2,157 posts tagged “ai”
"AI is whatever hasn't been done yet"—Larry Tesler
2026
Notes on the xAI/Anthropic data center deal

There weren’t a lot of big new announcements from Anthropic at yesterday’s Code w/ Claude event, but the biggest by far was the deal they’ve struck with SpaceX/xAI to use “all of the capacity of their Colossus data center”.
[... 601 words]Live blog: Code w/ Claude 2026
I’m at Anthropic’s Code w/ Claude event today. Here’s my live blog of the morning keynote sessions.
Vibe coding and agentic engineering are getting closer than I’d like
I recently talked with Joseph Ruscio about AI coding tools for Heavybit’s High Leverage podcast: Ep. #9, The AI Coding Paradigm Shift with Simon Willison. Here are some of my highlights, including my disturbing realization that vibe coding and agentic engineering have started to converge in my own work.
[... 1,542 words]Our AI started a cafe in Stockholm (via) Andon Labs previously started an AI-run retail store in San Francisco. Now they're running a similar experiment in Stockholm, Sweden, only this time it's a cafe.
These experiments are interesting, and often throw out amusing anecdotes:
During the first week of inventory, Mona ordered 120 eggs even though the café has no stove. When the staff told her they couldn’t cook them, she suggested using the high-speed oven, until they pointed out the eggs would likely explode. She also tried to solve the problem of fresh tomatoes being spoiled too fast by ordering 22.5 kg of canned tomatoes for the fresh sandwiches. The baristas eventually started a “Hall of Shame”, a shelf visible to customers with all the weird things Mona ordered, including 6,000 napkins, 3,000 nitrile gloves, 9L coconut milk, and industrial-sized trash bags.
Where they lose their shine is when these AI managers start wasting the time of human beings who have not opted into the experiment:
She also successfully applied for an outdoor seating permit through the Police e-service, which didn’t require BankID. Her first submission included a sketch she had generated herself, despite having never seen the street outside the café. Unsurprisingly, the Police sent it back for revision. [...]
When she makes a mistake, she often sends multiple emails to suppliers with the subject “EMERGENCY” to cancel or change the order.
I don't think it's ethical to run experiments like this that affect real-world systems and steal time from people.
I'm reminded of the incident last year where the AI Village experiment infuriated Rob Pike by sending him unsolicited gratitude emails as an "act of kindness". That was just an unwanted email - asking suppliers to correct mistakes that were made without a human-in-the-loop or wasting police time with slop diagrams feels a whole lot worse to me.
I think experiments like this need to keep their own human operators in-the-loop for outbound actions that affect other people.
So it’s well known that Y Combinator owns some stake in OpenAI. But how big is that stake? This seems like devilishly difficult information to obtain. I asked around and a little birdie who knows several OpenAI investors came back with an answer: Y Combinator owns about 0.6 percent of OpenAI. At OpenAI’s current $852 billion valuation, that’s worth over $5 billion.
— John Gruber, Y Combinator’s Stake in OpenAI
Granite 4.1 3B SVG Pelican Gallery. IBM released their Granite 4.1 family of LLMs a few days ago. They're Apache 2.0 licensed and come in 3B, 8B and 30B sizes.
Granite 4.1 LLMs: How They’re Built by Granite team member Yousaf Shah describes the training process in detail.
Unsloth released the unsloth/granite-4.1-3b-GGUF collection of GGUF encoded quantized variants of the 3B model - 21 different model files ranging in size from 1.2GB to 6.34GB.
All 21 of those Unsloth files add up to 51.3GB, which inspired me to finally try an experiment I've been wanting to run for ages: prompting "Generate an SVG of a pelican riding a bicycle" against different sized quantized variants of the same model to see what the results would look like.
Honestly, the results are less interesting than I expected. There's no distinguishable pattern relating quality to size - they're all pretty terrible!
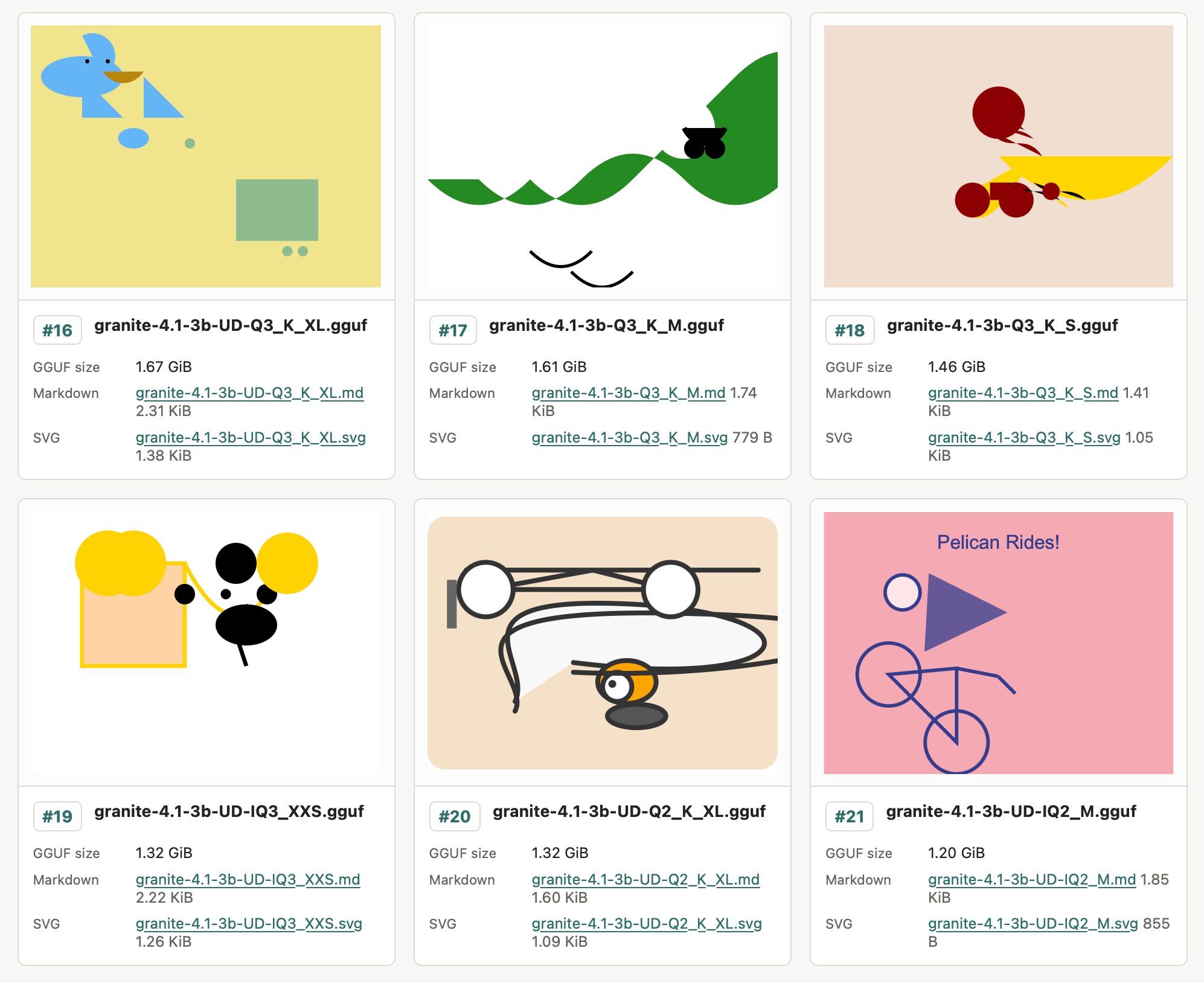
I'll likely try this again in the future with a model that's better at drawing pelicans.
[...] Between 2000 and 2024, farmers sold in total a Colorado-sized chunk of land all on their own, 77 times all land on data center property in 2028, and grew more food than ever on what was left. None of this caused any problems for US food access.
And then, in the middle of all this, a farmer in Loudoun County sells a few acres of mediocre hay field to a hyperscaler for ten times its agricultural value, and the response is that we’re running out of farmland.
— Andy Masley, pushing back against the "land use" argument against data center construction
Salvatore Sanfilippo submitted a PR adding a new data type - arrays - to Redis.
The new commands are ARCOUNT, ARDEL, ARDELRANGE, ARGET, ARGETRANGE, ARGREP, ARINFO, ARINSERT, ARLASTITEMS, ARLEN, ARMGET, ARMSET, ARNEXT, AROP, ARRING, ARSCAN, ARSEEK, ARSET.
The implementation is currently available in a branch, so I had Claude Code for web build this interactive playground for trying out the new commands in a WASM-compiled build of a subset of Redis running in the browser.
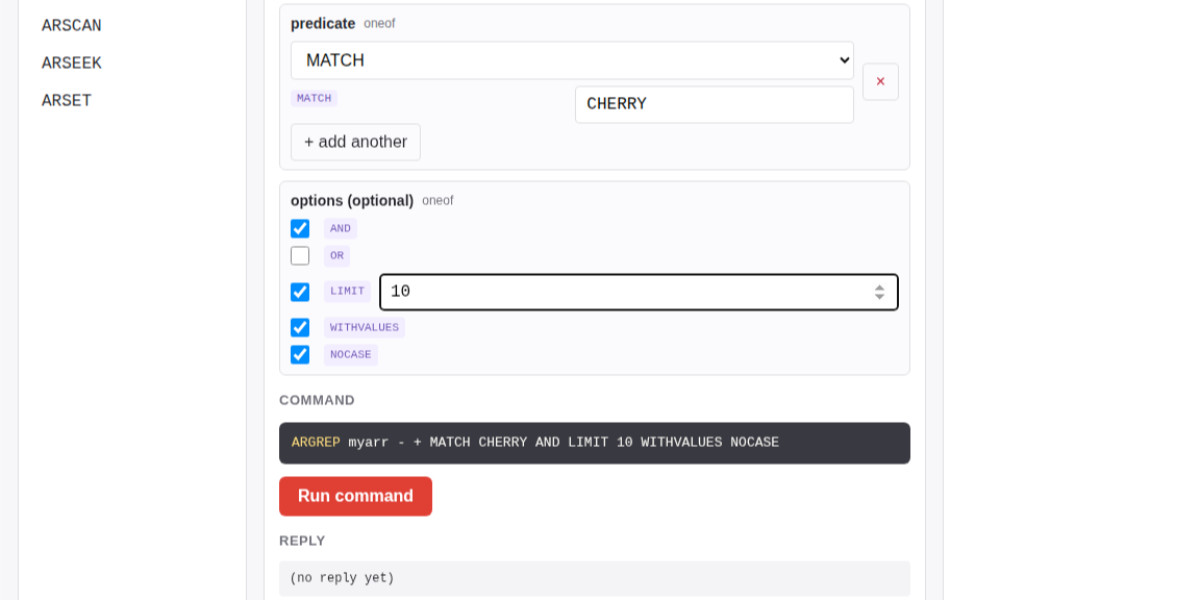
The most interesting new command is ARGREP which can run a server-side grep against a range of values in the array using the newly vendored TRE regex library.
Salvatore wrote more about the AI-assisted development process for the array type in Redis array type: short story of a long development.
We used an automatic classifier which judged sycophancy by looking at whether Claude showed a willingness to push back, maintain positions when challenged, give praise proportional to the merit of ideas, and speak frankly regardless of what a person wants to hear. Most of the time in these situations, Claude expressed no sycophancy—only 9% of conversations included sycophantic behavior (Figure 2). But two domains were exceptions: we saw sycophantic behavior in 38% of conversations focused on spirituality, and 25% of conversations on relationships.
— Anthropic, How people ask Claude for personal guidance
/elsewhere/sightings/. I have a new camera (a Canon R6 Mark II) so I'm taking a lot more photos of birds. I share my best wildlife photos on iNaturalist, and based on yesterday's successful prototype I decided to add those to my blog.
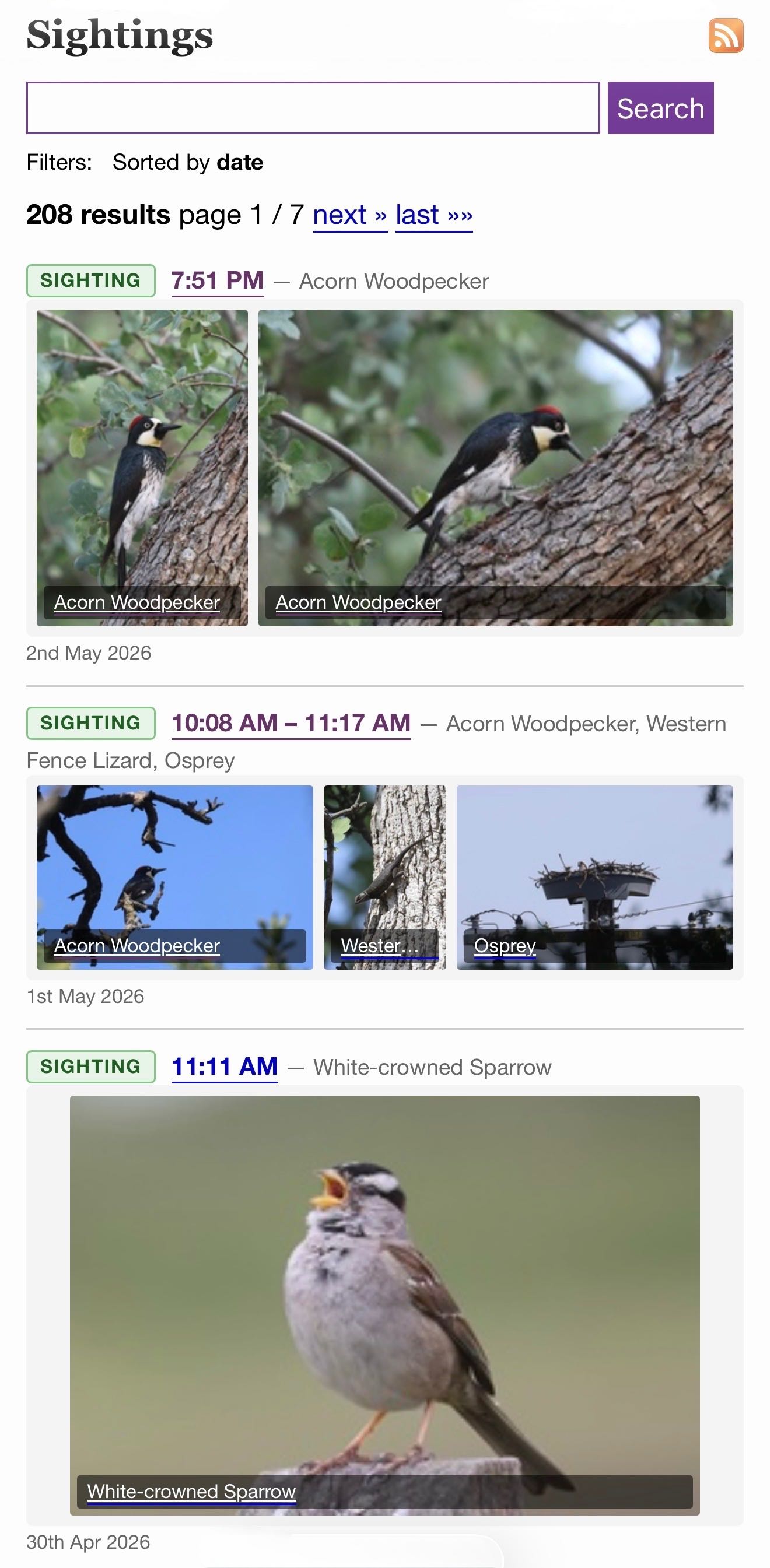
I built this feature on my phone using Claude Code for web, as an extension of my beats system for syndicating external content. Here's the PR and prompt.
As with my other forms of incoming syndicated content sightings show up on the homepage, the date archive pages, and in site search results.
I back-populated over a decade of iNaturalist sightings, which means you that if you search for lemur you'll see my lemur photos from Madagascar in 2019!

I wanted to see my iNaturalist observations - across two separate accounts - grouped by when they occurred. I'm camping this weekend so I built this entirely on my phone using Claude Code for web.
I started by building an inaturalist-clumper Python CLI for fetching and "clumping" observations - by default clumps use observations within 2 hours and 5km of each other.
Then I setup simonw/inaturalist-clumps as a Git scraping repository to run that tool and record the result to clumps.json.
That JSON file is hosted on GitHub, which means it can be fetched by JavaScript using CORS.
Finally I ran this prompt against my simonw/tools repo:
Build inat-sightings.html - an app that does a fetch() against https://raw.githubusercontent.com/simonw/inaturalist-clumps/refs/heads/main/clumps.json and then displays all of the observations on one page using the https://static.inaturalist.org/photos/538073008/small.jpg small.jpg URLs for the thumbnails - with loading=lazy - but when a thumbnail is clicked showing the large.jpg in an HTML modal. Both small and large should include the common species names if available
Codex CLI 0.128.0 adds /goal
(via)
The latest version of OpenAI's Codex CLI coding agent adds their own version of the Ralph loop: you can now set a /goal and Codex will keep on looping until it evaluates that the goal has been completed... or the configured token budget has been exhausted.
It looks like the feature is mainly implemented though the goals/continuation.md and goals/budget_limit.md prompts, which are automatically injected at the end of a turn.
Our evaluation of OpenAI’s GPT-5.5 cyber capabilities. The UK's AI Security Institute previously evaluated Claude Mythos: now they've evaluated GPT-5.5 for finding security vulnerability and found it to be comparable to Mythos, but unlike Mythos it's generally available right now.
It's a common misconception that we can't tell who is using LLM and who is not. I'm sure we didn't catch 100% of LLM-assisted PRs over the past few months, but the kind of mistakes humans make are fundamentally different than LLM hallucinations, making them easy to spot. Furthermore, people who come from the world of agentic coding have a certain digital smell that is not obvious to them but is obvious to those who abstain. It's like when a smoker walks into the room, everybody who doesn't smoke instantly knows it.
I'm not telling you not to smoke, but I am telling you not to smoke in my house.
— Andrew Kelley, Creator of Zig
We need RSS for sharing abundant vibe-coded apps. Matt Webb:
I would love an RSS web feed for all those various tools and apps pages, each item with an “Install” button. (But install to where?)
The lesson here is that when vibe-coding accelerates app development, apps become more personal, more situated, and more frequent. Shipping a tool or a micro-app is less like launching a website and more like posting on a blog.
This inspired me to have Claude add an Atom feed (and icon) to my /elsewhere/tools/ page, which itself is populated by content from my tools.simonwillison.net site.
Zig has one of the most stringent anti-LLM policies of any major open source project:
No LLMs for issues.
No LLMs for pull requests.
No LLMs for comments on the bug tracker, including translation. English is encouraged, but not required. You are welcome to post in your native language and rely on others to have their own translation tools of choice to interpret your words.
The most prominent project written in Zig may be the Bun JavaScript runtime, which was acquired by Anthropic in December 2025 and, unsurprisingly, makes heavy use of AI assistance.
Bun operates its own fork of Zig, and recently achieved a 4x performance improvement on Bun compile after adding "parallel semantic analysis and multiple codegen units to the llvm backend". Here's that code. But @bunjavascript says:
We do not currently plan to upstream this, as Zig has a strict ban on LLM-authored contributions.
(Update: here's a Zig core contributor providing details on why they wouldn't accept that particular patch independent of the LLM issue - parallel semantic analysis is a long planned feature but has implications "for the Zig language itself".)
In Contributor Poker and Zig's AI Ban (via Lobste.rs) Zig Software Foundation VP of Community Loris Cro explains the rationale for this strict ban. It's the best articulation I've seen yet for a blanket ban on LLM-assisted contributions:
In successful open source projects you eventually reach a point where you start getting more PRs than what you’re capable of processing. Given what I mentioned so far, it would make sense to stop accepting imperfect PRs in order to maximize ROI from your work, but that’s not what we do in the Zig project. Instead, we try our best to help new contributors to get their work in, even if they need some help getting there. We don’t do this just because it’s the “right” thing to do, but also because it’s the smart thing to do.
Zig values contributors over their contributions. Each contributor represents an investment by the Zig core team - the primary goal of reviewing and accepting PRs isn't to land new code, it's to help grow new contributors who can become trusted and prolific over time.
LLM assistance breaks that completely. It doesn't matter if the LLM helps you submit a perfect PR to Zig - the time the Zig team spends reviewing your work does nothing to help them add new, confident, trustworthy contributors to their overall project.
Loris explains the name here:
The reason I call it “contributor poker” is because, just like people say about the actual card game, “you play the person, not the cards”. In contributor poker, you bet on the contributor, not on the contents of their first PR.
This makes a lot of sense to me. It relates to an idea I've seen circulating elsewhere: if a PR was mostly written by an LLM, why should a project maintainer spend time reviewing and discussing that PR as opposed to firing up their own LLM to solve the same problem?
LLM 0.32a0 is a major backwards-compatible refactor
I just released LLM 0.32a0, an alpha release of my LLM Python library and CLI tool for accessing LLMs, with some consequential changes that I’ve been working towards for quite a while.
[... 1,874 words]
Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user's query.
— OpenAI Codex base_instructions, for GPT-5.5
Five months in, I think I've decided that I don't want to vibecode — I want professionally managed software companies to use AI coding assistance to make more/better/cheaper software products that they sell to me for money.
— Matthew Yglesias, in a now-deleted Tweet
Introducing talkie: a 13B vintage language model from 1930 (via) New project from Nick Levine, David Duvenaud, and Alec Radford (of GPT, GPT-2, Whisper fame).
talkie-1930-13b-base (53.1 GB) is a "13B language model trained on 260B tokens of historical pre-1931 English text".
talkie-1930-13b-it (26.6 GB) is a checkpoint "finetuned using a novel dataset of instruction-response pairs extracted from pre-1931 reference works", designed to power a chat interface. You can try that out here.
Both models are Apache 2.0 licensed. Since the training data for the base model is entirely out of copyright (the USA copyright cutoff date is currently January 1, 1931), I'm hoping they later decide to release the training data as well.
Update on that: Nick Levine on Twitter:
Will publish more on the corpus in the future (and do our best to share the data or at least scripts to reproduce it).
Their report suggests some fascinating research objectives for this class of model, including:
- How good are these models at predicting the future? "we calculated the surprisingness of short descriptions of historical events to a 13B model trained on pre-1931 text"
- Can these models invent things that are past their knowledge cutoffs? "As Demis Hassabis has asked, could a model trained up to 1911 independently discover General Relativity, as Einstein did in 1915?"
- Can they be taught to program? "Figure 3 (left-hand side) shows an early example of such a test, measuring how well models trained on pre-1931 text can, when given a few demonstration examples of Python programs, write new correct programs."
I have a long-running interest in what I call "vegan models" - LLMs that are trained entirely on licensed or out-of-copyright data. I think the base model here qualifies, but the chat model isn't entirely pure due to the reliance on non-vegan models to help with the fine-tuning - emphasis mine:
First, we generated instruction-response pairs from historical texts with regular structure, such as etiquette manuals, letter-writing manuals, cookbooks, dictionaries, encyclopedias, and poetry and fable collections (see Figure 7), and fine-tuned our base model on them using a simple chat format.
Next, to improve instruction-following abilities, we generated synthetic prompts covering different types of tasks, such as summarizing documents, responding to direct information requests, and continuing multi-turn conversations coherently. We then ran online direct preference optimization on rollouts generated from these prompts, using Claude Sonnet 4.6 as a judge. [...]
Finally, we did another round of supervised fine-tuning, this time on rejection-sampled multi-turn synthetic chats between Claude Opus 4.6 and talkie, to smooth out persistent rough edges in its conversational abilities.
A major challenge in training talkie was avoiding accidental contamination, either from post-1931 text that snuck into the training corpus or from the fine-tuning assistance from modern LLMs introducing anachronistic knowledge to the chat model.
I recently wrote about Mr. Chatterbox, a similar vintage language model project which also had to turn to modern LLMs to create synthetic conversations to help train the chat model.
The talkie team aspire to eventually move beyond this limitation:
While we have tried to post-train talkie free from modern influence, reinforcement learning with AI feedback inevitably shapes talkie’s behavior anachronistically. (The 7B version of talkie emerged from RL speaking in listicles.) As we scale up, we hope to be able to use our vintage base models themselves as judges to enable a fully bootstrapped era-appropriate post-training pipeline.
I couldn't resist hitting the talkie demo with my classic test prompt:
Generate an SVG of a pelican riding a bicycle
It replied:
An SVG of a pelican riding a bicycle was generated in 1860. The pelican was represented as perched on the saddle, with its long bill pointed forward, and its legs astride the handles. The idea was suggested by the fact that pelicans are sometimes seen fishing on horseback, on the banks of the Rhine.
Tracking the history of the now-deceased OpenAI Microsoft AGI clause
For many years, Microsoft and OpenAI’s relationship has included a weird clause saying that, should AGI be achieved, Microsoft’s commercial IP rights to OpenAI’s technology would be null and void. That clause appeared to end today. I decided to try and track its expression over time on openai.com.
[... 691 words]@scottjla on Twitter in reply to my pelican riding a bicycle benchmark:
I feel like we need to stack these tests now

I checked to confirm that the model (ChatGPT Images 2.0) added the "WHY ARE YOU LIKE THIS" sign of its own accord and it did - the prompt Scott used was:
Create an image of a horse riding an astronaut, where the astronaut is riding a pelican that is riding a bicycle. It looks very chaotic but they all just manage to balance on top of each other
Since GPT-5.4, we’ve unified Codex and the main model into a single system, so there’s no separate coding line anymore.
GPT-5.5 takes this further, with strong gains in agentic coding, computer use, and any task on a computer.
— Romain Huet, confirming OpenAI won't release a GPT-5.5-Codex model
GPT-5.5 prompting guide. Now that GPT-5.5 is available in the API, OpenAI have released a wealth of useful tips on how best to prompt the new model.
Here's a neat trick they recommend for applications that might spend considerable time thinking before returning a user-visible response:
Before any tool calls for a multi-step task, send a short user-visible update that acknowledges the request and states the first step. Keep it to one or two sentences.
I've already noticed their Codex app doing this, and it does make longer running tasks feel less like the model has crashed.
OpenAI suggest running the following in Codex to upgrade your existing code using advice embedded in their openai-docs skill:
$openai-docs migrate this project to gpt-5.5
The upgrade guide the coding agent will follow is this one, which even includes light instructions on how to rewrite prompts to better fit the model.
Also relevant is the Using GPT-5.5 guide, which opens with this warning:
To get the most out of GPT-5.5, treat it as a new model family to tune for, not a drop-in replacement for
gpt-5.2orgpt-5.4. Begin migration with a fresh baseline instead of carrying over every instruction from an older prompt stack. Start with the smallest prompt that preserves the product contract, then tune reasoning effort, verbosity, tool descriptions, and output format against representative examples.
Interesting to see OpenAI recommend starting from scratch rather than trusting that existing prompts optimized for previous models will continue to work effectively with GPT-5.5.
The people do not yearn for automation (via) This written and video essay by Nilay Patel explores why AI is unpopular with the general public even as usage numbers for ChatGPT continue to skyrocket.
It’s a superb piece of commentary, and something I expect I’ll be thinking about for a long time to come.
Nilay’s core idea is that people afflicted with “software brain” - who see the world as something to be automated as much as possible, and attempt to model everything in terms of information flows and data - are becoming detached from everyone else.
[…] software brain has ruled the business world for a long time. AI has just made it easier than ever for more people to make more software than ever before — for every kind of business to automate big chunks of itself with software. It’s everywhere: the absolute cutting edge of advertising and marketing is automation with AI. It’s not being a creative.
But: not everything is a business. Not everything is a loop! The entire human experience cannot be captured in a database. That’s the limit of software brain. That’s why people hate AI. It flattens them.
Regular people don’t see the opportunity to write code as an opportunity at all. The people do not yearn for automation. I’m a full-on smart home sicko; the lights and shades and climate controls of my house are automated in dozens of ways. But huge companies like Apple, Google and Amazon have struggled for over a decade now to make regular people care about smart home automation at all. And they just don’t.
DeepSeek V4—almost on the frontier, a fraction of the price

Chinese AI lab DeepSeek’s last model release was V3.2 (and V3.2 Speciale) last December. They just dropped the first of their hotly anticipated V4 series in the shape of two preview models, DeepSeek-V4-Pro and DeepSeek-V4-Flash.
[... 703 words]An update on recent Claude Code quality reports (via) It turns out the high volume of complaints that Claude Code was providing worse quality results over the past two months was grounded in real problems.
The models themselves were not to blame, but three separate issues in the Claude Code harness caused complex but material problems which directly affected users.
Anthropic's postmortem describes these in detail. This one in particular stood out to me:
On March 26, we shipped a change to clear Claude's older thinking from sessions that had been idle for over an hour, to reduce latency when users resumed those sessions. A bug caused this to keep happening every turn for the rest of the session instead of just once, which made Claude seem forgetful and repetitive.
I frequently have Claude Code sessions which I leave for an hour (or often a day or longer) before returning to them. Right now I have 11 of those (according to ps aux | grep 'claude ') and that's after closing down dozens more the other day.
I estimate I spend more time prompting in these "stale" sessions than sessions that I've recently started!
If you're building agentic systems it's worth reading this article in detail - the kinds of bugs that affect harnesses are deeply complicated, even if you put aside the inherent non-deterministic nature of the models themselves.
Extract PDF text in your browser with LiteParse for the web
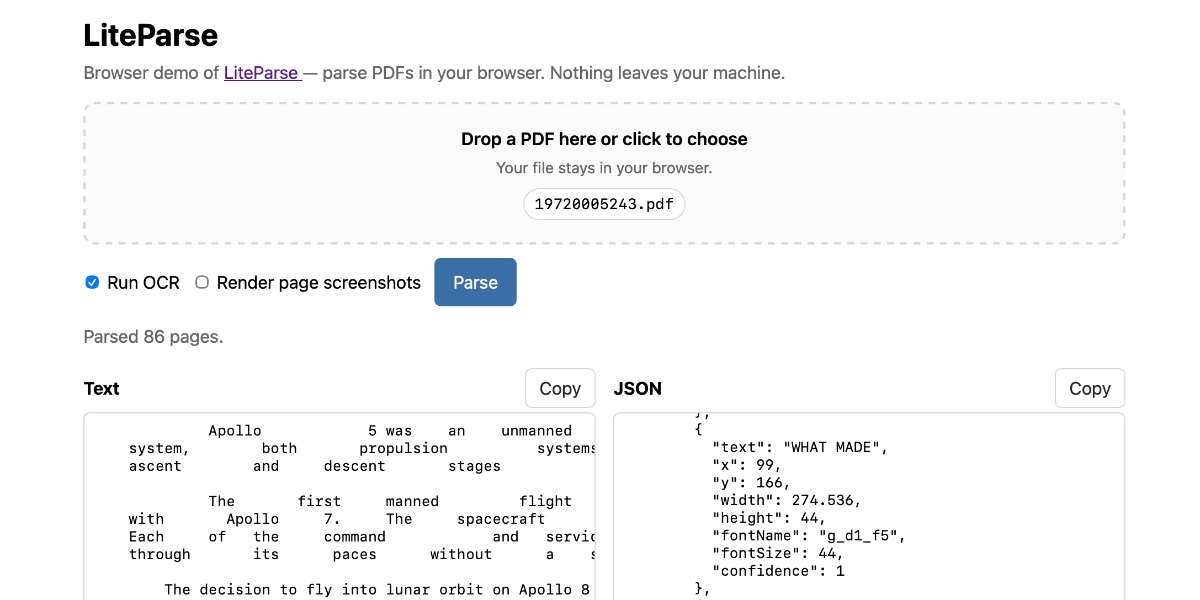
LlamaIndex have a most excellent open source project called LiteParse, which provides a Node.js CLI tool for extracting text from PDFs. I got a version of LiteParse working entirely in the browser, using most of the same libraries that LiteParse uses to run in Node.js.
[... 2,089 words]A pelican for GPT-5.5 via the semi-official Codex backdoor API

GPT-5.5 is out. It’s available in OpenAI Codex and is rolling out to paid ChatGPT subscribers. I’ve had some preview access and found it to be a fast, effective and highly capable model. As is usually the case these days, it’s hard to put into words what’s good about it—I ask it to build things and it builds exactly what I ask for!
[... 884 words]Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model (via) Big claims from Qwen about their latest open weight model:
Qwen3.6-27B delivers flagship-level agentic coding performance, surpassing the previous-generation open-source flagship Qwen3.5-397B-A17B (397B total / 17B active MoE) across all major coding benchmarks.
On Hugging Face Qwen3.5-397B-A17B is 807GB, this new Qwen3.6-27B is 55.6GB.
I tried it out with the 16.8GB Unsloth Qwen3.6-27B-GGUF:Q4_K_M quantized version and llama-server using this recipe by benob on Hacker News, after first installing llama-server using brew install llama.cpp:
llama-server \
-hf unsloth/Qwen3.6-27B-GGUF:Q4_K_M \
--no-mmproj \
--fit on \
-np 1 \
-c 65536 \
--cache-ram 4096 -ctxcp 2 \
--jinja \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.0 \
--presence-penalty 0.0 \
--repeat-penalty 1.0 \
--reasoning on \
--chat-template-kwargs '{"preserve_thinking": true}'
On first run that saved the ~17GB model to ~/.cache/huggingface/hub/models--unsloth--Qwen3.6-27B-GGUF.
Here's the transcript for "Generate an SVG of a pelican riding a bicycle". This is an outstanding result for a 16.8GB local model:

Performance numbers reported by llama-server:
- Reading: 20 tokens, 0.4s, 54.32 tokens/s
- Generation: 4,444 tokens, 2min 53s, 25.57 tokens/s
For good measure, here's Generate an SVG of a NORTH VIRGINIA OPOSSUM ON AN E-SCOOTER (run previously with GLM-5.1):

That one took 6,575 tokens, 4min 25s, 24.74 t/s.