentation.
simonw/ollama-models-atom-feed. I setup a GitHub Actions + GitHub Pages Atom feed of scraped recent models data from the Ollama latest models page - Ollama remains one of the easiest ways to run models on a laptop so a new model release from them is worth hearing about.
I built the scraper by pasting example HTML into Claude and asking for a Python script to convert it to Atom - here's the script we wrote together.
Update 25th March 2025: The first version of this included all 160+ models in a single feed. I've upgraded the script to output two feeds - the original atom.xml one and a new atom-recent-20.xml feed containing just the most recent 20 items.
I modified the script using Google's new Gemini 2.5 Pro model, like this:
cat to_atom.py | llm -m gemini-2.5-pro-exp-03-25 \
-s 'rewrite this script so that instead of outputting Atom to stdout it saves two files, one called atom.xml with everything and another called atom-recent-20.xml with just the most recent 20 items - remove the output option entirely'
Here's the full transcript.
Building and deploying a custom site using GitHub Actions and GitHub Pages. I figured out a minimal example of how to use GitHub Actions to run custom scripts to build a website and then publish that static site to GitHub Pages. I turned the example into a template repository, which should make getting started for a new project extremely quick.
I've needed this for various projects over the years, but today I finally put these notes together while setting up a system for scraping the iNaturalist API for recent sightings of the California Brown Pelican and converting those into an Atom feed that I can subscribe to in NetNewsWire:
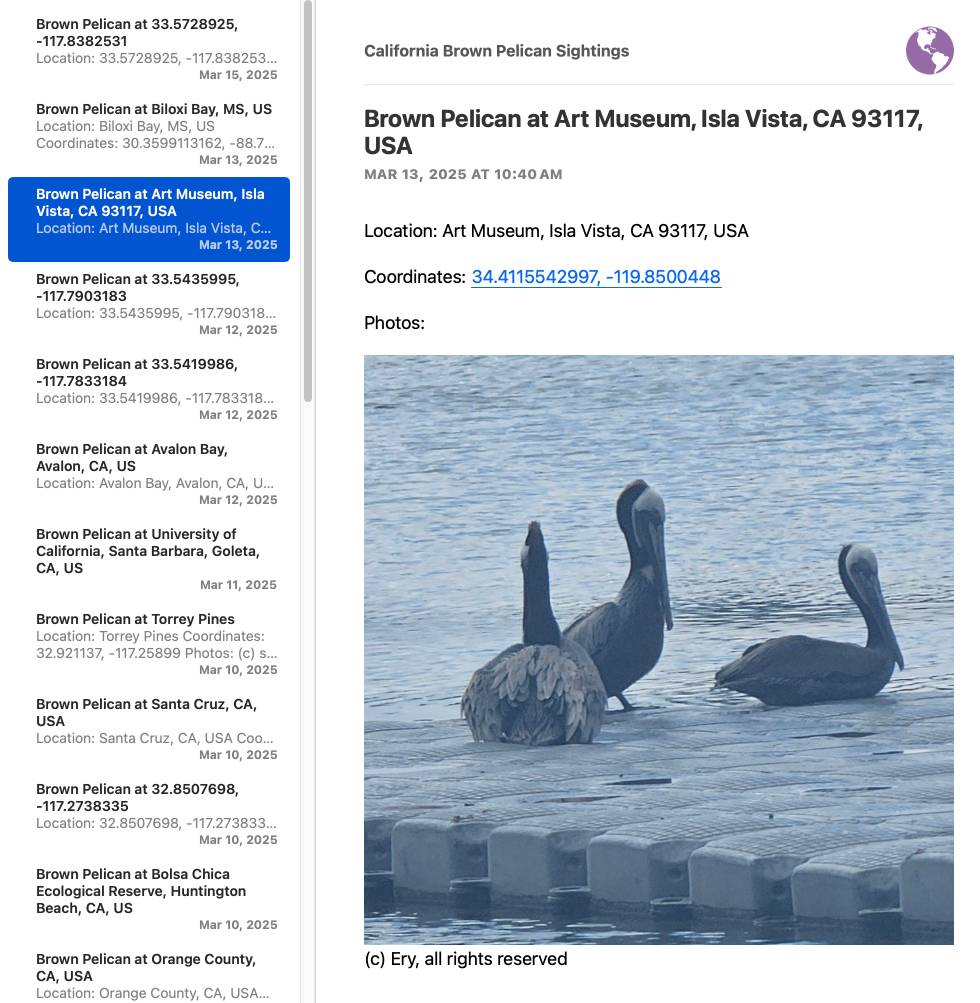
I got Claude to write me the script that converts the scraped JSON to atom.
Update: I just found out iNaturalist have their own atom feeds! Here's their own feed of recent Pelican observations.
Cutting-edge web scraping techniques at NICAR. Here's the handout for a workshop I presented this morning at NICAR 2025 on web scraping, focusing on lesser know tips and tricks that became possible only with recent developments in LLMs.
For workshops like this I like to work off an extremely detailed handout, so that people can move at their own pace or catch up later if they didn't get everything done.
The workshop consisted of four parts:
- Building a Git scraper - an automated scraper in GitHub Actions that records changes to a resource over time
- Using in-browser JavaScript and then shot-scraper to extract useful information
- Using LLM with both OpenAI and Google Gemini to extract structured data from unstructured websites
- Video scraping using Google AI Studio
I released several new tools in preparation for this workshop (I call this "NICAR Driven Development"):
- git-scraper-template template repository for quickly setting up new Git scrapers, which I wrote about here
- LLM schemas, finally adding structured schema support to my LLM tool
- shot-scraper har for archiving pages as HTML Archive files - though I cut this from the workshop for time
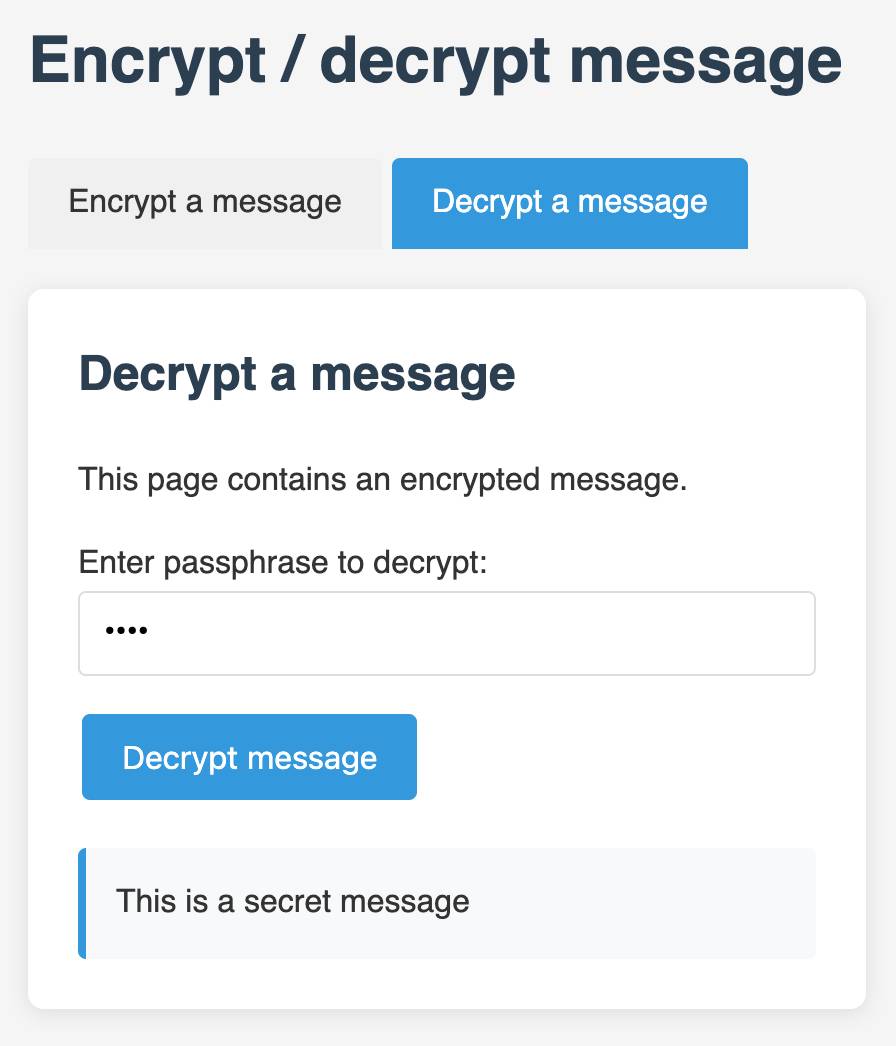
I also came up with a fun way to distribute API keys for workshop participants: I had Claude build me a web page where I can create an encrypted message with a passphrase, then share a URL to that page with users and give them the passphrase to unlock the encrypted message. You can try that at tools.simonwillison.net/encrypt - or use this link and enter the passphrase "demo":
simonw/git-scraper-template. I built this new GitHub template repository in preparation for a workshop I'm giving at NICAR (the data journalism conference) next week on Cutting-edge web scraping techniques.
One of the topics I'll be covering is Git scraping - creating a GitHub repository that uses scheduled GitHub Actions workflows to grab copies of websites and data feeds and store their changes over time using Git.
This template repository is designed to be the fastest possible way to get started with a new Git scraper: simple create a new repository from the template and paste the URL you want to scrape into the description field and the repository will be initialized with a custom script that scrapes and stores that URL.
It's modeled after my earlier shot-scraper-template tool which I described in detail in Instantly create a GitHub repository to take screenshots of a web page.
The new git-scraper-template repo took some help from Claude to figure out. It uses a custom script to download the provided URL and derive a filename to use based on the URL and the content type, detected using file --mime-type -b "$file_path" against the downloaded file.
It also detects if the downloaded content is JSON and, if it is, pretty-prints it using jq - I find this is a quick way to generate much more useful diffs when the content changes.
Using a Tailscale exit node with GitHub Actions. New TIL. I started running a git scraper against doge.gov to track changes made to that website over time. The DOGE site runs behind Cloudflare which was blocking requests from the GitHub Actions IP range, but I figured out how to run a Tailscale exit node on my Apple TV and use that to proxy my shot-scraper requests.
The scraper is running in simonw/scrape-doge-gov. It uses the new shot-scraper har command I added in shot-scraper 1.6 (and improved in shot-scraper 1.7).
2024
New improved commit messages for scrape-hacker-news-by-domain. My simonw/scrape-hacker-news-by-domain repo has a very specific purpose. Once an hour it scrapes the Hacker News /from?site=simonwillison.net page (and the equivalent for datasette.io) using my shot-scraper tool and stashes the parsed links, scores and comment counts in JSON files in that repo.
It does this mainly so I can subscribe to GitHub's Atom feed of the commit log - visit simonw/scrape-hacker-news-by-domain/commits/main and add .atom to the URL to get that.
NetNewsWire will inform me within about an hour if any of my content has made it to Hacker News, and the repo will track the score and comment count for me over time. I wrote more about how this works in Scraping web pages from the command line with shot-scraper back in March 2022.
Prior to the latest improvement, the commit messages themselves were pretty uninformative. The message had the date, and to actually see which Hacker News post it was referring to, I had to click through to the commit and look at the diff.
I built my csv-diff tool a while back to help address this problem: it can produce a slightly more human-readable version of a diff between two CSV or JSON files, ideally suited for including in a commit message attached to a git scraping repo like this one.
I got that working, but there was still room for improvement. I recently learned that any Hacker News thread has an undocumented URL at /latest?id=x which displays the most recently added comments at the top.
I wanted that in my commit messages, so I could quickly click a link to see the most recent comments on a thread.
So... I added one more feature to csv-diff: a new --extra option lets you specify a Python format string to be used to add extra fields to the displayed difference.
My GitHub Actions workflow now runs this command:
csv-diff simonwillison-net.json simonwillison-net-new.json \
--key id --format json \
--extra latest 'https://news.ycombinator.com/latest?id={id}' \
>> /tmp/commit.txt
This generates the diff between the two versions, using the id property in the JSON to tie records together. It adds a latest field linking to that URL.
The commits now look like this:

interactive-feed (via) Sam Morris maintains this project which gathers interactive, graphic and data visualization stories from various newsrooms around the world and publishes them on Twitter, Mastodon and Bluesky.
It runs automatically using GitHub Actions, and gathers data using a number of different techniques - XML feeds, custom API integrations (for the NYT, Guardian and Washington Post) and in some cases by scraping index pages on news websites using CSS selectors and cheerio.
The data it collects is archived as JSON in the data/ directory of the repository.
Figure out who’s leaving the company: dump, diff, repeat (via) Rachel Kroll describes a neat hack for companies with an internal LDAP server or similar machine-readable employee directory: run a cron somewhere internal that grabs the latest version and diffs it against the previous to figure out who has joined or left the company.
I suggest using Git for this - a form of Git scraping - as then you get a detailed commit log of changes over time effectively for free.
I really enjoyed Rachel's closing thought:
Incidentally, if someone gets mad about you running this sort of thing, you probably don't want to work there anyway. On the other hand, if you're able to build such tools without IT or similar getting "threatened" by it, then you might be somewhere that actually enjoys creating interesting and useful stuff. Treasure such places. They don't tend to last.
2022
Tracking Mastodon user numbers over time with a bucket of tricks
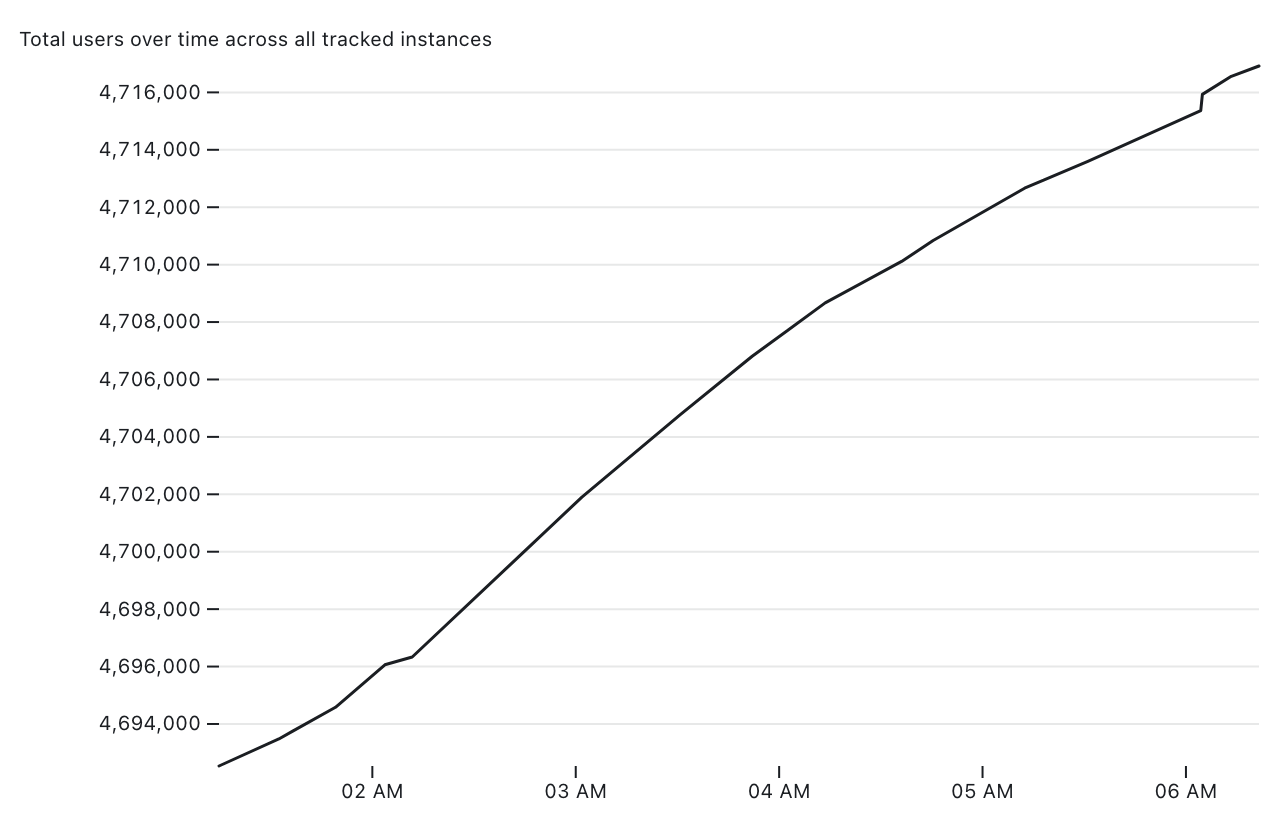
Mastodon is definitely having a moment. User growth is skyrocketing as more and more people migrate over from Twitter.
[... 1,534 words]Measuring traffic during the Half Moon Bay Pumpkin Festival
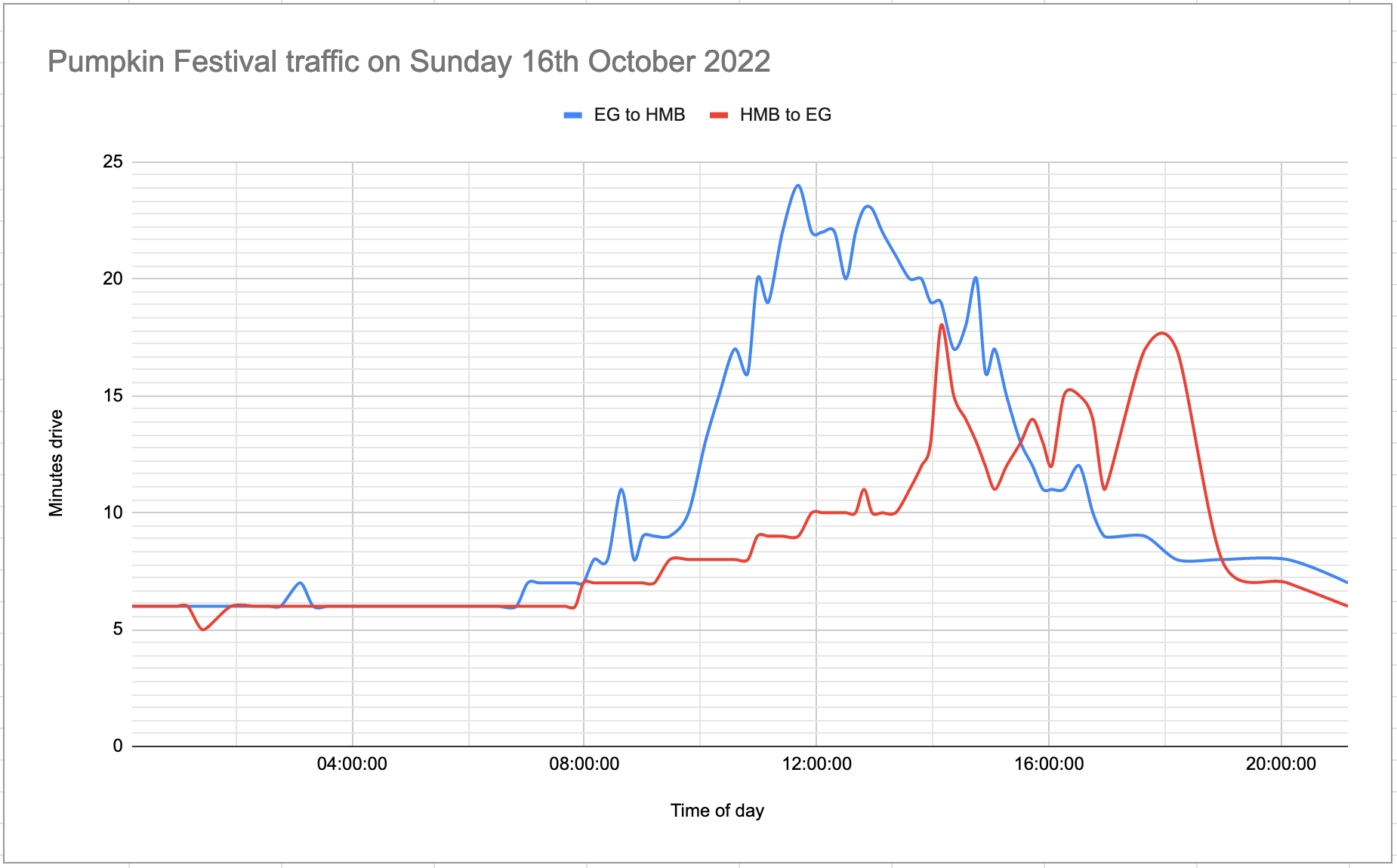
This weekend was the 50th annual Half Moon Bay Pumpkin Festival.
[... 2,693 words]Half Moon Bay Pumpkin Festival traffic on Saturday 15th October 2022 (via) It’s the Half Moon Bay Pumpkin Festival this weekend... and its impact on the traffic between our little town of El Granada and Half Moon Bay—8 minutes drive away—is notorious. So I built a git scraper that archives estimated driving times from the Google Maps Navigation API, and used git-history to turn that scraped data into a SQLite database and visualize it on a chart.
Automatically opening issues when tracked file content changes
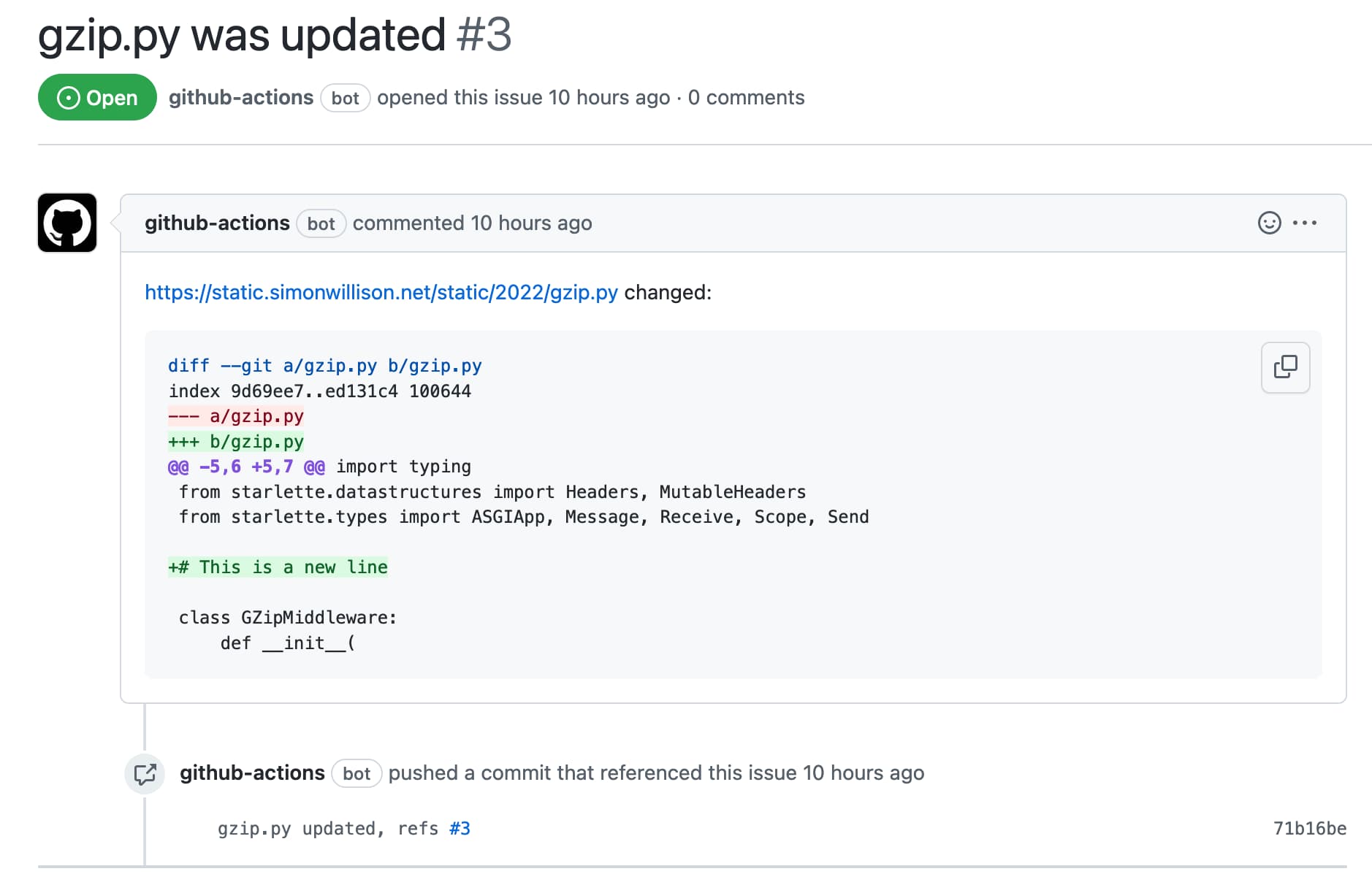
I figured out a GitHub Actions pattern to keep track of a file published somewhere on the internet and automatically open a new repository issue any time the contents of that file changes.
[... 1,211 words]Scraping web pages from the command line with shot-scraper
I’ve added a powerful new capability to my shot-scraper command line browser automation tool: you can now use it to load a web page in a headless browser, execute JavaScript to extract information and return that information back to the terminal as JSON.
[... 1,277 words]shot-scraper: automated screenshots for documentation, built on Playwright
shot-scraper is a new tool that I’ve built to help automate the process of keeping screenshots up-to-date in my documentation. It also doubles as a scraping tool—hence the name—which I picked as a complement to my git scraping and help scraping techniques.
[... 1,802 words]Help scraping: track changes to CLI tools by recording their --help using Git
I’ve been experimenting with a new variant of Git scraping this week which I’m calling Help scraping. The key idea is to track changes made to CLI tools over time by recording the output of their --help commands in a Git repository.
2021
Weeknotes: Shaving some beautiful yaks

I’ve been mostly shaving yaks this week—two in particular: the Datasette table refactor and the next release of git-history. I also built and released my first Web Component!
[... 1,307 words]Weeknotes: Apache proxies in Docker containers, refactoring Datasette
Updates to six major projects this week, plus finally some concrete progress towards Datasette 1.0.
[... 1,630 words]Weeknotes: git-history, created for a Git scraping workshop
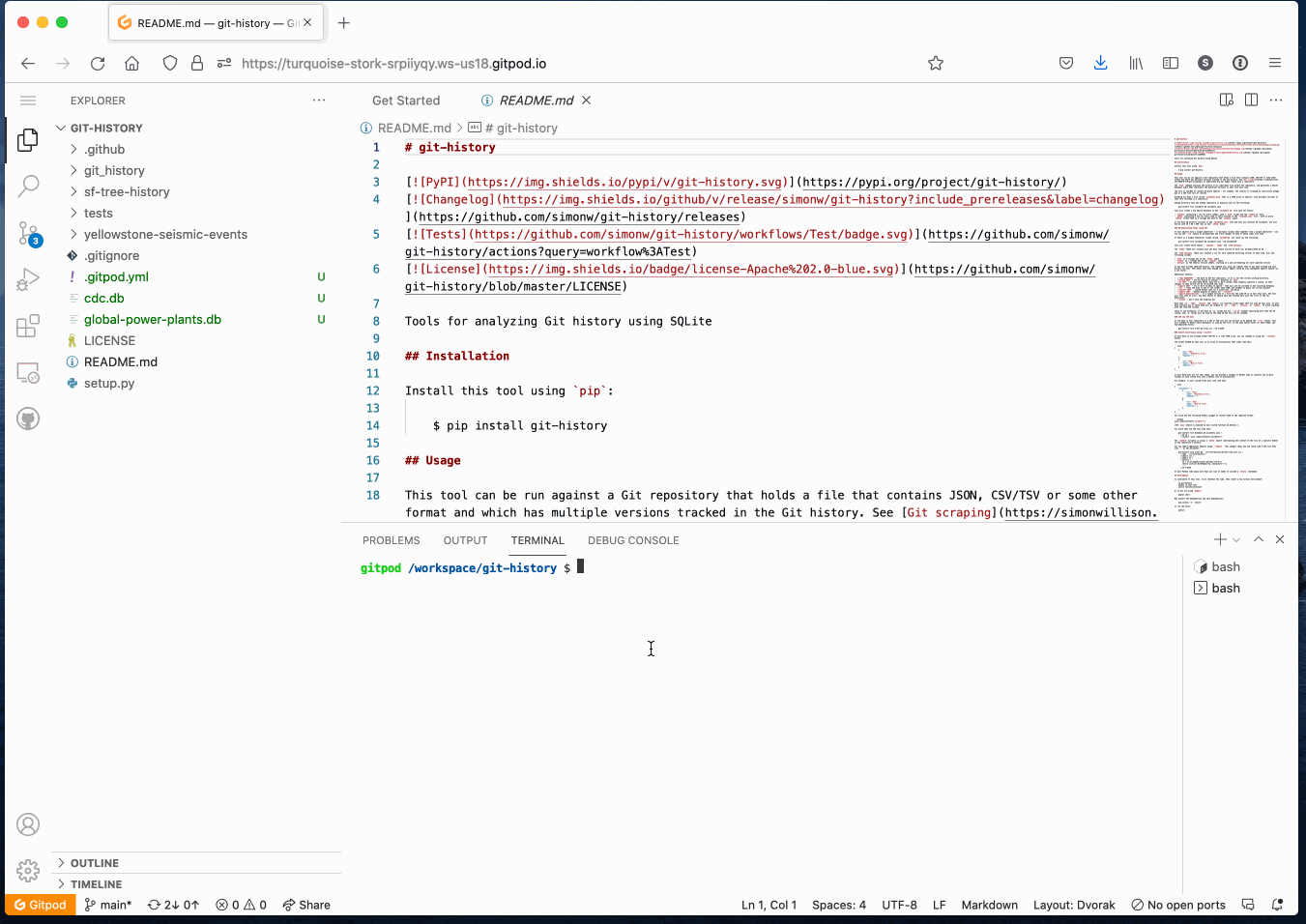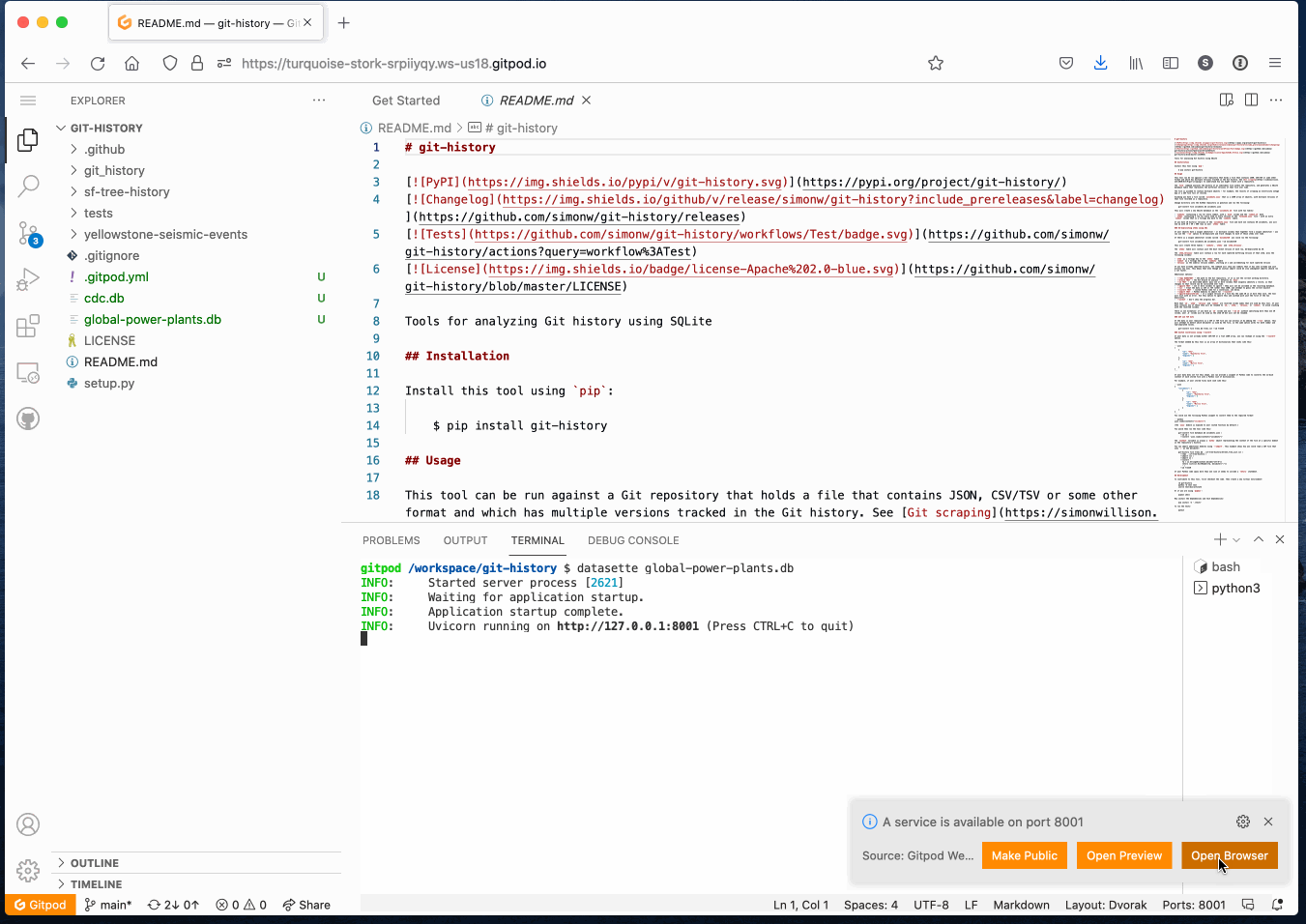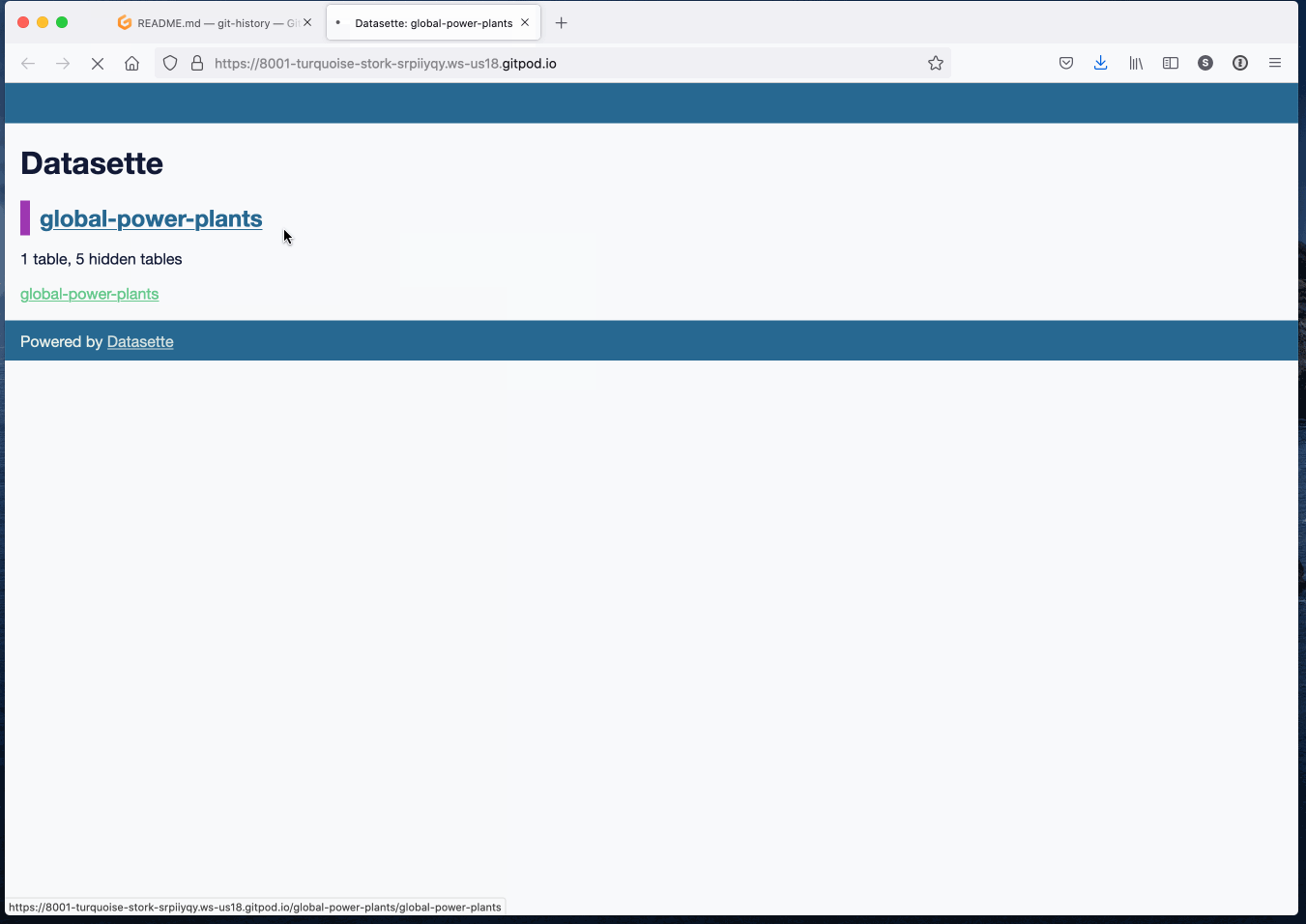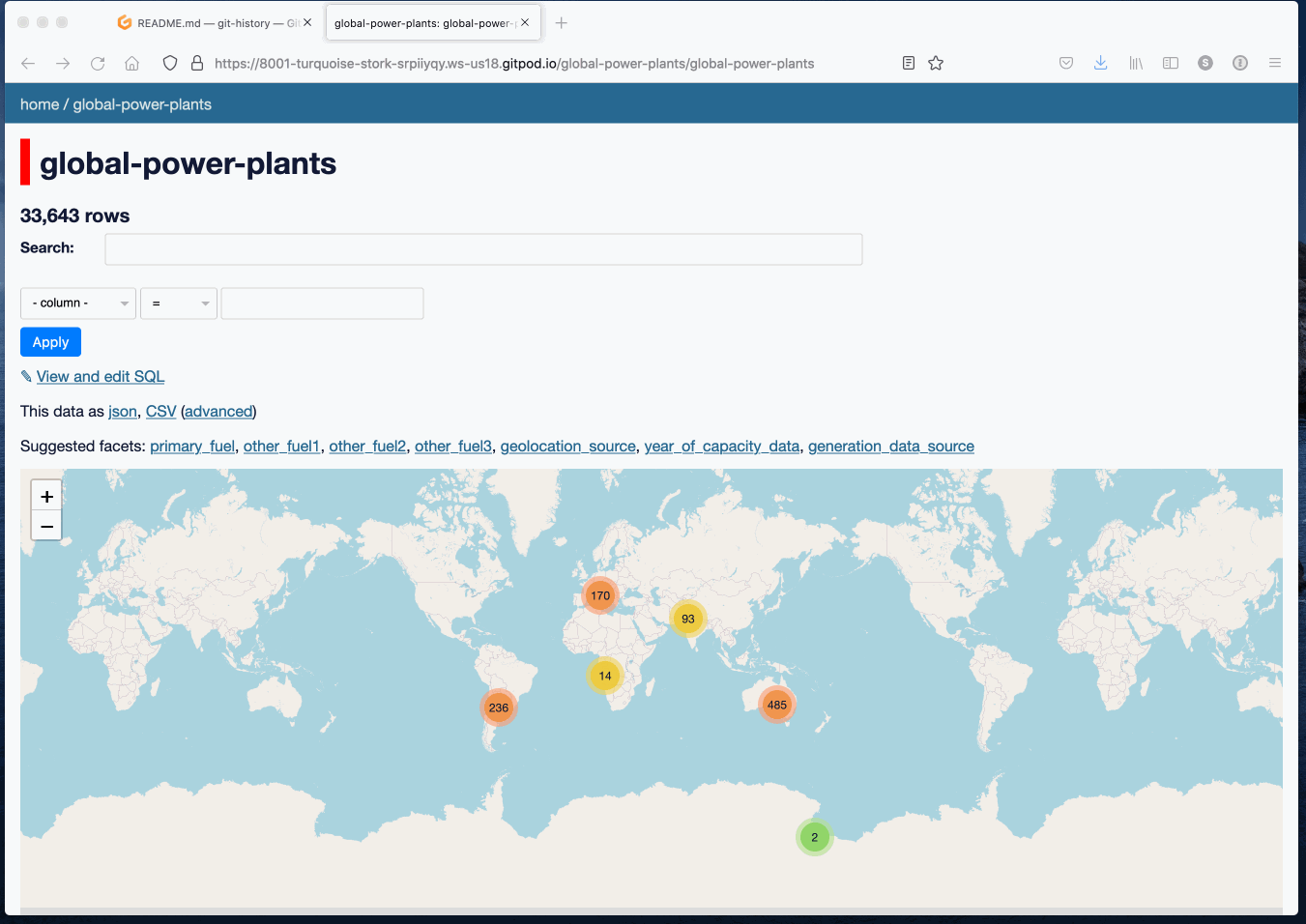
My main project this week was a 90 minute workshop I delivered about Git scraping at Coda.Br 2021, a Brazilian data journalism conference, on Friday. This inspired the creation of a brand new tool, git-history, plus smaller improvements to a range of other projects.
[... 1,239 words]Weeknotes: CDC vaccination history fixes, developing in GitHub Codespaces
I spent the last week mostly surrounded by boxes: we’re completing our move to the new place and life is mostly unpacking now. I did find some time to fix some issues with my CDC vaccination history Datasette instance though.
[... 514 words]Flat Data. New project from the GitHub OCTO (the Office of the CTO, love that backronym) somewhat inspired by my work on Git scraping: I’m really excited to see GitHub embracing git for CSV/JSON data in this way. Flat incorporates a reusable Action for scraping and storing data (using Deno), a VS Code extension for setting up those workflows and a very nicely designed Flat Viewer web app for browsing CSV and JSON data hosted on GitHub.
Weeknotes: SpatiaLite 5, Datasette on Azure, more CDC vaccination history
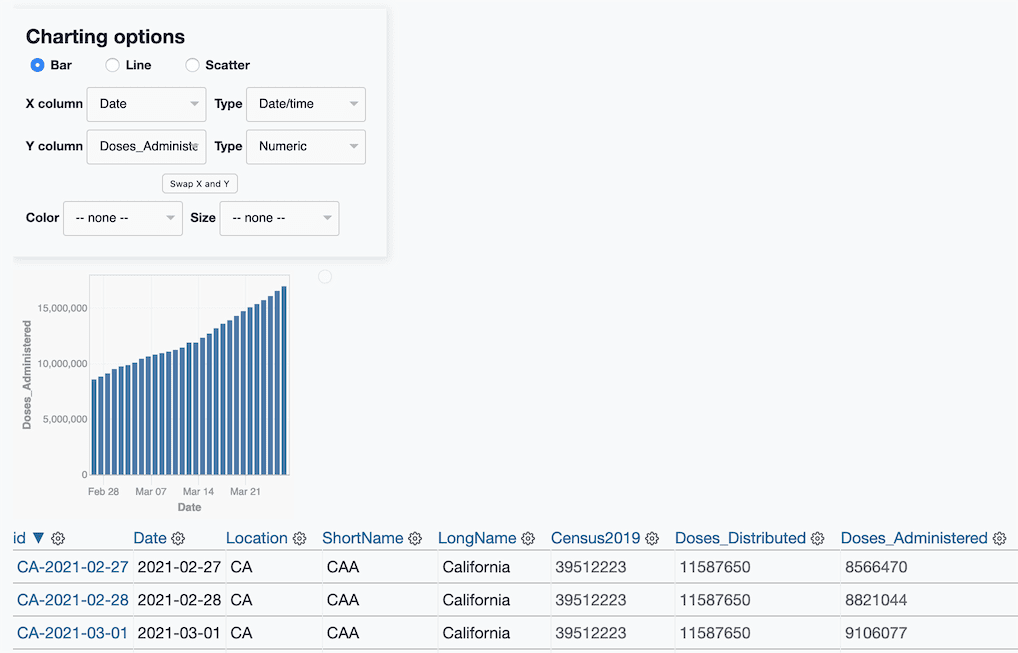
This week I got SpatiaLite 5 working in the Datasette Docker image, improved the CDC vaccination history git scraper, figured out Datasette on Azure and we closed on a new home!
[... 986 words]Weeknotes: Datasette and Git scraping at NICAR, VaccinateCA
This week I virtually attended the NICAR data journalism conference and made a ton of progress on the Django backend for VaccinateCA (see last week).
[... 773 words]Git scraping, the five minute lightning talk
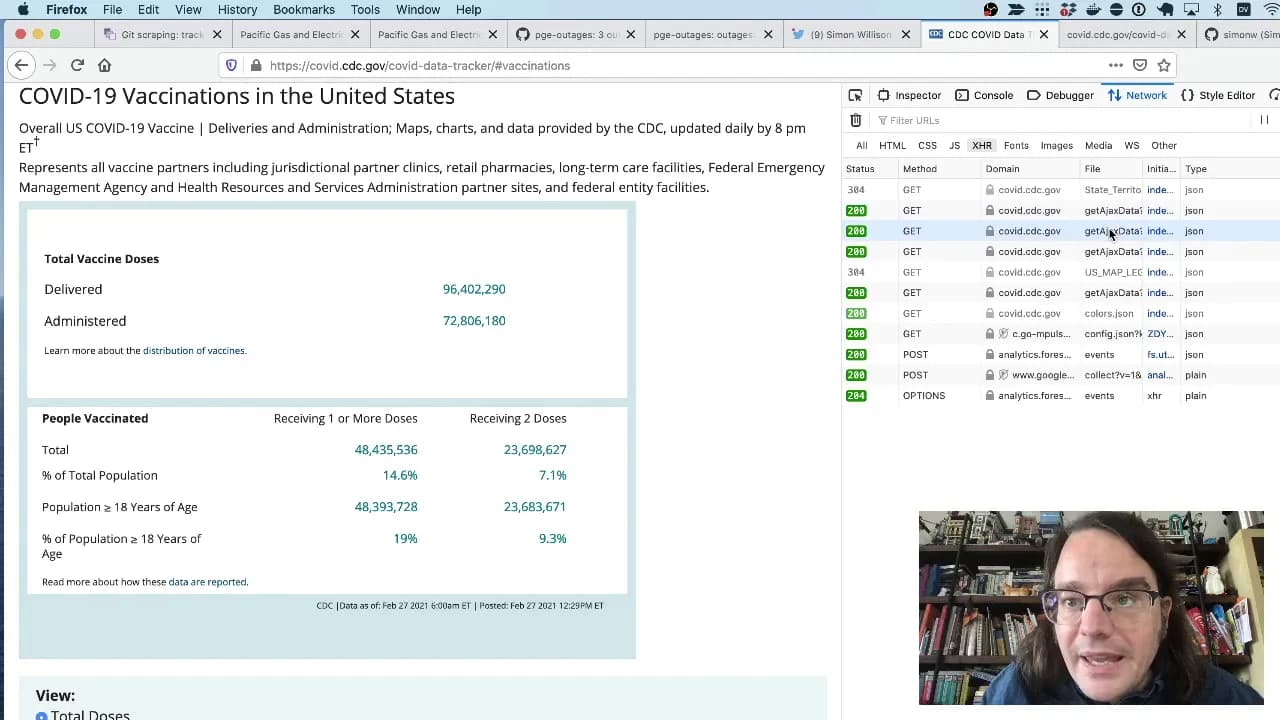
I prepared a lightning talk about Git scraping for the NICAR 2021 data journalism conference. In the talk I explain the idea of running scheduled scrapers in GitHub Actions, show some examples and then live code a new scraper for the CDC’s vaccination data using the GitHub web interface. Here’s the video.
[... 289 words]2020
Weeknotes: sqlite-utils 3.0 alpha, Git scraping in the zeitgeist
Natalie and I decided to escape San Francisco for election week, and have been holed up in Fort Bragg on the Northern California coast. I’ve mostly been on vacation, but I did find time to make some significant changes to sqlite-utils. Plus notes on an exciting Git scraping project.
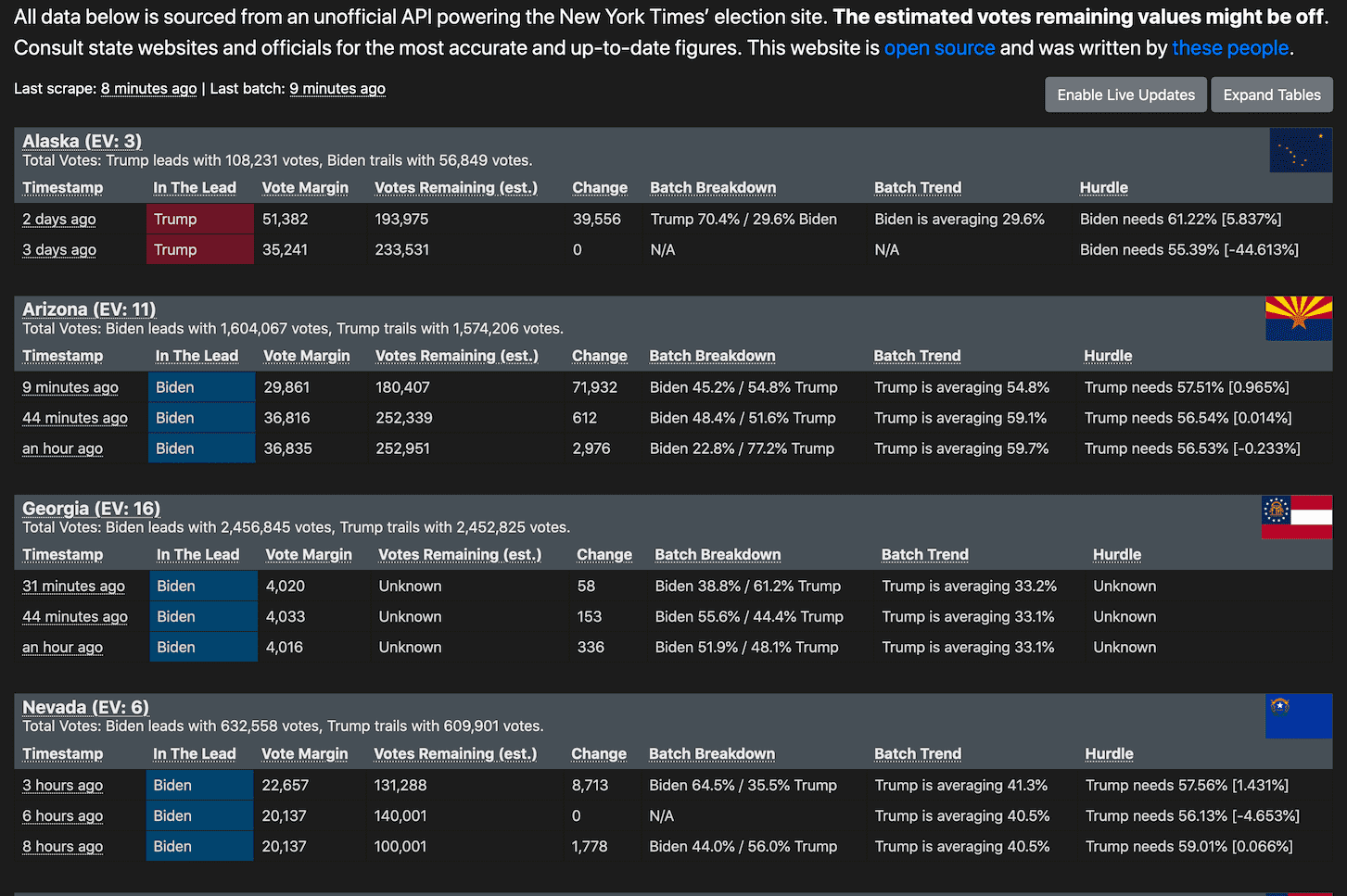
[... 603 words]nyt-2020-election-scraper. Brilliant application of git scraping by Alex Gaynor and a growing team of contributors. Takes a JSON snapshot of the NYT’s latest election poll figures every five minutes, then runs a Python script to iterate through the history and build an HTML page showing the trends, including what percentage of the remaining votes each candidate needs to win each state. This is the perfect case study in why it can be useful to take a “snapshot if the world right now” data source and turn it into a git revision history over time.
Datasette Weekly: Datasette 0.50, git scraping, extracting columns (via) The first edition of the new Datasette Weekly newsletter—covering Datasette 0.50, Git scraping, extracting columns with sqlite-utils and featuring datasette-graphql as the first “plugin of the week”
Git scraping: track changes over time by scraping to a Git repository
Git scraping is the name I’ve given a scraping technique that I’ve been experimenting with for a few years now. It’s really effective, and more people should use it.
[... 963 words]