Entries Links Quotes Notes Guides Elsewhere
Feb. 27, 2026
Free Claude Max for (large project) open source maintainers (via) Anthropic are now offering their $200/month Claude Max 20x plan for free to open source maintainers... for six months... and you have to meet the following criteria:
- Maintainers: You're a primary maintainer or core team member of a public repo with 5,000+ GitHub stars or 1M+ monthly NPM downloads. You've made commits, releases, or PR reviews within the last 3 months.
- Don't quite fit the criteria If you maintain something the ecosystem quietly depends on, apply anyway and tell us about it.
Also in the small print: "Applications are reviewed on a rolling basis. We accept up to 10,000 contributors".
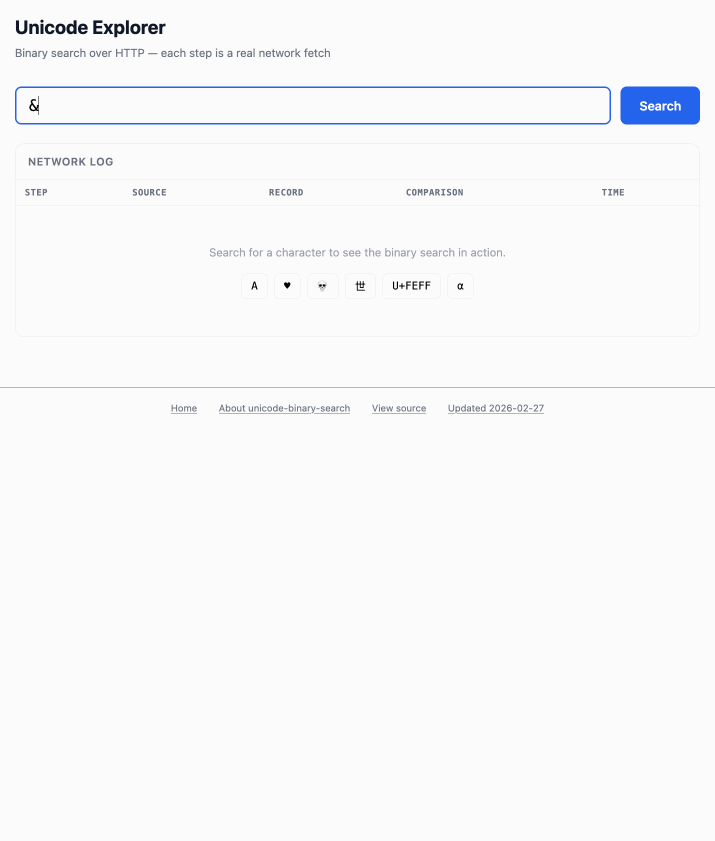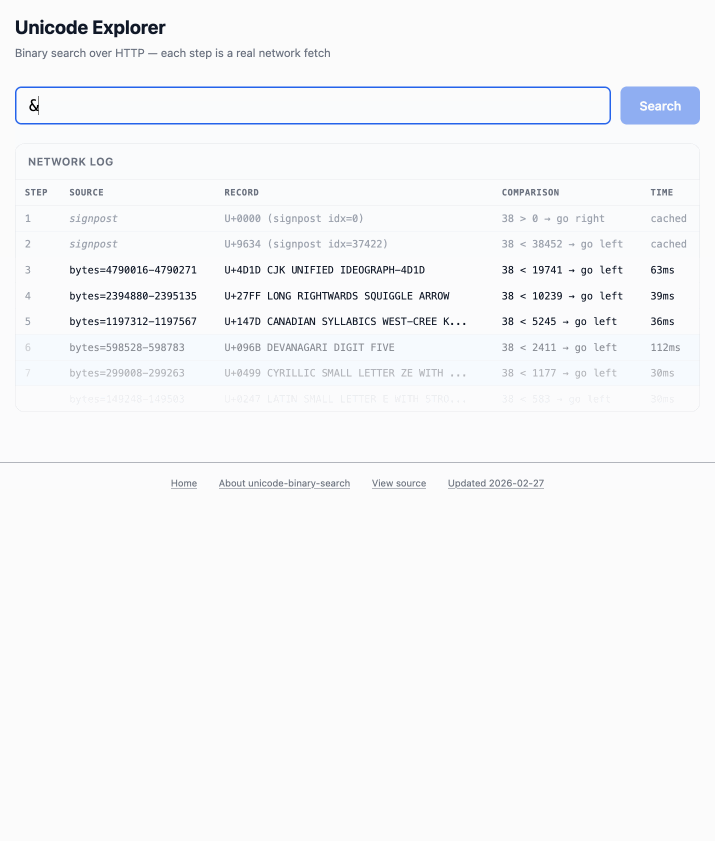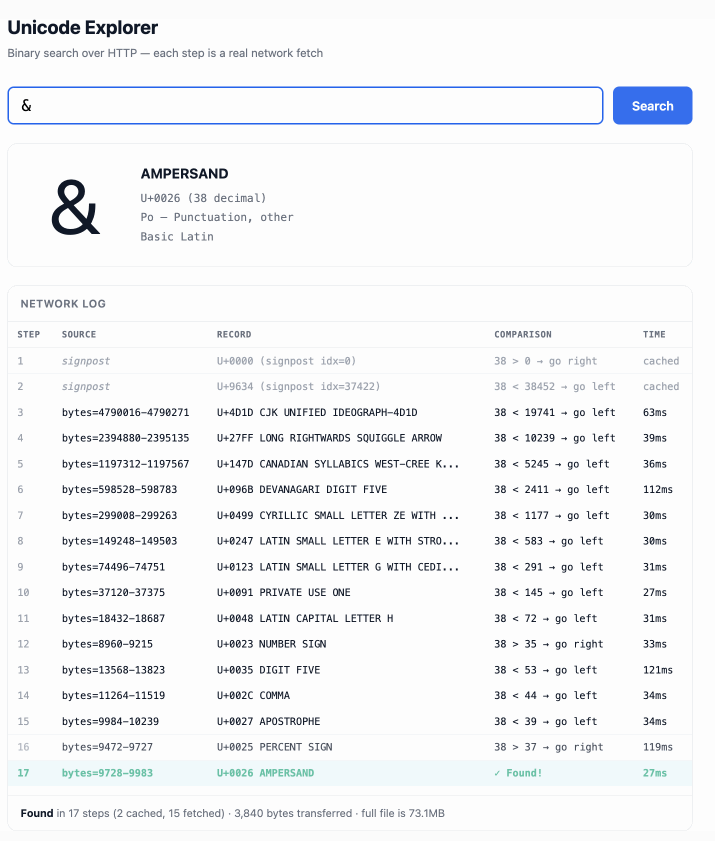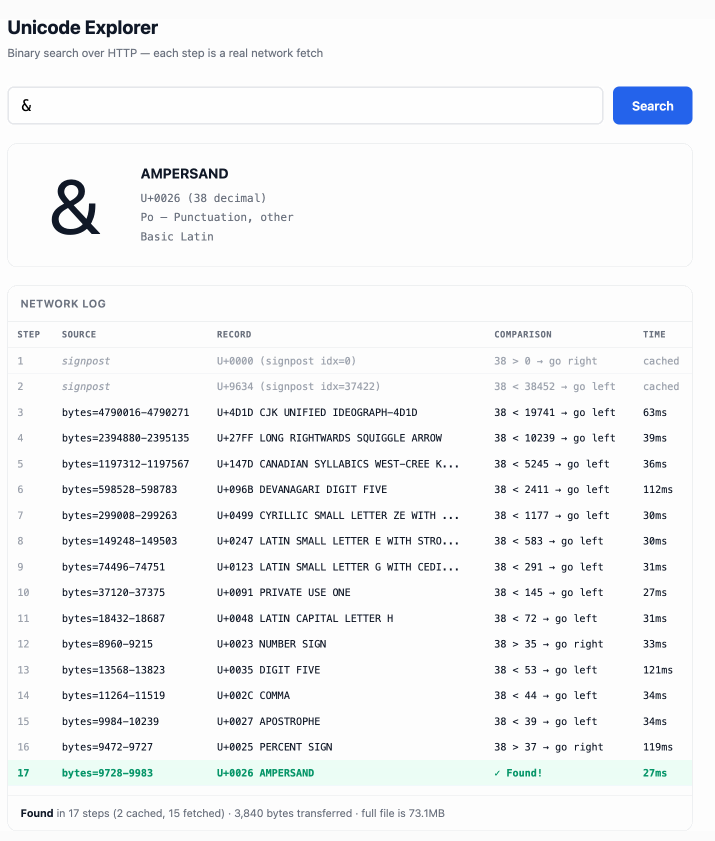
Unicode Explorer using binary search over fetch() HTTP range requests. Here's a little prototype I built this morning from my phone as an experiment in HTTP range requests, and a general example of using LLMs to satisfy curiosity.
I've been collecting HTTP range tricks for a while now, and I decided it would be fun to build something with them myself that used binary search against a large file to do something useful.
So I brainstormed with Claude. The challenge was coming up with a use case for binary search where the data could be naturally sorted in a way that would benefit from binary search.
One of Claude's suggestions was looking up information about unicode codepoints, which means searching through many MBs of metadata.
I had Claude write me a spec to feed to Claude Code - visible here - then kicked off an asynchronous research project with Claude Code for web against my simonw/research repo to turn that into working code.
Here's the resulting report and code. One interesting thing I learned is that Range request tricks aren't compatible with HTTP compression because they mess with the byte offset calculations. I added 'Accept-Encoding': 'identity' to the fetch() calls but this isn't actually necessary because Cloudflare and other CDNs automatically skip compression if a content-range header is present.
I deployed the result to my tools.simonwillison.net site, after first tweaking it to query the data via range requests against a CORS-enabled 76.6MB file in an S3 bucket fronted by Cloudflare.
The demo is fun to play with - type in a single character like ø or a hexadecimal codepoint indicator like 1F99C and it will binary search its way through the large file and show you the steps it takes along the way:
Feb. 26, 2026
Hoard things you know how to do
Many of my tips for working productively with coding agents are extensions of advice I've found useful in my career without them. Here's a great example of that: hoard things you know how to do.
A big part of the skill in building software is understanding what's possible and what isn't, and having at least a rough idea of how those things can be accomplished.
These questions can be broad or quite obscure. Can a web page run OCR operations in JavaScript alone? Can an iPhone app pair with a Bluetooth device even when the app isn't running? Can we process a 100GB JSON file in Python without loading the entire thing into memory first? [... 1,467 words]
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow. [...]
Google API Keys Weren’t Secrets. But then Gemini Changed the Rules. (via) Yikes! It turns out Gemini and Google Maps (and other services) share the same API keys... but Google Maps API keys are designed to be public, since they are embedded directly in web pages. Gemini API keys can be used to access private files and make billable API requests, so they absolutely should not be shared.
If you don't understand this it's very easy to accidentally enable Gemini billing on a previously public API key that exists in the wild already.
What makes this a privilege escalation rather than a misconfiguration is the sequence of events.
- A developer creates an API key and embeds it in a website for Maps. (At that point, the key is harmless.)
- The Gemini API gets enabled on the same project. (Now that same key can access sensitive Gemini endpoints.)
- The developer is never warned that the keys' privileges changed underneath it. (The key went from public identifier to secret credential).
Truffle Security found 2,863 API keys in the November 2025 Common Crawl that could access Gemini, verified by hitting the /models listing endpoint. This included several keys belonging to Google themselves, one of which had been deployed since February 2023 (according to the Internet Archive) hence predating the Gemini API that it could now access.
Google are working to revoke affected keys but it's still a good idea to check that none of yours are affected by this.
If people are only using this a couple of times a week at most, and can’t think of anything to do with it on the average day, it hasn’t changed their life. OpenAI itself admits the problem, talking about a ‘capability gap’ between what the models can do and what people do with them, which seems to me like a way to avoid saying that you don’t have clear product-market fit.
Hence, OpenAI’s ad project is partly just about covering the cost of serving the 90% or more of users who don’t pay (and capturing an early lead with advertisers and early learning in how this might work), but more strategically, it’s also about making it possible to give those users the latest and most powerful (i.e. expensive) models, in the hope that this will deepen their engagement.
— Benedict Evans, How will OpenAI compete?
Feb. 25, 2026
tldraw issue: Move tests to closed source repo (via) It's become very apparent over the past few months that a comprehensive test suite is enough to build a completely fresh implementation of any open source library from scratch, potentially in a different language.
This has worrying implications for open source projects with commercial business models. Here's an example of a response: tldraw, the outstanding collaborative drawing library (see previous coverage), are moving their test suite to a private repository - apparently in response to Cloudflare's project to port Next.js to use Vite in a week using AI.
They also filed a joke issue, now closed to Translate source code to Traditional Chinese:
The current tldraw codebase is in English, making it easy for external AI coding agents to replicate. It is imperative that we defend our intellectual property.
Worth noting that tldraw aren't technically open source - their custom license requires a commercial license if you want to use it in "production environments".
Update: Well this is embarrassing, it turns out the issue I linked to about removing the tests was a joke as well:
Sorry folks, this issue was more of a joke (am I allowed to do that?) but I'll keep the issue open since there's some discussion here. Writing from mobile
- moving our tests into another repo would complicate and slow down our development, and speed for us is more important than ever
- more canvas better, I know for sure that our decisions have inspired other products and that's fine and good
- tldraw itself may eventually be a vibe coded alternative to tldraw
- the value is in the ability to produce new and good product decisions for users / customers, however you choose to create the code
Claude Code Remote Control (via) New Claude Code feature dropped yesterday: you can now run a "remote control" session on your computer and then use the Claude Code for web interfaces (on web, iOS and native desktop app) to send prompts to that session.
It's a little bit janky right now. Initially when I tried it I got the error "Remote Control is not enabled for your account. Contact your administrator." (but I am my administrator?) - then I logged out and back into the Claude Code terminal app and it started working:
claude remote-control
You can only run one session on your machine at a time. If you upgrade the Claude iOS app it then shows up as "Remote Control Session (Mac)" in the Code tab.
It appears not to support the --dangerously-skip-permissions flag (I passed that to claude remote-control and it didn't reject the option, but it also appeared to have no effect) - which means you have to approve every new action it takes.
I also managed to get it to a state where every prompt I tried was met by an API 500 error.
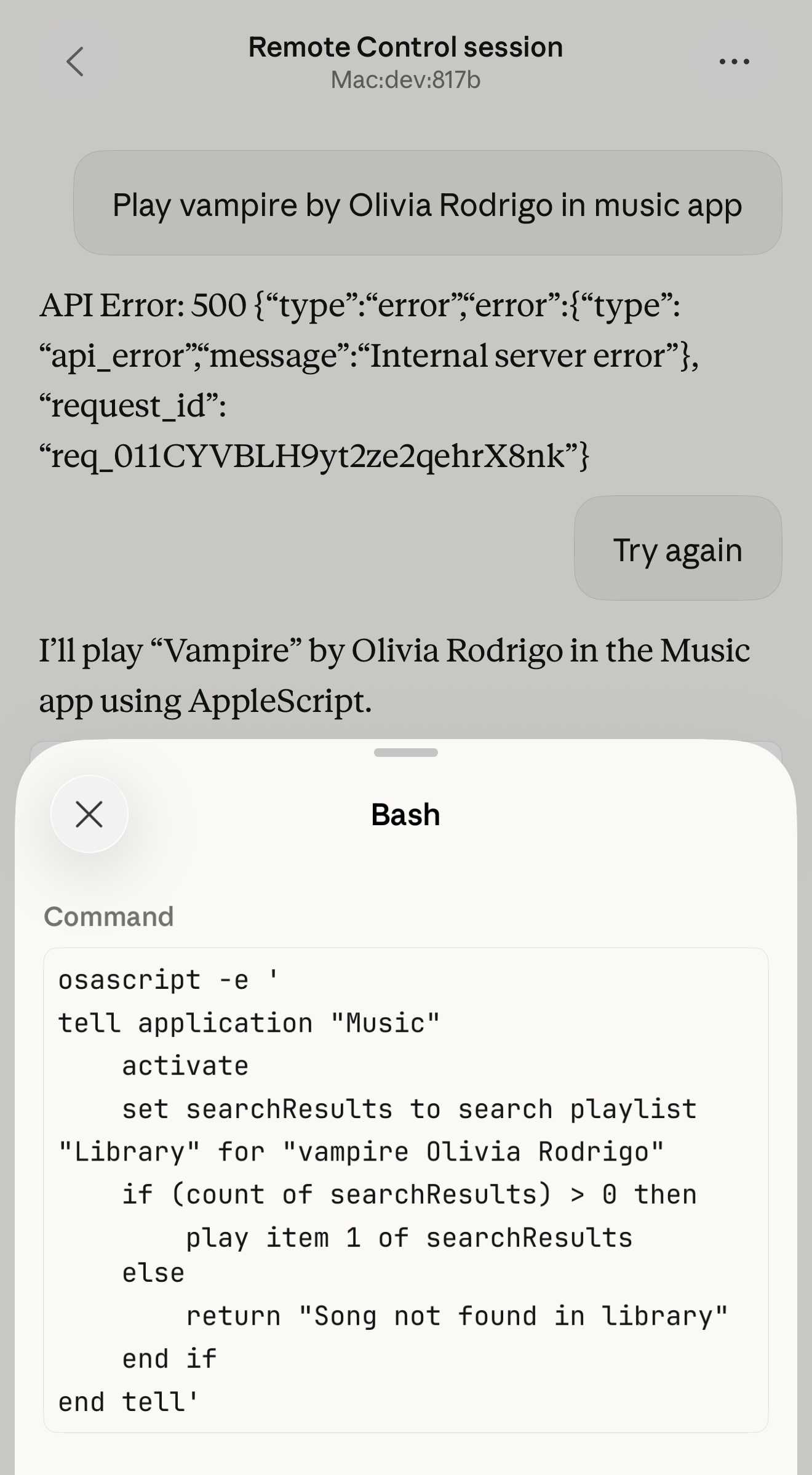
Restarting the program on the machine also causes existing sessions to start returning mysterious API errors rather than neatly explaining that the session has terminated.
I expect they'll iron out all of these issues relatively quickly. It's interesting to then contrast this to solutions like OpenClaw, where one of the big selling points is the ability to control your personal device from your phone.
Claude Code still doesn't have a documented mechanism for running things on a schedule, which is the other killer feature of the Claw category of software.
Update: I spoke too soon: also today Anthropic announced Schedule recurring tasks in Cowork, Claude Code's general agent sibling. These do include an important limitation:
Scheduled tasks only run while your computer is awake and the Claude Desktop app is open. If your computer is asleep or the app is closed when a task is scheduled to run, Cowork will skip the task, then run it automatically once your computer wakes up or you open the desktop app again.
I really hope they're working on a Cowork Cloud product.
I vibe coded my dream macOS presentation app
I gave a talk this weekend at Social Science FOO Camp in Mountain View. The event was a classic unconference format where anyone could present a talk without needing to propose it in advance. I grabbed a slot for a talk I titled “The State of LLMs, February 2026 edition”, subtitle “It’s all changed since November!”. I vibe coded a custom macOS app for the presentation the night before.
[... 1,613 words]It’s also reasonable for people who entered technology in the last couple of decades because it was good job, or because they enjoyed coding to look at this moment with a real feeling of loss. That feeling of loss though can be hard to understand emotionally for people my age who entered tech because we were addicted to feeling of agency it gave us. The web was objectively awful as a technology, and genuinely amazing, and nobody got into it because programming in Perl was somehow aesthetically delightful.
— Kellan Elliott-McCrea, Code has always been the easy part
Linear walkthroughs
Sometimes it's useful to have a coding agent give you a structured walkthrough of a codebase.
Maybe it's existing code you need to get up to speed on, maybe it's your own code that you've forgotten the details of, or maybe you vibe coded the whole thing and need to understand how it actually works.
Frontier models with the right agent harness can construct a detailed walkthrough to help you understand how code works. [... 525 words]
Feb. 24, 2026
go-size-analyzer (via) The Go ecosystem is really good at tooling. I just learned about this tool for analyzing the size of Go binaries using a pleasing treemap view of their bundled dependencies.
You can install and run the tool locally, but it's also compiled to WebAssembly and hosted at gsa.zxilly.dev - which means you can open compiled Go binaries and analyze them directly in your browser.
I tried it with a 8.1MB macOS compiled copy of my Go Showboat tool and got this:
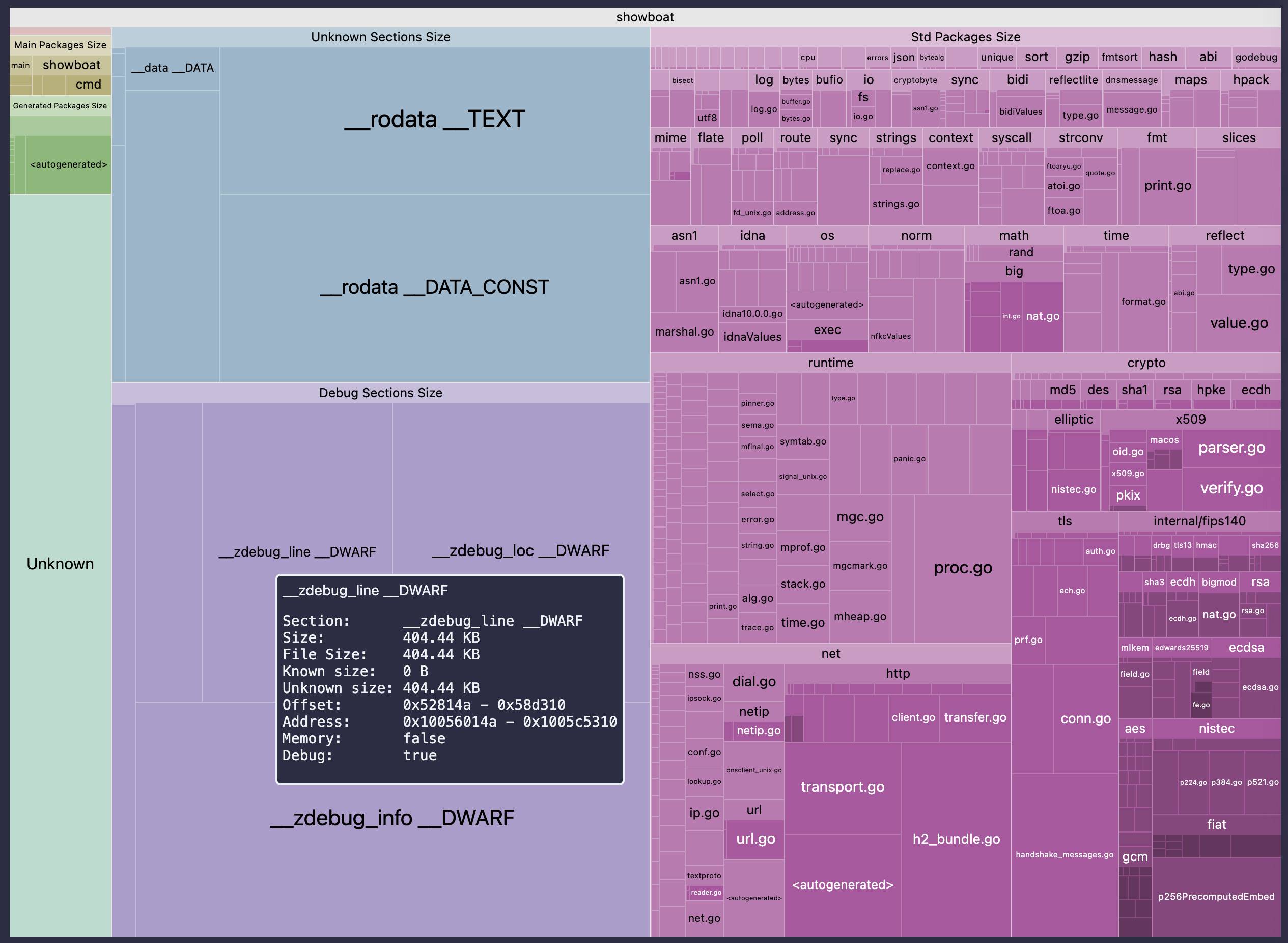
First run the tests
Automated tests are no longer optional when working with coding agents.
The old excuses for not writing them - that they're time consuming and expensive to constantly rewrite while a codebase is rapidly evolving - no longer hold when an agent can knock them into shape in just a few minutes.
They're also vital for ensuring AI-generated code does what it claims to do. If the code has never been executed it's pure luck if it actually works when deployed to production. [... 355 words]
Feb. 23, 2026
Ladybird adopts Rust, with help from AI (via) Really interesting case-study from Andreas Kling on advanced, sophisticated use of coding agents for ambitious coding projects with critical code. After a few years hoping Swift's platform support outside of the Apple ecosystem would mature they switched tracks to Rust their memory-safe language of choice, starting with an AI-assisted port of a critical library:
Our first target was LibJS , Ladybird's JavaScript engine. The lexer, parser, AST, and bytecode generator are relatively self-contained and have extensive test coverage through test262, which made them a natural starting point.
I used Claude Code and Codex for the translation. This was human-directed, not autonomous code generation. I decided what to port, in what order, and what the Rust code should look like. It was hundreds of small prompts, steering the agents where things needed to go. [...]
The requirement from the start was byte-for-byte identical output from both pipelines. The result was about 25,000 lines of Rust, and the entire port took about two weeks. The same work would have taken me multiple months to do by hand. We’ve verified that every AST produced by the Rust parser is identical to the C++ one, and all bytecode generated by the Rust compiler is identical to the C++ compiler’s output. Zero regressions across the board.
Having an existing conformance testing suite of the quality of test262 is a huge unlock for projects of this magnitude, and the ability to compare output with an existing trusted implementation makes agentic engineering much more of a safe bet.
Writing about Agentic Engineering Patterns

I’ve started a new project to collect and document Agentic Engineering Patterns—coding practices and patterns to help get the best results out of this new era of coding agent development we find ourselves entering.
[... 554 words]Writing code is cheap now
The biggest challenge in adopting agentic engineering practices is getting comfortable with the consequences of the fact that writing code is cheap now.
Code has always been expensive. Producing a few hundred lines of clean, tested code takes most software developers a full day or more. Many of our engineering habits, at both the macro and micro level, are built around this core constraint.
At the macro level we spend a great deal of time designing, estimating and planning out projects, to ensure that our expensive coding time is spent as efficiently as possible. Product feature ideas are evaluated in terms of how much value they can provide in exchange for that time - a feature needs to earn its development costs many times over to be worthwhile! [... 661 words]
The paper asked me to explain vibe coding, and I did so, because I think something big is coming there, and I'm deep in, and I worry that normal people are not able to see it and I want them to be prepared. But people can't just read something and hate you quietly; they can't see that you have provided them with a utility or a warning; they need their screech. You are distributed to millions of people, and become the local proxy for the emotions of maybe dozens of people, who disagree and demand your attention, and because you are the one in the paper you need to welcome them with a pastor's smile and deep empathy, and if you speak a word in your own defense they'll screech even louder.
— Paul Ford, on writing about vibe coding for the New York Times
The latest scourge of Twitter is AI bots that reply to your tweets with generic, banal commentary slop, often accompanied by a question to "drive engagement" and waste as much of your time as possible.
I just found out that the category name for this genre of software is reply guy tools. Amazing.