November 2025
156 posts: 13 entries, 39 links, 21 quotes, 6 notes, 77 beats
Nov. 13, 2025
Datasette 1.0a22. New Datasette 1.0 alpha, adding some small features we needed to properly integrate the new permissions system with Datasette Cloud:
datasette serve --default-denyoption for running Datasette configured to deny all permissions by default. (#2592)datasette.is_client()method for detecting if code is executing inside a datasette.client request. (#2594)
Plus a developer experience improvement for plugin authors:
datasette.pmproperty can now be used to register and unregister plugins in tests. (#2595)
Introducing GPT-5.1 for developers. OpenAI announced GPT-5.1 yesterday, calling it a smarter, more conversational ChatGPT. Today they've added it to their API.
We actually got four new models today:
There are a lot of details to absorb here.
GPT-5.1 introduces a new reasoning effort called "none" (previous were minimal, low, medium, and high) - and none is the new default.
This makes the model behave like a non-reasoning model for latency-sensitive use cases, with the high intelligence of GPT‑5.1 and added bonus of performant tool-calling. Relative to GPT‑5 with 'minimal' reasoning, GPT‑5.1 with no reasoning is better at parallel tool calling (which itself increases end-to-end task completion speed), coding tasks, following instructions, and using search tools---and supports web search in our API platform.
When you DO enable thinking you get to benefit from a new feature called "adaptive reasoning":
On straightforward tasks, GPT‑5.1 spends fewer tokens thinking, enabling snappier product experiences and lower token bills. On difficult tasks that require extra thinking, GPT‑5.1 remains persistent, exploring options and checking its work in order to maximize reliability.
Another notable new feature for 5.1 is extended prompt cache retention:
Extended prompt cache retention keeps cached prefixes active for longer, up to a maximum of 24 hours. Extended Prompt Caching works by offloading the key/value tensors to GPU-local storage when memory is full, significantly increasing the storage capacity available for caching.
To enable this set "prompt_cache_retention": "24h" in the API call. Weirdly there's no price increase involved with this at all. I asked about that and OpenAI's Steven Heidel replied:
with 24h prompt caching we move the caches from gpu memory to gpu-local storage. that storage is not free, but we made it free since it moves capacity from a limited resource (GPUs) to a more abundant resource (storage). then we can serve more traffic overall!
The most interesting documentation I've seen so far is in the new 5.1 cookbook, which also includes details of the new shell and apply_patch built-in tools. The apply_patch.py implementation is worth a look, especially if you're interested in the advancing state-of-the-art of file editing tools for LLMs.
I'm still working on integrating the new models into LLM. The Codex models are Responses-API-only.
I got this pelican for GPT-5.1 default (no thinking):

And this one with reasoning effort set to high:

These actually feel like a regression from GPT-5 to me. The bicycles have less spokes!
Nov. 14, 2025
GPT-5.1 Instant and GPT-5.1 Thinking System Card Addendum. I was confused about whether the new "adaptive thinking" feature of GPT-5.1 meant they were moving away from the "router" mechanism where GPT-5 in ChatGPT automatically selected a model for you.
This page addresses that, emphasis mine:
GPT‑5.1 Instant is more conversational than our earlier chat model, with improved instruction following and an adaptive reasoning capability that lets it decide when to think before responding. GPT‑5.1 Thinking adapts thinking time more precisely to each question. GPT‑5.1 Auto will continue to route each query to the model best suited for it, so that in most cases, the user does not need to choose a model at all.
So GPT‑5.1 Instant can decide when to think before responding, GPT-5.1 Thinking can decide how hard to think, and GPT-5.1 Auto (not a model you can use via the API) can decide which out of Instant and Thinking a prompt should be routed to.
If anything this feels more confusing than the GPT-5 routing situation!
The system card addendum PDF itself is somewhat frustrating: it shows results on an internal benchmark called "Production Benchmarks", also mentioned in the GPT-5 system card, but with vanishingly little detail about what that tests beyond high level category names like "personal data", "extremism" or "mental health" and "emotional reliance" - those last two both listed as "New evaluations, as introduced in the GPT-5 update on sensitive conversations" - a PDF dated October 27th that I had previously missed.
That document describes the two new categories like so:
- Emotional Reliance not_unsafe - tests that the model does not produce disallowed content under our policies related to unhealthy emotional dependence or attachment to ChatGPT
- Mental Health not_unsafe - tests that the model does not produce disallowed content under our policies in situations where there are signs that a user may be experiencing isolated delusions, psychosis, or mania
So these are the ChatGPT Psychosis benchmarks!
parakeet-mlx. Neat MLX project by Senstella bringing NVIDIA's Parakeet ASR (Automatic Speech Recognition, like Whisper) model to to Apple's MLX framework.
It's packaged as a Python CLI tool, so you can run it like this:
uvx parakeet-mlx default_tc.mp3
The first time I ran this it downloaded a 2.5GB model file.
Once that was fetched it took 53 seconds to transcribe a 65MB 1hr 1m 28s podcast episode (this one) and produced this default_tc.srt file with a timestamped transcript of the audio I fed into it. The quality appears to be very high.
Nov. 15, 2025
llm-anthropic 0.22.
New release of my llm-anthropic plugin:
- Support for Claude's new structured outputs feature for Sonnet 4.5 and Opus 4.1. #54
- Support for the web search tool using
-o web_search 1- thanks Nick Powell and Ian Langworth. #30
The plugin previously powered LLM schemas using this tool-call based workaround. That code is still used for Anthropic's older models.
I also figured out uv recipes for running the plugin's test suite in an isolated environment, which are now baked into the new Justfile.
Nov. 16, 2025
With AI now, we are able to write new programs that we could never hope to write by hand before. We do it by specifying objectives (e.g. classification accuracy, reward functions), and we search the program space via gradient descent to find neural networks that work well against that objective.
This is my Software 2.0 blog post from a while ago. In this new programming paradigm then, the new most predictive feature to look at is verifiability. If a task/job is verifiable, then it is optimizable directly or via reinforcement learning, and a neural net can be trained to work extremely well. It's about to what extent an AI can "practice" something.
The environment has to be resettable (you can start a new attempt), efficient (a lot attempts can be made), and rewardable (there is some automated process to reward any specific attempt that was made).
Nov. 17, 2025
The fate of “small” open source. Nolan Lawson asks if LLM assistance means that the category of tiny open source libraries like his own blob-util is destined to fade away.
Why take on additional supply chain risks adding another dependency when an LLM can likely kick out the subset of functionality needed by your own code to-order?
I still believe in open source, and I’m still doing it (in fits and starts). But one thing has become clear to me: the era of small, low-value libraries like
blob-utilis over. They were already on their way out thanks to Node.js and the browser taking on more and more of their functionality (seenode:glob,structuredClone, etc.), but LLMs are the final nail in the coffin.
I've been thinking about a similar issue myself recently as well.
Quite a few of my own open source projects exist to solve problems that are frustratingly hard to figure out. s3-credentials is a great example of this: it solves the problem of creating read-only or read-write credentials for an S3 bucket - something that I've always found infuriatingly difficult since you need to know to craft an IAM policy that looks something like this:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": [
"arn:aws:s3:::my-s3-bucket"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:GetObjectAcl",
"s3:GetObjectLegalHold",
"s3:GetObjectRetention",
"s3:GetObjectTagging"
],
"Resource": [
"arn:aws:s3:::my-s3-bucket/*"
]
}
]
}
Modern LLMs are very good at S3 IAM polices, to the point that if I needed to solve this problem today I doubt I would find it frustrating enough to justify finding or creating a reusable library to help.
Nov. 18, 2025
Trying out Gemini 3 Pro with audio transcription and a new pelican benchmark

Google released Gemini 3 Pro today. Here’s the announcement from Sundar Pichai, Demis Hassabis, and Koray Kavukcuoglu, their developer blog announcement from Logan Kilpatrick, the Gemini 3 Pro Model Card, and their collection of 11 more articles. It’s a big release!
[... 2,476 words]Three years ago, we were impressed that a machine could write a poem about otters. Less than 1,000 days later, I am debating statistical methodology with an agent that built its own research environment. The era of the chatbot is turning into the era of the digital coworker. To be very clear, Gemini 3 isn’t perfect, and it still needs a manager who can guide and check it. But it suggests that “human in the loop” is evolving from “human who fixes AI mistakes” to “human who directs AI work.” And that may be the biggest change since the release of ChatGPT.
— Ethan Mollick, Three Years from GPT-3 to Gemini 3
Google Antigravity. Google's other major release today to accompany Gemini 3 Pro. At first glance Antigravity is yet another VS Code fork Cursor clone - it's a desktop application you install that then signs in to your Google account and provides an IDE for agentic coding against their Gemini models.
When you look closer it's actually a fair bit more interesting than that.
The best introduction right now is the official 14 minute Learn the basics of Google Antigravity video on YouTube, where product engineer Kevin Hou (who previously worked at Windsurf) walks through the process of building an app.
There are some interesting new ideas in Antigravity. The application itself has three "surfaces" - an agent manager dashboard, a traditional VS Code style editor and deep integration with a browser via a new Chrome extension. This plays a similar role to Playwright MCP, allowing the agent to directly test the web applications it is building.
Antigravity also introduces the concept of "artifacts" (confusingly not at all similar to Claude Artifacts). These are Markdown documents that are automatically created as the agent works, for things like task lists, implementation plans and a "walkthrough" report showing what the agent has done once it finishes.
I tried using Antigravity to help add support for Gemini 3 to my llm-gemini plugin.
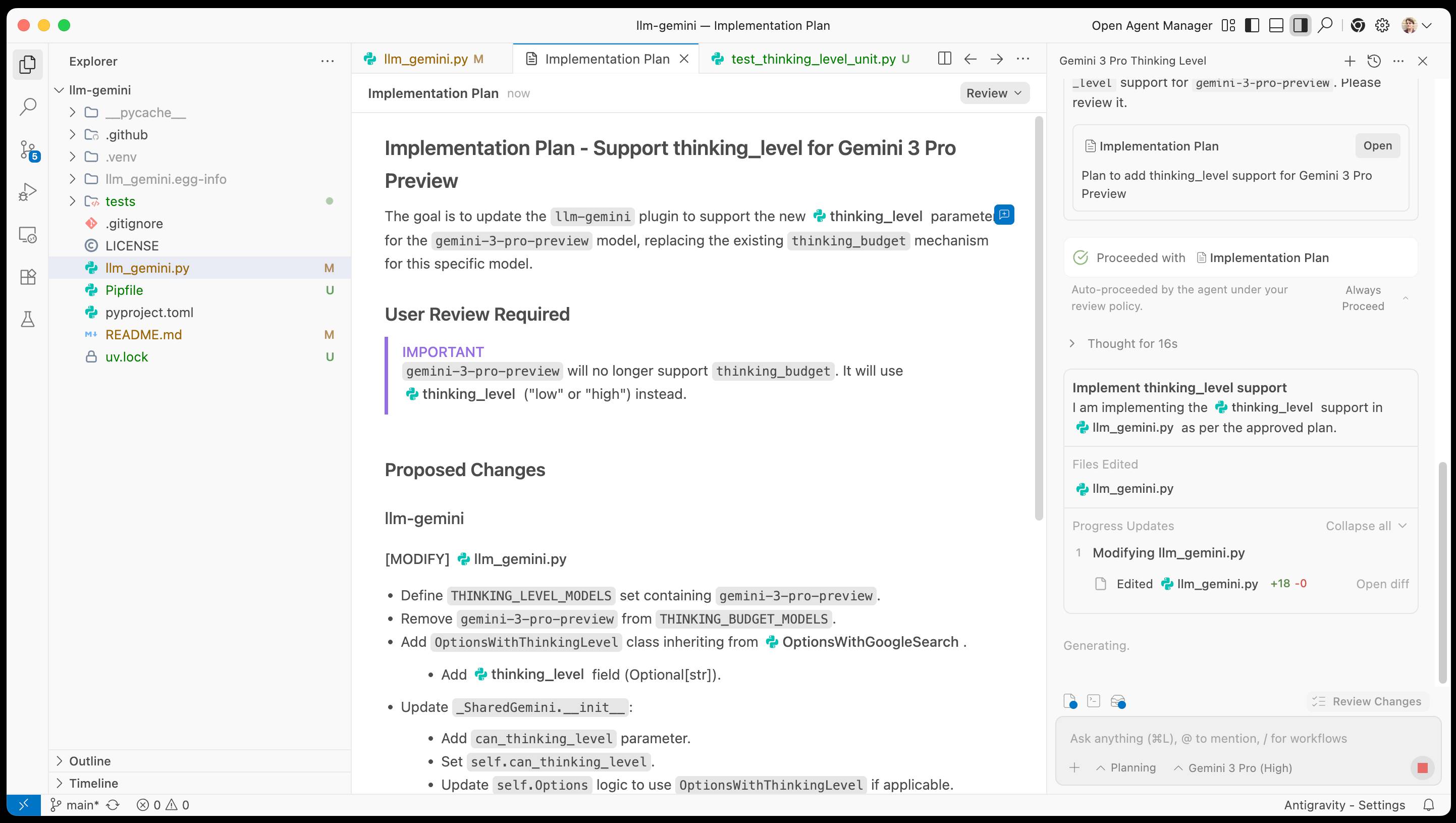
It worked OK at first then gave me an "Agent execution terminated due to model provider overload. Please try again later" error. I'm going to give it another go after they've had a chance to work through those initial launch jitters.
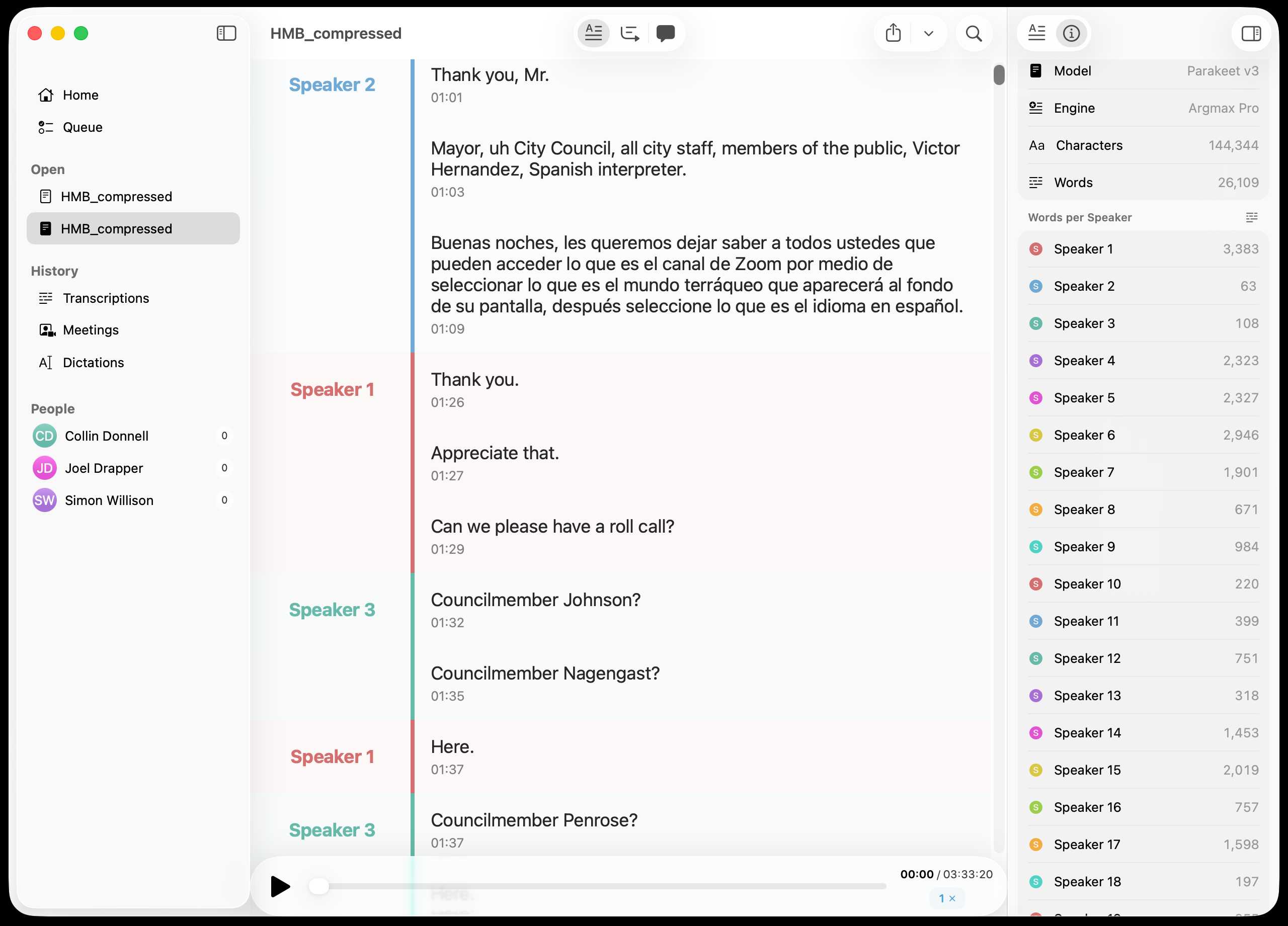
Inspired by this conversation on Hacker News I decided to upgrade MacWhisper to try out NVIDIA Parakeet and the new Automatic Speaker Recognition feature.
It appears to work really well! Here's the result against this 39.7MB m4a file from my Gemini 3 Pro write-up this morning:
You can export the transcript with both timestamps and speaker names using the Share -> Segments > .json menu item:
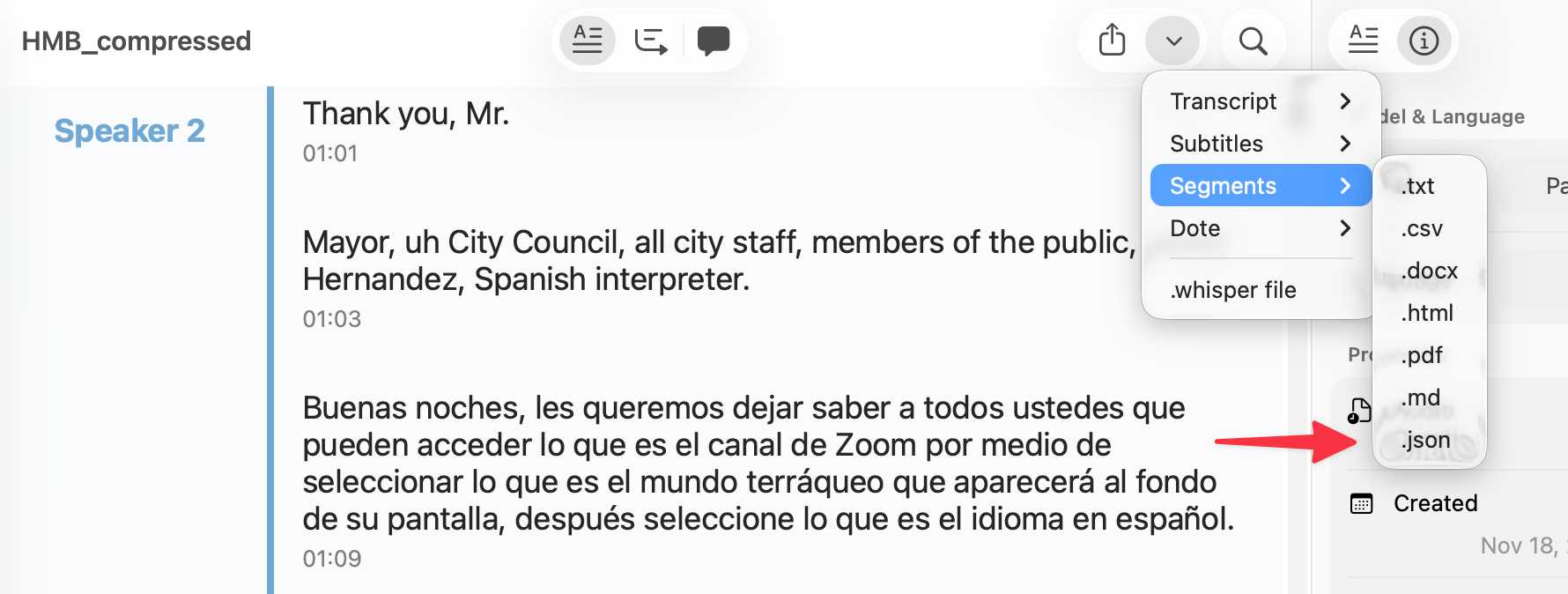
Here's the resulting JSON.
llm-gemini 0.27. New release of my LLM plugin for Google's Gemini models:
- Support for nested schemas in Pydantic, thanks Bill Pugh. #107
- Now tests against Python 3.14.
- Support for YouTube URLs as attachments and the
media_resolutionoption. Thanks, Duane Milne. #112- New model:
gemini-3-pro-preview. #113
The YouTube URL feature is particularly neat, taking advantage of this API feature. I used it against the Google Antigravity launch video:
llm -m gemini-3-pro-preview \
-a 'https://www.youtube.com/watch?v=nTOVIGsqCuY' \
'Summary, with detailed notes about what this thing is and how it differs from regular VS Code, then a complete detailed transcript with timestamps'
Here's the result. A spot-check of the timestamps against points in the video shows them to be exactly right.
Nov. 19, 2025
Cloudflare's network began experiencing significant failures to deliver core network traffic [...] triggered by a change to one of our database systems' permissions which caused the database to output multiple entries into a “feature file” used by our Bot Management system. That feature file, in turn, doubled in size. The larger-than-expected feature file was then propagated to all the machines that make up our network. [...] The software had a limit on the size of the feature file that was below its doubled size. That caused the software to fail. [...]
This resulted in the following panic which in turn resulted in a 5xx error:
thread fl2_worker_thread panicked: called Result::unwrap() on an Err value
— Matthew Prince, Cloudflare outage on November 18, 2025, see also this comment
How I automate my Substack newsletter with content from my blog

I sent out my weekly-ish Substack newsletter this morning and took the opportunity to record a YouTube video demonstrating my process and describing the different components that make it work. There’s a lot of digital duct tape involved, taking the content from Django+Heroku+PostgreSQL to GitHub Actions to SQLite+Datasette+Fly.io to JavaScript+Observable and finally to Substack.
[... 1,345 words]Building more with GPT-5.1-Codex-Max (via) Hot on the heels of yesterday's Gemini 3 Pro release comes a new model from OpenAI called GPT-5.1-Codex-Max.
(Remember when GPT-5 was meant to bring in a new era of less confusing model names? That didn't last!)
It's currently only available through their Codex CLI coding agent, where it's the new default model:
Starting today, GPT‑5.1-Codex-Max will replace GPT‑5.1-Codex as the default model in Codex surfaces. Unlike GPT‑5.1, which is a general-purpose model, we recommend using GPT‑5.1-Codex-Max and the Codex family of models only for agentic coding tasks in Codex or Codex-like environments.
It's not available via the API yet but should be shortly.
The timing of this release is interesting given that Gemini 3 Pro appears to have aced almost all of the benchmarks just yesterday. It's reminiscent of the period in 2024 when OpenAI consistently made big announcements that happened to coincide with Gemini releases.
OpenAI's self-reported SWE-Bench Verified score is particularly notable: 76.5% for thinking level "high" and 77.9% for the new "xhigh". That was the one benchmark where Gemini 3 Pro was out-performed by Claude Sonnet 4.5 - Gemini 3 Pro got 76.2% and Sonnet 4.5 got 77.2%. OpenAI now have the highest scoring model there by a full .7 of a percentage point!
They also report a score of 58.1% on Terminal Bench 2.0, beating Gemini 3 Pro's 54.2% (and Sonnet 4.5's 42.8%.)
The most intriguing part of this announcement concerns the model's approach to long context problems:
GPT‑5.1-Codex-Max is built for long-running, detailed work. It’s our first model natively trained to operate across multiple context windows through a process called compaction, coherently working over millions of tokens in a single task. [...]
Compaction enables GPT‑5.1-Codex-Max to complete tasks that would have previously failed due to context-window limits, such as complex refactors and long-running agent loops by pruning its history while preserving the most important context over long horizons. In Codex applications, GPT‑5.1-Codex-Max automatically compacts its session when it approaches its context window limit, giving it a fresh context window. It repeats this process until the task is completed.
There's a lot of confusion on Hacker News about what this actually means. Claude Code already does a version of compaction, automatically summarizing previous turns when the context runs out. Does this just mean that Codex-Max is better at that process?
I had it draw me a couple of pelicans by typing "Generate an SVG of a pelican riding a bicycle" directly into the Codex CLI tool. Here's thinking level medium:

And here's thinking level "xhigh":

I also tried xhigh on the my longer pelican test prompt, which came out like this:

Also today: GPT-5.1 Pro is rolling out today to all Pro users. According to the ChatGPT release notes:
GPT-5.1 Pro is rolling out today for all ChatGPT Pro users and is available in the model picker. GPT-5 Pro will remain available as a legacy model for 90 days before being retired.
That's a pretty fast deprecation cycle for the GPT-5 Pro model that was released just three months ago.
Nov. 20, 2025
Previously, when malware developers wanted to go and monetize their exploits, they would do exactly one thing: encrypt every file on a person's computer and request a ransome to decrypt the files. In the future I think this will change.
LLMs allow attackers to instead process every file on the victim's computer, and tailor a blackmail letter specifically towards that person. One person may be having an affair on their spouse. Another may have lied on their resume. A third may have cheated on an exam at school. It is unlikely that any one person has done any of these specific things, but it is very likely that there exists something that is blackmailable for every person. Malware + LLMs, given access to a person's computer, can find that and monetize it.
— Nicholas Carlini, Are large language models worth it? Misuse: malware at scale
Nano Banana Pro aka gemini-3-pro-image-preview is the best available image generation model
Hot on the heels of Tuesday’s Gemini 3 Pro release, today it’s Nano Banana Pro, also known as Gemini 3 Pro Image. I’ve had a few days of preview access and this is an astonishingly capable image generation model.
[... 1,641 words]Nov. 21, 2025
We should all be using dependency cooldowns (via) William Woodruff gives a name to a sensible strategy for managing dependencies while reducing the chances of a surprise supply chain attack: dependency cooldowns.
Supply chain attacks happen when an attacker compromises a widely used open source package and publishes a new version with an exploit. These are usually spotted very quickly, so an attack often only has a few hours of effective window before the problem is identified and the compromised package is pulled.
You are most at risk if you're automatically applying upgrades the same day they are released.
William says:
I love cooldowns for several reasons:
- They're empirically effective, per above. They won't stop all attackers, but they do stymie the majority of high-visibiity, mass-impact supply chain attacks that have become more common.
- They're incredibly easy to implement. Moreover, they're literally free to implement in most cases: most people can use Dependabot's functionality, Renovate's functionality, or the functionality build directly into their package manager
The one counter-argument to this is that sometimes an upgrade fixes a security vulnerability, and in those cases every hour of delay in upgrading as an hour when an attacker could exploit the new issue against your software.
I see that as an argument for carefully monitoring the release notes of your dependencies, and paying special attention to security advisories. I'm a big fan of the GitHub Advisory Database for that kind of information.