22 posts tagged “ai-ethics” and “training-data”
Ethical concerns related to building and using AI systems.
2025
Anthropic to pay $1.5 billion to authors in landmark AI settlement. I wrote about the details of this case when it was found that Anthropic's training on book content was fair use, but they needed to have purchased individual copies of the books first... and they had seeded their collection with pirated ebooks from Books3, PiLiMi and LibGen.
The remaining open question from that case was the penalty for pirating those 500,000 books. That question has now been resolved in a settlement:
Anthropic has reached an agreement to pay “at least” a staggering $1.5 billion, plus interest, to authors to settle its class-action lawsuit. The amount breaks down to smaller payouts expected to be approximately $3,000 per book or work.
It's wild to me that a $1.5 billion settlement can feel like a win for Anthropic, but given that it's undisputed that they downloaded pirated books (as did Meta and likely many other research teams) the maximum allowed penalty was $150,000 per book, so $3,000 per book is actually a significant discount.
As far as I can tell this case sets a precedent for Anthropic's more recent approach of buying millions of (mostly used) physical books and destructively scanning them for training as covered by "fair use". I'm not sure if other in-flight legal cases will find differently.
To be clear: it appears it is legal, at least in the USA, to buy a used copy of a physical book (used = the author gets nothing), chop the spine off, scan the pages, discard the paper copy and then train on the scanned content. The transformation from paper to scan is "fair use".
If this does hold it's going to be a great time to be a bulk retailer of used books!
Update: The official website for the class action lawsuit is www.anthropiccopyrightsettlement.com:
In the coming weeks, and if the court preliminarily approves the settlement, the website will provide to find a full and easily searchable listing of all works covered by the settlement.
In the meantime the Atlantic have a search engine to see if your work was included in LibGen, one of the pirated book sources involved in this case.
I had a look and it turns out the book I co-authored with 6 other people back in 2007 The Art & Science of JavaScript is in there, so maybe I'm due for 1/7th of one of those $3,000 settlements! (Update 4th October: you can now search for affected titles and mine isn't in there.)
Update 2: Here's an interesting detail from the Washington Post story about the settlement:
Anthropic said in the settlement that the specific digital copies of books covered by the agreement were not used in the training of its commercially released AI models.
Update 3: I'm not confident that destroying the scanned books is a hard requirement here - I got that impression from this section of the summary judgment in June:
Here, every purchased print copy was copied in order to save storage space and to enable searchability as a digital copy. The print original was destroyed. One replaced the other. And, there is no evidence that the new, digital copy was shown, shared, or sold outside the company. This use was even more clearly transformative than those in Texaco, Google, and Sony Betamax (where the number of copies went up by at least one), and, of course, more transformative than those uses rejected in Napster (where the number went up by “millions” of copies shared for free with others).
Reddit will block the Internet Archive. Well this sucks. Jay Peters for the Verge:
Reddit says that it has caught AI companies scraping its data from the Internet Archive’s Wayback Machine, so it’s going to start blocking the Internet Archive from indexing the vast majority of Reddit. The Wayback Machine will no longer be able to crawl post detail pages, comments, or profiles; instead, it will only be able to index the Reddit.com homepage, which effectively means Internet Archive will only be able to archive insights into which news headlines and posts were most popular on a given day.
Anthropic wins a major fair use victory for AI — but it’s still in trouble for stealing books. Major USA legal news for the AI industry today. Judge William Alsup released a "summary judgement" (a legal decision that results in some parts of a case skipping a trial) in a lawsuit between five authors and Anthropic concerning the use of their books in training data.
The judgement itself is a very readable 32 page PDF, and contains all sorts of interesting behind-the-scenes details about how Anthropic trained their models.
The facts of the complaint go back to the very beginning of the company. Anthropic was founded by a group of ex-OpenAI researchers in February 2021. According to the judgement:
So, in January or February 2021, another Anthropic cofounder, Ben Mann, downloaded Books3, an online library of 196,640 books that he knew had been assembled from unauthorized copies of copyrighted books — that is, pirated. Anthropic's next pirated acquisitions involved downloading distributed, reshared copies of other pirate libraries. In June 2021, Mann downloaded in this way at least five million copies of books from Library Genesis, or LibGen, which he knew had been pirated. And, in July 2022, Anthropic likewise downloaded at least two million copies of books from the Pirate Library Mirror, or PiLiMi, which Anthropic knew had been pirated.
Books3 was also listed as part of the training data for Meta's first LLaMA model!
Anthropic apparently used these sources of data to help build an internal "research library" of content that they then filtered and annotated and used in training runs.
Books turned out to be a very valuable component of the "data mix" to train strong models. By 2024 Anthropic had a new approach to collecting them: purchase and scan millions of print books!
To find a new way to get books, in February 2024, Anthropic hired the former head of partnerships for Google's book-scanning project, Tom Turvey. He was tasked with obtaining "all the books in the world" while still avoiding as much "legal/practice/business slog" as possible (Opp. Exhs. 21, 27). [...] Turvey and his team emailed major book distributors and retailers about bulk-purchasing their print copies for the AI firm's "research library" (Opp. Exh. 22 at 145; Opp. Exh. 31 at -035589). Anthropic spent many millions of dollars to purchase millions of print books, often in used condition. Then, its service providers stripped the books from their bindings, cut their pages to size, and scanned the books into digital form — discarding the paper originals. Each print book resulted in a PDF copy containing images of the scanned pages with machine-readable text (including front and back cover scans for softcover books).
The summary judgement found that these scanned books did fall under fair use, since they were transformative versions of the works and were not shared outside of the company. The downloaded ebooks did not count as fair use, and it looks like those will be the subject of a forthcoming jury trial.
Here's that section of the decision:
Before buying books for its central library, Anthropic downloaded over seven million pirated copies of books, paid nothing, and kept these pirated copies in its library even after deciding it would not use them to train its AI (at all or ever again). Authors argue Anthropic should have paid for these pirated library copies (e.g, Tr. 24–25, 65; Opp. 7, 12–13). This order agrees.
The most important aspect of this case is the question of whether training an LLM on unlicensed data counts as "fair use". The judge found that it did. The argument for why takes up several pages of the document but this seems like a key point:
Everyone reads texts, too, then writes new texts. They may need to pay for getting their hands on a text in the first instance. But to make anyone pay specifically for the use of a book each time they read it, each time they recall it from memory, each time they later draw upon it when writing new things in new ways would be unthinkable. For centuries, we have read and re-read books. We have admired, memorized, and internalized their sweeping themes, their substantive points, and their stylistic solutions to recurring writing problems.
The judge who signed this summary judgement is an interesting character: William Haskell Alsup (yes, his middle name really is Haskell) presided over jury trials for Oracle America, Inc. v. Google, Inc in 2012 and 2016 where he famously used his hobbyist BASIC programming experience to challenge claims made by lawyers in the case.
Update 6th September 2025: Anthropic settled the resulting class action lawsuit for $1.5 billion.
Disney and Universal Sue AI Company Midjourney for Copyright Infringement. This is a big one. It's very easy to demonstrate that Midjourney will output images of copyright protected characters (like Darth Vader or Yoda) based on a short text prompt.
There are already dozens of copyright lawsuits against AI companies winding through the US court system—including a class action lawsuit visual artists brought against Midjourney in 2023—but this is the first time major Hollywood studios have jumped into the fray.
Here's the lawsuit on Document Cloud - 110 pages, most of which are examples of supposedly infringing images.

Comma v0.1 1T and 2T—7B LLMs trained on openly licensed text
It’s been a long time coming, but we finally have some promising LLMs to try out which are trained entirely on openly licensed text!
[... 656 words]Baroness Kidron’s speech regarding UK AI legislation (via) Barnstormer of a speech by UK film director and member of the House of Lords Baroness Kidron. This is the Hansard transcript but you can also watch the video on parliamentlive.tv. She presents a strong argument against the UK's proposed copyright and AI reform legislation, which would provide a copyright exemption for AI training with a weak-toothed opt-out mechanism.
The Government are doing this not because the current law does not protect intellectual property rights, nor because they do not understand the devastation it will cause, but because they are hooked on the delusion that the UK's best interests and economic future align with those of Silicon Valley.
She throws in some cleverly selected numbers:
The Prime Minister cited an IMF report that claimed that, if fully realised, the gains from AI could be worth up to an average of £47 billion to the UK each year over a decade. He did not say that the very same report suggested that unemployment would increase by 5.5% over the same period. This is a big number—a lot of jobs and a very significant cost to the taxpayer. Nor does that £47 billion account for the transfer of funds from one sector to another. The creative industries contribute £126 billion per year to the economy. I do not understand the excitement about £47 billion when you are giving up £126 billion.
Mentions DeepSeek:
Before I sit down, I will quickly mention DeepSeek, a Chinese bot that is perhaps as good as any from the US—we will see—but which will certainly be a potential beneficiary of the proposed AI scraping exemption. Who cares that it does not recognise Taiwan or know what happened in Tiananmen Square? It was built for $5 million and wiped $1 trillion off the value of the US AI sector. The uncertainty that the Government claim is not an uncertainty about how copyright works; it is uncertainty about who will be the winners and losers in the race for AI.
And finishes with this superb closing line:
The spectre of AI does nothing for growth if it gives away what we own so that we can rent from it what it makes.
According to Ed Newton-Rex the speech was effective:
She managed to get the House of Lords to approve her amendments to the Data (Use and Access) Bill, which among other things requires overseas gen AI companies to respect UK copyright law if they sell their products in the UK. (As a reminder, it is illegal to train commercial gen AI models on ©️ work without a licence in the UK.)
What's astonishing is that her amendments passed despite @UKLabour reportedly being whipped to vote against them, and the Conservatives largely abstaining. Essentially, Labour voted against the amendments, and everyone else who voted voted to protect copyright holders.
(Is it true that in the UK it's currently "illegal to train commercial gen AI models on ©️ work"? From points 44, 45 and 46 of this Copyright and AI: Consultation document it seems to me that the official answer is "it's complicated".)
I'm trying to understand if this amendment could make existing products such as ChatGPT, Claude and Gemini illegal to sell in the UK. How about usage of open weight models?
According to public financial documents from its parent company IAC and first reported by Adweek OpenAI is paying around $16 million per year to license content [from Dotdash Meredith].
That is no doubt welcome incremental revenue, and you could call it “lucrative” in the sense of having a fat margin, as OpenAI is almost certainly paying for content that was already being produced. But to put things into perspective, Dotdash Meredith is on course to generate over $1.5 billion in revenues in 2024, more than a third of it from print. So the OpenAI deal is equal to about 1% of the publisher’s total revenue.
2024
New Pleias 1.0 LLMs trained exclusively on openly licensed data (via) I wrote about the Common Corpus public domain dataset back in March. Now Pleias, the team behind Common Corpus, have released the first family of models that are:
[...] trained exclusively on open data, meaning data that are either non-copyrighted or are published under a permissible license.
There's a lot to absorb here. The Pleias 1.0 family comes in three base model sizes: 350M, 1.2B and 3B. They've also released two models specialized for multi-lingual RAG: Pleias-Pico (350M) and Pleias-Nano (1.2B).
Here's an official GGUF for Pleias-Pico.
I'm looking forward to seeing benchmarks from other sources, but Pleias ran their own custom multilingual RAG benchmark which had their Pleias-nano-1.2B-RAG model come in between Llama-3.2-Instruct-3B and Llama-3.2-Instruct-8B.
The 350M and 3B models were trained on the French government's Jean Zay supercomputer. Pleias are proud of their CO2 footprint for training the models - 0.5, 4 and 16 tCO2eq for the three models respectively, which they compare to Llama 3.2,s reported figure of 133 tCO2eq.
How clean is the training data from a licensing perspective? I'm confident people will find issues there - truly 100% public domain data remains a rare commodity. So far I've seen questions raised about the GitHub source code data (most open source licenses have attribution requirements) and Wikipedia (CC BY-SA, another attribution license). Plus this from the announcement:
To supplement our corpus, we have generated 30B+ words synthetically with models allowing for outputs reuse.
If those models were themselves trained on unlicensed data this could be seen as a form of copyright laundering.
Releasing the largest multilingual open pretraining dataset (via) Common Corpus is a new "open and permissible licensed text dataset, comprising over 2 trillion tokens (2,003,039,184,047 tokens)" released by French AI Lab PleIAs.
This appears to be the largest available corpus of openly licensed training data:
- 926,541,096,243 tokens of public domain books, newspapers, and Wikisource content
- 387,965,738,992 tokens of government financial and legal documents
- 334,658,896,533 tokens of open source code from GitHub
- 221,798,136,564 tokens of academic content from open science repositories
- 132,075,315,715 tokens from Wikipedia, YouTube Commons, StackExchange and other permissively licensed web sources
It's majority English but has significant portions in French and German, and some representation for Latin, Dutch, Italian, Polish, Greek and Portuguese.
I can't wait to try some LLMs trained exclusively on this data. Maybe we will finally get a GPT-4 class model that isn't trained on unlicensed copyrighted data.
Leaked Documents Show Nvidia Scraping ‘A Human Lifetime’ of Videos Per Day to Train AI.
Samantha Cole at 404 Media reports on a huge leak of internal NVIDIA communications - mainly from a Slack channel - revealing details of how they have been collecting video training data for a new video foundation model called Cosmos. The data is mostly from YouTube, downloaded via yt-dlp using a rotating set of AWS IP addresses and consisting of millions (maybe even hundreds of millions) of videos.
The fact that companies scrape unlicensed data to train models isn't at all surprising. This article still provides a fascinating insight into what model training teams care about, with details like this from a project update via email:
As we measure against our desired distribution focus for the next week remains on cinematic, drone footage, egocentric, some travel and nature.
Or this from Slack:
Movies are actually a good source of data to get gaming-like 3D consistency and fictional content but much higher quality.
My intuition here is that the backlash against scraped video data will be even more intense than for static images used to train generative image models. Video is generally more expensive to create, and video creators (such as Marques Brownlee / MKBHD, who is mentioned in a Slack message here as a potential source of "tech product neviews - super high quality") have a lot of influence.
There was considerable uproar a few weeks ago over this story about training against just captions scraped from YouTube, and now we have a much bigger story involving the actual video content itself.
Apple, Nvidia, Anthropic Used Thousands of Swiped YouTube Videos to Train AI. This article has been getting a lot of attention over the past couple of days.
The story itself is nothing new: the Pile is four years old now, and has been widely used for training LLMs since before anyone even cared what an LLM was. It turns out one of the components of the Pile is a set of ~170,000 YouTube video captions (just the captions, not the actual video) and this story by Annie Gilbertson and Alex Reisner highlights that and interviews some of the creators who were included in the data, as well as providing a search tool for seeing if a specific creator has content that was included.
What's notable is the response. Marques Brownlee (19m subscribers) posted a video about it. Abigail Thorn (Philosophy Tube, 1.57m subscribers) tweeted this:
Very sad to have to say this - an AI company called EleutherAI stole tens of thousands of YouTube videos - including many of mine. I’m one of the creators Proof News spoke to. The stolen data was sold to Apple, Nvidia, and other companies to build AI
When I was told about this I lay on the floor and cried, it’s so violating, it made me want to quit writing forever. The reason I got back up was because I know my audience come to my show for real connection and ideas, not cheapfake AI garbage, and I know they’ll stay with me
Framing the data as "sold to Apple..." is a slight misrepresentation here - EleutherAI have been giving the Pile away for free since 2020. It's a good illustration of the emotional impact here though: many creative people do not want their work used in this way, especially without their permission.
It's interesting seeing how attitudes to this stuff change over time. Four years ago the fact that a bunch of academic researchers were sharing and training models using 170,000 YouTube subtitles would likely not have caught any attention at all. Today, people care!
Listen to the AI-generated ripoff songs that got Udio and Suno sued. Jason Koebler reports on the lawsuit filed today by the RIAA against Udio and Suno, the two leading generative music startups.
The lawsuit includes examples of prompts that the record labels used to recreate famous songs that were almost certainly included in the (undisclosed) training data. Jason collected some of these together into a three minute video, and the result in pretty damning. Arguing "fair use" isn't going to be easy here.
It is in the public good to have AI produce quality and credible (if ‘hallucinations’ can be overcome) output. It is in the public good that there be the creation of original quality, credible, and artistic content. It is not in the public good if quality, credible content is excluded from AI training and output OR if quality, credible content is not created.
One of the core constitutional principles that guides our AI model development is privacy. We do not train our generative models on user-submitted data unless a user gives us explicit permission to do so. To date we have not used any customer or user-submitted data to train our generative models.
Releasing Common Corpus: the largest public domain dataset for training LLMs (via) Released today. 500 billion words from "a wide diversity of cultural heritage initiatives". 180 billion words of English, 110 billion of French, 30 billion of German, then Dutch, Spanish and Italian.
Includes quite a lot of US public domain data - 21 million digitized out-of-copyright newspapers (or do they mean newspaper articles?)
This is only an initial part of what we have collected so far, in part due to the lengthy process of copyright duration verification. In the following weeks and months, we’ll continue to publish many additional datasets also coming from other open sources, such as open data or open science.
Coordinated by French AI startup Pleias and supported by the French Ministry of Culture, among others.
I can't wait to try a model that's been trained on this.
2023
I’ve resigned from my role leading the Audio team at Stability AI, because I don’t agree with the company’s opinion that training generative AI models on copyrighted works is ‘fair use’.
[...] I disagree because one of the factors affecting whether the act of copying is fair use, according to Congress, is “the effect of the use upon the potential market for or value of the copyrighted work”. Today’s generative AI models can clearly be used to create works that compete with the copyrighted works they are trained on. So I don’t see how using copyrighted works to train generative AI models of this nature can be considered fair use.
But setting aside the fair use argument for a moment — since ‘fair use’ wasn’t designed with generative AI in mind — training generative AI models in this way is, to me, wrong. Companies worth billions of dollars are, without permission, training generative AI models on creators’ works, which are then being used to create new content that in many cases can compete with the original works.
mitsua-diffusion-one (via) “Mitsua Diffusion One is a latent text-to-image diffusion model, which is a successor of Mitsua Diffusion CC0. This model is trained from scratch using only public domain/CC0 or copyright images with permission for use.” I’ve been talking about how much I’d like to try out a “vegan” AI model trained entirely on out-of-copyright images for ages, and here one is! It looks like the training data mainly came from CC0 art gallery collections such as the Metropolitan Museum of Art Open Access.
Don’t trust AI to talk accurately about itself: Bard wasn’t trained on Gmail
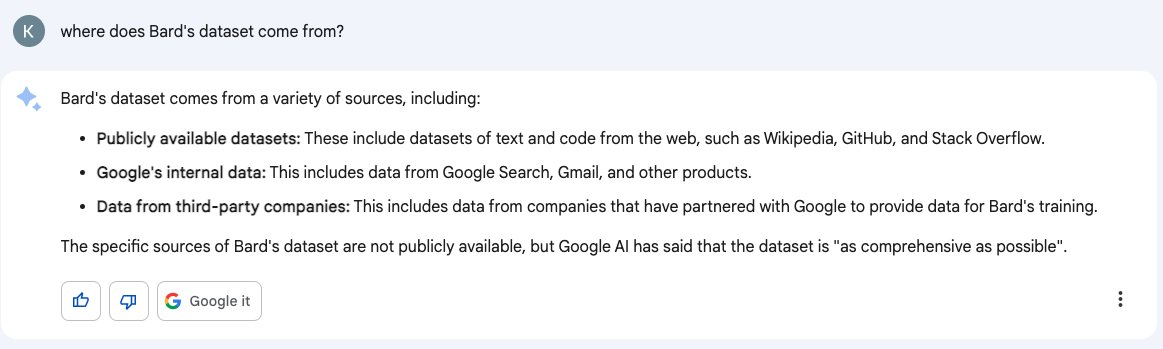
Earlier this month I wrote about how ChatGPT can’t access the internet, even though it really looks like it can. Consider this part two in the series. Here’s another common and non-intuitive mistake people make when interacting with large language model AI systems: asking them questions about themselves.
[... 1,950 words]Adobe made an AI image generator — and says it didn’t steal artists’ work to do it. Adobe Firefly is a brand new text-to-image model which Adobe claim was trained entirely on fully licensed imagery—either out of copyright, specially licensed or part of the existing Adobe Stock library. I’m sure they have the license, but I still wouldn’t be surprised to hear complaints from artists who licensed their content to Adobe Stock who didn’t anticipate it being used for model training.
Exploring MusicCaps, the evaluation data released to accompany Google’s MusicLM text-to-music model
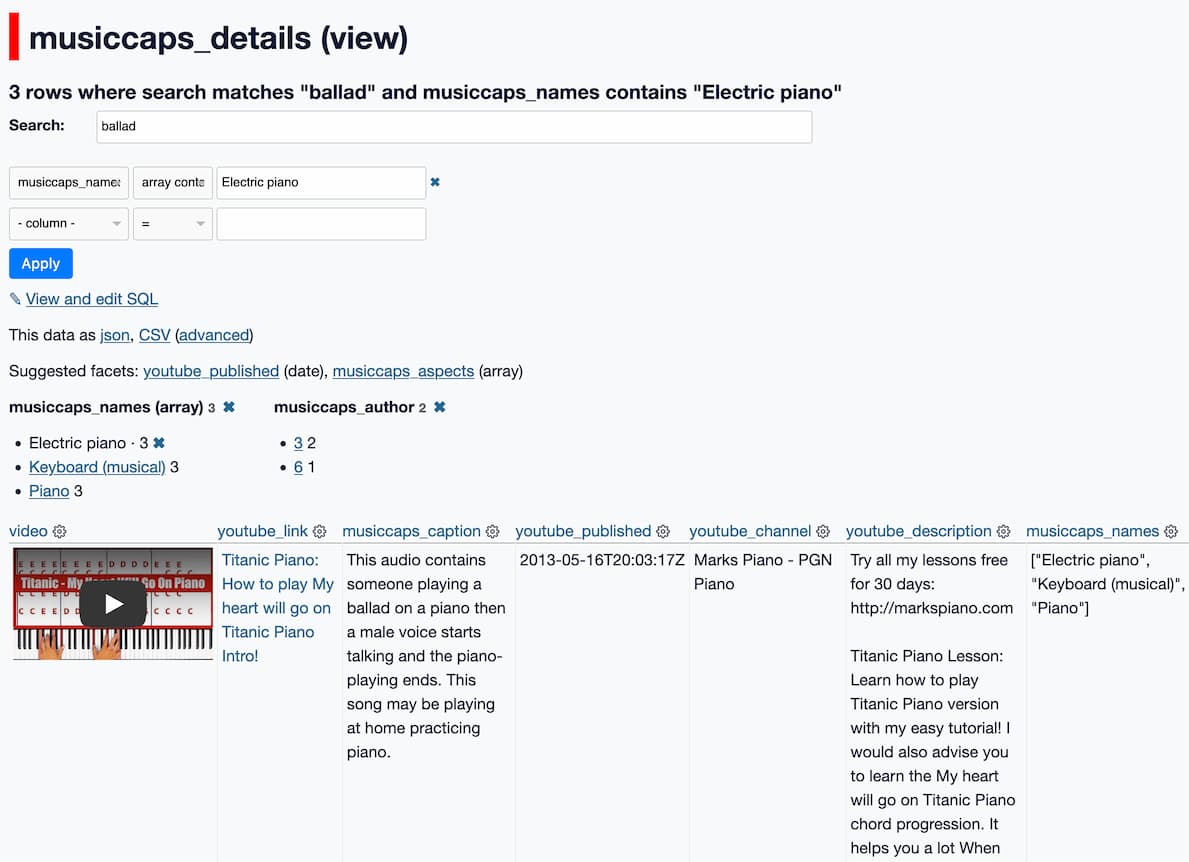
Google Research just released MusicLM: Generating Music From Text. It’s a new generative AI model that takes a descriptive prompt and produces a “high-fidelity” music track. Here’s the paper (and a more readable version using arXiv Vanity).
[... 1,323 words]2022
Exploring 10m scraped Shutterstock videos used to train Meta’s Make-A-Video text-to-video model
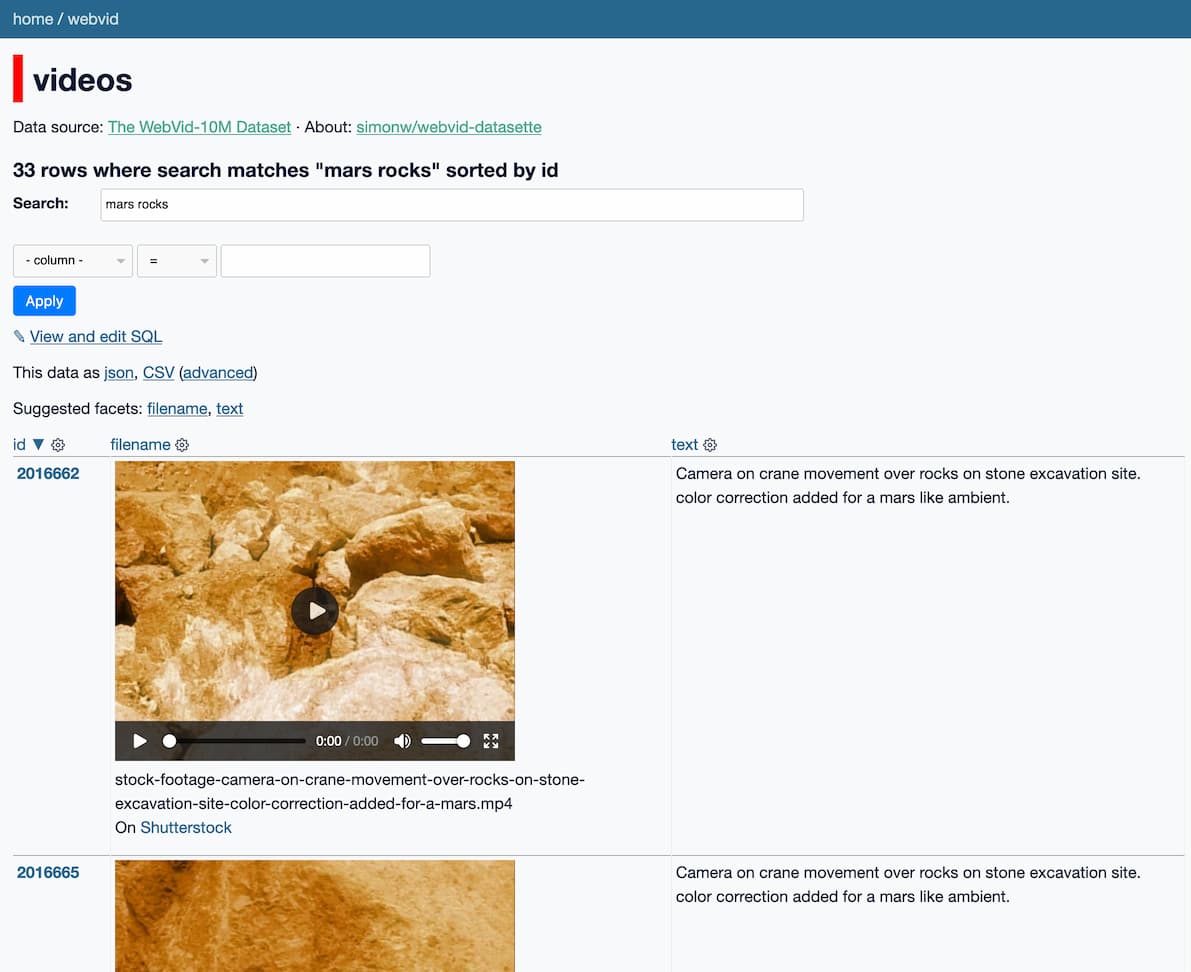
Make-A-Video is a new “state-of-the-art AI system that generates videos from text” from Meta AI. It looks incredible—it really is DALL-E / Stable Diffusion for video. And it appears to have been trained on 10m video preview clips scraped from Shutterstock.
[... 923 words]Exploring the training data behind Stable Diffusion
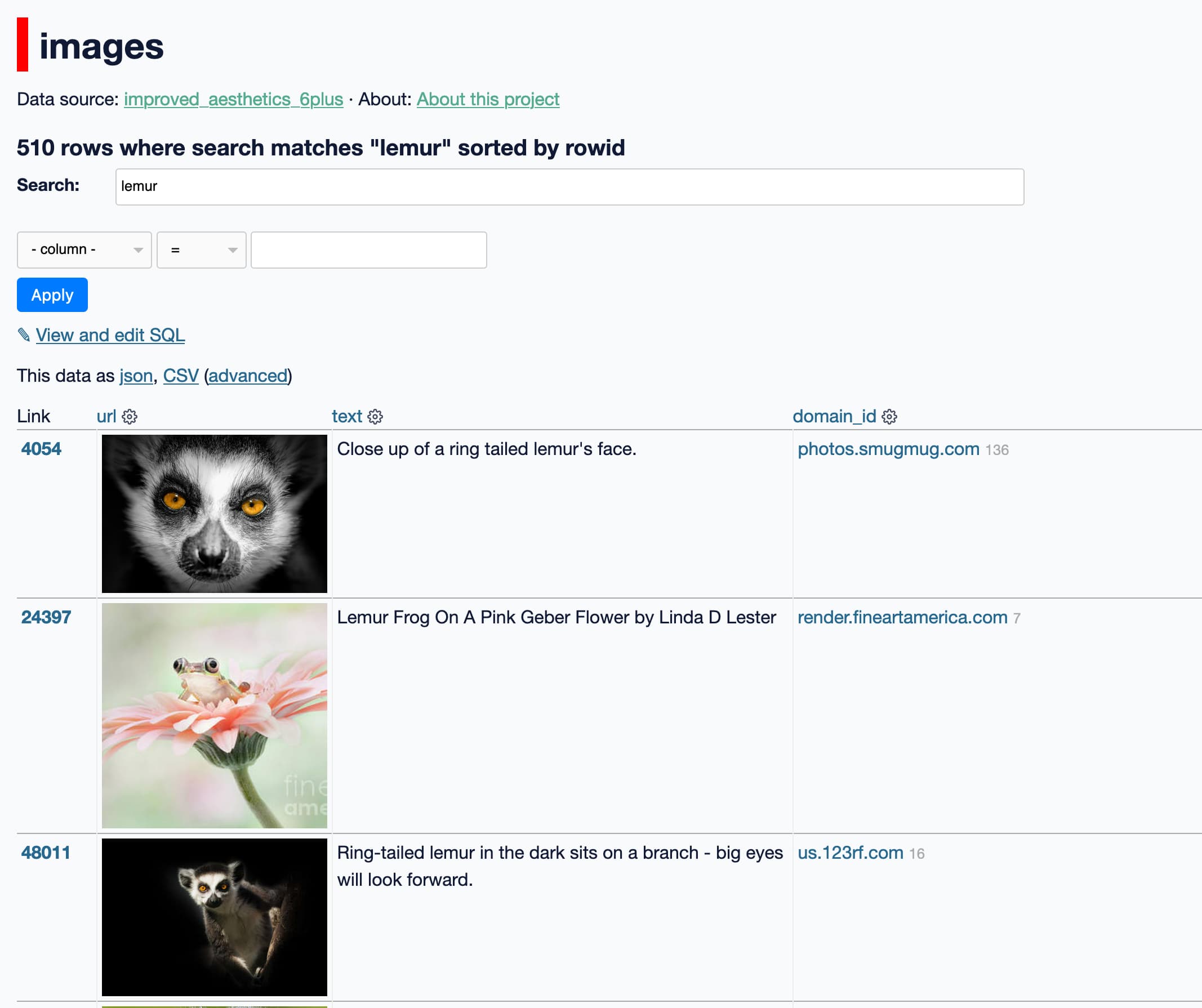
Two weeks ago, the Stable Diffusion image generation model was released to the public. I wrote about this last week, in Stable Diffusion is a really big deal—a post which has since become one of the top ten results for “stable diffusion” on Google and shown up in all sorts of different places online.
[... 2,897 words]