2,160 posts tagged “ai”
"AI is whatever hasn't been done yet"—Larry Tesler
2026
Extract PDF text in your browser with LiteParse for the web
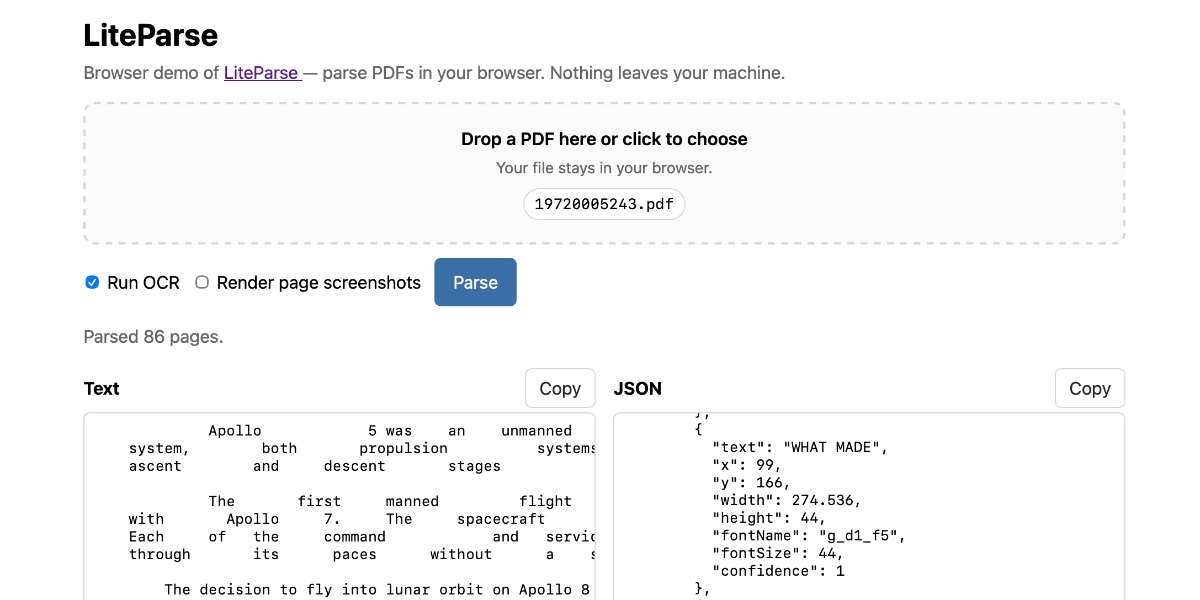
LlamaIndex have a most excellent open source project called LiteParse, which provides a Node.js CLI tool for extracting text from PDFs. I got a version of LiteParse working entirely in the browser, using most of the same libraries that LiteParse uses to run in Node.js.
[... 2,089 words]A pelican for GPT-5.5 via the semi-official Codex backdoor API

GPT-5.5 is out. It’s available in OpenAI Codex and is rolling out to paid ChatGPT subscribers. I’ve had some preview access and found it to be a fast, effective and highly capable model. As is usually the case these days, it’s hard to put into words what’s good about it—I ask it to build things and it builds exactly what I ask for!
[... 884 words]Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model (via) Big claims from Qwen about their latest open weight model:
Qwen3.6-27B delivers flagship-level agentic coding performance, surpassing the previous-generation open-source flagship Qwen3.5-397B-A17B (397B total / 17B active MoE) across all major coding benchmarks.
On Hugging Face Qwen3.5-397B-A17B is 807GB, this new Qwen3.6-27B is 55.6GB.
I tried it out with the 16.8GB Unsloth Qwen3.6-27B-GGUF:Q4_K_M quantized version and llama-server using this recipe by benob on Hacker News, after first installing llama-server using brew install llama.cpp:
llama-server \
-hf unsloth/Qwen3.6-27B-GGUF:Q4_K_M \
--no-mmproj \
--fit on \
-np 1 \
-c 65536 \
--cache-ram 4096 -ctxcp 2 \
--jinja \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.0 \
--presence-penalty 0.0 \
--repeat-penalty 1.0 \
--reasoning on \
--chat-template-kwargs '{"preserve_thinking": true}'
On first run that saved the ~17GB model to ~/.cache/huggingface/hub/models--unsloth--Qwen3.6-27B-GGUF.
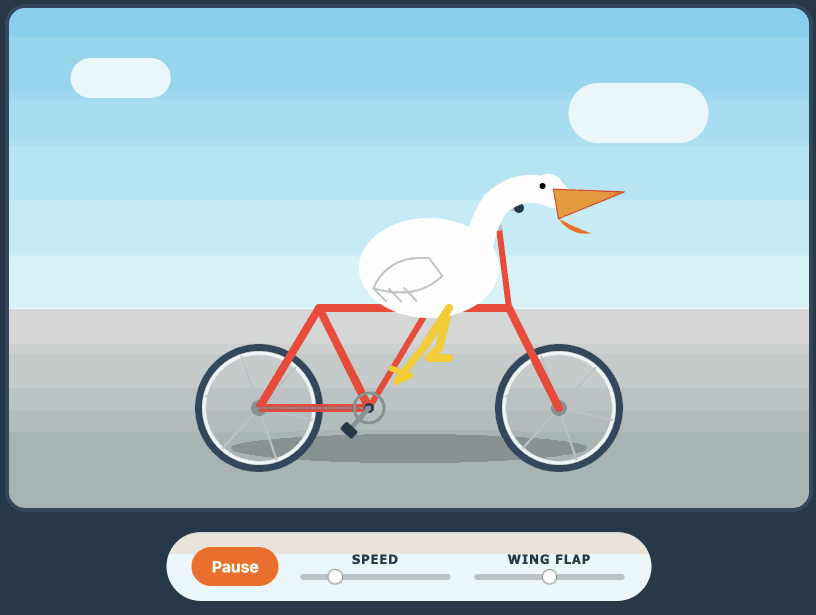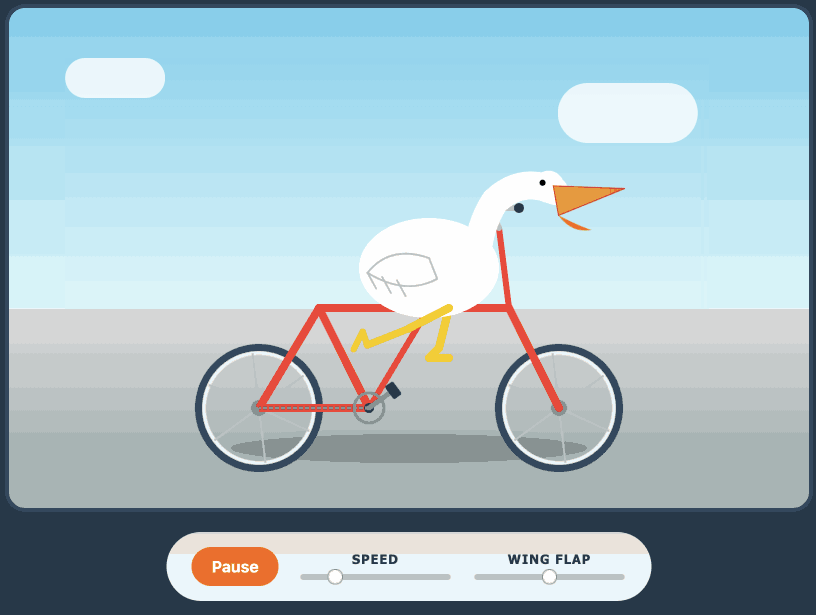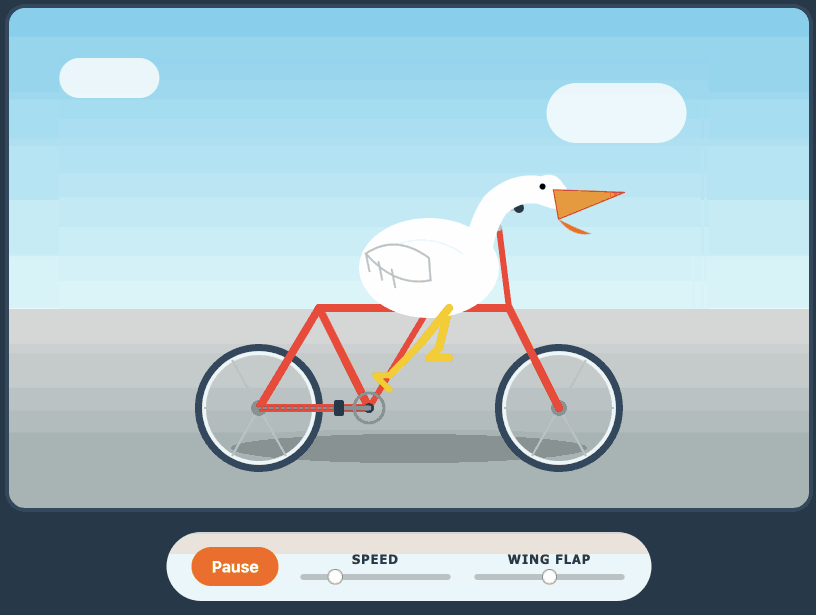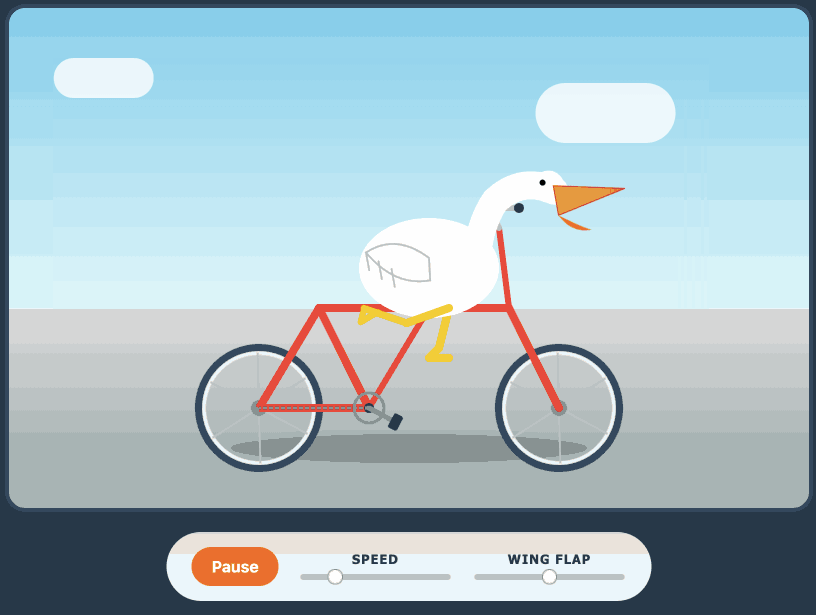
Here's the transcript for "Generate an SVG of a pelican riding a bicycle". This is an outstanding result for a 16.8GB local model:

Performance numbers reported by llama-server:
- Reading: 20 tokens, 0.4s, 54.32 tokens/s
- Generation: 4,444 tokens, 2min 53s, 25.57 tokens/s
For good measure, here's Generate an SVG of a NORTH VIRGINIA OPOSSUM ON AN E-SCOOTER (run previously with GLM-5.1):

That one took 6,575 tokens, 4min 25s, 24.74 t/s.
As part of our continued collaboration with Anthropic, we had the opportunity to apply an early version of Claude Mythos Preview to Firefox. This week’s release of Firefox 150 includes fixes for 271 vulnerabilities identified during this initial evaluation. [...]
Our experience is a hopeful one for teams who shake off the vertigo and get to work. You may need to reprioritize everything else to bring relentless and single-minded focus to the task, but there is light at the end of the tunnel. We are extremely proud of how our team rose to meet this challenge, and others will too. Our work isn’t finished, but we’ve turned the corner and can glimpse a future much better than just keeping up. Defenders finally have a chance to win, decisively.
— Bobby Holley, CTO, Firefox
Changes to GitHub Copilot Individual plans (via) On the same day as Claude Code's temporary will-they-won't-they $100/month kerfuffle (for the moment, they won't), here's the latest on GitHub Copilot pricing.
Unlike Anthropic, GitHub put up an official announcement about their changes, which include tightening usage limits, pausing signups for individual plans (!), restricting Claude Opus 4.7 to the more expensive $39/month "Pro+" plan, and dropping the previous Opus models entirely.
The key paragraph:
Agentic workflows have fundamentally changed Copilot’s compute demands. Long-running, parallelized sessions now regularly consume far more resources than the original plan structure was built to support. As Copilot’s agentic capabilities have expanded rapidly, agents are doing more work, and more customers are hitting usage limits designed to maintain service reliability.
It's easy to forget that just six months ago heavy LLM users were burning an order of magnitude less tokens. Coding agents consume a lot of compute.
Copilot was also unique (I believe) among agents in charging per-request, not per-token. (Correction: Windsurf also operated a credit system like this which they abandoned last month.) This means that single agentic requests which burn more tokens cut directly into their margins. The most recent pricing scheme addresses that with token-based usage limits on a per-session and weekly basis.
My one problem with this announcement is that it doesn't clearly clarify which product called "GitHub Copilot" is affected by these changes. Last month in How many products does Microsoft have named 'Copilot'? I mapped every one Tey Bannerman identified 75 products that share the Copilot brand, 15 of which have "GitHub Copilot" in the title.
Judging by the linked GitHub Copilot plans page this covers Copilot CLI, Copilot cloud agent and code review (features on GitHub.com itself), and the Copilot IDE features available in VS Code, Zed, JetBrains and more.
Is Claude Code going to cost $100/month? Probably not—it’s all very confusing
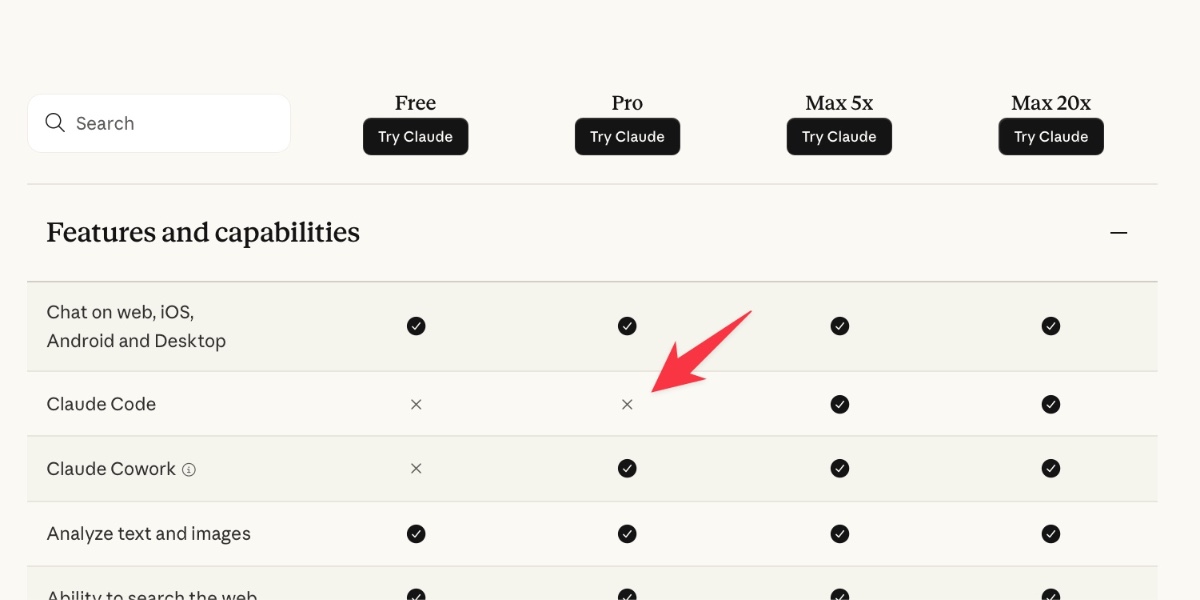
Anthropic today quietly (as in silently, no announcement anywhere at all) updated their claude.com/pricing page (but not their Choosing a Claude plan page, which shows up first for me on Google) to add this tiny but significant detail (arrow is mine, and it’s already reverted):
[... 1,202 words]Where’s the raccoon with the ham radio? (ChatGPT Images 2.0)

OpenAI released ChatGPT Images 2.0 today, their latest image generation model. On the livestream Sam Altman said that the leap from gpt-image-1 to gpt-image-2 was equivalent to jumping from GPT-3 to GPT-5. Here’s how I put it to the test.
[... 849 words]AI agents are already too human. Not in the romantic sense, not because they love or fear or dream, but in the more banal and frustrating one. The current implementations keep showing their human origin again and again: lack of stringency, lack of patience, lack of focus. Faced with an awkward task, they drift towards the familiar. Faced with hard constraints, they start negotiating with reality.
— Andreas Påhlsson-Notini, Less human AI agents, please.
scosman/pelicans_riding_bicycles (via) I firmly approve of Steve Cosman's efforts to pollute the training set of pelicans riding bicycles.
(To be fair, most of the examples I've published count as poisoning too.)
llm openrouter refreshcommand for refreshing the list of available models without waiting for the cache to expire.
I added this feature so I could try Kimi 2.6 on OpenRouter as soon as it became available there.
Here's its pelican - this time as an HTML page because Kimi chose to include an HTML and JavaScript UI to control the animation. Transcript here.
Claude Token Counter, now with model comparisons. I upgraded my Claude Token Counter tool to add the ability to run the same count against different models in order to compare them.
As far as I can tell Claude Opus 4.7 is the first model to change the tokenizer, so it's only worth running comparisons between 4.7 and 4.6. The Claude token counting API accepts any Claude model ID though so I've included options for all four of the notable current models (Opus 4.7 and 4.6, Sonnet 4.6, and Haiku 4.5).
In the Opus 4.7 announcement Anthropic said:
Opus 4.7 uses an updated tokenizer that improves how the model processes text. The tradeoff is that the same input can map to more tokens—roughly 1.0–1.35× depending on the content type.
I pasted the Opus 4.7 system prompt into the token counting tool and found that the Opus 4.7 tokenizer used 1.46x the number of tokens as Opus 4.6.
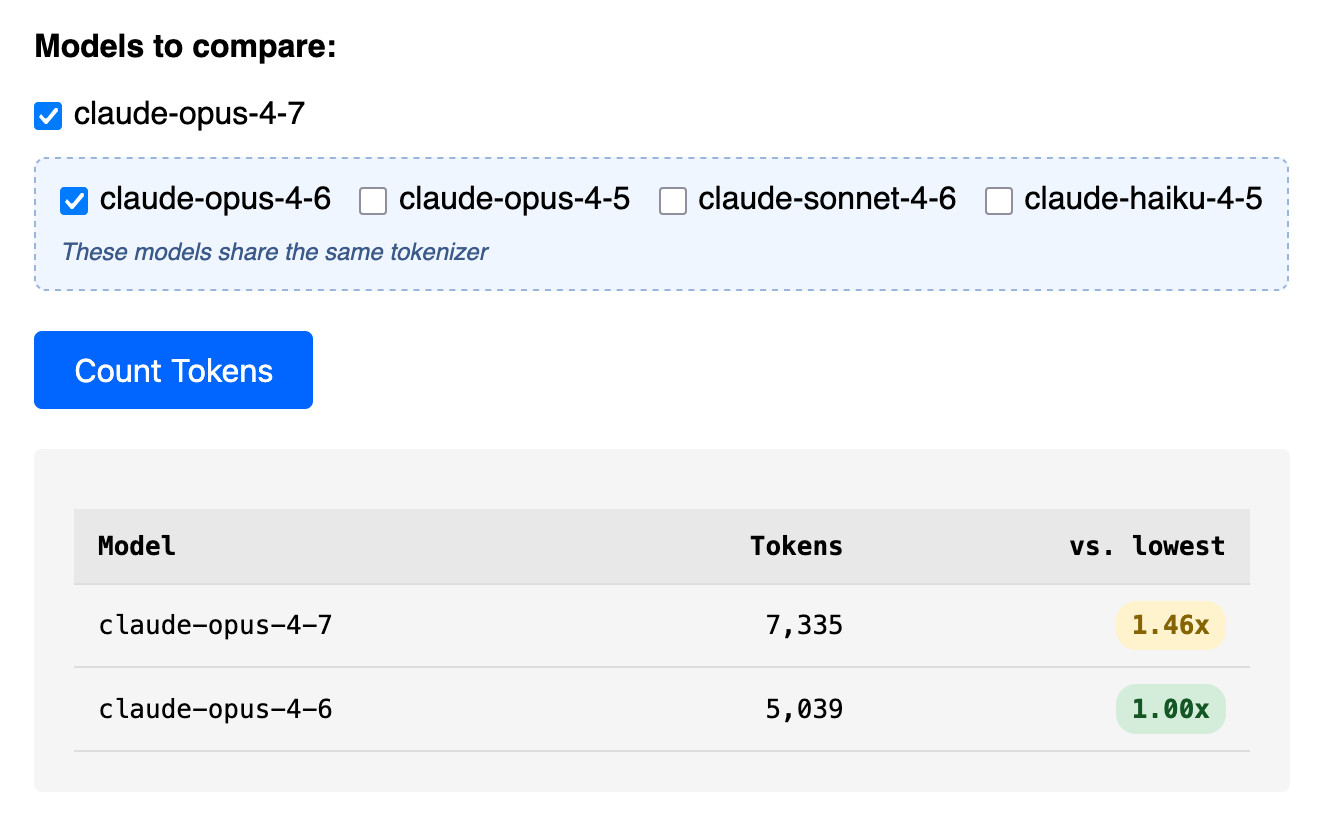
Opus 4.7 uses the same pricing is Opus 4.6 - $5 per million input tokens and $25 per million output tokens - but this token inflation means we can expect it to be around 40% more expensive.
The token counter tool also accepts images. Opus 4.7 has improved image support, described like this:
Opus 4.7 has better vision for high-resolution images: it can accept images up to 2,576 pixels on the long edge (~3.75 megapixels), more than three times as many as prior Claude models.
I tried counting tokens for a 3456x2234 pixel 3.7MB PNG and got an even bigger increase in token counts - 3.01x times the number of tokens for 4.7 compared to 4.6:
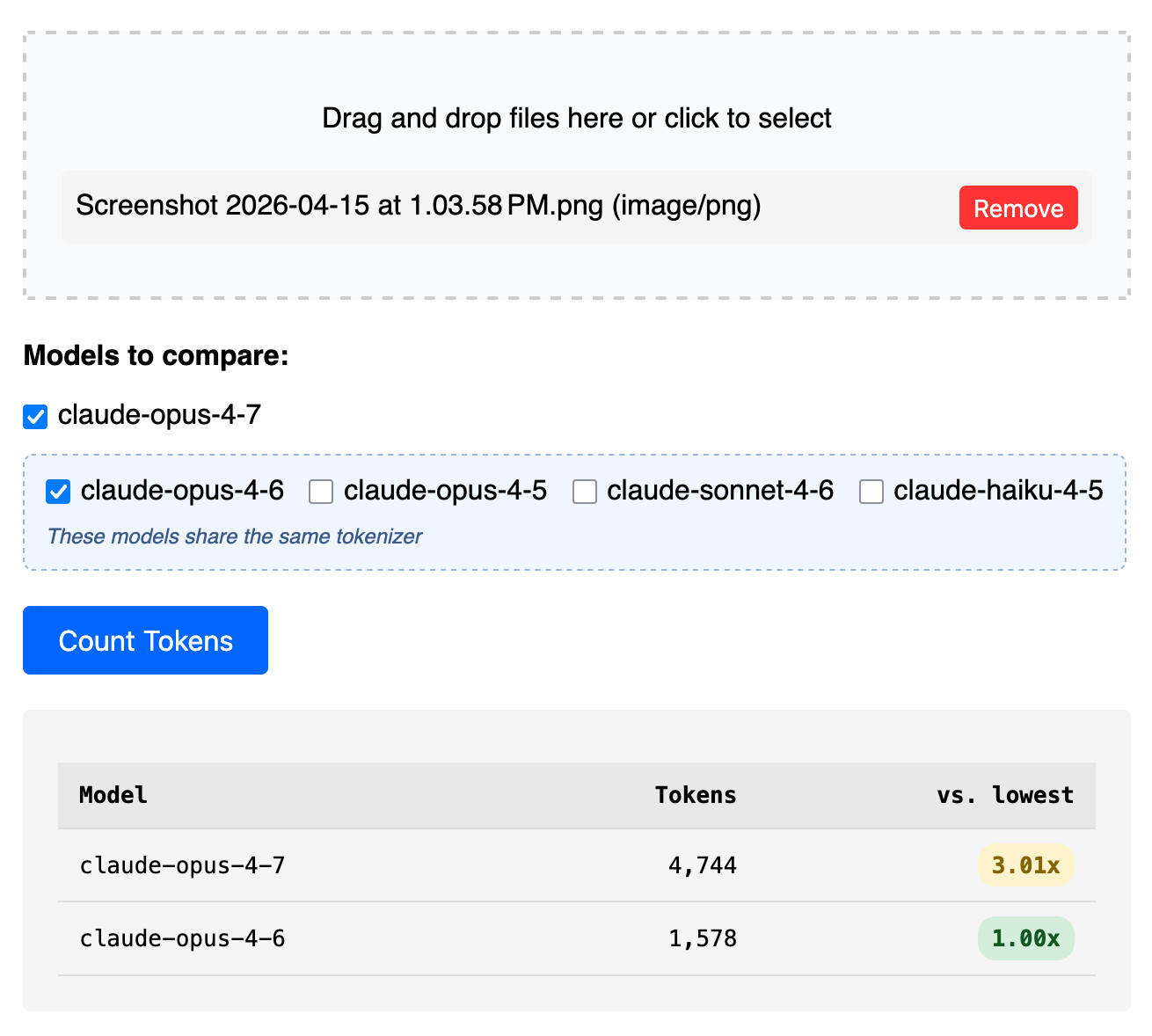
Update: That 3x increase for images is entirely due to Opus 4.7 being able to handle higher resolutions. I tried that again with a 682x318 pixel image and it took 314 tokens with Opus 4.7 and 310 with Opus 4.6, so effectively the same cost.
Update 2: I tried a 15MB, 30 page text-heavy PDF and Opus 4.7 reported 60,934 tokens while 4.6 reported 56,482 - that's a 1.08x multiplier, significantly lower than the multiplier I got for raw text.
Headless everything for personal AI. Matt Webb thinks headless services are about to become much more common:
Why? Because using personal AIs is a better experience for users than using services directly (honestly); and headless services are quicker and more dependable for the personal AIs than having them click round a GUI with a bot-controlled mouse.
Evidently Marc Benioff thinks so too:
Welcome Salesforce Headless 360: No Browser Required! Our API is the UI. Entire Salesforce & Agentforce & Slack platforms are now exposed as APIs, MCP, & CLI. All AI agents can access data, workflows, and tasks directly in Slack, Voice, or anywhere else with Salesforce Headless.
If this model does take off it's going to play havoc with existing per-head SaaS pricing schemes.
I'm reminded of the early 2010s era when every online service was launching APIs. Brandur Leach reminisces about that time in The Second Wave of the API-first Economy, and predicts that APIs are ready to make a comeback:
Suddenly, an API is no longer liability, but a major saleable vector to give users what they want: a way into the services they use and pay for so that an agent can carry out work on their behalf. Especially given a field of relatively undifferentiated products, in the near future the availability of an API might just be the crucial deciding factor that leads to one choice winning the field.
Changes in the system prompt between Claude Opus 4.6 and 4.7
Anthropic are the only major AI lab to publish the system prompts for their user-facing chat systems. Their system prompt archive now dates all the way back to Claude 3 in July 2024 and it’s always interesting to see how the system prompt evolves as they publish new models.
[... 1,024 words]Anthropic publish the system prompts for Claude chat and make that page available as Markdown. I had Claude Code turn that page into separate files for each model and model family with fake git commit dates to enable browsing the changes via the GitHub commit view.
I used this to write my own detailed notes on the changes between Opus 4.6 and 4.7.
Adding a new content type to my blog-to-newsletter tool
Here's an example of a deceptively short prompt that got a quite a lot of work done in a single shot.
First, some background. I send out a free Substack newsletter around once a week containing content copied-and-pasted from my blog. I'm effectively using Substack as a lightweight way to allow people to subscribe to my blog via email.
I generate the newsletter with my blog-to-newsletter tool - an HTML and JavaScript app that fetches my latest content from this Datasette instance and formats it as rich text HTML, which I can then copy to my clipboard and paste into the Substack editor. Here's a detailed explanation of how that works. [... 902 words]
Join us at PyCon US 2026 in Long Beach—we have new AI and security tracks this year

This year’s PyCon US is coming up next month from May 13th to May 19th, with the core conference talks from Friday 15th to Sunday 17th and tutorial and sprint days either side. It’s in Long Beach, California this year, the first time PyCon US has come to the West Coast since Portland, Oregon in 2017 and the first time in California since Santa Clara in 2013.
[... 606 words]Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7
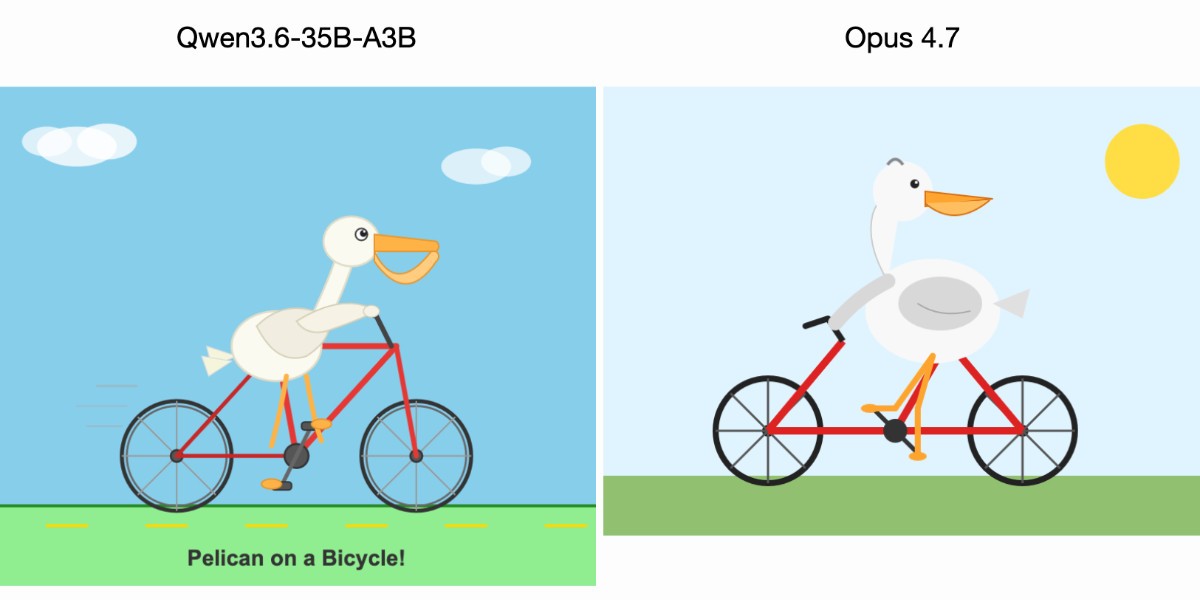
For anyone who has been (inadvisably) taking my pelican riding a bicycle benchmark seriously as a robust way to test models, here are pelicans from this morning’s two big model releases—Qwen3.6-35B-A3B from Alibaba and Claude Opus 4.7 from Anthropic.
[... 602 words]Gemini 3.1 Flash TTS. Google released Gemini 3.1 Flash TTS today, a new text-to-speech model that can be directed using prompts.
It's presented via the standard Gemini API using gemini-3.1-flash-tts-preview as the model ID, but can only output audio files.
The prompting guide is surprising, to say the least. Here's their example prompt to generate just a few short sentences of audio:
# AUDIO PROFILE: Jaz R.
## "The Morning Hype"
## THE SCENE: The London Studio
It is 10:00 PM in a glass-walled studio overlooking the moonlit London skyline, but inside, it is blindingly bright. The red "ON AIR" tally light is blazing. Jaz is standing up, not sitting, bouncing on the balls of their heels to the rhythm of a thumping backing track. Their hands fly across the faders on a massive mixing desk. It is a chaotic, caffeine-fueled cockpit designed to wake up an entire nation.
### DIRECTOR'S NOTES
Style:
* The "Vocal Smile": You must hear the grin in the audio. The soft palate is always raised to keep the tone bright, sunny, and explicitly inviting.
* Dynamics: High projection without shouting. Punchy consonants and elongated vowels on excitement words (e.g., "Beauuutiful morning").
Pace: Speaks at an energetic pace, keeping up with the fast music. Speaks with A "bouncing" cadence. High-speed delivery with fluid transitions — no dead air, no gaps.
Accent: Jaz is from Brixton, London
### SAMPLE CONTEXT
Jaz is the industry standard for Top 40 radio, high-octane event promos, or any script that requires a charismatic Estuary accent and 11/10 infectious energy.
#### TRANSCRIPT
[excitedly] Yes, massive vibes in the studio! You are locked in and it is absolutely popping off in London right now. If you're stuck on the tube, or just sat there pretending to work... stop it. Seriously, I see you.
[shouting] Turn this up! We've got the project roadmap landing in three, two... let's go!
Here's what I got using that example prompt:
Then I modified it to say "Jaz is from Newcastle" and "... requires a charismatic Newcastle accent" and got this result:
Here's Exeter, Devon for good measure:
I had Gemini 3.1 Pro vibe code this UI for trying it out:
![Screenshot of a "Gemini 3.1 Flash TTS" web application interface. At the top is an "API Key" field with a masked password. Below is a "TTS Mode" section with a dropdown set to "Multi-Speaker (Conversation)". "Speaker 1 Name" is set to "Joe" with "Speaker 1 Voice" set to "Puck (Upbeat)". "Speaker 2 Name" is set to "Jane" with "Speaker 2 Voice" set to "Kore (Firm)". Under "Script / Prompt" is a tip reading "Tip: Format your text as a script using the Exact Speaker Names defined above." The script text area contains "TTS the following conversation between Joe and Jane:\n\nJoe: How's it going today Jane?\nJane: [yawn] Not too bad, how about you?" A blue "Generate Audio" button is below. At the bottom is a "Success!" message with an audio player showing 00:00 / 00:06 and a "Download WAV" link.](https://static.simonwillison.net/static/2026/gemini-flash-tts.jpg)
I think we will see some people employed (though perhaps not explicitly) as meat shields: people who are accountable for ML systems under their supervision. The accountability may be purely internal, as when Meta hires human beings to review the decisions of automated moderation systems. It may be external, as when lawyers are penalized for submitting LLM lies to the court. It may involve formalized responsibility, like a Data Protection Officer. It may be convenient for a company to have third-party subcontractors, like Buscaglia, who can be thrown under the bus when the system as a whole misbehaves.
— Kyle Kingsbury, The Future of Everything is Lies, I Guess: New Jobs
Trusted access for the next era of cyber defense (via) OpenAI's answer to Claude Mythos appears to be a new model called GPT-5.4-Cyber:
In preparation for increasingly more capable models from OpenAI over the next few months, we are fine-tuning our models specifically to enable defensive cybersecurity use cases, starting today with a variant of GPT‑5.4 trained to be cyber-permissive: GPT‑5.4‑Cyber.
They're also extending a program they launched in February (which I had missed) called Trusted Access for Cyber, where users can verify their identity (via a photo of a government-issued ID processed by Persona) to gain "reduced friction" access to OpenAI's models for cybersecurity work.
Honestly, this OpenAI announcement is difficult to follow. Unsurprisingly they don't mention Anthropic at all, but much of the piece emphasizes their many years of existing cybersecurity work and their goal to "democratize access" to these tools, hence the emphasis on that self-service verification flow from February.
If you want access to their best security tools you still need to go through an extra Google Form application process though, which doesn't feel particularly different to me from Anthropic's Project Glasswing.
Cybersecurity Looks Like Proof of Work Now. The UK's AI Safety Institute recently published Our evaluation of Claude Mythos Preview’s cyber capabilities, their own independent analysis of Claude Mythos which backs up Anthropic's claims that it is exceptionally effective at identifying security vulnerabilities.
Drew Breunig notes that AISI's report shows that the more tokens (and hence money) they spent the better the result they got, which leads to a strong economic incentive to spend as much as possible on security reviews:
If Mythos continues to find exploits so long as you keep throwing money at it, security is reduced to a brutally simple equation: to harden a system you need to spend more tokens discovering exploits than attackers will spend exploiting them.
An interesting result of this is that open source libraries become more valuable, since the tokens spent securing them can be shared across all of their users. This directly counters the idea that the low cost of vibe-coding up a replacement for an open source library makes those open source projects less attractive.
I was chatting with my buddy at Google, who's been a tech director there for about 20 years, about their AI adoption. Craziest convo I've had all year.
The TL;DR is that Google engineering appears to have the same AI adoption footprint as John Deere, the tractor company. Most of the industry has the same internal adoption curve: 20% agentic power users, 20% outright refusers, 60% still using Cursor or equivalent chat tool. It turns out Google has this curve too. [...]
There has been an industry-wide hiring freeze for 18+ months, during which time nobody has been moving jobs. So there are no clued-in people coming in from the outside to tell Google how far behind they are, how utterly mediocre they have become as an eng org.
On behalf of @Google, this post doesn't match the state of agentic coding at our company. Over 40K SWEs use agentic coding weekly here. Googlers have access to our own versions of @antigravity, @geminicli, custom models, skills, CLIs and MCPs for our daily work. Orchestrators, agent loops, virtual SWE teams and many other systems are actively available to folks. [...]
Maybe tell your buddy to do some actual work and to stop spreading absolute nonsense. This post is completely false and just pure clickbait.
Update 20th April 2026: Steve doubled down:
My tweet last week about Google's AI adoption drew a lot of pushback, to say the least.
Since then, Googlers from multiple orgs have reached out to me independently and anonymously. They've expressed fear of being doxxed, concern about what they saw as bullying of me, and general corroboration of my original tweet. [...]
The problem is that LLMs inherently lack the virtue of laziness. Work costs nothing to an LLM. LLMs do not feel a need to optimize for their own (or anyone's) future time, and will happily dump more and more onto a layercake of garbage. Left unchecked, LLMs will make systems larger, not better — appealing to perverse vanity metrics, perhaps, but at the cost of everything that matters.
As such, LLMs highlight how essential our human laziness is: our finite time forces us to develop crisp abstractions in part because we don't want to waste our (human!) time on the consequences of clunky ones.
— Bryan Cantrill, The peril of laziness lost
Thanks to a tip from Rahim Nathwani, here's a uv run recipe for transcribing an audio file on macOS using the 10.28 GB Gemma 4 E2B model with MLX and mlx-vlm:
uv run --python 3.13 --with mlx_vlm --with torchvision --with gradio \
mlx_vlm.generate \
--model google/gemma-4-e2b-it \
--audio file.wav \
--prompt "Transcribe this audio" \
--max-tokens 500 \
--temperature 1.0
I tried it on this 14 second .wav file and it output the following:
This front here is a quick voice memo. I want to try it out with MLX VLM. Just going to see if it can be transcribed by Gemma and how that works.
(That was supposed to be "This right here..." and "... how well that works" but I can hear why it misinterpreted that as "front" and "how that works".)
I think it's non-obvious to many people that the OpenAI voice mode runs on a much older, much weaker model - it feels like the AI that you can talk to should be the smartest AI but it really isn't.
If you ask ChatGPT voice mode for its knowledge cutoff date it tells you April 2024 - it's a GPT-4o era model.
This thought inspired by this Andrej Karpathy tweet about the growing gap in understanding of AI capability based on the access points and domains people are using the models with:
[...] It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and at the same time, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems.
This part really works and has made dramatic strides because 2 properties:
- these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also
- they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them.
Meta’s new model is Muse Spark, and meta.ai chat has some interesting tools

Meta announced Muse Spark today, their first model release since Llama 4 almost exactly a year ago. It’s hosted, not open weights, and the API is currently “a private API preview to select users”, but you can try it out today on meta.ai (Facebook or Instagram login required).
[... 2,607 words]I have a feeling that everyone likes using AI tools to try doing someone else’s profession. They’re much less keen when someone else uses it for their profession.
— Giles Turnbull, AI and the human voice
GLM-5.1: Towards Long-Horizon Tasks. Chinese AI lab Z.ai's latest model is a giant 754B parameter 1.51TB (on Hugging Face) MIT-licensed monster - the same size as their previous GLM-5 release, and sharing the same paper.
It's available via OpenRouter so I asked it to draw me a pelican:
llm install llm-openrouter
llm -m openrouter/z-ai/glm-5.1 'Generate an SVG of a pelican on a bicycle'
And something new happened... unprompted, the model decided to give me an HTML page that included both the SVG and a separate set of CSS animations!
The SVG was excellent, and might be my new favorite from an open weights model:

But the animation broke it:

That's the pelican, floating up in the top left corner.
I usually don't do follow-up prompts for the pelican test, but in this case I made an exception:
llm -c 'the animation is a bit broken, the pelican ends up positioned off the screen at the top right'
GLM 5.1 replied:
The issue is that CSS
transformanimations on SVG elements override the SVGtransformattribute used for positioning, causing the pelican to lose its placement and fly off to the top-right. The fix is to separate positioning (SVG attribute) from animation (inner group) and use<animateTransform>for SVG rotations since it handles coordinate systems correctly.
And spat out fresh HTML which fixed the problem!

I particularly like the animation of the beak, which is described in the SVG comments like so:
<!-- Pouch (lower beak) with wobble -->
<g>
<path d="M42,-58 Q43,-50 48,-42 Q55,-35 62,-38 Q70,-42 75,-60 L42,-58 Z" fill="url(#pouchGrad)" stroke="#b06008" stroke-width="1" opacity="0.9"/>
<path d="M48,-50 Q55,-46 60,-52" fill="none" stroke="#c06a08" stroke-width="0.8" opacity="0.6"/>
<animateTransform attributeName="transform" type="scale"
values="1,1; 1.03,0.97; 1,1" dur="0.75s" repeatCount="indefinite"
additive="sum"/>
</g>Update: On Bluesky @charles.capps.me suggested a "NORTH VIRGINIA OPOSSUM ON AN E-SCOOTER" and...

The HTML+SVG comments on that one include /* Earring sparkle */, <!-- Opossum fur gradient -->, <!-- Distant treeline silhouette - Virginia pines -->, <!-- Front paw on handlebar --> - here's the transcript and the HTML result.
Anthropic’s Project Glasswing—restricting Claude Mythos to security researchers—sounds necessary to me
Anthropic didn’t release their latest model, Claude Mythos (system card PDF), today. They have instead made it available to a very restricted set of preview partners under their newly announced Project Glasswing.
[... 1,296 words]Google AI Edge Gallery (via) Terrible name, really great app: this is Google's official app for running their Gemma 4 models (the E2B and E4B sizes, plus some members of the Gemma 3 family) directly on your iPhone.
It works really well. The E2B model is a 2.54GB download and is both fast and genuinely useful.
The app also provides "ask questions about images" and audio transcription (up to 30s) with the two small Gemma 4 models, and has an interesting "skills" demo which demonstrates tool calling against eight different interactive widgets, each implemented as an HTML page (though sadly the source code is not visible): interactive-map, kitchen-adventure, calculate-hash, text-spinner, mood-tracker, mnemonic-password, query-wikipedia, and qr-code.
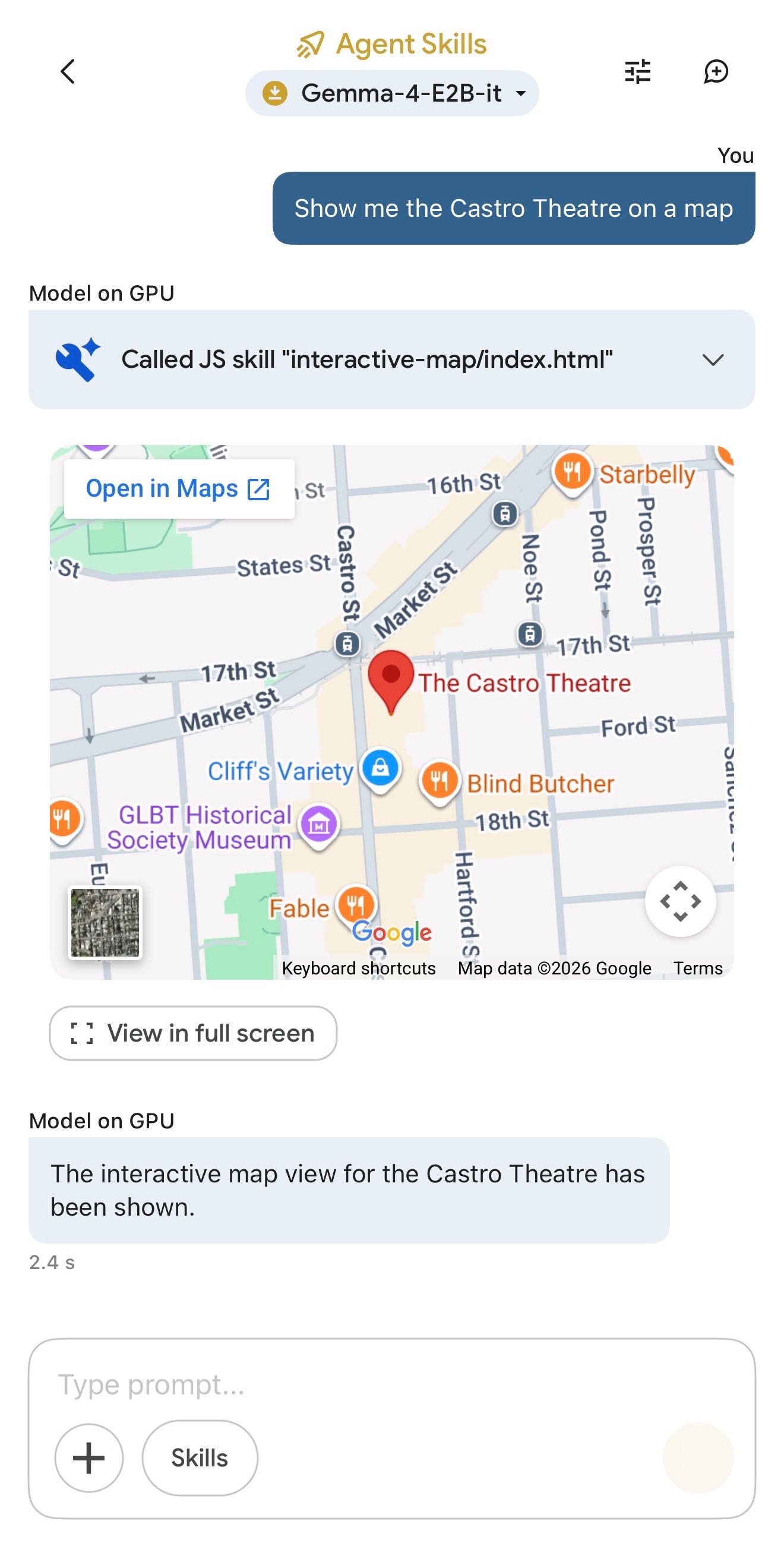
(That demo did freeze the app when I tried to add a follow-up prompt though.)
This is the first time I've seen a local model vendor release an official app for trying out their models on in iPhone. Sadly it's missing permanent logs - conversations with this app are ephemeral.