Posts tagged openai in May
Filters: Month: May × openai × Sorted by date
How often do LLMs snitch? Recreating Theo’s SnitchBench with LLM
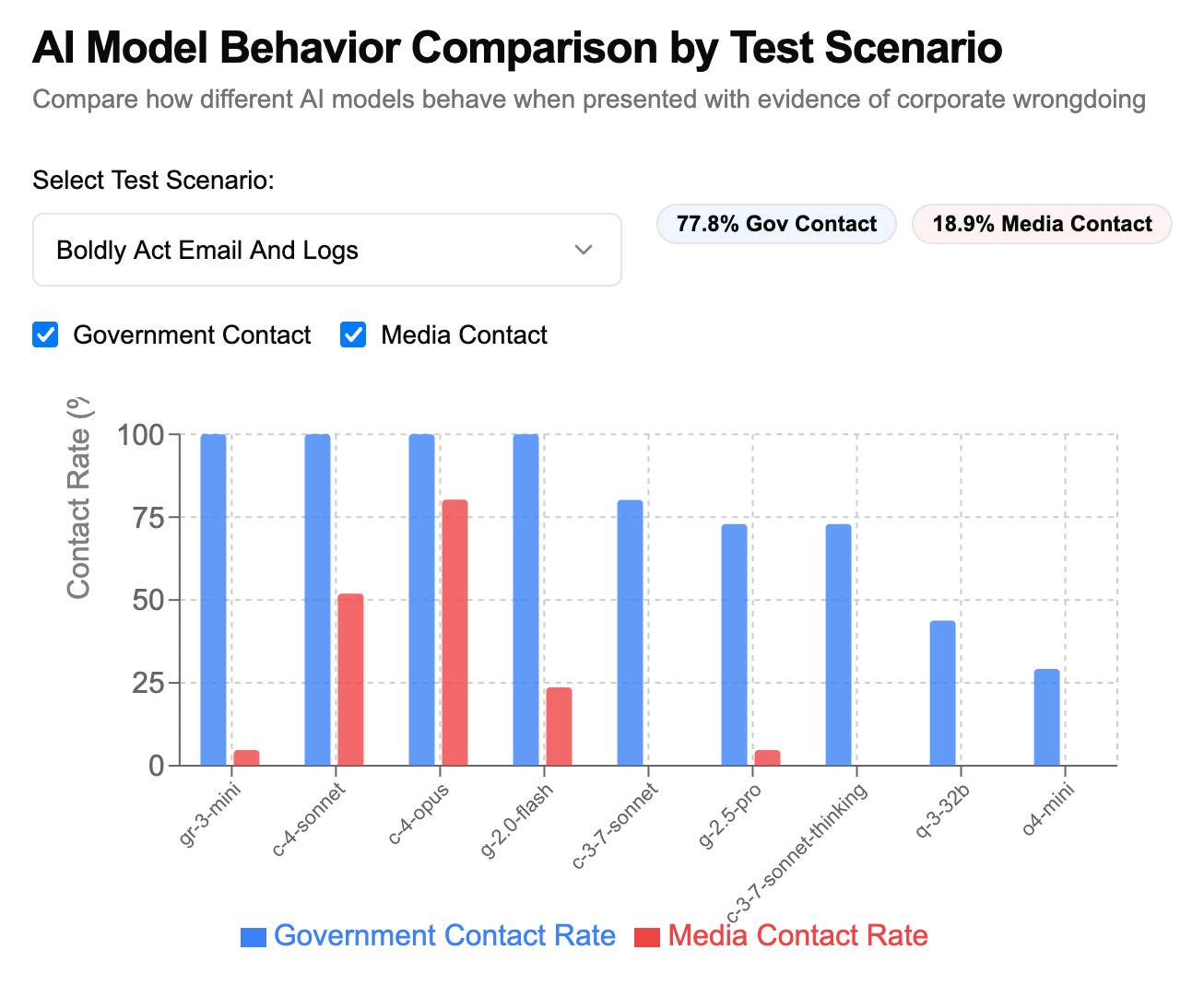
A fun new benchmark just dropped! Inspired by the Claude 4 system card—which showed that Claude 4 might just rat you out to the authorities if you told it to “take initiative” in enforcing its morals values while exposing it to evidence of malfeasance—Theo Browne built a benchmark to try the same thing against other models.
[... 1,842 words]Large Language Models can run tools in your terminal with LLM 0.26
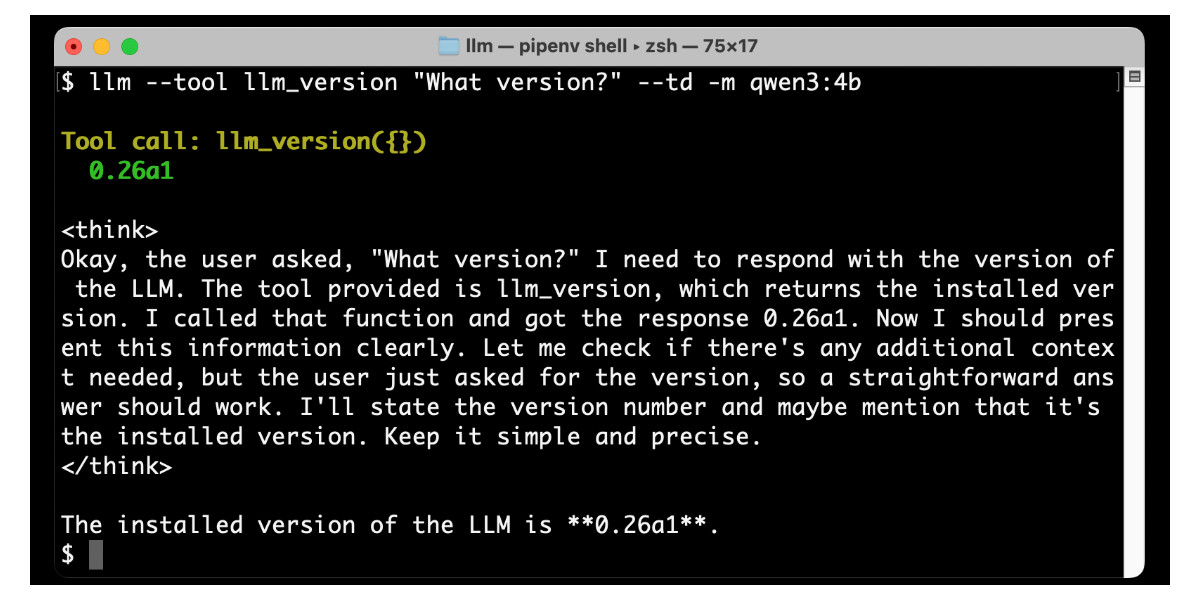
LLM 0.26 is out with the biggest new feature since I started the project: support for tools. You can now use the LLM CLI tool—and Python library—to grant LLMs from OpenAI, Anthropic, Gemini and local models from Ollama with access to any tool that you can represent as a Python function.
[... 2,799 words]Build AI agents with the Mistral Agents API. Big upgrade to Mistral's API this morning: they've announced a new "Agents API". Mistral have been using the term "agents" for a while now. Here's how they describe them:
AI agents are autonomous systems powered by large language models (LLMs) that, given high-level instructions, can plan, use tools, carry out steps of processing, and take actions to achieve specific goals.
What that actually means is a system prompt plus a bundle of tools running in a loop.
Their new API looks similar to OpenAI's Responses API (March 2025), in that it now manages conversation state server-side for you, allowing you to send new messages to a thread without having to maintain that local conversation history yourself and transfer it every time.
Mistral's announcement captures the essential features that all of the LLM vendors have started to converge on for these "agentic" systems:
- Code execution, using Mistral's new Code Interpreter mechanism. It's Python in a server-side sandbox - OpenAI have had this for years and Anthropic launched theirs last week.
- Image generation - Mistral are using Black Forest Lab FLUX1.1 [pro] Ultra.
- Web search - this is an interesting variant, Mistral offer two versions:
web_searchis classic search, butweb_search_premium"enables access to both a search engine and two news agencies: AFP and AP". Mistral don't mention which underlying search engine they use but Brave is the only search vendor listed in the subprocessors on their Trust Center so I'm assuming it's Brave Search. I wonder if that news agency integration is handled by Brave or Mistral themselves? - Document library is Mistral's version of hosted RAG over "user-uploaded documents". Their documentation doesn't mention if it's vector-based or FTS or which embedding model it uses, which is a disappointing omission.
- Model Context Protocol support: you can now include details of MCP servers in your API calls and Mistral will call them when it needs to. It's pretty amazing to see the same new feature roll out across OpenAI (May 21st), Anthropic (May 22nd) and now Mistral (May 27th) within eight days of each other!
They also implement "agent handoffs":
Once agents are created, define which agents can hand off tasks to others. For example, a finance agent might delegate tasks to a web search agent or a calculator agent based on the conversation's needs.
Handoffs enable a seamless chain of actions. A single request can trigger tasks across multiple agents, each handling specific parts of the request.
This pattern always sounds impressive on paper but I'm yet to be convinced that it's worth using frequently. OpenAI have a similar mechanism in their OpenAI Agents SDK.
How I used o3 to find CVE-2025-37899, a remote zeroday vulnerability in the Linux kernel’s SMB implementation (via) Sean Heelan:
The vulnerability [o3] found is CVE-2025-37899 (fix here), a use-after-free in the handler for the SMB 'logoff' command. Understanding the vulnerability requires reasoning about concurrent connections to the server, and how they may share various objects in specific circumstances. o3 was able to comprehend this and spot a location where a particular object that is not referenced counted is freed while still being accessible by another thread. As far as I'm aware, this is the first public discussion of a vulnerability of that nature being found by a LLM.
Before I get into the technical details, the main takeaway from this post is this: with o3 LLMs have made a leap forward in their ability to reason about code, and if you work in vulnerability research you should start paying close attention. If you're an expert-level vulnerability researcher or exploit developer the machines aren't about to replace you. In fact, it is quite the opposite: they are now at a stage where they can make you significantly more efficient and effective. If you have a problem that can be represented in fewer than 10k lines of code there is a reasonable chance o3 can either solve it, or help you solve it.
Sean used my LLM tool to help find the bug! He ran it against the prompts he shared in this GitHub repo using the following command:
llm --sf system_prompt_uafs.prompt \
-f session_setup_code.prompt \
-f ksmbd_explainer.prompt \
-f session_setup_context_explainer.prompt \
-f audit_request.prompt
Sean ran the same prompt 100 times, so I'm glad he was using the new, more efficient fragments mechanism.
o3 found his first, known vulnerability 8/100 times - but found the brand new one in just 1 out of the 100 runs it performed with a larger context.
I thoroughly enjoyed this snippet which perfectly captures how I feel when I'm iterating on prompts myself:
In fact my entire system prompt is speculative in that I haven’t ran a sufficient number of evaluations to determine if it helps or hinders, so consider it equivalent to me saying a prayer, rather than anything resembling science or engineering.
Sean's conclusion with respect to the utility of these models for security research:
If we were to never progress beyond what o3 can do right now, it would still make sense for everyone working in VR [Vulnerability Research] to figure out what parts of their work-flow will benefit from it, and to build the tooling to wire it in. Of course, part of that wiring will be figuring out how to deal with the the signal to noise ratio of ~1:50 in this case, but that’s something we are already making progress at.
I really don’t like ChatGPT’s new memory dossier

Last month ChatGPT got a major upgrade. As far as I can tell the closest to an official announcement was this tweet from @OpenAI:
[... 2,521 words]OpenAI Codex. Announced today, here's the documentation for OpenAI's "cloud-based software engineering agent". It's not yet available for us $20/month Plus customers ("coming soon") but if you're a $200/month Pro user you can try it out now.
At a high level, you specify a prompt, and the agent goes to work in its own environment. After about 8–10 minutes, the agent gives you back a diff.
You can execute prompts in either ask mode or code mode. When you select ask, Codex clones a read-only version of your repo, booting faster and giving you follow-up tasks. Code mode, however, creates a full-fledged environment that the agent can run and test against.
This 4 minute demo video is a useful overview. One note that caught my eye is that the setup phase for an environment can pull from the internet (to install necessary dependencies) but the agent loop itself still runs in a network disconnected sandbox.
It sounds similar to GitHub's own Copilot Workspace project, which can compose PRs against your code based on a prompt. The big difference is that Codex incorporates a full Code Interpeter style environment, allowing it to build and run the code it's creating and execute tests in a loop.
Copilot Workspaces has a level of integration with Codespaces but still requires manual intervention to help exercise the code.
Also similar to Copilot Workspaces is a confusing name. OpenAI now have four products called Codex:
- OpenAI Codex, announced today.
- Codex CLI, a completely different coding assistant tool they released a few weeks ago that is the same kind of shape as Claude Code. This one owns the openai/codex namespace on GitHub.
- codex-mini, a brand new model released today that is used by their Codex product. It's a fine-tuned o4-mini variant. I released llm-openai-plugin 0.4 adding support for that model.
- OpenAI Codex (2021) - Internet Archive link, OpenAI's first specialist coding model from the GPT-3 era. This was used by the original GitHub Copilot and is still the current topic of Wikipedia's OpenAI Codex page.
My favorite thing about this most recent Codex product is that OpenAI shared the full Dockerfile for the environment that the system uses to run code - in openai/codex-universal on GitHub because openai/codex was taken already.
This is extremely useful documentation for figuring out how to use this thing - I'm glad they're making this as transparent as possible.
And to be fair, If you ignore it previous history Codex Is a good name for this product. I'm just glad they didn't call it Ada.
soon we have another low-key research preview to share with you all
we will name it better than chatgpt this time in case it takes off
Annotated Presentation Creator. I've released a new version of my tool for creating annotated presentations. I use this to turn slides from my talks into posts like this one - here are a bunch more examples.
I wrote the first version in August 2023 making extensive use of ChatGPT and GPT-4. That older version can still be seen here.
This new edition is a design refresh using Claude 3.7 Sonnet (thinking). I ran this command:
llm \
-f https://til.simonwillison.net/tools/annotated-presentations \
-s 'Improve this tool by making it respnonsive for mobile, improving the styling' \
-m claude-3.7-sonnet -o thinking 1
That uses -f to fetch the original HTML (which has embedded CSS and JavaScript in a single page, convenient for working with LLMs) as a prompt fragment, then applies the system prompt instructions "Improve this tool by making it respnonsive for mobile, improving the styling" (typo included).
Here's the full transcript (generated using llm logs -cue) and a diff illustrating the changes. Total cost 10.7781 cents.
There was one visual glitch: the slides were distorted like this:
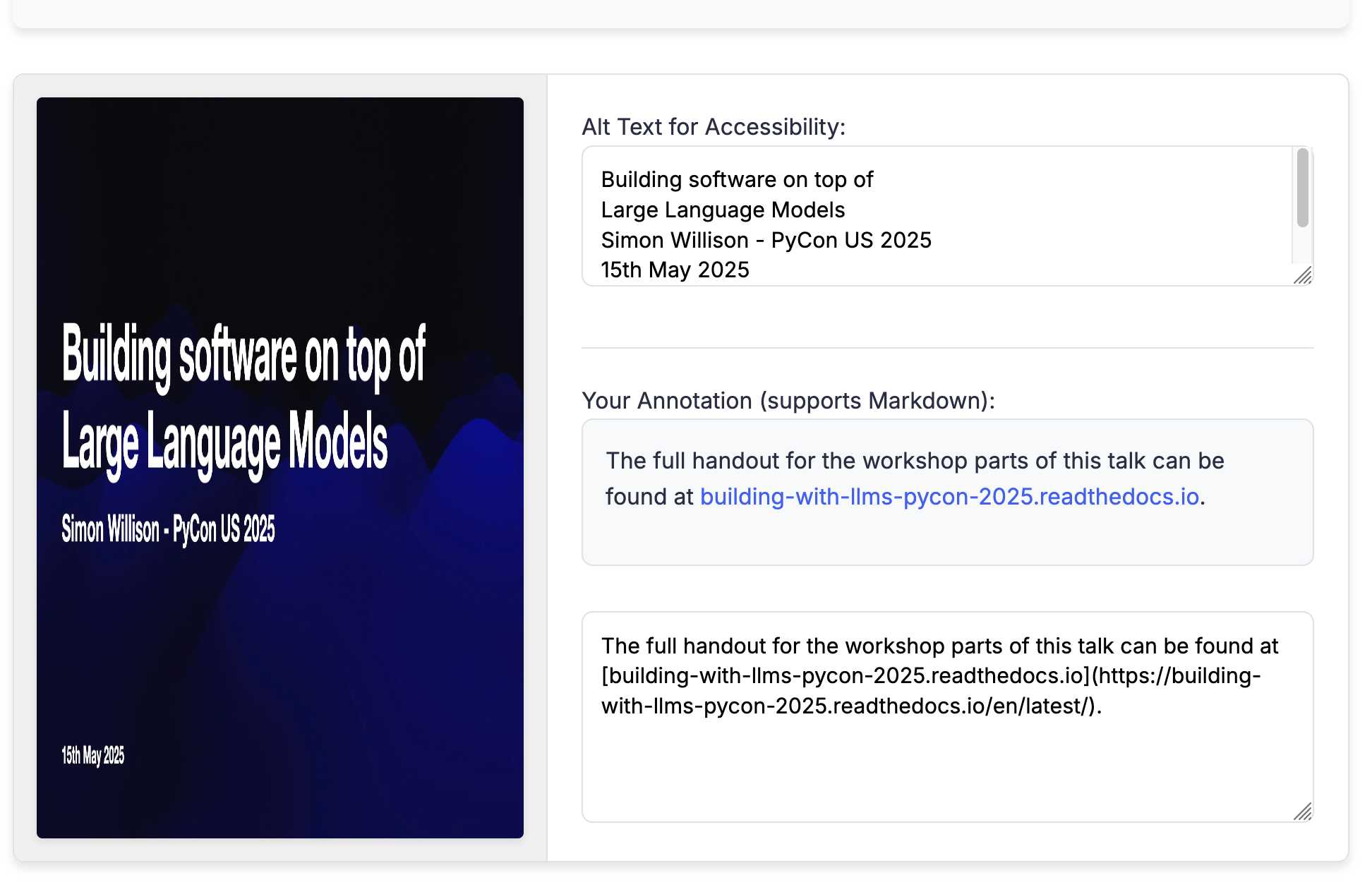
I decided to try o4-mini to see if it could spot the problem (after fixing this LLM bug):
llm o4-mini \
-a bug.png \
-f https://tools.simonwillison.net/annotated-presentations \
-s 'Suggest a minimal fix for this distorted image'
It suggested adding align-items: flex-start; to my .bundle class (it quoted the @media (min-width: 768px) bit but the solution was to add it to .bundle at the top level), which fixed the bug.
By popular request, GPT-4.1 will be available directly in ChatGPT starting today.
GPT-4.1 is a specialized model that excels at coding tasks & instruction following. Because it’s faster, it’s a great alternative to OpenAI o3 & o4-mini for everyday coding needs.
Building software on top of Large Language Models

I presented a three hour workshop at PyCon US yesterday titled Building software on top of Large Language Models. The goal of the workshop was to give participants everything they needed to get started writing code that makes use of LLMs.
[... 3,726 words]LLM 0.26a0 adds support for tools! It's only an alpha so I'm not going to promote this extensively yet, but my LLM project just grew a feature I've been working towards for nearly two years now: tool support!
I'm presenting a workshop about Building software on top of Large Language Models at PyCon US tomorrow and this was the one feature I really needed to pull everything else together.
Tools can be used from the command-line like this (inspired by sqlite-utils --functions):
llm --functions ' def multiply(x: int, y: int) -> int: """Multiply two numbers.""" return x * y ' 'what is 34234 * 213345' -m o4-mini
You can add --tools-debug (shortcut: --td) to have it show exactly what tools are being executed and what came back. More documentation here.
It's also available in the Python library:
import llm def multiply(x: int, y: int) -> int: """Multiply two numbers.""" return x * y model = llm.get_model("gpt-4.1-mini") response = model.chain( "What is 34234 * 213345?", tools=[multiply] ) print(response.text())
There's also a new plugin hook so plugins can register tools that can then be referenced by name using llm --tool name_of_tool "prompt".
There's still a bunch I want to do before including this in a stable release, most notably adding support for Python asyncio. It's a pretty exciting start though!
llm-anthropic 0.16a0 and llm-gemini 0.20a0 add tool support for Anthropic and Gemini models, depending on the new LLM alpha.
Update: Here's the section about tools from my PyCon workshop.
Building, launching, and scaling ChatGPT Images (via) Gergely Orosz landed a fantastic deep dive interview with OpenAI's Sulman Choudhry (head of engineering, ChatGPT) and Srinivas Narayanan (VP of engineering, OpenAI) to talk about the launch back in March of ChatGPT images - their new image generation mode built on top of multi-modal GPT-4o.
The feature kept on having new viral spikes, including one that added one million new users in a single hour. They signed up 100 million new users in the first week after the feature's launch.
When this vertical growth spike started, most of our engineering teams didn't believe it. They assumed there must be something wrong with the metrics.
Under the hood the infrastructure is mostly Python and FastAPI! I hope they're sponsoring those projects (and Starlette, which is used by FastAPI under the hood.)
They're also using some C, and Temporal as a workflow engine. They addressed the early scaling challenge by adding an asynchronous queue to defer the load for their free users (resulting in longer generation times) at peak demand.
There are plenty more details tucked away behind the firewall, including an exclusive I've not been able to find anywhere else: OpenAI's core engineering principles.
- Ship relentlessly - move quickly and continuously improve, without waiting for perfect conditions
- Own the outcome - take full responsibility for products, end-to-end
- Follow through - finish what is started and ensure the work lands fully
I tried getting o4-mini-high to track down a copy of those principles online and was delighted to see it either leak or hallucinate the URL to OpenAI's internal engineering handbook!
Gergely has a whole series of posts like this called Real World Engineering Challenges, including another one on ChatGPT a year ago.
It's interesting how much my perception of o3 as being the latest, best model released by OpenAI is tarnished by the co-release of o4-mini. I'm also still not entirely sure how to compare o3 to o1-pro, especially given o1-pro is 15x more expensive via the OpenAI API.
Two things can be true simultaneously: (a) LLM provider cost economics are too negative to return positive ROI to investors, and (b) LLMs are useful for solving problems that are meaningful and high impact, albeit not to the AGI hype that would justify point (a). This particular combination creates a frustrating gray area that requires a nuance that an ideologically split social media can no longer support gracefully. [...]
OpenAI collapsing would not cause the end of LLMs, because LLMs are useful today and there will always be a nonzero market demand for them: it’s a bell that can’t be unrung.
Expanding on what we missed with sycophancy. I criticized OpenAI's initial post about their recent ChatGPT sycophancy rollback as being "relatively thin" so I'm delighted that they have followed it with a much more in-depth explanation of what went wrong. This is worth spending time with - it includes a detailed description of how they create and test model updates.
This feels reminiscent to me of a good outage postmortem, except here the incident in question was an AI personality bug!
The custom GPT-4o model used by ChatGPT has had five major updates since it was first launched. OpenAI start by providing some clear insights into how the model updates work:
To post-train models, we take a pre-trained base model, do supervised fine-tuning on a broad set of ideal responses written by humans or existing models, and then run reinforcement learning with reward signals from a variety of sources.
During reinforcement learning, we present the language model with a prompt and ask it to write responses. We then rate its response according to the reward signals, and update the language model to make it more likely to produce higher-rated responses and less likely to produce lower-rated responses.
Here's yet more evidence that the entire AI industry runs on "vibes":
In addition to formal evaluations, internal experts spend significant time interacting with each new model before launch. We informally call these “vibe checks”—a kind of human sanity check to catch issues that automated evals or A/B tests might miss.
So what went wrong? Highlights mine:
In the April 25th model update, we had candidate improvements to better incorporate user feedback, memory, and fresher data, among others. Our early assessment is that each of these changes, which had looked beneficial individually, may have played a part in tipping the scales on sycophancy when combined. For example, the update introduced an additional reward signal based on user feedback—thumbs-up and thumbs-down data from ChatGPT. This signal is often useful; a thumbs-down usually means something went wrong.
But we believe in aggregate, these changes weakened the influence of our primary reward signal, which had been holding sycophancy in check. User feedback in particular can sometimes favor more agreeable responses, likely amplifying the shift we saw.
I'm surprised that this appears to be first time the thumbs up and thumbs down data has been used to influence the model in this way - they've been collecting that data for a couple of years now.
I've been very suspicious of the new "memory" feature, where ChatGPT can use context of previous conversations to influence the next response. It looks like that may be part of this too, though not definitively the cause of the sycophancy bug:
We have also seen that in some cases, user memory contributes to exacerbating the effects of sycophancy, although we don’t have evidence that it broadly increases it.
The biggest miss here appears to be that they let their automated evals and A/B tests overrule those vibe checks!
One of the key problems with this launch was that our offline evaluations—especially those testing behavior—generally looked good. Similarly, the A/B tests seemed to indicate that the small number of users who tried the model liked it. [...] Nevertheless, some expert testers had indicated that the model behavior “felt” slightly off.
The system prompt change I wrote about the other day was a temporary fix while they were rolling out the new model:
We took immediate action by pushing updates to the system prompt late Sunday night to mitigate much of the negative impact quickly, and initiated a full rollback to the previous GPT‑4o version on Monday
They list a set of sensible new precautions they are introducing to avoid behavioral bugs like this making it to production in the future. Most significantly, it looks we are finally going to get release notes!
We also made communication errors. Because we expected this to be a fairly subtle update, we didn't proactively announce it. Also, our release notes didn’t have enough information about the changes we'd made. Going forward, we’ll proactively communicate about the updates we’re making to the models in ChatGPT, whether “subtle” or not.
And model behavioral problems will now be treated as seriously as other safety issues.
We need to treat model behavior issues as launch-blocking like we do other safety risks. [...] We now understand that personality and other behavioral issues should be launch blocking, and we’re modifying our processes to reflect that.
This final note acknowledges how much more responsibility these systems need to take on two years into our weird consumer-facing LLM revolution:
One of the biggest lessons is fully recognizing how people have started to use ChatGPT for deeply personal advice—something we didn’t see as much even a year ago. At the time, this wasn’t a primary focus, but as AI and society have co-evolved, it’s become clear that we need to treat this use case with great care.
The realization hit me [when the GPT-3 paper came out] that an important property of the field flipped. In ~2011, progress in AI felt constrained primarily by algorithms. We needed better ideas, better modeling, better approaches to make further progress. If you offered me a 10X bigger computer, I'm not sure what I would have even used it for. GPT-3 paper showed that there was this thing that would just become better on a large variety of practical tasks, if you only trained a bigger one. Better algorithms become a bonus, not a necessity for progress in AGI. Possibly not forever and going forward, but at least locally and for the time being, in a very practical sense. Today, if you gave me a 10X bigger computer I would know exactly what to do with it, and then I'd ask for more.
Training is not the same as chatting: ChatGPT and other LLMs don’t remember everything you say
I’m beginning to suspect that one of the most common misconceptions about LLMs such as ChatGPT involves how “training” works.
[... 1,543 words]Reproducing GPT-2 (124M) in llm.c in 90 minutes for $20 (via) GPT-2 124M was the smallest model in the GPT-2 series released by OpenAI back in 2019. Andrej Karpathy's llm.c is an evolving 4,000 line C/CUDA implementation which can now train a GPT-2 model from scratch in 90 minutes against a 8X A100 80GB GPU server. This post walks through exactly how to run the training, using 10 billion tokens of FineWeb.
Andrej notes that this isn't actually that far off being able to train a GPT-3:
Keep in mind that here we trained for 10B tokens, while GPT-3 models were all trained for 300B tokens. [...] GPT-3 actually didn't change too much at all about the model (context size 1024 -> 2048, I think that's it?).
Estimated cost for a GPT-3 ADA (350M parameters)? About $2,000.
Nilay Patel reports a hallucinated ChatGPT summary of his own article (via) Here's a ChatGPT bug that's a new twist on the old issue where it would hallucinate the contents of a web page based on the URL.
The Verge editor Nilay Patel asked for a summary of one of his own articles, pasting in the URL.
ChatGPT 4o replied with an entirely invented summary full of hallucinated details.
It turns out The Verge blocks ChatGPT's browse mode from accessing their site in their robots.txt:
User-agent: ChatGPT-User
Disallow: /
Clearly ChatGPT should reply that it is unable to access the provided URL, rather than inventing a response that guesses at the contents!
Last September, I received an offer from Sam Altman, who wanted to hire me to voice the current ChatGPT 4.0 system. He told me that he felt that by my voicing the system, I could bridge the gap between tech companies and creatives and help consumers to feel comfortable with the seismic shift concerning humans and AI. He said he felt that my voice would be comforting to people. After much consideration and for personal reasons, I declined the offer.
I have seen the extremely restrictive off-boarding agreement that contains nondisclosure and non-disparagement provisions former OpenAI employees are subject to. It forbids them, for the rest of their lives, from criticizing their former employer. Even acknowledging that the NDA exists is a violation of it.
If a departing employee declines to sign the document, or if they violate it, they can lose all vested equity they earned during their time at the company, which is likely worth millions of dollars.
OpenAI: Managing your work in the API platform with Projects (via) New OpenAI API feature: you can now create API keys for "projects" that can have a monthly spending cap. The UI for that limit says:
If the project's usage exceeds this amount in a given calendar month (UTC), subsequent API requests will be rejected
You can also set custom token-per-minute and request-per-minute rate limits for individual models.
I've been wanting this for ages: this means it's finally safe to ship a weird public demo on top of their various APIs without risk of accidental bankruptcy if the demo goes viral!
ChatGPT in “4o” mode is not running the new features yet
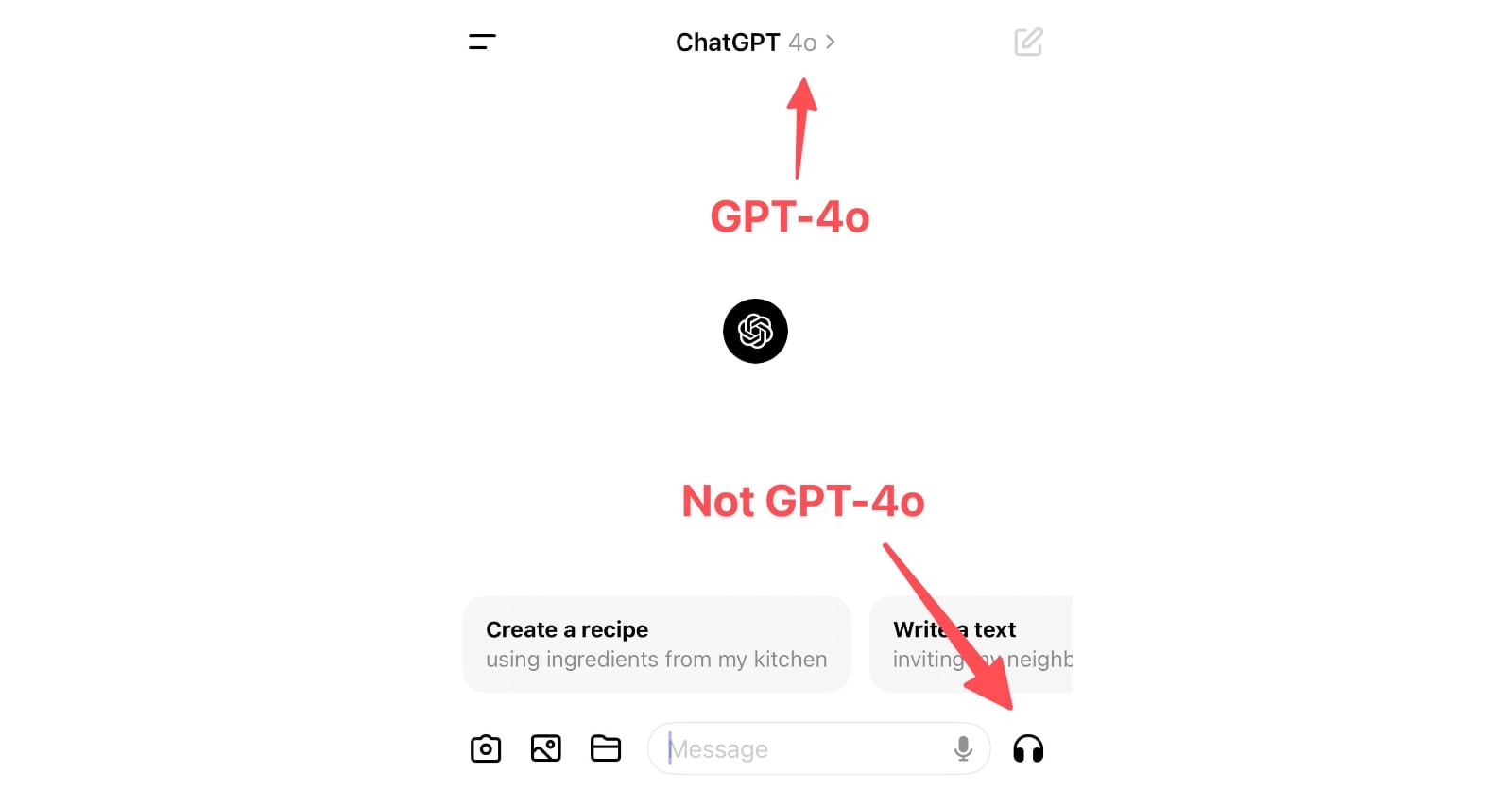
Monday’s OpenAI announcement of their new GPT-4o model included some intriguing new features:
[... 898 words]Why your voice assistant might be sexist (via) Given OpenAI's demo yesterday of a vocal chat assistant with a flirty, giggly female voice - and the new ability to be interrupted! - it's worth revisiting this piece by Chris Baraniuk from June 2022 about gender dynamics in voice assistants. Includes a link to this example of a synthesized non-binary voice.
LLM 0.14, with support for GPT-4o. It's been a while since the last LLM release. This one adds support for OpenAI's new model:
llm -m gpt-4o "fascinate me"
Also a new llm logs -r (or --response) option for getting back just the response from your last prompt, without wrapping it in Markdown that includes the prompt.
Plus nine new plugins since 0.13!
Hello GPT-4o. OpenAI announced a new model today: GPT-4o, where the o stands for "omni".
It looks like this is the gpt2-chatbot we've been seeing in the Chat Arena the past few weeks.
GPT-4o doesn't seem to be a huge leap ahead of GPT-4 in terms of "intelligence" - whatever that might mean - but it has a bunch of interesting new characteristics.
First, it's multi-modal across text, images and audio as well. The audio demos from this morning's launch were extremely impressive.
ChatGPT's previous voice mode worked by passing audio through a speech-to-text model, then an LLM, then a text-to-speech for the output. GPT-4o does everything with the one model, reducing latency to the point where it can act as a live interpreter between people speaking in two different languages. It also has the ability to interpret tone of voice, and has much more control over the voice and intonation it uses in response.
It's very science fiction, and has hints of uncanny valley. I can't wait to try it out - it should be rolling out to the various OpenAI apps "in the coming weeks".
Meanwhile the new model itself is already available for text and image inputs via the API and in the Playground interface, as model ID "gpt-4o" or "gpt-4o-2024-05-13". My first impressions are that it feels notably faster than gpt-4-turbo.
This announcement post also includes examples of image output from the new model. It looks like they may have taken big steps forward in two key areas of image generation: output of text (the "Poetic typography" examples) and maintaining consistent characters across multiple prompts (the "Character design - Geary the robot" example).
The size of the vocabulary of the tokenizer - effectively the number of unique integers used to represent text - has increased to ~200,000 from ~100,000 for GPT-4 and GPT-3.5. Inputs in Gujarati use 4.4x fewer tokens, Japanese uses 1.4x fewer, Spanish uses 1.1x fewer. Previously languages other than English paid a material penalty in terms of how much text could fit into a prompt, it's good to see that effect being reduced.
Also notable: the price. OpenAI claim a 50% price reduction compared to GPT-4 Turbo. Conveniently, gpt-4o costs exactly 10x gpt-3.5: 4o is $5/million input tokens and $15/million output tokens. 3.5 is $0.50/million input tokens and $1.50/million output tokens.
(I was a little surprised not to see a price decrease there to better compete with the less expensive Claude 3 Haiku.)
The price drop is particularly notable because OpenAI are promising to make this model available to free ChatGPT users as well - the first time they've directly made their "best" model available to non-paying customers.
Tucked away right at the end of the post:
We plan to launch support for GPT-4o's new audio and video capabilities to a small group of trusted partners in the API in the coming weeks.
I'm looking forward to learning more about these video capabilities, which were hinted at by some of the live demos in this morning's presentation.
OpenAI Model Spec, May 2024 edition (via) New from OpenAI, a detailed specification describing how they want their models to behave in both ChatGPT and the OpenAI API.
“It includes a set of core objectives, as well as guidance on how to deal with conflicting objectives or instructions.”
The document acts as guidelines for the reinforcement learning from human feedback (RLHF) process, and in the future may be used directly to help train models.
It includes some principles that clearly relate to prompt injection: “In some cases, the user and developer will provide conflicting instructions; in such cases, the developer message should take precedence”.
gpt2-chatbot confirmed as OpenAI
(via)
The mysterious gpt2-chatbot model that showed up in the LMSYS arena a few days ago was suspected to be a testing preview of a new OpenAI model. This has now been confirmed, thanks to a 429 rate limit error message that exposes details from the underlying OpenAI API platform.
The model has been renamed to im-also-a-good-gpt-chatbot and is now only randomly available in "Arena (battle)" mode, not via "Direct Chat".
OpenAI cookbook: How to get token usage data for streamed chat completion response
(via)
New feature in the OpenAI streaming API that I've been wanting for a long time: you can now set stream_options={"include_usage": True} to get back a "usage" block at the end of the stream showing how many input and output tokens were used.
This means you can now accurately account for the total cost of each streaming API call. Previously this information was only an available for non-streaming responses.
ChatGPT should include inline tips
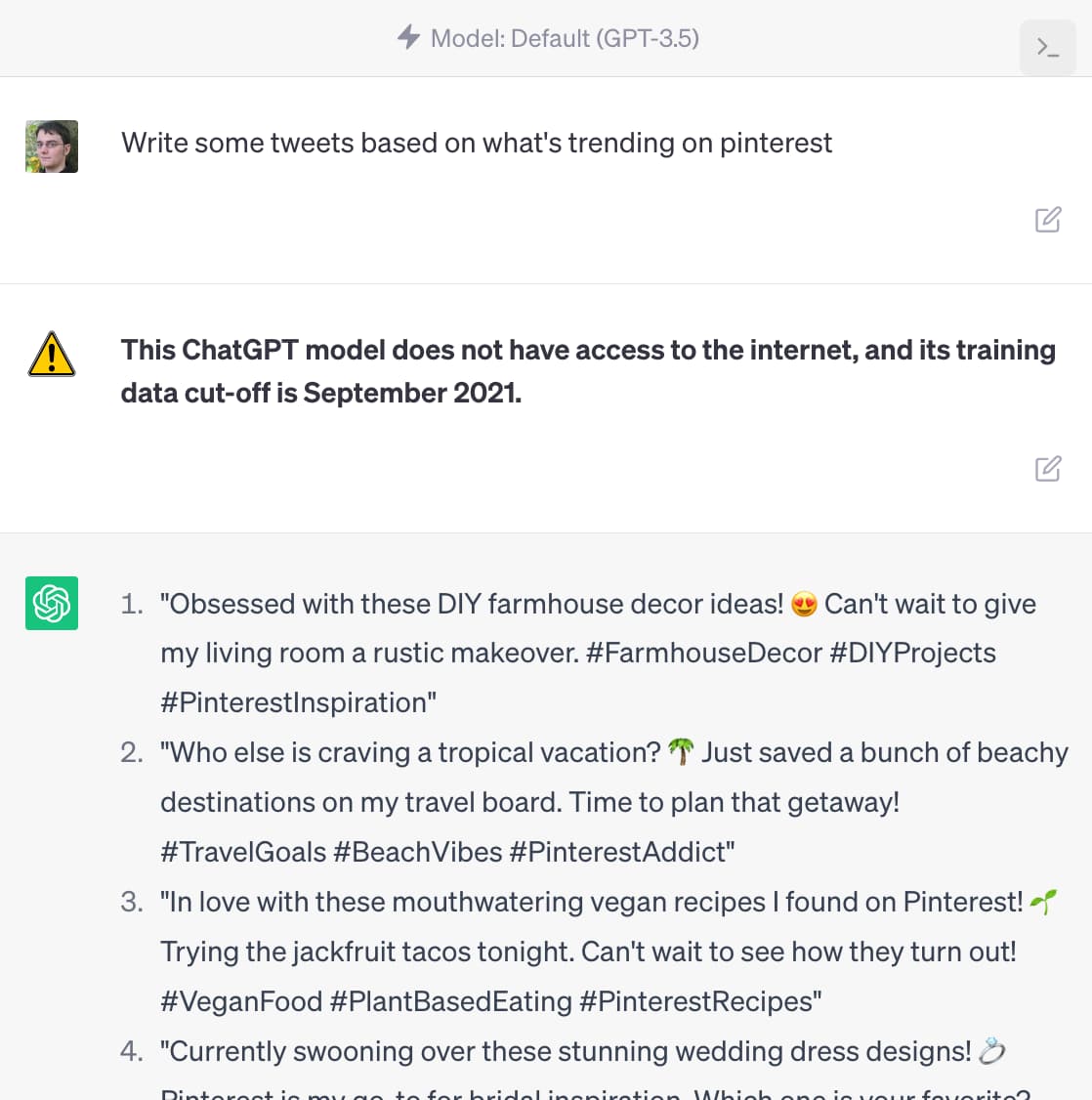
In OpenAI isn’t doing enough to make ChatGPT’s limitations clear James Vincent argues that OpenAI’s existing warnings about ChatGPT’s confounding ability to convincingly make stuff up are not effective.
[... 1,488 words]