April 2024
147 posts: 5 entries, 59 links, 26 quotes, 57 beats
April 20, 2024
The blog post announcing the shutdown was done one day early. The idea was to take the opportunity of the new Pope being announced and Andy Rubin being replaced as head of Android, so that the [Google] Reader news may be drowned out. PR didn't apparently realize that the kinds of people that care about the other two events (especially the Pope) are not the same kind of people that care about Reader, so it didn't work.
April 21, 2024
doom-htop (via) Ludicrous, brilliant hack: it runs Doom, converts each frame to ASCII art, then runs one process for each line of ASCII and sets each process to allocate enough memory such that sorting by M_VIRT will show the lines in the correct order. Then it updates the argv[0] for each process on every frame such that htop displays the state of the game.
Probably only works on Ubuntu.
From the FAQ: “Q: Why did you make this? A: I thought it would be funny.”
tiny-world-map (via) I love this project. It’s a JavaScript file (694K uncompressed, 283KB compressed) which can be used with the Leaflet mapping library and provides a SVG base map of the world with country borders and labels for every world city with a population more than 48,000—10,000 cities total.
This means you can bundle an offline map of the world as part of any application that doesn’t need a higher level of detail. A lot of smaller island nations are missing entirely though, so this may not be right for every project.
It even includes a service worker to help implement offline mapping support, plus several variants of the map with less cities that are even smaller.
qrank (via) Interesting and very niche project by Colin Dellow.
Wikidata has pages for huge numbers of concepts, people, places and things.
One of the many pieces of data they publish is QRank—“ranking Wikidata entities by aggregating page views on Wikipedia, Wikispecies, Wikibooks, Wikiquote, and other Wikimedia projects”. Every item gets a score and these scores can be used to answer questions like “which island nations get the most interest across Wikipedia”—potentially useful for things like deciding which labels to display on a highly compressed map of the world.
QRank is published as a gzipped CSV file.
Colin’s hikeratlas/qrank GitHub repository runs weekly, fetches the latest qrank.csv.gz file and loads it into a SQLite database using SQLite’s “.import” mechanism. Then it publishes the resulting SQLite database as an asset attached to the “latest” GitHub release on that repo—currently a 307MB file.
The database itself has just a single table mapping the Wikidata ID (a primary key integer) to the latest QRank—another integer. You’d need your own set of data with Wikidata IDs to join against this to do anything useful.
I’d never thought of using GitHub Releases for this kind of thing. I think it’s a really interesting pattern.
April 22, 2024
Options for accessing Llama 3 from the terminal using LLM
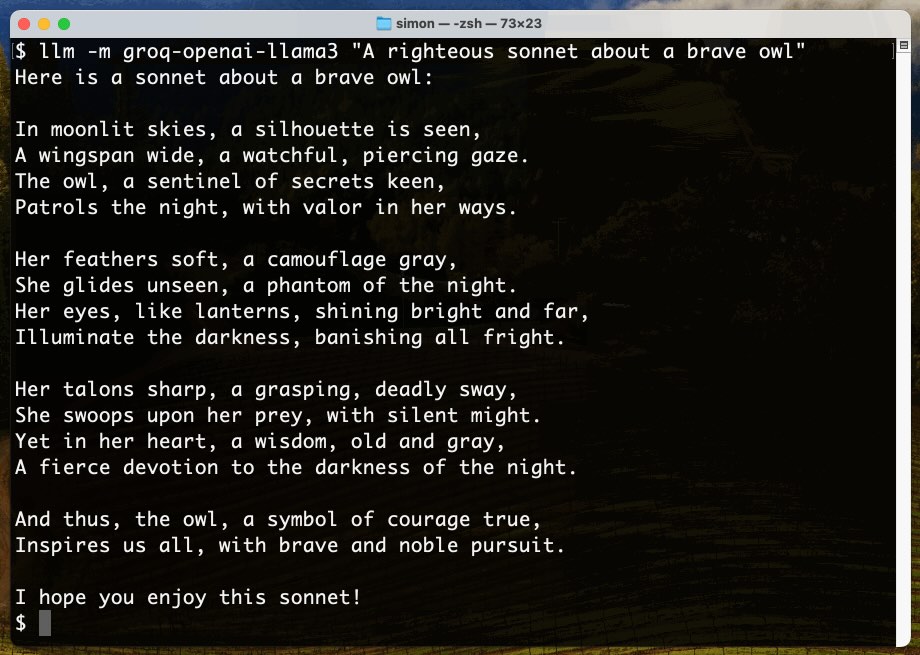
Llama 3 was released on Thursday. Early indications are that it’s now the best available openly licensed model—Llama 3 70b Instruct has taken joint 5th place on the LMSYS arena leaderboard, behind only Claude 3 Opus and some GPT-4s and sharing 5th place with Gemini Pro and Claude 3 Sonnet. But unlike those other models Llama 3 70b is weights available and can even be run on a (high end) laptop!
[... 1,962 words]No one buys books (via) Fascinating insights into the book publishing industry gathered by Elle Griffin from details that came out during the Penguin vs. DOJ antitrust lawsuit.
Publishing turns out to be similar to VC investing: a tiny percentage of books are hits that cover the costs for the vast majority that didn't sell well. The DOJ found that, of 58,000 books published in a year, "90 percent of them sold fewer than 2,000 copies and 50 percent sold less than a dozen copies."
UPDATE: This story is inaccurate: those statistics were grossly misinterpreted during the trial. See this post for updated information.
Here's an even better debunking: Yes, People Do Buy Books (subtitle: "Despite viral claims, Americans buy over a billion books a year").
timpaul/form-extractor-prototype (via) Tim Paul, Head of Interaction Design at the UK's Government Digital Service, published this brilliant prototype built on top of Claude 3 Opus.
The video shows what it can do. Give it an image of a form and it will extract the form fields and use them to create a GDS-style multi-page interactive form, using their GOV.UK design system and govuk-frontend npm package.
It works for both hand-drawn napkin illustrations and images of existing paper forms.
The bulk of the prompting logic is the schema definition in data/extract-form-questions.json.
I'm always excited to see applications built on LLMs that go beyond the chatbot UI. This is a great example of exactly that.
April 23, 2024
We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone.
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions (via) By far the most detailed paper on prompt injection I’ve seen yet from OpenAI, published a few days ago and with six credited authors: Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke and Alex Beutel.
The paper notes that prompt injection mitigations which completely refuse any form of instruction in an untrusted prompt may not actually be ideal: some forms of instruction are harmless, and refusing them may provide a worse experience.
Instead, it proposes a hierarchy—where models are trained to consider if instructions from different levels conflict with or support the goals of the higher-level instructions—if they are aligned or misaligned with them.
The authors tested this idea by fine-tuning a model on top of GPT 3.5, and claim that it shows greatly improved performance against numerous prompt injection benchmarks.
As always with prompt injection, my key concern is that I don’t think “improved” is good enough here. If you are facing an adversarial attacker reducing the chance that they might find an exploit just means they’ll try harder until they find an attack that works.
The paper concludes with this note: “Finally, our current models are likely still vulnerable to powerful adversarial attacks. In the future, we will conduct more explicit adversarial training, and study more generally whether LLMs can be made sufficiently robust to enable high-stakes agentic applications.”
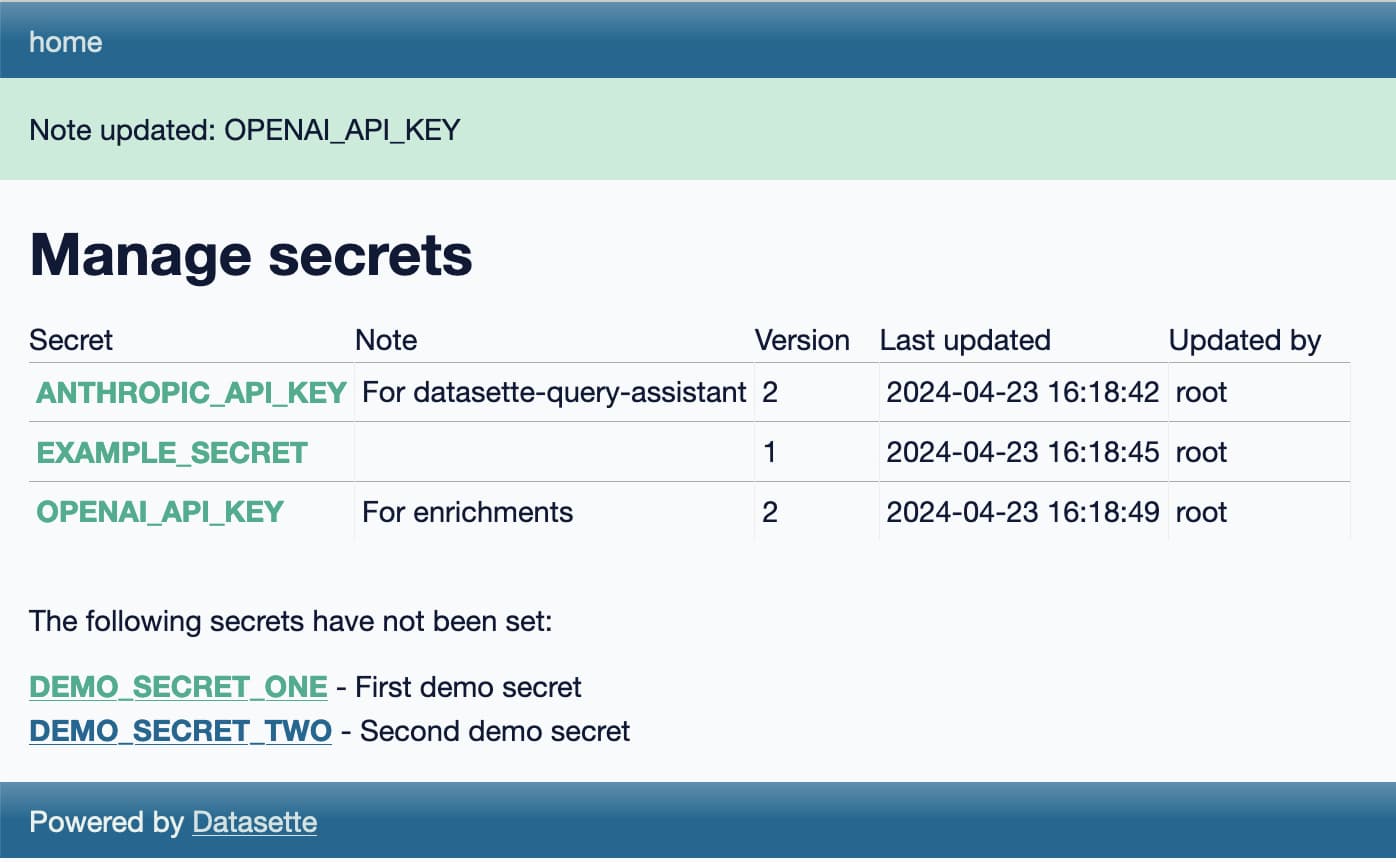
Weeknotes: Llama 3, AI for Data Journalism, llm-evals and datasette-secrets
Llama 3 landed on Thursday. I ended up updating a whole bunch of different plugins to work with it, described in Options for accessing Llama 3 from the terminal using LLM.
[... 1,030 words]microsoft/Phi-3-mini-4k-instruct-gguf (via) Microsoft’s Phi-3 LLM is out and it’s really impressive. This 4,000 token context GGUF model is just a 2.2GB (for the Q4 version) and ran on my Mac using the llamafile option described in the README. I could then run prompts through it using the llm-llamafile plugin.
The vibes are good! Initial test prompts I’ve tried feel similar to much larger 7B models, despite using just a few GBs of RAM. Tokens are returned fast too—it feels like the fastest model I’ve tried yet.
And it’s MIT licensed.
We [Bluesky] took a somewhat novel approach of giving every user their own SQLite database. By removing the Postgres dependency, we made it possible to run a ‘PDS in a box’ [Personal Data Server] without having to worry about managing a database. We didn’t have to worry about things like replicas or failover. For those thinking this is irresponsible: don’t worry, we are backing up all the data on our PDSs!
SQLite worked really well because the PDS – in its ideal form – is a single-tenant system. We owned up to that by having these single tenant SQLite databases.
April 24, 2024
A bad survey won’t tell you it’s bad. It’s actually really hard to find out that a bad survey is bad — or to tell whether you have written a good or bad set of questions. Bad code will have bugs. A bad interface design will fail a usability test. It’s possible to tell whether you are having a bad user interview right away. Feedback from a bad survey can only come in the form of a second source of information contradicting your analysis of the survey results.
Most seductively, surveys yield responses that are easy to count and counting things feels so certain and objective and truthful.
Even if you are counting lies.
openelm/README-pretraining.md. Apple released something big three hours ago, and I’m still trying to get my head around exactly what it is.
The parent project is called CoreNet, described as “A library for training deep neural networks”. Part of the release is a new LLM called OpenELM, which includes completely open source training code and a large number of published training checkpoint.
I’m linking here to the best documentation I’ve found of that training data: it looks like the bulk of it comes from RefinedWeb, RedPajama, The Pile and Dolma.
When I said “Send a text message to Julian Chokkattu,” who’s a friend and fellow AI Pin reviewer over at Wired, I thought I’d be asked what I wanted to tell him. Instead, the device simply said OK and told me it sent the words “Hey Julian, just checking in. How's your day going?” to Chokkattu. I've never said anything like that to him in our years of friendship, but I guess technically the AI Pin did do what I asked.
April 25, 2024
Snowflake Arctic Cookbook. Today's big model release was Snowflake Arctic, an enormous 480B model with a 128×3.66B MoE (Mixture of Experts) architecture. It's Apache 2 licensed and Snowflake state that "in addition, we are also open sourcing all of our data recipes and research insights."
The research insights will be shared on this Arctic Cookbook blog - which currently has two articles covering their MoE architecture and describing how they optimized their training run in great detail.
They also list dozens of "coming soon" posts, which should be pretty interesting given how much depth they've provided in their writing so far.
No, Most Books Don’t Sell Only a Dozen Copies. I linked to a story the other day about book sales claiming "90 percent of them sold fewer than 2,000 copies and 50 percent sold less than a dozen copies", based on numbers released in the Penguin antitrust lawsuit. It turns out those numbers were interpreted incorrectly.
In this piece from September 2022 Lincoln Michel addresses this and other common misconceptions about book statistics.
Understanding these numbers requires understanding a whole lot of intricacies about how publishing actually works. Here's one illustrative snippet:
"Take the statistic that most published books only sell 99 copies. This seems shocking on its face. But if you dig into it, you’ll notice it was counting one year’s sales of all books that were in BookScan’s system. That’s quite different statistic than saying most books don’t sell 100 copies in total! A book could easily be a bestseller in, say, 1960 and sell only a trickle of copies today."
The top comment on the post comes from Kristen McLean of NPD BookScan, the organization who's numbers were misrepresented is the trial. She wasn't certain how the numbers had been sliced to get that 90% result, but in her own analysis of "frontlist sales for the top 10 publishers by unit volume in the U.S. Trade market" she found that 14.7% sold less than 12 copies and the 51.4% spot was for books selling less than a thousand.
Blogmarks that use markdown. I needed to attach a correction to an older blogmark (my 20-year old name for short-form links with commentary on my blog) today - but the commentary field has always been text, not HTML, so I didn't have a way to add the necessary link.
This motivated me to finally add optional Markdown support for blogmarks to my blog's custom Django CMS. I then went through and added inline code markup to a bunch of different older posts, and built this Django SQL Dashboard to keep track of which posts I had updated.